Representation Learning for Spatiotemporal Physical Systems
Abstract: Machine learning approaches to spatiotemporal physical systems have primarily focused on next-frame prediction, with the goal of learning an accurate emulator for the system's evolution in time. However, these emulators are computationally expensive to train and are subject to performance pitfalls, such as compounding errors during autoregressive rollout. In this work, we take a different perspective and look at scientific tasks further downstream of predicting the next frame, such as estimation of a system's governing physical parameters. Accuracy on these tasks offers a uniquely quantifiable glimpse into the physical relevance of the representations of these models. We evaluate the effectiveness of general-purpose self-supervised methods in learning physics-grounded representations that are useful for downstream scientific tasks. Surprisingly, we find that not all methods designed for physical modeling outperform generic self-supervised learning methods on these tasks, and methods that learn in the latent space (e.g., joint embedding predictive architectures, or JEPAs) outperform those optimizing pixel-level prediction objectives. Code is available at https://github.com/helenqu/physical-representation-learning.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What this paper is about
This paper looks at a new way to teach computers to understand how physical systems change over space and time—things like fluids heating up and forming patterns, or layers of liquid sliding past each other. Instead of training models to predict every next video frame (which is slow and often fails over time), the authors focus on learning good “representations” (smart summaries) that help answer science questions, like “What are the hidden settings of this system?” They test different learning methods to see which ones capture the real physics best.
Objectives: The main questions they asked
The authors set out to answer a few simple questions:
- Can general-purpose, self-taught AI (trained without labels) learn useful, physics-aware summaries from videos of physical systems?
- Is it better to predict high-level summaries of what happens next, or to reconstruct raw pixels (the exact image)?
- How well do these learned summaries help with real science tasks, like estimating the system’s key physical parameters (the “invisible knobs” that control behavior)?
- Which methods work well even when you have limited data to fine-tune them for a specific task?
Approach: How they tested the idea (in everyday language)
Think of each physical system as a short movie. The challenge is not just to guess the next frame but to understand the rules behind the movie.
- They tested two main kinds of self-supervised learning:
- Latent prediction (JEPA): Instead of predicting every pixel, the model predicts the future “summary” (a compact representation) from the past summary. Analogy: rather than memorizing every detail of each scene, it learns the storyline and predicts where the story is going.
- Masked autoencoding (VideoMAE): The model hides parts of the video and learns to fill in the missing pixels. Analogy: a puzzle-solver who fills in missing pieces based on the picture’s details.
- They compared these with two physics-focused baselines:
- DISCO: A method that quickly figures out the evolution rules for a specific video and then simulates forward using those rules.
- MPP: An autoregressive model that tries to predict the next frame from the previous ones, frame by frame (like watching a movie one frame at a time and guessing the next image).
- To check whether the models truly “understand” the physics, they didn’t just ask them to make videos. Instead, they froze the learned summaries and trained a small, simple layer on top to predict the system’s hidden parameters. If a model can accurately recover these parameters, its summaries likely contain real physical meaning.
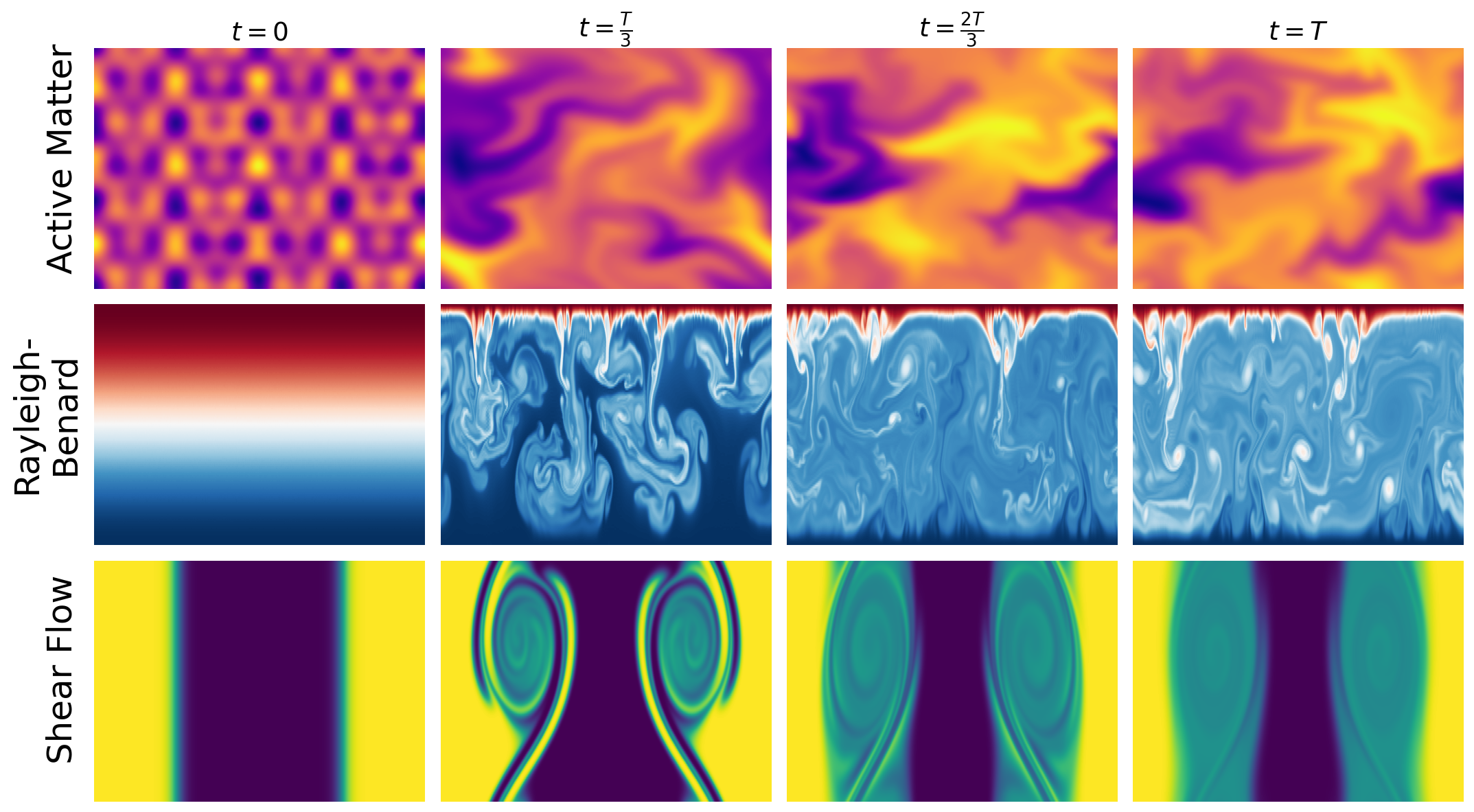
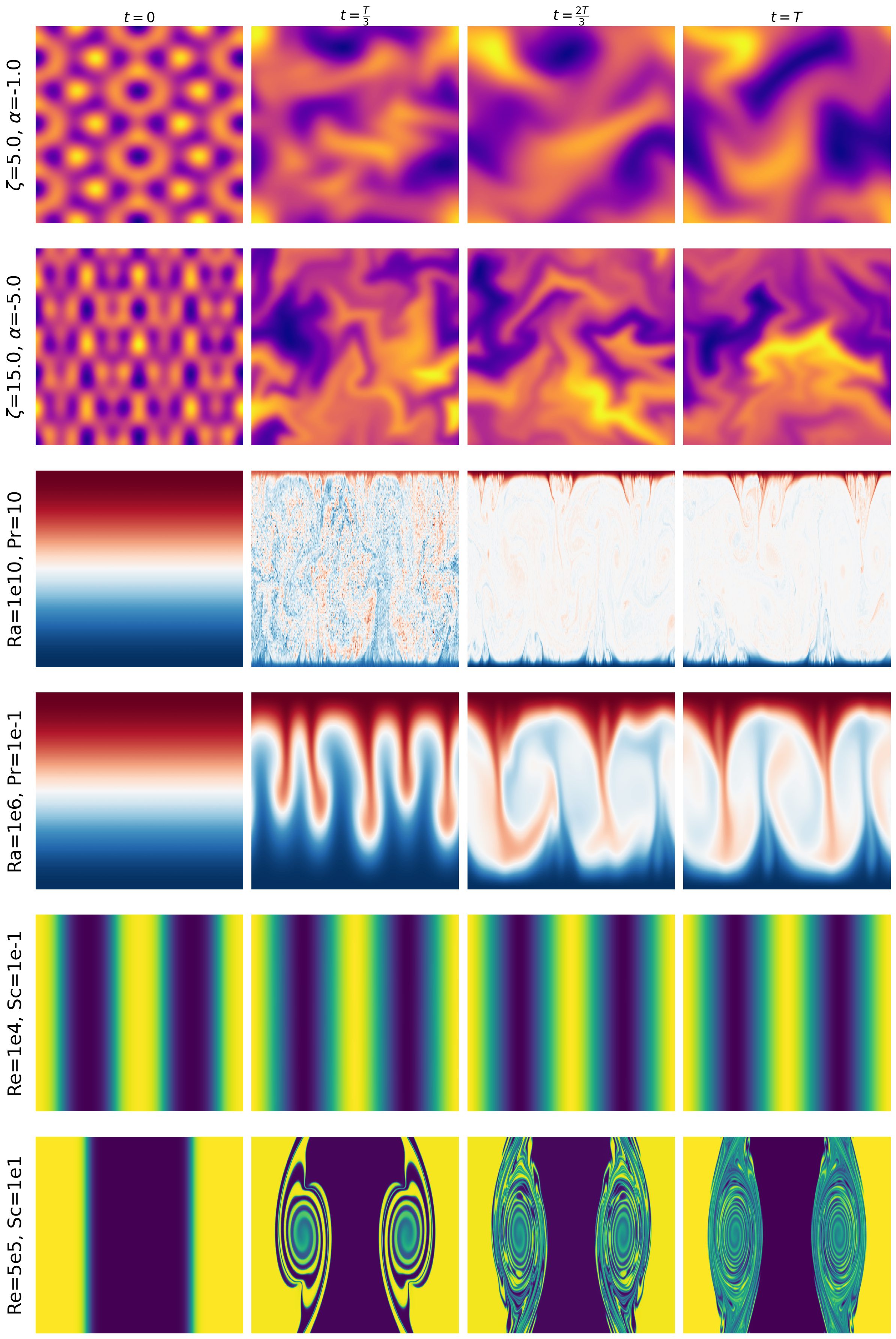
They used three classic systems:
- Active matter: many tiny self-propelled particles swimming around and interacting.
- Shear flow: layers of fluid sliding past each other, sometimes forming swirls and turbulence.
- Rayleigh–Bénard convection: a fluid heated from below and cooled from above, forming beautiful rising and sinking patterns (“cells”).
Each system has a few key parameters (like Reynolds number, Rayleigh number, etc.) that act as the system’s “invisible knobs.”
Main findings: What worked best and why it matters
Here are the main results, stated simply:
- Latent prediction (JEPA) beat pixel-reconstruction (VideoMAE) at estimating hidden physical parameters in all three systems.
- Example: On average, JEPA cut the parameter prediction error by about half on active matter and by a large margin on shear flow and convection.
- Physics-specific DISCO did the best overall, but JEPA—despite being a general-purpose method—came surprisingly close on some systems.
- The autoregressive next-frame model (MPP) struggled on most parameter estimation tasks, even when fully fine-tuned, though it did relatively better on one dataset.
- JEPA needed less fine-tuning data to perform well (good “sample efficiency”). Even with only 10% of the fine-tuning data, JEPA could outperform VideoMAE trained with all the data.
Why this matters:
- Predicting every pixel is like focusing on the little details and missing the big picture. JEPA focuses on the big picture—the underlying rules—so it preserves the physics better for scientific questions.
- Models that learn good summaries can be faster to train, more robust, and more useful for real science tasks like measurement and diagnosis, not just making pretty predictions.
Implications: What this could change
This work suggests a shift in how we build AI for science:
- Instead of pouring effort into pixel-perfect next-frame predictions (which can be slow and drift over time), we should train models to learn meaningful summaries that capture the physics.
- Such summaries make it easier to answer important questions—like estimating parameters, checking stability (laminar vs. turbulent), or comparing materials—without needing huge amounts of labeled data.
- Latent-space predictive learning (like JEPA) looks like a promising foundation for scientific machine learning: it’s efficient, accurate on downstream tasks, and aligns better with how scientists analyze systems—by finding the key variables and rules behind the scenes.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper for future researchers to address:
- Limited domain coverage: validation is confined to three PDE-governed 2D systems from The Well (active matter, shear flow, Rayleigh–Bénard convection); generalization to other physics (e.g., 3D turbulence, magnetohydrodynamics, elasticity, plasma, reaction–diffusion, multi-physics coupling) is untested.
- Distribution shift and OOD robustness: no experiments on extrapolating to unseen parameter ranges, different initial/boundary conditions, geometries, resolutions, or numerical schemes; robustness to domain shift (e.g., grid, discretization, solver) remains unknown.
- Real-world applicability: all evaluations use noise-free simulations; performance under realistic sensor noise, sparsity, occlusion, missing channels, or biased observations is unassessed.
- Partial observability: parameter inference from incomplete fields (e.g., only temperature or a few probes) is not tested, despite its practical relevance.
- Task scope: only scalar parameter estimation is evaluated; other scientific tasks (e.g., regime classification, qualitative behavior prediction, inverse PDE identification, control, causal/structural discovery, data assimilation) are not explored.
- Uncertainty quantification: parameter posteriors, calibrated confidence intervals, and epistemic/aleatoric uncertainty are not quantified; downstream scientific use often requires uncertainty-aware inference.
- Transfer learning and universality: pretraining is done per-dataset; cross-system pretraining, multi-physics pretraining, and transfer to novel systems are not studied.
- Scaling laws and capacity: no systematic study of model size, depth, latent dimensionality, or compute scaling for JEPA/MAE; how representation quality scales with model/data remains unclear.
- Compute and efficiency reporting: pretraining and fine-tuning compute costs, wall-clock times, and memory footprints are not reported; claims of efficiency are not quantitatively supported.
- Architectural confounds: JEPA uses a CNN encoder (ConvNeXt-like) while MAE uses ViT-tiny; gains may conflate objective vs backbone differences; same-backbone ablations are missing.
- Objective-design ablations: JEPA’s temporal horizon , prediction stride, segment length, and VICReg hyperparameters are not ablated; the sensitivity of performance to these choices is unknown.
- Alternative latent objectives: comparisons to other latent-prediction/self-supervised objectives (e.g., InfoNCE/contrastive, BYOL/SIM-Siam, time-contrastive, CPC, masked latent modeling, predictive coding with negatives) are absent.
- Augmentations and symmetries: effects of physics-consistent data augmentations (e.g., translations, rotations, flips, Galilean boosts, reflection) on learned invariances/equivariances are not analyzed.
- Equivariance and inductive biases: the role of group-equivariant architectures (e.g., SE(2)/SO(2)-equivariant CNNs/ViTs) and operator-inspired biases in latent representation quality is not investigated.
- Representation interpretability: how latent features relate to physical invariants, symmetries, spectra (e.g., energy/enstrophy), or coherent structures is not probed.
- Parameter identifiability: potential non-identifiability or degeneracy of parameter-to-trajectory mappings is not examined; no analysis of minimal observation length required for identifiability.
- Train/test split design: it is unclear whether splits are interpolation vs extrapolation in parameter space; without this, generalization claims are hard to interpret.
- Metrics and normalization: MSE is averaged across multiple parameters; parameter scaling/normalization, weighting, and unit handling are not detailed, possibly biasing comparisons.
- Statistical significance: results lack error bars, confidence intervals, or variability across seeds/runs; robustness and reproducibility of improvements are uncertain.
- Fine-tuning probe choices: only attentive probes on frozen encoders are used (JEPA/MAE/DISCO); linear-probe vs non-linear probe comparisons and partial end-to-end tuning ablations are missing.
- Context length and temporal dependence: the effect of input sequence length, sampling rate, and long-range temporal dependencies (especially for chaotic regimes) on parameter inference is not explored.
- CHAOS vs laminar regimes: performance across regime transitions (e.g., onset of turbulence at high Rayleigh/Reynolds) is not systematically characterized.
- Multi-resolution and regridding: invariance or transferability across spatial/temporal resolutions and grid topologies (structured vs unstructured meshes) is untested.
- Channel/modal diversity: handling of vector/tensor fields vs scalar fields, multi-channel inputs (e.g., velocity + temperature), and cross-modal fusion are not discussed.
- Comparison breadth: baselines exclude physics-informed inverse methods (e.g., PINNs for inverse problems, adjoint-based gradient methods, probabilistic operator inference) that directly target parameter estimation.
- Fairness of autoregressive baseline: MPP is not pretrained on the same datasets and uses a different training regime; a matched-data pretraining and representation-only evaluation is needed for a fair comparison.
- JEPA forecast utility: while latent prediction helps parameter inference, it is unclear how JEPA embeddings impact long-horizon rollout or emulator fidelity; trade-offs between representation quality and generative accuracy are not quantified.
- Data efficiency in pretraining: only fine-tuning sample efficiency is reported; dependence of representation quality on pretraining data volume and diversity is not studied.
- Domain-specific priors in JEPA: incorporation of PDE priors (e.g., conservation constraints, boundary conditions) into the latent objective or architecture is not explored.
- Robustness to perturbations: sensitivity to input noise, adversarial perturbations, and numerical artifacts is not evaluated.
- Generalization across geometry and BCs: transfer to different domains (e.g., non-periodic boundaries, different aspect ratios) and boundary conditions (no-slip vs free-slip) remains an open question.
- Hyperparameter transparency and reproducibility: key training details (e.g., learning rates, batch sizes, augmentations, optimizer settings) and code-level settings for all models are not fully enumerated for exact replication.
- Why JEPA underperforms DISCO on Rayleigh–Bénard: the cause of the large gap (e.g., missing inductive biases, regime complexity) is not analyzed; targeted experiments to close this gap are not provided.
- Few-shot and in-context use: zero-/few-shot parameter inference and in-context learning capabilities of JEPA embeddings are not assessed.
- Continual and multi-task learning: whether a single JEPA can support multiple downstream tasks (parameter inference, regime classification, PDE identification) without catastrophic forgetting is untested.
Practical Applications
Immediate Applications
The paper demonstrates that latent-space predictive learning (e.g., JEPA) yields physics-grounded representations that outperform pixel-level reconstruction and autoregressive models for non-generative tasks such as parameter estimation in spatiotemporal physical systems. The following are deployable now with modest adaptation of the released code and standard ML tooling.
- Physics parameter estimation from videos/fields
- Sector: energy, aerospace, manufacturing, chemical engineering, academia
- Use case: Estimate dimensionless numbers (e.g., Reynolds, Prandtl, Schmidt, Rayleigh) or system-specific parameters from CFD simulations or experimental videos to calibrate models, validate experiments, or initialize simulations.
- Tools/products/workflows: Pretrain a JEPA encoder on in-domain simulations; freeze encoder; fine-tune an attentive probe for regression on a small labeled set; deploy the probe for rapid parameter inference in labs and simulation pipelines.
- Assumptions/dependencies: Access to spatiotemporal data similar to pretraining domain; labeled examples of target parameters for fine-tuning; potential 2D-to-3D and sim-to-real domain gaps.
- Regime classification and early warnings for flow transitions
- Sector: energy, aerospace, process industries
- Use case: Classify laminar vs turbulent regimes or detect onset of convection/cellular patterns in pipelines, turbines, heat exchangers, or wind tunnels from sensor videos or flow fields.
- Tools/products/workflows: Train a classifier on frozen JEPA embeddings; integrate into monitoring dashboards for alarms and qualitative predictions.
- Assumptions/dependencies: Labeled regime data; sufficient sensor resolution and frame rate; deployment latency constraints.
- Data-efficient inverse modeling in microfluidics and bio-physical experiments
- Sector: biotech, healthcare R&D, lab-on-chip
- Use case: Infer viscosity, diffusivity, alignment/interaction strengths (active matter analogs) from microscopy videos to tune chip geometries or reagent properties.
- Tools/products/workflows: Pretrain on synthetic microfluidic simulations; fine-tune probes for specific devices; use embeddings for rapid parameter sweeps.
- Assumptions/dependencies: Quality synthetic data matching device physics; microscope video access; careful handling of domain shift.
- Digital twin calibration assistants
- Sector: manufacturing, energy, building systems
- Use case: Calibrate CFD-driven digital twins by matching observed spatiotemporal fields to parameter estimates (e.g., turbulence intensity, diffusivities) for better predictive fidelity.
- Tools/products/workflows: Embed observed data with JEPA; run parameter inference head; feed estimated parameters into the twin’s solver or reduced-order model.
- Assumptions/dependencies: Digital twin availability; consistent data formats; boundary condition and geometry mismatches must be considered.
- Embedding-based retrieval and experiment design
- Sector: academia, industrial R&D
- Use case: Retrieve similar dynamical behaviors across large simulation archives; accelerate hypothesis testing and experiment selection.
- Tools/products/workflows: Index JEPA embeddings; implement nearest-neighbor search for “find trajectories like this”; use results to guide parameter exploration.
- Assumptions/dependencies: Adequate metadata and storage for embedding indices; representative pretraining.
- Drop-in improvement for scientific ML pipelines
- Sector: software/tools for scientific computing
- Use case: Replace pixel-reconstruction pretraining (e.g., VideoMAE) with JEPA-style latent predictive pretraining for downstream non-generative tasks, improving accuracy and data efficiency.
- Tools/products/workflows: Integrate JEPA encoders into existing PyTorch/JAX pipelines; reuse attentive probe fine-tuning; leverage the paper’s public code.
- Assumptions/dependencies: Compute resources for pretraining; domain-specific augmentations and masking strategies tuned for PDE data.
- Curriculum and benchmarking in scientific ML education
- Sector: academia, education
- Use case: Teach representation learning for physics using the paper’s testbed (active matter, shear flow, Rayleigh–Bénard) to compare objectives and downstream utility.
- Tools/products/workflows: Classroom labs using released code/models; standardized parameter-estimation probes.
- Assumptions/dependencies: Access to datasets (e.g., The Well) and GPU time for small-scale runs.
Long-Term Applications
These applications extend the paper’s methods to broader domains, larger scale, and real-world systems, requiring further research in generalization (3D, geometry, noise), sim-to-real transfer, uncertainty quantification, and systems integration.
- Cross-domain scientific foundation encoders for PDE-governed systems
- Sector: climate/weather, materials, astrophysics, geoscience, plasma physics
- Use case: Pretrain large JEPA-style models across many physics datasets to enable zero/few-shot parameter inference and qualitative regime prediction in new systems.
- Tools/products/workflows: Model zoo and APIs for “physics encoders-as-a-service”; domain adapters for specific sensors/modalities.
- Assumptions/dependencies: Large, diverse pretraining corpora (e.g., expanded versions of The Well); standardized data formats; compute scaling; licensing for data/model sharing.
- Real-time adaptive control via latent representations
- Sector: aerospace, automotive, HVAC, renewable energy (wind farms)
- Use case: Use fast, robust embeddings to inform feedback controllers that suppress turbulence, reduce drag, or optimize mixing/heat transfer in real time.
- Tools/products/workflows: Onboard/edge deployment of JEPA encoders; co-design with control policies (MPC/RL) that operate in the learned latent space; latency-optimized inference.
- Assumptions/dependencies: Reliable sim-to-real transfer, safety certification, real-time constraints, integration with actuation systems.
- Data assimilation with latent spaces
- Sector: meteorology, oceanography, hydrology
- Use case: Embed observations into low-dimensional latent spaces for assimilation (e.g., EnKF/4D-Var in latent space) to speed up and stabilize state estimation and parameter calibration.
- Tools/products/workflows: Hybrid pipelines connecting JEPA encoders with operator learners or numerical solvers; uncertainty-aware probes.
- Assumptions/dependencies: Theoretical and empirical UQ in latent spaces; compatibility with operational assimilation systems; treatment of observation operators and error models.
- End-to-end inverse design and PDE-constrained optimization
- Sector: aerospace, materials, civil/mechanical engineering
- Use case: Combine JEPA embeddings with differentiable solvers/operators to accelerate inverse design (e.g., airfoils, metamaterials, thermal layouts) by learning informative low-dimensional summaries and parameter maps.
- Tools/products/workflows: Coupling with PINNs/neural operators/AmorFEA; gradient-based or Bayesian optimization in latent space.
- Assumptions/dependencies: Robustness across geometries and boundary conditions; integration with CAD/CAE workflows; scalable training data.
- Multimodal sensing and robotic navigation in fluid environments
- Sector: marine robotics, UAVs, environmental monitoring
- Use case: Fuse vision/flow sensors; estimate local flow parameters and regimes for navigation and station keeping near structures or in cluttered environments.
- Tools/products/workflows: Multimodal JEPA extensions (video + sparse sensor streams); onboard inference with low SWaP hardware.
- Assumptions/dependencies: Robustness to noise and occlusions; power and compute constraints; dataset collection and labeling.
- Smart buildings and infrastructure management
- Sector: built environment, facility management
- Use case: Infer convection and airflow patterns from cameras and thermal sensors to optimize HVAC control, improve comfort, and reduce energy consumption.
- Tools/products/workflows: Edge-deployed encoders; integration with building management systems; closed-loop optimization with latent features.
- Assumptions/dependencies: Privacy-preserving sensing; generalization to complex 3D indoor flows; regulatory approval.
- Bio-physical modeling and diagnostics
- Sector: healthcare research, biomedical engineering
- Use case: Model collective cell dynamics (active matter analogs) and infer biophysical parameters from live-cell imaging for diagnostics, drug screening, or tissue engineering.
- Tools/products/workflows: Domain-specific pretraining on bio-physical simulations; collaboration with automated microscopy and lab information systems.
- Assumptions/dependencies: High-quality labeled datasets; ethical approvals; handling of biological variability and noise.
- Policy planning with calibrated digital twins
- Sector: public sector, utilities, urban planning
- Use case: Faster scenario testing for climate adaptation (e.g., heat islands, urban airflow), water networks, and energy systems using parameter-calibrated twins for planning and risk assessment.
- Tools/products/workflows: JEPA-powered calibration modules embedded in city-scale twins; interactive planning tools.
- Assumptions/dependencies: Validation and trust frameworks; transparent uncertainty estimates; cross-agency data sharing.
- Open, standardized tooling for physics-grounded representation learning
- Sector: software ecosystems for scientific computing
- Use case: Community-maintained libraries providing pretrained physics encoders, probing heads, evaluation harnesses, and interoperability with numerical solvers.
- Tools/products/workflows: Plugins for PyTorch/JAX/SciPy; ONNX export for deployment; benchmarks and leaderboards spanning multiple domains.
- Assumptions/dependencies: Community governance; funding for maintenance; standards for datasets and metrics.
Notes across applications:
- The paper’s empirical evidence is based on three systems (active matter, shear flow, Rayleigh–Bénard) and synthetic datasets (e.g., The Well). Generalization to 3D, complex geometries, and real-world noise requires further validation.
- JEPA’s advantage is strongest for non-generative downstream tasks (e.g., parameter inference, regime classification) and under limited fine-tuning data; pixel-level or autoregressive models may still be preferable for high-fidelity rollout/emulation.
- For safety-critical or operational deployments, uncertainty quantification, interpretability, and robust handling of domain shifts are essential extensions.
Glossary
- Active dipole strength: A parameter quantifying the strength of force dipoles generated by active particles. "The system parameters of interest are α, the active dipole strength, and ζ, the strength of particle alignment through steric interactions."
- Active matter: Systems of self-driven agents that convert energy into motion, exhibiting emergent collective behavior. "Active matter systems are a collection of agents that convert chemical energy into mechanical work, causing emergent, system-wide patterns and collective dynamics."
- Attentive probes: Lightweight attention-based heads trained on frozen representations to assess or adapt learned features. "to fine-tune attentive probes for 100 epochs on top of the frozen encoders."
- Autoregressive foundation models: Large models trained to predict the next timestep conditioned on previous ones, often serving as surrogates for simulations. "Autoregressive foundation models."
- Autoregressive rollout: Iterative generation process where each prediction conditions on previous model outputs, potentially compounding errors. "compounding errors during autoregressive rollout."
- Bénard convective cells: Patterned convection rolls forming in a fluid layer heated from below and cooled from above. "forming Bénard convective cells due to the temperature gradient."
- Buoyancy forces: Forces arising from density differences in a fluid under gravity, driving convection. "the ratio of buoyancy forces to viscous forces"
- ConvNeXt: A modern convolutional neural network architecture used as a backbone encoder. "We implement the JEPA encoder as a downsampling CNN following ConvNeXt"
- Covariance matrix: Matrix capturing pairwise covariances between representation dimensions. "where is the covariance matrix of ."
- Covariance regularization term: A loss term that penalizes correlations between different representation dimensions to encourage decorrelation. " is the covariance regularization term"
- DISCO: An operator meta-learning framework for physical systems that learns to infer evolution rules from context. "the operator meta-learning framework DISCO"
- Eddy: Swirling flow structures in fluids associated with turbulence and mixing. "vortex/eddy formation"
- Embeddings: Vector representations learned by models that capture high-level features of inputs. "embeddings learned by latent prediction models consistently outperform pixel-based self-supervised methods."
- Explicit integration: Numerical time-stepping method advancing a system using current state information without solving implicit equations. "and evolves it forward in time using explicit integration."
- Foundation models (for physics): Broadly pretrained models intended to transfer across many physical systems and tasks. "Foundation models for physics, often implemented as pixel-level autoregressive models for spatiotemporal systems"
- Incompressible Navier-Stokes: The fluid dynamics equations assuming constant density, governing velocity and pressure fields. "modeled by incompressible Navier-Stokes"
- Inductive bias: Architectural or training assumptions that guide learning toward certain solution families. "with the inductive bias of neural operators."
- Invariance criterion: Loss component encouraging representations to be invariant across related inputs. " is the invariance criterion"
- In-context operator learning: Approach that infers a system-specific operator from a short context and then applies it to predict dynamics. "In-context operator learning models combine in-context transformers with the inductive bias of neural operators."
- JEPA (Joint Embedding Predictive Architectures): Models trained to predict future representations (not pixels), aligning embeddings across time. "joint embedding predictive architectures (JEPA)"
- Kinetic theory: Statistical description of many-particle systems used to model fluid-like behavior of active matter. "which is modeled by kinetic theory."
- Laminar: Smooth, orderly fluid flow regime with little mixing between layers. "whether the system remains laminar or becomes turbulent"
- Latent prediction models: Models that predict in representation space rather than pixel space, often yielding more abstract, task-relevant signals. "latent prediction models consistently outperform pixel-based self-supervised methods."
- Latent space: The model’s internal representation space capturing high-level factors of variation. "learn in the latent space (e.g., joint embedding predictive architectures, or JEPAs)"
- Masked autoencoding: Self-supervised learning technique reconstructing masked parts of inputs to learn useful representations. "We implement masked autoencoding in this work"
- Mode collapse: Failure mode where a model maps diverse inputs to similar representations or outputs. "to prevent mode collapse:"
- Momentum diffusivity: Effective diffusion of momentum in a fluid, related to viscosity. "the ratio of momentum diffusivity to thermal diffusivity."
- MPP: A specific autoregressive video model used as a baseline for physical prediction. "the autoregressive model MPP"
- Neural operator-style approaches: Methods that learn mappings between function spaces, embedding operator biases into architectures. "neural operator-style approaches"
- Operator network: A learned function that maps states to their time evolution rule in operator-learning frameworks. "infers a trajectory-specific operator network "
- Parameter estimation: Inferring underlying physical parameters governing a system’s dynamics from observed data. "such as parameter estimation or qualitative prediction"
- Pixel-level prediction models: Models trained to predict raw pixel values rather than abstract representations. "pixel-level prediction models"
- Pixel reconstruction models: Autoencoder-style models trained to reconstruct input pixels, often learning low-level visual details. "pixel reconstruction models learn low-level detail in the visual input"
- Prandtl number: Dimensionless ratio of momentum diffusivity to thermal diffusivity in fluid flow. "the Prandtl number , the ratio of momentum diffusivity to thermal diffusivity."
- Rayleigh-Bénard convection: Convection in a horizontal fluid layer heated from below and cooled from above, forming cellular patterns. "Rayleigh-Bénard convection"
- Rayleigh number: Dimensionless measure comparing buoyancy and viscous forces, indicating the onset of convection. "the Rayleigh number , the ratio of buoyancy forces to viscous forces"
- Reynolds number: Dimensionless ratio of inertial to viscous forces, indicating laminar versus turbulent flow regimes. "The system parameters of interest are the Reynolds number, the ratio between inertial and viscous forces in the fluid"
- Schmidt number: Dimensionless ratio of momentum diffusivity to mass diffusivity. "the Schmidt number, the ratio of momentum diffusivity to mass diffusivity, of the fluids."
- Shear flow: Flow characterized by layers moving parallel at different velocities, possibly leading to instabilities. "Shear flow describes the boundary between layers of fluid"
- Steric interactions: Repulsive interactions due to particle size and excluded volume effects. "steric interactions."
- Stokes fluid: Fluid regime where inertial forces are negligible compared to viscous forces (low Reynolds number). "immersed in a Stokes fluid"
- Surrogate models: Learned approximations that emulate expensive numerical simulations. "These are often called 'surrogate models' due to their potential to replace the computationally expensive procedure of numerically solving for the next step"
- Temporal tube masking: Video masking strategy where the same spatial mask is applied consistently across frames. "enforcing temporal tube masking"
- Thermal diffusivity: Rate at which heat diffuses through a material or fluid. "thermal diffusivity"
- Turbulence: Chaotic, vortical fluid flow regime with strong mixing across scales. "turbulence."
- Variance regularization term: Loss term encouraging each representation dimension to have sufficient variance to avoid collapse. " is the variance regularization term"
- VideoMAE: A masked autoencoding approach tailored for video self-supervised pretraining. "VideoMAE"
- Viscous forces: Forces due to viscosity that resist relative motion in a fluid. "viscous forces"
- Vortex: Rotating fluid structure associated with shear and turbulence. "vortex/eddy formation"
Collections
Sign up for free to add this paper to one or more collections.

