Video4Spatial: Towards Visuospatial Intelligence with Context-Guided Video Generation
Abstract: We investigate whether video generative models can exhibit visuospatial intelligence, a capability central to human cognition, using only visual data. To this end, we present Video4Spatial, a framework showing that video diffusion models conditioned solely on video-based scene context can perform complex spatial tasks. We validate on two tasks: scene navigation - following camera-pose instructions while remaining consistent with 3D geometry of the scene, and object grounding - which requires semantic localization, instruction following, and planning. Both tasks use video-only inputs, without auxiliary modalities such as depth or poses. With simple yet effective design choices in the framework and data curation, Video4Spatial demonstrates strong spatial understanding from video context: it plans navigation and grounds target objects end-to-end, follows camera-pose instructions while maintaining spatial consistency, and generalizes to long contexts and out-of-domain environments. Taken together, these results advance video generative models toward general visuospatial reasoning.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
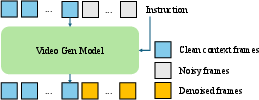
This paper asks a big question: can an AI that makes videos learn to “think in space” just by watching video clips? The authors build a system called Video4Spatial to test this. It takes a short video of a place (like a room) plus simple instructions, and then it generates a new video that:
- Navigates through the scene in a realistic way, and
- Finds and points out a specific object (like “a green plant” or “a guitar”)
Importantly, it does this using only video as input—no extra 3D maps, no depth sensors, and no camera pose labels.
What goals and questions does it explore?
Here’s what the researchers want to know, in simple terms:
- Can a video model understand the shape and layout of a room from a few frames?
- Can it plan a path that matches instructions (like a camera route) and still look true to the real room?
- Can it end the video with the right object clearly visible in the center, without making things up?
- Does it keep the video smooth over time and consistent with the scene?
- Can it work with long video contexts and also handle new, unfamiliar places?
How does the system work?
Think of the AI as a careful movie-maker:
- It starts with “context frames”: a handful of snapshots from the room. These act like anchors or a mini “memory” of the place.
- It gets an instruction:
- Text: “Find the green plant.”
- Or a camera plan: “Move forward, turn left, look up,” etc.
- It then “sculpts” a video from noise (this is how diffusion models work), step by step, making sure the new frames fit the room and follow the instruction.
To make this work well, the authors add a few clever tricks:
- Joint guidance: They teach the model to obey both the instruction and the context frames at the same time. Think of it like following a teacher (the instruction) while also respecting the map (the context).
- Bounding box helper: At the end of training videos, they draw a red rectangle around the target object. This teaches the model to point out the object clearly when it finds it.
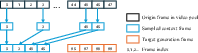
- Smart frame sampling: Instead of feeding lots of almost-identical frames, they pick frames that are spread out in time. They also tell the model where each frame came from in the original timeline (using a position encoding method), so it still understands order even with gaps. This reduces redundancy and helps the model handle longer contexts later.
Data and setup:
- They repurpose indoor 3D scanning datasets (ScanNet++ and ARKitScenes) because they have long videos of rooms.
- An AI helper (a vision-LLM) is used to:
- Find clips where an object ends up centered in the last frame, and
- Write simple text instructions for grounding tasks.
- For navigation tasks, they convert known camera routes into easy-to-follow pose instructions.
- They fine-tune a strong open video generator (Wan2.2) and inject instructions into the model so it can follow them while generating.
What did they find, and why does it matter?
Big takeaways:
- Strong spatial consistency: The model’s generated videos match the real room’s geometry closely. It avoids “hallucinations” (like inventing objects or impossible views) more than other video models that use only a single starting image.
- Better object grounding: When told to find an object, the model can end with that object centered and clearly marked. This improves a lot when using the red bounding box trick.
- Reliable navigation: It can follow camera movement instructions and produce videos that look smooth and believable—without needing extra 3D info like depth maps or camera poses, unlike many other methods.
- Generalization: Even though training was on indoor scenes, the model works surprisingly well outdoors and on new object types. It also handles longer context windows at test time than it saw during training.
- Design choices matter:
- Removing joint guidance or the bounding-box output hurts performance.
- Using continuous position encoding with non-contiguous frames confuses the model; the special non-contiguous encoding helps.
- Training with some, but not too much, context gives the best balance between obeying the scene and following instructions.
Why it’s important:
- It shows that a video generator can develop real 3D understanding just from video. That’s simpler and more scalable than requiring extra sensors or labels.
- It moves video AIs from “pretty renderers” toward “reasoners” that can plan and act within a space.
What could this lead to?
This kind of spatially aware video generation could help:
- Virtual tours and games: guiding a camera through realistic spaces.
- Robotics: planning where to move next using only a camera feed.
- AR/VR: generating consistent views that match the user’s environment.
- Storytelling and editing: creating scene-true shots without detailed 3D setups.
The authors note current limits (like modest resolution and occasional artifacts) and suggest future improvements: smarter long-term memory, better temporal modeling, higher-resolution generation, stronger grounding for rare objects, and handling dynamic, moving scenes. Overall, Video4Spatial is a promising step toward AI that understands and reasons about space using nothing more than video.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of gaps, limitations, and open questions the paper leaves unresolved. Each point is phrased to be actionable for future researchers.
- Limited resolution and context scaling: The method operates at 416×256 due to uncompressed context; no empirical scaling laws, memory/latency profiling, or validated context compression strategies (e.g., hierarchical tokens, state-space models) are provided for higher resolutions or longer contexts.
- OOD generalization is only qualitative: No quantitative evaluation on outdoor or truly out-of-domain scenes; lacks metrics, datasets, and protocols to assess robustness to novel semantics, lighting, weather, and geometry.
- Dynamic environments are unaddressed: The framework is tested on mostly static indoor scenes; it does not evaluate or train for moving objects, dynamic occlusions, non-rigid deformations, or human activities that change scene geometry over time.
- Pose compliance is not measured: Scene navigation reports PSNR/LPIPS/IQ against GT videos but does not estimate 6-DoF camera poses from generated videos to quantify deviation from commanded trajectories (e.g., ATE/RPE, angular error).
- Evaluation depends on external models with potential bias: SD relies on VGGT point-cloud reconstructions and registration using appended GT frames; IF relies on Qwen3-VL detection. No calibration, error analysis, or human-validated ground truth to quantify these dependencies and their failure modes.
- Potential evaluation leakage in SD: The registration step appends 40 GT frames to align generated point clouds—this may bias SD in favor of geometric consistency. An alternative alignment protocol without GT anchors or with learned alignment is needed.
- Grounding metric uses auto-labeled boxes: IF uses VLM-derived boxes rather than human annotations. The label noise, category coverage, and domain biases of Qwen3-VL are not measured; benchmarks with human GT boxes are needed.
- Auxiliary bbox trade-offs unquantified: Drawing red bboxes improves grounding but may reduce realism or cause learned “shortcut” behavior. The paper lacks user studies, realism metrics, or analyses on whether bbox priors harm generative fidelity or generalize to other reasoning cues.
- Lack of trajectory/planning metrics: Object-grounding “planning” is not quantitatively evaluated (e.g., path length optimality, detours, collision avoidance, visibility constraints). No measures of efficiency, exploration vs. exploitation, or causal task success beyond final-frame centering.
- Instruction complexity is narrow: Tested instructions are simple (focus on <object> centered). Compositional, ambiguous, multi-object, relational, or spatially constrained instructions (e.g., “go around the table then face the window”) are not evaluated.
- No text-only navigation: Scene navigation is controlled by explicit 6-DoF pose sequences; the ability to parse and execute natural-language navigation instructions without pose inputs remains unexplored.
- Long-horizon temporal coherence is not quantified: Beyond IQ/DD, no metrics (e.g., drift, cyclic consistency, temporal identity tracking) assess coherence across hundreds of frames or under long context extrapolation.
- Sensitivity to non-contiguous RoPE indexing and offsets: The fixed offset of 50 and sparse indexing are design choices without principled analysis; no hyperparameter sweeps, failure cases, or comparisons to alternative positional schemes (ALiBi, learned 3D positions).
- Robustness to degraded context is unknown: No tests on noisy, blurred, low-light, aliased, or occluded context frames; sensitivity analyses to context quality, sparsity, and misalignment are missing.
- Fairness of baseline comparisons: Baselines differ in resolution, frame counts, and required 3D inputs; no controlled re-implementations or matched configurations. The absence of strong video-only baselines limits interpretability of gains.
- Dataset bias and coverage: Training data stems from indoor scans with objects centered in the final frames (auto-curated). The distribution of categories, spatial layouts, and “easy vs. hard” scenes is not characterized; there is no stress testing on rare/long-tail categories.
- Pretraining dependency: The method degrades substantially without pretraining. There is no study of data scale vs. performance, model capacity vs. generalization, or whether training from scratch on task-specific data can close the gap.
- Flow-matching vs. diffusion objective: The partial fine-tuning of attention layers under a flow-matching objective is not compared to full diffusion fine-tuning or other objectives; the contribution of each training choice is unclear.
- Joint CFG formulation is under-theorized: The noise-context CFG extension lacks theoretical grounding and ablation across guidance scales and formulations (beyond a brief figure); how it interacts with instruction vs. context components is not dissected.
- Information leakage risks: Context and target frames may originate from the same source video; although RoPE offsets attempt separation, a more rigorous audit of leakage (e.g., memorization tests, synthetic leakage controls) is missing.
- Camera control tokenization: Camera poses are encoded via Plücker coordinates and added to frame tokens; there is no comparison to other encodings (e.g., SE(3) embeddings, Lie algebra, quaternions) or analysis of their effect on controllability and stability.
- No integration with action or control frameworks: The video-only outputs are not connected to agents or policies for embodied tasks; how to translate generated trajectories into executable actions or closed-loop control is not explored.
- Compute and efficiency are opaque: Training/inference costs, memory footprints, throughput, and scaling curves with context length/resolution are not reported; practical deployment constraints are unclear.
- Benchmark and code availability: The curated datasets, prompts, and evaluation pipelines (VGGT and Qwen3-VL dependencies) are not released; a standardized, reproducible benchmark for video-only visuospatial tasks is missing.
Practical Applications
Immediate Applications
The following applications can be deployed with current capabilities, given typical compute resources and reasonable integration effort.
- Bold: Context-guided shot generation for film and TV
- Sector: media, VFX, virtual production
- What it does: Starting from a few context frames of a set or scene, generate camera-following shots or object-finding sequences that respect the scene’s geometry without needing explicit depth or camera pose.
- Potential tool/product/workflow: “Spatially Consistent Shot Generator” plugin for editing suites (e.g., DaVinci Resolve, Premiere) where editors provide context clips plus text or pose instructions; outputs candidate navigations and “find-the-object” beats; optional overlay of model-generated bounding boxes in the final frames to verify target grounding.
- Assumptions/dependencies: Requires sufficient contextual overlap in the input video; current resolution is modest (416×256) and may need upscaling; quality depends on pretraining and joint classifier-free guidance (CFG) over context + instruction; not real-time.
- Bold: Virtual scouting and previsualization from existing set footage
- Sector: media, virtual production
- What it does: Use previously captured set walk-throughs to synthesize alternative camera trajectories and end shots centered on specified props (e.g., “end on the guitar center frame”), improving previsualization without additional on-set capture.
- Potential tool/product/workflow: Previs assistants that accept rough text prompts or pose waypoints and auto-generate multiple plausible navigation takes; diversity of paths emerges from the model’s planning in video generation.
- Assumptions/dependencies: Performs best with indoor scenes similar to training data; camera trajectory instructions can be encoded via Plücker coordinates; may require manual selection of context frames with good coverage.
- Bold: Continuity checking and spatial consistency audits in post
- Sector: media, QA
- What it does: Generate “reference-consistent” alternatives to check whether newly edited shots remain faithful to scene geometry; detect hallucinated content by comparing Spatial Distance (SD) against ground-truth point clouds (using VGGT).
- Potential tool/product/workflow: A “Spatial Consistency Auditor” that runs SD on generated edits and flags high SD (out-of-context hallucinations); supports iterative edits.
- Assumptions/dependencies: Requires access to original scene footage or reconstruction; SD uses VGGT to reconstruct point clouds from both reference and generated clips.
- Bold: Scene-aware video outpainting and extension
- Sector: media, advertising, social media content
- What it does: Extend short clips with additional frames that maintain 3D layout and camera control; add B‑roll consistent with the original setting.
- Potential tool/product/workflow: “Context-extend” mode in video editors leveraging non-contiguous context sampling and RoPE indexing to integrate long-history frames.
- Assumptions/dependencies: Needs diverse non-contiguous context frames for robust extension; performance improved by joint CFG and long-context inference.
- Bold: Warehouse and retail aisle assistance via video-only object finding
- Sector: logistics, retail operations
- What it does: Workers capture a short context video of an aisle; the system generates a path video and final frame with a bounding box around the desired SKU category (e.g., “bag of rice”), providing visual wayfinding without maps.
- Potential tool/product/workflow: Mobile app workflow where staff record 10–20 seconds of aisle video and select a target category; app outputs a guiding clip ending with a highlighted target.
- Assumptions/dependencies: Requires objects present in context; category grounding depends on training coverage; model generalizes better to indoor scenes; compute may be offloaded to cloud.
- Bold: Facility and real-estate virtual tours with guided navigation
- Sector: real estate, facility management
- What it does: Generate interactive tour segments following specified camera paths or ending at points of interest (e.g., “finish centered on the thermostat”), based purely on previously captured walkthroughs.
- Potential tool/product/workflow: “Tour Composer” that produces pose-following sequences from context; export to web tours with hotspots.
- Assumptions/dependencies: Works best when tours have overlapping viewpoints; higher-resolution fidelity may require upscaling or future context compression.
- Bold: Surveillance review assistance for object-of-interest localization
- Sector: security, investigations
- What it does: Given segments of CCTV footage from the same environment, synthesize navigation sequences that converge on objects or areas of interest and mark them with bounding boxes.
- Potential tool/product/workflow: Analyst console feature for “video-only object grounding”; quick hypothesis generation of paths to targets.
- Assumptions/dependencies: Not a replacement for forensics; risk of hallucinations in low-context settings; should include SD checks and human-in-the-loop validation.
- Bold: AR guidance overlays for indoor wayfinding
- Sector: AR/VR, consumer apps
- What it does: Capture a short indoor context video and generate a preview clip that demonstrates the route and final viewpoint; overlay a bounding box guide for the target item in the user’s camera view.
- Potential tool/product/workflow: Smartphone AR companion that pairs generated preview with on-device overlays aligning to the final frames.
- Assumptions/dependencies: Requires enough contextual coverage; alignment between generated and live camera feed needs simple homography or feature matching; works better in static scenes.
- Bold: Research tooling for video-only spatial reasoning
- Sector: academia, open-source
- What it does: Provide a turnkey pipeline for dataset bootstrapping (VLM-generated instructions and targets), training/fine-tuning with non-contiguous context and RoPE indexing, and evaluation with SD + Instruction Following (IF).
- Potential tool/product/workflow: Open-sourced “Video4Spatial Toolkit” comprising data curation scripts (Qwen3-VL or equivalents), training recipes (joint CFG, auxiliary bounding boxes), and evaluation code (VGGT-based SD).
- Assumptions/dependencies: Requires licensed access to a video generation backbone (e.g., Wan2.2) and a VLM for data curation; compute resources for fine-tuning.
- Bold: Educational demonstrations of visuospatial reasoning
- Sector: education
- What it does: Classroom-friendly demos where students specify camera paths or objects and see how the model plans and generates consistent sequences from context.
- Potential tool/product/workflow: Web demos illustrating geometric consistency, pose-following, and object grounding; supports lessons in spatial cognition and computer vision.
- Assumptions/dependencies: Content moderation and privacy controls for uploaded videos; lower fidelity at current resolutions.
Long-Term Applications
These applications will benefit from further research, higher-resolution, stronger temporal modeling, and robustness across dynamic/outdoor domains.
- Bold: Video-only embodied AI navigation and object fetch
- Sector: robotics, smart home
- What it does: Replace or augment SLAM with video-conditioned planning—robots infer 3D layout and plan paths from camera input, localizing target objects without explicit depth or pose sensors.
- Potential tool/product/workflow: “Visuospatial Navigator” module for domestic robots that fuses live video context with goal instructions to propose trajectories and final object localization.
- Assumptions/dependencies: Requires reliability in dynamic scenes, real-time inference, safety-certified planning, and robust domain generalization; likely needs hybrid integration with classical perception.
- Bold: Video-first spatial mapping for facilities (SLAM-lite)
- Sector: construction, facility management, digital twins
- What it does: Derive navigable videos and coarse spatial maps from routine walkthrough videos—reducing dependence on LiDAR or depth sensors for certain tasks (e.g., inspection routing).
- Potential tool/product/workflow: “Video Twin Builder” that builds navigable viewpoints and consistent trajectories from episodic video datasets; integrates with CAD/BIM.
- Assumptions/dependencies: Accuracy thresholds must be validated; integrating with 3D reconstruction still beneficial; policy and compliance for site data retention.
- Bold: AR assistants for finding household objects
- Sector: consumer, accessibility
- What it does: Users capture short videos; assistant generates route previews and final localized frames for missing items, with overlays guiding the search.
- Potential tool/product/workflow: “Find-It AR” assistant embedded in smart glasses or phones; relies on persistent video context caches of the home.
- Assumptions/dependencies: Requires fine-grained, reliable object recognition; privacy protection and on-device processing; resilient to clutter and scene changes.
- Bold: Hospital and campus navigation guides from archival video
- Sector: healthcare, education
- What it does: Create patient/staff wayfinding videos and specific equipment-location guides from existing corridor walkthroughs—no expensive mapping infrastructure.
- Potential tool/product/workflow: “Facility Wayfinder” that maintains spatially consistent preview routes to equipment and rooms.
- Assumptions/dependencies: Must handle dynamic crowds and frequent rearrangements; accessibility design and compliance; high reliability requirements.
- Bold: Robot training data synthesis without 3D labels
- Sector: robotics R&D
- What it does: Generate large-scale, scene-consistent video trajectories and object-grounding episodes from raw videos for training visuomotor policies, reducing the need for curated 3D annotations.
- Potential tool/product/workflow: “Video Curriculum Generator” producing diverse navigations and object-localization trajectories for policy learning.
- Assumptions/dependencies: Synthetic-to-real transfer and safety validation; better temporal coherence and higher resolution required; benchmarked against real performance.
- Bold: Interactive cinematic authoring with multi-shot spatial control
- Sector: media creation tools
- What it does: Author entire scenes by specifying camera paths and object focal points across shots; the system ensures inter-shot spatial consistency using video-only context.
- Potential tool/product/workflow: “Spatial Storyboarder” that links multiple shots via shared context memory; integrates mixture-of-shots generation and long-context attention.
- Assumptions/dependencies: Requires context compression, high-res generation, and production-grade fidelity; human oversight for narrative and continuity.
- Bold: Industrial inspection guidance (energy, utilities)
- Sector: energy, utilities, safety
- What it does: From periodic walkthrough videos, synthesize navigation guides to valves, gauges, or hazard points, maintaining spatial coherence without 3D sensors.
- Potential tool/product/workflow: “Inspection Route Composer” that exports navigable clips for crews; pairs with checklists and geotagging.
- Assumptions/dependencies: High reliability and traceability; handle outdoor/complex lighting; align with safety protocols; may need hybrid sensing for critical tasks.
- Bold: Policy frameworks for generative spatial guidance
- Sector: policy/regulation
- What it does: Establish standards for evaluating spatial consistency, hallucination risks, and disclosure when generative systems produce navigation or localization guidance.
- Potential tool/product/workflow: Guidelines adopting metrics such as SD and IF(SD<δ) for certification; mandated human-in-the-loop review for safety-critical deployments.
- Assumptions/dependencies: Multi-stakeholder input (industry, academia, regulators); evolving benchmarks; transparency about training data and limitations.
- Bold: Commercial context-compressed, high-res spatial generators
- Sector: software platforms
- What it does: Production-ready models that ingest long video histories via context compression (e.g., Mamba variants) and output high-resolution, geometry-consistent navigations and object groundings.
- Potential tool/product/workflow: “Spatial Gen Engine” SDK for app developers with APIs for text/pose conditioning, long-context attention, and SD-based validation.
- Assumptions/dependencies: Advances in context compression, efficient long-horizon attention, and robust non-contiguous RoPE; cost-effective inference.
- Bold: Standards for dataset curation via VLMs
- Sector: academia, industry consortia
- What it does: Shared protocols for using VLMs to produce object-centric clips and instructions, reducing manual labeling and enabling reproducible visuospatial benchmarks.
- Potential tool/product/workflow: “Visuospatial Benchmark Kit” with prompts, quality filters, and auditing tools to minimize dataset bias and label noise.
- Assumptions/dependencies: VLM quality and bias control; domain-diverse video sources; governance for data privacy.
Notes on cross-cutting assumptions and dependencies
- The model’s strongest performance is currently on indoor scenes; outdoor and highly dynamic environments require further training and robustness work.
- High-quality results depend on providing sufficiently diverse and overlapping context frames; non-contiguous sampling plus RoPE indexing helps extrapolate to longer contexts.
- Joint classifier-free guidance over both context and instruction is crucial for spatial coherence and instruction adherence; auxiliary bounding boxes act as explicit visual “reasoning traces” that improve grounding.
- Evaluation and safety: Use Spatial Distance (SD) and SD-thresholded Instruction Following (IF) to guard against out-of-context hallucinations; include human review for safety-critical applications.
- Compute and integration: Today’s resolutions are modest; production use may need upscaling or future context-compressed backbones for high-res outputs.
Glossary
- 6-DoF: Six degrees of freedom describing 3D pose (3D translation and 3D rotation). "Given a context video and a sequence of egocentric 6-DoF pose waypoints ( in meters; as yaw–pitch–roll in radians)"
- AnySplat: A 3D reconstruction and rendering method that builds scene representations from images. "AnySplat~\cite{jiang2025anysplat}"
- Autoregressive video generation: Video synthesis that generates frames sequentially, conditioning each on previously produced frames. "and autoregressive video generation~\cite{huang2025self, zhang2025packing}"
- Auxiliary bounding box (bbox): An added, explicit visual marker used during training to help the model localize target objects. "we annotate and augment the training videos at the end with a red bounding box (bbox) centered at the target object"
- Chamfer distance: A geometric distance between point sets, often used to compare reconstructed 3D shapes. "We calculate the maximum per-frame one-sided Chamfer distance of $\mathcal{P}^{\text{gen}$ to the ground-truth point cloud $\mathcal{P}^{\text{gt}$"
- Classifier-Free Guidance (CFG): A sampling technique for diffusion models that strengthens conditional generation by mixing conditional and unconditional scores. "Classifier‑free guidance~\cite{ho2022classifier} improves conditional sampling"
- DiT: Diffusion Transformer; a transformer-based diffusion architecture for image/video generation. "In line with DiT~\cite{peebles2023scalable}, we process context and target frames through the same transformer stack"
- Dynamic Degree (DD): A VBench metric assessing motion dynamics and temporal characteristics of videos. "Imaging Quality (IQ) and Dynamic Degree (DD) evaluate overall video quality."
- Egocentric: Viewpoint defined relative to the camera’s own position and orientation, as in first-person navigation. "Given a context video and a sequence of egocentric 6-DoF pose waypoints"
- Flow‑matching objective: A training objective aligning model predictions with probability flow, used as an alternative to score matching. "We fine‑tune the attention layers of video generation model Wan2.2~\cite{wan2025wan} with a flow‑matching objective~\cite{lipman2022flow}."
- History Guidance: Conditioning strategy that leverages prior frames as guidance during video generation. "Inspired by History Guidance~\cite{song2025history}, we extend classifier‑free guidance to video context"
- Latent diffusion: A diffusion approach operating in a compressed latent space for efficient high-fidelity generation. "VDMs~\cite{ho2022video} produce high-fidelity, temporally consistent videos, benefiting from transformer backbones~\cite{vaswani2017attention,peebles2023scalable} and latent diffusion~\cite{rombach2022high}."
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual metric that compares visual similarity of images/videos. "we report PSNR, LPIPS and IQ"
- Non‑contiguous context sampling: Selecting context frames sparsely (not adjacent) to reduce redundancy and improve long-range understanding. "we train by sampling non‑contiguous context frames from source videos."
- Novel view synthesis: Generating images/video from new camera viewpoints of a scene. "While related to novel view synthesis, we focus on navigation via continuous video generation"
- Out‑of‑domain (OOD): Data or scenarios that differ from the training distribution. "Out-of-domain result."
- Plücker coordinates: A representation of lines (and camera rays) in projective 3D geometry used to encode poses. "camera poses encoded with Plücker coordinates~\cite{sitzmann2021light}"
- Point cloud: A set of 3D points representing scene geometry. "We use generated frames (a) to reconstruct the point cloud (b), which is compared with the GT point cloud (c)"
- PSNR: Peak Signal-to-Noise Ratio; a fidelity metric indicating how closely generated frames match ground truth. "we report PSNR, LPIPS and IQ"
- Rotary Positional Embeddings (RoPE): A positional encoding technique that enables attention over relative spatial–temporal offsets. "we apply non‑contiguous RoPE over the corresponding subsampled indices."
- Spatial Distance (SD): A proposed metric measuring geometric consistency by comparing generated and ground-truth point clouds. "Spatial Distance (SD) measures whether the generated scene is contained in the ground-truth(GT) point cloud"
- VAE (Variational Autoencoder): A generative model that encodes inputs into a latent distribution and decodes samples back to data space. "Context frames are randomly drawn but always in contiguous groups of four to satisfy the Wan2.2~\cite{wan2025wan} VAE encoder."
- VBench: A benchmarking suite for video generation quality and dynamics. "Additionally, we report VBench Imaging Quality (IQ) and Dynamic Degree (DD)~\cite{huang2024vbench}"
- VDMs (Video Diffusion Models): Diffusion models specialized for video, generating temporally coherent sequences. "VDMs~\cite{ho2022video} produce high-fidelity, temporally consistent videos"
- VGGT: A visual geometry model used to estimate camera poses and reconstruct 3D from video frames. "We use VGGT~\cite{wang2025vggt} to reconstruct a point cloud"
- Vision‑LLM (VLM): A model that processes and reasons over both visual and textual inputs. "We use an off-the-shelf vision-LLM (VLM)~\cite{qwen3vl}"
- Visuospatial intelligence (VSI): The ability to perceive, represent, and reason about spatial relationships from visual input. "Visuospatial Intelligence (VSI) ~\cite{yang2025thinking} is the ability to perceive~\cite{wang2025vggt,wang2024dust3r}, represent~\cite{mildenhall2021nerf,kerbl20233d}, and act~\cite{chen2025gleam,wei2025streamvln,anderson2018vision} spatially from visual input."
- Yaw–pitch–roll: The three rotational angles defining orientation in 3D (around vertical, lateral, and longitudinal axes). "( as yaw–pitch–roll in radians)"
Collections
Sign up for free to add this paper to one or more collections.