QuantaAlpha: An Evolutionary Framework for LLM-Driven Alpha Mining
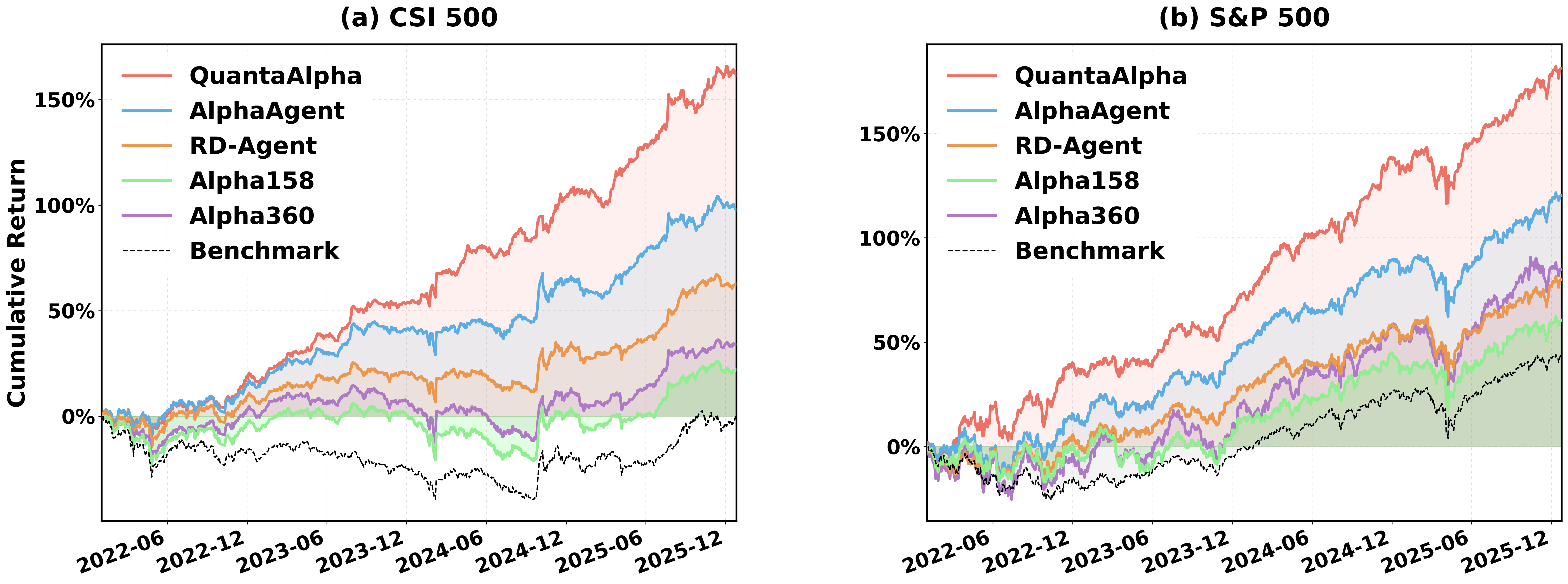
Abstract: Financial markets are noisy and non-stationary, making alpha mining highly sensitive to noise in backtesting results and sudden market regime shifts. While recent agentic frameworks improve alpha mining automation, they often lack controllable multi-round search and reliable reuse of validated experience. To address these challenges, we propose QuantaAlpha, an evolutionary alpha mining framework that treats each end-to-end mining run as a trajectory and improves factors through trajectory-level mutation and crossover operations. QuantaAlpha localizes suboptimal steps in each trajectory for targeted revision and recombines complementary high-reward segments to reuse effective patterns, enabling structured exploration and refinement across mining iterations. During factor generation, QuantaAlpha enforces semantic consistency across the hypothesis, factor expression, and executable code, while constraining the complexity and redundancy of the generated factor to mitigate crowding. Extensive experiments on the China Securities Index 300 (CSI 300) demonstrate consistent gains over strong baseline models and prior agentic systems. When utilizing GPT-5.2, QuantaAlpha achieves an Information Coefficient (IC) of 0.1501, with an Annualized Rate of Return (ARR) of 27.75% and a Maximum Drawdown (MDD) of 7.98%. Moreover, factors mined on CSI 300 transfer effectively to the China Securities Index 500 (CSI 500) and the Standard & Poor's 500 Index (S&P 500), delivering 160% and 137% cumulative excess return over four years, respectively, which indicates strong robustness of QuantaAlpha under market distribution shifts.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper is about teaching an AI system to discover good “signals” for picking stocks. In finance, these signals are called alpha factors: simple recipes that turn past market data (like price and volume) into a number that tries to predict which stocks will do better soon. The big challenge is that markets are noisy and always changing, so many signals that look good in tests don’t actually work later. The authors propose a new system, called QuantaAlpha, that uses ideas from evolution (like “mutating” and “combining” good ideas) to find stronger, more reliable signals.
What questions did the researchers ask?
They focused on four simple questions:
- Can we design an AI that improves stock-picking signals step by step, without getting confused by noisy test results?
- Can the AI reuse parts of past successes instead of reinventing everything every time?
- Can we keep the generated signals clear, simple, and not just copies of each other (to avoid “crowding,” where everyone uses the same idea)?
- Do the discovered signals work not just in one market, but also in other markets that behave differently?
How did they do it?
They built a multi-step, AI-driven workflow that treats each full attempt to discover a signal like a recorded journey, which they call a “trajectory.” Think of it like documenting every step in a recipe—from the idea to the final taste test—so you can later fix the exact step that went wrong or mix the best parts of two good recipes.
The idea of “trajectories”
A trajectory includes:
- A market idea (hypothesis) about why a pattern might predict returns.
- A precise, symbolic factor (a math-like expression built from a small set of allowed building blocks).
- Computer code that runs this factor on data.
- A backtest (a replay on past data) that scores how well it worked.
By saving this whole chain, the system can see exactly which step helped or hurt.
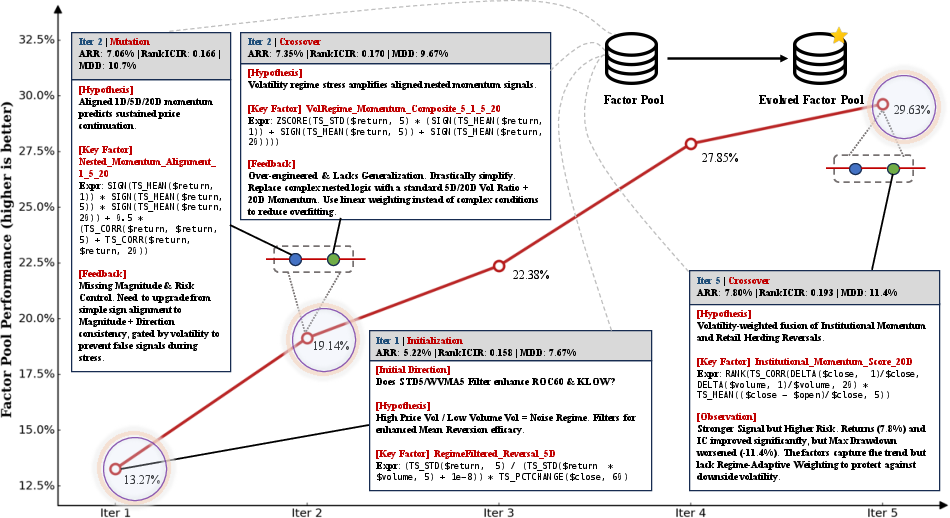
Evolution: mutation and crossover
They use two evolution-inspired operations:
- Mutation: If a trajectory didn’t work well, the AI pinpoints the weak step (like the hypothesis or a specific formula choice) and rewrites only that part. It keeps the rest the same. This is like fixing the one wrong instruction in a recipe instead of starting over.
- Crossover: If two different trajectories each have strong parts, the AI combines those strong parts into a new “child” trajectory. This is like merging the best crust from one pie with the best filling from another.
They also start with a diverse set of initial ideas so the system explores different styles (like momentum vs. mean reversion, short-term vs. long-term).
Keeping things consistent and simple
To avoid confusion and overfitting:
- The system checks that the hypothesis (idea), the symbolic formula, and the code all mean the same thing. This reduces mistakes where the code no longer matches the original idea.
- The system limits complexity (like keeping formulas from getting too long or too parameter-heavy).
- It avoids near-duplicates, so it doesn’t flood the pool with many versions of the same idea.
A helpful analogy: the factor is built from a library of “operators” (like LEGO blocks), and the “AST” is a blueprint showing how the blocks are connected. This makes it easier to validate, fix, and compile into working code.
How they tested it
They ran QuantaAlpha on the CSI 300 (a major Chinese stock index) and compared it to:
- Classic machine learning and deep learning models,
- Standard factor libraries,
- Other AI agent systems for factor discovery.
They measured:
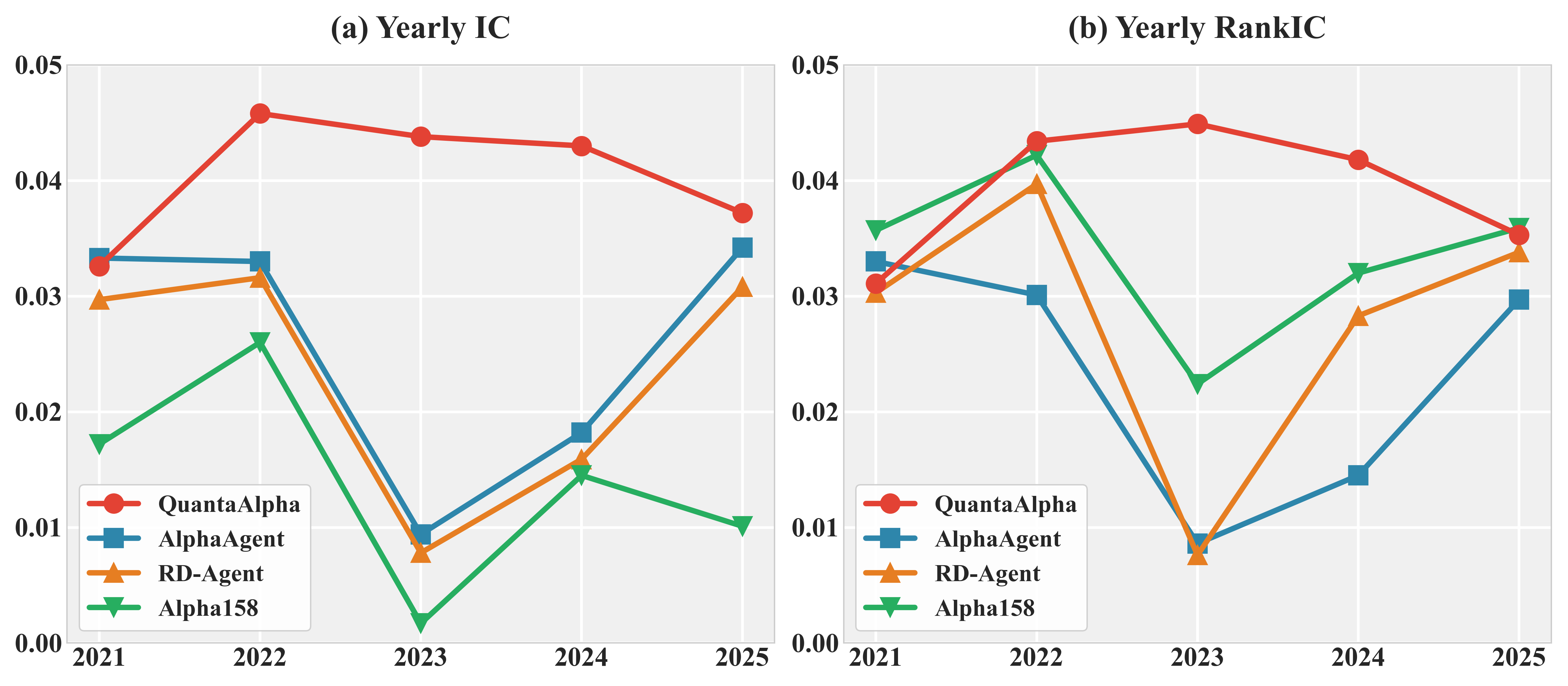
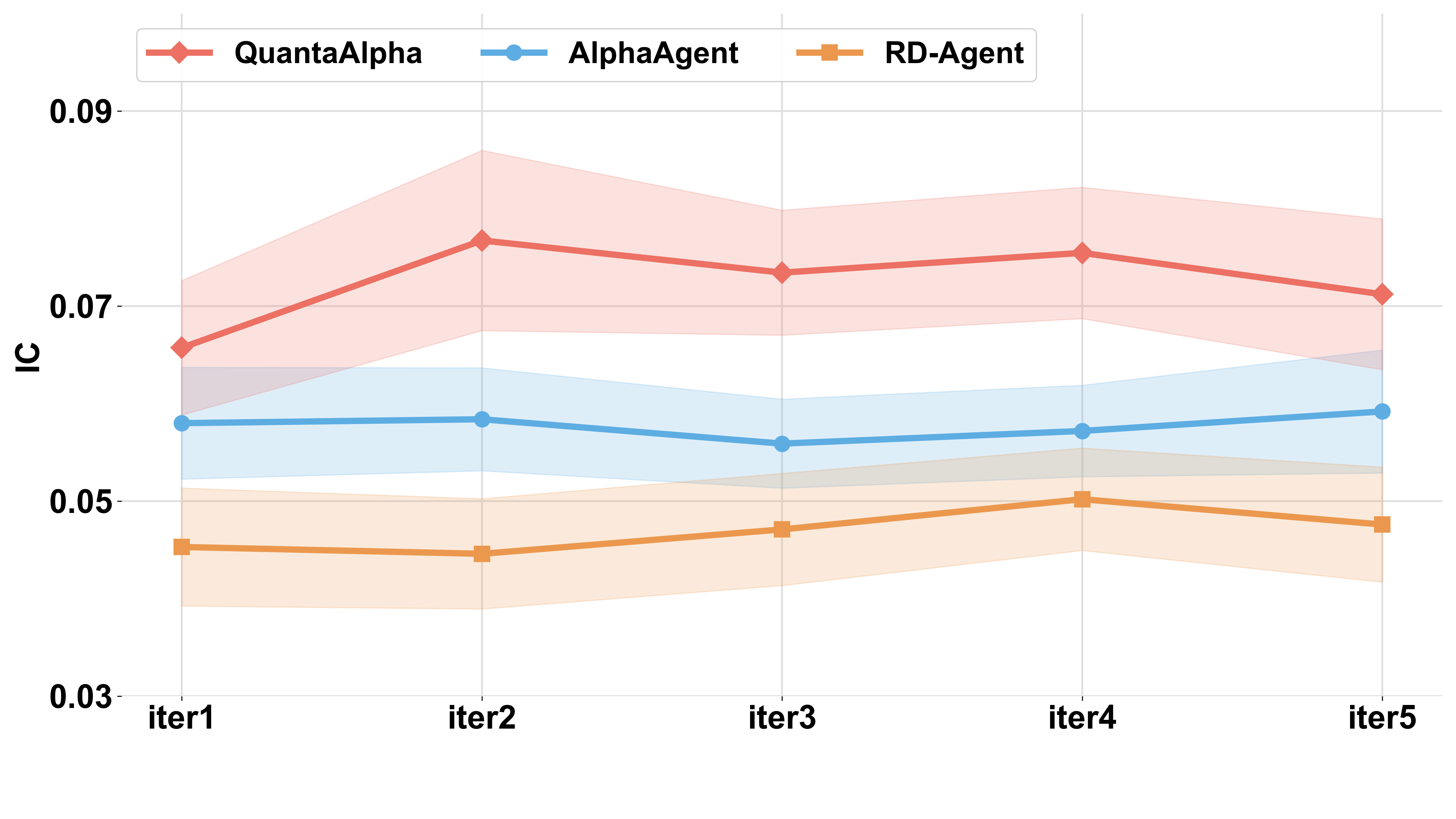
- Predictive power: Information Coefficient (IC) and Rank IC (both check how well the signal lines up with future returns; higher is better).
- Strategy performance: Annualized Return (ARR, how much you’d earn per year), Maximum Drawdown (MDD, the biggest drop from a peak; lower is better), and related ratios.
They also checked if signals learned on CSI 300 would still work on CSI 500 (China) and the S&P 500 (U.S.), with no extra tuning.
What did they find?
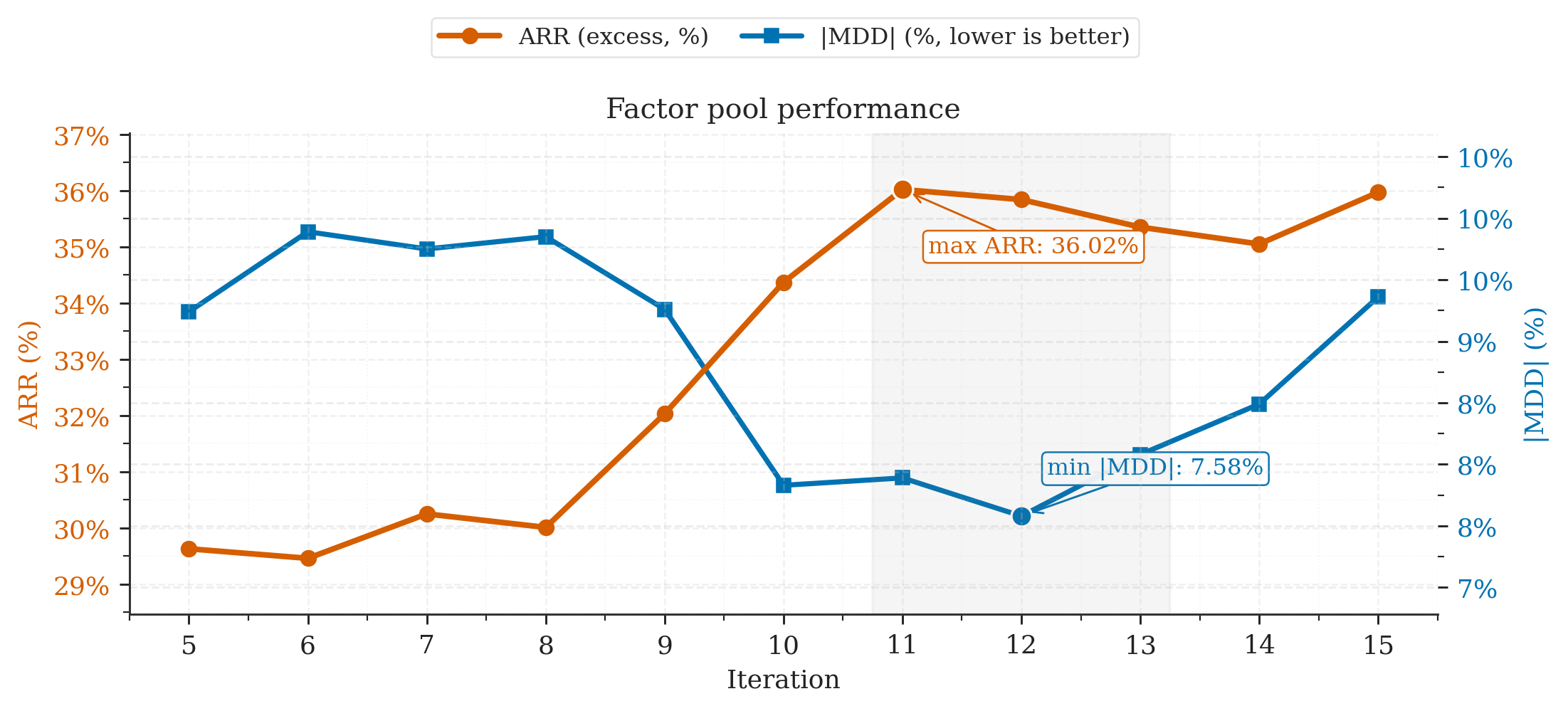
In their tests, QuantaAlpha beat the other methods on both prediction quality and investing performance:
- Using a strong base AI model, it reached an IC of about 0.150 (a high score for this task).
- It achieved around 27.8% annualized return with about 8% maximum drawdown on CSI 300 in their setup, which is both strong and relatively stable for a backtested strategy.
- Signals learned on CSI 300 transferred well to CSI 500 and the S&P 500, reaching roughly 160% and 137% cumulative extra return over four years in their tests. That suggests the signals weren’t just “fitted” to one market’s history.
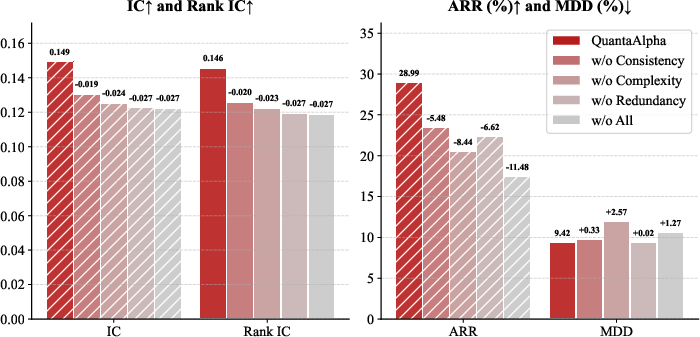
They also ran “ablation” checks (turning features off one by one) and found:
- Mutation (targeted fixes) made the biggest difference in finding better signals.
- Crossover (combining good parts) added steady, smaller gains.
- Starting with diverse ideas improved long-run stability.
- Consistency checks and limits on complexity/duplicates made the system more reliable and less likely to chase noise.
Another interesting result: when the market’s behavior changed (for example, in 2023 in China), many older-style signals weakened. QuantaAlpha still found patterns that held up, such as signals related to overnight price gaps and volatility structure—things that tend to persist across different market “moods.”
Why does it matter?
This work shows a practical way to make AI-driven finance research more:
- Robust: By evolving and fixing only the weak steps, the system avoids overreacting to noisy test results.
- Traceable: Saving full trajectories makes results easier to audit and trust.
- Diverse: Controls prevent overcrowding around the same idea, which can fail when too many people use it.
- Transferable: Signals that work across different markets are more likely to last in the real world.
In short, QuantaAlpha is a careful, step-by-step approach to discovering stock-picking signals that are simpler, clearer, and more likely to survive when markets change. If these results hold up outside of backtests, such methods could help build more stable, understandable investment strategies.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a single, consolidated list of unresolved issues and concrete open questions that future research could address to strengthen, validate, and extend the QuantaAlpha framework.
- Backtesting realism: Transaction costs, slippage, market impact, borrow/short constraints, turnover limits, and capacity/investability are not modeled; how do results change under realistic execution frictions and liquidity constraints?
- Portfolio construction details: The paper omits the portfolio formation/weighting scheme (e.g., long–short vs. long-only, leverage, rebalancing frequency, exposure caps); specify and stress-test the execution protocol driving ARR, IR, MDD, and CR.
- Multiple-testing risk and statistical significance: With large iterative search over many factors, apply formal multiple-comparison corrections (e.g., White’s Reality Check, SPA test, Deflated Sharpe) and report confidence intervals/p-values for IC/ARR to guard against data-snooping bias.
- Train/validation/test leakage: Evolutionary selection and crossover use “reward” from backtests—clarify whether only training/validation data inform evolution steps and ensure the test set is never used during search; implement strict nested CV to prevent look-ahead.
- Split consistency: Annual analyses include 2021 (validation) alongside 2022–2025 (test); re-run evaluations with a clean separation to ensure conclusions about generalization are not influenced by validation data.
- Factor combination procedure: The “final factor pool” is correlation-filtered, but the method to combine factors into a tradable strategy (weights, optimization objective, risk model) is unspecified; define and benchmark alternative combination schemes (equal-weight, risk-parity, mean–variance, convex optimization).
- Turnover and stability: Report turnover, holding periods, and decay rates for mined factors; quantify how complexity/redundancy constraints affect turnover and live-trading stability.
- Reward function specification: The utility term in R(τ) (L(f(X), y)) and regularization λ·R(f) are underspecified; detail metric choices, hyperparameters (e.g., λ, α1–α3), and sensitivity analyses to these choices.
- Consistency verifier reliability: The LLM-based semantic consistency checks lack empirical calibration; measure verifier precision/recall against human-annotated ground truth and quantify how misclassifications affect downstream performance.
- Mutation “failure localization”: The algorithmic criteria for identifying the failure-causing step k in a trajectory are not defined; formalize and evaluate different diagnostics (e.g., contribution analysis, counterfactual edits, Shapley-style credit assignment).
- Crossover mechanics: Segment selection, alignment, and coherence checks for recombined trajectories are described qualitatively; specify the segmentation algorithm, guardrails to avoid incoherent merges, and ablate selection pressure (elitism vs. diversity).
- AST similarity and scalability: Computing largest common isomorphic subtrees can be expensive; provide algorithmic details, complexity bounds, approximations, and runtime/memory benchmarks for large factor zoos.
- Operator library coverage: The standardized operator set O is not enumerated; document operators, feature spaces (daily vs. intraday, order-book/microstructure), event/corporate actions handling, and test whether extending O materially improves outcomes.
- Data specification and cleaning: Clarify data sources, survivorship-bias controls, corporate actions, delisting rules, missing data, outlier treatment, and alignment across markets (CSI vs. S&P); release data-prep pipelines for reproducibility.
- Risk exposure neutrality: Report exposures to common risk factors/styles (size, value, momentum, industry, beta) and whether signals add orthogonal alpha or load on known premia; include ex-ante/ex-post risk-neutralization tests.
- Generalization breadth: Cross-market transfer is shown for CSI 500 and S&P 500 only; extend to other geographies (Europe, EM), asset classes (futures, FX, rates), and different horizons (intraday) to probe limits of zero-shot transfer.
- Regime stress-tests: Evaluate robustness under extreme events (e.g., 2020 COVID crash, 2022 inflation shocks) and non-stationary volatility bursts; quantify resilience of mined factors and trajectory operators under stress.
- Reproducibility of LLM-dependent results: Results depend on specific, often proprietary LLMs (e.g., “GPT-5.2”); release prompts, agent scripts, seeds, and exact model versions; benchmark with fully open-source LLMs to ensure replicability.
- Compute/budget sensitivity: Report computational cost, iteration budgets, and wall-clock time; analyze performance vs. budget curves and trade-offs between breadth (planning) and depth (mutation/crossover).
- Fairness of baseline comparisons: Ensure identical data splits, execution settings, and cost models across RD-Agent, AlphaAgent, and QuantaAlpha; detail hyperparameter tuning budgets and iteration counts per method.
- Overfitting controls beyond constraints: Complexity/redundancy constraints are useful but may not suffice; test additional regularization (e.g., holdout gating, early stopping, Bayesian priors, penalty on trajectory edits) and measure impact.
- Strategy capacity and crowding: The paper frames “factor crowding” structurally via AST similarity; complement with market-level crowding metrics (overlap with popular signals, borrow/utilization, herding proxies) to assess live crowding risk.
- Execution venue/market-microstructure realism: Some signals rely on overnight/auction dynamics; verify applicability in markets without opening auctions or with different auction rules (e.g., US vs. CN) and adapt features accordingly.
- Robust live evaluation: Add forward-only paper-trading or shadow deployment to quantify live slippage from backtests; report stability of IC and IR in rolling out-of-sample windows with locked code/prompts.
- Governance and auditability: Trajectory lineage improves traceability, but auditing standards (versioning, decision rationales, compliance checks) are unspecified; define audit protocols for live deployment in regulated environments.
- Failure modes and negative results: Provide systematic catalog of common failure patterns (e.g., brittle gates, noisy path proxies) with quantitative frequencies and repair success rates to inform targeted method improvements.
Practical Applications
Immediate Applications
Below are practical use cases that can be deployed now, based on the paper’s methods (trajectory-level mutation/crossover, AST-based semantic consistency, complexity/redundancy controls) and findings (robust IC/ARR, cross-market transfer, mitigated crowding and drift).
- Finance — Quant research pipelines (buy-side/sell-side)
- Deploy QuantaAlpha as a “factor studio” to generate, audit, and curate alpha signals with trajectory-level mutation/crossover and AST-based verification; integrate into existing Python backtesting stacks (e.g., Zipline/Backtrader/custom), risk overlays, and portfolio construction modules.
- Outputs: factor libraries with lineage, redundancy-scanned pools, reproducible code artifacts; workflows to manage mutation rounds, crossover of high-reward segments, and gated compilation.
- Assumptions/Dependencies: clean, survivorship-bias-free data; realistic transaction cost/turnover modeling; access to capable LLMs; compute budget for iterative evolution; robust validation splits to avoid overfitting.
- Finance — Production trading and signal operations
- Use the factor pool for live long-short or long-only equity strategies with audit trails; emphasize regime-aware signals (e.g., overnight gap, volatility-structure, trend-quality) to reduce alpha decay under non-stationarity; enforce complexity/redundancy constraints to mitigate crowding risk.
- Tools: signal deployment playbooks, IC/Rank-IC monitoring dashboards, crowding scanner (AST similarity), lineage documentation for Investment Committees.
- Assumptions/Dependencies: execution infrastructure (smart-order routing, slippage models), real-time data quality, continuous monitoring for drift; compliance approval of LLM-assisted research.
- Finance — Cross-market scouting and transfer
- Zero-shot porting of vetted CSI 300 factors to CSI 500 and S&P 500 universes to rapidly identify robust signals; triage via transfer IC/ARR/MDD, then localize mutation at failure nodes to adapt mechanisms (e.g., scale, liquidity conditioning).
- Assumptions/Dependencies: comparable microstructure features and liquidity regimes; market-specific constraints (shorting, borrow costs); risk of transfer degradation if regimes diverge.
- FinTech/SaaS — LLM-driven quant research platform
- Offer a hosted “Alpha Mining Studio” (SaaS) that wraps AST compilation, semantic consistency checks, mutation/crossover orchestration, and redundancy controls; provide templates for factor families (momentum, mean-reversion, auction/overnight, range/volatility).
- Assumptions/Dependencies: customer data connectors, permissioning/security; cost management for LLM inference; clear SLAs on reproducibility and auditability.
- Data/Analytics vendors — Crowding and similarity services
- Provide a “factor similarity scanner” using AST subtree metrics to detect near-duplicates across client portfolios; deliver crowding reports and novelty scores to reduce systemic overlap.
- Assumptions/Dependencies: standardized operator libraries across clients; privacy-preserving structural comparison.
- Compliance/RegTech — Audit and governance tooling
- Use trajectory logs (hypothesis → symbolic → code → backtest) and lineage to support audit requirements; flag uncontrolled semantic drift or excessive complexity; maintain evidence of reproducible rationale.
- Assumptions/Dependencies: alignment with local regulatory expectations on AI-driven research; secure storage of prompts/outputs; human oversight policies.
- Academia — Reproducible factor research and teaching
- Adopt the framework in courses/labs to teach hypothesis-to-code alignment with ASTs, and controlled exploration via mutation/crossover; benchmark non-stationary robustness.
- Assumptions/Dependencies: open datasets and backtesting infrastructure; institutional policies for LLM usage.
- Advanced analytics (adjacent markets) — Commodities/FX/crypto
- Apply evolutionary factor mining to non-stationary assets (e.g., overnight information assimilation in futures; volatility-structure signals in crypto) using the same constraint gating and trajectory audit.
- Assumptions/Dependencies: domain-specific operator libraries (rolls, funding, basis); market microstructure differences; 24/7 trading quirks in crypto.
- Daily life — Retail quant toolkit
- Provide a lightweight version that compiles clean, auditable factors from public data with built-in complexity/redundancy limits, simple backtesting, and basic risk metrics (ARR, MDD, IR).
- Assumptions/Dependencies: education on model risk; limited data quality; small-account execution constraints (fees/slippage).
Long-Term Applications
These use cases require further research, scaling, or ecosystem development before widespread deployment.
- Finance — Fully autonomous research-to-execution agents
- Evolve from factor mining to closed-loop systems that co-optimize signals, models, portfolio construction, and execution under real-time regime detection; incorporate online mutation/crossover with adaptive risk budgets.
- Dependencies: reliable online learning under non-stationarity, robust drift detectors, execution feedback integration, strong safety rails for capital protection.
- Finance — Industry-wide AST/operator standards
- Establish common operator libraries and AST schemas for factor representation across institutions to streamline sharing, audit, and crowding measurement; enable inter-firm novelty and overlap metrics.
- Dependencies: standardization bodies, IP/licensing frameworks, interoperability with major quant platforms, privacy-preserving comparison protocols.
- Policy/Regulation — Systemic crowding monitoring
- Regulators and exchanges use structural similarity analytics (AST subtrees) to monitor market-wide factor crowding and procyclicality; stress-test alpha decay during regime shifts; set guidance on AI research traceability.
- Dependencies: access to anonymized structural features, legal mandates for reporting, robust aggregation methods that preserve confidentiality.
- Policy — AI governance for financial research agents
- Define best-practice guidelines for trajectory logging, semantic consistency verification, and mutation/crossover auditability to reduce black-box risk in AI-driven trading research.
- Dependencies: collaboration between regulators, industry consortia, and standards bodies; empirical evidence on risk mitigation.
- Cross-domain analytics — Non-stationary forecasting beyond finance
- Apply trajectory-level evolution and AST consistency to macroeconomic indicators, demand forecasting, and epidemiology/time-varying risk modeling; emphasize mutation-driven repair and crossover of validated model segments.
- Dependencies: domain-specific operator libraries (seasonality, interventions), robust evaluation protocols, data availability and quality.
- Software engineering/MLOps — Agentic pipeline synthesis
- Generalize the framework to synthesize and evolve data pipelines and ML workflows with intermediate ASTs, mutation at failure nodes, and crossover of high-performing subgraphs; improve reproducibility and auditability in AutoML.
- Dependencies: integration with CI/CD, cost-efficient LLMs, strong static/dynamic verification, domain-specific operator catalogs.
- Market microstructure R&D — Real-time regime-aware signals
- Build real-time detectors (auction shocks, liquidity re-rating, volatility clustering) that trigger adaptive factor sets and execution tactics; automate rollback/mutation when signals degrade.
- Dependencies: low-latency data, robust microstructure feature engineering, live evaluation safeguards.
- Education/Workforce — Hands-on AI quant apprenticeships
- Use the framework to train analysts on principled, auditable AI-assisted research, emphasizing semantic alignment, constraint gating, and evolutionary improvements; develop certification pathways.
- Dependencies: institutional buy-in, curricula, sandboxed environments with safe capital exposure.
- Risk management — Portfolio-level crowding and drift control
- Integrate structural redundancy metrics into portfolio construction to cap exposure to crowded factor archetypes; automate diversification across information channels (overnight, volatility-structure, trend-quality).
- Dependencies: cross-portfolio structural analytics, governance rules, coordination between PMs and risk teams.
- Multi-asset/global expansion — Cross-venue transfer learning
- Scale zero-shot factor transfer with automated market-specific mutation (fees, shorting, auction rules) across equities, futures, FX, and options; standardize adaptation workflows.
- Dependencies: heterogeneous microstructure modeling, cost-aware execution planners, global compliance constraints.
Glossary
- Abstract Syntax Tree (AST): A tree-structured intermediate representation that makes factor composition explicit and compilable. "an Abstract Syntax Tree (AST)"
- Agentic systems: Multi-agent LLM frameworks that autonomously execute research workflows. "agentic systems"
- Alpha decay: The deterioration of a factor’s predictive power over time, often due to crowding or regime changes. "alpha decay observed in 2023"
- Alpha factor: A quantitative signal intended to predict future cross-sectional returns. "alpha factor "
- Alpha mining: The process of discovering, constructing, and validating predictive financial factors from market data. "alpha mining highly sensitive to noise in backtesting results"
- Alpha zoo: A repository of existing factors used to check redundancy or similarity. "alpha zoo "
- Annualized Rate of Return (ARR): The annualized performance of a strategy, expressed as a percentage. "Annualized Rate of Return (ARR)"
- Backtesting: Evaluating a factor or strategy using historical data to assess performance. "backtesting-based evaluation"
- Calmar Ratio (CR): A performance metric equal to annualized return divided by maximum drawdown. "Calmar Ratio (CR)"
- Cross-sectional dependence: Statistical dependence among assets at the same time point, affecting factor tests. "cross-sectional dependence"
- Crossover: An evolutionary operator that recombines high-performing trajectory segments to create new solutions. "Crossover recombines complementary segments"
- Diversified Planning Initialization: A procedure that generates complementary hypotheses to widen the initial search space. "Diversified Planning Initialization"
- Factor crowding: Many strategies using similar signals, which reduces distinctiveness and erodes performance. "factor crowding"
- Heavy tails: Distribution property where extreme events occur more frequently than under a normal distribution. "heavy tails"
- IC Information Ratio (ICIR): The stability-adjusted measure of IC, typically mean IC divided by its volatility. "IC Information Ratio (ICIR)"
- Information Coefficient (IC): The cross-sectional correlation between factor scores and next-period returns. "Information Coefficient (IC)"
- Information Ratio (IR): A risk-adjusted return metric, often mean excess return divided by its standard deviation. "Information Ratio (IR)"
- Market microstructure: The mechanics of trading, liquidity, and price formation at short horizons. "market microstructure"
- Maximum Drawdown (MDD): The largest peak-to-trough loss experienced by a strategy over a period. "Maximum Drawdown (MDD)"
- Mean reversion: The tendency of prices to revert toward an average level after deviations. "mean-reversion"
- Mutation: An evolutionary operator that makes targeted, localized revisions to a trajectory to improve outcomes. "Mutation performs targeted revision"
- Non-stationarity: Time-varying statistical properties in data that challenge model stability and transferability. "non-stationarity"
- Operator library: A standardized set of composable primitives used to build symbolic factor expressions. "operator library "
- Parsimony: Preference for simpler factor expressions to improve robustness and interpretability. "promote parsimony and novelty."
- Rank IC: The Spearman correlation between factor ranks and next-period returns, measuring ordinal predictive power. "Rank IC"
- Rank ICIR: The information ratio computed on Rank IC to assess its consistency over time. "Rank ICIR"
- Regime shift: An abrupt change in market behavior that can invalidate previously effective signals. "market regime shifts"
- Semantic consistency: Alignment among hypothesis, symbolic expression, and code to prevent meaning shifts. "semantic consistency"
- Semantic drift: Unintended shift in meaning during iterative generation or refinement. "semantic drift"
- Signal-to-noise ratio: The relative strength of a predictive signal compared to background noise. "low signal-to-noise ratios"
- Subtree isomorphism: Structural equivalence between subtrees, used to measure factor redundancy via AST matching. "subtree isomorphism"
- True range: A range-based volatility measure used in several technical signals. "true range"
- Volatility clustering: The phenomenon where periods of high (or low) volatility tend to persist. "volatility clustering"
- Zero-shot transfer: Deploying mined factors to new markets without re-optimization. "zero-shot transfer experiment"
Collections
Sign up for free to add this paper to one or more collections.

