StreamGaze: Gaze-Guided Temporal Reasoning and Proactive Understanding in Streaming Videos
Abstract: Streaming video understanding requires models not only to process temporally incoming frames, but also to anticipate user intention for realistic applications like AR glasses. While prior streaming benchmarks evaluate temporal reasoning, none measure whether MLLMs can interpret or leverage human gaze signals within a streaming setting. To fill this gap, we introduce StreamGaze, the first benchmark designed to evaluate how effectively MLLMs use gaze for temporal and proactive reasoning in streaming videos. StreamGaze introduces gaze-guided past, present, and proactive tasks that comprehensively evaluate streaming video understanding. These tasks assess whether models can use real-time gaze to follow shifting attention and infer user intentions from only past and currently observed frames. To build StreamGaze, we develop a gaze-video QA generation pipeline that aligns egocentric videos with raw gaze trajectories via fixation extraction, region-specific visual prompting, and scanpath construction. This pipeline produces spatio-temporally grounded QA pairs that closely reflect human perceptual dynamics. Across all StreamGaze tasks, we observe substantial performance gaps between state-of-the-art MLLMs and human performance, revealing fundamental limitations in gaze-based temporal reasoning, intention modeling, and proactive prediction. We further provide detailed analyses of gaze-prompting strategies, reasoning behaviors, and task-specific failure modes, offering deeper insight into why current MLLMs struggle and what capabilities future models must develop. All data and code will be publicly released to support continued research in gaze-guided streaming video understanding.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces StreamGaze, a new “test” (benchmark) to see how well AI models can understand live, streaming videos by using where a person is looking (their eye gaze). The goal is to build smarter helpers for things like AR glasses or robots that watch what you see in real time and help before you even ask.
What questions did the paper ask?
The researchers wanted to know:
- Can today’s AIs follow a person’s shifting attention in a live video using eye gaze?
- Can they understand what the person is doing right now and what they might do next?
- What kinds of tasks and data are needed to fairly test these abilities?
How did the researchers do it?
Think of eye gaze like a tiny flashlight on the screen: wherever the flashlight shines is what the person is paying attention to. The team built StreamGaze to connect that “flashlight” with video understanding.
Building the StreamGaze benchmark
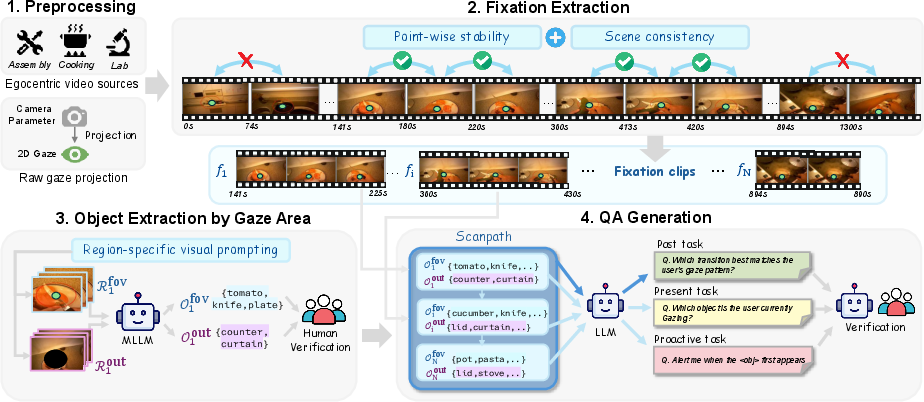
- Egocentric videos: They used videos taken from a person’s point of view (like wearing a head camera or AR glasses), so the camera shows what the person sees.
- Gaze tracking: They collected the person’s eye gaze—the exact spot on the screen where their eyes are looking at each moment.
- Fixations: When your eyes stop and “rest” briefly on something, that’s a fixation. The team found these stable moments to figure out what truly held the person’s attention (not the quick jumps between points).
- Field of View (FOV): They drew a small circle around the gaze point to mark the “focus area” (inside the circle) and everything else (outside the circle).
- Naming objects: They asked an AI to describe objects inside the FOV (what the person is focused on) and outside the FOV (background context), using simple visual cues like a colored dot and circle to show the gaze.
- Scanpath: They stitched fixations together over time—like a breadcrumb trail of attention—to show how the person’s gaze moved from object to object.
- Question generation: Using this gaze trail, they created different kinds of questions about the past, present, and future of the video. Humans then checked the questions and answers to make sure they were correct and clear.
In everyday terms: they matched what the person looked at, when they looked at it, and what was around them, then turned that into test questions for AIs.
The three kinds of tasks
To keep things clear, StreamGaze tests three timeframes, similar to how you’d help a friend in real time:
- Past: What happened before? Example tasks include remembering things that were visible but never directly looked at, or guessing the order of what the person looked at.
- Present: What’s happening now? Example tasks include naming the object the person is currently focusing on or identifying its attributes (like color or texture).
- Proactive (future): What might happen next? Example tasks include warning when a new object appears in the person’s side view, or predicting the user’s next action based on recent gaze.
What did they find?
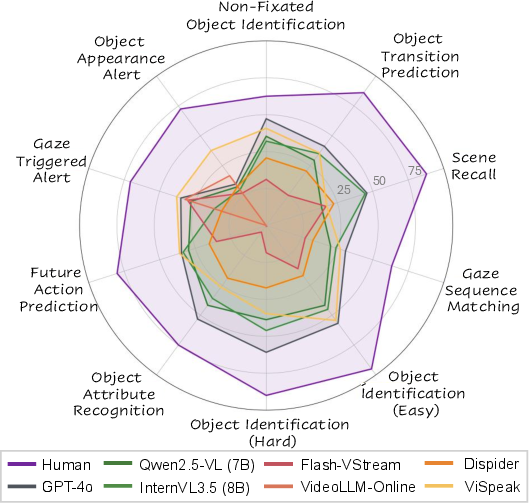
- Big gap between humans and AIs: People did much better than all tested AI models. Humans are naturally good at combining “where I looked,” “what’s around me,” and “what’s likely next.”
- Current AIs struggle with gaze over time: Popular multimodal AIs (that can see and read), including well-known ones, often fail to use gaze properly when the video keeps streaming. They tend to focus on single frames rather than the whole unfolding story.
- Proactive prediction is hard: Models often missed chances to alert at the right time, or alerted too early. Predicting what will happen next from gaze is still very challenging.
- Gaze-specialized models don’t generalize: A model trained on a previous (simpler, non-streaming) gaze dataset didn’t perform well in this live, time-sensitive setting.
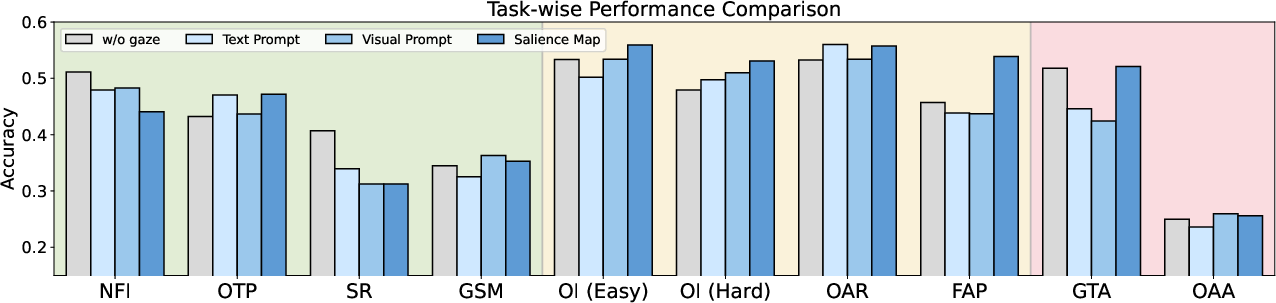
- Prompting helps, but not enough: Different ways of showing gaze to the model (like a dot on the frame or a heat map of gaze points) helped a bit in some tasks, but didn’t fix the core problems.
Why this matters: For helpful tools like AR assistants, it’s not enough to see the scene. The assistant must follow your attention, remember what just happened, and anticipate your needs—none of which current AIs do reliably yet.
Why this matters and what’s next
- Better real-time helpers: If AIs can learn to use gaze like humans do, AR glasses could highlight relevant tools during a repair, remind you of a missed step while cooking, or warn you about a hazard coming into view.
- More human-aligned AI: Eye gaze is a direct signal of what you care about. Using it well can make assistants feel more natural, helpful, and safe.
- Clear directions for future research: The results show that future models need stronger long-term memory, better ways to connect gaze shifts to events, and smarter prediction of intentions.
In short, StreamGaze gives researchers a realistic, gaze-aware testing ground. It shows where today’s AIs fall short and points the way toward assistants that truly understand what you’re looking at—right now and in the moments to come.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to be directly actionable for future research.
- Domain coverage is narrow (egocentric cooking/assembly/lab); generalization to outdoor, driving, social interaction, sports, and non-egocentric settings is untested.
- The FOV is modeled as a fixed circular region; the choice and physiological validity of the radius (τ_fov) per device/user are not justified or validated.
- Fixation detection thresholds (r_thresh, τ_dur) and scene consistency cutoff (τ_scene) are not reported; there is no sensitivity analysis, reproducibility guidance, or principled selection criteria.
- Scene consistency via Hue–Saturation histogram Pearson correlation may fail under illumination changes and motion blur; robustness to such cases is unexamined.
- Gaze noise handling is under-specified (e.g., saccades, micro-saccades, jitter); the pipeline’s tolerance to measurement noise and calibration drift is not quantified.
- Object extraction depends on an MLLM (InternVL3.5) rather than standard detectors/segmenters; error propagation from extraction to QA labels is not analyzed.
- Human verification is summarized (≈83% correctness) but lacks key details (annotator count, protocol, inter-annotator agreement, time per item); reliability and reproducibility remain unclear.
- Distractors are generated by Qwen3-VL-30B, yet Qwen2.5-VL is evaluated; potential cross-model bias/leakage is not assessed, and neutral distractor generation baselines are missing.
- Definitions and ground-truth rules for proactive triggers (GTA/OAA)—especially “first appearance,” partial/occluded visibility, and timing tolerance—are not formally specified.
- Most “streaming” evaluations are converted to offline clips; causality, latency, memory constraints, and online decision dynamics are not directly tested.
- Proactive evaluation relies on accuracy; cost-sensitive metrics (precision/recall, AUROC, F1), calibration (ECE), and trigger latency/time-to-detect are absent.
- Frame budgets and frame rates vary across models (16/32 frames, 1 fps, “adaptive”); comparability is confounded without standardized input budgets or fairness controls.
- There is no stratified analysis by dataset/domain/video length/head motion intensity/gaze noise level; factors driving failure modes remain unidentified.
- Overlaying gaze/FOV graphics may occlude content and bias perception; the impact of overlays vs separate channels vs coordinate streams is not studied.
- Salience maps outperform simple overlays, yet the optimal gaze encoding (temporal embeddings, gaze-conditioned cross-attention, learned gaze encoders) for MLLMs remains unexplored.
- The fixed memory window ω=60s is taken from prior work; sensitivity to shorter/longer horizons and task-specific optimal windows is not evaluated.
- Tasks like SR/OTP rely on MLLM-derived object sets; misdetections/miscaptions can corrupt labels—there is no confidence-aware scoring or label quality control analysis.
- Structured object annotations (categories, bounding boxes, tracks) aligned with gaze are missing; reliance on captions hinders objective grounding evaluation.
- Other embodied signals (audio, head pose, hand pose, IMU) are excluded; the benefit of multimodal fusion with gaze for intention and proactive prediction is unexplored.
- Open-ended outputs are scored via keyword regex for some models; more reliable semantic matching (LLM-as-judge with calibration, entailment metrics) is not employed or validated.
- Human baseline reporting lacks participant demographics, training, environment, time limits, and inter-rater reliability; the validity of human–model gaps is uncertain.
- Ethical and privacy implications of gaze-guided assistants (data collection, consent, sensitive inference risks) are not addressed; deployment guidelines are missing.
- Robustness to different eye trackers, camera calibrations, and calibration drift is untested; device variability handling and domain adaptation remain open.
- Task difficulty calibration (option balance, distractor similarity, guessing baselines) is not quantified; psychometric analyses (e.g., item response theory) are absent.
- There is no benchmark task for scanpath prediction or evaluation of predicted vs ground-truth scanpaths; extending StreamGaze to scanpath forecasting is an open direction.
- Train/val/test splits and protocols for fine-tuning models on StreamGaze are not specified; support for model development beyond zero-shot is unclear.
- Trigger timing granularity (frame vs second), temporal resolution effects, and sampling strategies on proactive evaluation are not analyzed.
- Cross-benchmark generalization (performance correlations with existing streaming/gaze benchmarks) is not studied; external validity remains unknown.
- Egocentric stabilization is limited (HS histograms); more robust approaches (optical flow, SLAM, video stabilization) are not investigated for improved gaze–content alignment.
- FOV vs “out-of-FOV” conflates peripheral/parafoveal vision; a graded salience model reflecting foveal, parafoveal, and peripheral regions is not considered.
- Filtering fixations by scene consistency may exclude challenging segments; selection bias and its impact on representativeness are not measured.
- The GTA task (“indicate user’s fixation”) risks being trivial or ill-defined; its practical utility, difficulty calibration, and error taxonomy need clarification.
- Failure analyses attribute weaknesses to capacity and frame sampling, but lack architectural ablations (memory modules, recurrence, explicit gaze-conditioning) that would pinpoint causal factors.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now by leveraging the paper’s benchmark, data-generation pipeline, and empirical insights on gaze prompting and proactive tasks.
- Gaze-aware evaluation suite for streaming assistants (academia, software/AI R&D)
- What: Use StreamGaze to benchmark MLLMs/VideoLLMs for gaze-conditioned past, present, and proactive reasoning.
- Tools/workflows: Integrate StreamGaze into CI for model releases; add task-wise dashboards (NFI, OTP, SR, GSM, OI, OAR, FAP, GTA, OAA) for regression testing; human-vs-model gap tracking.
- Assumptions/dependencies: Public release of dataset/code; ability to run models on controlled clips (offline evaluation).
- Gaze-to-QA data generation for internal datasets (software/AI R&D)
- What: Adopt the fixation extraction + FOV/out-of-FOV object extraction + scanpath construction pipeline to turn egocentric logs into training/eval QA pairs.
- Tools/workflows: “Gaze QA Generator” service for annotation teams; auto-generation + human verification loop.
- Assumptions/dependencies: Collect eye-tracking and egocentric video; calibration quality; human-in-the-loop capacity.
- Proactive alert prototyping in AR headsets using GTA/OAA policies (AR/VR, manufacturing, field service, safety)
- What: Implement rule-based “gaze-triggered alert” and “object appearance alert” as early-stage UX prototypes on AR devices (e.g., HoloLens/Quest, AR glasses).
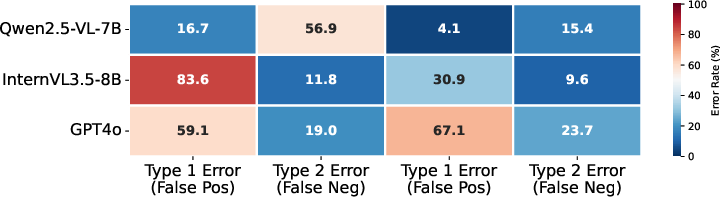
- Tools/workflows: On-device object detection + gaze overlays for hazard/target appearance; OAA/GTA decision logic; error-type (Type 1/Type 2) monitoring as in the paper’s analysis.
- Assumptions/dependencies: Eye-tracking hardware; low-latency detection; domain-specific object catalogs; privacy consent.
- Gaze salience prompting to improve model inputs (software/AI R&D)
- What: Replace per-frame gaze dots with aggregated “salience-map” prompts when feeding videos to MLLMs, which the paper found to work best among tested prompting strategies.
- Tools/workflows: Preprocessor that converts gaze trajectories to heatmaps; inference pipelines that attach the heatmap as an additional image channel.
- Assumptions/dependencies: Same model (e.g., Qwen2.5-VL) may still be gaze-naïve; results may vary by model and task.
- Usability testing and attention analytics for product teams (industry UX, human factors)
- What: Use scanpath extraction and task taxonomy to analyze where users look, what they miss, and how attention shifts, during software or device testing.
- Tools/workflows: “Scanpath Analytics” dashboard; NFI/SR tasks to quantify missed-but-visible content; A/B testing for UI changes.
- Assumptions/dependencies: Egocentric capture or screen-based eye-tracking; participant consent; data governance.
- Training data augmentation for gaze-aware models (academia, software/AI R&D)
- What: Fine-tune existing VideoLLMs with gaze-grounded QA pairs generated via the proposed pipeline to build stronger temporal and intention modeling.
- Tools/workflows: Curriculum that mixes present (OI/OAR) with past (SR/GSM/OTP) and simple proactive (GTA/OAA) tasks.
- Assumptions/dependencies: Compute budget; licensing for base models; domain mismatch between cooking/assembly footage and target domain.
- Robotics teleoperation logging and replay analytics (robotics, HRI)
- What: Analyze human operator gaze + video during teleoperation to distill fixation moments and object transitions that correlate with expert behavior.
- Tools/workflows: Replay tool using scanpaths; OTP/GSM tasks to identify expert attention patterns for training newcomers.
- Assumptions/dependencies: Access to teleop video + gaze; synchronization accuracy; safety/privacy compliance.
- Safety-critical situational awareness checks (transport, warehousing, construction)
- What: Post-hoc audits using NFI/SR tasks to determine whether workers/drivers had visual exposure to hazards without fixating on them.
- Tools/workflows: Audit reports that flag missed-but-present hazards (NFI) and scene-memory gaps (SR); policy-driven interventions.
- Assumptions/dependencies: Recording permission and data retention policies; hazard ontologies; legal/HR frameworks.
- Adaptive e-learning content based on gaze (education)
- What: Use fixation- and scanpath-based indicators to adapt video tutorials (e.g., cooking, lab training) and trigger remedial tips when key objects are overlooked.
- Tools/workflows: OAA-triggered hints; SR-based short quizzes about recently seen but unattended items to reinforce context.
- Assumptions/dependencies: Gaze-enabled devices for learners; acceptable latency; instructor buy-in.
- Benchmark-driven procurement and standards (policy, enterprise IT)
- What: Use StreamGaze scores to specify minimum performance thresholds for AR assistants or streaming perception systems that must handle user attention.
- Tools/workflows: RFP templates that reference StreamGaze tasks and error-type constraints for proactive alerts.
- Assumptions/dependencies: Broad acceptance of the benchmark; cross-domain generalizability.
Long-Term Applications
Below are applications that require further research, robust scaling, specialized models, or hardware/software maturation.
- Proactive, gaze-aware AR assistants with robust intention modeling (AR/VR, field service, healthcare, education)
- Vision: Assistants that anticipate the user’s next step (FAP) and surface timely guidance or safety prompts with low false alarms.
- Potential products: “Gaze-Intent AR Coach” for assembly/surgery/maintenance; “Attention-Aware Tutor” for lab and vocational training.
- Dependencies: On-device streaming models supporting long context; robust gaze calibration in motion; high-quality domain datasets; safety certification.
- Human-robot collaboration (HRC) using gaze-conditioned policies (robotics, manufacturing)
- Vision: Robots that interpret human gaze to understand task focus, yield workspace, or hand over tools proactively.
- Potential workflows: OTP/GSM-based learning of human attention shifts to inform robot anticipation and planning.
- Dependencies: Real-time gaze-to-scene grounding; joint perception/action planning; standardized HRC safety protocols; liability frameworks.
- Driver/operator monitoring with anticipatory alerts (automotive, heavy machinery)
- Vision: Systems that compare gaze scanpaths to hazard dynamics and proactively alert when critical objects appear outside FOV or are never fixated (OAA/NFI).
- Potential products: Advanced Driver Assistance Systems (ADAS) plugins leveraging gaze+video fusion.
- Dependencies: High-reliability sensors; domain adaptation beyond egocentric kitchen/assembly; stringent validation and regulatory approval.
- Clinical and assistive technologies based on attention patterns (healthcare)
- Vision: Assessment tools for attention disorders (e.g., ADHD) and rehabilitation platforms that adapt exercises from gaze-derived scanpaths.
- Potential products: “Gaze-Behavior Assessment Suite” for clinicians; home-care assistants that detect missed medications or steps.
- Dependencies: Clinical trials; privacy-preserving pipelines; medical device regulations; demographic generalization.
- Privacy-preserving, on-device gaze processing stacks (software/edge AI, policy)
- Vision: Local fixation detection, salience-map generation, and proactive decision logic that never uploads raw gaze/video.
- Potential products: “On-Device Gaze SDK” with differential privacy options and standardized consent flows.
- Dependencies: Efficient on-device inference; clear regulatory guidance; hardware support (secure enclaves).
- UI/UX that adapts to user attention in real time (software, productivity)
- Vision: Interfaces that reflow or highlight elements when gaze suggests confusion or missed content; dashboards that surface SR-based recaps.
- Potential products: “Attention-Adaptive IDE/Documentation Viewer” that reveals context when users miss references.
- Dependencies: Screen-based eye-tracking ubiquity; reliable reactive design patterns; user acceptance.
- Gaze-conditioned model architectures and training curricula (academia, software/AI R&D)
- Vision: New VideoLLM architectures with explicit gaze channels, temporal memories for scanpaths, and objective functions aligned to StreamGaze tasks.
- Potential tools: Pretraining with gaze self-supervision; multi-task heads for NFI/SR/FAP/GTA/OAA; task-aware prompting agents.
- Dependencies: Larger-scale gaze-video corpora; training compute; reproducible evaluation beyond current domains.
- Standardized certifications for attention-aware systems (policy, industry consortia)
- Vision: Sector-specific benchmarks and acceptance criteria (e.g., acceptable proactive alert error rates, recall of unseen hazards) rooted in StreamGaze methodology.
- Potential workflows: Third-party testing labs; compliance badges for procurement.
- Dependencies: Multi-stakeholder consensus; extensions to diverse tasks/environments.
- Retail and consumer analytics from in-store egocentric sessions (retail, marketing)
- Vision: Analyze attention to shelves/products; detect missed promotions; optimize layouts based on NFI/SR-derived metrics.
- Potential tools: “Gaze-Behavior Insights” with scanpath heatmaps and object transition reports.
- Dependencies: Consent and privacy compliance; robust object catalogs; bias mitigation.
- Content creation and editing tools using attention signals (media, education)
- Vision: Automatic highlight reels or instruction overlays based on where creators/learners focused; pacing tuned to gaze dynamics.
- Potential products: “Gaze-Guided Editor” that aligns cuts to viewer attention or instructor fixations.
- Dependencies: Creator workflows with gaze capture; integration with NLEs; editorial standards.
- Workforce training simulators with attention scoring (enterprise training)
- Vision: Simulators that score trainees on whether they attend to critical elements (NFI) and recall scene context (SR), with proactive feedback.
- Potential tools: “Scanpath-Based Scoring Engine” integrated into VR/AR training platforms.
- Dependencies: Synthetic or domain-specific content; standardized rubrics; longitudinal validation.
- Multimodal safety copilots with calibrated proactive behavior (cross-industry)
- Vision: Systems that tune alert thresholds based on task risk and model’s error-type profile (as analyzed in the paper).
- Potential workflows: Policy-based alert managers that adapt to operator role and environment.
- Dependencies: Rich error analytics; governance frameworks; incident response integration.
Cross-Cutting Assumptions and Dependencies
- Hardware: Eye-tracking AR glasses or screen-based trackers; accurate, low-latency gaze capture and calibration under motion.
- Data: Domain-relevant egocentric video with object labels; object taxonomies for alerts; consented collection and retention policies.
- Models: VideoLLMs capable of streaming/long-context reasoning; task-aware prompting; on-device or near-edge inference to meet latency constraints.
- Generalization: StreamGaze domains (cooking/assembly/lab) differ from many target settings; transfer learning or new data collection may be required.
- Privacy and ethics: Strong governance for gaze data (highly sensitive biometric/behavioral signal); transparent consent and local processing where possible.
- Safety: Proactive systems must manage false positives/negatives; human factors validation, fail-safe designs, and sector-specific certifications are needed.
Glossary
- AR-glass assistants: Wearable augmented reality devices that provide real-time visual information and support to users. "Such capability is essential for real-world applications such as robotics, embodied agents, and AR-glass assistants"
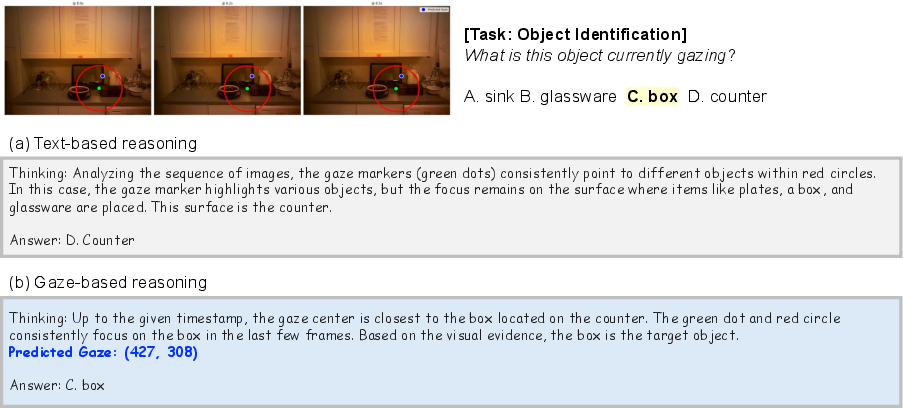
- Chain-of-thought prompting: A prompting technique that encourages models to reason step by step before answering. "For textual reasoning, we apply standard chain-of-thought prompting"
- Ego-motion: The motion of the camera or observer causing the visual scene to change with the user's movement. "how objects enter the user's FOV (Field of View) through ego-motion"
- Egocentric videos: First-person perspective videos captured from the viewpoint of the user. "we develop a gaze–video QA generation pipeline that aligns egocentric videos with raw gaze trajectories via fixation extraction, region-specific visual prompting, and scanpath construction"
- Embodied agents: AI systems situated within a physical environment and capable of perception and action. "applications such as robotics, embodied agents, and AR-glass assistants"
- Field of View (FOV): The area in the visual field that the user is focusing on around the gaze point. "how objects enter the user's FOV (Field of View) through ego-motion"
- Fixation: A period when the eyes remain relatively stable, indicating focused visual attention. "We primarily target fixation moments, intervals where the gaze remains relatively stable within a localized region"
- Foveal region: The central area of the retina responsible for sharp vision, often modeled as a small area around the gaze point. "which models the foveal and parafoveal regions as circular areas around the gaze point"
- Future Action Prediction (FAP): A task that predicts the user’s next action from recent gaze-conditioned context. "Future Action Prediction (FAP): Models intention inference by predicting the user’s next action"
- Gaze trajectory: The sequence of gaze coordinates over time that represents where the user is looking. "To obtain the gaze trajectory ... we project raw gaze in world coordinates onto the 2D image plane using officially provided camera parameters"
- Gaze Sequence Matching (GSM): A task that measures how well models capture sequential patterns in gaze transitions. "Gaze Sequence Matching (GSM): Measures how well models capture human-like scanpath patterns through sequential gaze transitions"
- Gaze-Triggered Alert (GTA): A proactive task that triggers an alert when the user fixates on a specified object. "Gaze-Triggered Alert (GTA): Triggers an alert when the user gaze a specified object within $\mathcal{R}_i^{\text{fov}$"
- Gaze-conditioned: Conditioned on or guided by gaze signals to influence understanding or prediction. "StreamGaze provides a unified suite of gaze-conditioned tasks spanning past, present, and proactive reasoning"
- Hue–Saturation histograms: Color feature histograms computed from hue and saturation channels to assess scene consistency. "we compute frame-wise Hue–Saturation histograms for all frames"
- Intention modeling: Inferring the user’s goals or future actions from perceptual cues like gaze. "revealing fundamental limitations in gaze-based temporal reasoning, intention modeling, and proactive prediction"
- MLLMs (Multimodal LLMs): LLMs that process multiple modalities such as text and video. "We introduce StreamGaze, the first benchmark designed to evaluate how effectively MLLMs use gaze for temporal and proactive reasoning in streaming videos"
- Multi-triggering query protocol: An evaluation protocol that repeatedly queries models over time to simulate online decision-making. "we adopt a multi-triggering query protocol following~\cite{niu2025ovo,lin2024streamingbench} to simulate online decision-making"
- Non-Fixated Object Identification (NFI): A task that identifies objects that were visible but never directly fixated. "Non-Fixated Object Identification (NFI): Evaluates implicit visual awareness by identifying objects that were visible but never directly fixated"
- Object Appearance Alert (OAA): A proactive task that alerts when a specified object first appears outside the current FOV. "Object Appearance Alert (OAA): Triggers an alert when the specified object first appears in the peripheral region $\mathcal{R}_i^{\text{out}$"
- Object Attribute Recognition (OAR): A task that predicts visual attributes (e.g., color, shape) of the currently fixated object. "Object Attribute Recognition (OAR): Assesses fine-grained perceptual understanding by predicting visual attributes"
- Object Transition Prediction (OTP): A task that predicts the next object to be fixated based on current gaze. "Object Transition Prediction (OTP): Assesses temporal continuity in gaze behavior by predicting the next object to be fixated"
- Offline inference: Evaluating models by providing pre-recorded inputs rather than streaming data in real time. "we convert all streaming tasks into offline inference by providing each model with the corresponding video clip"
- Parafoveal region: The area surrounding the fovea that supports peripheral but still detailed vision. "which models the foveal and parafoveal regions as circular areas around the gaze point"
- Pearson correlation: A statistical measure of linear correlation between two variables, used here for histogram similarity. "we then measure the minimum Pearson correlation between consecutive histograms"
- Proactive understanding: Anticipating future events or user intentions from current perceptual cues. "leaving out proactive understanding, the ability to anticipate future events and user intentions"
- Region-specific visual prompting: Guiding a model’s attention by cropping or masking image regions based on gaze. "Region-specific visual prompting. To extract objects from each region, we employ a MLLM (InternVL3.5-38B) with spatially guided visual prompts"
- Salience-map prompt: A prompting input constructed by aggregating gaze into a heatmap image. "In the salience-map prompt, the entire gaze trajectory is aggregated into a single heatmap, which is then provided as an additional image input"
- Saccadic: Rapid eye movements between fixation points. "compared to rapid eye shifts (i.e., saccadic)"
- Scanpath: The ordered sequence of fixations representing how attention shifts over time. "we construct a scanpath that represents the temporal evolution of gaze-guided object observations"
- Scene consistency: Ensuring visual continuity across frames within a fixation to avoid abrupt changes. "Scene consistency. Even if a fixation satisfies spatial and temporal stability, abrupt scene changes may occur due to camera motion or cuts"
- Scene Recall (SR): A task that tests recalling background objects previously visible during a fixation. "Scene Recall (SR): Tests contextual memory by recalling background objects previously visible during a fixation"
- Spatio-temporally grounded QA pairs: Question–answer pairs that are anchored to specific locations and times in the video. "This pipeline produces spatio-temporally grounded QA pairs that closely reflect human perceptual dynamics"
- Streaming video understanding: Interpreting and responding to incoming video frames in real time without future context. "Streaming video understanding requires models to interpret and respond to temporally incoming frames without access to future context"
- Temporal reasoning: Reasoning over time to connect past, present, and anticipated future events. "revealing fundamental limitations in gaze-based temporal reasoning"
- Visual prompting: Providing visual cues (e.g., overlays, masks, heatmaps) to guide model inference. "We employ a visual prompting strategy inspired by~\cite{peng2025eye}"
Collections
Sign up for free to add this paper to one or more collections.

