Training-Free Group Relative Policy Optimization
Abstract: Recent advances in LLM agents have demonstrated their promising general capabilities. However, their performance in specialized real-world domains often degrades due to challenges in effectively integrating external tools and specific prompting strategies. While methods like agentic reinforcement learning have been proposed to address this, they typically rely on costly parameter updates, for example, through a process that uses Supervised Fine-Tuning (SFT) followed by a Reinforcement Learning (RL) phase with Group Relative Policy Optimization (GRPO) to alter the output distribution. However, we argue that LLMs can achieve a similar effect on the output distribution by learning experiential knowledge as a token prior, which is a far more lightweight approach that not only addresses practical data scarcity but also avoids the common issue of overfitting. To this end, we propose Training-Free Group Relative Policy Optimization (Training-Free GRPO), a cost-effective solution that enhances LLM agent performance without any parameter updates. Our method leverages the group relative semantic advantage instead of numerical ones within each group of rollouts, iteratively distilling high-quality experiential knowledge during multi-epoch learning on a minimal ground-truth data. Such knowledge serves as the learned token prior, which is seamlessly integrated during LLM API calls to guide model behavior. Experiments on mathematical reasoning and web searching tasks demonstrate that Training-Free GRPO, when applied to DeepSeek-V3.1-Terminus, significantly improves out-of-domain performance. With just a few dozen training samples, Training-Free GRPO outperforms fine-tuned small LLMs with marginal training data and cost.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
A simple explanation of “Training-Free Group Relative Policy Optimization”
What is this paper about?
This paper shows an easier, cheaper way to make big AI models (like chatbots) act smarter in specific real-world jobs (for example, doing hard math or searching the web). Instead of retraining the model (which is expensive and needs lots of data), the authors teach the model with a small “cheat sheet” of lessons learned from its own practice attempts. They call this method Training-Free GRPO.
What questions did the researchers ask?
- Can we improve a large AI model’s behavior without changing its internal settings (its “weights”)?
- Can we get the benefits of reinforcement learning (RL)—which usually needs heavy training—by using smart prompting and simple add-on notes instead?
- Will this work with very little data and low cost, and still perform well in different tasks?
How did they do it? (Methods in simple terms)
Imagine a classroom:
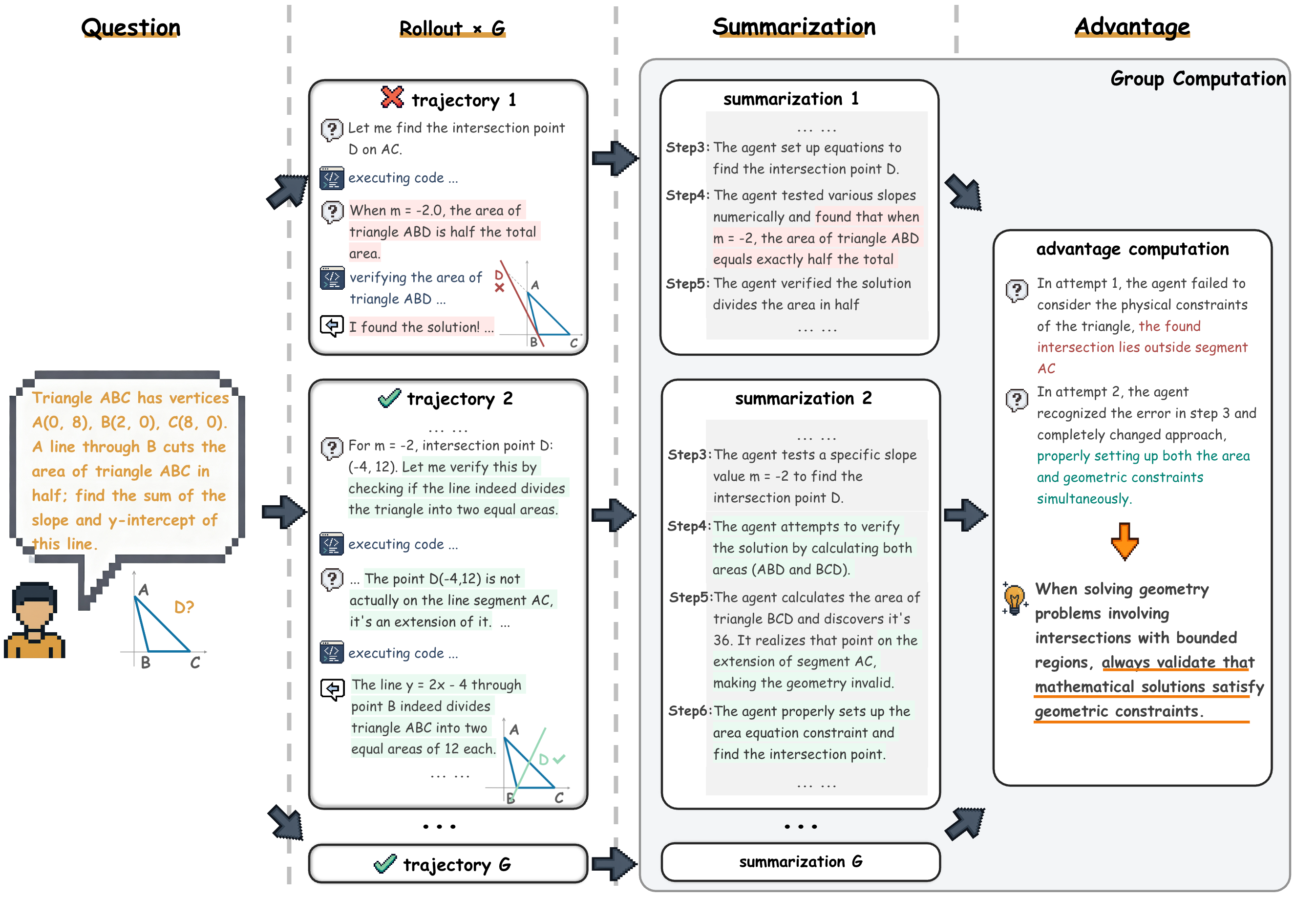
- The AI writes several draft answers to the same question (like multiple students turning in versions of an essay).
- A “reward model” acts like a teacher that scores each draft.
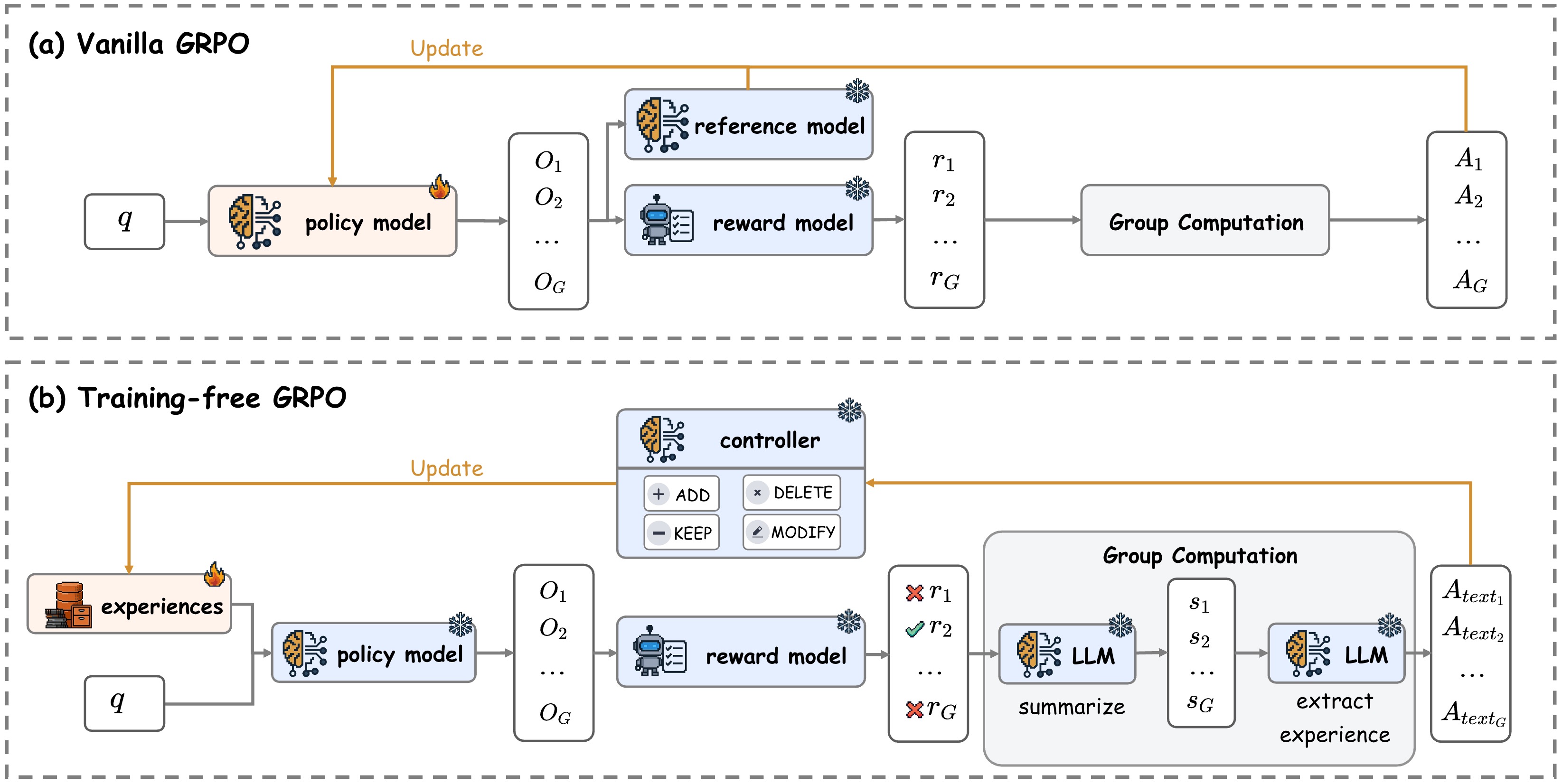
- Instead of changing the AI’s brain (retraining its weights), the system compares the drafts, figures out which ones were better and why, and then writes short, clear tips about what worked and what didn’t.
- These tips are saved in an “experience library”—think of it as a growing sticky-note cheat sheet.
- Next time, the AI answers new questions with those sticky notes placed at the top of its prompt. That guides it to behave better without changing the model itself.
- This repeat-and-refine cycle runs for a few rounds (called “epochs”) so the tips get better over time.
Key terms in everyday language:
- LLM: A very big chatbot that can read and write text.
- Rollouts: Multiple answer attempts to the same question.
- Reward model: An automatic grader that scores each attempt.
- Group-relative comparison: Ranking answers against each other in the same batch (who did best, who did worst).
- “Semantic advantage”: Written reasons (in plain language) that explain why some attempts are better than others. These reasons become the tips on the cheat sheet.
- Token prior / in-context learning: Putting those tips directly into the prompt so the model uses them when answering—like giving instructions before starting the test.
- Frozen model: The model’s settings are not changed; only the prompt is updated with better tips.
Here’s the process in short steps:
- The AI makes several answers for each question.
- A scorer grades them.
- The system compares them and asks the AI to explain (in words) what made the good ones better.
- It updates the cheat sheet by adding, removing, or refining tips (add/delete/modify/keep).
- The AI uses this updated cheat sheet in future prompts, so its next answers are guided by these lessons.
This mirrors how RL improves behavior—but it does so by improving the instructions (context), not by retraining the model.
What did they find?
The method worked well on two kinds of tasks:
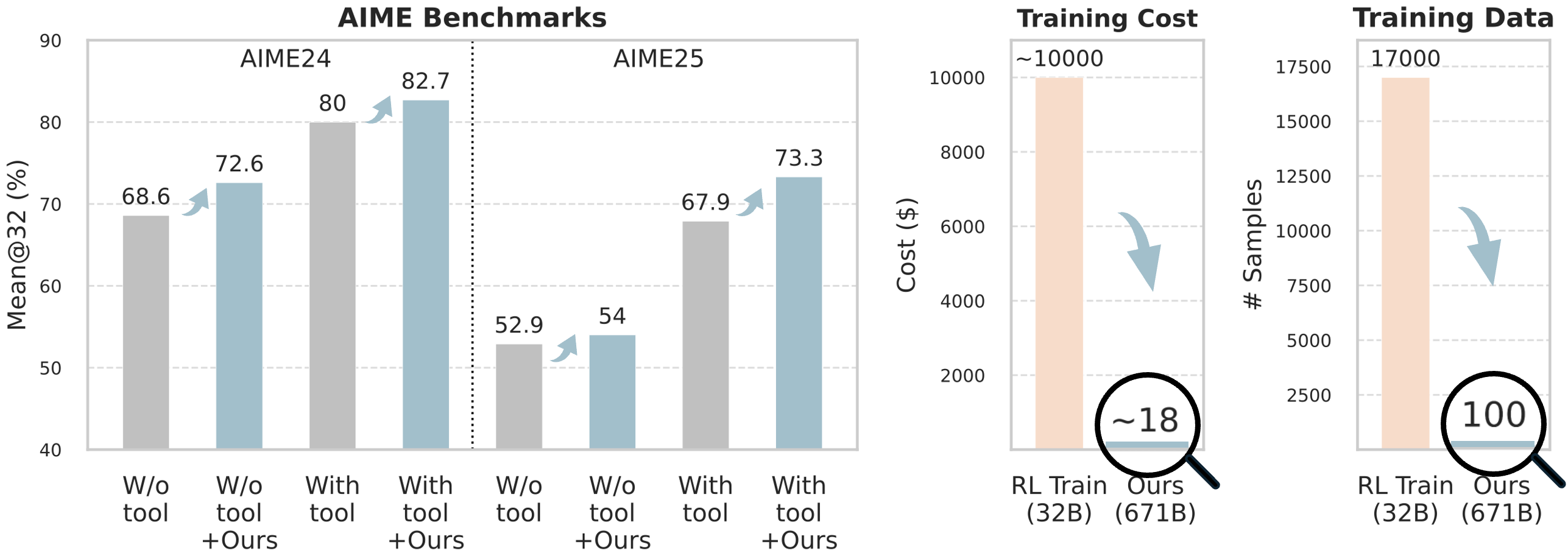
- Hard math problems (AIME 2024 and AIME 2025):
- Using the large model DeepSeek-V3.1-Terminus with tool use (a code interpreter), their scores increased:
- AIME 2024: from 80.0% to 82.7%
- AIME 2025: from 67.9% to 73.3%
- Even without tools (just prompting), scores went up too.
- They only used about 100 training examples and spent roughly $8–$18 in API costs.
- These gains beat or match several much more expensive methods that retrain a smaller model and can cost $10,000–$20,000.
- Web searching (WebWalkerQA benchmark):
- Score improved from 63.2% to 67.8% using the same training-free tips approach.
Other important observations:
- It generalizes well: Keeping the model frozen helps it stay good at many things. You can “plug in” different small cheat sheets for different tasks.
- It can still help even without exact right answers (ground truth) during learning, though having ground truth helps more.
- Comparing multiple answers at once (groups) matters: removing group comparison hurts performance.
- It often reduces unnecessary tool calls, meaning the AI uses tools (like a code interpreter) more efficiently.
Why does this matter?
- It’s much cheaper and faster: Instead of retraining a model (which needs lots of data, money, and time), you can add a lightweight “experience library” to the prompt.
- It avoids overfitting: Because you don’t change the model’s internal weights, you keep its broad skills while still getting better at a specific task.
- It’s flexible: You can switch cheat sheets for different domains (math vs. web search) without maintaining many specialized models.
- It’s practical for real-world use: Ideal for teams with limited data and budget, or for apps that don’t have steady traffic (so paying per use is better than running your own servers).
In short, Training-Free GRPO shows that you can get RL-like improvements by teaching the model through smarter prompts and lessons learned from its own attempts—no heavy retraining needed. This makes powerful AI more accessible, adaptable, and cost-effective.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a consolidated list of specific gaps and open questions that remain unresolved and could guide future research:
- Unspecified reward modeling details: the paper does not fully describe the reward model(s) used during training for different domains (math vs. web), including whether exact-match answers, heuristic scoring, or environment signals are used, and the potential biases or failure modes of these rewards.
- Ambiguity in ground-truth usage for web tasks: for WebWalkerQA training (AFM-100), it is unclear how ground truth correctness is determined and fed back to the learning process, especially when ground-truth supervision is reportedly absent in some variants.
- Lack of formal definition of “semantic group advantage”: the method operationalizes advantage as natural-language experience, but does not provide a formal objective, a quantifiable mapping to numerical advantage, or criteria for correctness/consistency across groups.
- Missing theoretical guarantees: there is no convergence analysis, formal equivalence, or bounds linking Training-Free GRPO to the GRPO objective, PPO-style stability, or policy improvement guarantees.
- Unclear criteria for “clear winners and losers”: the paper states experiences are distilled only when groups have winners and losers, but does not define thresholds, tie-handling, or the decision logic when reward variance is low or noisy.
- Experience library update policy is under-specified: the Add/Delete/Modify/Keep operations lack concrete algorithms for conflict resolution, deduplication, ranking, and versioning; how multiple contradictory experiences are handled remains unknown.
- Retrieval and conditioning strategy is opaque: it is unclear how a subset of experiences is selected and injected into prompts at inference-time (e.g., domain detection, relevance scoring, retrieval mechanism, prompt length budgeting).
- Context window constraints and scaling: the paper does not analyze how the experience library scales with larger corpora, how context length limits are managed, and the trade-off between prior size, token cost, and performance.
- Risk of error accumulation: there is no mechanism described to detect, quarantine, or roll back harmful or incorrect experiences; robustness to cumulative mistakes and “experience drift” is not studied.
- Hyperparameter sensitivity is not analyzed: performance sensitivity to group size G, temperature settings, number of epochs, and prompt templates (p_summary, p_extract) is not systematically evaluated.
- Prompt design reproducibility: the exact prompt templates used for summarization, advantage extraction, and experience updates are not provided, limiting reproducibility and transferability.
- Statistical rigor and confidence intervals: although Mean@32 (AIME) and pass@1 metrics are reported, confidence intervals, statistical significance tests, and variability across seeds/runs are not provided.
- Limited domain coverage: evaluation focuses on math reasoning and web searching; applicability to code generation, GUI agents, multi-agent coordination, long-horizon planning, and safety-critical domains is unexplored.
- Baseline breadth for training-free methods: comparisons omit other inference-time optimization baselines (e.g., Self-Refine, Reflexion, In-Context RL, TextGrad, AgentKB with retrieval), limiting insight into relative gains over established training-free techniques.
- Fairness of comparisons to parameter-tuned baselines: comparisons are primarily against fine-tuned smaller models (≤32B); the paper does not evaluate against parameter-tuned larger models, LoRA adapters on powerful LLMs, or distilled large-to-small approaches.
- Data leakage and distribution overlap: the claimed out-of-domain setup (DAPO-100 vs. AIME, AFM-100 vs. WebWalkerQA) is not accompanied by leakage checks or overlap analyses between training and test distributions.
- Robustness to reward noise and adversarial feedback: performance under noisy, mislabeled, or adversarial rewards is not evaluated; the method’s tolerance and safeguards against reward hacking remain open.
- Tool-use efficiency assessment is qualitative: claims of fewer tool calls lack detailed metrics on latency, wall-clock time, token usage during evaluation, and trade-offs between speed and accuracy.
- Cost analysis generality: the economic comparison depends on specific cloud pricing (DeepSeek) and serving assumptions; cost robustness across vendors, caching policies, and varying traffic patterns is not examined.
- Model capability threshold: the method appears to rely on strong base-model reasoning and tool-use (e.g., QwQ-32B underperforms); minimal capability requirements and scaling laws (improvement vs. base model strength) are not characterized.
- Sample efficiency scaling: only ~100 training examples and 3 epochs are studied; curves for more data/epochs, diminishing returns, and the optimal regime for sample size, group size, and epochs are unknown.
- Cross-domain experience management: when multiple domain priors coexist, automatic domain detection, safe merging, and interference mitigation (negative transfer) are not addressed.
- KL-like stability claim is not quantified: the assertion that a frozen base model acts as a stability prior “analogous to KL” lacks empirical measures of distributional drift or formal constraints on context-induced deviation.
- Experience structure and formalism: experiences are represented in natural language; potential benefits of structured representations (rules, schemas) and their impact on reliability, retrieval, and compositionality are unexplored.
- Safety and security considerations: injection of experiences may introduce prompt-injection vulnerabilities or encode unsafe behaviors; no threat model, sanitization pipeline, or red-teaming results are provided.
- Privacy and compliance: storing experiential knowledge derived from tools or web interactions may involve sensitive data; governance, provenance tracking, and compliance mechanisms are not discussed.
- Generalization under distribution shift: the method’s stability across large shifts (e.g., new math topics, web UI changes, API failures) is not studied; adaptation triggers and fallback strategies are missing.
- Interaction granularity: GRPO-like advantages are computed at the trajectory level; extension to step-level credit assignment (e.g., GiGPO) or hybrid token/step advantages is not explored.
- Combination with parameter updates: potential synergies (or conflicts) between Training-Free GRPO and lightweight parameter tuning (e.g., LoRA, adapters) are not investigated.
- Failure analysis depth: limited qualitative error analysis is provided; systematic categorization of failure modes (reasoning errors, retrieval mistakes, tool misuse) and targeted mitigations are absent.
- Reproducibility assets: while a code link is given, the paper lacks explicit details on seeds, models/versions, prompt template contents, reward function definitions, and experience libraries needed for full replication.
Practical Applications
Immediate Applications
Below is a concise set of deployable applications that leverage Training-Free GRPO’s context-space optimization, semantic group advantage, and experiential knowledge (token priors) without model fine-tuning.
- Software and AI Infrastructure (Developer Platforms)
- Use case: “ExperienceOps” SDK that plugs into ReAct-style agents to run group rollouts, score outputs, distill semantic advantages, and maintain an experience library injected at inference.
- Tools/products/workflows: Prompt middleware for token-prior injection, experience library manager (Add/Delete/Modify/Keep), batch rollout orchestration (G=3–5), reward-model adapters, caching-aware API clients (e.g., DeepSeek).
- Sector: Software, AI tooling.
- Assumptions/dependencies: Access to a capable LLM (performance depends on model quality), reward signals (ground truth or heuristic), long-context support and cache pricing for cost-effectiveness.
- Enterprise Web Research Assistants
- Use case: Corporate knowledge workers use a web agent with Training-Free GRPO (as shown on WebWalkerQA) to improve pass@1 with minimal domain examples (e.g., 100 queries).
- Tools/products/workflows: Browsing agent with minimal on-policy learning, experience library tuned to company-specific sources, “semantic advantage” prompts to reduce redundant clicks/tool calls.
- Sector: Enterprise software, knowledge management.
- Assumptions/dependencies: Access to internal web/repositories, light reward feedback (e.g., click-through success or verified answers), guardrails for data leakage.
- Math/Technical Tutoring and Assessment
- Use case: Classroom or online tutoring agents that quickly adapt to specific problem sets (AIME-style) using a small curated dataset (e.g., 50–100 problems).
- Tools/products/workflows: Teacher dashboard to build experience libraries per unit, group rollouts for common errors, token-prior injection for step-by-step validation and verification checks.
- Sector: Education, EdTech.
- Assumptions/dependencies: Ground-truth availability for scoring, student privacy controls, reliable LLM reasoning capability.
- Code Reasoning and Tool-Integrated Debugging
- Use case: IDE copilots that reduce tool call overhead and improve consistency by learning experiential heuristics (e.g., when to run code, when to refactor).
- Tools/products/workflows: CI-integrated agents with GRPO-like experience cycles, semantic advantage prompts about tool invocation timing, lightweight experience library per repo/team.
- Sector: Software engineering, DevTools.
- Assumptions/dependencies: Stable code execution environment, minimal labeled examples (e.g., successful fix patterns), capability for multi-epoch in-context learning.
- Financial and Market Intelligence
- Use case: Analyst assistants for rapid due diligence (10-Ks, news, filings) that learn firm-specific heuristics (e.g., which sources are authoritative, what sections to prioritize).
- Tools/products/workflows: Rollout-and-reward with verified snippets, knowledge base pointers in token priors, semantic advantages to minimize non-authoritative citations.
- Sector: Finance.
- Assumptions/dependencies: Clear reward proxies (e.g., citation correctness), compliance review for sources, strong base LLM for reading long documents.
- Legal Research and Compliance Triage
- Use case: Law firm or in-house teams deploy browsing/retrieval agents tuned via training-free GRPO to improve precision and auditability without retraining base models.
- Tools/products/workflows: Experience libraries on case law, citation checking, multi-epoch optimization on small annotated sets; audit logs of experience changes.
- Sector: LegalTech, compliance.
- Assumptions/dependencies: Verified ground truth labels (e.g., authoritative citations), strict prompt governance, privacy-safe context management.
- Healthcare Knowledge Retrieval (Non-diagnostic)
- Use case: Clinical documentation assistants that learn experiential heuristics for guideline retrieval, coding references, and policy lookups without changing model weights.
- Tools/products/workflows: Token priors encoding trusted sources and structured validation steps; rollouts scored by match to verified excerpts.
- Sector: Healthcare IT, medical administration.
- Assumptions/dependencies: Non-diagnostic scope, curated high-quality sources, HIPAA/PHI-safe workflows; strong LLM reading comprehension.
- Customer Support Macros and Triage
- Use case: Support bots learn experiential patterns (e.g., when to escalate, which knowledge base article to use) from small, labeled transcripts.
- Tools/products/workflows: Multi-epoch semantic advantage distillation from paired ticket-resolution examples; token priors that encode decision trees and escalation criteria.
- Sector: Customer support, BPO.
- Assumptions/dependencies: Access to representative transcripts and outcomes; alignment with escalation policies; monitoring for distribution drift.
- Low-Traffic Specialist Services (Cost-Optimized)
- Use case: SMEs deploy agents for niche tasks (e.g., regulatory map lookups) where hosting fine-tuned models is uneconomical; pay-as-you-go API with training-free optimization.
- Tools/products/workflows: Lightweight learning loops (3–4 steps, ~100 examples), cache-aware prompting, and experience re-use across similar tasks.
- Sector: SMB services, government contractors.
- Assumptions/dependencies: Token pricing fits budget; robust API SLAs; minimal data for experience learning.
- Data Science and Analytics Assistants
- Use case: Analytical agents that learn heuristics for choosing the right chart, validating numeric results (calculator/API), and documenting steps for reproducibility.
- Tools/products/workflows: Reward metrics from correctness checks, semantic advantage templates for tool selection efficiency, experience libraries per team.
- Sector: Analytics, BI.
- Assumptions/dependencies: Reliable tools (calculators, DB connectors), small curated datasets for learning, clear correctness tests.
- Sustainability and Procurement Guidance (Policy)
- Use case: Organizations favor context-space optimization over fine-tuning to reduce compute, cost, and emissions in AI procurement and governance.
- Tools/products/workflows: Internal policy memo templates; cost-emission calculators comparing parameter-space vs. context-space approaches; audit trails for experience changes.
- Sector: Policy, ESG.
- Assumptions/dependencies: Decision frameworks and metrics; verifiable accounting for token and GPU-hours; oversight on data privacy in prompts.
Long-Term Applications
The following applications require further research, scaling, or development to reach production-grade maturity.
- Federated “Experience Marketplace”
- Vision: Secure exchange of anonymized experience libraries across organizations or teams to bootstrap agents in new domains.
- Products/workflows: Standardized experience formats, differential privacy, provenance metadata, reputation scores for experiences.
- Sector: Software platforms, ecosystems.
- Assumptions/dependencies: Privacy-preserving sharing, interoperable schemas, governance for toxic/biased experiences.
- Continuous On-Policy Learning from Live Usage
- Vision: Agents auto-update experience libraries based on user feedback and implicit signals (success/failure) with safe rollback and A/B testing.
- Products/workflows: Automated semantic advantage pipelines, drift detectors, experience versioning, human-in-the-loop gates.
- Sector: SaaS, enterprise AI.
- Assumptions/dependencies: Reliable feedback signals; robust rollback; guardrails to prevent experience degradation.
- Domain-Independent Reward Modeling
- Vision: Generalizable reward models that work when ground truth is scarce, using heuristics (majority voting, self-reflection) and weak supervision.
- Products/workflows: Reward ensemble services; calibrators for noisy labels; metrics for semantic advantage quality.
- Sector: AI research, tooling.
- Assumptions/dependencies: Validation datasets; techniques for reward robustness; standards for evaluating non-ground truth domains.
- Safety, Compliance, and Audit Frameworks for Experience Libraries
- Vision: Tools to detect harmful, biased, or policy-violating experiences and enforce usage constraints.
- Products/workflows: Experience linting, toxicity filters, compliance audits, explainable advantage-to-experience mapping.
- Sector: Policy, LegalTech, safety.
- Assumptions/dependencies: Detection models, compliance rulesets, explainability requirements.
- Multi-Agent Orchestration with Shared Experiences
- Vision: Collaborative agents (planner, tool caller, verifier) that share and update a common experience KB, improving credit assignment and tool-use efficiency.
- Products/workflows: Role-specific experience segments; cross-agent semantic advantage aggregation; coordination protocols.
- Sector: Robotics (simulated), complex workflows, RPA.
- Assumptions/dependencies: Stable interfaces and toolchains; methods for credit assignment; robust conflict resolution across agents.
- Robotics and Embodied AI Planning Heuristics
- Vision: Training-free experience priors guide high-level planning and tool selection for robots without fine-tuning policy networks.
- Products/workflows: Simulation-based rollouts, reward proxies for task completion and safety, semantic advantage distillation for planning heuristics.
- Sector: Robotics.
- Assumptions/dependencies: Strong base model and tool integrations; safety validation; sim-to-real transfer; reliable reward proxies.
- Healthcare Decision Support (Regulated)
- Vision: Experience-guided assistants help clinicians with structured guideline retrieval, risk scoring explanations, and documentation consistency in regulated settings.
- Products/workflows: Clinically validated experience libraries; traceable advantage extraction; integration with EHRs (non-diagnostic).
- Sector: Healthcare.
- Assumptions/dependencies: Regulatory approvals; rigorous validation; PHI-safe pipelines; strong clinical oversight.
- Financial Advisory and Trading Research (High-Regulation)
- Vision: Agents use experience priors to structure research workflows, source validation, and risk annotations without changing base model parameters.
- Products/workflows: Regulator-ready audit trails for experiences, conflict-of-interest checks, scenario backtesting integration.
- Sector: Finance.
- Assumptions/dependencies: Compliance frameworks; reliable reward metrics; strict data governance.
- Standardization of Experience Formats and Benchmarks
- Vision: Community standards for experience schemas, evaluation protocols, and cross-domain benchmarks for context-space optimization.
- Products/workflows: Open datasets of experience libraries, reference reward models, leaderboard metrics for semantic advantage methods.
- Sector: Academia, open-source.
- Assumptions/dependencies: Broad adoption; funding for benchmark maintenance; fair evaluation under differing base models.
- Edge and On-Device Adaptation
- Vision: Apply training-free GRPO to mid-size local models, using compact experience libraries and low-latency reward signals.
- Products/workflows: Experience compression, prompt templates optimized for short context windows, local tool integration.
- Sector: Mobile, IoT.
- Assumptions/dependencies: Adequate model capability; prompt optimization under tight context budgets; local privacy and security.
- Cross-Domain Transfer Playbooks
- Vision: Repeatable playbooks to port experience libraries across domains (e.g., math → engineering analysis; web research → legal research).
- Products/workflows: Transferability diagnostics, adaptation heuristics (which experiences generalize), domain-specific validators.
- Sector: Consulting, enterprise AI enablement.
- Assumptions/dependencies: Methods to measure and mitigate negative transfer; domain-aware reward recalibration; curated bridging examples.
Glossary
- AFM: A reinforcement learning dataset of multi-turn web interactions for agent training. "AFM (Chain-of-Agents) web interaction RL dataset"
- Agent KB: A method that builds a reusable, hierarchical knowledge base of problem-solving experiences for agents. "Agent KB constructs a shared, hierarchical knowledge base to enable the reuse of problem-solving experiences across tasks."
- Agentic reinforcement learning (Agentic RL): RL approaches tailored to align and improve autonomous LLM agent behavior through interaction and feedback. "Recent advancements in agentic reinforcement learning (Agentic RL) approaches have employed Group Relative Policy Optimization (GRPO)"
- AIME: The American Invitational Mathematics Examination, used here as out-of-domain math reasoning benchmarks. "AIME 2024 and 2025 benchmarks"
- Chain-of-Agents: A multi-agent framework/dataset setup enabling coordinated roles and tools within a single model. "AFM (Chain-of-Agents) web interaction RL dataset"
- Chain-of-Thought (CoT): A prompting strategy where models produce explicit reasoning steps to guide actions. "prompt LLMs to generate explicit chain-of-thought (CoT) and actionable steps"
- DAPO-100: A 100-sample subset of DAPO-Math-17K used for lightweight training-free optimization. "we randomly sample 100 problems from the DAPO-Math-17K dataset, denoted as DAPO-100."
- DAPO-Math-17K: A math reasoning dataset used as a source for small training subsets. "DAPO-Math-17K dataset"
- DeepSeek-V3.1-Terminus: A large LLM used as a frozen base policy in experiments. "Training-Free GRPO, when applied to DeepSeek-V3.1-Terminus, significantly improves out-of-domain performance."
- GiGPO: An RL method with hierarchical grouping for precise credit assignment across trajectories and steps. "GiGPO~\citep{gigpo} implements a two-level grouping mechanism for trajectories"
- Group Relative Policy Optimization (GRPO): An RL algorithm that computes advantages from groups of responses without a critic to update policy. "Group Relative Policy Optimization (GRPO)~\citep{grpo}"
- In-Context Learning (ICL): Adapting model behavior at inference by providing demonstrations and priors in the prompt. "in-context learning~\citep{icl} that leverages a lightweight token prior"
- KL-divergence penalty: A regularization term that constrains policy updates to stay close to a reference model. "By combining a KL-divergence penalty against a reference model"
- Mean@32: The average Pass@1 over 32 independent runs per problem. "we evaluate each problem with 32 independent runs and report the average Pass@1 score, which we denote as Mean@32."
- MetaGPT: A multi-agent system that enhances planning and tool integration. "MetaGPT~\citep{metagpt}, CodeAct~\citep{codeact}, and OWL~\citep{owl}"
- MiroThinker: A web-interaction–optimized agentic approach evaluated for cross-domain transfer. "MiroThinker \citep{mirothinker} significantly underperforms ReTool that is trained in the math domain on the AIME benchmarks."
- On-policy RL: RL where optimization uses data collected by the current policy, here mirrored in-context across epochs. "more closely mirrors on-policy RL with multi-epoch learning."
- OWL: An agentic system focusing on tool integration and action execution. "MetaGPT~\citep{metagpt}, CodeAct~\citep{codeact}, and OWL~\citep{owl}"
- Pass@1: The proportion of tasks solved correctly on the first attempt. "Pass@1 score"
- Pass@3: The proportion of tasks correctly solved within three attempts. "pass@3"
- Proximal Policy Optimization (PPO): An RL algorithm using clipped objectives and a critic for stable updates. "Proximal Policy Optimization (PPO)~\citep{ppo} employ a policy model for generation and a separate critic model to estimate token-level value."
- PPO-clipped objective function: The objective with clipping used in PPO to prevent overly large policy updates. "constructs a PPO-clipped objective function"
- QwQ-32B: A 32B parameter model used in ablation for web tasks. "Applying Training-Free GRPO to QwQ-32B~\citep{qwq32b} yields only 25.5\% pass@1"
- Qwen2.5-32B-Instruct: A 32B instruction-tuned model used for RL baselines. "Qwen2.5-32B-Instruct"
- Qwen3-32B: A 32B model variant used for cross-domain comparisons. "Qwen3-32B (Non-Thinking)"
- ReAct: A prompting framework interleaving reasoning and actions to use tools. "ReAct~\citep{react} prompt LLMs to generate explicit chain-of-thought (CoT) and actionable steps"
- Reflexion: An inference-time refinement method using external feedback for a second attempt. "Reflexion~\citep{reflexion} incorporates an external feedback signal to prompt the model for reflection and a new attempt."
- ReTool: An RL method training agents to integrate natural language and code execution for math reasoning. "ReTool~\citep{retool} uses PPO to train an agent to interleave natural language with code execution for mathematical reasoning."
- Reward model: A model that assigns scalar scores to outputs to guide optimization. "Each output is then independently scored with a reward model ."
- Semantic advantage: A natural-language, experience-based measure of relative output quality used for optimization. "This natural language experience $A_{\text{text}$ serves as our semantic advantage"
- Semantic group advantage: A group-level, language-based comparison replacing numeric advantages in GRPO. "We replace numerical group advantage in vanilla GRPO with semantic group advantage"
- Self-Refine: An iterative method where the LLM critiques and improves its own outputs. "Self-Refine~\citep{selfrefine} generates an initial output and then uses the same LLM to provide verbal feedback for subsequent revisions."
- SimpleTIR: An RL approach for tool-integrated reasoning with significant training cost. "SimpleTIR~\citep{simpletir}"
- TextGrad: A framework that backpropagates textual feedback through computation graphs for optimization. "TextGrad~\citep{textgrad} proposes a more general framework, treating optimization as a process of back-propagating textual feedback through a structured computation graph."
- Token prior: A compact set of learned tokens encoding experiential knowledge to steer outputs in-context. "experiential knowledge as a token prior"
- Toolformer: A method where LLMs learn to invoke APIs via self-supervised fine-tuning. "Toolformer~\citep{toolformer} demonstrates that LLMs can learn to self-supervise the invocation of APIs via parameter fine-tuning."
- Trajectory: A sequence of actions and outputs (a rollout) used for comparison and learning. "enable the LLM to compare different trajectories within each group"
- Training-Free GRPO: An inference-time method that optimizes policy via contextual experiences without updating parameters. "We introduce Training-Free GRPO"
- vLLM: A serving framework enabling batched inference for high throughput. "vLLM-based batching requests"
- WebWalkerQA: A benchmark assessing web agent performance on complex browsing tasks. "WebWalkerQA benchmark"
- ZeroTIR: A tool-integrated RL method with high training cost used as a baseline. "ZeroTIR~\citep{zerotir}"
Collections
Sign up for free to add this paper to one or more collections.

