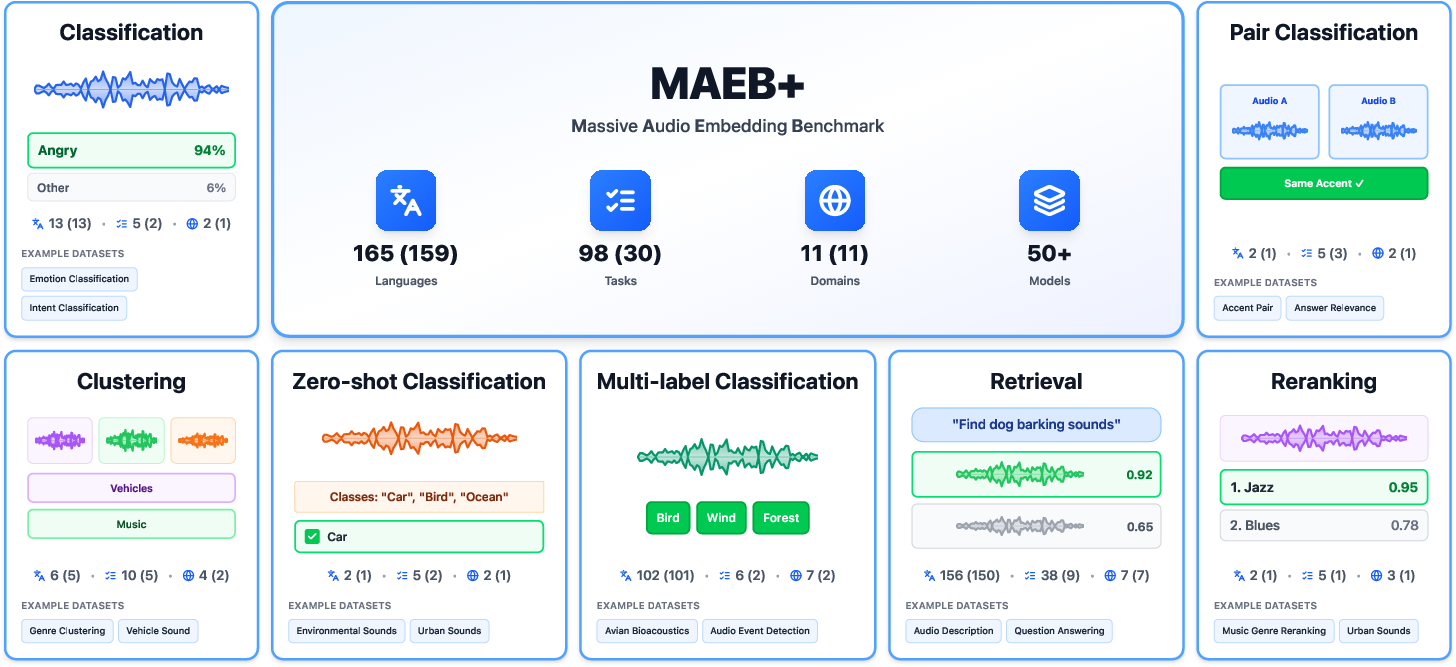
MAEB: Massive Audio Embedding Benchmark
Abstract: We introduce the Massive Audio Embedding Benchmark (MAEB), a large-scale benchmark covering 30 tasks across speech, music, environmental sounds, and cross-modal audio-text reasoning in 100+ languages. We evaluate 50+ models and find that no single model dominates across all tasks: contrastive audio-text models excel at environmental sound classification (e.g., ESC50) but score near random on multilingual speech tasks (e.g., SIB-FLEURS), while speech-pretrained models show the opposite pattern. Clustering remains challenging for all models, with even the best-performing model achieving only modest results. We observe that models excelling on acoustic understanding often perform poorly on linguistic tasks, and vice versa. We also show that the performance of audio encoders on MAEB correlates highly with their performance when used in audio LLMs. MAEB is derived from MAEB+, a collection of 98 tasks. MAEB is designed to maintain task diversity while reducing evaluation cost, and it integrates into the MTEB ecosystem for unified evaluation across text, image, and audio modalities. We release MAEB and all 98 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
1. Overview: What is this paper about?
This paper introduces MAEB, the Massive Audio Embedding Benchmark. Think of it as a big, fair test for computer models that “listen” to sounds and turn them into useful summaries called embeddings. MAEB checks how well these models understand many kinds of audio—speech, music, environmental sounds like rain or sirens, and even sound paired with text—across 30 tasks and 100+ languages. The researchers tested more than 50 models and built easy-to-use tools, public code, and a leaderboard so anyone can compare results.
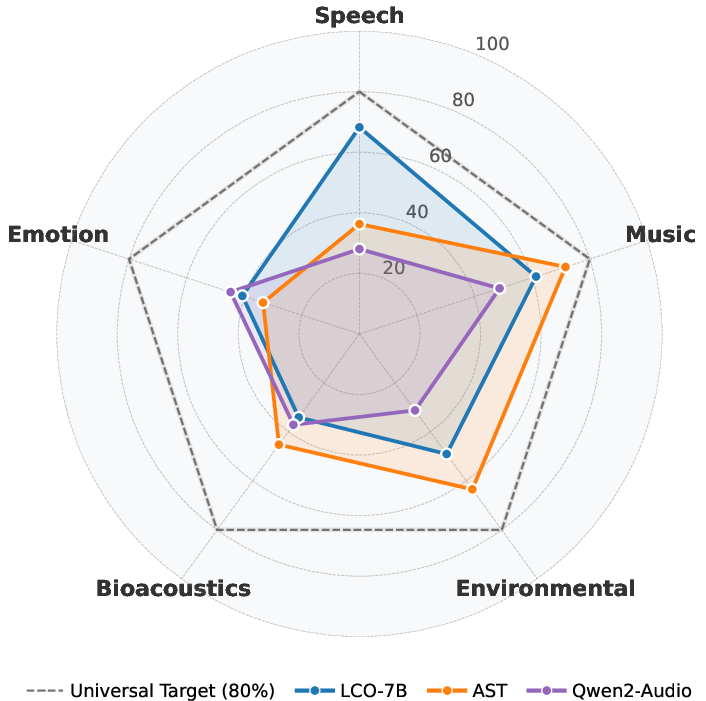
The main takeaway: there isn’t one “best” audio model for everything. Models that are great at understanding sound events (like dog barks) often struggle with language across many languages, and models good at multilingual speech can stumble on music or environmental sounds. MAEB shows these trade-offs clearly and points to what needs improving next.
2. Objectives: What questions did the paper try to answer?
The paper focused on a few simple, big questions:
- Can we build one unified, fair benchmark to compare audio models across many real-world tasks and languages?
- Do any existing models perform well across all types of audio (speech, music, environmental sounds) and tasks (classification, clustering, retrieval, etc.)?
- How do models trained for audio-text alignment (matching sounds with descriptions) compare to speech-focused models?
- Where do current models struggle the most (for example, multilingual speech or organizing sounds without labels)?
- Do scores on this benchmark predict how well an Audio LLM (Audio LLM) will do when it uses these encoders?
3. Methods: How did they test the models?
To keep things simple, imagine each sound clip gets turned into a “numeric fingerprint”—an embedding—that captures important features of the audio. MAEB evaluates how useful these embeddings are across many tasks:
- Before listing tasks, here’s a quick analogy: If audio clips were books, embeddings are like short summaries. The benchmark checks if these summaries help with different jobs: sorting books by topic, finding similar books, matching books to descriptions, or deciding if two books are related.
The benchmark includes these task types:
- Classification: Train a simple classifier on the embeddings to assign labels (like “rock music” or “sad speech”). This uses a small “few-shot” setup—only 8 examples per label—to keep it fair and efficient.
- Zero-shot classification: No training. The model tries to match audio to short text prompts like “This is the sound of a dog bark.” It tests if the audio and text live in the same “understanding space.”
- Clustering: Group similar audio clips without labels, like organizing a playlist by vibe. The score checks if the groups match real categories.
- Retrieval: Like a search engine—given a query, find the most relevant items. This can be audio-to-audio (find a similar sound) or cross-modal (text-to-audio or audio-to-text).
- Pair classification: Decide if two audio clips are similar based on a specific rule (same speaker, same sound class).
- Reranking: Fine-tune the ordering among a small set of candidates, focusing on ranking quality.
How did they choose tasks and keep evaluation fast?
- They started with a larger collection (MAEB+, 98 tasks), then carefully filtered down to 30 diverse tasks to save time while keeping variety and fairness.
- They picked tasks that cover different domains (speech, music, environmental sounds, bioacoustics), many languages, and different skills.
- They removed near-duplicate tasks and kept the ones with broader coverage or lower runtime.
- They use a “Borda count” ranking system—imagine each task “votes” for the models it thinks did best, and the final rank adds up those votes. This avoids unfairness caused by different score scales across tasks.
Models and setup:
- They evaluated 50+ models from different families:
- Speech-focused models (like Whisper, Wav2Vec2)
- Audio-text models (like CLAP), which align sounds and text
- General audio encoders (like AST, YAMNet)
- Large audio-LLMs adapted to produce embeddings (like Qwen2-Audio, LCO-Embedding)
- For fairness, audio clips were capped at about 30 seconds, with standard processing.
- Embeddings were extracted according to each model’s design and compared using simple similarity measures.
4. Main findings: What did they discover, and why is it important?
Key discoveries:
- No “universal” audio model: Models tend to specialize. Speech models (like Whisper) are strong on speech tasks but weaker on music or environmental sounds. Audio-text models (like CLAP) are strong at matching sounds to descriptions and environmental sound tasks but often struggle on multilingual speech tasks.
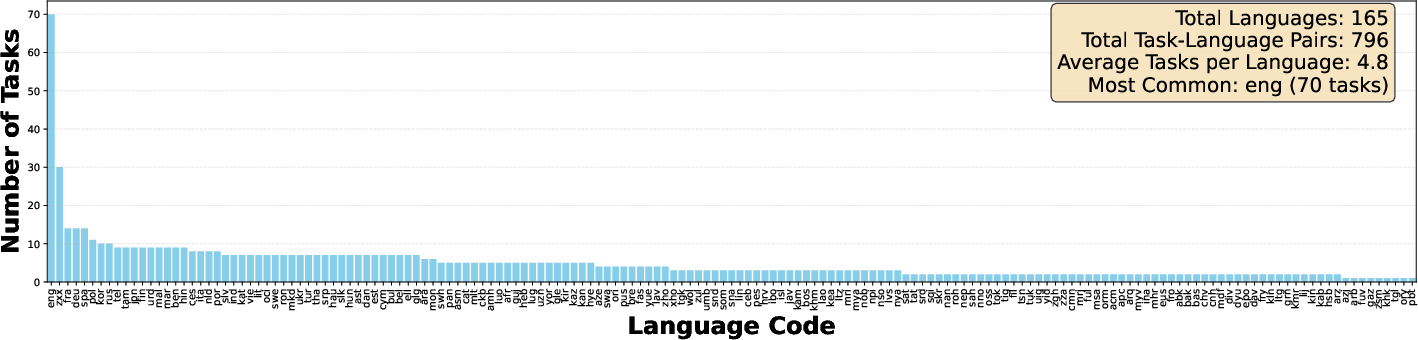
- Multilingual is hard: On tasks across 100+ languages, models did much worse on low-resource languages (like many African or Indigenous languages) than on high-resource ones. Cross-modal retrieval in multilingual settings (e.g., matching speech in many languages to text) often performed near random, showing a big gap in global language coverage.
- Acoustic vs. linguistic trade-off: Some models capture acoustic properties well (like speaker gender or sound texture) but fail at language identification or understanding content, and vice versa. Today’s models seem to lean toward either the “sound” side or the “language” side, not both.
- Clustering is weak across the board: Organizing audio into meaningful groups without labels was tough for all models. Even top models scored low, suggesting embeddings aren’t yet structured well for unsupervised tasks (like automatic playlist building or sound library organization).
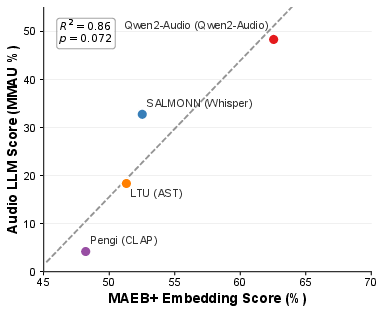
- Benchmark scores relate to Audio LLM performance: Early evidence suggests that models scoring well on MAEB also help Audio LLMs perform better on a multi-task audio test. This hints that MAEB is a good predictor for real-world use, though the sample size was small.
Why this matters:
- These results spotlight where the field is strong (some speech and environmental sound tasks) and where it’s clearly weak (multilingual and clustering).
- Knowing these gaps helps researchers focus on building fairer, more capable models that work across sounds, languages, and tasks.
5. Implications: What could this change or improve?
MAEB’s impact and what comes next:
- Better, fairer comparisons: With a unified benchmark, the community can track progress clearly and avoid cherry-picked results.
- Push toward truly general audio models: The paper encourages creating models that handle speech, music, and environmental sounds without giving up performance in any one area.
- Multilingual audio understanding: There’s an urgent need to train on more diverse languages and use smart methods to transfer knowledge from high-resource languages to low-resource ones so that global users aren’t left behind.
- Balanced representations: Future models should capture both acoustic features (like tone and timbre) and linguistic content (what’s being said) at the same time.
- Improved organization and discovery: By designing training that supports clustering (grouping similar sounds), we could unlock better tools for libraries, streaming platforms, wildlife monitoring, and education.
- Practical access: The benchmark is efficient to run and fully integrated with the broader MTEB ecosystem, making it easier for labs and companies to evaluate their models.
- Open resources: Public code and a leaderboard let the community build, test, and improve together.
In short, MAEB gives the audio AI world a shared test and a clear map of what’s working and what still needs attention—especially for multilingual understanding and unsupervised organization—so we can build smarter, fairer, and more useful audio systems.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, expressed as concrete, actionable gaps for future research.
- Lack of long-form audio evaluation: all inputs are truncated to 30 seconds, leaving untested models’ ability to represent podcasts, lectures, full songs, multi-part scenes, and aggregation strategies across segments.
- Absent real-time/streaming evaluation: no metrics for latency, throughput, memory footprint, or online updates—critical for deployment on edge devices and interactive applications.
- Missing robustness assessments: limited ecological validity due to predominantly clean, studio-recorded audio; no systematic evaluation under noise, reverberation, compression artifacts, microphone/device variability, far-field conditions, or overlapping speakers.
- Stereo/spatial information not assessed: mono conversion for many models may erase spatial cues; need tasks testing spatial audio, stereo music, and microphone array scenarios (e.g., localization, dereverberation).
- Sparse bioacoustics and emotion coverage: only 2 bioacoustics and 6 emotion tasks; expand with diverse species, habitats, and culturally diverse affect datasets to avoid overfitting to narrow domains.
- Multilingual cross-modal collapse remains unresolved: audio-text retrieval is near-random for most non-English languages; requires multilingual audio-caption corpora, multilingual prompt sets, and cross-lingual alignment strategies.
- Zero-shot prompt design underexplored: class prompts are simple English templates; evaluate multilingual prompts, richer descriptions, synonyms, hierarchical labels, and label semantics length to improve zero-shot performance.
- Acoustic vs linguistic trade-off unaddressed: models optimize either timbre/speaker traits or linguistic content; need architectures/training that disentangle and jointly capture both, plus tasks explicitly probing this separation (e.g., controlled speaker/content swaps).
- Clustering weaknesses unexamined mechanistically: poor V-measure across models suggests weak semantic geometry; explore clustering-aware losses, neighborhood structure regularization, and alternative unsupervised objectives (e.g., VICReg, SwAV) to improve grouping.
- Clustering evaluation design limited: only MiniBatchKMeans with k equal to true labels and V-measure; add ARI/NMI, silhouette, density-based clustering, sensitivity to k, and open-set scenarios where k is unknown.
- Retrieval metrics and direction choices not fully validated: heterogenous use of CV Recall@5 vs NDCG across datasets and prioritized directions; systematically compare both audio-to-text and text-to-audio, multiple cutoffs (R@10/50), and mAP for consistency.
- Few-shot probe dependence unstudied: classification uses 8-shot logistic regression; provide shot-sensitivity curves, alternative linear probes (SVM, ridge), and calibration analyses to assess stability of ranking conclusions.
- Preprocessing confounds unquantified: heterogeneous sampling rates, mono conversion, and model-native pooling may bias comparisons; run controlled ablations to measure the impact of resampling, stereo vs mono, normalization, and pooling strategies.
- Parameter count vs data curation vs architecture trade-offs unmeasured: claims that scale does not guarantee balance need broader, controlled comparisons disentangling training objective, dataset composition, and model size.
- Limited model coverage: the 50+ encoders exclude recent or domain-specialized models (e.g., bioacoustics-specific, music structure-aware, diarization-focused); expand coverage and regularly refresh the leaderboard.
- Underrepresentation of non-Western music: current music tasks skew toward Western genres; add datasets capturing non-Western instruments, microtonal scales, ornamentation, and region-specific styles.
- Missing temporal localization tasks: clip-level tasks dominate; add event localization, segmentation, and boundary detection to test embeddings’ temporal sensitivity.
- No evaluation of audio generation quality: embeddings are not tested for their utility in assessing TTS/music generation fidelity, prosody, intelligibility, or style similarity.
- Fairness and bias analyses absent: tasks involve gender/age/language identification, but no assessment of demographic biases, disparate performance, or potential harms; introduce fairness protocols and bias diagnostics.
- Code-switching and dialectal variation poorly covered: expand datasets and tasks capturing intra-utterance language mixing and rich dialect diversity to test cross-lingual robustness.
- Insufficient analysis of multilingual retrieval failures: investigate whether failure stems from captions, tokenization, phonetic variability, or model text encoders; add aligned multilingual audio-caption corpora and cross-lingual negative mining.
- Borda aggregation limitations: rank-based aggregation is not continuous and may mask effect sizes; provide uncertainty estimates (bootstrap CIs), significance testing, and sensitivity to aggregation choices (mean, median, pairwise tournament).
- Task selection pruning risks: redundancy removal via rank correlation (ρ > 0.8) may over-prune informative tasks; verify stability across more models, model families, and future submissions; consider periodic re-selection.
- Preliminary encoder–Audio LLM correlation: based on n=4 with marginal p-value; expand to more Audio LLMs and encoders, include non-classification tasks (retrieval, clustering), and analyze causal mechanisms linking embedding geometry to LLM reasoning.
- Candidate reranking protocol transparency: clarify candidate set construction and hardness; evaluate robustness to candidate composition, hard-negative mining, and domain mismatch.
- Open-vocabulary and hierarchical classification gaps: beyond zero-shot single-label, add multi-label zero-shot, hierarchical taxonomies, and long-tail category distributions to test generalization.
- Domain adaptation and transfer learning untested: quantify cross-domain transfer (speech→environmental, music→speech), including few-shot adaptation and test-time augmentation strategies.
- Energy and efficiency metrics missing: no standardized reporting of GPU hours per task, energy use, or CPU/mobile inference throughput; add efficiency benchmarks for practical deployment.
- Audio–vision and broader multimodal alignment absent: MAEB focuses on audio–text; add audio–video/image tasks (e.g., Foley retrieval, AV event localization) to probe cross-modal generalization.
- Speaker diarization and change detection not covered: introduce tasks requiring embeddings to capture speaker turns, diarization segments, and conversation dynamics.
- Governance and dataset drift: long-term maintenance plan mentions community development, but no protocol for dataset versioning, license changes, and stability of benchmark scores; define governance and reproducibility policies.
Practical Applications
Immediate Applications
The MAEB benchmark, codebase, and leaderboard enable concrete, near-term improvements in how teams choose, test, and deploy audio encoders across domains and languages. The following use cases can be implemented with the released tools today.
- Production model selection and routing for audio products (software, consumer tech, media)
- Use case: Select and/or route between encoders by task/domain: e.g., CLAP variants for environmental sound/music retrieval and zero-shot tagging; Whisper/MMS/SeamlessM4T for multilingual speech tasks (intent classification, language ID); AST/YAMNet for general environmental audio tagging.
- Tools/products/workflows: MAEB leaderboard; MAEB(audio) subset for fast checks; domain-detector + router to pick encoder per input; Borda-ranked thresholds for CI gating.
- Sectors: Software, media/entertainment, telecom, smart devices.
- Dependencies/assumptions: Licensing compatibility for chosen encoders; compute cost at inference; domain-detector accuracy; 30s audio truncation may miss long-form cues.
- Continuous evaluation in MLOps/CI for audio embeddings (DevOps for ML)
- Use case: Integrate MAEB as a regression gate for new encoder releases; track per-category metrics (classification, retrieval, clustering) to prevent silent degradations.
- Tools/products/workflows: MAEB GitHub repo; reproducible pipelines; GPU budget manageable (~2 GPU hours for small/audio-only).
- Sectors: Software platforms, ML infrastructure.
- Dependencies/assumptions: Benchmark-task alignment with product KPIs; periodic updates of tasks/datasets.
- Audio search and cataloging pipelines for media platforms
- Use case: Improve music and sound effect search by adopting top reranking/retrieval models (e.g., Qwen2-Audio for reranking; CLAP for cross-modal matching), and zero-shot tagging for new assets.
- Tools/products/workflows: Replace indexer embeddings; add reranker stage; zero-shot class prompts (“This is a sound of …”).
- Sectors: Media/entertainment, creator tools, DAM systems.
- Dependencies/assumptions: Availability/quality of text captions; multilingual cross-modal retrieval is weak and may need language-specific fallbacks.
- Contact-center analytics and voice IVR optimization
- Use case: Choose speech-pretrained models (Whisper/MMS) for multilingual intent classification and language ID; apply pair classification for speaker verification and compliance checks.
- Tools/products/workflows: Encoder swap-in; per-call embedding extraction; downstream linear probes.
- Sectors: Finance, telecom, retail.
- Dependencies/assumptions: Privacy/PII constraints; consent and data governance; inference cost and latency.
- Accessibility and voice assistants
- Use case: Improve English-centric assistants using LCO-Embedding for cross-modal tasks; use speech-focused encoders for command detection; deploy routing between specialized encoders per task.
- Tools/products/workflows: On-device vs cloud routing; MAEB(audio) for lightweight model choice.
- Sectors: Consumer tech, public sector services.
- Dependencies/assumptions: Multilingual performance is uneven—fallbacks or localized models needed; on-device memory/compute limits.
- Academic benchmarking and reproducible baselines
- Use case: Standardize evaluation for new audio encoders; report MAEB scores alongside model cards; compare fairly across modalities via MTEB integration.
- Tools/products/workflows: MAEB code; versioned artifacts; Borda count and mean reporting.
- Sectors: Academia, open-source.
- Dependencies/assumptions: Community maintenance; adherence to preprocessing standards.
- Procurement and governance checklists for public deployments
- Use case: Require MAEB task performance (e.g., SIB-FLEURS/FLEURS for multilingual) in RFPs for ASR/IVR or emergency hotlines.
- Tools/products/workflows: Score thresholds by language; per-category minimums.
- Sectors: Government, NGOs, regulated industries.
- Dependencies/assumptions: Adoption by procurement bodies; fairness/audit frameworks.
- Encoder pre-selection for Audio LLMs
- Use case: Filter candidate audio encoders for multimodal LLMs based on MAEB correlation with Audio LLM performance to save training cycles.
- Tools/products/workflows: Shortlist encoders with high MAEB domain scores before instruction tuning.
- Sectors: Foundation model labs, product R&D.
- Dependencies/assumptions: Correlation is preliminary (R²≈0.86, n=4); validate with internal tasks.
- Device-vendor QA for edge audio (IoT)
- Use case: Benchmark small, efficient encoders (e.g., YAMNet, CNN14) on MAEB(audio) for power/latency-constrained devices (cameras, doorbells, wearables).
- Tools/products/workflows: On-device evaluation harness; MAEB(audio) KPIs per firmware release.
- Sectors: Hardware, smart home, automotive.
- Dependencies/assumptions: Real-time constraints not explicitly measured by MAEB; environmental noise differences vs benchmark datasets.
- Data-centric planning for multilingual coverage
- Use case: Use MAEB language-wise results to identify weakest languages and direct data collection/labeling to reduce gaps.
- Tools/products/workflows: Language-wise dashboards; active learning loops.
- Sectors: All sectors deploying multilingual audio.
- Dependencies/assumptions: Rights-cleared multilingual audio-text corpora; community participation.
Long-Term Applications
Findings on specialization gaps, multilingual failures, weak clustering, and cross-modal trade-offs suggest medium-to-longer horizon products and standards that will require new research, data, or scaling.
- Universal audio embedding services and APIs
- Vision: Domain-agnostic encoders that perform well across speech, music, environmental sounds, and emotions without routing.
- Tools/products/workflows: Unified training objectives; multi-domain pretraining; disentangled representations.
- Sectors: Software platforms, cloud providers.
- Dependencies/assumptions: Large diverse training corpora; architectural advances to resolve acoustic/linguistic trade-offs.
- Mixture-of-experts routing at inference time
- Vision: Automatic domain detectors route inputs to specialist encoders (speech vs music vs ambient); fuse embeddings for downstream tasks.
- Tools/products/workflows: Gating networks trained on MAEB domains; late-fusion aggregation.
- Sectors: Consumer devices, content platforms.
- Dependencies/assumptions: Reliable domain detection; latency budgets; maintenance complexity.
- Multilingual cross-modal audio–text retrieval at scale
- Vision: CLAP-like models trained on multilingual audio-text corpora to fix near-random performance on many languages.
- Tools/products/workflows: New multilingual alignment datasets; cross-lingual transfer and distillation.
- Sectors: Search, media, education, cultural heritage.
- Dependencies/assumptions: Sizable multilingual caption corpora; licensing; balanced representation for low-resource languages.
- Clustering-aware embeddings for massive audio libraries
- Vision: Embeddings that self-organize semantically (podcasts, sound FX, field recordings) without labels; improved discovery.
- Tools/products/workflows: Clustering losses / neighborhood regularizers; unsupervised evaluation suites; library organization UIs.
- Sectors: Media asset management, enterprise knowledge, archives.
- Dependencies/assumptions: New objectives and benchmarks; validation on noisy, long-form data.
- Standards and conformance testing for public-sector audio systems
- Vision: MAEB-derived standards for minimum multilingual performance, fairness across dialects, and transparency in model cards.
- Tools/products/workflows: Certification suites; periodic audits tied to a public leaderboard.
- Sectors: Policy/government, healthcare, emergency services.
- Dependencies/assumptions: Multi-stakeholder governance; version stability; legal frameworks.
- Healthcare and bioacoustics diagnostics
- Vision: Robust embeddings for cough, respiratory, cardiac, and wildlife monitoring that generalize across devices and environments.
- Tools/products/workflows: Task extensions (bioacoustics/emergency sounds); clinical-grade dataset curation; device calibration protocols.
- Sectors: Healthcare, environmental monitoring.
- Dependencies/assumptions: Regulated data pipelines; clinical validation; privacy/ethics.
- Robotics and autonomous systems
- Vision: Reliable acoustic scene understanding for navigation, safety, and human–robot interaction in diverse environments.
- Tools/products/workflows: Long-form, real-time benchmarks; integration with sensor fusion.
- Sectors: Robotics, manufacturing, logistics.
- Dependencies/assumptions: Real-time constraints and noise robustness not yet covered by MAEB; on-device efficiency.
- Edge/on-device universal audio analytics
- Vision: Low-latency, low-power embedding stacks informed by MAEB but extended with latency/energy metrics for IoT.
- Tools/products/workflows: Benchmark variants capturing throughput and energy; model compression/distillation guided by MAEB scores.
- Sectors: Smart home, wearables, automotive.
- Dependencies/assumptions: New evaluation dimensions (RTF, energy); hardware-specific optimizations.
- Personal multimodal memory and search
- Vision: Private, on-device search across personal audio (meetings, voicemails) using strong cross-modal retrieval.
- Tools/products/workflows: Privacy-preserving embeddings; federated improvement; semantic tagging.
- Sectors: Productivity, consumer apps.
- Dependencies/assumptions: Improved multilingual cross-modal performance; privacy safeguards.
- Language learning and education technology
- Vision: Real-time feedback on pronunciation, prosody, and emotion in many languages.
- Tools/products/workflows: Encoders with balanced acoustic/linguistic representations; task-specific fine-tuning pipelines.
- Sectors: Education, EdTech.
- Dependencies/assumptions: Better multilingual performance; culturally inclusive datasets.
- Compliance monitoring and risk analytics for finance/call centers
- Vision: Cross-lingual monitoring of trading/compliance calls with robust language ID, speaker verification, and semantic tagging.
- Tools/products/workflows: Multilingual embeddings; domain-adapted probes; alerting dashboards.
- Sectors: Finance, insurance, BPO.
- Dependencies/assumptions: Legal acceptance; high recall in low-resource languages.
- Environmental/biodiversity monitoring at scale
- Vision: Global sensor networks using embeddings for species detection and ecosystem health indicators.
- Tools/products/workflows: Bioacoustics tasks expanded in MAEB; unsupervised discovery of novel species calls via clustering.
- Sectors: Conservation, energy (asset monitoring), agriculture.
- Dependencies/assumptions: Data coverage across habitats; sensor standardization.
- MAEB-based evaluation services and platform integrations
- Vision: Hosted “MAEB Dashboard” SaaS and GitHub Actions that continuously evaluate internal models across versions and tasks.
- Tools/products/workflows: APIs, leaderboards for private data; AutoML hooks to choose encoders per task.
- Sectors: ML platforms, enterprise AI.
- Dependencies/assumptions: Maintenance funding; dataset licensing for hosted services.
- Audio LLM development workflows
- Vision: Automated pipelines that select, distill, and align encoders for LALMs using MAEB as an upstream signal.
- Tools/products/workflows: Encoder bake-off + selection; distillation into small LALMs; domain-wise pretraining schedules.
- Sectors: Foundation model builders, applied AI.
- Dependencies/assumptions: Stronger, validated correlation across more models and tasks; scalable training stacks.
Notes on feasibility across applications:
- The paper’s findings emphasize that no single model is universally best; immediate deployments should prefer specialist encoders or routing strategies.
- Multilingual cross-modal retrieval is currently weak; long-term applications relying on this require significant new multilingual datasets and training.
- Clustering is a consistent failure mode; unsupervised organization tools will need embedding advances and/or hybrid human-in-the-loop workflows.
- MAEB currently focuses on representation quality (not ASR/generation/real-time); applications needing transcription or strict latency must complement MAEB with additional evaluations.
Glossary
- Audio LLM: A LLM specialized for processing and understanding audio alongside text, often leveraging encoder embeddings. "Preliminary evidence from four Audio LLMs suggests that MAEB encoder quality may correlate with downstream Audio LLM performance (~=~0.86, ~=~4; see \autoref{fig:maeb_correlation})"
- Audio spectrograms: Visual representations of audio frequencies over time used as inputs to models. "Transformer-based models apply vision transformer architectures to audio spectrograms, including AST \cite{gong2021astaudiospectrogramtransformer}."
- Audio-to-text retrieval: Finding the most relevant text for a given audio query. "including uni-modal (audio-to-audio) and cross-modal (text-to-audio, audio-to-text) scenarios."
- Average precision: A ranking metric summarizing precision across recall levels, often used with similarity scores. "Similarity is computed between embeddings, and average precision based on cosine similarity serves as the main metric."
- Bioacoustics: The study and analysis of animal sounds and biological acoustic signals. "including speech, music, environmental sounds, and bioacoustics"
- Borda count: A rank aggregation method where items receive points based on their positions across voters. "we compute model ranks using a Borda count \cite{colombo2022what} by treating each task as a preference voter over models."
- Clustering-aware losses: Training objectives that encourage embeddings to form semantically coherent groups without labels. "Incorporating clustering-aware losses or contrastive objectives that explicitly encourage semantically coherent embedding neighborhoods could address this gap"
- Contrastive alignment objective: A training objective that pulls matched audio–text pairs closer and pushes mismatched pairs apart in embedding space. "models that learn joint audio-text embedding spaces through a contrastive alignment objective"
- Cosine similarity: A measure of similarity between two vectors based on the cosine of the angle between them. "Documents are ranked by cosine similarity, with CV Recall@5 (cross-validation recall at 5) as the main metric."
- Cross-lingual transfer learning: Techniques that use knowledge from high-resource languages to improve performance on low-resource languages. "implementing cross-lingual transfer learning to leverage high-resource language knowledge for the 100+ languages where current models achieve near-random performance."
- Cross-modal: Involving multiple data modalities (e.g., audio and text) in a unified task or model. "cross-modal audio-text tasks that have been largely absent from prior audio benchmarks."
- CV Recall@5: Cross-validation recall at rank 5, measuring how often the correct item appears in the top 5 retrieved results across folds. "Documents are ranked by cosine similarity, with CV Recall@5 (cross-validation recall at 5) as the main metric."
- Disentangled representations: Embeddings structured to separate different factors of variation (e.g., acoustic vs. linguistic). "Future architectures should explore disentangled representations or multi-task learning approaches that capture both acoustic properties (speaker, timbre) and linguistic content simultaneously"
- Domain-agnostic architectures: Model designs intended to generalize across different audio domains (speech, music, environmental sounds). "The specialization gap calls for domain-agnostic architectures that generalize across speech, music, and environmental sound without sacrificing domain-specific capabilities."
- Ecological validity: The degree to which evaluation reflects real-world conditions. "Ecological validity is limited as many tasks use clean, studio-recorded audio that does not reflect real-world conditions with noise, reverberation, and compression artifacts."
- Global average pooling: An operation that aggregates features by averaging across spatial or temporal dimensions. "CNN models use global average pooling"
- Hard negatives: Challenging non-relevant items included to stress-test ranking or retrieval. "pre-selected candidate sets containing relevant documents and hard negatives."
- L2 normalization: Scaling a vector so its L2 norm (Euclidean length) is 1, commonly used before similarity computations. "use their audio encoder branches with L2 normalization for retrieval compatibility."
- Last-token pooling: Extracting an embedding from the final token/state of a sequence model. "Large audio-LLMs extract embeddings from the final hidden layer using last-token pooling."
- Linear probing: Training a simple linear classifier on frozen embeddings to assess representational quality. "We use few-shot linear probing~\citep{muennighoff2022mteb,cherti2023reproducible} with 8 examples per class"
- Long-form audio processing: Handling extended-duration audio such as lectures or podcasts. "audio-specific aspects such as multilingual audio understanding, long-form audio processing, and cross-modal audio-text tasks"
- MAP@1000: Mean Average Precision computed up to the top 1000 ranked items. "This tests fine-grained discrimination, with MAP@1000 (mean average precision at 1000) as the main metric."
- Mean pooling: Averaging feature vectors over time to produce a single embedding. "transformer models employ mean pooling over temporal dimensions"
- MiniBatchKMeans: A scalable variant of k-means clustering that uses mini-batches for efficiency. "We use MiniBatchKMeans (with k set to the number of true labels) and V-measure~\citep{rosenberg-hirschberg-2007-v} as the main metric"
- Multilingual audio understanding: Modeling and evaluating audio tasks across many languages. "audio-specific aspects such as multilingual audio understanding, long-form audio processing, and cross-modal audio-text tasks"
- Neural codec: Learned audio compression models that produce compact representations. "Neural codec models provide audio compression through learned representations, including Encodec \cite{défossez2022highfidelityneuralaudio}."
- Pair classification: Predicting whether two inputs are similar under a defined criterion. "Given two audio inputs, the task is to predict whether they are similar according to a criterion (e.g., same speaker, same sound class)."
- Paralinguistic understanding: Recognizing non-verbal aspects of speech such as emotion and speaker traits. "demonstrating the advantages of multimodal instruction-tuning for paralinguistic understanding."
- Pearson r: A correlation coefficient measuring linear association between two variables. "MAEB maintains strong correlation with MAEB(extended) in terms of model scores (Pearson =0.981)"
- Reranking: Reordering a set of candidate items (with some relevant ones) to improve ranking quality. "Unlike retrieval over full corpora, reranking evaluates ranking quality on pre-selected candidate sets containing relevant documents and hard negatives."
- Retrieval: Finding relevant items in a corpus given a query, evaluated by ranking metrics. "Retrieval evaluates finding relevant documents from a corpus given a query, including uni-modal (audio-to-audio) and cross-modal (text-to-audio, audio-to-text) scenarios."
- Sequence-to-sequence objective: Training to map an input sequence to an output sequence (e.g., ASR, translation). "models trained for a sequence-to-sequence objective, e.g., for speech recognition and translation."
- Spearman ρ: A rank correlation coefficient assessing monotonic relationships. "remove tasks with Spearman to a retained task"
- V-measure: A clustering evaluation metric based on homogeneity and completeness. "We use MiniBatchKMeans (with k set to the number of true labels) and V-measure~\citep{rosenberg-hirschberg-2007-v} as the main metric"
- Zero-shot classification: Assigning labels without task-specific training, often via text prompts. "Audio embeddings are directly matched to class labels converted to text prompts (e.g., ``This is a sound of dog bark'') without training a classifier."
- zxx (No Linguistic Content): ISO 639 code indicating data with no linguistic content. "We use zxx (No Linguistic Content) to tag datasets with no languages present."
Collections
Sign up for free to add this paper to one or more collections.

