- The paper introduces a VLA model adapted for robotic collaboration that infers human intent from motion cues.
- It leverages FiLM conditioning, auxiliary intent loss, and action post-processing to enhance cross-modal alignment and control stability.
- Real-world evaluations reveal challenges like trainer overfitting and latency while achieving compositional tasks in collaborative settings.
Robotic Assistant: Completing Collaborative Tasks with Dexterous Vision-Language-Action Models
Introduction and Motivation
This paper presents a method for enabling dexterous robotic collaboration with humans by adapting pre-trained Vision-Language-Action (VLA) models to infer human intent from motion cues, minimizing reliance on explicit language prompting. The approach is motivated by the limitations of direct LLM deployment in robotics, notably the disconnect between high-level reasoning and low-level control, and the latency introduced by language-based interaction. The proposed system leverages multimodal perception and action generation to facilitate real-time, context-aware collaboration.

Figure 1: The robotic system integrates a Mimic hand, Franka Panda arm, and multi-view cameras for dexterous manipulation.
Data Collection and Collaborative Task Design
A dual-human data collection pipeline is established, involving a teleoperator (using Rokoko mocap gloves for robot control) and a collaborator (interacting naturally with the robot). The system records synchronized sensory and control data, augmented with text prompts and auxiliary labels (e.g., 3D hand pose, target object index) to enhance intent interpretation.


Figure 2: The collaborator interacts with the robot, providing natural motion cues for intent inference.

Figure 3: The synchronized dataset structure includes multimodal sensory data, text prompts, and auxiliary intent labels.
Two representative tasks are designed: "pick up cube" (robot infers and picks up the cube indicated by the human) and "pass cube" (robot passes the held cube to the human). These tasks are composable, enabling long-horizon evaluation of collaborative behavior.
Model Architecture and Modifications
The foundation is Open-VLA, which fuses visual (SigLIP, DINOv2), linguistic (LLaMA2-7B), and proprioceptive inputs via a multimodal transformer. Several architectural modifications are introduced:
Training and Inference Pipelines
Training is performed on a 4×H100 GPU cluster using bfloat16 precision and LoRA adapters for efficient fine-tuning. The pipeline samples frames from demonstration trajectories, processes inputs, and optimizes a composite loss (action + auxiliary) via Adam. Hyperparameters are tuned for stability and throughput.

Figure 5: Distributed training pipeline with data collation, preprocessing, and model optimization.
Inference involves streaming real-time observations to the model, which outputs actions with ~0.3s latency on an RTX 4090. A rule-based high-level planner sequences tasks by monitoring hand position, switching prompts to chain behaviors.
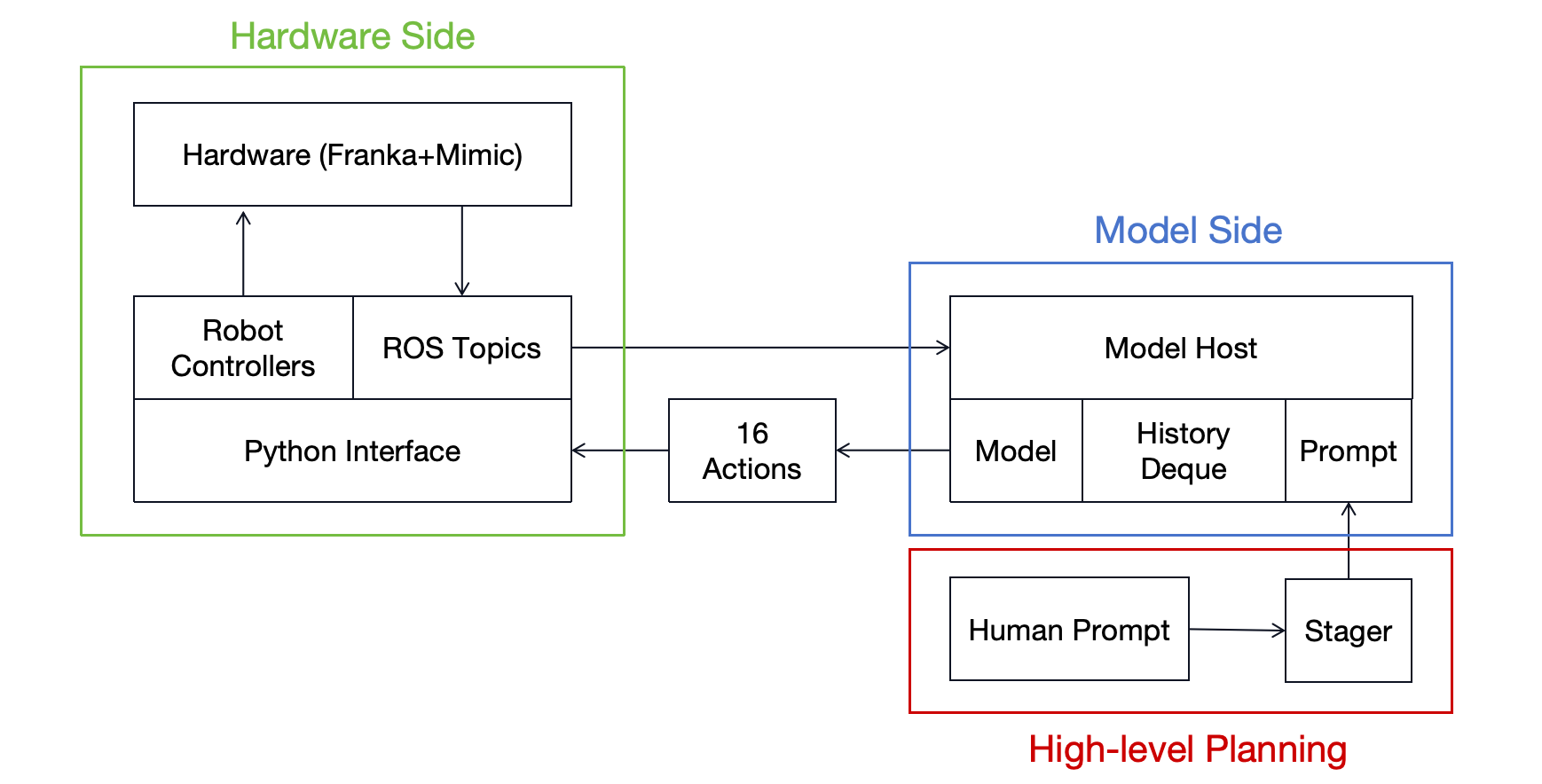
Figure 6: Inference pipeline with hardware interface (green), model host (blue), and high-level planner (red).
Action Space Analysis
Empirical analysis reveals that the raw action space is highly non-convex, but delta encoding yields a smoother, near-Gaussian distribution. PCA on hand joint states shows that four principal components explain 96% of variance, justifying dimensionality reduction.


Figure 7: Original action distribution is non-convex, complicating direct learning.
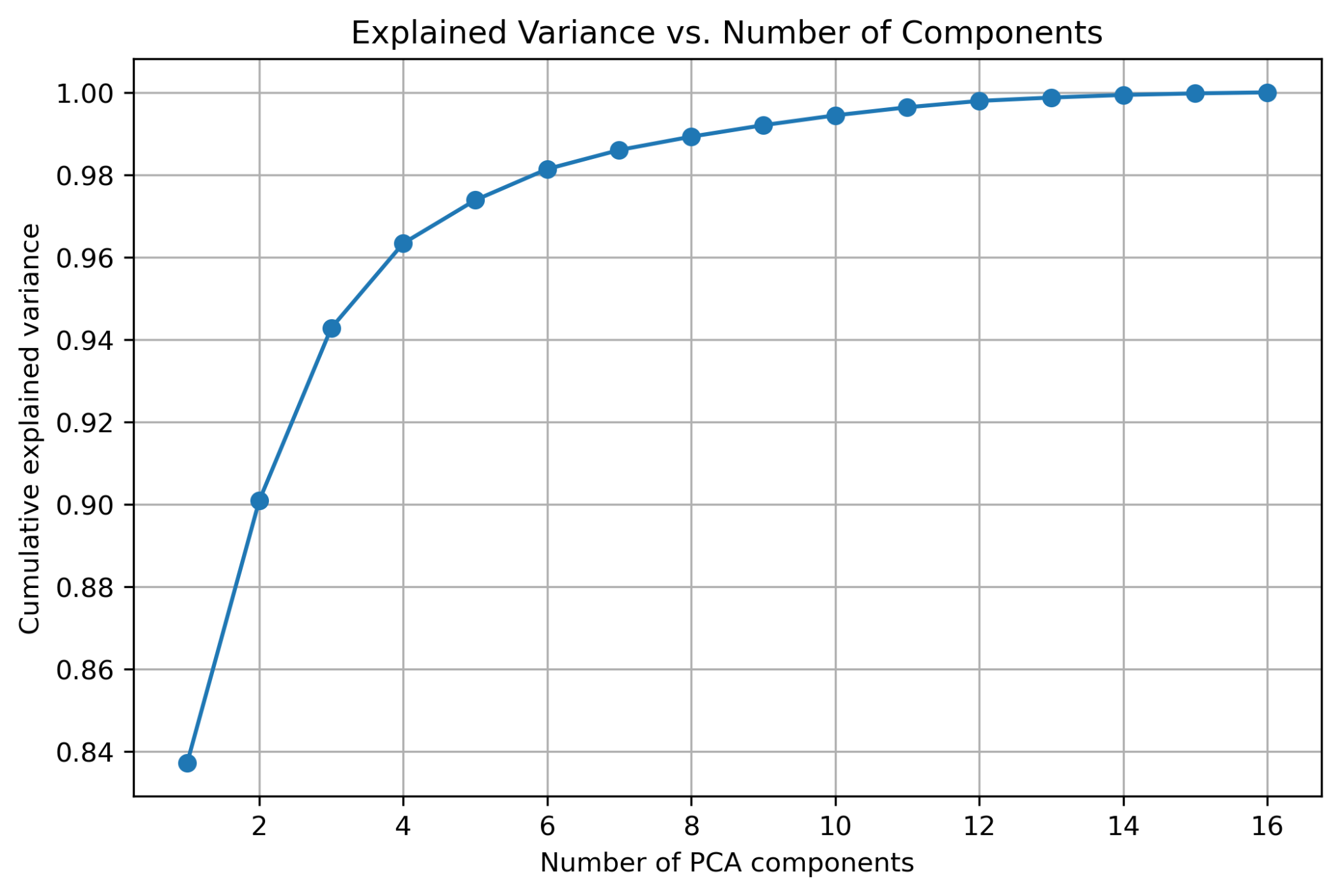
Figure 8: PCA analysis of hand joint states; four components capture 96% of variance.
Ablation Studies
Ablation experiments demonstrate that action post-processing is the most impactful modification, significantly improving all metrics. Auxiliary hand-pose loss provides consistent but modest gains. Directional loss and FiLM conditioning yield mixed results, with directional loss generally detrimental and FiLM beneficial only for low-dimensional objectives.

Figure 9: Ablation study results; full model excludes directional loss and FiLM conditioning for optimal performance.
Trainer Overfitting and Generalization
A notable finding is "trainer overfitting": models trained on a single collaborator generalize poorly to new users, reverting to fixed routines. Auxiliary loss curves confirm elevated error when evaluated on unseen collaborators, highlighting a critical limitation for real-world deployment.

Figure 10: Auxiliary loss increases when evaluated on different-hand collaborators, evidencing trainer overfitting.
Real-World Evaluation
Real-world trials show that the model can successfully execute the combined long-horizon task (pick up then pass cube) in 1 out of 10 attempts. Failures are primarily due to misinterpretation of collaborator intent, attributed to trainer overfitting and limited data diversity.

Figure 11: Snapshots of successful real-world inference for pass, pick up, and combined tasks.
Implications and Future Directions
The results indicate that VLA models, when equipped with appropriate inductive biases (FiLM, auxiliary loss, action post-processing), can be adapted for collaborative robotics. However, generalization across users and latency remain significant challenges. Addressing trainer overfitting will require larger, more diverse datasets and potentially meta-learning or domain adaptation techniques. Latency reduction is essential for fluid interaction, with temporal ensembling and model optimization as promising avenues. Transitioning from rule-based to embodied chain-of-thought planning could further enhance adaptability in dynamic environments.
Conclusion
This work demonstrates that fine-tuned VLA models can facilitate dexterous, context-aware human-robot collaboration by inferring intent from motion cues. Architectural modifications—particularly action post-processing and auxiliary intent modeling—are critical for efficient learning and robust performance. While the system achieves real-time inference and compositional task execution, generalization and latency remain open challenges. Future research should focus on scalable data collection, cross-user generalization, and advanced planning for deployment in complex, open-ended collaborative scenarios.


