Semantic Tube Prediction: Beating LLM Data Efficiency with JEPA
Abstract: LLMs obey consistent scaling laws -- empirical power-law fits that predict how loss decreases with compute, data, and parameters. While predictive, these laws are descriptive rather than prescriptive: they characterize typical training, not optimal training. Surprisingly few works have successfully challenged the data-efficiency bounds implied by these laws -- which is our primary focus. To that end, we introduce the Geodesic Hypothesis, positing that token sequences trace geodesics on a smooth semantic manifold and are therefore locally linear. Building on this principle, we propose a novel Semantic Tube Prediction (STP) task, a JEPA-style regularizer that confines hidden-state trajectories to a tubular neighborhood of the geodesic. STP generalizes JEPA to language without requiring explicit multi-view augmentations. We show this constraint improves signal-to-noise ratio, and consequently preserves diversity by preventing trajectory collisions during inference. Empirically, STP allows LLMs to match baseline accuracy with 16$\times$ less training data on the NL-RX-SYNTH dataset, directly violating the data term of Chinchilla-style scaling laws and demonstrating that principled geometric priors can surpass brute-force scaling. Code is available at https://github.com/galilai-group/LLM-jepa#stp.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about a new way to train LLMs so they learn faster from less data and make more consistent, diverse predictions. The authors introduce a simple idea called “Semantic Tube Prediction” (STP). Think of it like putting gentle guardrails around the model’s internal thinking path so it stays focused on the true meaning of a sentence and doesn’t wobble off course.
What questions are the authors asking?
The authors ask:
- Can we train LLMs to learn as well (or better) using much less training data?
- Why does the usual training goal—predicting the next word—sometimes fail to keep the model’s internal thoughts stable?
- Is there a simple “shape” that good sentences follow inside a model, and can we use that shape to guide training?
How does their approach work?
Key idea: Meaning follows a mostly straight path
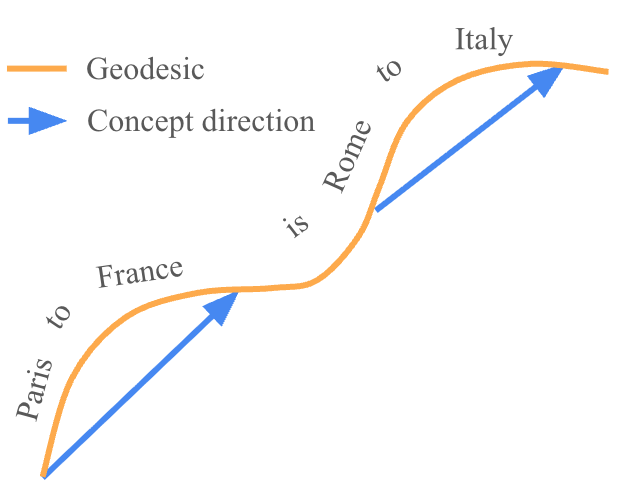
Inside an LLM, each word turns into a vector (a bundle of numbers) called a “hidden state.” As a sentence unfolds word by word, these hidden states form a path. The authors suggest a “Geodesic Hypothesis”: if the model is understanding correctly, that path is almost straight over short stretches—like taking the straightest route on a smooth surface.
- Analogy: Imagine walking across a smooth field from point A to point B. If you’re not distracted, you’ll walk more or less straight. That straight path is the “geodesic.”
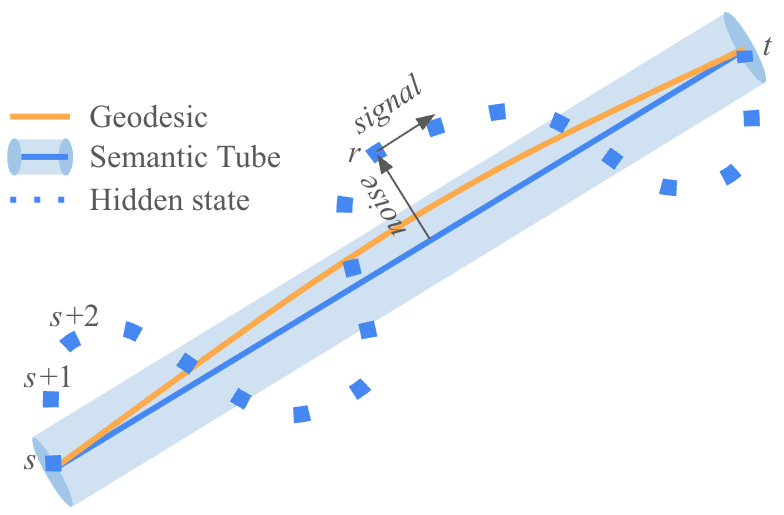
The “Semantic Tube”
If the correct path is almost straight, then a good path should stay inside a “tube” around that straight line. Any sideways drift away from this tube is “noise,” while moving forward along the tube is “signal.”
- Analogy: The tube is like flexible guardrails that keep your walk straight without forcing an exact line.
What is STP (Semantic Tube Prediction)?
STP is a tiny extra training rule added to the usual “predict the next word” goal. In simple terms, it checks three moments in a sentence (call them earlier, middle, later) and encourages the middle step to lie in line with the earlier and later steps. That makes the hidden-state path smoother and straighter.
- In math words (you don’t need the details): the extra loss rewards and pointing in the same direction (high cosine similarity), which is the same as saying “keep the path straight.”
Why add this to next-word prediction?
The standard next-token prediction (NTP) objective tells the model what the next word should be, but it doesn’t fully control how the model’s internal states line up. That can cause the model’s internal path to drift, leading to bland or collapsed outputs (different prompts producing similar answers) or odd mistakes.
- Analogy: Next-word training is like grading each step of an essay, one sentence at a time. STP makes sure the whole argument flows in a straight, clear line—so the parts connect well.
A note on their theory (gentle version)
- They show that you can think of a sentence’s progress as a smooth path (like an object moving steadily), which means two different starting points should not collide if the path is correct.
- But because next-word training doesn’t fully pin down the internal path, paths can drift. STP adds a gentle nudge that keeps those paths separated and consistent.
What did they find?
The authors tested STP across different models and datasets and report several important results:
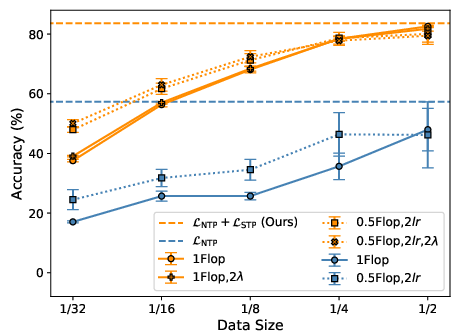
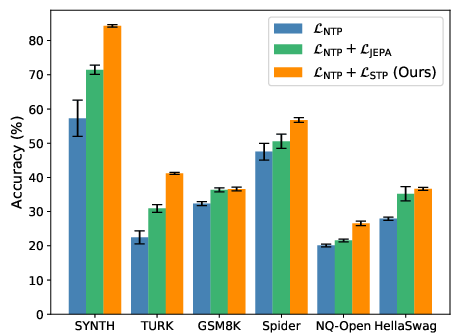
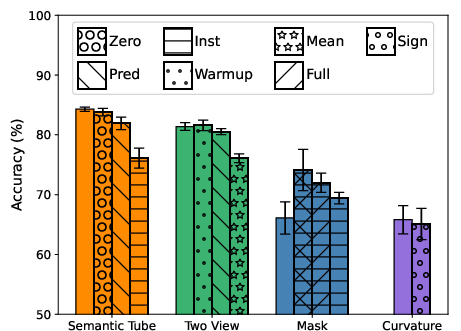
- Better data efficiency: With STP, a model reached the same accuracy using about 16× less training data on one benchmark (NL-RX-SYNTH). That’s a big deal because it breaks the usual “more data = better results” pattern known as scaling laws.
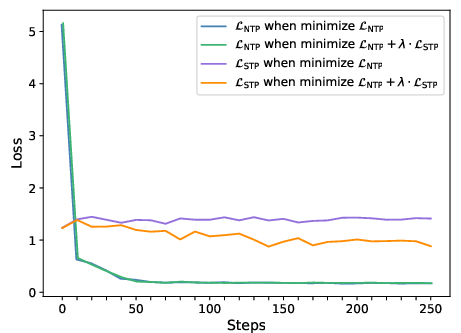
- Steadier training: The usual next-word loss (NTP) can stop improving (plateau), but the STP loss keeps improving. This shows STP is helping even when NTP seems “stuck.”
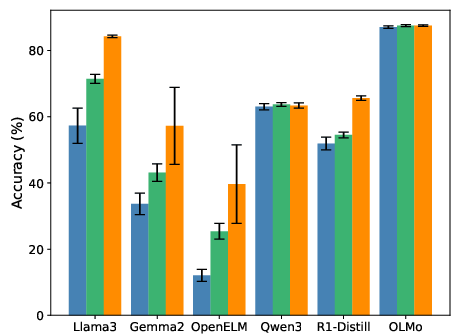
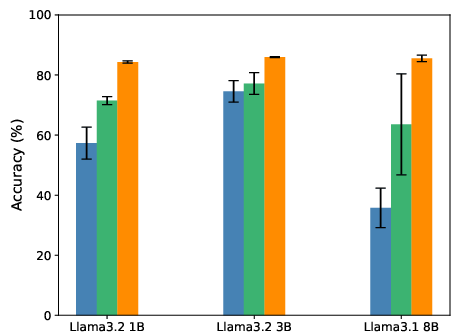
- Higher accuracy: Across different tasks and models, adding STP led to better performance than regular fine-tuning and a prior method called LLM-JEPA.
- Preserves diversity: STP helps the model keep different valid styles or answers, rather than collapsing to one favorite style. For example, it learned to produce two equally correct patterns in a coding task, instead of preferring just one.
- Simple and cheap to use: STP uses the same hidden states the model already computes, so it adds little to training cost. It also doesn’t need complicated extra networks or multiple views of the data.
Why is this important?
- Learn more with less: If models can learn well with much less data, we can train useful systems faster, cheaper, and with less energy.
- More reliable generations: Keeping the model’s internal path straight reduces random drifts, which can lower errors and odd outputs.
- Keeps answers varied and fair: By preventing different prompts from collapsing into the same answer, STP supports richer and more diverse responses.
- A new guiding principle: The “geodesic” view (that good meaning paths are nearly straight locally) gives researchers a clear geometric target for future training methods.
Bottom line
This paper proposes a simple extra training signal—Semantic Tube Prediction—that acts like soft guardrails for a model’s internal thinking path. It helps the model focus on the meaningful direction of a sentence and ignore sideways noise. The result: better accuracy, far better data efficiency (up to 16× less data for the same performance in their tests), and more diverse outputs. If widely adopted, this approach could make building strong LLMs faster, cheaper, and more reliable.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to enable actionable follow-up work.
- Formalization of the ODE model for discrete token sequences:
- Precisely define the embedding-time parameterization under which concatenation becomes additive and can be treated as vector subtraction.
- State and verify the smoothness/Lipschitz assumptions on needed for Picard–Lindelöf uniqueness in the sequence space and justify their applicability to modern LLMs.
- Geodesic Hypothesis validation:
- Directly measure local linearity on hidden-state trajectories across layers, tasks, and sequence lengths; estimate and in Definition 3.1 and quantify the fraction of segments satisfying the local-linearity inequality.
- Compare geodesic conformity for real-world corpora vs synthetic tasks and across different tokenization schemes.
- Principle of Least Action grounding:
- Specify an explicit Lagrangian for LLM sequence dynamics and derive conditions under which “least action” implies geodesic-like hidden-state evolution.
- Prove that minimizing the STP loss corresponds to minimizing action (or a provably related functional), not merely penalizing local curvature.
- STP degeneracy and stability analysis:
- Analyze whether trivial solutions (e.g., vanishing differences, near-zero norm differences with unstable cosine) can minimize STP; add safeguards (norm constraints, margins) and prove non-collapse under realistic training regimes.
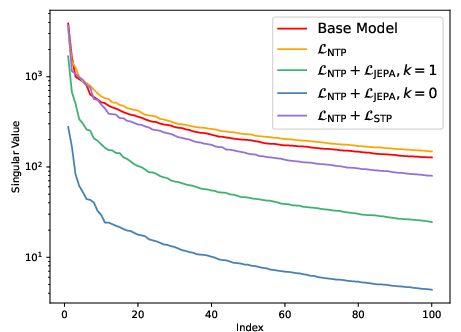
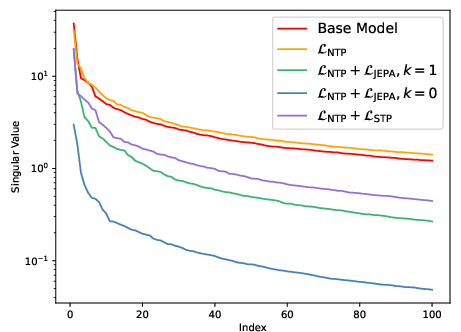
- Quantify interactions between STP and representation norms; explain the “polymorphism” SVD observation theoretically.
- Index selection strategy for STP:
- Systematically study how sampling of , window sizes, and proximity thresholds affect performance, stability, and compute/memory overhead.
- Explore curricula or adaptive schedules for selecting indices based on sequence length and model stage.
- Layer-wise and architectural placement:
- Evaluate applying STP at different layers (early/middle/late), aggregated across layers, or on attention outputs rather than final hidden states; analyze effects on attention patterns and feature hierarchies.
- Long-context and nonlocal dynamics:
- Test STP on very long contexts and tasks with nonlocal dependencies (topic shifts, multi-hop reasoning, dialogue), examining whether curvature suppression harms necessary nonlinearity.
- Diversity and mode-collapse metrics:
- Move beyond regex suffixes to comprehensive diversity metrics (e.g., distinct-n, entropy of output distributions, prompt-space collision rates, cluster separations) on open-ended generation tasks.
- Study prompt-wise geodesic separation empirically to substantiate the “no intersection” claim in realistic inference settings.
- Decoding interactions:
- Evaluate how STP-trained models behave under different decoding strategies (greedy, temperature sampling, nucleus/beam search) and whether diversity preservation depends on decoding choices.
- Inference-time SDE and “cone” behavior:
- Empirically quantify the claimed Brownian cone () during inference; propose and test inference-time controls (e.g., guidance or constraints) that leverage STP to mitigate divergence.
- Scaling law claims and generality:
- Test the data-efficiency claim on large-scale pretraining (not just fine-tuning), across diverse corpora and budgets, to rigorously assess whether STP “violates” Chinchilla-style data scaling terms.
- Examine compute–data–parameter tradeoffs under controlled scaling experiments with standardized metrics (loss, perplexity, accuracy).
- Standard language modeling metrics:
- Report effects on perplexity, calibration (ECE/Brier), and log-likelihood to confirm that NTP performance “remaining stable” is robust across benchmarks and not task-specific.
- Model scale and practicality:
- Assess STP on larger models (>30B parameters), reporting throughput, wall-clock times, and memory overhead from storing per-token hidden states; quantify “negligible overhead” claims.
- Hyperparameterization and automation:
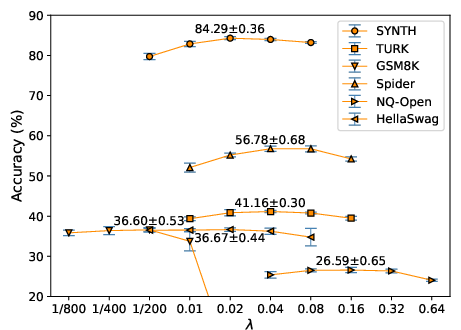
- Develop principled, task-agnostic methods to set (e.g., via validation curves, gradient-balancing, uncertainty estimates) and study scheduling (warmup/annealing) across training phases.
- Comparisons with alternative regularizers:
- Benchmark STP against curvature penalties (second-order finite differences), Jacobian/contractive regularization, temporal smoothing, or feature orthogonality constraints under identical compute.
- Compatibility with other training regimes:
- Investigate interactions with RLHF/DPO, instruction tuning, multi-task training, and structured reasoning curricula; identify synergies/conflicts and best practices.
- Tokenization and vocabulary effects:
- Test STP’s sensitivity to different tokenizers (BPE, sentencepiece, word-level) and vocabulary sizes; analyze whether local linearity depends on subword segmentation.
- OOD robustness and generalization:
- Evaluate STP on domain-shifted datasets and adversarial prompts; measure generalization and robustness under distributional changes.
- Safety and content moderation:
- Analyze whether “preserving diversity” inadvertently preserves harmful completions; integrate safety filters and measure toxicity/harms post-STP.
- Theoretical links to NTK and feature learning:
- Provide formal derivations connecting STP to NTK dynamics or feature-learning regimes in the infinite-width limit; clarify when identity predictors outperform learned projections.
- Empirical curvature and manifold diagnostics:
- Quantify curvature, geodesic distances, and manifold smoothness along trajectories; test the Manifold and Linear Representation Hypotheses under STP with standardized probes.
- Task breadth and evaluation transparency:
- Expand beyond the listed datasets with broader, standardized benchmarks (e.g., MMLU, BBH, long-form QA, code generation); provide full metrics, statistical tests, and ablation details for reproducibility.
- Training from scratch vs fine-tuning:
- Determine whether STP benefits persist when training models from scratch and whether they change early vs late in training; study exposure-bias mitigation throughout.
- Norms, margins, and cosine numerics:
- Address potential numerical instabilities in cosine-based losses for small-magnitude vectors; propose norm floors or margin-based variants and compare empirically.
- Attention-level diagnostics:
- Investigate how STP affects head specialization, token selectivity, and max-margin token selection in attention; link observed changes to SNR improvements.
- Practical guidance and resources:
- Provide detailed compute profiles, memory usage, implementation tips (e.g., gradient checkpointing with hidden-state access), and reproducible code for large-scale runs beyond small models.
- Cross-modal extensions:
- Test whether STP generalizes to multimodal LLMs (text–image, text–audio) without explicit multi-view scaffolding; quantify benefits and failure modes.
- Formal SNR definition and proofs:
- Make explicit the SNR metric used for hidden states; include the referenced proofs (sec:snr-proofs) tying SNR changes to accuracy and data efficiency with assumptions clearly stated.
- Curvature–reasoning trade-offs:
- Examine whether enforcing local straightness impairs branching/structured reasoning (e.g., chain-of-thought, program synthesis), and identify regimes where curvature is beneficial vs detrimental.
- Robust statistical validation:
- Increase the number of seeds and report two-tailed tests, effect sizes, and confidence intervals; ensure claimed improvements are statistically strong across tasks and settings.
Practical Applications
Overview
The paper introduces Semantic Tube Prediction (STP), a JEPA-style training regularizer for LLMs that enforces local linearity of hidden-state trajectories (“semantic tubes”) along hypothesized geodesics on a smooth semantic manifold. Practically, STP is an auxiliary loss term added to standard next-token prediction (NTP), computed as 1 - cos(h_t - h_r, h_r - h_s) for randomly selected token indices s < r < t. STP improves signal-to-noise ratio (SNR), preserves diversity by reducing trajectory collisions, and achieves strong data efficiency (matching baseline accuracy with approximately 16× less training data on NL-RX-SYNTH). It requires negligible additional compute, no multi-view scaffolding, and no predictor network.
Below are actionable applications derived from these findings, organized by deployment horizon.
Immediate Applications
These applications can be implemented now with existing open-weight LLMs and standard tooling (e.g., HuggingFace Transformers), subject to task-specific validation.
- Efficient fine-tuning recipes for industry LLM products
- Sectors: software, finance, healthcare, legal, customer support.
- What to do: augment existing supervised fine-tuning pipelines with STP (
L = L_NTP + λ·L_STP) to achieve similar accuracy with significantly less data or compute. Tune λ (typically between 0.01 and 0.08). - Tools/products/workflows: “STP-enabled” fine-tuning scripts; training dashboards tracking STP loss alongside NTP; model cards reporting data-efficiency gains.
- Assumptions/dependencies: geodesic/local linearity behavior holds for the task/domain; hidden states are accessible; minimal overhead (cosine similarity) fits compute budgets; empirical gains generalize beyond datasets tested.
- Data-limited domain adaptation and personalization
- Sectors: healthcare (clinical note summarization), enterprise (internal knowledge assistants), NGOs and academia (low-resource languages).
- What to do: use STP to fine-tune small/medium LLMs on modest labeled datasets to achieve viable performance where standard NTP degrades; combine STP with parameter-efficient methods (e.g., LoRA).
- Tools/workflows: rapid domain adaptation pipelines; “few-shot fine-tuning” service offerings; federated fine-tuning with STP for privacy-preserving personalization.
- Assumptions/dependencies: annotated data scarcity; local linearity assumption holds; privacy/compliance constraints allow on-device or federated updates.
- On-device/edge model refinement with small datasets
- Sectors: mobile, IoT, healthcare edge devices, robotics interfaces.
- What to do: integrate STP into lightweight fine-tuning on-device (e.g., LoRA+STP) to reduce data/compute requirements and preserve diversity under limited training conditions.
- Tools/workflows: edge training runtimes that expose last-layer hidden states; STP metrics for local diagnostics.
- Assumptions/dependencies: device supports the minor extra computation for cosine similarity; memory overhead is acceptable; task compatibility.
- Diversity-preserving generative systems (reducing mode collapse)
- Sectors: media, marketing, education (content authoring), code generation.
- What to do: adopt STP during fine-tuning to maintain stylistic and structural diversity in generation (e.g., preserving alternate valid patterns, formats, or styles).
- Tools/workflows: evaluation suites checking diversity metrics; A/B experiments comparing NTP-only vs. NTP+STP; content pipelines that rely on robust variant preservation.
- Assumptions/dependencies: diversity matters for downstream utility; STP’s diversity benefits translate from studied tasks to target domains.
- Safety-sensitive assistant training (reducing drift/hallucinations)
- Sectors: finance, legal, healthcare, government services.
- What to do: incorporate STP during supervised fine-tuning to reduce hidden-state drift and trajectory collisions that can lead to hallucinations or brittle chains of thought.
- Tools/workflows: training KPIs include STP loss stabilization; risk assessments correlate STP loss with error profiles; safety eval batteries.
- Assumptions/dependencies: hallucination reduction carries over; inference-time SDE drift still requires robust decoding strategies; domain-specific validation is required.
- Cost and energy savings for MLOps
- Sectors: cloud providers, AI platform teams, sustainability programs.
- What to do: schedule fine-tuning runs with less data or epochs while maintaining accuracy via STP; include STP metrics in cost/perf dashboards; quantify carbon reductions from data-efficiency.
- Tools/workflows: “green training” policies; budget calculators using measured data-efficiency multipliers; training orchestration with λ as a tunable control.
- Assumptions/dependencies: observed data-efficiency generalizes to internal tasks; organizational willingness to adopt new KPIs (SNR/STP).
- Synthetic/noisy data training robustness
- Sectors: software (code/text generation), education (synthetic tutoring corpora), data curation startups.
- What to do: leverage STP to improve SNR when training on noisier or synthetic datasets; reduce reliance on heavy manual curation.
- Tools/workflows: synthetic data generation pipelines paired with STP-regularized fine-tuning; monitoring of STP loss as a proxy for “trajectory smoothness.”
- Assumptions/dependencies: synthetic data quality is sufficient; STP compensates noise without over-regularizing complex semantics.
- Academic research instrumentation for representation geometry
- Sectors: academia and research labs.
- What to do: use STP as a probe and training objective to study local linearity, geodesic behavior, scaling law violations, and diversity preservation across tasks/models.
- Tools/workflows: analysis notebooks computing STP loss curves, SVDs of representation differences, and loss plateaus (NTP vs. STP).
- Assumptions/dependencies: reproducibility across models/datasets; access to base model internals and training logs.
- Practical active learning and curriculum diagnostics
- Sectors: education technology, enterprise AI training.
- What to do: use per-batch STP loss as a diagnostic to identify examples or segments that strongly deviate from local linearity (potentially noisy/harder samples); adjust sampling or curriculum accordingly.
- Tools/workflows: data sampling utilities ranking segments by STP loss; adaptive curricula that focus on high-SNR batches.
- Assumptions/dependencies: correlation of STP loss with pedagogical value or data quality holds; limited risk of overfitting to “easier” linear segments.
Long-Term Applications
These applications likely require broader empirical validation, scaling studies, new algorithms, or cross-modal extensions before production deployment.
- Foundation model pretraining with STP to challenge scaling laws
- Sectors: AI platform companies, large labs.
- What to do: integrate STP at pretraining scale to reduce data requirements and preserve diversity; empirically validate generalization across corpora and tasks.
- Tools/products/workflows: pretraining frameworks supporting STP computation at scale; model cards reporting data-efficiency gains and diversity metrics.
- Assumptions/dependencies: geodesic hypothesis broadly holds; STP’s benefits persist at trillion-token scales; stability with distributed training.
- Inference-time geometry-aware decoding
- Sectors: general LLM deployment (software, finance, healthcare).
- What to do: develop decoders that monitor hidden-state geometry online (e.g., perpendicular drift to a learned tube) to correct or penalize divergence, potentially mitigating inference-time SDE drift.
- Tools/workflows: “geodesic monitor” modules that run alongside sampling; feedback controllers adjusting temperature or beam search based on drift.
- Assumptions/dependencies: reliable inference-time estimation of local geodesic direction; access to hidden states; efficient real-time computation.
- Cross-modal STP for sequential decision-making and multimodal learning
- Sectors: robotics, autonomous systems, AR/VR, speech.
- What to do: apply STP-like trajectory regularization to action sequences, sensor streams, or multimodal embeddings (text–vision–audio) to improve stability, data-efficiency, and diversity of policies or generation.
- Tools/workflows: multimodal training stacks (e.g., vision-language-action) with STP over temporal embeddings; robotics policy learning with local linearity constraints.
- Assumptions/dependencies: suitable continuous latent trajectories exist; careful handling of modality-specific dynamics; safety validation for physical systems.
- Data selection and active learning driven by geometric signals
- Sectors: education technology, enterprise knowledge management, annotation services.
- What to do: design data curation pipelines that prefer examples improving local linearity/SNR (low perpendicular components), or strategically include “high-curvature” examples for robustness.
- Tools/workflows: geometric scoring functions for data selection; curriculum schedulers balancing linearity and coverage.
- Assumptions/dependencies: validated link between STP metrics and generalization; avoidance of over-pruning diverse but valuable samples.
- Interpretability, steering, and concept editing via geodesic analysis
- Sectors: model governance, responsible AI, developer tooling.
- What to do: build tools that visualize hidden-state paths, identify concept directions, and steer generation by aligning with geodesics (unifying LRH and manifold perspectives).
- Tools/products/workflows: “Trajectory Explorer” dashboards; editing operations that keep sequences within semantic tubes; audits for curvature straightening.
- Assumptions/dependencies: robust mapping between trajectories and interpretable concepts; guardrails against misuse or oversteering.
- Integration with RLHF/DPO and multi-objective training
- Sectors: alignment teams, enterprise assistants.
- What to do: combine STP with preference optimization to reduce mode collapse and enhance stable reasoning chains under feedback; explore trajectory-wise action minimization beyond state-wise losses.
- Tools/workflows: hybrid training pipelines (SFT + STP + RLHF/DPO); evaluation suites measuring diversity, stability, and preference adherence.
- Assumptions/dependencies: compatible gradients and stable training dynamics; empirical gains across diverse feedback distributions.
- Fairness and diversity governance in generative systems
- Sectors: social platforms, media, policy.
- What to do: use STP to preserve minority styles or formats and resist homogenization; incorporate geometric diversity metrics into governance and audits.
- Tools/workflows: fairness dashboards tracking diversity preservation; policy guidelines referencing diversity-aware training.
- Assumptions/dependencies: demonstrated benefits across sensitive domains; safeguards against amplifying biased trajectories.
- Sustainability standards and policy for data-efficient AI
- Sectors: government, industry consortia, ESG programs.
- What to do: adopt standards encouraging SNR-improving objectives (like STP) to reduce training data and energy footprints; include geometric metrics in reporting.
- Tools/workflows: procurement requirements; ESG reporting templates; certifications for data-efficient training.
- Assumptions/dependencies: broad community validation; transparent measurement methodologies; alignment with existing regulatory frameworks.
Notes on Feasibility and Dependencies
- Empirical scope: While STP shows strong improvements (including 16× data-efficiency on NL-RX-SYNTH) and better accuracy across several datasets and models, broader validation across domains and very large scales is still needed.
- Architectural access: STP requires access to per-token hidden states (commonly available via open-weight Transformer libraries); closed APIs may restrict this.
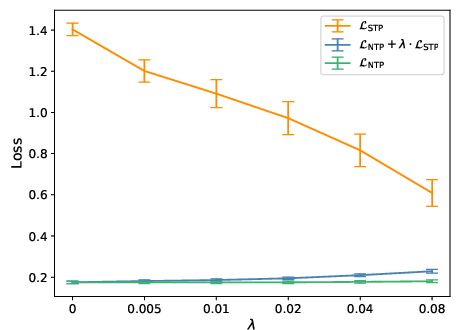
- Hyperparameter tuning: λ is task-dependent; reported effective ranges are typically 0.01–0.08 but should be validated per dataset/model.
- Inference behavior: STP is a training-only objective; inference-time drift (SDE behavior) may still require geometry-aware decoding or other safety mechanisms for the highest-stakes deployments.
- Diversity trade-offs: STP aims to preserve diversity; downstream evaluation should confirm that diversity remains aligned with utility and fairness goals.
- Compute overhead: The added cost is primarily cosine similarity; negligible relative to a forward pass, but must be profiled in edge deployments.
Glossary
- Autoregressive sequence models: Models that generate each token conditioned on previous tokens in a sequence. "a simplified form of self-consistency for autoregressive sequence models."
- Ballistic trajectories: Paths that evolve with near-constant direction locally, resembling straight-line motion in representation space. "proposing that token sequence trajectories can be modeled by an Ordinary Differential Equation (ODE) characterized by ballistic trajectories."
- Brownian motion: A stochastic process modeling random fluctuations, used here to capture inference-time noise. "the inference process can be modeled as a Stochastic Differential Equation (SDE) with a Brownian motion term."
- Chinchilla-style scaling laws: Empirical power-law relations describing optimal tradeoffs among data, compute, and model size. "directly violating the data term of Chinchilla-style scaling laws"
- Dimensional collapse: A failure mode where learned representations collapse into a low-dimensional subspace, reducing expressivity. "despite the risk of dimensional collapse"
- Energy-Based Models (EBMs): Models that assign low energy to compatible variable configurations and high energy to incompatible ones. "Our framework extends the philosophy of Energy-Based Models (EBMs)"
- Exposure Bias: The mismatch between training on ground-truth histories and inference on model-generated histories that can cause error accumulation. "addresses the classic Exposure Bias problem"
- Geodesic: The shortest path on a manifold; locally straight in the manifold’s geometry. "we hypothesize that error-free hidden state trajectories are geodesics, which are locally linear"
- Geodesic Hypothesis: The proposal that token and hidden-state trajectories follow locally linear geodesics on a semantic manifold. "If the Geodesic Hypothesis holds, it entails the following predictions:"
- Geometric priors: Inductive biases grounded in geometric structure (e.g., manifolds, geodesics) imposed on model representations. "demonstrating that principled geometric priors can surpass brute-force scaling."
- Identity predictor: A predictor that outputs its input unchanged; here, used because local linearity implies no transformation is needed. "as local linearity implies an identity predictor."
- Infinite-width limit: The theoretical regime where network width tends to infinity, simplifying training dynamics. "in the infinite-width limit"
- Joint-Embedding Predictive Architecture (JEPA): A self-supervised framework that predicts one view’s representation from another to learn shared embeddings. "Semantic Tube draws inspiration from the Joint-Embedding Predictive Architecture (JEPA)"
- Lagrangian: A function whose time integral (the action) is minimized by the system’s trajectory under the Principle of Least Action. "the integral of the Lagrangian over time"
- Linear Representation Hypothesis (LRH): The idea that concepts are encoded as directions in representation space. "The Linear Representation Hypothesis (LRH) posits that simple concepts are encoded as directions in the representation space,"
- Lipschitz-continuous: A smoothness condition ensuring bounded changes in outputs for bounded input changes. "If is Lipschitz-continuous"
- Manifold Hypothesis: The assumption that learned representations lie on or near a low-dimensional, smooth manifold. "The Manifold Hypothesis posits that learned representations form a simple and smooth manifold."
- Markov's inequality: A probabilistic bound used to relate expectations to tail probabilities. "By Markov's inequality, for any ,"
- Maximum Likelihood Estimation: A training principle maximizing the likelihood of observed data under the model. "Although Maximum Likelihood Estimation ( in the case of LLMs) is empirically effective,"
- Mode collapse: A degeneration where generations lose diversity and collapse to a few modes. "This leads to mode collapse"
- Multi-view augmentations: Creating different “views” of data for contrastive or predictive objectives; often costly in language settings. "without requiring explicit multi-view augmentations."
- Neural Tangent Kernel (NTK): A kernel that characterizes training dynamics in wide neural networks. "The Neural Tangent Kernel (NTK) simplifies infinite-width dynamics,"
- Next Token Prediction (NTP): The standard autoregressive objective of predicting the next token given the prefix. "the cross-entropy loss for Next Token Prediction (NTP)"
- Ordinary Differential Equation (ODE): A continuous-time equation modeling deterministic dynamics of sequences or states. "modeled by an Ordinary Differential Equation (ODE)"
- Picard-Lindelöf Theorem: A result guaranteeing existence and uniqueness of ODE solutions under smoothness conditions. "The Picard-Lindelöf Theorem guarantees that"
- Principle of Least Action: The physical principle that trajectories minimize the action (integral of the Lagrangian). "We hypothesize that the Principle of Least Action is at work."
- Semantic manifold: A smooth space hypothesized to underlie semantic structure of token sequences. "a smooth semantic manifold"
- Semantic Tube: A tubular neighborhood around the geodesic constraining hidden-state trajectories to be locally linear. "We designate this structure the Semantic Tube"
- Semantic Tube Prediction (STP): An auxiliary loss that enforces local linearity by aligning consecutive hidden-state differences. "we propose a novel Semantic Tube Prediction (STP) task"
- Signal-to-Noise Ratio (SNR): The proportion of meaningful signal relative to noise in training dynamics. "Minimizing the noise term is expected to improve the Signal-to-Noise Ratio (SNR) during training."
- Singular Value Decomposition (SVD): A matrix factorization revealing principal directions and magnitudes in data. "we compute the singular value decomposition (SVD) of "
- Stochastic Differential Equation (SDE): A differential equation with randomness (e.g., Brownian motion) modeling stochastic dynamics. "modeled as a Stochastic Differential Equation (SDE) with a Brownian motion term."
- Teacher Forcing: A training technique that feeds ground-truth tokens as inputs at each step. "trained with Teacher Forcing—conditioning on the ground-truth history—"
- Unembedding: The mapping from hidden states back to token logits or token space; errors here misalign hidden states and outputs. "unembedding errors"
- Voronoi cell: The region of space closest to a particular token embedding, partitioning representation space. "the correct Voronoi cell"
Collections
Sign up for free to add this paper to one or more collections.