Features as Rewards: Scalable Supervision for Open-Ended Tasks via Interpretability
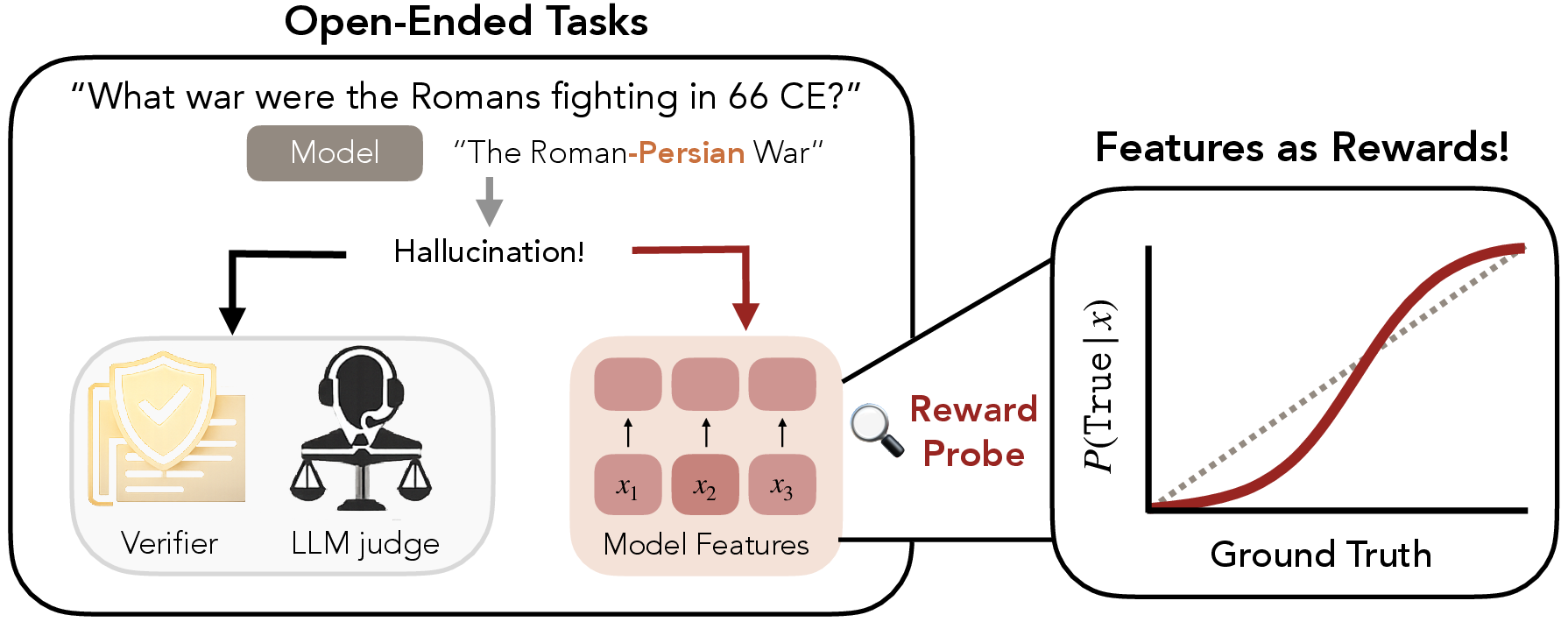
Abstract: LLMs trained on large-scale datasets have been shown to learn features that encode abstract concepts such as factuality or intent. Such features are traditionally used for test-time monitoring or steering. We present an alternative affordance: features as scalable supervision for open-ended tasks. We consider the case of hallucination-reduction as a desirable, yet open-ended behavior and design a reinforcement learning (RL) pipeline, titled RLFR (Reinforcement Learning from Feature Rewards), that uses features as reward functions. Grounded in a novel probing framework that identifies candidate hallucinated claims, our pipeline teaches a model to intervene and correct its completions when it is uncertain of their factuality. Furthermore, the pipeline enables scalable test-time compute, guided once more by our reward features. This end-to-end process operationalized on Gemma-3-12B-IT results in a policy that is 58% less likely to hallucinate compared to the original model (when run in tandem with our probing harness), while preserving performance on standard benchmarks. Taken together, by grounding supervision in the language of features, this paper introduces a novel paradigm in the use of interpretability for learning open-ended tasks.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching AI LLMs to “know when they don’t know” and to fix their own mistakes. The authors show a new way to reduce hallucinations—times when an AI confidently makes something up—by using the model’s own internal signals as guidance. They call their approach RLFR, short for Reinforcement Learning from Feature Rewards.
What questions did the researchers ask?
- Can we use what a model “internally believes” to guide it toward better behavior on open-ended tasks (like being factual), where it’s hard or expensive to check every answer?
- Specifically, can we reduce AI hallucinations by training the model to retract or correct doubtful claims using its own internal features, instead of always relying on a slow, expensive outside judge?
How did they do it?
Think of a LLM as having lots of tiny meters and dials inside it that track ideas like “Is this statement true?” or “Am I confident about this claim?” These hidden meters are called features. The researchers:
- Found the model’s internal “factuality meters”
- They used simple tools called probes (like thermometers that read a meter) to detect:
- Where a claim is being made in the text (localization).
- Whether that claim is likely made up (classification).
- To get reliable training labels, they sometimes used an external, expensive judge AI with web search to mark claims as supported or hallucinated. Then they trained cheap probes to mimic that judge’s decisions using the model’s internal features.
- They used simple tools called probes (like thermometers that read a meter) to detect:
- Taught the model to intervene on risky claims
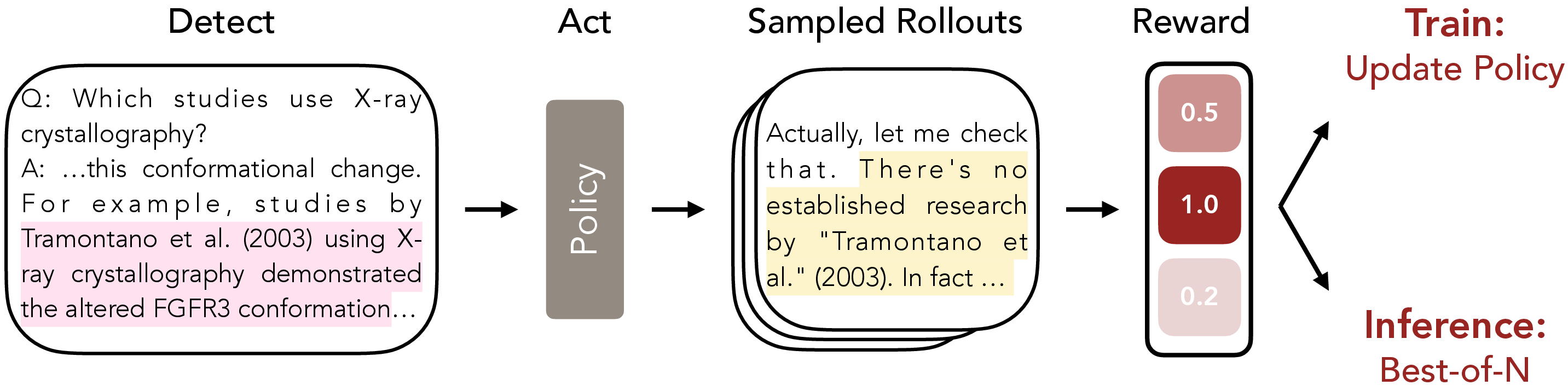
- When the probes flag a suspicious claim, the model starts a small side task where it chooses one of three actions:
- Maintain (keep the claim),
- Retract (say “I’m not sure” and pull it back),
- Correct (fix it with a more accurate, specific statement).
- The model then writes a short, targeted retraction or correction.
- When the probes flag a suspicious claim, the model starts a small side task where it chooses one of three actions:
- Rewarded good fixes using internal features
- Instead of always asking the expensive judge if a fix is good, they trained new probes that score retractions and corrections by reading the model’s own features.
- This turns the model’s internal signals into a fast, cheap “reward function” telling it how well it did.
- Reinforced good behavior (Reinforcement Learning)
- The model practices thousands of times. It gets higher rewards when it retracts or corrects appropriately (and remains clear and on-topic).
- Over time, it learns to avoid hallucinations and to step in when it’s unsure.
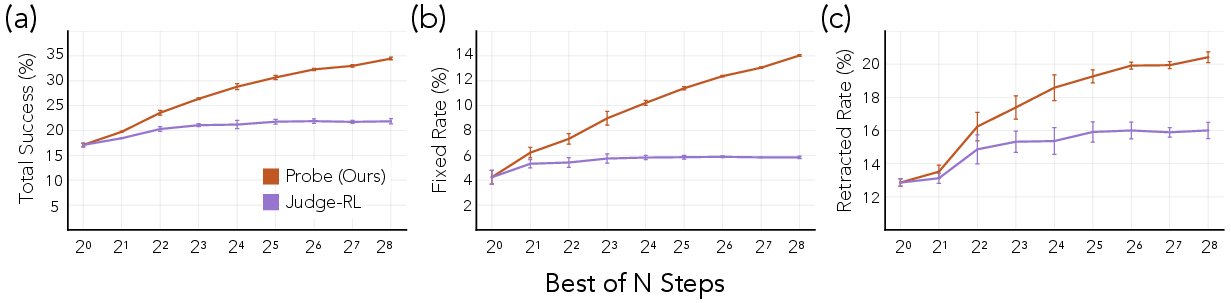
- Used test-time selection to improve answers
- At answer time, the model can generate several possible fixes and use the probes to pick the best one (this is called “Best-of-N” sampling—like brainstorming multiple options and choosing the strongest).
In short: they turned the model’s own internal “belief meters” into a fast coach that trains it to be more factual and self-correcting.
What did they find?
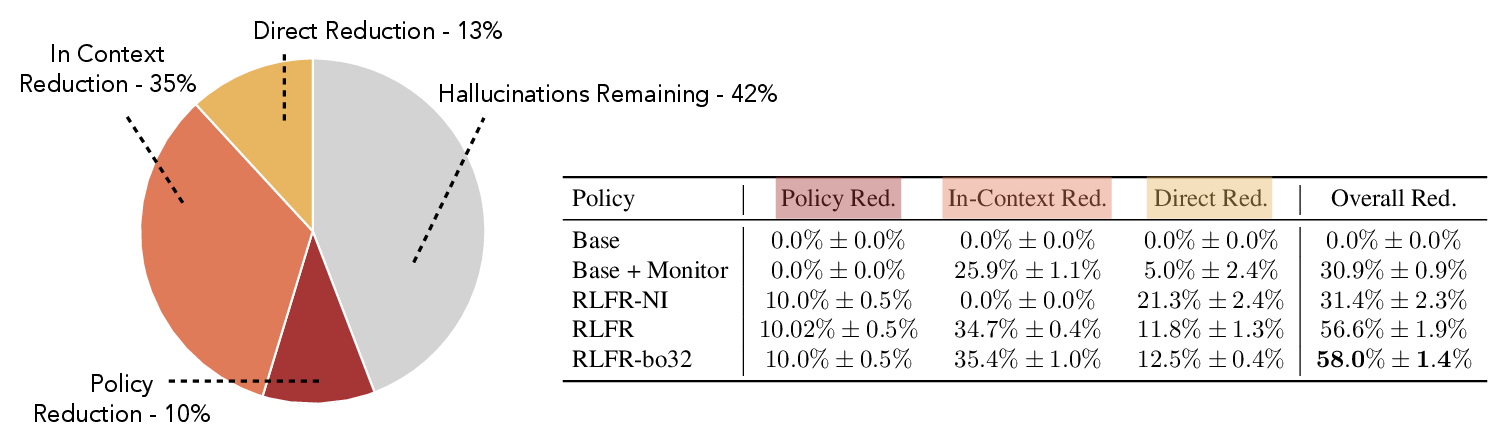
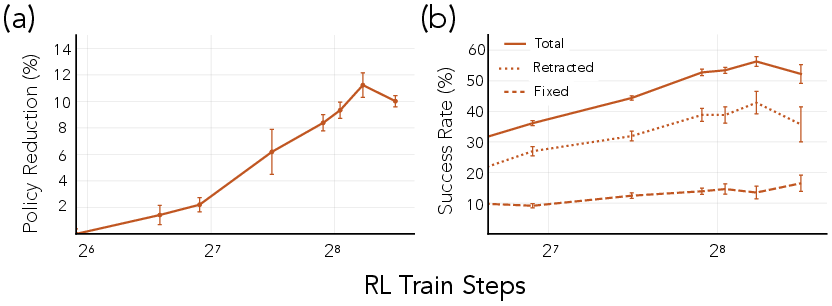
- Big drop in hallucinations
- Using their full pipeline, the trained model was 58% less likely to hallucinate than the original model.
- Some of this came from the model being safer by default, and some came from the model inserting helpful retractions/corrections into the answer.
- Much cheaper than always using an external judge
- Their feature-based rewards were about 90 times cheaper per graded intervention than using a powerful judge model with web search.
- Works even better with “pick the best of many”
- Generating multiple candidate fixes and selecting the best with the probes made corrections and retractions more accurate.
- Keeps normal skills intact
- On standard tests (like general knowledge and reasoning benchmarks), the trained model performed about the same as before. In other words, it didn’t become worse at other tasks.
- Doesn’t just “say less”
- The model didn’t simply stop making claims to avoid being wrong. It made a similar number of claims but did a better job of retracting or correcting doubtful ones.
Why is this important?
- A scalable way to supervise open-ended skills
- Some tasks (like “be factual,” “be helpful,” or “be polite”) are hard to judge automatically and expensive to grade with humans or judge AIs. This method uses the model’s own features as a fast, dense training signal, making it practical to train for these behaviors at scale.
- Better alignment by design
- The approach shows how interpretability (understanding a model’s internal signals) can directly improve training, not just monitoring. It shifts interpretability from “watching” to “teaching.”
- Flexible and general
- Although they focused on hallucinations, the same idea could be applied to other open-ended goals, like reducing sycophancy (agreeing too easily) or controlling verbosity, while keeping performance high.
Bottom line
The authors show a new, practical way to make AI models more reliable: read their internal “belief meters,” use those signals to reward good behavior, and train them to retract or correct risky claims. This cuts hallucinations by more than half, stays affordable, and keeps the model’s general abilities intact—paving the way for building AI that’s not just smart, but also self-aware about its own uncertainty.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete, actionable directions that the paper leaves open.
- Generalization to other open-ended behaviors: Validate RLFR beyond hallucination reduction (e.g., sycophancy/agreeableness control, verbosity reduction, safety alignment) and assess whether calibrated features exist and remain usable as rewards for these behaviors.
- Cross-model and cross-domain transfer: Test probe robustness and reward effectiveness across different model families/sizes (7B–70B+, multimodal) and domains (medical, legal, code), including cross-lingual settings.
- Probe calibration and robustness under deployment: Quantify calibration drift and stability of localization/classification probes under streaming generation, different decoding settings (temperature, top-p), and distribution shifts.
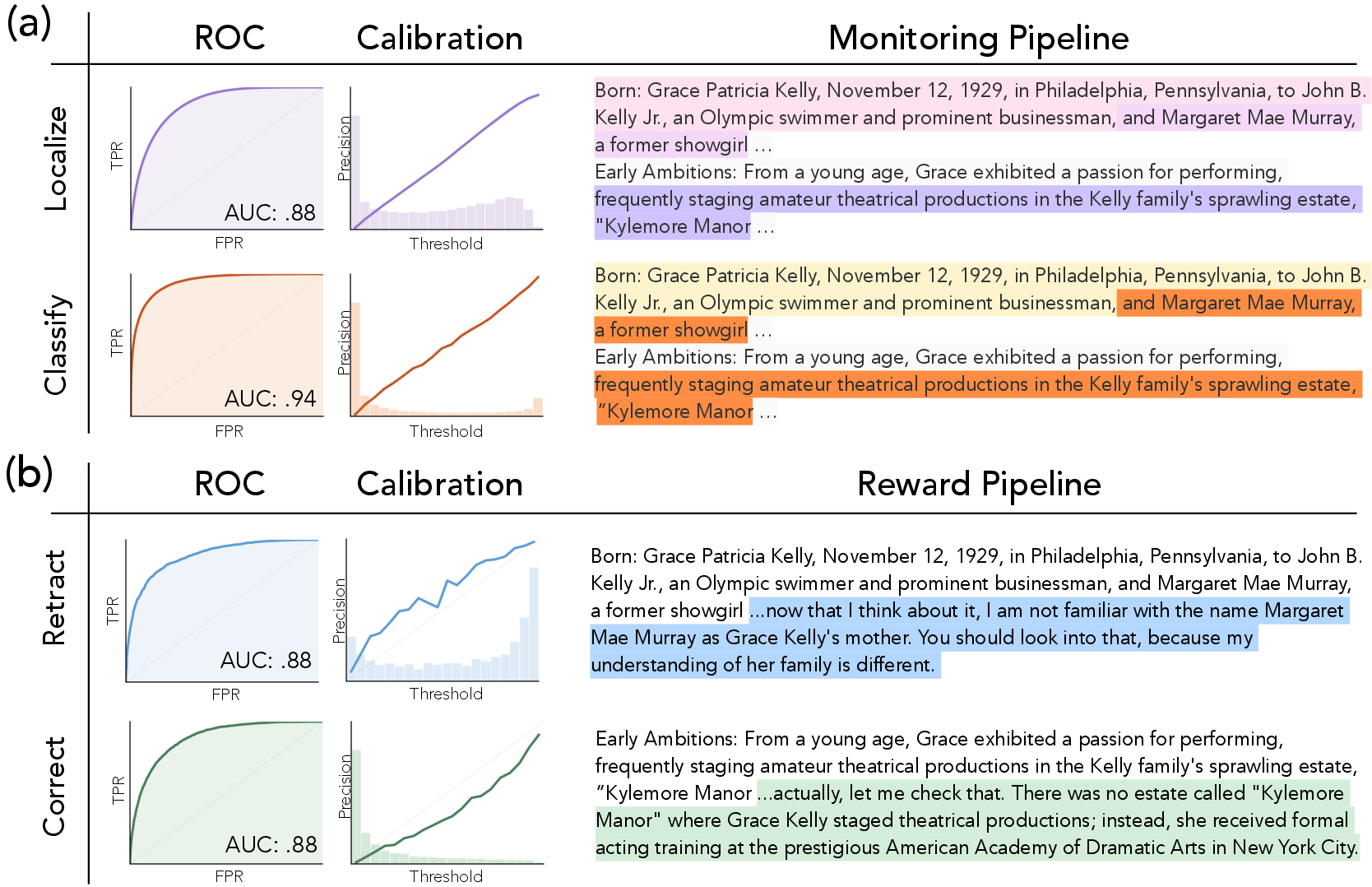
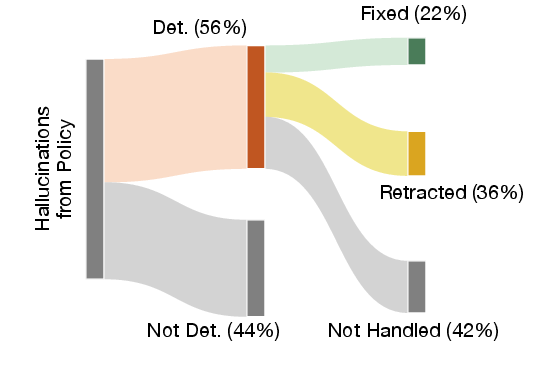
- Missed detections and thresholding: Improve recall of the monitoring pipeline (currently ~56–61%) via better segmentation, threshold tuning, and false-negative analysis; develop principled methods to balance precision–recall for real-time use.
- Entity segmentation quality: Audit and improve the definition and extraction of “falsifiable spans” (Entity boundaries, multi-sentence claims, nested claims), including multi-claim resolution and language-specific segmentation errors.
- Dependence on Gemini 2.5 Pro as ground truth: Replicate labels with independent human evaluators and open-source judges; quantify systematic biases, variance, and failure modes of the judge+search pipeline.
- Reward hacking and evasion risk: Assess whether the student can inflate probe scores without improving factuality; develop adversarial evaluations and anti-gaming strategies (e.g., probe ensembles, causal tests, randomization).
- Stability of reward probes on student vs. base activations: Characterize how far training can drift before probe orderings degrade; test longer training runs, different RL protocols, and heavier updates.
- Best-of-N (BoN) selection strategy: Analyze the cost–benefit of BoN at different N under deployment constraints; explore alternative selection mechanisms (e.g., bandit selection, top-k reranking, diversity-aware sampling).
- Lagrangian constraint choice (60:40 corrections:retractions): Study sensitivity to this ratio, derive principled estimation from data, and explore adaptive or learned constraints over time.
- Aggregating rewards across multiple entities: Develop principled multi-entity scoring and credit assignment (e.g., weighted aggregation, per-entity constraints) rather than single-entity intervention selection.
- RL credit assignment and algorithm choice: Compare CISPO to alternative RL methods (off-policy, actor–critic, sequence-level vs. token-level credit assignment) and quantify sample efficiency and stability.
- Reward composition and weighting: Examine how legibility and substantive-ness (judged in token space) interact with feature-based rewards; perform sensitivity analyses and ablations on multiplicative vs. additive schemes.
- Direct avoidance vs. post-hoc correction: Introduce explicit rewards/penalties for proactively avoiding hallucinations (not just intervening after detection) and measure trade-offs with helpfulness/coverage.
- Mechanistic validation of features-as-beliefs: Provide causal evidence that probes measure beliefs/uncertainty (e.g., representation interventions, causal scrubbing); distinguish correlation from causation.
- Inline intervention effects: Mechanistically explain why in-context interventions reduce hallucinations; analyze representation changes during inline correction and test persistence across subsequent tokens/tasks.
- Degeneracy under repeated/severe interventions: Detect and mitigate the reported OOD degeneration when many interventions are inlined (e.g., fallback to notinline, escalation to expensive judges, adaptive budgets).
- Fairness and bias audits: Evaluate whether probe scores and interventions vary across topics, demographics, dialects, or languages; develop fairness diagnostics and mitigations.
- Evaluation independence and external validity: Use disjoint prompts, alternative judges, and human panels to ensure that improvements are not artifacts of the shared prompting/tooling stack.
- Human A/B preference and trust: Extend the blind preference test beyond a single rubric; measure user trust, perceived honesty, and willingness to accept retractions, and quantify trade-offs with verbosity and helpfulness.
- Tool-use contexts: Test RLFR when the model has access to tools (search, retrieval, calculators), including multi-step verification and iterative correction loops.
- Deployment feasibility with closed models: Address practical constraints where internal activations are inaccessible; explore proxy features (e.g., log-prob features, embeddings) or distillation of probes to token-space judges.
- Alternative probe architectures: Compare attention-based probes to geometric/structural probes, sparse autoencoders, or linear probes; quantify trade-offs in calibration, interpretability, and compute.
- Cascaded oversight design: Implement and evaluate cascades where low-confidence probe detections trigger more expensive judges, optimizing latency, accuracy, and cost under budgets.
- Topic-wise performance and risk: Report per-domain hallucination reduction, false positives/negatives, and off-target effects (e.g., over-cautiousness) to identify where RLFR helps or hurts most.
Glossary
- Activations: The internal numerical representations produced by a model’s layers during processing; often used as inputs to probes or analyses. "These are run on activations from the separate (intervention) context"
- Attention heatmaps: Visualizations of attention weights that indicate which tokens a model focuses on when making predictions. "We use Attention heatmaps to coarsely assess what information the reward probes focus on"
- Attention-based architectures: Model or probe designs that leverage attention mechanisms to incorporate contextual information. "All of our probes use attention-based architectures, following recent work"
- AUC-ROC: Area Under the Receiver Operating Characteristic curve; a metric for classifier performance across thresholds. "First, we ensure that each of them have high AUC-ROC, which is our main metric for selecting probes."
- Best-of-N (BoN) sampling: An inference strategy where multiple candidate outputs are sampled and the best is selected according to a scoring function. "improving the trained policy's performance via standard techniques like Best-of-N (BoN) sampling \citep{snell2024scaling}"
- Cascaded monitors: A layered monitoring approach where cheaper signals trigger more expensive checks when confidence is low. "probes for defining cascaded monitors that function alongside highly capable LLMs"
- Causally efficacious: A property of a representation whose intervention reliably changes model behavior, indicating causal involvement. "when the decoded quantity is causally efficacious—in the sense that interventions on the associated representation systematically change behavior—probing supports a stronger claim"
- CISPO: A specific policy optimization protocol used during reinforcement learning. "with CISPO \citep{chen2025minimax} as our policy optimization protocol."
- Dense supervision: Frequent, fine-grained training signals that guide learning, as opposed to sparse rewards. "transform a model's features into an inexpensive, dense signal for learning open-ended tasks?"
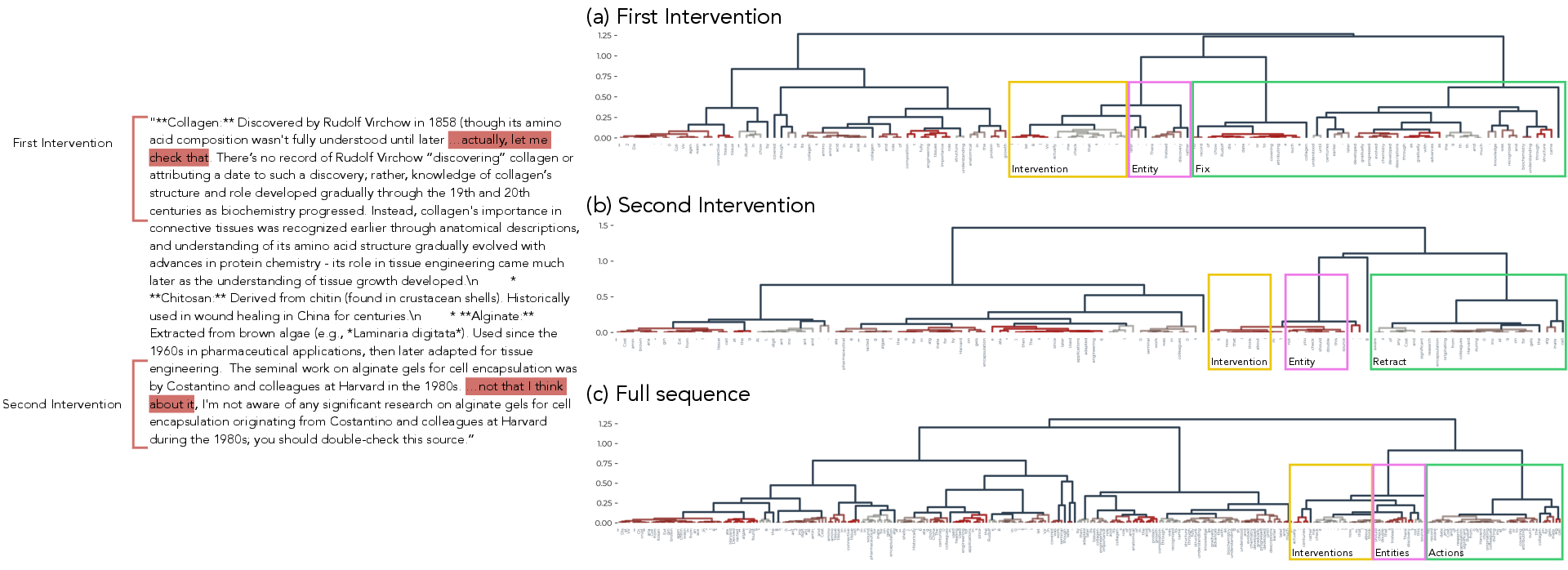
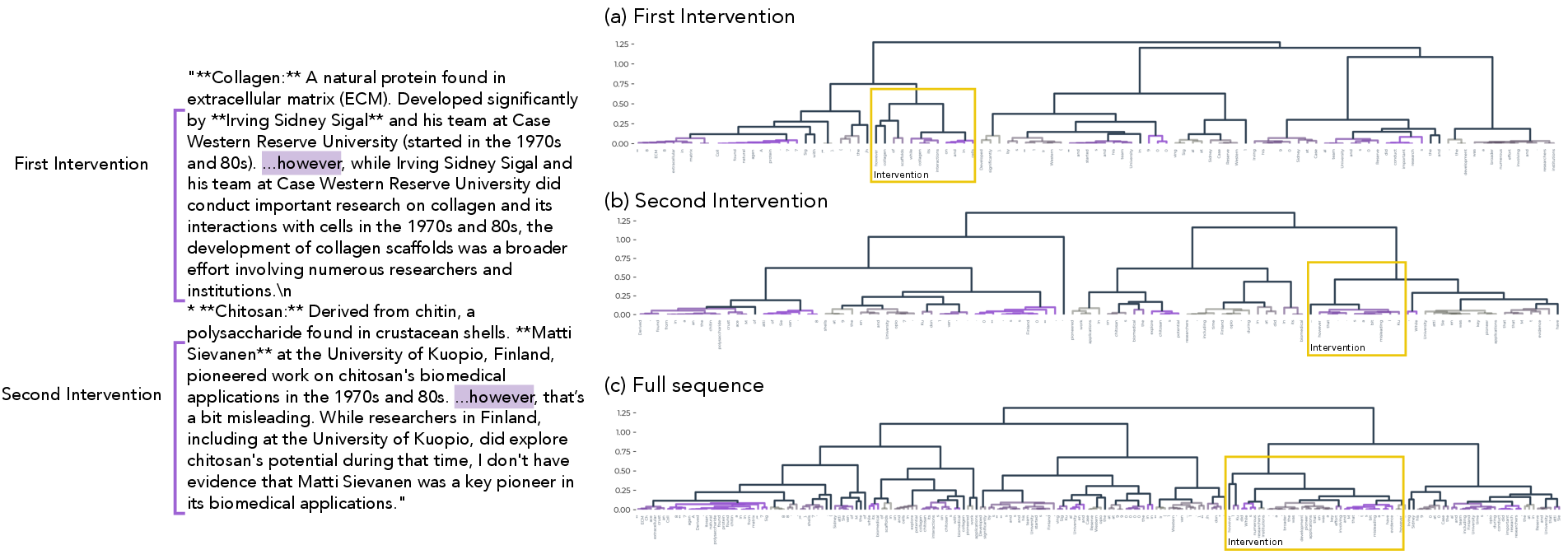
- Entity: A localized span representing a single falsifiable claim used for hallucination detection and intervention. "where an Entity is a single claim that is to be tested for hallucinations."
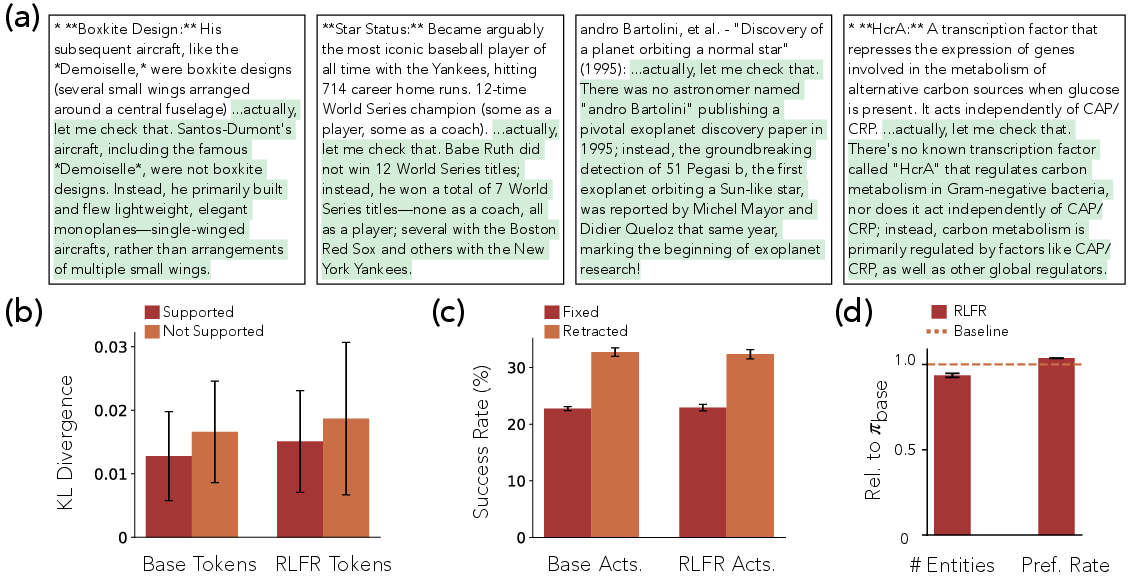
- Forward KL divergence: The Kullback–Leibler divergence computed in the forward direction to measure distributional drift (P||Q). "We compute the per-token forward KL divergences between the base and RLFR'd model"
- Frozen parameters: Model weights kept fixed to prevent gaming of monitors and preserve consistency during evaluation. "We mitigate this issue by running the probe on a frozen set of parameters"
- Hallucination: An unsupported or false claim generated by a LLM. "the persistent problem of hallucinations in LLMs"
- Hallucination-monitoring pipeline: A system that detects potential hallucinations and triggers corrective interventions. "a novel hallucination-monitoring pipeline as well as an intervention-and-reward pipeline."
- In-context learning (ICL): The phenomenon where models adapt their behavior within a single prompt based on provided examples or interventions. "This has 'trickling effects' on the remainder of the rollout through in-context learning (ICL)"
- Inline interventions: Corrections inserted directly into the ongoing generation context to influence subsequent output. "which we refer to as an 'inline intervention'"
- Inverse RL: Inferring a reward function from observed behavior to enable reinforcement learning. "often framed as inverse RL or preference learning"
- Interpretability: Techniques for understanding and analyzing the internal representations and computations of models. "interpretability techniques such as probes."
- Lagrangian: An optimization construct that incorporates constraints via multipliers in the training objective. "we utilized the Lagrangian of a pre-determined population level constraint"
- Latent preferences: Underlying, unobserved preference signals inferred from comparisons or behavior. "infer latent preferences from observed comparisons (often framed as inverse RL or preference learning)"
- Latent variables: Unobserved factors or concepts that explain patterns in the data and are represented in model features. "concepts (latent variables) underlying their generative processes"
- Localization probe: A probe that identifies the boundaries of claim spans (Entities) within text. "The localization probe predicts at each token whether it is in an Entity with the previous token"
- Longfact++ dataset: A benchmark dataset designed to elicit long-form generations containing falsifiable claims. "we use the Longfact++ dataset~\citep{obeso2025real}"
- LLM-as-a-judge: Using a LLM to evaluate or score outputs instead of a programmatic verifier. "versus our LLM-as-a-Judge baseline"
- Majority voting: Selecting an action or label based on the most frequent choice among multiple samples. "by majority voting to choose the action"
- Non-identifiability: The ambiguity where multiple reward functions can explain the same observed behavior, leading to brittle generalization. "The central difficulty with such approaches is non-identifiability under limited data coverage"
- Notinline interventions: Corrections generated but not inserted into the ongoing context; saved or evaluated separately. "referred to as a 'notinline' intervention"
- Policy: The model or decision-making function being trained to select actions or generate outputs. "We use the notation π to refer to the student policy trained via our pipeline"
- Policy optimization protocol: A method for updating a policy’s parameters during reinforcement learning. "with CISPO \citep{chen2025minimax} as our policy optimization protocol."
- Posterior belief: The interpreted confidence from a probe’s readout regarding a concept’s validity in context. "interpret the output of the probe as a posterior belief, i.e., uncertainty"
- Preference learning: Learning a reward or scoring function from comparisons or preferences rather than explicit labels. "often framed as inverse RL or preference learning"
- Probing: Training simple readouts on model features to detect or quantify the presence of concepts. "Probing is done in two pipelines: Monitoring and Reward."
- Programmatic verifier: An automatic, deterministic checker of correctness (e.g., in code or math) used for cheap validation. "compared to a programmatic verifier"
- Reward hacking: Exploiting flaws in the reward specification to maximize the reward without achieving the intended behavior. "yielding brittle generalization and reward hacking"
- Reward model: A learned function (often an LLM) that predicts how a verifier would score an output. "and train a reward model (generally itself an LLM) that predicts what a verifier would say"
- Reward pipeline: The system of probes and evaluators that assigns rewards to interventions for RL training. "our reward pipeline also allows us to scale test time compute via BoN sampling"
- Reward probe: A probe whose output is used directly as a reward signal for reinforcement learning. "the relevant reward probe's score"
- Reward scaling: Adjusting reward magnitudes to balance learning across different objectives or actions. "This, along with reward scaling and segmented judges"
- Rollout: A generated sequence or trajectory produced by a policy during evaluation or training. "Since a rollout may involve several claims"
- Rubric-reward: A reward computed by applying a rubric (e.g., legibility, substantive-ness) via an LLM judge. "define a multiplicative rubric-reward"
- ScaleRL: An RL training framework used to run large-scale reinforcement learning experiments. "using ScaleRL ~\citep{khatri2025art}"
- Segmented judges: Using different judging modules or prompts for distinct aspects of evaluation to stabilize training. "This, along with reward scaling and segmented judges"
- Sparse, success-based reward: Occasional rewards given only upon successful outcomes, common in verifiable tasks. "which can act as a sparse, success-based reward to optimize against."
- Test-time compute: Additional computation or sampling performed during inference to improve output quality. "Furthermore, the pipeline enables scalable test-time compute"
- Verifiable domains: Tasks where correctness can be automatically and deterministically checked, such as code or math. "particularly in verifiable domains such as code generation and math"
- Well-calibrated: When predicted probabilities align with true frequencies, indicating reliable confidence estimates. "we ensure the probes are well-calibrated, meaning that a probe prediction of .XY corresponds closely to an XY\% chance of the positive class."
Practical Applications
Overview
This paper introduces RLFR (Reinforcement Learning from Feature Rewards), a practical framework that turns internal model features (read via probes) into reliable, low-cost reward functions for open-ended behaviors that are hard to verify (e.g., factuality/hallucination reduction). The authors demonstrate a 58% hallucination reduction on Gemma-3-12B-IT using feature-derived rewards and best-of-N sampling, at roughly two orders-of-magnitude lower train-time cost than an LLM-as-a-judge with web search. The method retains benchmark performance and supports scalable test-time compute via feature-guided ranking. Below are actionable applications that leverage these findings across industry, academia, policy, and daily life.
Immediate Applications
The following applications can be deployed with existing LLMs and tooling, using probe-based monitoring and reward-guided self-correction.
- Industry: Hallucination-monitoring and self-correction for enterprise assistants
- Use case: Customer support, internal knowledge assistants, and documentation generators that automatically retract or correct uncertain claims in longform outputs.
- Workflow: Integrate a localization+classification probe to detect claim spans; trigger an “intervention context” where the model chooses to maintain/retract/correct; inline accepted interventions back into the main response.
- Tools/Products: “FeatureGuard” middleware for LangChain/LlamaIndex; “CorrectionAgent” prompt component; per-claim audit logs.
- Assumptions/Dependencies: Access to model activations, well-calibrated probes in the target domain, initial labels from an LLM judge or human reviewers.
- Healthcare: Safer summarization and patient communication
- Use case: Clinical note summarization and patient Q&A systems that retract uncertain medical claims and suggest verification or clinician follow-up.
- Workflow: Probe-driven detection of medical assertions; cascade retraction/correction with confidence thresholds; inline interventions plus escalation if probe confidence is low.
- Tools/Products: EHR-integrated “Clinical Claim Gate,” audit trail of interventions for compliance.
- Assumptions/Dependencies: Domain-specific probe training and validation; human-in-the-loop for critical items; regulatory alignment (HIPAA, MDR).
- Education: Truth-aware tutoring systems
- Use case: Tutors that flag, retract, or correct unsupported statements, with citations or references.
- Workflow: Use probes to detect claims; select best-of-N self-corrections via reward probes; show student-friendly retraction or correction with sources.
- Tools/Products: “StudySafe” tutor module; classroom dashboards tracking intervention rates.
- Assumptions/Dependencies: Domain coverage (curricula, subject complexity); calibration across grade levels.
- Software: Feature-guided best-of-N output selection
- Use case: Code comments, design docs, API descriptions, and architectural summaries where selecting the most factual draft matters.
- Workflow: Generate N candidates; rank with feature-based reward probes (shown to outperform text-only LLM-as-judge ranking); return top candidate.
- Tools/Products: “BoN-Ranker” for CI/CD pipelines; IDE plugin to flag uncertain statements in generated docs.
- Assumptions/Dependencies: Compatibility with base model activations; stable probe transfer to post-trained policies.
- Finance: Compliance-aware analyst assistants
- Use case: Assistants that retract uncertain forecasts or claims in market summaries and risk reports, preserving auditability.
- Workflow: Probe detection of claim spans; correction attempts with sourcing; intervention logs for model governance.
- Tools/Products: “RegAudit Ledger” for intervention trails; feature-based monitors on disclosures.
- Assumptions/Dependencies: Domain-specific probes; supervisory review for material statements; integration with compliance workflows.
- Policy/Governance: Cost-effective model oversight and evaluation
- Use case: Procurement and governance teams benchmark models’ hallucination rates using probe-driven evaluation (Longfact++ style).
- Workflow: Run localization/classification probes and feature-based reward metrics in test suites; report precision/recall, intervention success, and BoN gains.
- Tools/Products: “ProbeEval” harness for vendor assessments; standardized dashboards for oversight.
- Assumptions/Dependencies: Acceptability of feature-level metrics; reproducible probe calibration; transparent logging.
- MLOps: Real-time monitoring and alerting for LLM deployments
- Use case: Operations teams track hallucination rates and intervention success in production; trigger alerts when uncertainty spikes.
- Workflow: Stream probes over live traffic; record entity counts, precision/recall, fixed/retracted ratios; route low-confidence cases to fallback judges or humans.
- Tools/Products: “LLM Ops Monitor,” “Intervention Router,” and per-tenant dashboards.
- Assumptions/Dependencies: Telemetry and privacy controls for activation-level monitoring; scalable inference pipelines.
- Retrieval/RAG: Probe-guided search activation
- Use case: Trigger retrieval or external search only when probes detect uncertain claims, cutting unnecessary tool calls.
- Workflow: Confidence thresholds from probes decide when to fetch sources; re-run correction in a retrieval-informed context; inline the corrected claim.
- Tools/Products: “Confidence-Gated RAG,” cost dashboards comparing tool use versus probe-driven gating.
- Assumptions/Dependencies: Reliable probe calibration; integration with search/RAG tools.
- Academia: Low-cost, feature-based evaluation suites
- Use case: Research groups benchmark hallucination reduction across models without expensive LLM judges.
- Workflow: Train lightweight probes on a labeled subset; reuse to score intervention success and BoN rankings at scale.
- Tools/Products: Open-source “RLFR-kit,” probe libraries for common architectures (Gemma/Llama/Mistral).
- Assumptions/Dependencies: Data labeling seed; probe training protocols and validation.
- Daily life: Safer personal assistants and browser extensions
- Use case: Assistants and extensions that retract/correct unsupported facts in recipes, travel tips, or health advice.
- Workflow: Localized claim detection; inline retractions with simple language; highlight confidence and encourage verification.
- Tools/Products: “TruthLens” browser addon; mobile assistant with visible “retract/correct” tags.
- Assumptions/Dependencies: Lightweight on-device probes or secure activation streaming; UX that maintains trust and clarity.
Long-Term Applications
These applications require further research, scaling, domain adaptation, standardization, or productization beyond the paper’s current scope.
- Cross-behavior RLFR: Sycophancy, agreeableness, toxicity, bias, and verbosity control
- Sector: Safety and alignment across all industries.
- Concept: Use calibrated features as rewards to penalize flattery/sycophancy, reduce harmful outputs, or control reasoning verbosity while preserving quality.
- Dependencies: Robust feature discovery and causal efficacy across behaviors; multi-objective reward design; avoidance of reward hacking.
- Cascaded oversight with formal guarantees
- Sector: Regulated domains (healthcare, finance, public sector).
- Concept: Hierarchical monitors where low-confidence probes escalate to expensive judges or humans; certify reliability thresholds.
- Dependencies: Standardized confidence metrics, auditability, and regulatory acceptance; cost-aware orchestration.
- Universal probe libraries and cross-model transfer
- Sector: Model vendors and platform providers.
- Concept: Portably trained probes that generalize across architectures and post-training regimes; “Probe-as-a-Service.”
- Dependencies: Shared representation stability; tooling to read activations safely; licensing and privacy compliance.
- Autonomous agents with self-monitoring and dynamic compute allocation
- Sector: Software agents, robotics, operations.
- Concept: Agents route tasks based on feature-calibrated uncertainty, allocating more samples or invoking tools when risk is high.
- Dependencies: Reliable uncertainty estimates, action-routing policies, energy/latency budgets.
- Retrieval augmentation guided by feature-level uncertainty
- Sector: Search and knowledge management.
- Concept: Probes trigger tailored retrieval with query expansion aligned to the uncertain entity span; reduce unnecessary retrieval calls.
- Dependencies: Span-level retrieval augmentation, domain ontologies, source quality controls.
- Education: Curriculum-aware factuality and citation scaffolding
- Sector: EdTech and institutions.
- Concept: Tutors adapt hints and explanations using feature-calibrated uncertainty; retract and correct with traceable citations.
- Dependencies: Domain-specific probe sets per subject; content sourcing; educator UX design.
- Healthcare: Probe-gated clinical decision support
- Sector: Hospitals, clinics, and payers.
- Concept: Models that gate suggestions with feature uncertainty; escalate to clinicians; record interventions for audit.
- Dependencies: Medical-grade validation, liability frameworks, integration with EHRs and clinical workflows.
- Finance: Risk dashboards and policy-compliant summaries
- Sector: Banking, asset management, insurance.
- Concept: Assistants minimize unsupported claims in earnings summaries; probe-based flags trigger compliance review.
- Dependencies: Domain adaptation, human review policies, storage of intervention ledgers for audits.
- Robotics: Safety-constrained language-conditioned control
- Sector: Industrial automation and consumer robots.
- Concept: Use features as rewards to encode safety constraints and risk awareness in language-guided control policies.
- Dependencies: Grounded tasks, causal links between features and control behavior, sim-to-real transfer.
- Energy: Reliability-critical operations assistants
- Sector: Power grids and utilities.
- Concept: Probe-gated assistants reduce false operational recommendations; escalate to engineers when uncertain spans arise.
- Dependencies: Domain-specific probes, integrated logging, regulatory compliance.
- Scientific research: Truth-aware literature assistants
- Sector: Academia and biotech/pharma R&D.
- Concept: Assistants retract/correct unsupported summaries; track intervention outcomes; aid reproducibility.
- Dependencies: Bibliographic integration, citation verification pipelines, domain calibration.
- Governance and standards: Feature-calibrated uncertainty reporting
- Sector: Public policy and standards bodies.
- Concept: Create reporting standards that require calibrated uncertainty signals and intervention logs for high-stakes deployments.
- Dependencies: Broad stakeholder buy-in, test suites, certification mechanisms.
Key Assumptions and Dependencies
- Probe calibration and causal relevance: The approach assumes model features encoding target concepts can be read reliably and are well-calibrated against ground truth.
- Labeling seed: Initial training of probes requires high-quality labels (LLM-as-judge with search or human annotations); quality of this seed affects generalization.
- Activation access: Implementations need safe, compliant access to model activations; vendor APIs or on-prem deployments must support this.
- Stability across post-training: Reward probes trained on base model activations are assumed to transfer to post-trained policies; large drifts may require re-tuning.
- Domain coverage: Probes trained on one domain (e.g., general longform) may need adaptation for specialized sectors (medical, legal, finance).
- UX and trust: Inline interventions must maintain clarity, legibility, and user trust; over-retraction or style changes should be monitored.
- Governance and privacy: Activation-level monitoring introduces logging and privacy considerations; organizations need policies and audit controls.
- Avoiding reward hacking: Multi-objective design and constraints (e.g., retraction/correction ratios, rubric checks) should be maintained to reduce Goodharting and evasion.
These applications leverage the paper’s core innovation—using features as scalable, calibrated rewards—to reduce hallucinations and unlock cost-effective oversight across open-ended tasks, while preserving model performance and enabling robust test-time compute.
Collections
Sign up for free to add this paper to one or more collections.