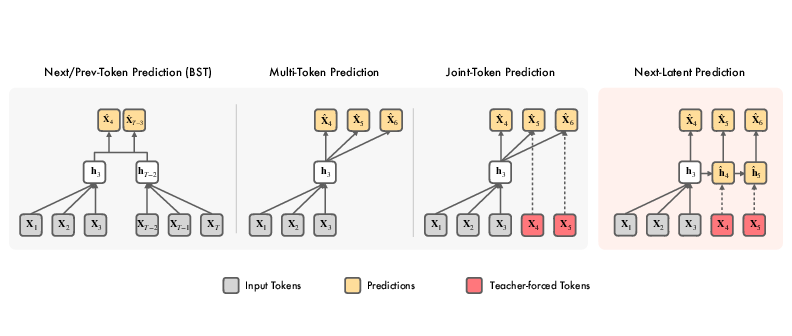
Next-Latent Prediction Transformers Learn Compact World Models
Abstract: Transformers replace recurrence with a memory that grows with sequence length and self-attention that enables ad-hoc look ups over past tokens. Consequently, they lack an inherent incentive to compress history into compact latent states with consistent transition rules. This often leads to learning solutions that generalize poorly. We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space. Specifically, NextLat trains a transformer to learn latent representations that are predictive of its next latent state given the next output token. Theoretically, we show that these latents provably converge to belief states, compressed information of the history necessary to predict the future. This simple auxiliary objective also injects a recurrent inductive bias into transformers, while leaving their architecture, parallel training, and inference unchanged. NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics -- a crucial property absent in standard next-token prediction transformers. Empirically, across benchmarks targeting core sequence modeling competencies -- world modeling, reasoning, planning, and language modeling -- NextLat demonstrates significant gains over standard next-token training in downstream accuracy, representation compression, and lookahead planning. NextLat stands as a simple and efficient paradigm for shaping transformer representations toward stronger generalization.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a new way to train transformer models (the kind of AI used in tools like ChatGPT) so they learn a simpler, more reliable “internal understanding” of the world. The method is called Next-Latent Prediction (NextLat). It teaches a transformer not just to guess the next word or token, but also to predict how its own internal “memory” should change when the next token arrives. This helps the model build compact, consistent summaries of the past that make it better at planning, reasoning, and generalizing to new situations.
Key Questions the Paper Tries to Answer
The paper explores three easy-to-understand questions:
- Can we make transformers build simpler internal summaries of the past (like notes) that still contain everything needed to predict the future?
- If we do that, will transformers get better at tasks that require planning and long-term thinking, not just one-step-ahead predictions?
- Can we add this improvement without slowing down the model or changing how it runs during use?
How the Method Works (in everyday terms)
Imagine a transformer as a student reading a long story. Standard training asks the student to guess the next word—good for short-term accuracy, but the student can just skim and look up recent words without forming a solid understanding of the story’s structure.
NextLat adds a second, simple exercise:
- In addition to guessing the next word, the student also predicts how their own “mental summary” (their internal notes) should update after seeing that next word.
Here’s the core idea in plain language:
- Latent state = the model’s internal memory snapshot at each step (a compact vector).
- Next-token prediction = what transformers already do: guess the next token.
- Next-latent prediction = a small add-on that teaches the model to predict its next internal memory snapshot from its current snapshot plus the next token.
Think of it like a video game:
- The latent state is your current game HUD: health, position, inventory—a compressed summary.
- The next-latent prediction is the rule that updates your HUD after your next action.
- Training the model to learn both the “what happens next” and “how does my HUD update” helps it build a consistent world model with clear state transitions.
Technically (explained simply):
- The transformer keeps its usual architecture.
- A small helper network (called a latent dynamics model) learns to predict the next hidden state using the current hidden state and the next token.
- The training uses:
- The normal next-token loss (so language skills stay strong).
- A smooth loss that makes the predicted next hidden state match the real one.
- A KL loss that checks the predicted hidden state would lead to similar token predictions as the true hidden state.
- During actual use (inference), the helper network isn’t needed. The transformer runs as usual.
The authors also prove something important: if the model gets good at both next-token prediction and next-latent prediction, its hidden states become “belief states.” That’s a math term meaning the compact summaries truly contain everything needed to predict the future—like having a perfect set of notes for the story so far.
Main Findings and Why They Matter
The team tested NextLat across four kinds of tasks:
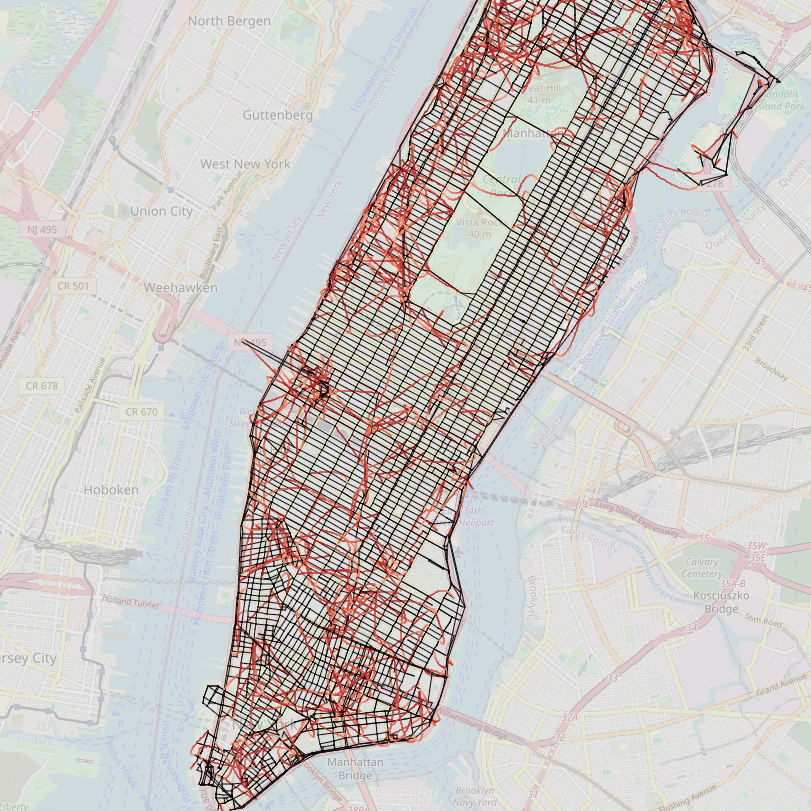
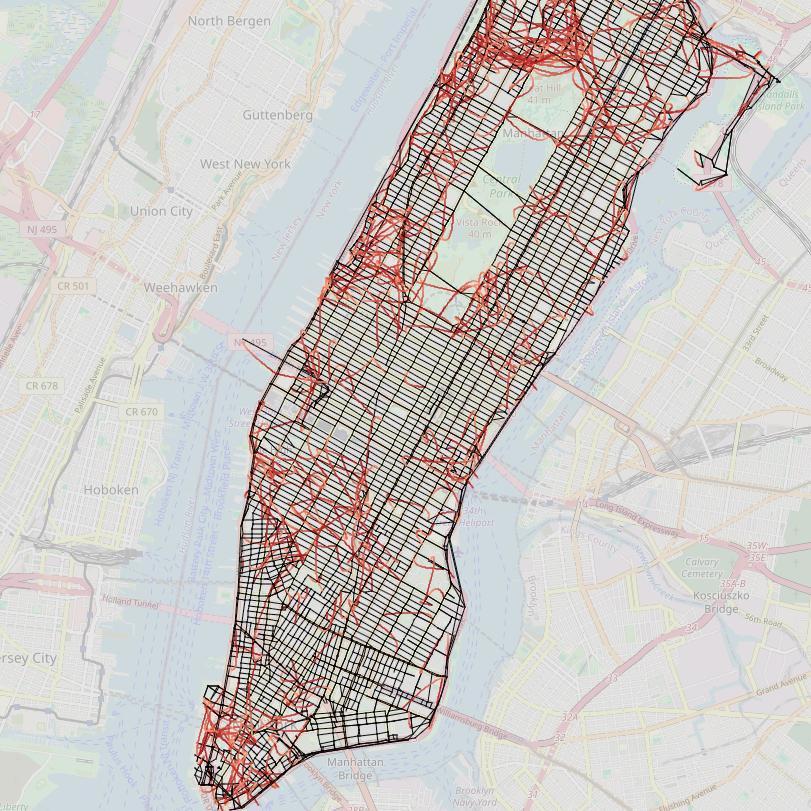
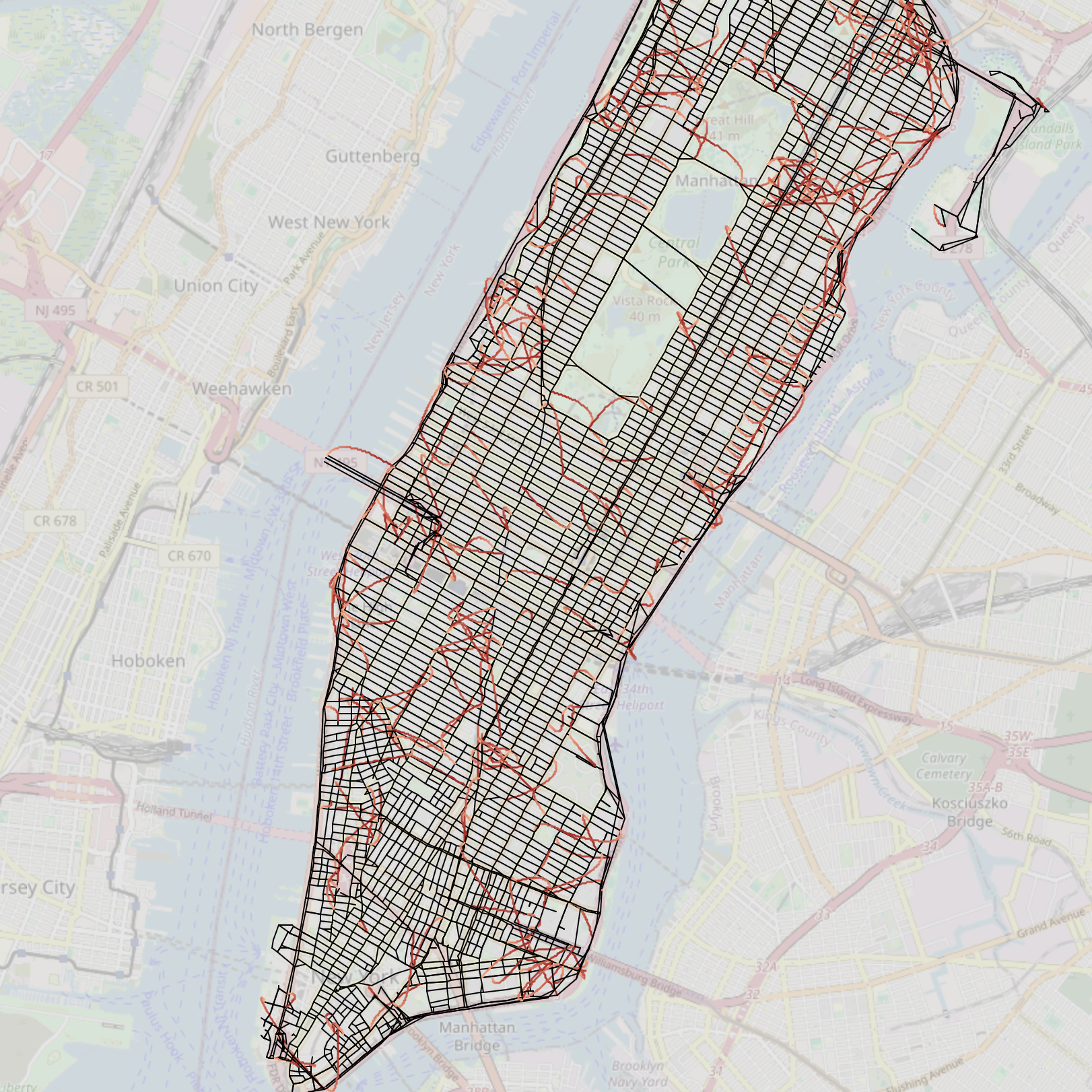
- World Modeling (Manhattan Taxi Rides)
- Task: Learn the structure of city streets from sequences of taxi turns.
- Why it matters: It checks if the model builds a consistent “map” of the world.
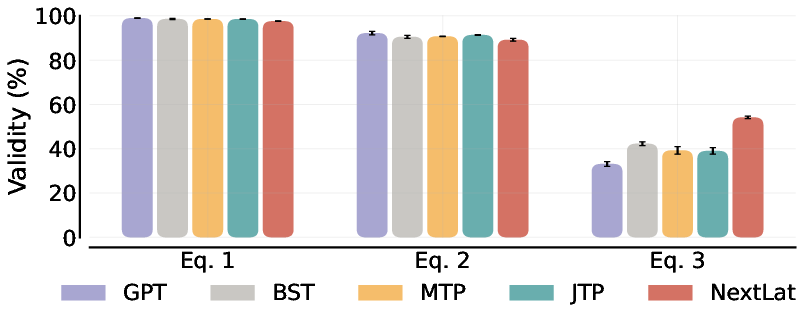
- Result: All models scored perfectly on next-token accuracy, but NextLat built a much cleaner, more accurate internal map. It:
- Produced more valid routes between new start and end points.
- Was more robust to detours.
- Compressed history better (its internal memory used fewer dimensions).
- Why it’s important: It shows NextLat helps transformers learn the real underlying structure, not just short-term patterns.
- Reasoning (Countdown math puzzle)
- Task: Use given numbers and basic arithmetic to reach a target number (like 24 from {90, 8, 20, 50}).
- Why it matters: This needs planning several steps ahead.
- Result: NextLat consistently beat other methods, especially at shallow horizons. It made fewer “regretful compromises” (wrong last steps to force the target), showing stronger lookahead planning.
- Why it’s important: Better planning means fewer mistakes when the path to the solution is long or tricky.
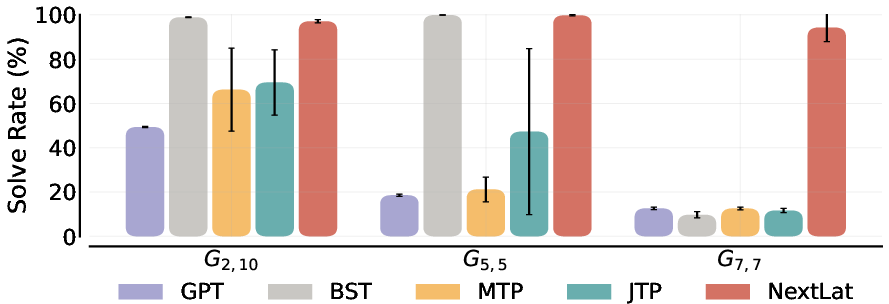
- Planning (Path-Star Graph)
- Task: Find a path through a graph with multiple arms—like navigating spokes on a wheel.
- Why it matters: Designed to expose models that rely on local shortcuts instead of real planning.
- Result: NextLat solved nearly 100% of cases across graph sizes, outperforming methods that only predict multiple future tokens.
- Why it’s important: Predicting in latent space (internal memory) avoids shallow token tricks and teaches the model the true transition structure.
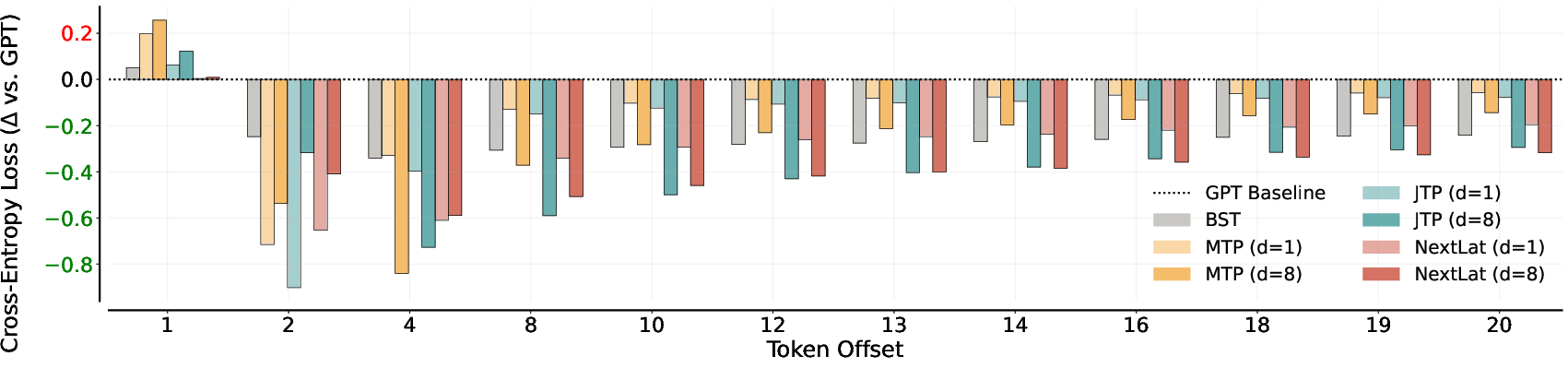
- Language Modeling (TinyStories)
- Task: Learn to write short stories and then test how well the model’s internal memory can predict many tokens ahead using simple linear probes.
- Why it matters: Good internal summaries should help predict far into the future, not just the next word.
- Result: NextLat kept next-token performance strong and had the best long-range predictions (up to 20 tokens ahead). Other multi-token methods often hurt next-token quality and faded at longer horizons.
- Why it’s important: It suggests NextLat builds belief-like representations that support coherent, longer narratives.
Efficiency and Practicality
- NextLat requires only a small helper network during training and doesn’t change the transformer’s architecture or how it runs.
- Training speed is close to standard transformers for short horizons and still efficient at longer ones.
- It avoids the heavy cost of some prior belief-state methods that need extra models or quadratic losses.
Implications: What could this mean for the future?
- Better generalization: Models that learn compact, consistent internal “world models” are less likely to be fooled by shortcuts and more likely to handle new, unseen situations.
- Stronger planning and reasoning: NextLat helps models think ahead, not just react—useful for math, navigation, coding, strategy games, and long-form writing.
- Efficiency without complexity: It adds a simple training objective but keeps the model fast and unchanged at use-time.
- A step toward smarter AI: Teaching models to maintain belief states (good summaries of the past) makes them more reliable, more interpretable, and better at building “mental maps” of tasks and environments.
In short, NextLat shows that small, smart changes in training can push transformers to learn deeper structure—helping them plan, reason, and generalize—without sacrificing speed or simplicity.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of gaps and open questions the paper leaves unresolved. Each item is phrased to be actionable for future research.
- Theoretical guarantees rely on exact “consistency” equalities (next-token and transition consistency) that are unattainable in finite-data, non-convex optimization; provide approximate guarantees (e.g., bounds showing that small emission/transition errors imply approximate belief states).
- Clarify gradient flow: with stop-gradients on h and a frozen output head in the KL term, the NextLat losses as written seem to update only the latent dynamics model p_psi, not the transformer’s latent states; specify how and where gradients shape transformer representations, or add an explicit term that backpropagates into the transformer via predicted latents.
- Formalize compactness: the theorem argues for belief states but does not guarantee minimality or compression; provide conditions under which learned belief states are minimal sufficient statistics, or derive bounds on latent dimensionality needed to represent the process.
- Identifiability and degeneracy: belief states are not unique; characterize the class of equivalent latent representations that satisfy the consistency objectives and propose regularizers or constraints that select compact, interpretable solutions.
- Robustness of latent dynamics under free-running generation: multi-step losses use teacher-forced tokens; evaluate whether learned p_psi generalizes when the model’s own predictions deviate, and quantify compounding errors in latent rollouts without teacher forcing.
- Use of p_psi at inference: the dynamics model is only used during training; investigate using p_psi for lookahead rollouts, planning, sequence scoring, consistency checks, or search (e.g., guiding beam search or planning over latent states).
- Sensitivity analyses missing: systematically study the impact of horizon d, the coefficients λ_next-h and λ_KL, loss choices (Smooth L1 vs. MSE), and stop-gradient placement on stability, convergence, and generalization.
- Architecture of p_psi: only simple MLPs are explored; benchmark alternative latent dynamics (e.g., residual MLPs, GRUs/SSMs, hypernetworks, JEPA-like heads) and quantify trade-offs in accuracy, stability, and compute at scale.
- Layer choice: NextLat operates on final-layer hidden states; assess whether applying NextLat on intermediate layers, or using multi-scale latents, improves compression and predictive sufficiency.
- Scalability to large LLMs and long contexts: results are on small/medium models; evaluate NextLat on billion-parameter models, long-context length generalization, and large-scale corpora to test training stability, throughput, and memory footprint.
- Mainstream LM metrics absent: report perplexity on standard benchmarks (e.g., WikiText-103, The Pile) and downstream tasks (e.g., GSM8K, MATH, HumanEval, BIG-bench) to assess generalization beyond TinyStories and synthetic tasks.
- Fair compute-matched comparisons: BST is excluded from Manhattan due to cost; provide compute-normalized comparisons (matched training tokens/time/parameters) across all baselines to isolate objective effects from capacity/training budget.
- Countdown analysis depth: include difficulty-stratified results, error taxonomy (operator choice, arithmetic, search failures), and ablations on pause-token count to understand which competencies NextLat improves.
- Path-Star generality: test larger d, ℓ, N, randomized topologies, and adversarial graph patterns; analyze failure modes and the extent to which NextLat mitigates Clever Hans-like shortcuts under diverse structures.
- Compression metrics beyond effective rank: the rank-based measure is heuristic; validate compression with mutual information estimates, Minimum Description Length (MDL) proxies, or spectrum/CCA analyses across tasks.
- Belief-state measurement: provide direct tests of sufficiency (e.g., can we decode future token distributions from latents without accessing the history?), and quantify how much future predictive information is retained as a function of horizon d.
- Observability horizon claims: JTP requires d ≥ k, whereas NextLat is claimed independent of k; formalize this independence and characterize the conditions under which NextLat succeeds when k is large or unbounded.
- Stochastic transformers: the paper mentions stochasticity but experiments/regression assume determinism; implement and evaluate variational NextLat for stochastic transformer layers, and measure its impact on learning belief states.
- Training stability and failure modes: report variance across seeds, training loss dynamics, and collapse behaviors when stop-gradients and KL terms are modified; include diagnostics for representation drift and collapse prevention.
- Interplay with attention: investigate whether NextLat encourages reliance on compressed latent summaries over ad-hoc token lookup and how it changes attention patterns, retrieval behavior, and length generalization.
- Domain generality: extend beyond text-like sequences to multi-modal data (vision, audio), event streams, and interactive environments; test whether NextLat remains effective with noisy observations and partial observability.
- Manhattan evaluation breadth: include non-random taxi trajectories, temporal patterns (rush hour), map perturbations, and alternative reconstruction metrics to stress-test world-model quality; quantify statistical significance.
- Inference-time efficiency: measure memory/latency impacts in full-stack systems (kv-cache, long contexts) and whether NextLat alters the trade-off between cache size, latency, and accuracy.
- Interpretability: develop tools to decode semantic content from belief states (e.g., mapping latents to graph nodes, arithmetic subgoals) and assess alignment between learned latent transitions and underlying world structure.
- Alternative objectives: compare NextLat with contrastive/InfoNCE or JEPA-style objectives in the latent space; assess whether predictive vs. contrastive supervision yields better sufficiency, compactness, or robustness.
- Planning and reasoning integration: test combining NextLat with external search/planning (MCTS, A* over latents), self-consistency checks, or tool use; quantify whether belief states reduce myopic errors in complex multi-step tasks.
- Data efficiency: examine sample complexity—does NextLat require fewer tokens to achieve comparable generalization? Provide learning curves and ablations in low-data regimes.
- Safety and calibration: assess whether latent transition regularization affects calibration, uncertainty estimation, or hallucination rates in open-ended generation.
- The “Expressivity of the Recurrence” section is incomplete; clarify the relationship between NextLat and state-space models (e.g., S4/Mamba), and compare expressivity, training dynamics, and compute trade-offs.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging the paper’s Next-Latent Prediction (NextLat) training objective to shape transformer representations toward compact, predictive “belief states.”
- LLM training recipe upgrade for improved generalization and planning (Software/AI)
- What: Integrate NextLat as an auxiliary loss during pretraining or fine-tuning to reduce shortcut learning and strengthen long-horizon reasoning and planning without changing inference.
- Tools/products/workflows: A plug-in loss module for PyTorch/Hugging Face trainers; simple MLP latent-dynamics head p_ψ; training scripts that schedule horizon d and λ coefficients.
- Assumptions/dependencies: Access to hidden states during training; moderate training overhead (typically < 20% at low d); careful tuning to avoid representation collapse (stop-gradient, KL alignment).
- More coherent long-form text generation with unchanged inference (Software, Media)
- What: Pretrain/fine-tune story-writing models (e.g., TinyStories-scale) with NextLat to maintain narrative coherence for 1–20+ token lookahead.
- Tools/products/workflows: “NextLat-pretrained” LLMs for content platforms; probe-based validation suite to confirm longer-horizon predictive capacity.
- Assumptions/dependencies: Quality long-context data; standard tokenization; probes to monitor next-token fidelity.
- Math and logic tutors with fewer “regretful compromise” errors (Education)
- What: Fine-tune tutoring/chat models on math-reasoning datasets (e.g., Countdown-like tasks) using NextLat to improve multi-step calculation validity.
- Tools/products/workflows: NextLat training + “pause tokens” workflow to allocate planning time pre-solution; validity-check instrumentation (LHS=RHS) during eval.
- Assumptions/dependencies: High-quality problem sets; evaluation harness that checks equation correctness; inference remains standard autoregressive decoding.
- Structured planning for workflow automation and process orchestration (Enterprise software)
- What: Train sequence models on operational logs (tickets, customer journeys, workflow traces) to reduce myopic decisions and improve multi-step plan consistency.
- Tools/products/workflows: A “belief-state” planner layer in orchestration engines; path-star–style internal tests to detect shortcut learning.
- Assumptions/dependencies: Tokenization of meaningful actions/states; data pipelines to build sequential corpora; basic map/reconstruction metrics for QA.
- Map reconstruction and route-planning from trajectories (Transportation, Logistics)
- What: Train models on mobility logs (e.g., rideshare, delivery routes) to learn compact, more faithful latent world models; use sequence compression and detour robustness to evaluate consistency.
- Tools/products/workflows: World-model reconstruction toolkit (based on paper metrics); route suggestion systems that verify validity under detours.
- Assumptions/dependencies: Sufficient coverage of trajectories; reliable tokenization of turns/actions; OOD evaluation pairs to test generalization.
- Robust agent planning in tool-use pipelines (Software agents)
- What: Improve lookahead behavior in agents that chain multiple tools/APIs by training with NextLat on tool-call sequences.
- Tools/products/workflows: Agent training datasets (tool calls + results); horizon scheduling (small d for efficiency, larger d for stronger supervision).
- Assumptions/dependencies: Access to tool-call logs; consistency between tokenization and tool semantics; additional training compute proportional to d.
- Better sequence compression for retrieval, deduplication, and indexing (Search/Knowledge management)
- What: Use NextLat-trained hidden states to produce more compact, canonical latent summaries of sequences, reducing redundancy and improving retrieval alignment.
- Tools/products/workflows: Latent clustering for canonicalization; compression-based QA checks (identical continuations from equivalent states).
- Assumptions/dependencies: Reliable mapping from sequences to states; singular value–based effective-rank monitoring; domain-specific thresholds.
- Evaluation suites for “world-model quality” beyond next-token accuracy (Academia, ML Ops)
- What: Adopt sequence compression, effective latent rank, and detour robustness as standard evaluation metrics in pretraining pipelines.
- Tools/products/workflows: Metrics library; CI gates for long-horizon consistency; dashboards that track belief-state proxy metrics over training.
- Assumptions/dependencies: Access to hidden states; reproducible evaluation corpora; SVD compute for effective rank.
- Reliable story generation and planning in consumer apps (Daily life, Media)
- What: Deploy writing assistants that keep plot structures coherent across chapters and avoid short-horizon drift.
- Tools/products/workflows: NextLat-pretrained consumer LLMs; optional “planning mode” UI that allocates computation (pause tokens).
- Assumptions/dependencies: Domain corpora with long-range dependencies; baseline QA harness (e.g., probe-based checks).
- More data-efficient belief-state learning compared to BST/JTP (Academia, Open-source)
- What: Use NextLat as a simpler, faster alternative to BST (no second transformer, no O(T²) gradients) and less restrictive than JTP (no need for d ≥ k observability).
- Tools/products/workflows: Reproducible research baselines; small-code MLP p_ψ modules; benchmark suites (Manhattan, Path-Star, Countdown).
- Assumptions/dependencies: Adequate capacity and optimization to reach consistency; data with sequential structure; community adoption.
Long-Term Applications
The following use cases require further research, scaling, domain adaptation, and/or governance to realize safely and effectively.
- Agentic systems with reliable internal world models (Software, Robotics)
- What: Build tool-augmented, multi-modal agents that maintain and update belief states across long tasks (coding, DevOps, household robotics).
- Tools/products/workflows: Cross-modal NextLat (text + actions + sensor streams); latent-dynamics diagnostics; planning traces with verifiable consistency.
- Assumptions/dependencies: Stable multi-modal tokenization; safety checks for long-horizon failures; integration with SSMs or control loops.
- Clinical decision support with belief-state summaries (Healthcare)
- What: Encode longitudinal patient histories into compact belief states to inform treatment planning and simulation of outcomes.
- Tools/products/workflows: EHR-sequence NextLat pretraining; causal validation; clinician-in-the-loop planning; regulatory-grade evaluation.
- Assumptions/dependencies: Privacy-preserving data access; domain shift robustness; rigorous safety/interpretability; regulatory approval.
- Autonomous driving and mobility world modeling (Transportation, Robotics)
- What: Learn compact latent maps and transition dynamics from driving logs to improve planning and ODD generalization.
- Tools/products/workflows: Sequence modeling of maneuvers; detour and OOD stress tests; fusion with perception stacks; closed-loop planning evaluation.
- Assumptions/dependencies: High-fidelity sensor-to-token mapping; robust sim-to-real transfer; exhaustive safety validation.
- Grid operations and IoT predictive control (Energy)
- What: Use belief-state transformers for long-horizon forecasting and control in power systems, building management, and industrial IoT.
- Tools/products/workflows: Offline logs for NextLat pretraining; coupling to MPC/RL controllers; rolling-horizon evaluation.
- Assumptions/dependencies: Coverage of rare events; safe control interfaces; governance for critical infrastructure.
- Scenario planning and risk reasoning in finance (Finance)
- What: Reduce myopic strategies by enforcing latent transition consistency across multi-step market scenarios (portfolio allocation, stress testing).
- Tools/products/workflows: Historical logs + synthetic scenarios; NextLat-pretrained planning models; audit trails for latent-state transitions.
- Assumptions/dependencies: Regulatory compliance; robust backtesting; guardrails against spurious correlations.
- Policy standards for “planning-capable” AI (Policy/Governance)
- What: Establish certification criteria that go beyond perplexity, incorporating world-model metrics (compression, detour robustness) and belief-state diagnostics.
- Tools/products/workflows: Standardized evaluation suites; procurement checklists; red-team procedures targeting long-horizon consistency.
- Assumptions/dependencies: Multi-stakeholder consensus; transparent reporting; alignment with sector-specific safety norms.
- Interpretable belief-state probes and human-readable state maps (Cross-sector)
- What: Map latent belief states to interpretable abstractions (graphs, timelines, causal schemas) to support audits and debugging.
- Tools/products/workflows: Probe libraries; canonical-state visualization tools; alignment checks between latent dynamics and human concepts.
- Assumptions/dependencies: Domain-specific ontologies; reliable probe design; avoidance of probe overfitting.
- Curriculum schedules for belief-state training at scale (Academia, Foundation model developers)
- What: Develop training curricula that progressively increase horizon d, adjust λ coefficients, and mix token- and latent-space objectives for stable convergence.
- Tools/products/workflows: Auto-curriculum controllers; early-warning monitors for myopic collapse; ablation libraries across domains.
- Assumptions/dependencies: Large-scale compute; robust optimization regimes; reproducibility across datasets.
- Generalized world-model reconstruction platforms (Software, Research infra)
- What: Offer turnkey platforms to reconstruct and validate world models from arbitrary sequential data (mobility, operations, game logs).
- Tools/products/workflows: WorldModel Inspector suite (map reconstruction, compression, effective rank); API to ingest sequences and export validated latent graphs.
- Assumptions/dependencies: Data pipelines; standardized tokenization; diverse benchmarks for OOD and detour robustness.
Notes on feasibility across all applications:
- NextLat improves training-time representation formation; inference remains standard autoregressive decoding. Gains depend on optimization reaching consistency and having sufficient capacity.
- Horizon d introduces additional training cost; select d pragmatically (often small values suffice) and monitor with the paper’s diagnostics.
- Benefits are strongest for data with genuine sequential structure and long-horizon dependencies; tokenization must reflect meaningful states/actions.
- Safety-critical deployments require domain-specific validation, interpretability, and governance beyond the paper’s experimental scope.
Glossary
- Autoregressive language modeling: A modeling approach where the next token is predicted based on previous tokens in sequence. "Yet, learning these latent dynamics for autoregressive language modeling in transformers remains underexplored."
- Backpropagation Through Time (TBPTT): A training technique for recurrent models that backpropagates gradients through temporal steps; truncated TBPTT limits this window to reduce cost. "Conceptually, the one-step and multi-step prediction in NextLat resembles truncated backpropagation through time (TBPTT) in RNNs, with truncation windows of $1$ and , respectively."
- Belief state: A compact representation of past information that is sufficient to predict future observations. "NextLat provably shapes transformer representations into belief states---compact summaries of past information sufficient for predicting future observations"
- Belief State Transformers (BST): A transformer approach designed to learn belief-state representations for planning. "Recently, Belief State Transformers (BST; \citep{hu2025the}) extended the notion of belief states to transformers, and demonstrated benefits in planning tasks."
- Clever Hans cheat: A form of shortcut solution that exploits spurious patterns rather than true reasoning. "This phenomenon, termed the Clever Hans cheat \citep{bachmann24a}, is related to the difficulty of learning parity"
- Cross-entropy loss: A standard loss function for probabilistic classification, measuring the difference between predicted and true distributions. "As usual, we optimize the transformer and output head for next-token prediction (...) using the cross-entropy loss:"
- Curse of dimensionality: The exponential growth in complexity as the dimensionality of data increases, making learning from long histories difficult. "To mitigate this curse of dimensionality, recent work focused on compressing history into latent representations capturing all information necessary for future prediction."
- Dirac distribution: A degenerate probability distribution that concentrates all mass at a single point. "For a deterministic transformer model, is a Dirac distribution, and we can optimize via regression"
- Effective Latent Rank: A measure of the intrinsic dimensionality of learned representations, computed via entropy of singular values. "Effective Latent Rank: Effective rank/dimension of hidden states measured as the exponentiated Shannon entropy of the normalized singular values"
- Hidden state: The internal vector representation produced by a model at each time step. "a transformer with parameters that produces hidden states at each time step "
- Knowledge distillation: A technique where a model learns from the soft targets of another model to transfer knowledge. "This KL acts similarly to knowledge distillation~\citep{hinton2015distilling}"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from another reference distribution. "We introduce a complementary KL objective enforcing agreement in token prediction space:"
- Latent dynamics model: A model that predicts the evolution of latent (hidden) states over time given current state and input. "introducing a latent dynamics model that predicts the next hidden state directly from ."
- Linear probe: A simple linear classifier trained on frozen model representations to evaluate the information they contain. "we train linear probes on the hidden representations of the frozen transformers to predict future tokens."
- Lookahead planning: The ability to anticipate future consequences over multiple steps when choosing actions or outputs. "This task represents a minimal instance of lookahead planning"
- Markov kernel: The transition rule (conditional distribution) governing the next state or observation given the current one. "can delay or even prevent learning of the true Markov kernel"
- Multi-Token Prediction (MTP): A training objective that predicts multiple future tokens at once rather than just the next token. "For completeness, we also report the performances of standard next-token prediction (GPT) and multi-token prediction (MTP)."
- Next-Latent Prediction (NextLat): The proposed method that augments next-token training by predicting the model’s next latent state. "We introduce Next-Latent Prediction (NextLat), which extends standard next-token training with self-supervised predictions in the latent space."
- Next-token prediction: The standard autoregressive objective of predicting only the immediate next token in a sequence. "Beyond Next-Token Prediction."
- N-gram modeling: Modeling that relies on fixed-size token windows to estimate next-token probabilities. "early training can often resemble -gram modeling, which can delay or even prevent learning of the true Markov kernel"
- Observability horizon: The minimum number of observations needed to infer the underlying state of a process. "prediction horizon satisfies , where denotes the observability horizon of the underlying data-generating process"
- Perplexity: A standard metric for LLM quality, reflecting predictive uncertainty over tokens. "lower perplexity correlates strongly with improved downstream performance"
- Recurrent inductive bias: A structural training preference that encourages models to behave like recurrent systems that summarize history compactly. "This simple auxiliary objective also injects a recurrent inductive bias into transformers"
- Self-attention: A mechanism that allows a model to weigh and integrate information from different positions within its input sequence. "self-attention that enables ad-hoc look ups over past tokens"
- Self-predictive learning: A paradigm where models learn representations by predicting their own future latent states. "The approach is inspired by the self-predictive learning paradigm in reinforcement learning (RL)"
- Self-supervised learning (SSL): Learning from unlabeled data by creating supervision signals from the data itself. "Self-supervised learning (SSL; \citet{SSLdeSa1993, balestriero2023cookbookselfsupervisedlearning}) is a framework for learning from unlabeled data, where a model generates its own supervisory signals from the structure of raw inputs."
- Shannon entropy: A measure of uncertainty or information content in a probability distribution. "exponentiated Shannon entropy of the normalized singular values"
- Smooth L1 loss: A regression loss function less sensitive to outliers than L2, combining L1 and L2 behavior. "We supervise all intermediate rollouts using the smooth L1 loss"
- State-space models (SSMs): Sequence models that use efficient recurrent state updates to capture long-range dependencies. "Modern state-space models (SSMs), such as S4 and Mamba, implement efficient linear recurrent updates in their hidden states"
- Stop-gradient operator: An operation that prevents gradients from flowing through a tensor during backpropagation. "where denotes the stop-gradient operator, used to prevent representational collapse in self-predictive learning"
- Sufficient statistic: A compressed representation of data that retains all information needed for a particular inference task. "Equivalently, is a sufficient statistic~\citep{striebel1965sufficient} of the history for predicting the future tokens"
- Teacher forcing: A training technique where ground-truth future tokens are fed to the model during training rollouts. "using teacher-forced tokens "
- Variational inference: A method for approximating complex probability distributions through optimization over a tractable family. "If considering a stochastic transformer model, can be optimized through variational inference."
- World model: An internal predictive model of environment dynamics that supports planning and generalization. "NextLat effectively encourages the transformer to form compact internal world models with its own belief states and transition dynamics"
Collections
Sign up for free to add this paper to one or more collections.