- The paper presents AccidentBench, a benchmark designed to rigorously evaluate temporal, spatial, and intent reasoning in safety-critical scenarios.
- It compiles around 2,000 videos and 19,000 human-annotated QA pairs to systematically measure model performance across varying task difficulties and video lengths.
- Experimental findings highlight significant performance degradation in state-of-the-art models, especially on complex intent-based reasoning tasks.
AccidentBench: A Comprehensive Benchmark for Multimodal Reasoning in Safety-Critical Scenarios
Motivation and Scope
The AccidentBench benchmark addresses a critical gap in the evaluation of large multimodal models (LMMs) by focusing on real-world, safety-critical scenarios, particularly vehicle accidents, as well as high-stakes domains in air and water. Existing benchmarks often emphasize general video understanding or isolated reasoning skills, but lack systematic coverage of dynamic, physically grounded, and causally complex environments where robust temporal, spatial, and intent reasoning is essential for safe AI deployment. AccidentBench unifies these requirements, providing a rigorous testbed for evaluating and advancing the capabilities of multimodal models in domains where failure can have severe consequences.

Figure 1: AccidentBench logo, representing its focus on safety-critical multimodal evaluation.
Benchmark Design
AccidentBench comprises approximately 2,000 real-world videos and over 19,000 human-annotated question–answer pairs. The dataset is dominated by vehicle accident scenarios (83%), with additional coverage of airplane navigation (10.2%) and ship motion (6.8%). Each scenario is annotated with tasks that systematically probe three core reasoning capabilities:
- Temporal Reasoning: Understanding event sequences, causality, and motion over time.
- Spatial Reasoning: Assessing dynamic spatial relationships, localization, and multi-agent trajectories.
- Intent Reasoning: Inferring agent goals, planning, and counterfactual reasoning.
Tasks are stratified by difficulty (easy, medium, hard) and video length (short, medium, long), with answer formats ranging from coarse interval-based to fine-grained accuracy-based choices. This design enables controlled evaluation of model performance as a function of both scenario complexity and required reasoning precision.
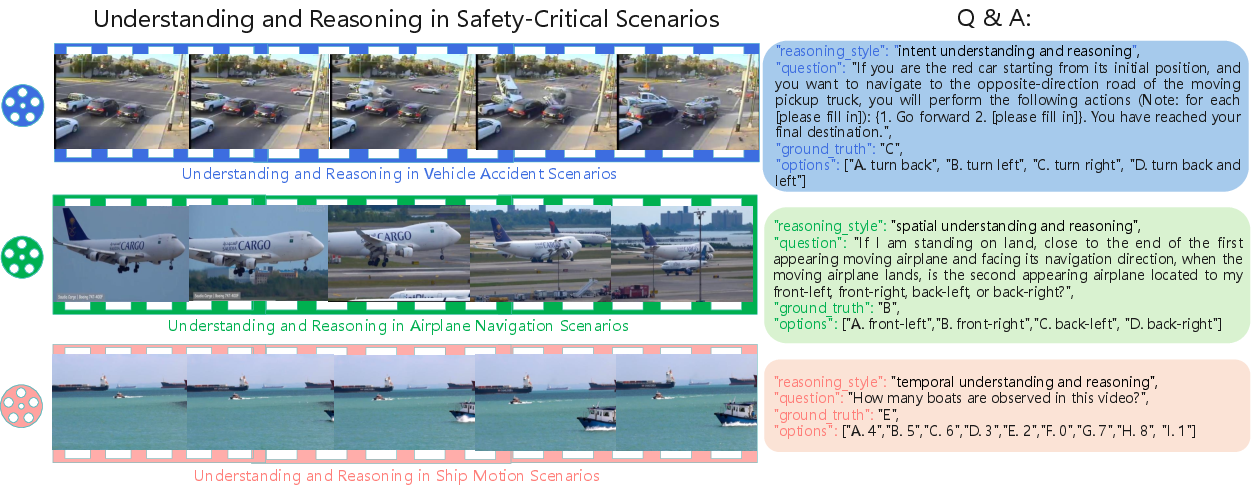
Figure 2: Examples of multimodal understanding and reasoning in vehicle accident and other safety-critical scenarios.

Figure 3: Land-space traffic accident scenarios for open-space video understanding and reasoning, illustrating the diversity of environments and conditions.

Figure 4: Examples of question settings across temporal, spatial, and intent reasoning types.
Dataset Analysis
The dataset is characterized by a strong emphasis on short, dynamic scenarios (76.5% of videos <10s), but also includes longer, more complex sequences. The distribution of task types is balanced across temporal (34.0%), spatial (35.4%), and intent (30.6%) reasoning, ensuring comprehensive coverage of the key dimensions required for robust real-world understanding.
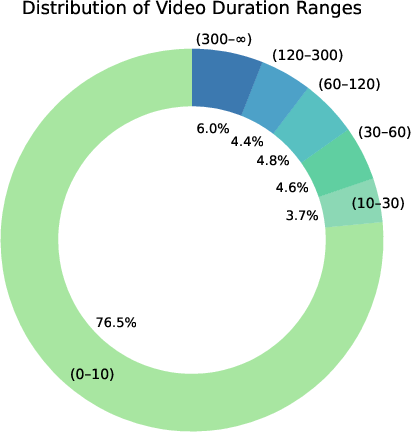
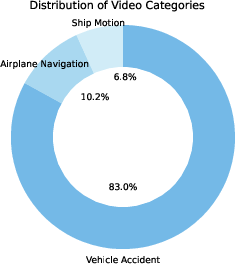
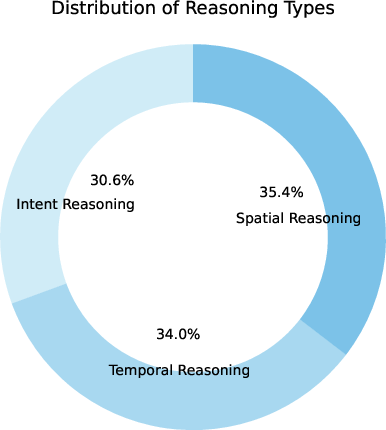
Figure 5: Distribution of video durations, scenario categories, and reasoning task types in AccidentBench.
Experimental Evaluation
A broad suite of state-of-the-art proprietary and open-source LMMs was evaluated on AccidentBench, including GPT-5, Gemini 2.5 Pro, GPT-4o, Claude 3.5, InternVL2.5, Qwen2.5 VL, and LLaVA variants. The evaluation reveals several key findings:
- Performance Degradation with Task Complexity: All models exhibit a marked decline in accuracy as task difficulty and video length increase. For hard, accuracy-based tasks on long videos, even the best models (e.g., GPT-5, Gemini 2.5 Pro) achieve only ~18% accuracy, far from reliable real-world operation.
- Reasoning Type Sensitivity: Intent reasoning is consistently the most challenging, followed by temporal and then spatial reasoning. This trend is robust across all domains (land, air, water).
- Proprietary vs. Open-Source Models: Proprietary models outperform open-source counterparts, but none demonstrate robust, generalizable reasoning across all settings. InternVL2.5 (26B) is the strongest open-source model, but still lags behind leading proprietary systems.
- Domain Transfer: Performance in underexplored domains (airplane navigation, ship motion) is even lower, highlighting the lack of generalization and the need for domain-specific adaptation.

Figure 6: Qualitative error analysis of SOTA multimodal models (Gemini 2.5 and GPT-4o) on AccidentBench, illustrating persistent failure cases in spatial, temporal, and intent reasoning.
Error Analysis
Qualitative analysis reveals that even top-performing models struggle with:
- Accurate spatial localization and object counting in dynamic scenes.
- Tracking causality and temporal dependencies over extended sequences.
- Inferring agent intent and reasoning about counterfactuals or strategic interactions.
These limitations are especially pronounced in safety-critical, perception-intensive tasks, underscoring the inadequacy of current LMMs for deployment in real-world, high-stakes environments.
Benchmarking Methodology
AccidentBench employs a uniform sampling strategy for large-scale evaluation, ensuring representative coverage while managing computational cost. Ablation studies confirm that sampled subsets yield performance estimates consistent with full-dataset evaluation, validating the reliability of the reported results.

Figure 7: Example of a question–answer template, illustrating the systematic coverage of reasoning types and video lengths.
Implications and Future Directions
AccidentBench exposes critical gaps in the current generation of LMMs, particularly in their ability to perform robust, physically grounded reasoning in dynamic, safety-critical settings. The benchmark's comprehensive coverage of temporal, spatial, and intent reasoning across land, air, and water domains provides a diagnostic tool for identifying failure modes and guiding model development.
Practical Implications:
- AccidentBench can be used to evaluate and compare LMMs for deployment in autonomous driving, robotics, aviation, and maritime applications, where safety and reliability are paramount.
- The benchmark's fine-grained task stratification enables targeted analysis of model weaknesses, informing the design of training curricula, data augmentation strategies, and architectural innovations.
Theoretical Implications:
- The persistent failure of LMMs on complex, long-horizon, and intent-based reasoning tasks suggests fundamental limitations in current model architectures and training regimes.
- Progress on AccidentBench will likely require advances in temporal modeling, causal inference, and multi-agent reasoning, as well as improved integration of physical priors and domain knowledge.
Future Developments:
- Extension of AccidentBench to additional safety-critical domains (e.g., industrial automation, healthcare).
- Development of new evaluation metrics that better capture real-world risk and safety considerations.
- Integration with simulation environments for closed-loop testing and reinforcement learning.
Conclusion
AccidentBench establishes a new standard for the evaluation of multimodal understanding and reasoning in safety-critical, real-world scenarios. By systematically exposing the limitations of current LMMs across temporal, spatial, and intent reasoning tasks, it provides both a challenge and a roadmap for the development of safer, more robust, and more generalizable AI systems. The benchmark is poised to play a central role in advancing the state of the art in multimodal AI for high-stakes applications.