- The paper establishes a theoretical framework for dual-space encoding that separates context and sample representations to reconcile in-context and in-weight learning.
- It employs the CoQE architecture, validated on synthetic classification, regression, and generative tasks, demonstrating superior performance over standard Transformers.
- Empirical analyses using metrics like the context and sample silhouette coefficients confirm that disentangled dual spaces yield robust task generalization and improved out-of-distribution accuracy.
Reconciling In-Context and In-Weight Learning via Dual Representation Space Encoding
Introduction and Problem Statement
The study addresses a foundational question in the development and understanding of Transformer-based models: the apparent and pervasive conflict between in-context learning (ICL)—the ability to learn dynamically from prompts at inference time—and in-weight learning (IWL)—the model’s recall of knowledge embedded during training. Prior research has observed that optimizing for one of these capabilities often comes at the expense of the other, with the balance being highly sensitive to architectural and data distribution factors [chan2022data, singh2023transient, chantoward]. This work seeks both a theoretical explanation and a practical solution for the ICL-IWL tradeoff.
Empirical Analysis of Representation Spaces
The investigation begins with extensive controlled experiments on synthetic few-shot classification tasks derived from Omniglot, designed to dissociate ICL from IWL behavior. Models are trained under varied data distributions (e.g., Zipfian exponents, degree of burstiness), embedding dimensions, and Transformer depths. The central empirical finding is that standard Transformers encode both task/contextual and sample-specific information into a single representation space, with superior clustering for samples (favoring IWL) impairing contextual clustering (impairing ICL), and vice versa.
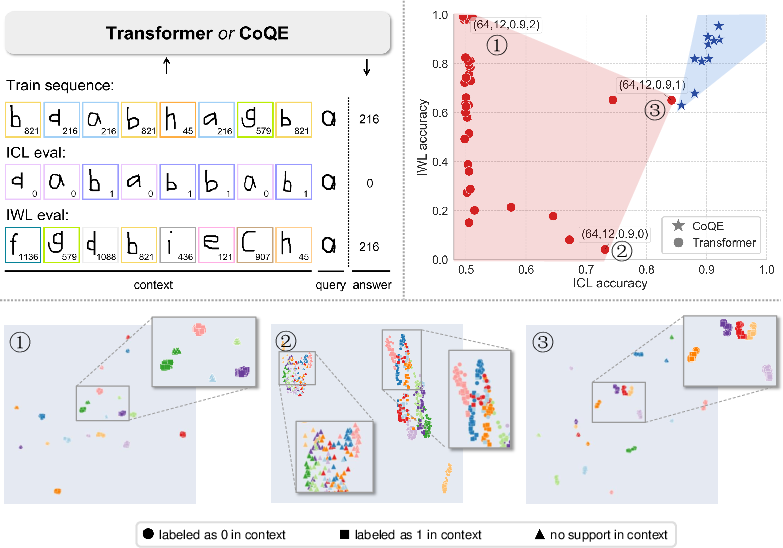
Figure 1: Synthetic task design and empirical demonstration of the ICL/IWL tradeoff in standard Transformers, visualized across training settings and representation clusters.
Using the context silhouette coefficient (CSC) and sample silhouette coefficient (SSC) to quantify cluster purity, the study establishes a strong positive correlation between ICL performance and CSC, and between IWL performance and SSC. These findings support the thesis that learning both forms of information in a shared space introduces intrinsic interference.
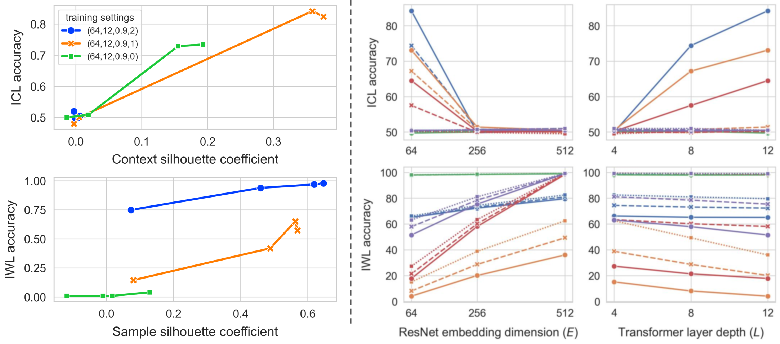
Figure 2: Empirical correlation between ICL and context clustering as well as IWL and sample clustering, across settings and model checkpoints. Variations in embedding and layer dimensions show differential impacts on the ICL/IWL balance.
Theoretical Framework: Dual-Space Modeling
To resolve the entanglement, the authors propose a dual-space encoding—formally modeling context-induced task representations and sample representations as dual vector spaces. Drawing on the linear representation hypothesis [mikolov2013linguistic, nanda2023emergent, park2023linearhypothesis], the context encoding space (task representation) is constructed as the dual of the sample representation space, establishing an explicit mathematical structure for their interaction via the Riesz representation theorem.
Theoretical results demonstrate that under this framework, in the presence of a sufficiently rich curriculum traversing task space, the model's learned sample representations span the space necessary for universal task generalization via ICL. Notably, the analysis proves that standard softmax-based attention (dominant in Transformers) fundamentally cannot yield such a bilinear, disentangled decomposition, explaining the persistent competition observed empirically.
CoQE Architecture: Design and Implementation
To instantiate dual-space modeling, the authors introduce CoQE (Context-Query Encoder architecture), which separates the processing of context and query inputs with dedicated encoders: a context encoder generates task representations from context, and a sample encoder generates representations for queries and individual samples. The model output is computed as the inner product of context- and sample-derived vectors, satisfying the dual-space theoretical criterion.
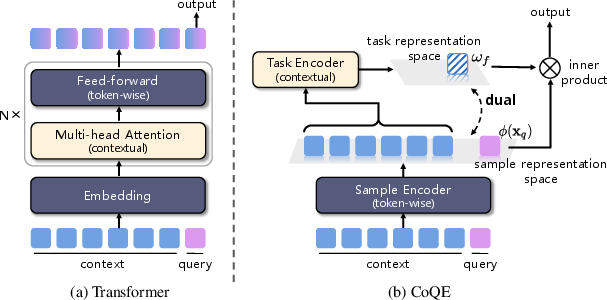
Figure 3: Architectural comparison—standard Transformer entangles context and samples in a single space; CoQE deploys dual pathways, explicitly separating and later integrating context-level and sample-level information.
Experimental Validation
Regression ICL Setting
On regression tasks spanning linear, sparse linear, two-layer ReLU, and composite functions, CoQE demonstrates strictly lower ICL error than comparable Transformers under both in-distribution and multiple forms of out-of-distribution perturbations. Particularly for tasks reliant on shared underlying representations (e.g., composite and nonlinear functions), CoQE's basis-structured sample space, predicted by the dual-space theory, provides a marked advantage.
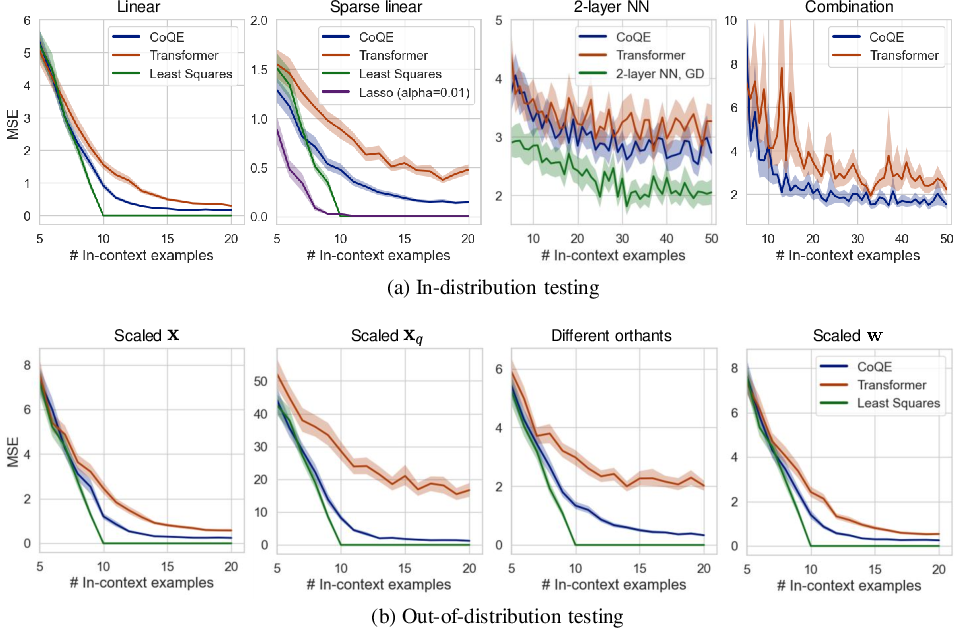
Figure 4: ICL regression test errors—CoQE dominates the Transformer baseline across all scenarios, especially for tasks necessitating generalization beyond in-weight memorization.
Few-shot Classification
In synthetic few-shot classification, CoQE robustly attains high accuracy in both ICL and IWL evaluations, while baseline Transformers and regularization or forgetting-based baselines remain confined to distinct performance regimes.
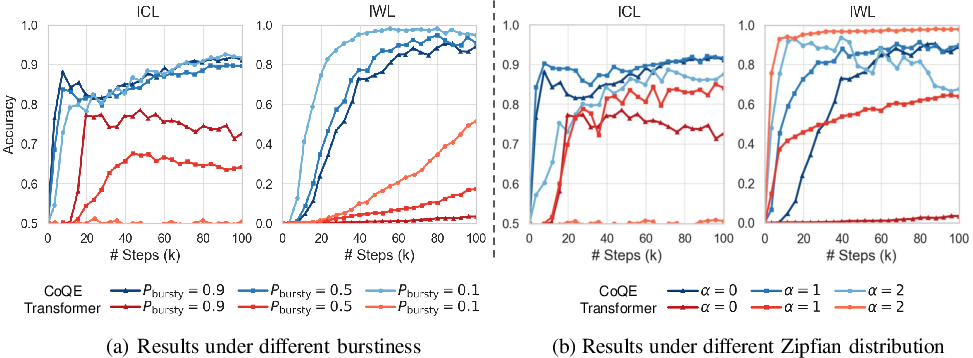
Figure 5: Training curves on synthetic few-shot classification—CoQE rapidly acquires and then stabilizes strong ICL capabilities alongside persistent IWL. Standard Transformer ICL capability quickly collapses as training proceeds.
Further experiments using Llama token embeddings confirm the generality of these findings, with CoQE displaying notable ICL improvements in semantic vector spaces where standard Transformers barely exceed random guessing in the ICL regime.
Conditional Pseudo-Arithmetic Task
The approach generalizes to generative tasks: fine-tuning a GPT-2 model with CoQE modifications on a pseudo-arithmetic task demonstrates compelling gains—retaining IWL for trained tasks while strongly improving OOD ICL accuracy, where traditional methods fail to leverage context.
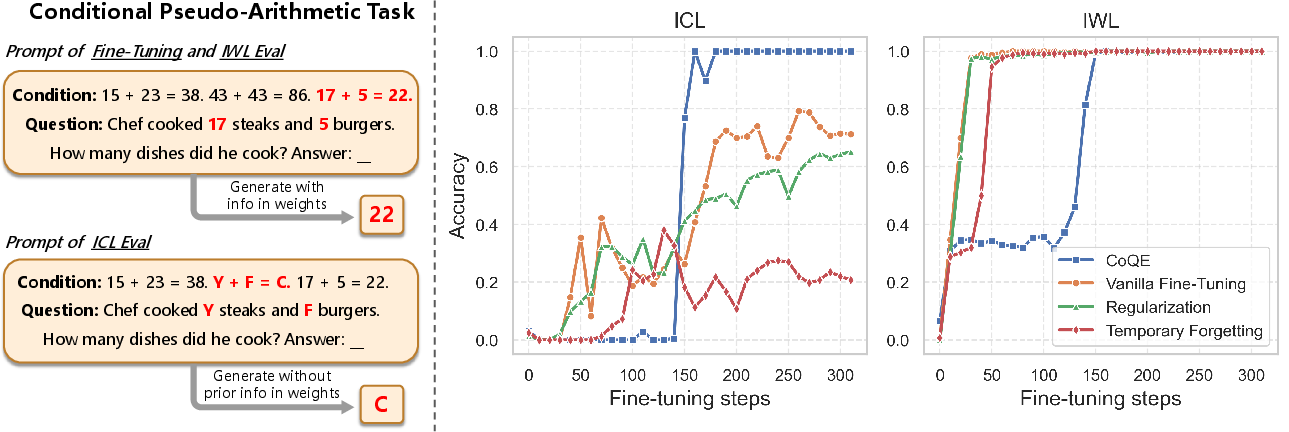
Figure 6: CoQE's learning trajectory on a conditional arithmetic task: after fine-tuning, it uniquely reconciles near-perfect IWL with substantially higher ICL than competing approaches.
Ablation and Representation Analysis
Ablations on noise regularization, parameter scaling, and training curriculum confirm that CoQE's robust ICL/IWL coexistence is sensitive to representation noise and architectural balance, but consistently superior to standard approaches under equivalent resource budgets.
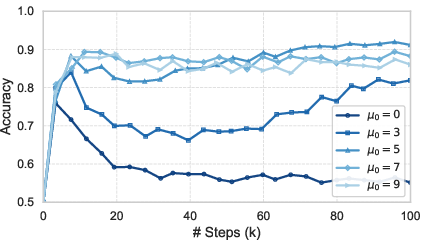
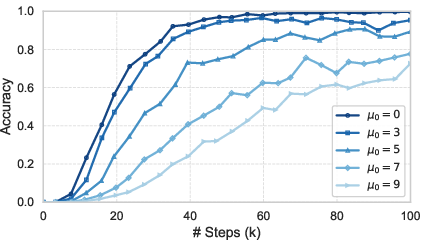
Figure 7: Effect of representation noise regularization on ICL/IWL convergence—noise is necessary to prevent the collapse of context-sensitive encodings.
Analysis of the CoQE-learned sample representation space for composite functions verifies a near-basis alignment with the ground-truth transformation structure, consistent with the dual-space completeness theorem.
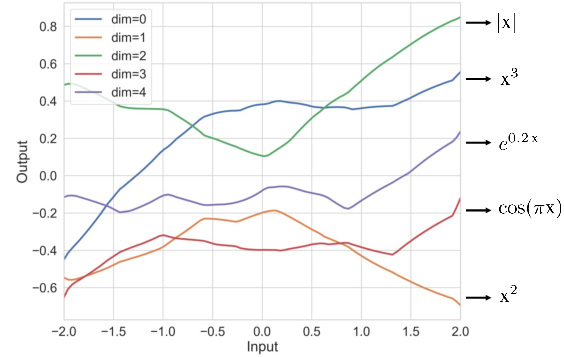
Figure 8: Direct projection of learned sample representation space on composite functions—dimensions distinctly map onto interpretable task-relevant transformations.
Implications and Future Work
This work establishes both a formal theory and practical method for overcoming the historical competition between in-context and in-weight learning in sequence models. The results suggest that the shared-encoding architecture is a fundamental limitation in Transformers for robust generalization and adaptability. The dual-space approach enables a model to simultaneously encode stable long-term knowledge and flexibly instantiate new task computations from prompt context, circumventing reliance on statistical properties of training data that were previously necessary for balancing ICL/IWL.
While empirical results are primarily on synthetic and small-scale tasks, the theoretical framework is amenable to scaling and naturalistic data. Limiting assumptions—such as the linearity at the core of the representational analysis and the restriction to single-token answers in theory—outline clear directions for extension to deeper, nonlinear architectures and generative LLMs.
Conclusion
Reconciling ICL and IWL in neural sequence models demands architectural and representational rethinking. Through dual representation space encoding, this work provides the first principled solution—both theoretically rigorous and empirically validated—to the coexistence problem. The findings have far-reaching implications for model generalization, robustness under domain shifts, and architectural design in both current Transformers and emerging multimodal and task-adaptive AI systems.