Enhancing Spatial Understanding in Image Generation via Reward Modeling
Abstract: Recent progress in text-to-image generation has greatly advanced visual fidelity and creativity, but it has also imposed higher demands on prompt complexity-particularly in encoding intricate spatial relationships. In such cases, achieving satisfactory results often requires multiple sampling attempts. To address this challenge, we introduce a novel method that strengthens the spatial understanding of current image generation models. We first construct the SpatialReward-Dataset with over 80k preference pairs. Building on this dataset, we build SpatialScore, a reward model designed to evaluate the accuracy of spatial relationships in text-to-image generation, achieving performance that even surpasses leading proprietary models on spatial evaluation. We further demonstrate that this reward model effectively enables online reinforcement learning for the complex spatial generation. Extensive experiments across multiple benchmarks show that our specialized reward model yields significant and consistent gains in spatial understanding for image generation.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Enhancing Spatial Understanding in Image Generation via Reward Modeling — Explained Simply
What’s this paper about? (Big idea)
This paper is about teaching image-making AI to better understand “where things are” in a picture when you describe a scene with words. For example, if you say, “a cat sitting under a blue table to the left of a window,” the AI should get the positions right. The authors build a special “judge” (called a reward model) that scores how well a generated image matches the spatial relationships in the text, and then they use that judge to train image generators to improve.
1) Brief overview
Modern text-to-image AIs are great at making pretty pictures, but they often mess up spatial details—like mixing up left and right, or putting objects in the wrong place. This paper creates:
- a new dataset of human-checked examples focused on spatial relationships, and
- a new “reward model” (called SpatialScore) that can accurately judge whether an image matches the spatial details in the text.
Then, they use this judge to train an image generator with reinforcement learning (a training style where the model gets “points” for doing well), making it much better at following complex spatial instructions.
2) What questions were they trying to answer?
The researchers focused on three simple questions:
- Can we build a reliable judge that really understands spatial relationships in images and text?
- If we use this judge to give feedback, will image generators learn to place objects correctly in complex scenes (especially with long, detailed prompts)?
- Can this approach work better than current methods that either rely on simple rules or expensive commercial AI services?
3) How did they do it? (Methods in everyday terms)
Think of this training like teaching a student (the image generator) with a very strict but fair teacher (the reward model). Here’s how they set it up:
- Step 1: Build a special dataset (SpatialReward-Dataset)
- They wrote many detailed prompts that describe scenes with multiple objects and precise positions (e.g., “a red ball on the left, a blue cube on the right, the cube in front of a chair”).
- They then made “perturbed” versions of those prompts by changing some spatial relationships (e.g., swapping left/right).
- For each pair (original vs. perturbed), they generated two images—one that should be correct and one that should be wrong.
- Human reviewers carefully checked each pair to make sure the “correct” image really matched the original prompt and the “wrong” one didn’t.
- Result: over 80,000 high-quality “preference pairs” (correct vs. incorrect) focused on spatial understanding.
- Step 2: Train the judge (SpatialScore)
- They started with a vision-LLM (a type of AI that looks at images and reads text together) and retrained it to output a single score: “How well does this image follow the spatial instructions?”
- They trained it using the preference pairs: the judge learns to score the correct image higher than the incorrect one for the same prompt.
- To make the judge stable and less noisy, they modeled the score like a bell curve (a simple statistical trick) and optimized it to be a strong ranker.
- Step 3: Use the judge to improve an image generator with reinforcement learning
- The image generator (they used a strong model called FLUX.1-dev) creates several images for each prompt.
- The judge (SpatialScore) scores each image.
- The training gives “credit” to better images and “penalizes” worse ones—like giving gold stars to the most accurate and taking away points from the least accurate.
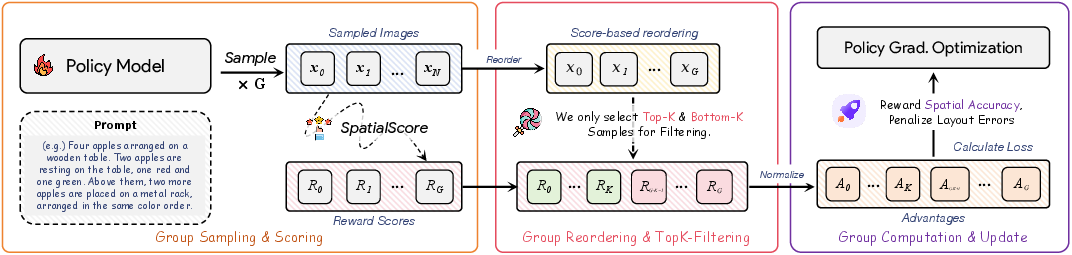
- They also added a helpful trick called top‑k filtering: instead of using all images in a batch, they train on the best few and the worst few. This reduces bias when a prompt is too easy (where almost everything is good) or too hard (where almost everything is bad), and it saves compute time.
In short: they built a tough judge for spatial accuracy and used it to coach the image model to place objects correctly.
4) What did they find, and why is it important?
- The judge (SpatialScore) is very accurate:
- On a special test set, SpatialScore beat many existing open-source models and even outperformed some top paid services at telling which image matches the spatial instructions better.
- This matters because a good judge is essential for training: if feedback is wrong or shaky, the student model won’t improve.
- The image generator got much better at spatial tasks:
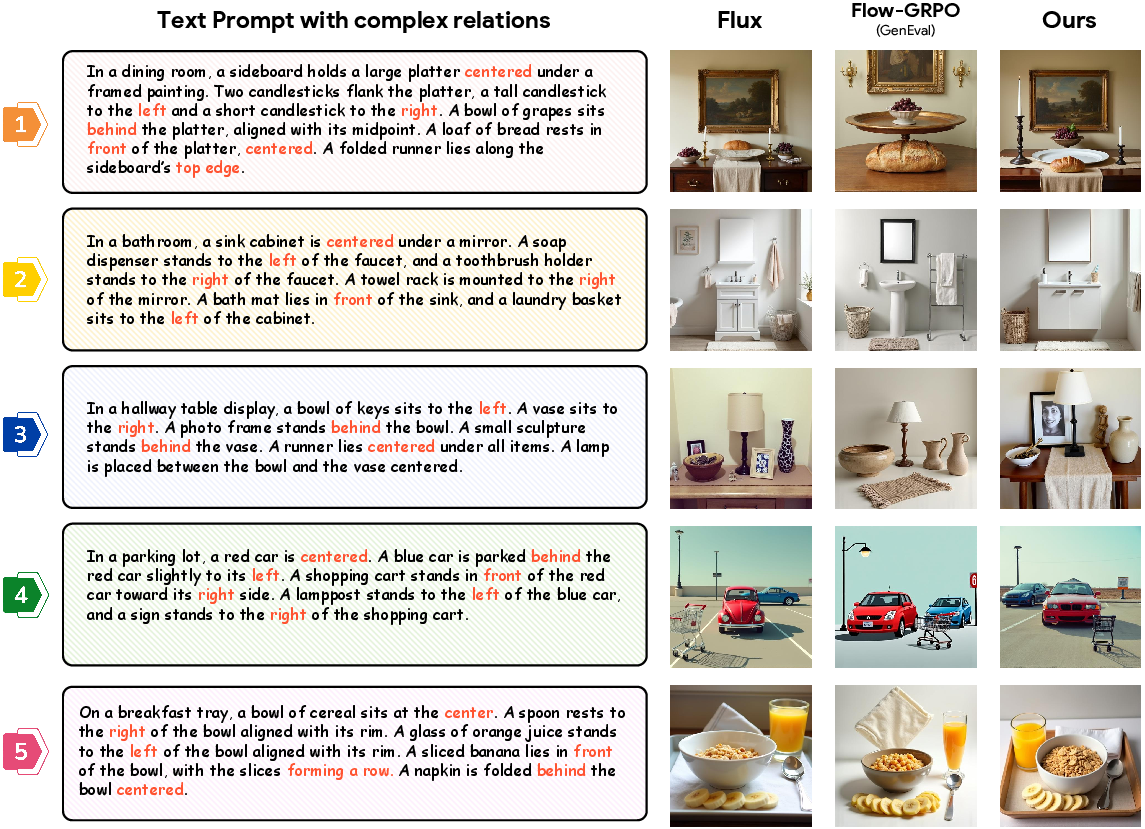
- After training with SpatialScore, the model made images that matched complex prompts more reliably—especially when prompts were long and involved many objects and relationships.
- It performed better across several benchmarks that measure spatial understanding and text–image alignment (such as DPG-Bench, TIIF-Bench, and UniGenBench++).
- Compared to methods that use simple rule-based checks (like detecting objects and comparing positions), this approach generalized better and didn’t break when scenes were complicated or objects were partly hidden.
- The training trick (top‑k filtering) helped:
- It made training more stable, less biased by “too easy” or “too hard” prompts, and reduced the number of model evaluations needed.
Why this is important:
- You get images that actually follow your instructions—fewer retries, less frustration.
- It brings us closer to reliable, controllable image generation for real-world uses (design, education, storytelling, games).
5) What’s the impact? (So what?)
- Better tools for creators: Artists, teachers, and game developers can describe complex scenes and expect the AI to place things where they belong.
- More reliable AI: This paper shows that specialized judges (reward models) can make AI follow rules more consistently—not just be “pretty,” but be correct.
- More affordable training: Since the judge is open and efficient, it avoids the high costs of repeatedly using commercial AI APIs for feedback.
- Future directions: The same idea could be extended to even trickier tasks—like 3D layouts, videos (spatial + time), or physics-aware scenes (“the cup is on the table, not floating”).
In one sentence
The authors built a high-quality “spatial judge” and used it to coach image-making AI so it stops mixing up where things should go, making it far better at following detailed, multi-object descriptions.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, written to be concrete and actionable for future research.
- Dataset provenance and bias: The SpatialReward-Dataset is built using GPT-5 for prompt generation/perturbation and images from specific generators (Qwen-Image, HunyuanImage, Seedream). How much do model-specific artifacts or GPT-generated prompt styles bias SpatialScore, and does the reward model generalize to images and prompts from other, diverse sources (including human-authored prompts)?
- Annotation rigor: The paper states “careful human review” but provides no inter-annotator agreement, annotation protocol details, or error taxonomy. Future work should quantify annotator consistency, systematic error rates, and provide a formal guideline for adjudicating spatial relations (especially under occlusion and perspective).
- Dataset coverage: The dataset’s coverage of spatial phenomena (e.g., occlusion, perspective, camera viewpoint changes, scale differences, 2D vs. 3D prepositions, topological relations, symmetry, nested containment, multi-hop spatial chains) is not characterized. A detailed distributional analysis and targeted stress tests are needed.
- Multilingual generalization: Prompts appear to be English-only. It is unknown whether SpatialScore and RL gains extend to multilingual prompts, culturally specific object layouts, or non-Latin scripts.
- Real-user prompt generalization: The dataset relies on GPT-generated prompts; the paper does not evaluate on prompts collected from real users (noisy, incomplete, or colloquial spatial descriptions). Testing on organic, real-world prompt distributions is needed.
- Out-of-domain reward robustness: SpatialScore is evaluated on a small, in-house benchmark of 365 pairs constructed similarly to the training data. Broader, third-party spatial-reasoning benchmarks (with held-out generators and prompt styles) are required to verify true out-of-domain generalization and avoid distribution coupling.
- Reward uncertainty usage: SpatialScore models reward as a Gaussian with mean and variance, but the training and RL procedures appear to use only point estimates in Bradley–Terry and advantage computation. How can the model’s uncertainty (sigma) be explicitly incorporated for risk-aware policy updates, robust normalization, or active sampling?
- Reward calibration and scale: The numeric calibration of SpatialScore across different prompt complexities and image domains is unexplored. How should rewards be normalized across prompts to prevent advantage bias without discarding “middle” samples (e.g., via per-prompt baselines, quantile normalization, or difficulty-aware scaling)?
- Reward hacking risk: The generator may learn to exploit systematic weaknesses in SpatialScore (e.g., superficial textual cues, frequent composition templates, specific arrangements favored by the VLM backbone). No red-teaming or adversarial analysis shows whether RL-trained models “game” the reward without truly improving spatial correctness.
- Occlusion and viewpoint robustness: Although the paper critiques GenEval’s sensitivity to occlusion, it does not quantify SpatialScore’s robustness under occluded objects, partial visibility, clutter, or viewpoint changes. Controlled occlusion/viewpoint experiments are missing.
- 3D reasoning limits: The paper evaluates “Layout-3D” using 2D images but does not clarify how depth relationships are inferred. Without explicit depth signals, a systematic evaluation of 3D prepositions (in front of/behind, closer/farther, above/below with perspective) is needed, potentially with synthetic scenes that encode ground-truth geometry.
- Counting and numeracy: Many spatial instructions implicitly involve counting and disambiguation (e.g., “the third cup from the left”). The paper does not analyze failures or gains on precise counting intertwined with spatial relations.
- Transfer across base generators: SpatialScore is trained on data from specific T2I models and used to RL-tune FLUX.1-dev only. It remains unclear whether SpatialScore reliably drives RL for other generators (e.g., SDXL, Playground, DALL·E-like models) or whether gains depend on FLUX’s architecture.
- Trade-offs with other qualities: The paper reports spatial improvements but does not quantify trade-offs with aesthetics, style fidelity, diversity, photorealism, and artifact rates (e.g., floating objects). Comprehensive multi-metric evaluation (FID/KID, CLIP-score, aesthetic scores, diversity metrics) is missing.
- Hyperparameter sensitivity: GRPO training uses fixed group size, KL penalty, noise schedule, and LoRA rank. There is no exploration of how these choices affect stability, sample efficiency, or overfitting, especially with the proposed top-k filtering.
- Top-k filtering design: The top-k strategy is static and only ablated at k=4/6. Adaptive k, difficulty-aware sampling, or alternative normalization (e.g., per-prompt baselines or robust z-scoring) may better address advantage bias while preserving sample diversity; these options remain unexplored.
- SDE noise schedule effects: The conversion from ODE to SDE introduces noise (σ_t), but the schedule and its impact on image fidelity and exploration efficiency are not studied. How do different noise schedules and discretization steps affect spatial learning and visual quality?
- RL vs. supervised alternatives: The paper does not compare against non-RL baselines such as supervised fine-tuning on spatially annotated data, DPO/DPG-based methods with SpatialScore as a judge, or offline RL. It is unclear whether online RL is necessary or optimal for spatial improvements.
- Evaluation judge reliability: Out-of-domain evaluations rely on proprietary judges (GPT-4o, Gemini) whose spatial reasoning reliability varies across prompts. Cross-judge agreement, judge calibration, and sensitivity analyses are missing.
- Benchmark breadth and size: The in-house reward evaluation (365 pairs) is small and potentially coupled to training distributions. Larger, community-accepted spatial benchmarks, with transparent protocols and diverse generators, are needed for credible claims of surpassing proprietary models.
- Failure case taxonomy: The paper lacks a systematic analysis of SpatialScore’s and RL-tuned generator’s failure types (e.g., directional confusion, near/far ambiguity, relative order mistakes, nested containment errors), which would guide targeted improvements.
- Computational cost and accessibility: RL training uses 32 H20 GPUs; per-query latency and cost of SpatialScore (7B VLM backbone) are not reported. Practical pathways for lower-resource labs (e.g., distilled or quantized reward models, batch evaluation) are not provided.
- Reproducibility and release: It is unclear whether the SpatialReward-Dataset, prompts, code, and reward model checkpoints will be released with licenses that permit broad use. Without release and detailed documentation, replication and community benchmarking are constrained.
- Ethical and safety considerations: The work does not discuss safety implications (e.g., biased spatial depictions involving people or environments) or potential misuse (e.g., reward hacking to produce deceptive images), nor propose guardrails or audits.
- Compositional generalization beyond spatial: While some gains are shown in attribute+relation and relation+reasoning, the approach focuses on spatial relations. Extending the reward design to broader compositional reasoning (temporal order, causality, logical quantifiers) is left open.
- Robustness to image transformations: Sensitivity of SpatialScore to benign transformations (cropping, resizing, color shifts, compression artifacts) is not tested. Such robustness is important if rewards are to be reliable under typical generation post-processing.
- Active data acquisition: The dataset is static; strategies for active or adversarial data collection (e.g., hard-negative mining driven by current reward failures) to continually improve SpatialScore are not explored.
- Uncertainty-aware RL: The model outputs a variance, but RL ignores it. Methods that integrate reward uncertainty (e.g., risk-sensitive objectives, Thompson sampling for exploration) could stabilize training and reduce overfitting; this remains an open direction.
Practical Applications
Immediate Applications
Below are concrete ways the paper’s findings, methods, and tools can be deployed today. Each item notes sectors, potential tools/products/workflows, and feasibility assumptions.
- Bold reranking and QA gate for image generation pipelines
- Sectors: software, advertising/marketing, e-commerce, media
- Tool/Product/Workflow: use SpatialScore as a “spatial-accuracy scorer” to rerank N sampled images per prompt; insert a pass/fail QA gate that filters outputs violating relative positions (e.g., “A left of B”).
- Assumptions/Dependencies: access to SpatialScore weights or API; inference compute for scoring batches; base T2I model supports long prompts (e.g., FLUX.1-dev or SDXL).
- Bold enterprise content compliance checker for layouts
- Sectors: publishing, advertising, retail, finance (report graphics), education (worksheets)
- Tool/Product/Workflow: automated check that generated thumbnails, flyers, or infographics respect specified object placements (e.g., logo upper-right, disclaimer below chart).
- Assumptions/Dependencies: accurate prompt formalization of layout rules; integration with creative asset management (DAM) pipelines.
- Bold prompt authoring assistant with spatial validation
- Sectors: software tooling, education
- Tool/Product/Workflow: IDE-like assistant that previews multiple candidates and flags likely spatial ambiguities; suggests prompt edits (e.g., add disambiguating prepositions) based on low SpatialScore.
- Assumptions/Dependencies: UI integration; prompt rewriting heuristics; low-latency scoring.
- Bold vendor benchmarking and procurement audits
- Sectors: policy/regulation, enterprise IT procurement, standards bodies
- Tool/Product/Workflow: add SpatialScore, DPG-Bench spatial subset, TIIF/UniGenBench++ spatial sub-metrics to RFP test suites for generative services; require minimum spatial adherence thresholds.
- Assumptions/Dependencies: public availability of the reward model/benchmarks; reproducible evaluation harnesses.
- Bold synthetic dataset QA for computer vision
- Sectors: robotics, autonomous systems, retail analytics, CV research
- Tool/Product/Workflow: when generating synthetic scenes for detection/relational reasoning, use SpatialScore to accept only scenes that satisfy target relations (reduces label noise).
- Assumptions/Dependencies: domain-appropriate prompts; coverage of relevant object taxonomies; acceptable domain shift between synthetic and downstream tasks.
- Bold storyboard and previsualization verifier
- Sectors: film/TV, animation, game studios
- Tool/Product/Workflow: validate multi-object blocking (“actor left of prop; camera behind table”) during storyboard generation; auto-rerank panels by spatial correctness.
- Assumptions/Dependencies: robust parsing of scene directions into prompts; batch scoring workflow.
- Bold e-commerce product scene generator with positional guarantees
- Sectors: retail/e-commerce, marketplace platforms
- Tool/Product/Workflow: generate product shots with consistent placements (e.g., accessory to the right of model; scale ratios preserved) using reward-weighted sampling + reranking.
- Assumptions/Dependencies: accurate object detectors for SKUs (optional); prompt templates; brand compliance rules encoded in text.
- Bold AR try-on and interior mockup sanity checks
- Sectors: fashion, furniture/interior design, home improvement
- Tool/Product/Workflow: verify that overlays (e.g., lamp above nightstand; sofa under window) respect relationships before presenting to users; auto-regenerate failures.
- Assumptions/Dependencies: consistent camera/model coordinate prompts; latency budgets for mobile apps.
- Bold game level/blockout generation with relation tests
- Sectors: gaming
- Tool/Product/Workflow: procedural 2D/3D blockouts with “door right of corridor; key behind statue”; discard or penalize spatially invalid generations using SpatialScore in-the-loop.
- Assumptions/Dependencies: mapping from level grammar to textual relations; sufficient sample diversity.
- Bold educational content generator for spatial reasoning
- Sectors: education (K–12, language learning)
- Tool/Product/Workflow: automatically create worksheets and illustrations that accurately depict prepositions and spatial relations; flag misaligned images for teacher review.
- Assumptions/Dependencies: curated prompt banks; human-in-the-loop for final approval.
- Bold “model-as-a-judge” for regression tests of T2I releases
- Sectors: software/ML ops
- Tool/Product/Workflow: add SpatialScore-based unit tests to CI/CD for T2I models; fail builds when spatial adherence regresses on a fixed prompt suite.
- Assumptions/Dependencies: governance to manage Goodhart’s risk (monitor for overfitting to the judge); store prompt seeds and baselines.
- Bold lightweight RLFT pilot with top-k filtering
- Sectors: software/ML research groups, T2I vendors
- Tool/Product/Workflow: LoRA-based online RL runs (GRPO + SpatialScore + top-k) to customize a base T2I model for enterprise spatial needs; short sprints to assess uplift.
- Assumptions/Dependencies: multi-GPU training capacity; reward model availability; KL regularization to avoid style drift; curated prompt sets.
Long-Term Applications
These opportunities require further research, scaling, or productization to be production-ready.
- Bold production-grade RLFT for spatially reliable T2I services
- Sectors: creative SaaS, cloud AI providers
- Tool/Product/Workflow: train foundation image models with SpatialScore-guided online RL at scale to deliver single-shot spatial adherence on long, multi-relation prompts.
- Assumptions/Dependencies: efficient reward batching; robust anti-Goodhart evaluations; cost-optimized training; periodic human audits.
- Bold spatially consistent text-to-video and 3D scene generation
- Sectors: media/entertainment, simulation, AR/VR
- Tool/Product/Workflow: extend reward modeling to temporal and 3D consistency (object retains relative positions across frames/views); scene-graph to video/image pipelines with reward shaping.
- Assumptions/Dependencies: new datasets with temporal/3D spatial preferences; reward models that reason over sequences/multi-view inputs.
- Bold robotics and autonomy sim2real curricula
- Sectors: robotics, autonomous driving, warehouse logistics
- Tool/Product/Workflow: generate photorealistic training scenes with controlled spatial relations (e.g., “pallet behind forklift; pedestrian left of crosswalk”), validated by SpatialScore-like judges to train relation-sensitive policies or perception.
- Assumptions/Dependencies: domain adaptation to robot sensors; coupling with physics engines; safety validation for sim2real gaps.
- Bold CAD/scene-graph–aware generative design
- Sectors: architecture, industrial design, retail planograms
- Tool/Product/Workflow: integrate constraint solvers or CAD scene graphs with reward-guided generation to produce images consistent with architectural/layout constraints.
- Assumptions/Dependencies: interfaces between CAD constraints and text prompts; bi-directional mapping (image → constraints) for iterative refinement.
- Bold interactive layout designer with real-time reward feedback
- Sectors: marketing, publishing, UI/UX
- Tool/Product/Workflow: WYSIWYG tool where designers set relational constraints; generator proposes variations while the reward model continuously scores and improves layouts.
- Assumptions/Dependencies: low-latency inference; incremental generation APIs; user-controllable constraint weighting.
- Bold regulatory and standards frameworks for generative spatial fidelity
- Sectors: policy, public sector procurement, safety-critical communications
- Tool/Product/Workflow: standardized spatial test suites and certification badges (e.g., “Spatial-Fidelity A”) for generative vendors; mandates for accurate spatial depictions in public safety or educational materials.
- Assumptions/Dependencies: community benchmarks; third-party audit infrastructure; documented limitations and bias assessments.
- Bold multimodal agents with grounded spatial reasoning
- Sectors: robotics, assistive tech, digital twins
- Tool/Product/Workflow: couple VLM planners with spatial reward critics to enforce correct relative placements when generating plans, instructions, or visualizations.
- Assumptions/Dependencies: joint training of planner and critic; interpretable constraint representations; safety layers.
- Bold medical and surgical training synthetic visuals (non-diagnostic)
- Sectors: healthcare education, medical device UX
- Tool/Product/Workflow: generate anatomically constrained training diagrams or OR layout visuals with enforced spatial relations (e.g., instrument placement relative to drapes).
- Assumptions/Dependencies: expert-curated prompts; strict non-diagnostic use; clinical oversight; domain-specific reward tuning.
- Bold urban planning and infrastructure visualization
- Sectors: civil engineering, energy/infrastructure planning
- Tool/Product/Workflow: produce proposal visuals honoring spatial constraints (e.g., “substation east of roadway, setback behind sound barrier”) with reward-guided verification.
- Assumptions/Dependencies: coupling with GIS/scene graphs; real-world coordinate grounding; public review workflows.
- Bold on-device or edge reward inference for interactive apps
- Sectors: mobile AR, design apps
- Tool/Product/Workflow: quantized SpatialScore variants for local scoring, enabling interactive spatial correction loops without cloud latency.
- Assumptions/Dependencies: model distillation/quantization; hardware acceleration; accuracy–latency trade-off studies.
- Bold generalized physical-consistency reward models
- Sectors: simulation, safety systems, education
- Tool/Product/Workflow: extend beyond spatial relations to physics (support, occlusion, gravity plausibility) and commonsense constraints; multi-attribute reward shaping during generation.
- Assumptions/Dependencies: new preference datasets; composite reward aggregation; careful balance to avoid suppressing creativity.
- Bold marketplaces for “spatially precise imagery”
- Sectors: stock media, enterprise content platforms
- Tool/Product/Workflow: curated libraries or generation services that guarantee spatial constraints (sold with constraint metadata), enabling downstream automation.
- Assumptions/Dependencies: enforceable SLAs backed by automated audits; clear constraint schemas; legal review of guarantees.
Cross-cutting assumptions, risks, and dependencies
- Model availability and licensing: practical deployment depends on releasing SpatialScore weights/dataset or a compatible reproduction; clarify permissible commercial use.
- Distribution shift: reward model was trained on complex textual prompts and SOTA generators; verify generalization to new domains (medical, industrial, satellite imagery) before high-stakes use.
- Goodhart’s law: prolonged RL against a single judge risks overfitting; mitigate with multi-judge ensembles, human audits, and out-of-domain tests.
- Compute and latency: online RL requires substantial GPU capacity; production reranking needs acceptable time budgets; consider batched scoring and caching.
- Safety and ethics: ensure generated scenes do not mislead in safety-critical contexts; add human-in-the-loop for regulated sectors; document known failure modes (occlusion, rare objects).
- Data and IP: confirm that prompts, images, and annotations comply with data usage policies; track provenance for audits.
Glossary
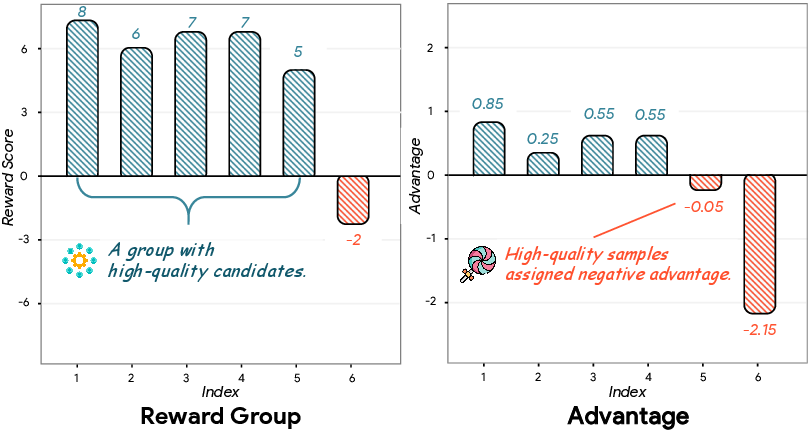
- Advantage bias: A systematic distortion in estimated advantages within a sampling group that can assign negative advantages to good samples due to high group means. "Advantage bias. For easy prompts with many high-reward samples, some high-quality samples often obtain negative advantages due to the high group mean."
- Adversarial preference pairs: Paired examples where one sample intentionally violates certain conditions to create a challenging contrast for preference learning. "We first introduce SpatialReward-Dataset, which contains 80K adversarial preference pairs spanning a wide range of real-world scenarios."
- Binary cross-entropy loss: A loss function for binary classification or preference modeling that penalizes the negative log-likelihood of correct outcomes. "by minimizing the negative log-likelihood of the ground-truth preference using a binary cross-entropy loss:"
- Bradley-Terry model: A probabilistic model for pairwise comparisons that estimates the probability one item is preferred over another. "The reward model is optimized following the Bradley-Terry model~\cite{bradley1952rank-Bradley-Terry} by minimizing the negative log-likelihood of the ground-truth preference using a binary cross-entropy loss:"
- Compositional generation: Generating images that correctly combine multiple attributes and relations among objects within a scene. "have also explored compositional generation on the rule-based GenEval benchmark~\cite{ghosh2023geneval}"
- Denoising step count: The number of iterative denoising steps used during sampling in diffusion/flow-based models. "NFE per prompt for each training step is reported under a denoising step count of 6."
- Direct Perference Optimization (DPO): A reinforcement learning approach optimizing models directly from preference signals rather than explicit rewards. "Direct Perference Optimization (DPO)~\cite{rafailov2023direct-dpo} originally developed for LLMs, have been successfully adapted to diffusion-based generation~\cite{jiang2025t2i,li2025science-t2i,zhu2025dspo,ren2024-dppo,xu2023imagereward}, improving task alignment and controllability."
- Euler–Maruyama scheme: A numerical method to discretize stochastic differential equations for simulation and sampling. "The resulting SDE can be discretized using the EulerâMaruyama scheme as follows:"
- Flow matching: A generative modeling approach where continuous-time flows are trained to match data distributions, typically resulting in deterministic ODE sampling. "However, flow matching inherently employs a deterministic ODE for sampling, whereas RL relies on stochasticity for policy exploration."
- Gaussian distribution: A normal distribution used to model uncertainty in predicted reward scores via mean and variance. "we adopt a Gaussian distribution to model the final reward score"
- Group Relative Policy Optimization (GRPO): A policy optimization method that leverages relative ranking within groups of samples for stable updates. "have integrated the flow model with Group Relative Policy Optimization (GRPO)~\cite{guo2025deepseek-r1}."
- Group-wise normalization: Normalizing rewards within a sample group by subtracting the group mean and dividing by the group standard deviation. "the group-wise normalization may yield a high mean value, which in turn assigns negative advantages to some high-quality samples"
- Hallucinations (in VLMs): Model outputs that assert incorrect or fabricated details not supported by the input. "even advanced models such as Qwen2.5-VL-72B~\cite{bai2025qwen2.5vl} suffer from substantial hallucinations and fail to provide reliable and accurate rewards"
- Importance clipping range: The clipping limits applied to importance ratios in PPO-style objectives to stabilize training. "an importance clipping range of "
- In-domain performance: Evaluation on data that match the training domain or the primary target setting. "we first employ our proposed reward model SpatialScore to assess in-domain performance in spatial reasoning."
- KL-divergence penalty: A regularization term that penalizes divergence between the current policy and a reference policy. "An additional KL-divergence penalty term $D_{\mathrm{KL}\!\left(\pi_{\theta}\,\|\,\pi_{\mathrm{ref}\right)$ is introduced to regularize the policy"
- Layout-2D/3D: Spatial arrangement evaluation metrics assessing two-dimensional and three-dimensional layout consistency. "Lay-2D/3D refer to layout-2D/3D."
- LoRA (Low-Rank Adaptation): A parameter-efficient fine-tuning technique that injects low-rank adapters into pretrained models. "To build our SpatialScore reward model, we fine-tune Qwen2.5-VL-7B using the LoRA~\cite{hu2022lora} to preserve the inherent knowledge priors of the model."
- Marginal distribution: The distribution of a subset of variables irrespective of others; used to ensure SDE matches ODE marginals. "we convert the deterministic ODE into an equivalent SDE that shares the same marginal distribution."
- Multilayer perceptron (MLP): A feedforward neural network with multiple layers used here as the reward projection head. "The final-layer embedding of this special token is then mapped to and through the reward head , implemented as a multilayer perceptron (MLP)."
- Number of function evaluations (NFE): A measure of computational cost counting how many model evaluations are needed during sampling or training. "Our GRPO optimization reduces the number of function evaluations (NFE) required for updating the policy"
- Object detectors: Models that identify and localize objects in images; here, used for rule-based reward calculation in benchmarks. "The rule-based GenEval rewards, which rely on object detectors, often produce incorrect evaluations under visual challenges like occlusion"
- Occlusion: A visual scenario where objects partially block each other, making detection or evaluation harder. "produce incorrect evaluations under visual challenges like occlusion"
- Online reinforcement learning (online RL): Reinforcement learning where the policy is updated continuously using feedback obtained during training. "We further demonstrate that this reward model effectively enables online reinforcement learning for the complex spatial generation."
- Ordinary differential equation (ODE): A deterministic differential equation used for continuous-time sampling in flow models. "They transform deterministic ordinary differential equation (ODE) sampling into stochastic differential equation (SDE)~\cite{song2020score-sde,albergo2023stochastic-sde-flow} to facilitate policy exploration."
- Out-of-domain benchmarks: Evaluation datasets that differ from the training distribution to assess generalization. "Beyond in-domain evaluation, we further adopt several out-of-domain benchmarks designed to measure textâimage alignment"
- Pairwise-accuracy: The proportion of correct choices in pairwise preference comparisons between two options. "Pairwise-accuracy comparisons on the reward evaluation benchmark."
- Policy exploration: The stochastic process of trying diverse actions or samples to discover better policies. "They transform deterministic ordinary differential equation (ODE) sampling into stochastic differential equation (SDE)~\cite{song2020score-sde,albergo2023stochastic-sde-flow} to facilitate policy exploration."
- Policy gradient optimization: A family of methods that optimize policies by following gradients of expected returns. "The policy model is updated via policy gradient optimization to directly reward correct spatial layouts and penalize errors"
- Preference learning: Learning from comparative judgments (preferences) rather than absolute scores to train models. "preference learning outperforms pointwise score regression for reward training"
- Preference pairs: Pairs of samples labeled by which one is preferred, used for training ranking-based reward models. "Please review the academic paper and generate an alphabetical list of all advanced domain-specific terms that might not be known to an undergraduate computer science student. "
- Proximal Policy Optimization (PPO): A widely used RL algorithm employing clipped objectives for stable policy updates. "Proximal Policy Optimization (PPO)~\cite{schulman2017proximal-policy-opt} and Direct Perference Optimization (DPO)~\cite{rafailov2023direct-dpo} ... have been successfully adapted to diffusion-based generation"
- Qwen2.5-VL-7B: A 7B-parameter vision-LLM used as the backbone for the SpatialScore reward model. "we use Qwen2.5-VL-7B~\cite{bai2025qwen2.5vl} as the backbone "
- Reference policy: A fixed or slowly updated policy used as a baseline to regularize the learning policy via KL penalties. "prevent excessive deviation from the reference policy $\pi_{\text{ref}$."
- Reward head: A projection module that maps joint image-text features to a scalar reward (or parameters of a reward distribution). "replacing the original language modeling head with a new linear reward head that projects the features to predict the reward value."
- Rule-based GenEval benchmark: A compositional evaluation suite that uses rules and detectors to compute rewards for spatial relations. "Recent works such as Flow-GRPO~\cite{liu2025flow-grpo} have also explored compositional generation on the rule-based GenEval benchmark~\cite{ghosh2023geneval}"
- Sigmoid function: A bounded activation mapping real numbers to [0, 1], used to turn score differences into probabilities. "Here, denotes the sigmoid function, which constrains the output to a probability value within the interval "
- Special token <reward>: A designated token appended to prompts so the model can output reward-related embeddings. "we insert a special token <reward> at the end of the full prompt"
- Spatial understanding: The capability to correctly interpret and generate complex spatial relations among multiple objects. "we introduce a novel method that strengthens the spatial understanding of current image generation models."
- Stochastic differential equation (SDE): A differential equation with stochastic terms enabling random sampling trajectories in generative models. "They transform deterministic ordinary differential equation (ODE) sampling into stochastic differential equation (SDE)~\cite{song2020score-sde,albergo2023stochastic-sde-flow} to facilitate policy exploration."
- Stochasticity: Randomness introduced into the sampling or policy to enable exploration and diversity. "whereas RL relies on stochasticity for policy exploration."
- SDE sampling: Generating samples via discretized stochastic differential equations. "the base model as the policy generates a group of images through SDE sampling."
- Text–image alignment: The degree to which a generated image matches the semantics of its textual prompt. "reward models~\cite{lin2024vqascore, hu2023tifa} designed for text-image alignment, which rely on VQA-style evaluations, exhibit the same limitation."
- Top- filtering strategy: Selecting the highest- and lowest-scored samples within a group to reduce bias and stabilize learning. "To mitigate advantage biases across prompts of varying difficulty, we propose a top- filtering strategy."
- Velocity field: The model’s predicted vector field guiding state evolution in continuous-time generative sampling. "and denotes the estimated velocity field."
- Vision-LLMs (VLMs): Models that jointly process visual and textual modalities for tasks like grounding and evaluation. "Visual LLMs (VLMs) have achieved remarkable progress and been widely applied to various visionâlanguage tasks"
- VQA-style evaluations: Evaluation methods modeled after Visual Question Answering, often used to assess image-text alignment. "reward models~\cite{lin2024vqascore, hu2023tifa} designed for text-image alignment, which rely on VQA-style evaluations, exhibit the same limitation."
- Zero-shot spatial understanding: The ability to correctly reason about spatial relations without task-specific fine-tuning. "which shows their strong zero-shot spatial understanding for image generation."
Collections
Sign up for free to add this paper to one or more collections.