- The paper introduces TaYS, a streaming chain-of-thought framework for LVLMs that synchronizes reasoning with real-time visual input to enhance temporal alignment.
- It employs innovations such as streaming attention masks, decoupled positional encoding, and parallel dual KV-cache to reduce latency and improve accuracy.
- Empirical results demonstrate up to +2.9% accuracy gains, near-zero TTFT, and 55% reduction in temporal deviation, paving the way for scalable real-time multimodal reasoning.
Streaming Chain-of-Thought Reasoning for LVLMs: The Think-as-You-See (TaYS) Framework
Motivation and Paradigm Shift
Conventional video reasoning with Large Vision-LLMs (LVLMs) predominantly relies on batch inference—waiting for the complete video input before initiating reasoning. This architecture, although tractable for post-hoc analysis, induces substantial latency and exacerbates temporal drift, as reasoning steps become increasingly desynchronized from visual events across extended sequences. More critically, in real-time domains such as surveillance and robotics teleoperation, the static batch paradigm is fundamentally misaligned with the streaming nature of input data.
The TaYS framework addresses this inefficacy by redefining video reasoning as a streaming process: inference proceeds incrementally, tightly synchronized with the ongoing visual stream. Reasoning evolves concurrently with perception, enabling models to reactively interpret and update knowledge as new frames arrive.
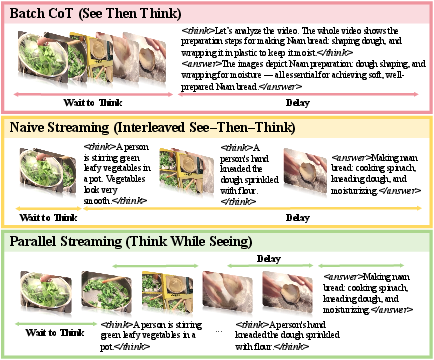
Figure 1: Conventional LVLM reasoning (batch paradigm) versus proposed streaming thinking, highlighting latency and attention misalignment.
Streaming Video Chain-of-Thought Generation
A core requirement for streaming reasoning is precise temporal alignment between frames and their corresponding reasoning steps. The TaYS data pipeline resamples videos at 2 FPS, retaining annotated keyframes as semantic anchors. Each keyframe is mapped to reasoning sentences, visual evidence descriptors, and temporally grounded QA pairs, producing structured reasoning trajectories suitable for supervised fine-tuning. Key quality controls include semantic relevance (embedding similarity thresholds) and temporal distinctiveness (anti-redundancy filtering), ensuring high-fidelity frame-level reasoning streams.
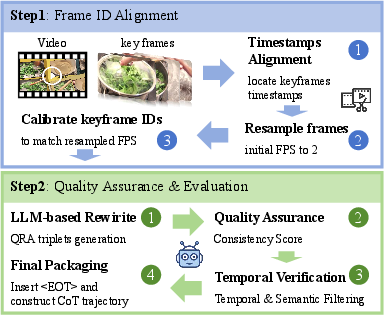
Figure 2: Two-step process for generating Streaming Video CoT: frame ID alignment and progressive trajectory construction.
Streaming Reasoning Architecture
Naive Interleaving vs. Parallel Streaming
The naive streaming baseline interleaves frame input and reasoning generation in a strict alternation. All tokens share a causal attention mask, resulting in serialized dependencies: perception cannot proceed until reasoning completes, and vice versa. This design introduces computational bottlenecks and deviates from LVLM pretraining distributions, impeding scalability in dynamic scenarios.
TaYS overcomes these constraints via three architectural innovations:
- Streaming Attention Mask: Enforces strict temporal causality such that reasoning at time t attends only to frames up to t, precluding access to future visual tokens and eliminating information leakage.
- Decoupled Positional Encoding: Assigns independent positional axes to vision and reasoning tokens, preventing dynamic index collisions and preserving semantic consistency across expanding sequences.
- Parallel Dual KV-Cache: Maintains modality-specific caches, allowing asynchronous visual encoding and textual token generation. The visual cache is appended non-blockingly as frames arrive, while the text cache is updated during autoregressive reasoning. At inference, logical pointer-level merges and splits enable concurrent cache management without redundant computation or memory overhead.
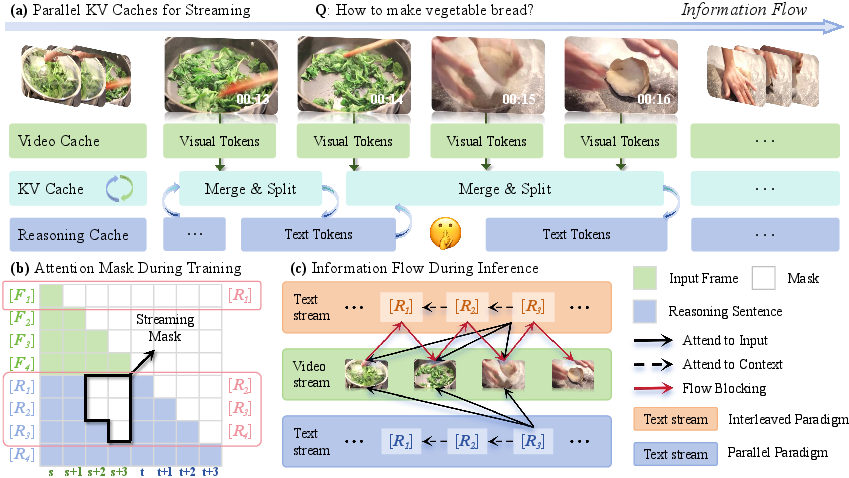
Figure 3: Overview of streaming reasoning in TaYS: parallel KV caches, attention masking, and reduced sequential blocking.
Numerical Results and Analysis
Reasoning Accuracy and Latency
TaYS is instantiated with Qwen2.5-VL-3B/7B-Instruct, evaluated on the extended VideoEspresso benchmark with diverse tasks (event dynamics, causal analysis, cooking, traffic). Compared to batch and naive interleaved baselines, TaYS provides:
- +2.9% improvement in reasoning accuracy.
- TTFT reduction from 10.6s (batch) to near-zero.
- Reasoning-event deviation (temporal grounding) decreased by 55%—from 1.52s to 0.69s.
Subjective evaluations (GPT-5) further confirm enhanced logical consistency and contextual appropriateness, with a normalized win rate of 43.7%, outperforming batch (31.4%) and interleaved (21.7%) models. TaYS excelled on temporally dependent tasks (Cooking and Preparation Steps), maintaining tight synchronization between reasoning and visual evidence.

Figure 4: Case study—TaYS aligns reasoning steps closely with visual events; interleaved baseline produces fragmented, less accurate outputs.
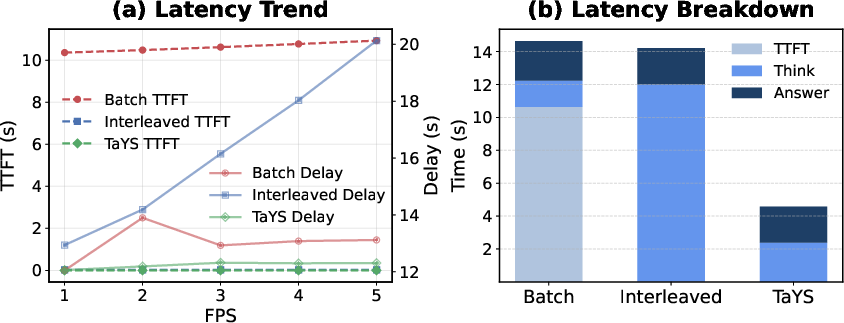
Figure 5: TaYS yields lowest TTFT and stable overall delay across frame rates due to parallel cache architecture.
Temporal Precision and Coherence
TaYS achieves superior fine-grained event sensitivity: 86.0% of reasoning steps fall within one second of keyframes. Semantic continuity between consecutive reasoning outputs is evident, avoiding redundant high-similarity peaks and ensuring sustained reasoning distinctiveness as the stream evolves.
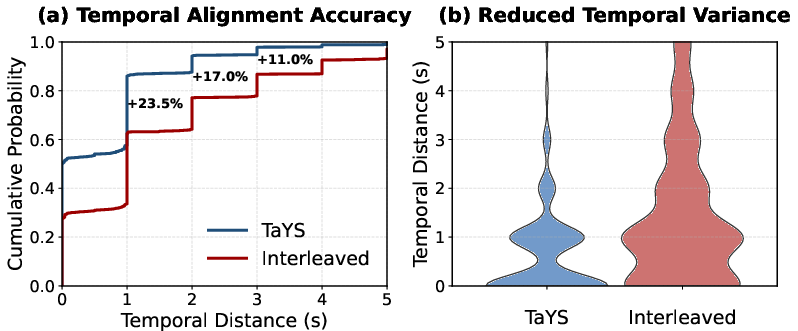
Figure 6: Temporal distance distribution—TaYS closely aligns reasoning with annotated event boundaries.
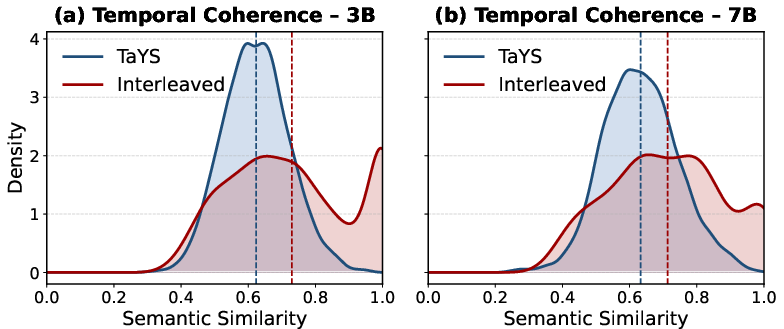
Figure 7: Semantic similarity between reasoning steps—TaYS maintains smoother, progressive transitions; interleaved baseline exhibits redundancies.
Practical and Theoretical Implications
The TaYS paradigm fundamentally improves responsiveness and temporal grounding in multimodal reasoning. Parallel cache design enables scalable real-time applications in open-world, embodied AI, and agentic interaction settings. The decoupled modality management opens avenues for future research on memory compression, adaptive attention modulation, and streaming multi-modal instruction tuning, with broad applicability to long-context and online learning protocols.
On the theoretical front, TaYS resolves the historical trade-off in LVLMs between post-hoc interpretability and real-time decision-making, paving the way for architectures that can simultaneously sustain depth and reactivity. The principles demonstrated by streaming attention, position encoding, and KV-cache design are extensible to broader online reasoning problems, including audio, spatial, and multi-agent streams.
Conclusion
TaYS establishes a general framework for streaming Chain-of-Thought reasoning in LVLMs, harmonizing perception and cognition via causal masking, positional decoupling, and parallel cache management. Extensive empirical evaluation validates its superiority over batch and interleaved paradigms in reasoning accuracy, latency, and temporal coherence. TaYS provides the architectural foundation for real-time, temporally grounded multimodal intelligence, driving future advances in open-world and embodied AI scenarios (2603.02872).