- The paper introduces RePro, a process-level reward framework that treats LLM reasoning as an optimization trajectory, improving solution accuracy and efficiency.
- It employs dual scoring—magnitude for progress and stability for smoothness—to mitigate overthinking and reduce inefficient token usage.
- Empirical results across math, science, and code benchmarks demonstrate improved accuracy, lower token cost, and reduced backtracking in LLM reasoning.
Rectifying LLM Reasoning via Optimization Process-Level Rewards: An Expert Analysis
Introduction
"Rectifying LLM Thought from Lens of Optimization" (2512.01925) introduces RePro (Rectifying Process-level Reward), a process-level reward framework designed to refine the reasoning trajectories of LLMs. The work focuses on chain-of-thought (CoT) reasoning in LLMs, which, although pivotal for complex problem solving, often suffers from suboptimal dynamics—notably overthinking and lengthy, inefficacious token sequences. The RePro framework approaches reasoning as an optimization trajectory, analogous to a gradient descent process, and aims to induce more efficient and effective LLM reasoning by integrating process-level optimization metrics within reinforcement learning post-training.
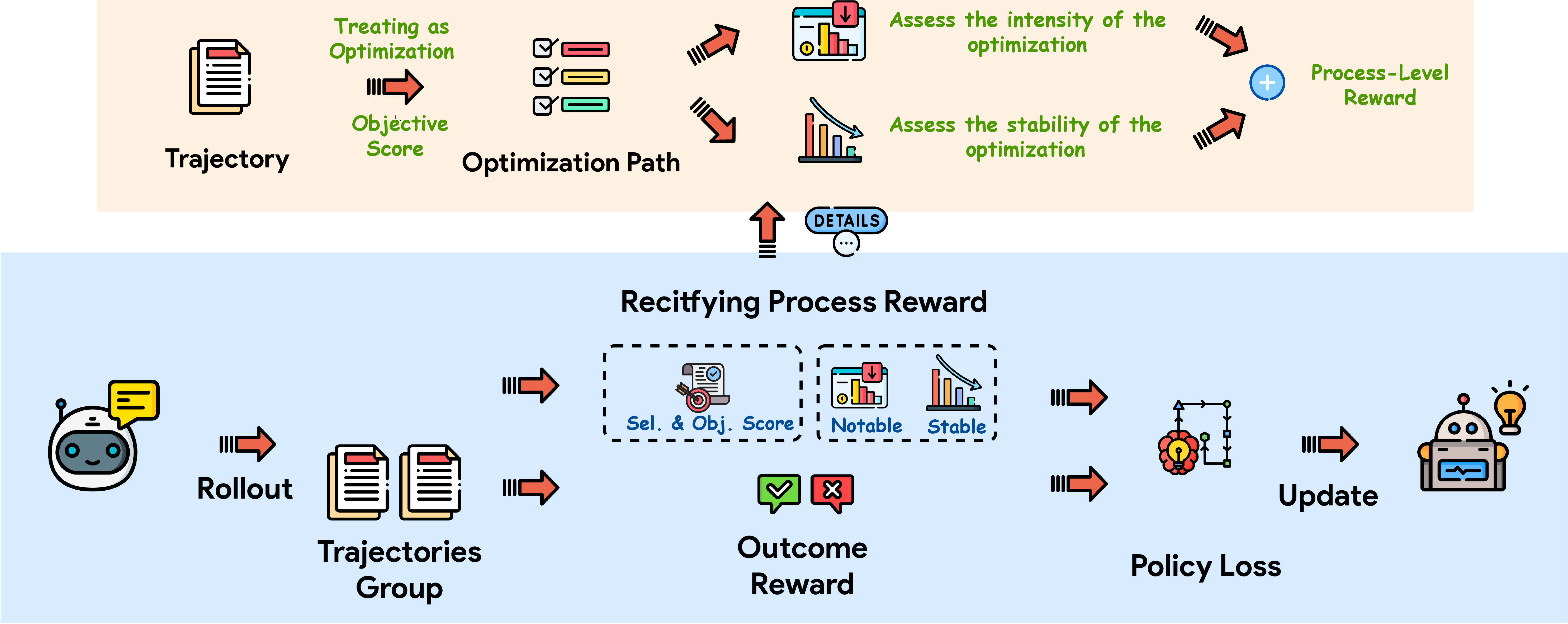
Figure 1: The RePro framework conceptualizes LLM reasoning as an optimization process and integrates rectifying process-level rewards into RLVR training.
Process-Level Reasoning as Optimization
The central theoretical premise is the optimization lens: CoT prompting is treated as a gradient update process through which the model iteratively approaches problem resolution. Each reasoning step is viewed as an update to the model's internal state, and the overall trajectory is assessed in terms of progress toward higher confidence on ground-truth answers.
The surrogate objective function, J~, is defined as the model's log-likelihood (normalized by answer length) of generating the correct answer, conditioned on the context at each reasoning step. Empirical results demonstrate monotonic improvement of J~ as reasoning unfolds in successful trajectories:
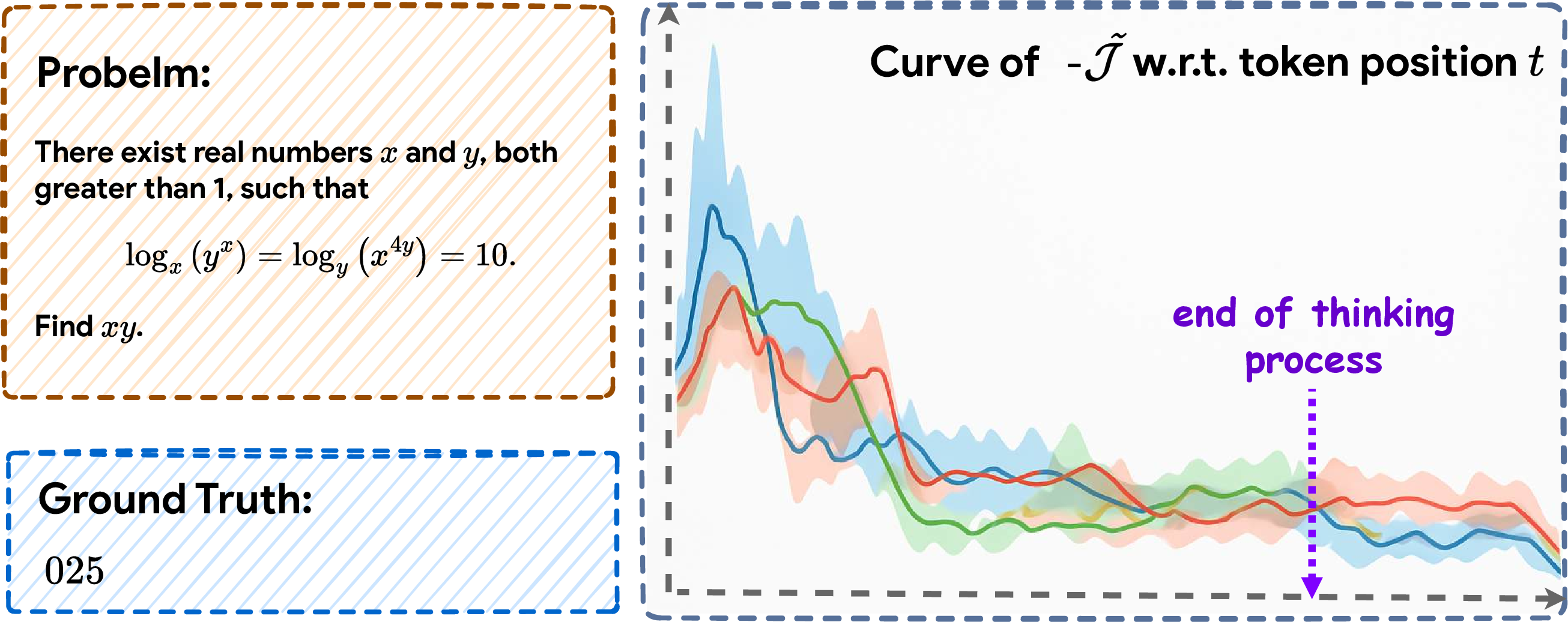
Figure 2: Empirical evidence that −J~ systematically decreases (i.e., confidence increases) across correct reasoning trajectories, validating it as a proxy for progress monitoring.
Dual Scoring: Quantifying Optimization Trajectories
To quantify process quality, RePro introduces a dual scoring mechanism:
- Magnitude Score (smagn): Measures relative improvement in J~ over a greedily-predicted baseline, normalized by a tanh to mitigate extreme fluctuations.
- Stability Score (sstab): Measures smoothness/monotonicity of the update sequence, leveraging Kendall's Tau for oscillation assessment.
Scores are combined via a weighting hyperparameter w to produce the final process-level score, which serves as a rectifying reward signal for RL updates.
Integration with RLVR and Training Considerations
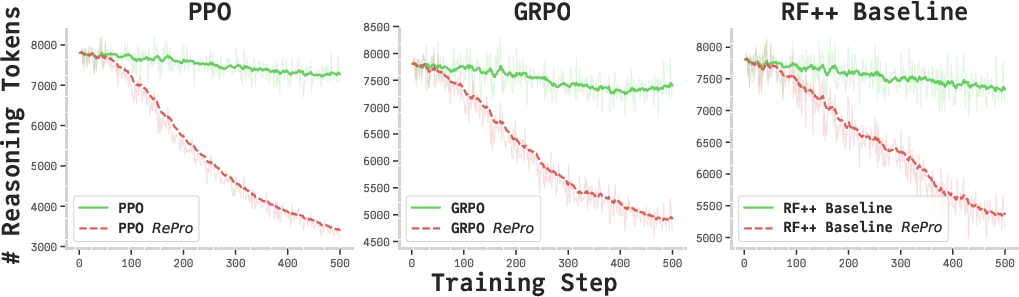
RePro is implemented as an additional process-level reward term in RL with verifiable rewards (RLVR) pipelines (including PPO, GRPO, REINFORCE++ variants), augmenting the standard outcome-based advantages. To contain computational cost, only high-entropy reasoning segments—indicative of major decision points—are selected for reward computation, exploiting segment entropy as an efficient proxy for key trajectory updates.
Reward normalization strategies are detailed for compatibility with common actor-critic-free RL algorithms, ensuring stable policy updates across batch, trajectory, and segment dimensions.
Empirical Evaluation
Extensive benchmarks across mathematics (AIME24/25, MATH500, LiveMathBench), science (GPQA-Diamond), and code (MBPP, LiveCodeBench) show that RePro yields consistent, sometimes substantial, improvements over vanilla RLVR post-training schemes. Notably:
The framework also significantly reduces inference token cost while maintaining or improving accuracy:
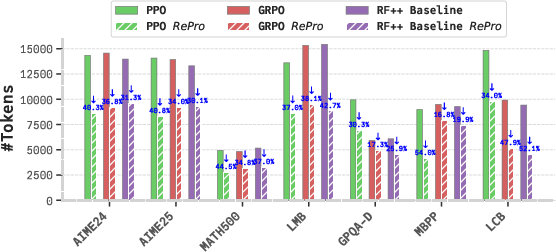
Figure 4: Reasoning token cost at inference for DeepSeek-R1-Distill-Qwen-1.5B; RePro achieves superior efficiency relative to baselines.
Analogous results are replicated on higher-capacity models:
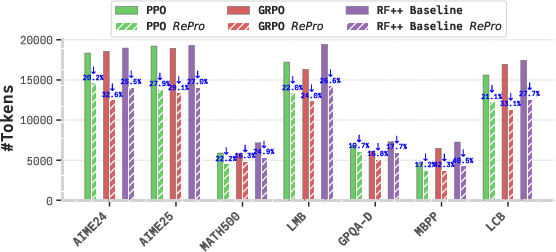
Figure 5: Reasoning token cost for Qwen3-1.7B; RePro consistently promotes higher efficiency than standard RLVR objectives.
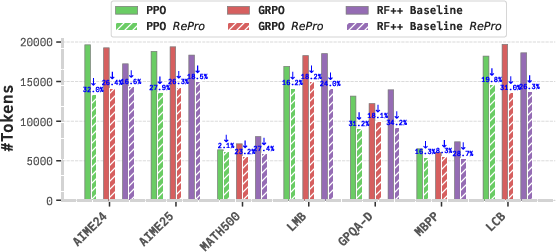
Figure 6: RePro reduces token cost for Hunyuan-1.8B-Instruct, maintaining token efficiency trends across families.
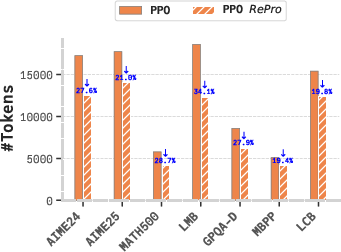
Figure 7: Evaluation on Qwen3-8B verifies scalability: RePro meaningfully reduces token cost for large-scale models.
Diagnosing and Modifying Reasoning Behaviors
Qualitative and quantitative analyses reveal RePro's effect in eliminating suboptimal thinking patterns, such as excessive backtracking, redundant re-statements, and inefficient exploration, as corroborated by introspective pattern recognition tools and token-count studies. Notably, RePro models demonstrate:
- Higher utility per token during generation.
- Sharply reduced backtracking incidence (ineffective revisits of previously traversed solution paths).
- More linear, decisive chains—indicative of a more efficient optimization process rather than unconstrained, meandering exploration.
Implications and Future Directions
RePro demonstrates that process-level optimization metrics are effective for supervising LLM reasoning, transcending the limitations of purely outcome-based or coarse token-length regularization. Its architecture- and RL-backbone-agnostic design positions it as a general mechanism for mitigating inefficient, over-thought trajectories without stifling necessary deliberation.
Practically, such efficiency directly impacts real-world LLM deployment by:
- Reducing latency and compute cost, critical for large-scale, real-time applications.
- Allowing finer-grained adjustment of model reasoning depth versus efficiency depending on task requirements.
Theoretically, this paradigm invites further investigation into meta-optimization of model reasoning, where LLMs may be taught optimization heuristics for their own cognitive process.
Potential future lines include:
- Adversarial or curriculum-style supervision to further enhance reasoning robustness.
- Extending process-level rewards to multi-modal, agentic, or memory-augmented LLM frameworks.
- Unifying process- and outcome-level rewards for dynamic, context-sensitive reasoning control.
Conclusion
This work establishes RePro as a compelling process-level supervision framework for rectifying the inefficiencies inherent in long-CoT LLM reasoning (2512.01925). By formulating reasoning as an optimization trajectory and rewarding progress and stability at the process level, RePro advances both the efficiency and accuracy of LLMs in mathematical, scientific, and code domains. Its generality, empirical robustness, and compatibility with diverse RL algorithms and model architectures underscore its relevance for both practical system development and theoretical advancement in controllable, interpretable LLM reasoning.