NVIDIA Nemotron Parse 1.1
Abstract: We introduce Nemotron-Parse-1.1, a lightweight document parsing and OCR model that advances the capabilities of its predecessor, Nemoretriever-Parse-1.0. Nemotron-Parse-1.1 delivers improved capabilities across general OCR, markdown formatting, structured table parsing, and text extraction from pictures, charts, and diagrams. It also supports a longer output sequence length for visually dense documents. As with its predecessor, it extracts bounding boxes of text segments, as well as corresponding semantic classes. Nemotron-Parse-1.1 follows an encoder-decoder architecture with 885M parameters, including a compact 256M-parameter language decoder. It achieves competitive accuracy on public benchmarks making it a strong lightweight OCR solution. We release the model weights publicly on Huggingface, as well as an optimized NIM container, along with a subset of the training data as part of the broader Nemotron-VLM-v2 dataset. Additionally, we release Nemotron-Parse-1.1-TC which operates on a reduced vision token length, offering a 20% speed improvement with minimal quality degradation.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces NVIDIA Nemotron-Parse 1.1, a smart tool that “reads” images of documents and turns them into clean, structured text. Think of it like a super-powered scanner: it doesn’t just copy words, it understands where things are on the page (like titles, captions, tables) and keeps the reading order, so the output looks like a well-formatted document. It can also handle math, tables, multi-column pages, and even text inside pictures or diagrams.
What questions does the paper try to answer?
The team set out to solve a few simple but important problems:
- How can we turn complex document images into clean text with correct layout and formatting?
- Can we keep the reading order (the way a person would read the page), not just dump all text?
- Can we label different parts of the page (like “Title,” “Table,” “Caption”) and give box coordinates for each?
- Can we do all of this quickly, on many pages, without a big bulky model?
- Can we support multiple languages and long, dense documents?
How it works (methods explained simply)
Nemotron-Parse is a “vision-language” model, which means it looks at an image (vision) and writes out text (language).
- Encoder-decoder: Imagine a two-step process.
- The encoder is like your eyes: it looks at the page image and turns it into a compact set of features (a “summary” of what’s seen).
- The decoder is like your brain and hands: it takes those features and writes the text in the right format and order.
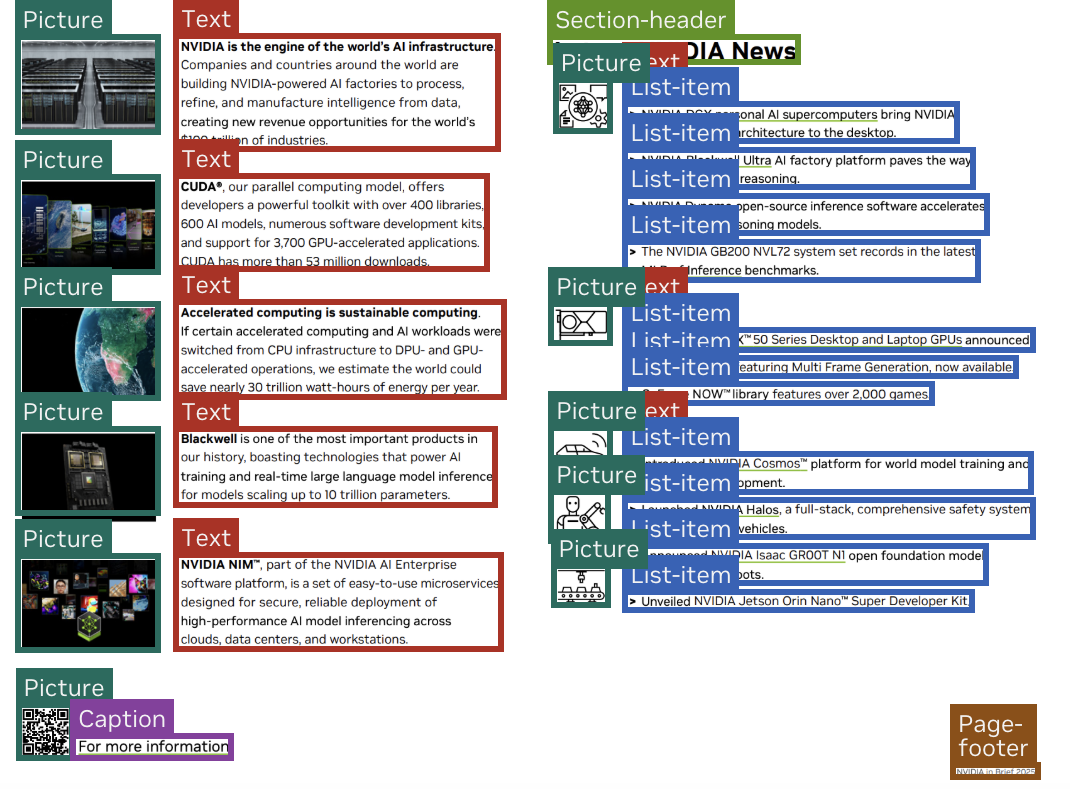
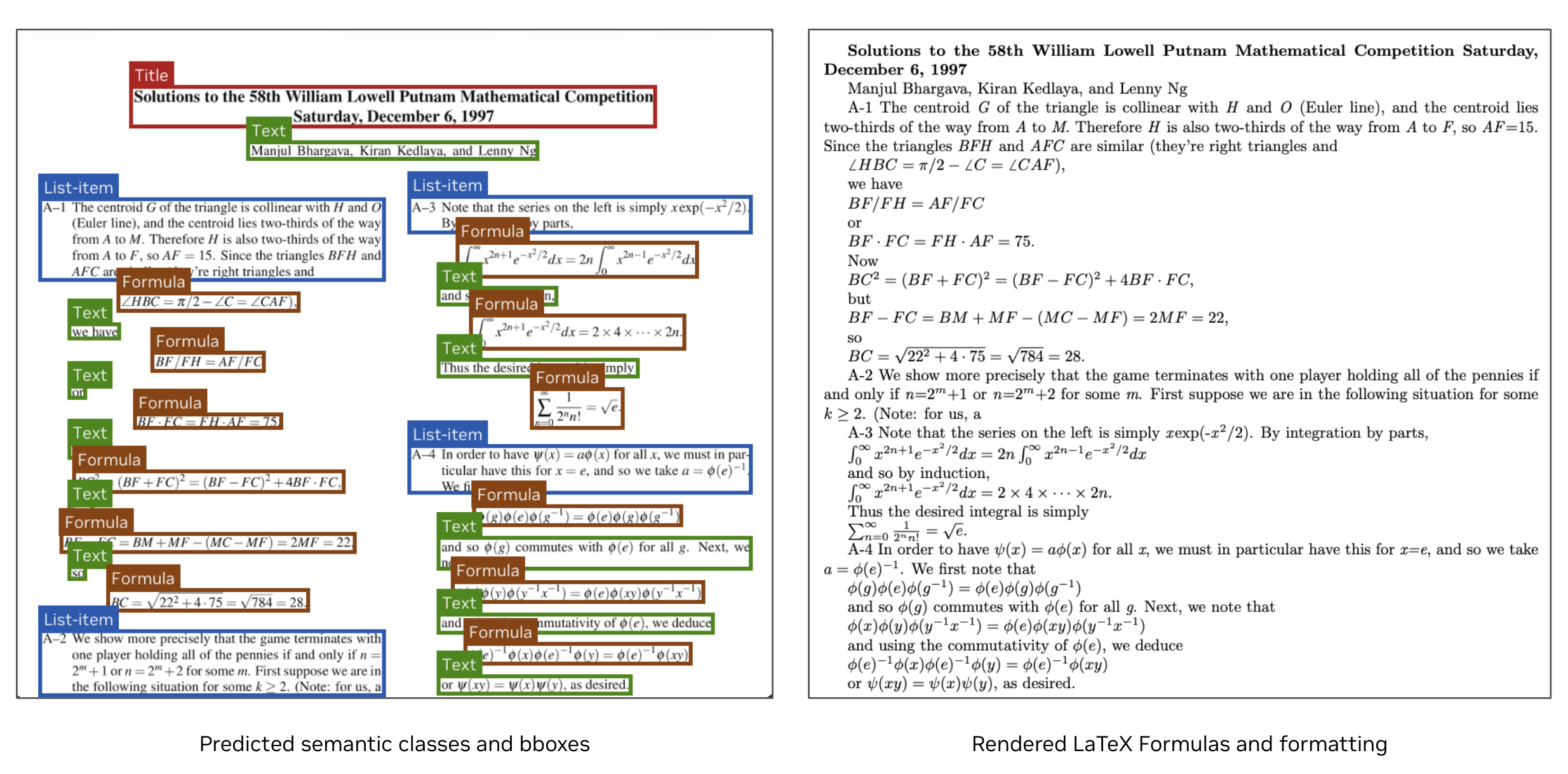
- Bounding boxes: The model draws rectangles around different parts of the page and labels them (e.g., Title, Text, Table, Caption). This tells you exactly where each piece of text came from.
- Formatting: The output can be plain text or formatted text, mainly using Markdown and LaTeX. Markdown helps with headings, lists, and simple styling. LaTeX helps with math and complex tables.
- Reading order: The model arranges the extracted text in the way you’d naturally read the page—headers first, main text next, tables and footnotes in a sensible order. The “TC” version improves this even more by making floating elements appear where they belong in the page flow.
- No positional embeddings in the decoder: Normally, models use special “position signals” to keep track of token order. Here, the decoder relies on its attention mask (which only looks backward) and the visual layout from the image. This keeps the system simpler and lets it handle longer outputs.
- Multi-token inference: Instead of writing one token (tiny piece of text) at a time, the model can predict several at once—like typing multiple letters in a single keystroke. This speeds things up and can also improve accuracy.
- Token compression (TC): The TC version shortens the “vision token” sequence (fewer visual chunks to process) using techniques like pixel-shuffle. It’s faster—about 20% quicker—with only minor quality loss.
Training and data:
- The team built a large, high-quality training set using an advanced pipeline (NVpdftex) that connects directly to LaTeX rendering to capture precise text positions, classes, and reading order.
- They blended synthetic data, public datasets (like DocLayNet, PubTables-1M, FinTabNet), human-labeled pages, and multilingual sources (including Wikipedia), with extra tricks like font/color changes and machine translation to diversify examples.
What did they find?
Nemotron-Parse 1.1 and its faster “TC” variant show strong performance across several tests:
- General OCR quality: Low word error rates (WER) and high F1 scores on internal and public benchmarks.
- Reading order: Very good at ordering text as humans would read, and the TC version improves how floating elements are placed.
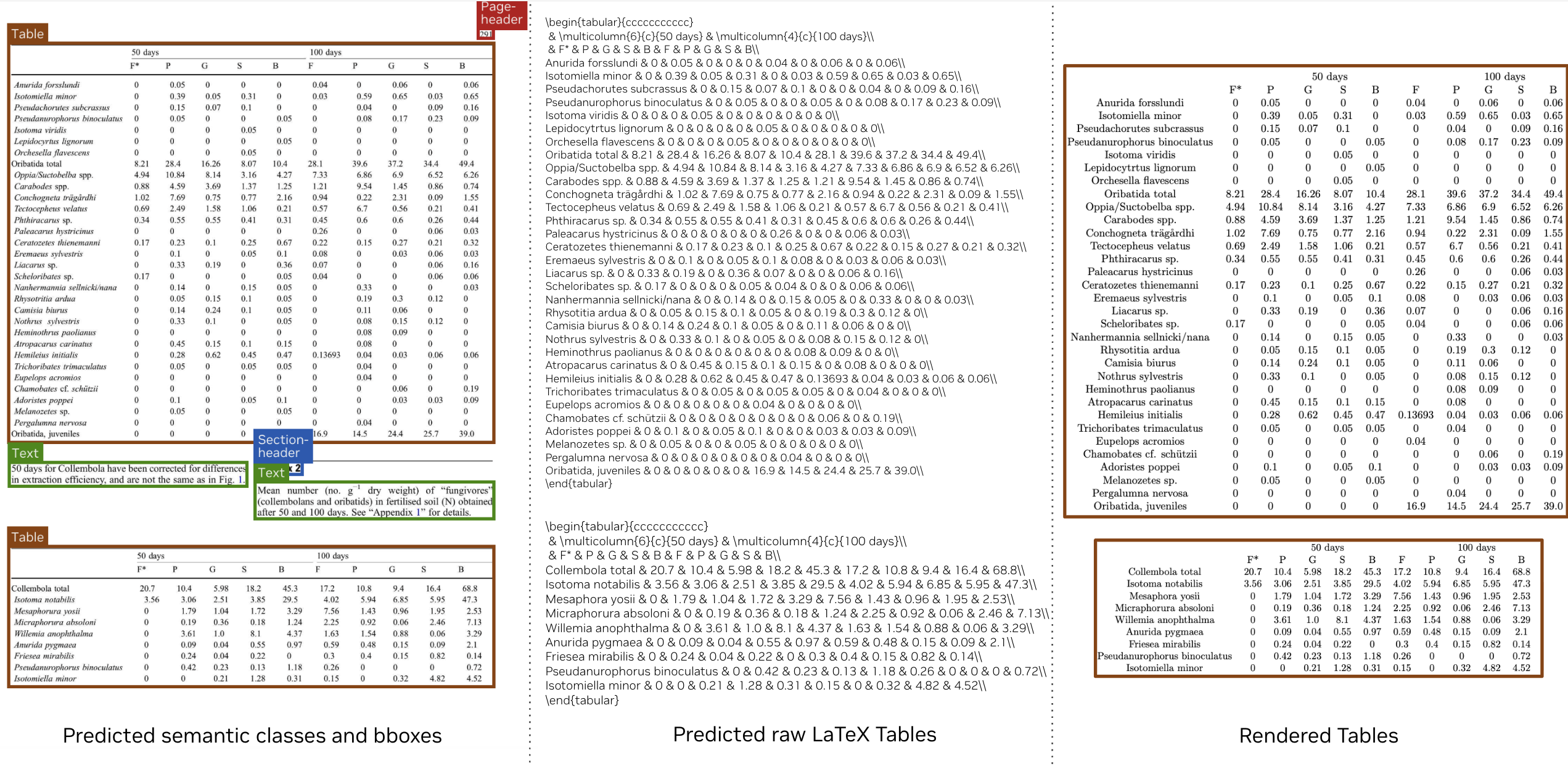
- Tables: Competitive or better results on table benchmarks (TEDS/S-TEDS and RD-TableBench), comparable to larger or commercial systems.
- Multilingual: High accuracy for English and several European languages, plus solid results for Chinese and Japanese in scientific-style documents.
- Speed: On a single NVIDIA H100 GPU, Nemotron-Parse-TC can process roughly 5 average pages per second; the standard model does about 4 pages per second.
In some comparisons, Nemotron-Parse is beaten by large commercial models (e.g., Gemini Flash 2.0), but it’s still a strong, lightweight open solution.
Why this matters
- Better document understanding: It turns messy or complex PDFs into neat, usable text with layout and labels, which helps search, study, and automation.
- Useful for AI systems: LLMs and document tools can consume Nemotron-Parse outputs to answer questions, extract data, and build knowledge bases.
- Efficient and fast: The TC version is ideal for batch processing, edge devices, or interactive apps where speed matters.
- Open access: The model weights and some training data are released, making it easier for researchers and developers to build on top of this work.
In short
Nemotron-Parse 1.1 is like a careful reader and organizer for documents. It doesn’t just read words—it understands the page structure, keeps the reading order, labels parts of the page, and formats the output nicely. It does this quickly and across multiple languages. This makes it a practical tool for turning scanned documents and PDFs into clean, searchable, and structured data that people and AI systems can use.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Lack of formal evaluation for bounding box detection and classification: no IoU/precision–recall metrics or per-class confusion matrices are reported for box accuracy and semantic class prediction.
- Reading-order evaluation excludes key elements (tables, equations, TeX commands) and floating components; standardized metrics covering all element types, floating elements, and multi-column/multi-page layouts are not provided.
- The TC variant is claimed to “improve reading order,” but there is no analysis explaining why compression improves ordering nor quantitative ablations comparing ordering fidelity across variants and document types.
- Formula representation mismatch (Markdown vs LaTeX) is acknowledged, yet there is no dual-output evaluation protocol (e.g., LaTeX-only math mode) nor metrics for LaTeX syntactic validity or compile success rate of predicted formulas.
- Absence of extreme-length tests: no experiments characterizing decoder length generalization without positional embeddings (e.g., accuracy vs output length curves, max supported sequence length, failure modes at very long contexts).
- Multi-token prediction is described but not rigorously evaluated: no ablations on the number of simultaneously predicted tokens, accuracy–latency trade-offs, error propagation/cascade analysis, or token verification/refinement strategies.
- Pixel-shuffle token compression design lacks robustness analysis: no results on sensitivity to input resolution/DPI, document types (e.g., scans vs born-digital), compression ratios beyond ×16, or degradation in fine-grained layout tasks.
- Missing evaluation on noisy, low-quality, or adversarial inputs: no robustness studies for skew, blur, compression artifacts, handwriting, stamps, watermarks, overlays, hidden PDF text layers, or page rotations.
- Limited multilingual coverage and domain generalization: evaluations focus on dense scientific documents; no rigorous tests for in-the-wild CJK documents, RTL scripts (Arabic/Hebrew), Indic scripts (Devanagari, Tamil, etc.), vertical writing, or mixed-script pages.
- No benchmark results for text extraction inside pictures, charts, and diagrams despite claims; tasks like ChartOCR/ChartQA, figure-text OCR, diagram structure extraction, and caption–figure association remain untested.
- Multi-page continuity is unaddressed: how reading order, references, captions, and tables that span pages are handled, and whether the model preserves document-level coherence across page boundaries.
- Missing metrics for end-to-end structured conversion fidelity beyond tables: no tree-edit or structural similarity metrics for general Markdown/LaTeX output (e.g., headings hierarchy, lists, footnotes, cross-references).
- Box coordinate system and alignment: boxes are predicted in a 1024×1280 normalized scale, but procedures/accuracy for mapping back to original PDF coordinates/DPI and preserving physical dimensions are unspecified.
- Lack of granular error analysis: no breakdown of common failure modes (e.g., nested/overlapping elements, sidebars/marginalia, complex tables with row/col spans, rotated text, multi-column footnotes).
- Prompt interface is limited to fixed control tokens; there is no evaluation of natural-language instruction following, prompt conflicts, or partial-output requests (e.g., “extract only tables and formulas with boxes”).
- Autolabeling pipeline (stage-1 self-training) is insufficiently documented: label noise rates, filtering thresholds, and the impact of imperfect labels on downstream accuracy/generalization are not quantified.
- Training mixture composition is opaque: dataset sampling ratios, curriculum strategies, loss weighting across tasks (text/boxes/classes), and their influence on trade-offs (e.g., OCR vs layout) are not reported.
- No assessment of syntactic correctness and recoverability: proportion of outputs that are valid Markdown/LaTeX, compile/run rates for LaTeX tables/formulas, and parsing robustness for downstream consumers (renderers/parsers).
- Chart/diagram data extraction beyond text is unaddressed: methods and metrics for extracting structured numeric data, legends, axes, and relationships in plots are not presented.
- Semantic class taxonomy coverage may be limited (e.g., references, code blocks, forms, signatures, annotations); class set completeness and performance on rarer classes are not evaluated.
- Fairness and reproducibility of benchmarks: masking headers/footers for certain baselines but not others, reliance on internal test sets, and partial public data release hinder apples-to-apples comparisons and full reproducibility.
- Resource and deployment constraints are not characterized: memory footprint, latency, throughput on commodity GPUs/CPUs, quantization options, and energy/performance trade-offs for edge/mobile deployments are missing.
- Hybrid extraction strategies (vision + PDF text layer) are unexplored: potential gains from combining rendered-image OCR with PDF-native text/metadata for accuracy and speed are not assessed.
- Downstream utility is not validated: impact on retrieval, RAG, QA, and content indexing pipelines, including error tolerance and post-processing costs, is not measured.
- Security and safety considerations are absent: handling of personally identifiable information, license compliance for training data, and vulnerability to prompt or document injection attacks are not discussed.
- Coordinate and layout normalization across diverse page sizes/orientations is unclear: procedures for consistent handling of landscape pages, non-standard aspect ratios, and multi-column layout normalization are not detailed.
- No comparison across different vision encoders or decoder architectures: sensitivity to encoder choice (e.g., RADIO vs alternatives), decoder depth, tied weights, and NoPE vs PE is not ablated.
- Lack of evaluation on forms and interactive documents: detection and extraction of fields, checkboxes, and form semantics (key–value pairs) are not benchmarked despite mention of checkboxes in synthetic tables.
- Conversion pathways introduce potential bias: converting predicted LaTeX tables to HTML/Markdown may alter fidelity; canonicalization methods and their effects on TEDS/S-TEDS scores are not analyzed.
- Release scope is partial: only a subset of training data is public; exact data compositions and full recipes to reproduce reported metrics are missing, limiting independent verification.
Practical Applications
Practical Applications of Nemotron-Parse 1.1
Below are actionable applications derived from the paper’s methods and findings. Each bullet specifies the use case, sectors, potential tools/products/workflows, and assumptions or dependencies. The items are grouped into Immediate Applications (deployable now) and Long-Term Applications (requiring further research, scaling, or development).
Immediate Applications
- Layout-aware document ingestion and conversion to structured text
- Sectors: software, enterprise IT, publishing, academia
- What it does: Convert PDFs and scanned documents into Markdown/LaTeX with preserved reading order, bounding boxes, and semantic block classes (Title, Section-Header, Table, Formula, Caption, etc.).
- Tools/workflows: Hugging Face
nvidia/NVIDIA-Nemotron-Parse-v1.1, NIM container (build.nvidia.com/nvidia/nemotron-parse), VLLM deployment; use the maximal information prompt<output_markdown><predict_bbox><predict_classes>. - Assumptions/dependencies: Page images at adequate resolution; mapping relative coordinates (1024×1280 scale) back to original page size; GPU recommended for throughput (H100 numbers quoted); output for formulas may mix Markdown and LaTeX.
- High-throughput batch OCR for archives and backfile conversion
- Sectors: government archives, publishing, records management
- What it does: Large-scale conversion of books, periodicals, and scanned records with consistent reading order and semantic labeling.
- Tools/workflows: Nemotron-Parse-1.1-TC (token-compressed variant) for ~20% speed improvement and improved page-order handling; multi-token inference for faster decoding.
- Assumptions/dependencies: Throughput measured on H100; CPU inference feasible but slower; robust performance demonstrated on OmniDocBench and GOT, but quality can vary with poor scan quality.
- Table extraction to LaTeX/HTML/Markdown for analytics
- Sectors: finance, operations, procurement, research
- What it does: Extract complex tables with high TEDS/S-TEDS scores; convert tables to LaTeX and then downstream to HTML/CSV for analytics.
- Tools/workflows: Post-processing pipelines to convert LaTeX tables to CSV; integration with ETL and BI tools (e.g., dbt, Snowflake, BigQuery).
- Assumptions/dependencies: LaTeX-to-HTML/CSV conversion steps; handling of merged cells and checkboxes may require normalization rules; accuracy acceptable across PubTabNet, RD-TableBench, OmniDocBench.
- RAG-ready document chunking with layout and semantics
- Sectors: software, enterprise search, knowledge management
- What it does: Produce layout-aware chunks (boxes) with classes to improve retrieval and grounding for LLMs in Q&A systems.
- Tools/workflows: Indexing workflows in Elastic/OpenSearch; LangChain/LlamaIndex chunkers that use bounding boxes and semantic labels; storage of box coordinates for provenance.
- Assumptions/dependencies: Downstream retrieval stack must accept structured chunks; consistent coordinate mapping; improved quality when the TC variant’s ordering is used.
- Accessibility remediation and reading-order correction
- Sectors: public sector, education, publishing
- What it does: Fix reading order and structure for screen readers and accessibility tooling; recover captions and footnotes; reflow multi-column content.
- Tools/workflows: Generate accessible Markdown/HTML; pair with PDF/UA remediation tools; export semantic classes to accessibility tags.
- Assumptions/dependencies: Additional tooling needed for alt-text-generation of non-textual images; PDF/UA compliance requires extra metadata and checks beyond OCR.
- Scientific content conversion for publishers and researchers
- Sectors: academia, publishing, education
- What it does: Convert papers and textbooks into structured formats with formulas and tables preserved; prepare course materials and lecture notes for web publishing.
- Tools/workflows: Markdown/LaTeX outputs; NVpdftex pipeline to generate high-quality supervised data; post-processing to journal-specific formats.
- Assumptions/dependencies: Some inline formulas output in Markdown (not LaTeX math mode); domain-specific style guides may need additional formatting rules.
- Multilingual OCR for European languages and scientific CJK content
- Sectors: global enterprises, academia, localization
- What it does: Competitive OCR in English, German, French, Italian, Spanish; strong scientific-domain performance for Chinese and Japanese; useful for cross-language ingestion.
- Tools/workflows: Pair Nemotron-Parse outputs with machine translation for end-to-end localization; script-level normalizers for multilingual fonts.
- Assumptions/dependencies: Limited support for in-the-wild CJK documents; best results in scientific/standard PDFs; font and color augmentations help but field variability still matters.
- Legal eDiscovery and contract analytics
- Sectors: legal, compliance, corporate governance
- What it does: Normalize multi-column contracts and discovery documents; preserve headers/footers and canonical reading order; extract tables for clause comparisons.
- Tools/workflows: Document ETL pipelines that produce structured Markdown and metadata; downstream contract analysis tools.
- Assumptions/dependencies: Clause/semantic extraction requires additional NLP; OCR is input normalization; sensitive data implies on-prem deployment with NIM container.
- AP automation and invoice/receipt processing
- Sectors: finance, retail, operations
- What it does: Extract line items and totals from invoices/receipts; retain layout and bounding boxes for auditability; produce CSV for ERP systems.
- Tools/workflows: Nemotron-Parse-1.1-TC for edge or batch ingestion; post-process tables to standardized schemas; integrate with SAP/Oracle ERPs.
- Assumptions/dependencies: Template diversity may require additional rule learning; handwriting and low-quality scans reduce accuracy; CJK in-the-wild may need further fine-tuning.
- Edge scanning and kiosk deployments
- Sectors: logistics, healthcare intake, branch banking
- What it does: Low-latency OCR on scanning devices or kiosks; faster response using token compression while preserving layout semantics.
- Tools/workflows: NIM container on edge GPU; prompt selection for text-only vs maximal outputs; on-device post-processing (CSV/JSON).
- Assumptions/dependencies: GPU-equipped edge hardware or high-performance CPU; secure deployment and local storage constraints.
Long-Term Applications
- Chart and diagram data extraction beyond text
- Sectors: finance, energy, manufacturing, research
- What it could do: Extract not just text from figures, but structured chart series, axes, annotations, and diagram relationships for analytics and simulation inputs.
- Tools/workflows: Integrate with chart-understanding modules; build pipelines to produce JSON specs (e.g., Vega-Lite) from figures.
- Assumptions/dependencies: Requires additional training/data and specialized parsers; current model focuses on text; figure-to-data is an active research area.
- Handwriting, forms, and in-the-wild CJK generalization
- Sectors: public services, healthcare, logistics, retail
- What it could do: Robustly process handwritten forms, receipts, and diverse field documents across languages.
- Tools/workflows: Fine-tuning with new datasets; layout-aware form field detection and value extraction; pairing with key-value parsers.
- Assumptions/dependencies: New annotated datasets and domain adaptation; potential model distillation for edge reliability.
- Full PDF/UA compliance automation
- Sectors: publishing, government, education
- What it could do: End-to-end automated remediation of PDFs for accessibility, including alt-text generation for images and tagged structure.
- Tools/workflows: Combine Nemotron-Parse with VLMs for image description; validators for PDF/UA; automated captioning and figure labeling.
- Assumptions/dependencies: Additional modules for semantic role inference and image description; policy and quality assurance requirements.
- Document QA agents with layout-grounded reasoning
- Sectors: software, customer support, legal, finance
- What it could do: Agents answer questions using layout-aware chunks, cite bounding boxes, and navigate multi-page structures reliably.
- Tools/workflows: RAG stacks with bounding box provenance; UI components that highlight cited regions; memory management exploiting long-context NoPE decoder.
- Assumptions/dependencies: Requires robust retrievers and citation controllers; multi-document state handling; guardrails for hallucination.
- Knowledge graph construction from documents
- Sectors: enterprise search, research, compliance
- What it could do: Extract entities, relations, and table facts with reliable provenance coordinates and semantic classes, enabling auditability in knowledge graphs.
- Tools/workflows: Structured ETL from Markdown/LaTeX to RDF/Property Graphs; link facts to box IDs and page coordinates.
- Assumptions/dependencies: Additional IE/NLP layers; ontology design; document diversity and cross-document resolution.
- Mobile/on-device OCR via model compression and distillation
- Sectors: consumer apps, field service, SMBs
- What it could do: Smartphone-grade Nemotron-Parse variants for receipts, invoices, and notes with layout awareness.
- Tools/workflows: Quantization, pruning, and distillation leveraging the TC architecture; optimized on-device inference stacks.
- Assumptions/dependencies: Model size and memory constraints; battery and latency trade-offs; domain adaptation for mobile captures.
- Multi-page, cross-reference understanding for books and reports
- Sectors: publishing, academia, legal
- What it could do: Preserve cross-page reading order, figure references, footnotes, and citations to enable interactive e-books and dynamic PDFs.
- Tools/workflows: Long-context decoding pipelines leveraging NoPE design; cross-page linking and back-references; dynamic navigation UIs.
- Assumptions/dependencies: Requires multi-page training and post-processing; consistent figure/citation detection modules.
- Healthcare document normalization to HL7/FHIR
- Sectors: healthcare, insurance
- What it could do: Map structured OCR outputs (tables, forms) to HL7/FHIR resources for EHR ingestion and claims processing.
- Tools/workflows: Schema mapping services; validation against clinical terminologies (SNOMED, LOINC).
- Assumptions/dependencies: Clinical-domain fine-tuning; strict privacy and security controls; integration with hospital IT.
- Policy-driven digital records modernization
- Sectors: government, public administration
- What it could do: Standards that mandate machine-readable layout semantics and reading order in public records, easing accessibility and search.
- Tools/workflows: Reference implementations using NIM container; public benchmarks and conformance suites (e.g., NVpdftex-generated datasets).
- Assumptions/dependencies: Policy adoption, procurement requirements, and training of personnel; interoperability across agencies.
- End-to-end document ETL platforms and SDK ecosystem
- Sectors: software vendors, integrators
- What it could do: Vendor-neutral SDKs that expose prompts, structured outputs, coordinate mappings, and conversion utilities to downstream apps.
- Tools/workflows: Connectors to DMS/ECM systems, RAG, BI; conversion libraries for LaTeX↔HTML↔CSV; provenance-aware APIs.
- Assumptions/dependencies: Community tooling and best practices; maintenance of conversion fidelity across complex documents.
Glossary
- Autoregressive models: Models that generate a sequence one token at a time, each conditioned on previously generated tokens. "Autoregressive models, including those used for OCR, operate by decoding one token at a time, leading to slow inferenceâespecially for text-dense images."
- bf16: Bfloat16; a 16-bit floating-point format that speeds up training/inference while preserving a wide dynamic range. "fp32/bf16 formats"
- BLEU: A text generation metric based on n-gram precision that evaluates overlap with reference text. "BLEU "
- Bounding boxes: Rectangular regions that localize elements on a page or image, typically represented by coordinate pairs. "Nemotron-Parse predicts bounding boxes of the semantic blocks in the form of relative coordinates"
- Canonical reading order: A standardized ordering of page elements that reflects how a human would read the document. "These bounding boxes are predicted in a canonical reading order"
- Causal decoder-only models: Transformer models where each token attends only to earlier tokens via a causal mask, enabling implicit positional information. "in causal decoder-only models the attention mask already provides positional cues"
- Decoder head: The final projection layer in a decoder that maps hidden states to output token logits. "refers to the decoder head"
- Dense OCR: Optical character recognition on images containing unusually high amounts of text per area. "models struggle with dense OCR"
- fp32: 32-bit floating-point format commonly used for model weights and precise computation. "fp32/bf16 formats"
- LaTeXML: A tool that converts LaTeX to XML/HTML for downstream processing. "into HTML with LaTeXML and then into markdown"
- Maximal-information prompt (MIP): A prompt configuration that requests formatted text, bounding boxes, and semantic classes simultaneously. "we define the maximal-information prompt (MIP) as: <output_markdown><predict_bbox><predict_classes>"
- METEOR: A text similarity metric combining precision, recall, stemming, and synonymy, often more recall-oriented than BLEU. "METEOR "
- mBART: A multilingual sequence-to-sequence Transformer architecture used as the language decoder. "uses mBART \citep{mbart} architecture reduced to 10 layers"
- Multi-token inference: Decoding that predicts multiple tokens in parallel per step to accelerate generation. "Multi-token inference"
- No Positional Encoding (NoPE): Training strategy that omits explicit positional embeddings, relying on attention masks and visual features. "No Positional Encoding (NoPE) approaches have been reported to generalize better to longer sequences"
- NVpdftex: An integrated LaTeX-based pipeline producing tightly aligned rendered pages, character-level boxes, and semantic labels. "a high-quality large-scale ground-truth corpus of documents referred to as NVpdftex."
- OmniDocBench: A benchmark suite for evaluating document understanding tasks (text, formulas, tables, reading order). "Further, we evaluate Nemotron-Parse on widely-adopted OmniDocBench (v1.0) benchmark"
- Pixel-shuffle: An operation that rearranges channel information into spatial dimensions to reduce sequence length and computation. "we additionally apply pixel-shuffle on top of the compressed sequence"
- Prompt tokens: Special control tokens that specify which outputs (text, boxes, classes) the model should produce. "three independent prompt tokens that define the requested outputs"
- RADIO: A vision foundation model backbone used to initialize the encoder. "initialized from RADIO~\citep{radio, Heinrich_2025_CVPR}"
- RD-TableBench: A public benchmark of diverse, in-the-wild tables for evaluating table extraction systems. "public RD-TableBench \citep{rdbench} benchmark"
- Relative coordinates: Normalized coordinate representations (e.g., scaled to a fixed width and height). "in the form of relative coordinates, in a scale of "
- Semantic classes: Labels identifying the type or role of detected elements (e.g., Title, Caption, Footnote). "it extracts bounding boxes of text segments, as well as corresponding semantic classes."
- Summary token: A global aggregation token from the encoder appended to the sequence to summarize visual content. "We additionally concatenate the summary token of RADIO to the sequence."
- TEDS: Tree Edit Distance-based Similarity; a metric for comparing predicted vs. ground-truth table structures. "We additionally report TEDS and S-TEDS on several public table benchmarks"
- Teacher forcing: A training technique where ground-truth tokens are fed into the model to guide prediction of subsequent tokens. "During training, we use teacher forcing for token embeddings of additional tokens."
- Token compression (TC): Reducing the number of vision tokens to speed up inference with minimal quality loss. "Nemotron Parse 1.1 with token compression (TC)"
- ViT-H/16: A large Vision Transformer variant with 16×16 patch size used for the vision encoder. "which follows a ViT-H /16 \citep{vit} architecture (657M parameters)"
- Vision neck: An intermediate module that reduces latent dimensionality and sequence length between the encoder and decoder. "The vision neck consisting of horizontal convolutional kernels of size and stride then reduces the dimensionality of the latent space as well as the sequence length."
- Vision token length: The number of visual tokens produced by the encoder that the decoder consumes. "operates on a reduced vision token length"
- Vision-LLMs (VLMs): Models that jointly process visual and textual inputs for tasks like OCR and document understanding. "end-to-end Vision-LLMs \citep{feng2025dolphin, marker, mathpix, wang2409mineru, li2025monkeyocr, cui2025paddleocr, Nougat, nassar2022tableformer, nassar2025smoldocling, poznanski2025olmocr, GOT, ocrflux, dotsocr}"
- VLLM: A high-throughput inference framework/library for serving LLMs efficiently. "along with VLLM support"
- WER: Word Error Rate; the fraction of incorrectly recognized words, used to evaluate OCR accuracy. "we report plaintext WER and F1"
Collections
Sign up for free to add this paper to one or more collections.

