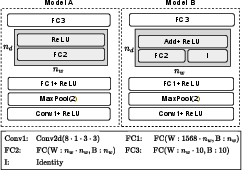
- The paper introduces a novel conjugate learning theory that explains trainability and generalization through convex duality and gradient energy bounds.
- It rigorously establishes Fenchel-Young losses as the unique, well-behaved loss functions while detailing the effects of architecture, SGD, and overparameterization.
- Empirical results validate the theory across multiple architectures, linking design choices like skip connections to improved optimization and generalization.
Conjugate Learning Theory: Unified Principles of Deep Neural Network Trainability and Generalization
Introduction and Motivation
"Conjugate Learning Theory: Uncovering the Mechanisms of Trainability and Generalization in Deep Neural Networks" (2602.16177) provides a comprehensive theoretical framework uniting the study of trainability and generalization in deep neural networks (DNNs). The major challenge addressed is the lack of a theory that explains why overparameterized, highly non-convex DNNs are efficiently trainable with simple SGD and simultaneously demonstrate superior generalization even in regimes where classical theory would predict overfitting. The proposed framework, rooted in convex conjugate duality, not only subsumes much of existing loss function theory, but also communicates how model architecture—depth, width, parameter sharing—and data properties conspire to produce observed learning dynamics.
Theoretical Foundations: Practical Learnability and the Conjugate Framework
The paper builds on the statistical insight that conditional distribution estimation from finite data is fundamentally constrained by the Pitman-Darmois-Koopmans theorem, restricting "practically learnable" conditional distributions to the exponential family unless extra structure is imposed. Consequently, virtually all machine learning problems become conditional exponential family estimation, typically solved by minimizing the negative log-likelihood.
This insight yields a formalization: all practical learning objectives can be cast as the minimization of a Fenchel-Young loss—induces by a strictly convex generating function—between the target and dual-transformed model output, subject to convex constraints encoding domain knowledge. This formal construction is general, directly encompassing softmax cross entropy, MSE, and many other standard objectives.
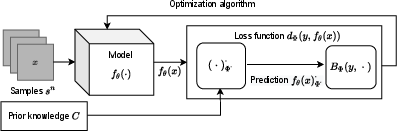
Figure 1: Schematic illustration of the conjugate learning framework: input transformation, model output, conjugate mapping, and target approximation are tightly integrated via duality.
Key Advancements:
- Rigorously proves that Fenchel-Young losses are the unique class of well-behaved (differentiable, strictly convex, proper) loss functions for finite data estimation.
- Explicitly quantifies and leverages convex constraints (e.g., probability simplex for classification), showing architectural mechanisms such as softmax emerge naturally in the conjugate duality view.
- Offers a universal protocol for integrating prior knowledge and ensuring target space consistency.
Mechanisms of Trainability: Gradient Energy and Structure Matrix
A central theoretical contribution is the identification of the "structure matrix" Ax=∇θfθ(x)∇θfθ(x)⊤, which characterizes the sensitivity of model output to parameters and encodes architectural properties such as depth, width, skip connections, and parameter sharing.
The gradient energy (expected squared gradient norm of loss w.r.t. parameters) is shown to tightly bound the empirical (training) risk, up to scalar factors determined by the extremal eigenvalues of the structure matrix:
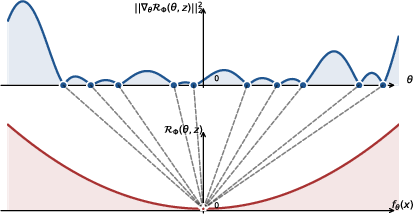
Figure 2: Mapping of gradient energy minima to empirical risk minima, with critical dependence on the conditioning of the structure matrix.
Critical Theoretical Results:
Optimization Dynamics: SGD, Batch Size, and Gradient Correlation
The analysis of SGD is generalized: convergence of gradient energy can be tightly bounded in terms of a "gradient correlation factor" M, which quantifies how mini-batch updates transfer to out-of-batch samples. Crucially, M is reduced by (a) smaller batch sizes, (b) more parameter independence, (c) sparser connectivity—all properties that both empirical practice and architecture search favor for robust optimization.
Hence, controlling the structure matrix (by architecture), gradient energy (by SGD and batch/batch-size tuning), and M yields a unified recipe for efficient trainability in deep models.
Sharp Generalization Bounds: Deterministic and Probabilistic
Generalization analysis leverages generalized (and classical) conditional entropy, deriving:
- Deterministic generalization bounds: For any sampling method, the generalization gap is upper bounded by model-specific factors (maximum loss γΦ, relative/absolute information loss via the model, and generalized conditional entropy of the data). This bound is architecture-agnostic and does not require i.i.d. assumptions.
- Probabilistic bounds: For i.i.d. samples, the generalization error's distribution is controlled by the effective support size of the feature space (collapsed by absolute information loss), sample size, model output stability (γΦ), and data distribution smoothness.
- The theory unifies regularization (e.g., via L2 or Lp norm) as explicitly controlling γΦ, thus linking norm-based parameter control directly to tight generalization bounds rather than solely as implicit bias.
Empirical Validation
Comprehensive experiments are performed with classic architectures (LeNet, ResNet18, ViT) and custom ablation networks across multiple datasets to empirically substantiate:
- Throughout training, the upper and lower theoretical bounds (function of structure matrix eigenvalues and gradient energy) match observed empirical risk closely.
- Skip connections, depth scaling, and width scaling impact the structure matrix exactly as predicted by the theory. Overparameterization reliably reduces the spectral gap, and deeper residual architectures maintain manageable eigenvalues.
- Dynamic correlation measurements (via sliding window Pearson coefficients) confirm that empirical risk is controlled by gradient energy only when structure matrix eigenvalues have stabilized, as the theory predicts.
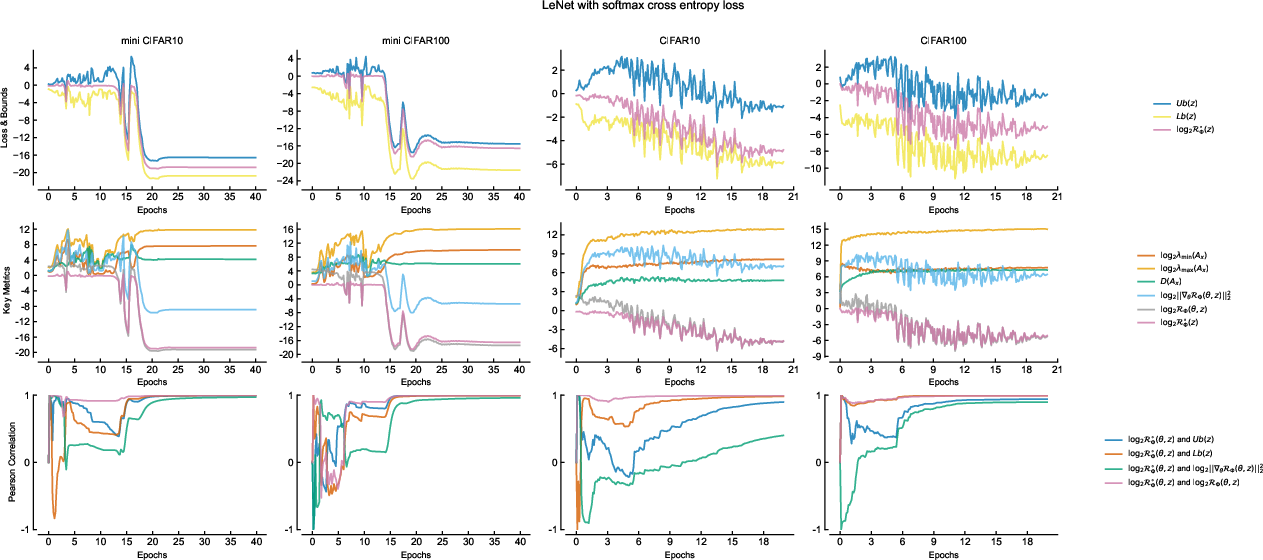
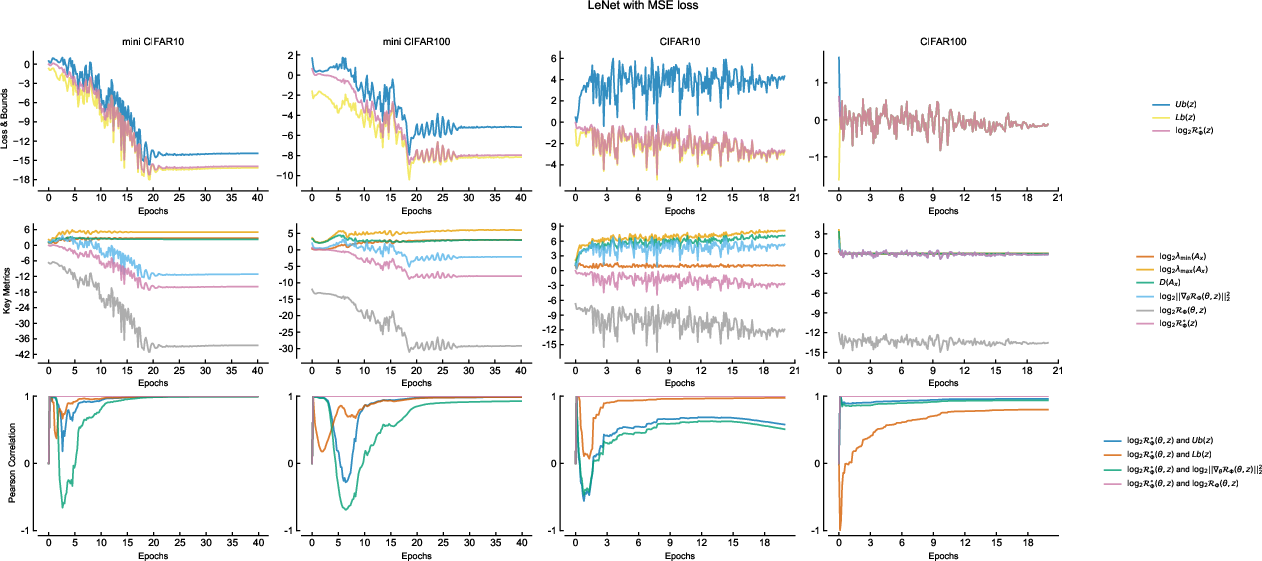
Figure 4: Training dynamics for LeNet under softmax cross entropy: empirical risk and theoretical bounds evolve in lockstep throughout training.
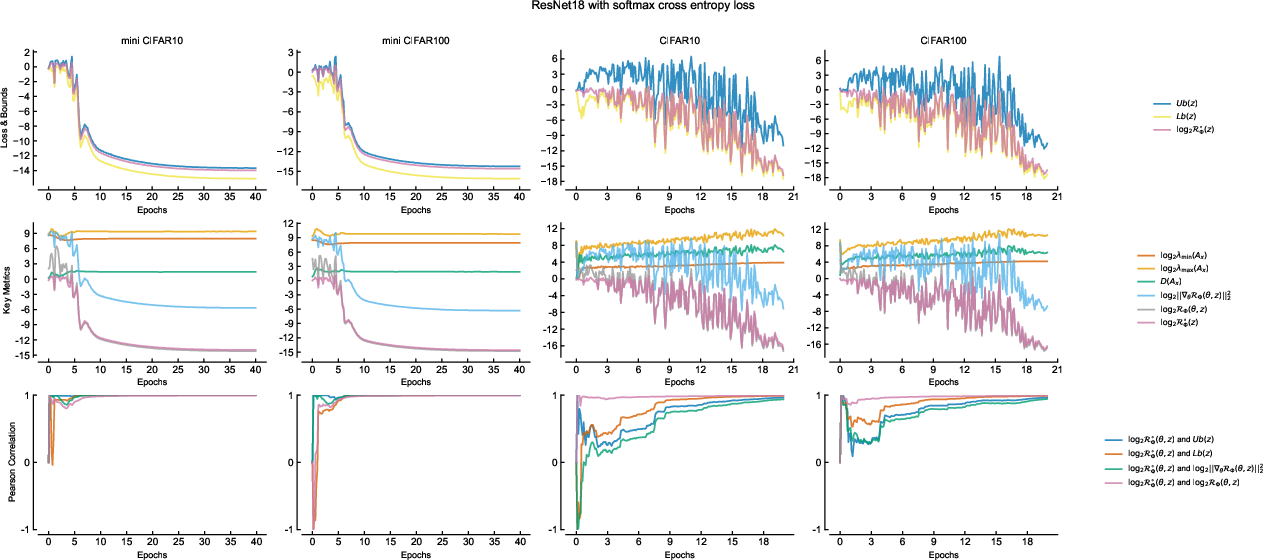
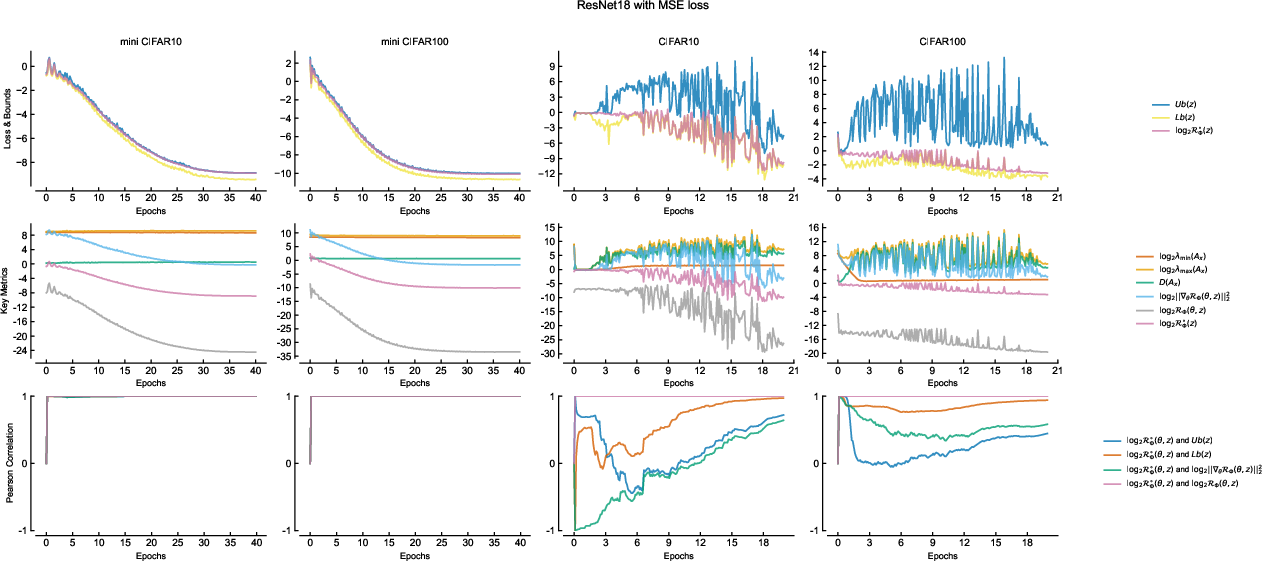
Figure 5: Training dynamics for ResNet18 with softmax cross entropy, showing similar empirical-theoretical matching.
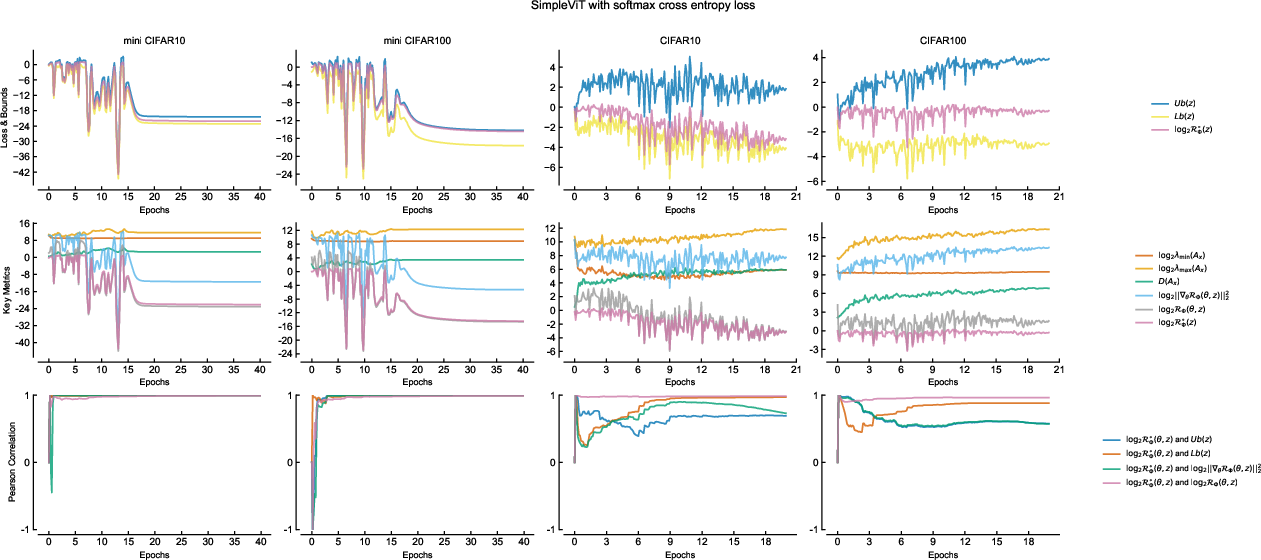
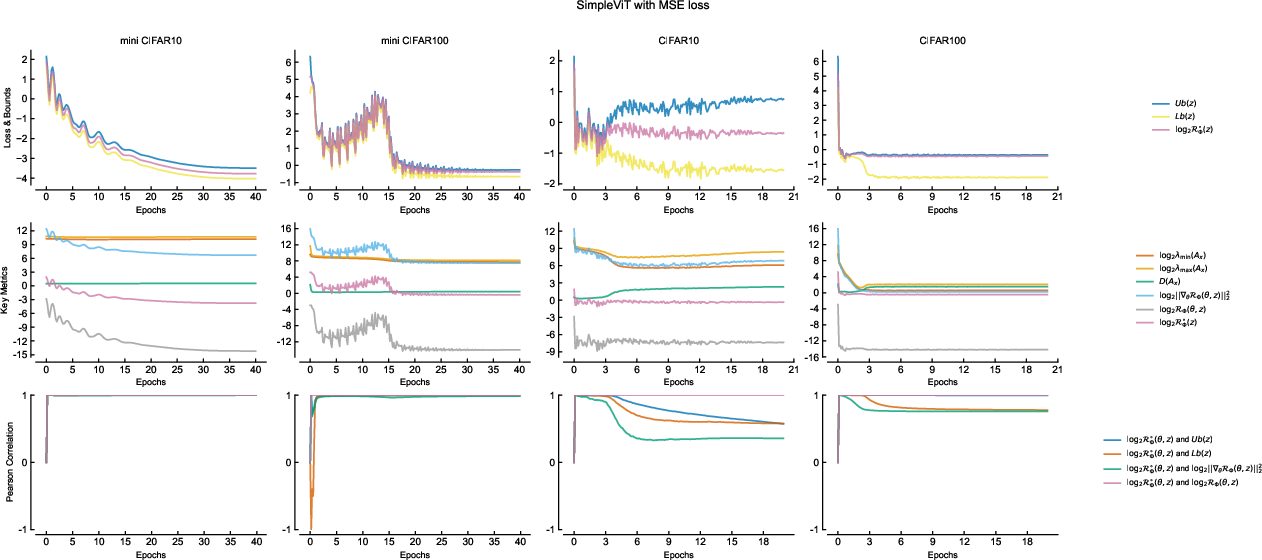
Figure 6: Training dynamics of ViT on softmax cross entropy. Dynamics are consistent with convolutional and residual architectures, validating the theory’s generality.
Implications and Theoretical Synthesis
The conjugate learning theory offers a concrete answer to several open problems in deep learning theory:
- Optimization Hardness: It clarifies why SGD can globally minimize highly non-convex, overparameterized DNNs, provided structure matrix conditioning is preserved through architectural design.
- Generalization Paradox: The observed strong generalization in deep, overparameterized DNNs becomes tractable; the crucial factors are architectural control of output space, information-theoretic regularization, and batch-size/structure-induced gradient decorrelation—rather than traditional notions of VC-dimension or hypothesis class cardinality.
- Loss Function Selection: The Fenchel-Young framework is both necessary and sufficient for loss function design; ad hoc choices outside this class are neither theoretically justified nor optimal for trainability or generalization.
- Interpretability of Regularization: Classical explicit (L2, Lp) and implicit (architecture, batch size) regularization gain a precise role, quantifiably connected to maximum loss control and, thus, generalization.
- Practical Evaluation Beyond Test Sets: Information-theoretic metrics intrinsic to the model and data can, in principle, supplement or supersede conventional test-set-based comparison for robust evaluation in open-world settings.
Conclusion
Conjugate learning theory provides a rigorous, universal framework encapsulating DNN trainability and generalization, grounded in convex conjugate duality and conditional exponential family estimation. The synergy between theory and experiment across architectures and loss functions substantiates its claims. The framework not only demystifies why modern architectures and optimization strategies work but furnishes principled guidelines for the design of future models. Extensions to continuous feature discretization, further tightening of generalization bounds, and adaptive algorithmic strategies informed by the gradient correlation factor are promising directions for advancing both the mathematical and practical frontiers of deep learning.