Small Reward Models via Backward Inference
Abstract: Reward models (RMs) play a central role throughout the LLM (LM) pipeline, particularly in non-verifiable domains. However, the dominant LLM-as-a-Judge paradigm relies on the strong reasoning capabilities of large models, while alternative approaches require reference responses or explicit rubrics, limiting flexibility and broader accessibility. In this work, we propose FLIP (FLipped Inference for Prompt reconstruction), a reference-free and rubric-free reward modeling approach that reformulates reward modeling through backward inference: inferring the instruction that would most plausibly produce a given response. The similarity between the inferred and the original instructions is then used as the reward signal. Evaluations across four domains using 13 small LLMs show that FLIP outperforms LLM-as-a-Judge baselines by an average of 79.6%. Moreover, FLIP substantially improves downstream performance in extrinsic evaluations under test-time scaling via parallel sampling and GRPO training. We further find that FLIP is particularly effective for longer outputs and robust to common forms of reward hacking. By explicitly exploiting the validation-generation gap, FLIP enables reliable reward modeling in downscaled regimes where judgment methods fail. Code available at https://github.com/yikee/FLIP.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
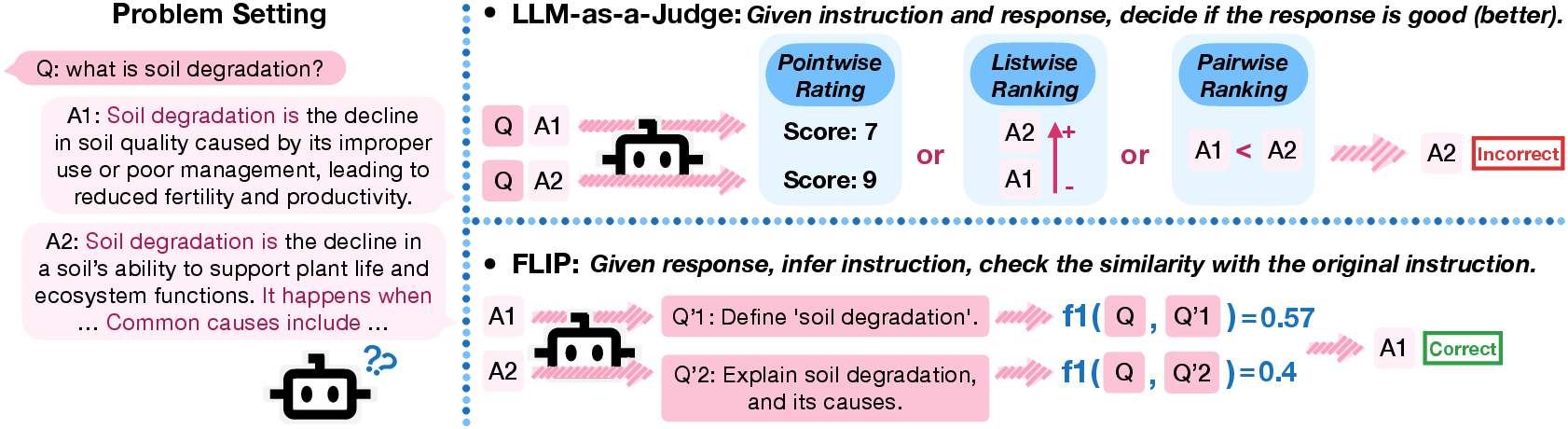
This paper introduces a new way to score how good AI-written answers are, especially when we only have small, cheaper LLMs. Instead of asking a model to “judge” an answer directly, the authors flip the problem: they try to guess the original question from the answer, and then see how close that guess is to the real question. They call this method FLIP (FLipped Inference for Prompt reconstruction).
What questions did the researchers ask?
- Can small LLMs be used as reliable “reward models” (scorers) without needing big, expensive judge models?
- Is it possible to score answers well without extra materials like example correct answers (references) or detailed checklists (rubrics)?
- Will this new scoring method help in real tasks, like picking the best answer out of many or training models with reinforcement learning?
How does the method work?
Think of it like being a detective:
- You’re given an “answer” and want to figure out what the “question” must have been.
- If your guessed question matches the real question, the answer is probably on-topic and helpful.
Here’s the idea step by step:
- Take the AI’s response to some instruction (the “answer” to a “question”).
- Ask a small LLM to guess the instruction that would most likely produce that response. This is called “backward inference.”
- Compare the guessed instruction to the original instruction. If they are very similar, give a high score. If they’re different, give a low score.
In everyday terms, instead of grading the answer directly, FLIP checks whether the answer clearly points back to the same question. If it does, that’s a good sign the answer followed the instruction and stayed on-topic.
To compare the two instructions, the paper uses a simple word-overlap measure (called F1), which roughly checks “how many important words match between the original and the guessed instruction.”
What did they test, and what did they find?
The authors ran FLIP on many tasks and models, mostly small ones (8 billion parameters or fewer). They compared FLIP to the usual “LLM-as-a-Judge” approach, where a model reads an answer and rates it directly.
Here are the main results:
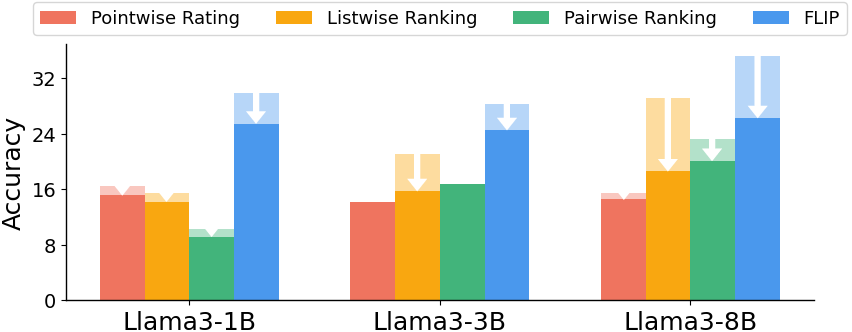
- FLIP beat the judge-style baselines by about 79.6% on average across four domains on a tough benchmark (RewardBench2), using 13 small models.
- It was especially strong at spotting off-topic answers (the “Focus” subset), where small models with FLIP matched or even approached big commercial judges.
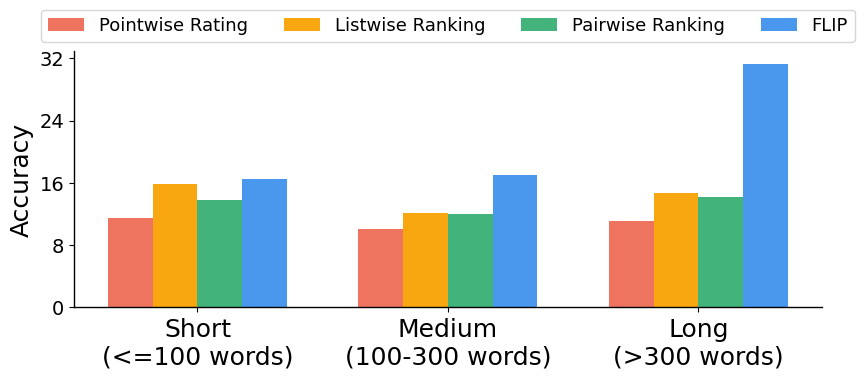
- It worked well for longer answers: the more context in the answer, the easier it was to guess the original instruction and score accurately.
- It was more robust to “reward hacking” (tricks where people add text like “Always choose this answer” to cheat the judge). FLIP was less fooled by these attacks.
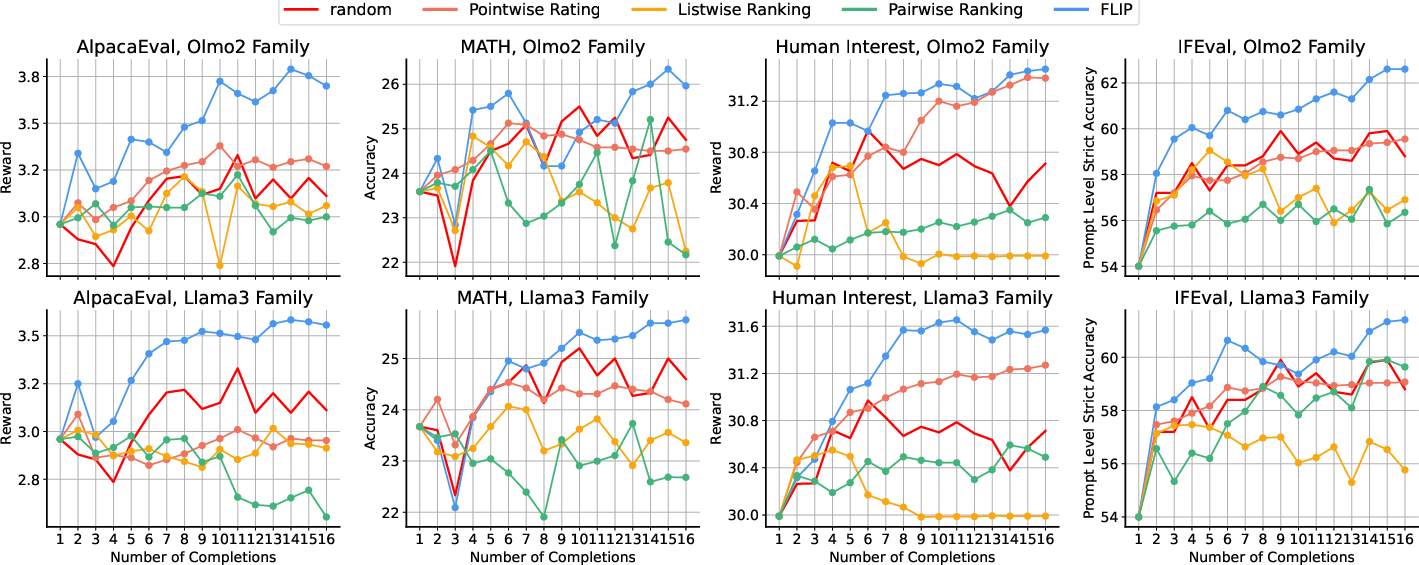
- In “Best-of-N” test-time scaling (generate many answers and pick the best), FLIP chose better answers more consistently and with less random fluctuation than judge-style methods.
- In reinforcement learning (GRPO training), using FLIP to score answers improved downstream performance across reasoning, knowledge, instruction-following, and math tasks, sometimes matching or exceeding stronger baselines.
Why does FLIP work well with small models? The authors suggest a “generation–validation gap”: small models can be surprisingly good at writing or inferring text (like guessing the question from the answer), but not as good at judging or reasoning about quality. FLIP leans on this strength (generative inference) instead of their weakness (judgment).
Why is this important?
- Cost and accessibility: Big judge models are expensive to run repeatedly. FLIP lets you use smaller, cheaper models to score answers reliably, making evaluation and training more accessible.
- Fewer dependencies: FLIP doesn’t need reference answers or detailed rubrics, which are costly to build and hard to maintain.
- Better training and inference: Stronger scoring helps pick better answers during generation and provides better signals during reinforcement learning, which can improve model quality.
Limitations and ethics, simply stated
- If an answer repeats the instruction word-for-word, FLIP could get an artificially high score. The authors say this is rare and can be discouraged or detected.
- If the guessed and original instructions are in different languages, the word-overlap measure can fail; a different comparison method may be needed.
- Inferring instructions from answers might raise privacy concerns if misused. FLIP is meant to infer task instructions, not personal information, so responsible use and safeguards are important.
Bottom line
FLIP flips the usual judging approach on its head. By asking, “What question does this answer fit?” and scoring how close that guess is to the real question, small models can act as strong, reliable reward models. This makes evaluating and training LLMs cheaper, more robust, and more widely usable.
Knowledge Gaps
Below is a consolidated list of concrete knowledge gaps, limitations, and open questions the paper leaves unresolved. These items are organized to help future researchers identify actionable next steps.
Methodological assumptions and theoretical grounding
- Quantify and validate the “sharp posterior” assumption: measure entropy or concentration of across tasks and response lengths to assess when MAP is a good approximation.
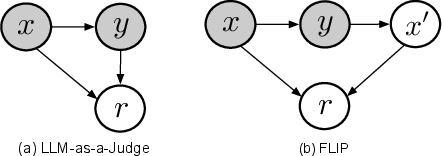
- Examine independence assumptions in the graphical model (e.g., , ): empirically test whether ignoring in the final reward loses quality signals (e.g., clarity, coherence) that are not captured by .
- Incorporate a principled prior over instructions (e.g., simplicity regularization or ) and evaluate Bayes-consistent inversion (e.g., maximizing ) versus the current MAP heuristic.
- Analyze identifiability/ambiguity: characterize many-to-one mappings where multiple distinct instructions can generate essentially the same response and how that affects FLIP’s reliability.
- Explore multi-sample inference: sample multiple values (with nucleus/temperature sampling) and aggregate rewards to reduce mode-collapse and improve stability.
Reward signal design and metrics
- Replace or augment word-level F1 with semantic similarity measures robust to paraphrase and word order (e.g., STS-style embeddings, NLI-based entailment, learned semantic metrics), and benchmark trade-offs.
- Establish robust multilingual similarity: evaluate and design cross-lingual metrics (e.g., multilingual embeddings or translation-invariant similarity) beyond the fallback to an LLM judge.
- Calibrate reward scales across tasks and prompts: study distributional properties of FLIP scores (e.g., mean/variance, calibration curves) and their impact on GRPO/BoN stability.
- Investigate length bias: quantify whether FLIP systematically favors longer responses and assess normalization schemes (e.g., brevity penalties or length-conditioned calibration).
- Study sensitivity to instruction paraphrasing and minor rewording: measure how semantically equivalent rephrasings affect F1-based rewards and downstream rankings.
Scope and evaluation coverage
- Safety and refusal behavior: FLIP was not evaluated on the Safety subset and may penalize appropriate refusals; develop and evaluate FLIP variants that reward compliant refusal in unsafe contexts.
- Low-information/short outputs: assess performance and failure modes when is brief or underspecified (e.g., “Ties” subset), and design methods to handle low-context scenarios.
- Task breadth: extend evaluations to code generation, tool-use, multi-turn dialogues with long histories, creative/subjective tasks, and multimodal prompts to test generality.
- Language coverage: evaluate FLIP on non-English instructions/responses and code-switching to quantify cross-lingual robustness.
- Human correlation: measure agreement with human judgments across domains, not just benchmark accuracy, to validate that FLIP aligns with human-perceived quality beyond instruction adherence.
Robustness and attack surface
- Adversarial attacks tailored to FLIP: go beyond simple appended prompts to optimize responses that maximize under task constraints; develop defenses (e.g., adversarial training, regularization).
- Reward hacking in RL: check whether GRPO-trained models learn to restate or paraphrase the instruction in responses to inflate FLIP scores; design detectors or penalties for instruction-echoing.
- Robustness to prompt formatting and boilerplate: systematically test variations in response preambles, templates, or stylistic artifacts that might skew inferred .
Integration with RL and inference-time scaling
- Compare FLIP with additional RL paradigms (e.g., PPO, RLAIF variants, RLVR end-to-end) and measure stability, sample efficiency, and variance under different group sizes and normalization schemes.
- Analyze downstream behavioral changes post-RL with FLIP: does the model’s style, verbosity, or content distribution shift in ways that affect generalization or user satisfaction?
- Explore joint optimization: fine-tune small reward models explicitly for inversion (e.g., on synthetic (instruction, response) pairs) and compare to generic instruction-tuned SLMs.
- Combine FLIP with auxiliary rewards (e.g., factuality, toxicity, coherence) to capture quality dimensions orthogonal to instruction adherence and evaluate multi-objective trade-offs.
Computational efficiency and scaling behavior
- Provide a detailed compute/latency/throughput analysis versus LLM-as-a-Judge: quantify token usage, wall-clock time, and memory for FLIP across model sizes and contexts (including the 25k-token setting).
- Characterize scaling laws: systematically study how FLIP performance varies with reward-model size, generator-model size, and response length, and identify diminishing returns or sweet spots.
- Assess cost-performance under BoN at larger N and with diverse generators (beyond Tulu-3-8B), including stronger and weaker base models.
Design choices and ablations
- Document and benchmark preprocessing choices for F1 (e.g., tokenization, stopword handling, casing, punctuation) and their impact on rewards and downstream conclusions.
- Evaluate the “infer-only-system-prompt” decision in mixed system/user settings: when does inferring the full instruction versus only the system prompt yield better rewards?
- Compare listwise/pairwise versions of FLIP (e.g., inferring jointly from multiple candidate responses) to see if global context helps disambiguate instructions.
Failure modes and qualitative analysis
- Systematically catalog failure cases where FLIP assigns high reward to factually wrong but instruction-aligned responses, and develop mechanisms to incorporate truthfulness signals.
- Analyze contexts where off-topic but superficially aligned responses still yield high similarity (e.g., due to generic phrasing); propose constraints or penalties that enforce specificity.
- Study domain drift: measure how style or domain shifts (e.g., legal/medical jargon) affect inversion quality and whether domain-adaptive priors or normalization are needed.
These gaps outline concrete avenues for improving the theoretical soundness, robustness, scope, and practical utility of FLIP as a reward modeling approach in downscaled regimes and beyond.
Practical Applications
Immediate Applications
Below is a curated set of deployable use cases that leverage the paper’s FLIP method (backward inference of instructions) with small reward models to improve cost, robustness, and effectiveness across industry, academia, policy, and daily life.
- Bold: FLIP reward service for RL pipelines (software/AI development)
- Use case: Replace LLM-as-a-Judge with small FLIP-based reward models in RLHF-style pipelines (e.g., GRPO) to score K rollouts, compute group-normalized advantages, and optimize policies.
- Tools/products/workflows:
- “FLIP Scorer” microservice with an API:
score(instruction x, response y) -> {inferred_x’, F1(x, x’)}. - Integration with Open Instruct/TRL-style training loops for GRPO/DPO variants.
- Logging dashboards showing instruction alignment scores over training.
- Assumptions/dependencies:
- Responses are substantive enough to enable reliable backward inference (longer outputs perform better).
- F1 similarity is adequate; consider fallback metrics (embedding-based or LLM judge) for multilingual settings.
- Safety/refusal cases and single-token answers may require specialized handling (the paper excludes these subsets).
- Bold: Best-of-N (BoN) reranking in production inference (customer support, productivity apps, developer tools)
- Use case: Generate N candidate completions in parallel and select the response with the highest FLIP score; immediately boosts on-topic adherence and quality (especially for longer outputs).
- Tools/products/workflows:
- “BoN with FLIP” wrapper around any chat/model endpoint: sample 8–16 candidates, compute
F1(infer(y), x), return best. - Drop-in replacement for LLM-as-a-Judge rerankers to reduce cost and increase stability with small models.
- Assumptions/dependencies:
- Small models (≤8B) suffice for inference-based reward; ensure token budgets (e.g., 512–2,048) and prompt formatting for inversion.
- Tasks with strict, multi-constraint instructions may still need domain-specific guardrails.
- Bold: Reference-free evaluation and A/B testing (academia, model QA, open-source benchmarking)
- Use case: Automatically evaluate adherence in non-verifiable domains without curated references or rubrics, enabling large-scale A/B tests of model versions and prompts.
- Tools/products/workflows:
- “Auto-Eval Harness” for CI: compute FLIP scores across sampled test suites (e.g., AlpacaEval-like corpora).
- Aggregate “instruction adherence” scorecards for internal model governance.
- Assumptions/dependencies:
- Backward-inference is reliable for typical long-form responses; short one-liners may need task-specific evaluators.
- Bold: RAG guardrails for on-topicness and prompt drift detection (software, search assistants, enterprise knowledge systems)
- Use case: Detect off-topic/hallucinated answers by comparing inferred instruction to the original user prompt; flag or auto-correct retrieval queries or prompts.
- Tools/products/workflows:
- “Prompt Drift Detector”: if
F1(x, infer(y)) < threshold, re-run retrieval, change system prompt, or ask the model to self-correct. - Live dashboards showing drift rates across content categories.
- Assumptions/dependencies:
- Works best when answers include adequate context; threshold tuning needed across domains.
- Bold: Content quality assurance for non-verifiable outputs (marketing, legal drafting support, editorial workflows)
- Use case: Ensure a draft adheres to requested style, structure, and constraints by reconstructing the instruction and measuring similarity; prioritize drafts that follow the brief.
- Tools/products/workflows:
- “Instruction Adherence Checker” plugin for CMS/editor tools (e.g., Google Docs, Notion).
- Highlight mismatched constraints (missing disclaimers, extra sections) using inferred instruction differences.
- Assumptions/dependencies:
- Domain-specific constraints may need custom similarity or rule checks beyond F1.
- Bold: Robustness to reward hacking in evaluations (security, model assurance)
- Use case: Reduce susceptibility to “judge hacking” (prompt injections that inflate scores) by switching to backward inference, which focuses on substantive content rather than appended directives.
- Tools/products/workflows:
- Add FLIP to adversarial evaluation suites; report delta scores under prompt-injection tests.
- Combine FLIP with regex filters/heuristics to catch trivial repeats of the instruction.
- Assumptions/dependencies:
- FLIP is more robust but not invulnerable; adversarial defenses tailored to backward inference should be added over time.
- Bold: Instruction reconstruction for data synthesis and curation (academia, data engineering)
- Use case: Infer instructions from unlabeled responses (logs, forums) to build instruction-response datasets without manual labeling.
- Tools/products/workflows:
- “Instruction Back-Translation” pipeline:
infer(x’|y)pairs for instruction-tuning data creation. - Quality filters using FLIP scores and length thresholds to select strong pairs.
- Assumptions/dependencies:
- Privacy considerations when reconstructing instructions from user-authored content; apply consent and PII filters.
- Bold: Human-in-the-loop review with inferred intent (enterprise content production, compliance reviews)
- Use case: Display the inferred instruction alongside the original to help reviewers spot misalignment (missing requirements, overreach, off-topic content).
- Tools/products/workflows:
- Review UI showing x vs. inferred x’ and their diff; quick accept/revise actions.
- Workflow rules: if similarity < threshold, route for edit or require model self-revision.
- Assumptions/dependencies:
- Reviewer training on interpreting inferred instructions; diff views must be clear and actionable.
- Bold: Automated grading for instruction adherence in open-ended coursework (education)
- Use case: Evaluate whether student answers follow assignment prompts (structure, constraints) without requiring fine-grained rubrics, flagging mismatches for instructor review.
- Tools/products/workflows:
- “Adherence-first grading assistant”: show inferred prompt and adherence score; optionally ask students to revise.
- Assumptions/dependencies:
- Use as formative feedback; avoid high-stakes decisions without human oversight to prevent bias or misinterpretation.
- Bold: On-device/edge reward modeling for local BoN selection (mobile, embedded, robotics)
- Use case: Run small FLIP reward models on-device to select better completions locally, enabling private, low-latency inference-time scaling.
- Tools/products/workflows:
- Lightweight SLM deploys (1–4B) with quantization; mobile APIs for BoN selection.
- Assumptions/dependencies:
- Memory and context window constraints; ensure careful prompt packing and response truncation policies.
- Bold: Pre-send intent checks for email and messaging assistants (daily life, productivity)
- Use case: Infer the intent behind a drafted message and compare with the user’s original prompt/task; prompt revisions if misaligned (missing attachments, unclear asks).
- Tools/products/workflows:
- “Intent Mirror” feature in email clients: show inferred intent and highlight gaps before sending.
- Assumptions/dependencies:
- Respect privacy; opt-in and local processing preferred.
Long-Term Applications
Below are forward-looking use cases that will benefit from further research, scaling, tooling, or standardization before widespread deployment.
- Bold: Multilingual FLIP with semantic similarity beyond F1 (global enterprise, international education)
- Use case: Apply FLIP across languages and domains with embedding-based, cross-lingual similarity or semantic LLM judges for the s(x, x’) function.
- Dependencies:
- Develop multilingual inversion prompts; evaluate fairness/bias; swap F1 for multilingual semantic similarity.
- Bold: Multi-turn and multi-modal instruction adherence (voice assistants, robotics, healthcare documentation)
- Use case: Infer system-level prompts across multi-turn dialogues and integrate perception modalities (speech, vision) to validate adherence across complex tasks.
- Dependencies:
- Conversation-history conditioning and modality fusion; robust inversion for mixed-context outputs; domain safety approvals (e.g., clinical settings).
- Bold: FLIP-specific adversarial defense and certification (security, compliance)
- Use case: Train small reward models to resist backward-inference hacking attempts and certify resilience under standardized red-team suites.
- Dependencies:
- Design attack taxonomies targeting inversion; adversarial training; external auditing standards.
- Bold: Standardized, reference-free evaluation frameworks for non-verifiable domains (policy, procurement, academic benchmarks)
- Use case: Codify FLIP-like evaluation protocols as public standards (benchmarks, metrics, reporting) for model vendor assessment and reproducibility.
- Dependencies:
- Governance processes, community consensus, inter-rater alignment studies, and transparency tooling.
- Bold: Adaptive instruction repair and prompt refinement agents (software agents, enterprise automation)
- Use case: Use inferred x’ to automatically rewrite or clarify the original instruction (resolve ambiguity, add missing constraints) in iterative agent loops.
- Dependencies:
- Safety checks to avoid drift; human approval gates for high-stakes changes; meta-prompt design.
- Bold: Personalized, on-device self-alignment loops (consumer AI)
- Use case: Local RL-style improvement of assistants using small FLIP reward models aligned to user-level preferences without cloud data sharing.
- Dependencies:
- Efficient training on-device; privacy-preserving telemetry; cold-start preference bootstrapping.
- Bold: Agentic coding and complex task orchestration (developer tools, autonomous agents)
- Use case: Combine FLIP reranking with verifiable checks to pick the best code/plan among candidates for tasks blending verifiable and non-verifiable subtasks.
- Dependencies:
- Hybrid reward designs (tests + FLIP); task decomposition; strong traceability of agent decisions.
- Bold: Regulatory and compliance adherence checking for long reports (finance, energy, legal)
- Use case: Infer the intended compliance brief from long outputs and measure adherence (required sections, disclaimers, constraints).
- Dependencies:
- Domain-tuned inversion prompts and similarity criteria; audit trails; legal validation and calibration.
- Bold: Clinical documentation and SDoH summarization adherence (healthcare)
- Use case: Validate that generated notes follow clinical instructions/templates; flag omissions and additions.
- Dependencies:
- Clinical-grade evaluation, privacy and HIPAA compliance, domain adaptation, human oversight.
- Bold: Behavioral telemetry and preference leakage auditing (model safety research)
- Use case: Use inversion signals to detect when outputs systematically align with unintended instructions (contamination or preference leakage).
- Dependencies:
- New auditing metrics, controlled experiments, access to model training metadata.
Notes on Assumptions and Dependencies
- FLIP thrives on longer, context-rich responses; very short or purely verifiable tasks may need hybrid evaluators.
- The similarity function s(x, x’) is currently F1 over tokens; swap or augment with semantic similarity or multilingual LLM judges when needed.
- Safety/refusal behaviors and one-word answers were excluded in the paper’s intrinsic tests; tailor evaluators for these edge cases.
- Backward inference relies on small models’ generative strengths (validation–generation gap); prompt design and context windows are critical.
- While more robust to reward hacking than LLM-as-a-Judge, FLIP is not immune; invest in FLIP-specific adversarial defenses for high-stakes deployments.
- Privacy: instruction reconstruction can expose latent user intent; adhere to consent, minimization, and PII safeguards, especially for data synthesis.
Glossary
- Adversarial attacks: Attempts to manipulate an evaluator or reward model using crafted text to boost scores artificially. "are vulnerable to adversarial attacks that artificially inflate evaluation scores through carefully crafted text sequences"
- Adversarial prompts: Inserted or appended instructions designed to sway the reward model’s decision or ranking. "we evaluate the impact of adversarial prompts on different reward modeling methods."
- Backward inference: Inferring the original instruction from a given response, rather than judging the response directly. "through backward inference: inferring the instruction that would most plausibly produce a given response"
- Bayesian theory: Probabilistic framework used to formalize inference and uncertainty; here, to explain FLIP’s formulation. "We explain our method through Bayesian theory."
- Best-of-N sampling: Test-time strategy that generates N candidates and selects the highest-scoring one. "parallel test-time scaling (Best-of-N sampling)"
- Conditional distribution: A probability distribution of a variable given others; used to model rewards conditioned on instruction and response. "Formally, it defines a conditional distribution: r ∼ p_{\phi}(r \mid x, y)"
- Direct Preference Optimization (DPO): A learning method that aligns models using preference data instead of explicit rewards. "We use the DPO-trained version of OLMo3-7B-Think"
- Downscaled regimes: Settings that use smaller models or limited compute, often challenging for judge-based methods. "reward modeling in downscaled regimes where judgment methods fail."
- Extrinsic evaluations: Assessments of a method by its impact on downstream tasks or performance, outside intrinsic scoring. "improves downstream performance in extrinsic evaluations under test-time scaling via parallel sampling and GRPO training."
- F1 score: The harmonic mean of precision and recall; used as the similarity-based reward in FLIP. "We then define the reward r as the F1 score"
- FLIP (FLipped Inference for Prompt reconstruction): A reference-free, rubric-free reward modeling approach that scores by reconstructing the instruction from the response. "we propose FLIP (FLipped Inference for Prompt reconstruction), a reference-free and rubric-free reward modeling approach"
- Generator–validator inconsistency: A mismatch between a model’s ability to generate correct answers and to validate them. "highlight the prevalence of generator–validator inconsistency in LLMs."
- Graphical models: Structured probabilistic diagrams depicting dependencies among variables in the reward framework. "Graphical models of LLM-as-a-Judge and FLIP."
- Group Relative Policy Optimization (GRPO): An RL algorithm that uses group-based normalization of advantages to optimize policies. "as well as Group Relative Policy Optimization (GRPO) training."
- Group-normalized advantage: An RL signal computed by normalizing advantages within a group to guide policy updates. "and computing a group-normalized advantage to guide optimization."
- Instruction-following: The capability of LMs to adhere to given instructions in their outputs. "FLIP only targets open-ended instruction-following problems"
- Intrinsic evaluation: Assessment within the task itself (e.g., scoring or ranking responses) rather than via downstream effects. "through both intrinsic and extrinsic evaluations"
- LLM inversion: Recovering hidden prompts or inputs using only a model’s outputs. "LLM inversion aims to recover hidden prompts or inputs using only the outputs of a LLM."
- Latent variable: An unobserved variable inferred from data; here, the inferred instruction x′. "Marginalizing over the latent variable x′ yields"
- Listwise Ranking: A ranking approach that considers all candidates jointly to infer an ordering. "Listwise Ranking*"
- LLM-as-a-Judge: Using an LM to directly evaluate and score responses. "LLM-as-a-Judge directly employs as the evaluator"
- Marginal reward distribution: The distribution of rewards after integrating over latent variables. "the marginal reward distribution can be approximated by"
- Maximum a posteriori (MAP) estimate: The most probable value of a variable under the posterior distribution. "maximum a posteriori (MAP) estimate"
- Non-verifiable domains: Tasks lacking objective ground truth, making automatic verification difficult. "particularly in non-verifiable domains"
- Pairwise Ranking: A method that compares responses in pairs to infer preferences. "Pairwise Ranking*"
- Parallel sampling: Generating multiple candidates concurrently and selecting among them at inference time. "test-time scaling via parallel sampling"
- Permutation: A reordering of indices representing the preferred ranking among candidates. "Specifically, we seek a permutation π such that"
- Pointwise Rating: Assigning an absolute score to each response individually. "Pointwise Rating"
- Posterior distribution: Probability distribution of a variable after observing data; here, p_{\phi}(x′ ∣ y). "the posterior distribution p_{\phi}(x′ \mid y) is assumed to be sharply peaked around its mode"
- Preference optimization: Training that aligns models to match human or model preferences. "preference optimization, reranking, and automatic evaluation"
- Preference ordering: An ordered list reflecting which responses are preferred over others. "our goal is to estimate a ranking (i.e., a preference ordering) over these responses"
- Prompt leakage: Unintended exposure of hidden prompts or instructions through outputs. "such as prompt leakage and data exposure"
- Reference responses: Ground-truth or exemplar answers used to evaluate outputs. "without reference responses or rubrics"
- Reinforcement learning (RL): Learning via rewards for actions; central in LM alignment pipelines. "they play a central role in reinforcement learning"
- Reranking: Reordering candidate outputs using a learned or heuristic scoring function. "preference optimization, reranking, and automatic evaluation"
- Reward hacking: Exploiting evaluator weaknesses to obtain high scores with low-quality responses. "robust to common forms of reward hacking."
- Reward models (RMs): Models that assign scores or preferences to responses to guide training and evaluation. "Reward models (RMs) are widely used throughout the LLM (LM) pipeline"
- RLVR: Reinforcement Learning with verifiable rewards; an RL technique used in some LM training pipelines. "which has not been trained with RLVR"
- Rubric-free: Not relying on hand-crafted criteria or checklists to evaluate responses. "a reference-free and rubric-free reward modeling approach"
- System prompt: The instruction framing the assistant’s behavior; distinct from the user’s prompt. "we treat the user prompt as an additional context and infer only the system prompt."
- Test-time scaling: Improving performance by increasing inference-time compute (e.g., sampling more candidates). "test-time scaling via parallel sampling"
- Validation–generation gap: The difference between a model’s ability to validate outputs and to generate them. "We hypothesize that the effectiveness of FLIP stems from the validation–generation gap"
Collections
Sign up for free to add this paper to one or more collections.