On the geometry and topology of representations: the manifolds of modular addition
Abstract: The Clock and Pizza interpretations, associated with architectures differing in either uniform or learnable attention, were introduced to argue that different architectural designs can yield distinct circuits for modular addition. In this work, we show that this is not the case, and that both uniform attention and trainable attention architectures implement the same algorithm via topologically and geometrically equivalent representations. Our methodology goes beyond the interpretation of individual neurons and weights. Instead, we identify all of the neurons corresponding to each learned representation and then study the collective group of neurons as one entity. This method reveals that each learned representation is a manifold that we can study utilizing tools from topology. Based on this insight, we can statistically analyze the learned representations across hundreds of circuits to demonstrate the similarity between learned modular addition circuits that arise naturally from common deep learning paradigms.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how neural networks “think” when they learn a simple math rule called modular addition (like adding hours on a clock). Earlier work said there were two totally different ways networks solved it: the “Clock” way and the “Pizza” way. This paper shows that, underneath the surface, those two ways are actually the same kind of solution. The networks build very similar shapes in their internal representations, so the supposed differences are mostly about appearance, not the core idea.
What questions did the authors ask?
- Do different neural network designs truly learn different internal “circuits” for modular addition, or are they secretly doing the same thing in different outfits?
- Can we describe what the network learns as a simple geometric shape (a “manifold”), and compare networks by comparing these shapes?
- Can tools from topology (the math of shapes and holes) help us test this at scale?
How did they study this?
To keep the ideas friendly, think of the network’s internal activity as drawing points in space. Different inputs land at different places, and together they form a shape. The authors:
- Trained several small models on modular addition (like adding two numbers but wrapping around a fixed number n, e.g., 59, just like a 59-hour clock).
- MLP-Add: adds the two input embeddings directly.
- MLP-Concat: sticks the two input embeddings side by side.
- Attention 0.0 (“Pizza”): transformer with fixed, uniform attention.
- Attention 1.0 (“Clock”): transformer with learnable attention.
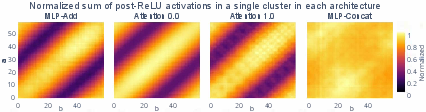
- Looked at groups of neurons together instead of one neuron at a time. They grouped neurons that “vibrate” with the same rhythm (frequency), because many neurons behave like smooth waves on a circle: cos(…) and sin(…).
- Turned each group’s responses into a cloud of points and studied the cloud’s shape.
- PCA: a way to squish high-dimensional points down to 2D or 4D so we can see the shape.
- Topology (Betti numbers): counts holes in shapes (no holes = disc, 1 loop = circle, donut = torus).
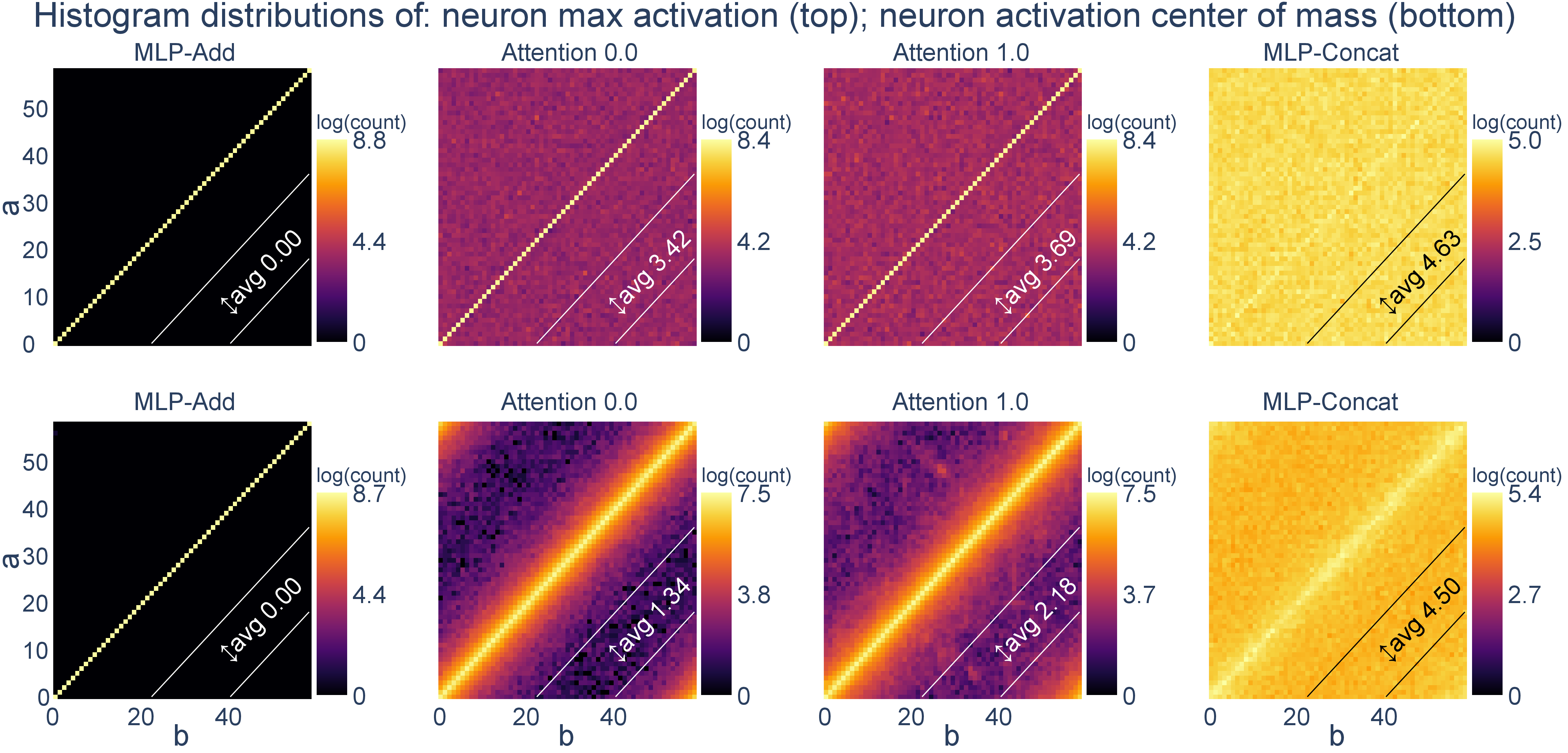
- Phase Alignment Distribution (PAD): checks where each neuron lights up the most across inputs; if neurons often peak when a = b, it means the two inputs are aligned in phase (their angles match).
- MMD: a statistical test to compare PADs between models.
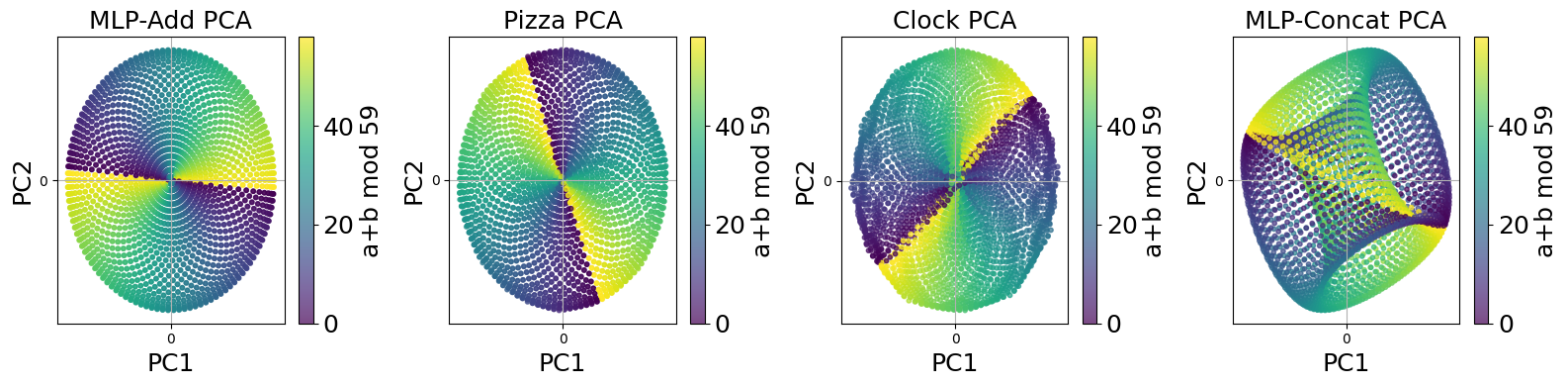
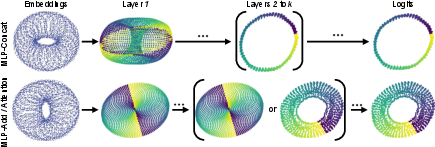
They also proved a key math result: if the waves for the two inputs are aligned (their phases match), the first hidden layer forms a 2D disc (the “pizza” shape). If the waves for the two inputs act independently, the first hidden layer forms a 4D donut (a torus). Importantly, the disc is just a simple projection (flattening) of the torus—so they’re two views of the same family of solutions.
Main findings and why they matter
- The “Clock” and “Pizza” models learn the same kind of internal shape.
- In practice, both Attention 0.0 (Pizza) and Attention 1.0 (Clock) show almost identical first-layer geometry: a 2D disc. Their PADs and statistical distances (MMD) are extremely close.
- MLP-Add looks the same as both attention models in that first layer.
- MLP-Concat looks different at first—but it’s just a more complete version of the same idea.
- Its first layer forms a torus (a donut shape), which naturally contains the needed structure. The other models form a disc, which is just the torus seen through a linear projection (a flattening).
- Across layers, all models move toward the same final answer shape.
- As you go deeper, the internal shapes transform into something that looks like a circle or a thin ring where the correct outputs live (the “logits” stage).
- The “Clock vs. Pizza” split isn’t a true divide.
- What looked like two different circuits turns out to be one underlying method: build a low-dimensional shape (disc or torus) that makes modular addition easy to read off. The disc is a simple projection of the torus.
Why this matters: It supports the “universality” idea—different networks trained on the same task tend to learn similar internal solutions. That’s good news for interpretability: it means we can find common patterns rather than a jumble of unrelated tricks.
Implications and impact
- Big picture: Different architectures converge to the same geometric idea—learn a simple, low-dimensional manifold (shape) that encodes modular addition. Sometimes it’s a torus; sometimes a disc that’s just a torus viewed through a linear lens.
- For interpretability: Studying groups of neurons as shapes, and using topology (holes and loops) plus statistics (PAD, MMD), is a powerful, scalable way to compare what models learn.
- For the “universality” hypothesis: This work removes a claimed counterexample. It suggests that, at least for modular addition, networks do share a common internal structure.
- Limitation: The paper focuses on modular addition, a clean and controlled task. Future work needs to test whether these manifold-based insights extend to more complex, real-world problems.
In short: What looked like two different stories—Clock and Pizza—is basically one story told with different camera angles. The networks learn the same kind of shape to solve the problem, which is encouraging for building general understanding of how neural networks represent and compute.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored, phrased to be actionable for future work:
- Formalize partial phase correlation: Theorem 1 covers perfect correlation (disc) and independence (torus) but not intermediate correlations. Characterize the manifold rank/topology and resulting factorization for arbitrary correlation structures between and , including finite-sample effects when (neurons per frequency) is small.
- Later-layer theory: The analysis and guarantees are for first-layer preactivations. Provide a rigorous theory for how torus/disc manifolds evolve through nonlinearities and linear maps across layers, and prove conditions under which circles/annuli at the logits must emerge.
- Beyond shared single embedding: The results assume a single learnable embedding matrix shared across a and b. Test and theoretically analyze cases with untied embeddings, fixed sinusoidal/one-hot embeddings, separate positional encodings, or multiple embedding tables.
- Architectural breadth: Validate and extend to deeper transformers with multiple attention heads, residual connections, layer norm, and MLP blocks; assess whether torus/disc universality persists in full-stack models beyond one-layer attention.
- Conditions for “Clock” emergence: The paper argues Clock manifolds are implausible under its assumptions but does not specify conditions under which they could arise. Construct architectures/training regimes (e.g., bilinear layers, multiplicative interactions, gated attention, or symmetry-breaking embeddings) to test whether Clock-like representations can be induced and sustained.
- Role of optimization and regularization: Quantify sensitivity of learned manifolds to optimizer choice, learning rate schedule, weight decay, dropout, batch size, and early stopping; report when phase alignment distributions (PADs) or Betti distributions change qualitatively.
- Generalization across moduli: Experiments focus on n=59. Systematically vary n (prime vs composite, large vs small), and report whether manifold types, phase correlations, and frequency usage change with group structure (e.g., CRT structure for composite n).
- Multi-frequency interactions: The theory treats a single frequency cluster at a time. Analyze how multiple frequencies interact in later layers, whether cross-frequency mixing alters topology/geometry, and whether combined representations deviate from simple torus/disc models.
- Quantifying manifold “efficiency”: The paper states MLP-Concat is “more efficient” but does not formalize efficiency. Define and measure feature/parameter/sample efficiency (e.g., rank, mutual information, accuracy vs width/depth) to compare torus vs disc projections.
- PAD estimation robustness: The PAD relies on maximum-activation or center-of-mass estimators for phases. Assess estimator bias/variance, confidence intervals, and sensitivity to activation noise, non-Gaussianity, and neuron sparsity; benchmark alternative estimators (e.g., sinusoid regression with regularization).
- Statistical testing details for PAD: Specify kernel choices, bandwidth selection, and multiple-comparison controls in MMD; provide power analyses and confidence intervals to calibrate “closeness” claims across architectures.
- Cluster identification reliability: Frequency clustering depends on 2D DFT of neuron preactivations. Quantify mis-clustering risk due to frequency leakage, mixed-frequency neurons, windowing artifacts, or harmonics; propose robust clustering (e.g., model selection with sparse Fourier fits).
- TDA pipeline sensitivity: Persistent homology is sensitive to scaling, metric choice, and filtration parameters. Report stability analyses (e.g., bottleneck/Wasserstein distances), diagram confidence bands, and ablations on preprocessing (raw vs PCA, normalization) to ensure topological claims are not artifacts.
- Discs at logits as TDA artifacts: The paper notes that some “discs” at logits may be PH limitations. Provide a principled procedure to distinguish genuine vs spurious holes (e.g., persistence thresholds, bootstrapping) and quantify false positive/negative rates.
- Training dynamics and grokking: The work studies end-state representations. Track topology/geometry and PADs during training (including grokking phases) to understand when and how phase alignment and manifold type stabilize.
- Symmetry assumptions vs practice: The theory relies on commutativity-induced symmetry (identical distributions of and ). Empirically test symmetry breaking from data order, tokenization, parameter initialization, or model asymmetries (e.g., asymmetric embeddings or attention) and measure its impact on manifolds.
- Universality scope: The paper “restores possibility” of universality in modular addition. Extend tests to other groups (dihedral, symmetric), other algorithmic tasks (sorting, parity, carry lookahead), and naturalistic tasks to probe whether torus/disc universality is a special case or a broader phenomenon.
- Logit annulus claims: The circle/annulus structure at logits is argued qualitatively. Provide closed-form derivations and quantitative fits for the logit manifold (e.g., radii, thickness, angular uniformity) and test across architectures and depths.
- Effect of width and depth: Systematically vary layer widths, depths, and number of neurons per frequency. Determine thresholds for reliably realizing torus vs disc and how finite-rank constraints distort intended manifolds.
- Role of nonlinearity: The analysis assumes simple cosine preactivations but does not characterize how ReLU (or other activations) shape manifold geometry beyond layer 1. Analyze theoretically and empirically the impact of activation choice on topology and the torus-to-circle map.
- Data noise and distribution shifts: Assess robustness of learned manifolds and PADs under label noise, input corruption, sub-sampling (non-exhaustive training sets), or distribution shifts; test whether topology degrades gracefully or undergoes phase transitions.
- Inference-level interpretability transfer: The approach is specialized to modular addition. Design a general methodology to extract “phase-like” latent variables and PAD analogs in non-group tasks so the manifold-based interpretability strategy can transfer.
- Sample independence in PAD: PADs aggregate across neurons and seeds; neurons within a model are not IID and clusters with more neurons are over-represented. Correct for intra-model dependence and cluster-size bias (e.g., hierarchical resampling) and re-evaluate PAD distances.
- Exact conditions on phase support: Theorem 1 assumes positive Lebesgue-measure support for phase distributions. Provide empirical tests and confidence intervals for phase support properties in trained models; explore what happens when support is discrete or concentrated.
- Benchmarking against Clock-inducing baselines: Construct targeted baselines designed to favor multiplicative/second-order interactions (e.g., bilinear layers, attention with quadratic terms) and verify whether Clock-like manifolds can be induced; if not, clarify why optimization avoids them.
- Scaling to large models: Validate whether the torus/disc picture persists in larger transformers with realistic token embeddings, context windows, and tasks (including modular addition as an in-context subtask) to test real-world relevance.
- Reproducibility package: Provide code/data for PAD/TDA pipelines with deterministic seeds, parameter sweeps, and reporting standards (e.g., kernel, filtration) to allow independent auditing of topological conclusions.
Glossary
- Algebraic topology: A branch of mathematics that studies properties of spaces via algebraic invariants, used here to analyze learned representations. "We use Betti numbers from algebraic topology to distinguish the structure of different stages of circuits across layers."
- Annulus: A ring-shaped manifold; in this paper, the shape formed by logits in representation space. "before ultimately arriving at a logit annulus."
- Betti numbers: Integers that count topological features (holes) of different dimensions in a space. "The -th Betti number counts dimensional holes: counts connected components, counts loops, counts voids enclosed by surfaces."
- Chinese Remainder Theorem: A number-theoretic result enabling reconstruction from residues; referenced as an algorithmic target approximated by networks. "approximates the Chinese Remainder Theorem and matches its logarithmic feature efficiency."
- Cyclic group: A group consisting of modular arithmetic classes under addition; the task studied is addition in a cyclic group. "The learning task we are interested in is the operation of the cyclic group, modular addition for ."
- Dihedral multiplication: Group operation in the dihedral group (symmetries of a polygon); used as a testbed for interpretability. "and dihedral multiplication \cite{mccracken2025representations}--researchers have uncovered mechanisms that speak to core hypotheses about representations"
- Discrete Fourier Transform (DFT): A transform that decomposes discrete signals into frequencies; used to identify neuron frequency clusters. "A 2D Discrete Fourier Transform (DFT) of the matrix gives the key frequency for the neuron."
- Grokking: A learning phenomenon where models suddenly generalize after overfitting on small algorithmic datasets. "describe their internal computations to illuminate the grokking phenomenon \citep{power2022grokkinggeneralizationoverfittingsmall}"
- Lebesgue measure: The standard notion of volume in Euclidean spaces; used to formalize the support of phase distributions. "and that the support of $\phasedist{a}{b}$ has positive (Lebesgue) measure."
- Logits: The unnormalized output scores of a model prior to a softmax or similar normalization. "Later layers can construct a circle, and the logits approximate a circle."
- Manifold hypothesis: The idea that data (or learned representations) lie near low-dimensional manifolds in high-dimensional spaces. "the manifold hypothesis \citep{bengio2013representation, goodfellow2016deep}, suggests that representation learning consists of finding a lower-dimensional manifold for the data."
- Mapper: A TDA tool that builds a simplified graph of data topology via cover and clustering. "surveyed TDA tools such as persistent homology and Mapper for analyzing architectures, decision boundaries, representations, and training dynamics."
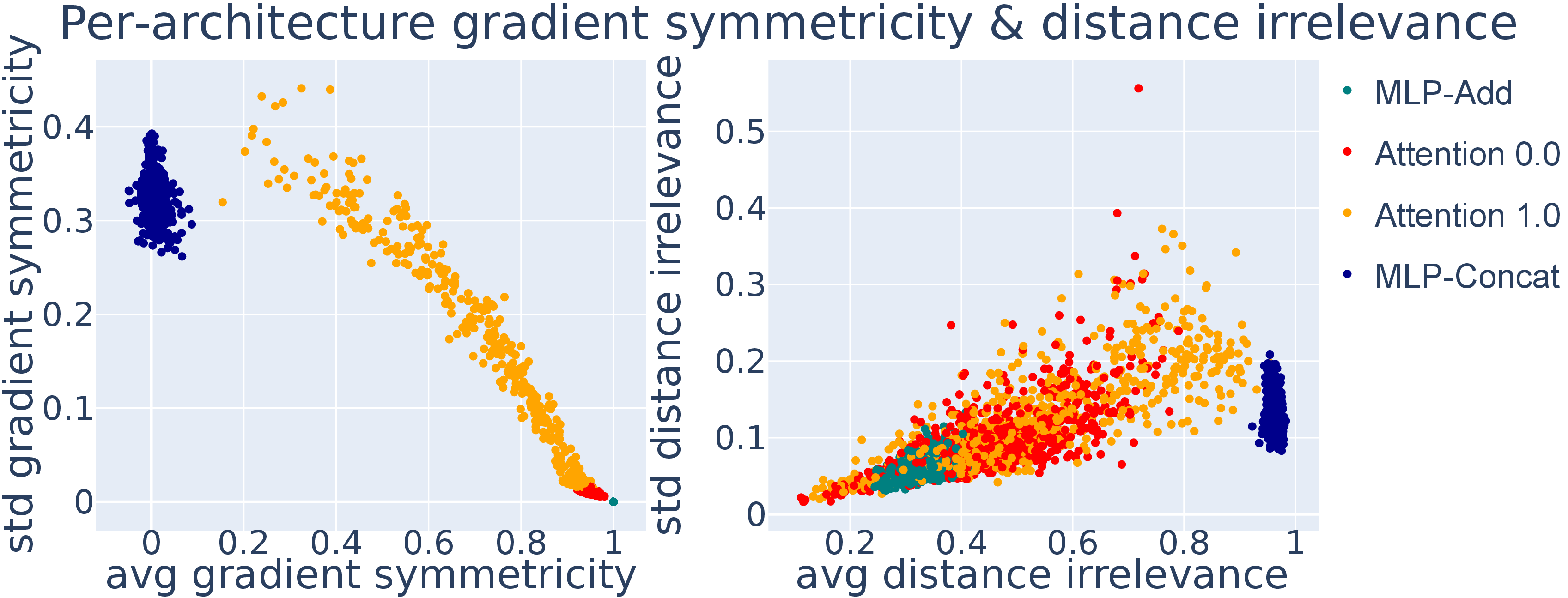
- Maximum mean discrepancy (MMD): A kernel-based statistical distance used to compare probability distributions. "distributional methods such as maximum mean discrepancy (MMD) \cite{gretton2012kernel} are rarely used in mechanistic interpretability"
- Mechanistic interpretability: An approach that reverse-engineers internal structures and circuits of neural networks to explain their computations. "research in mechanistic interpretability has focused on identifying sub-structures of these models---referred to as circuits---and understanding the function and formation of these circuits"
- Persistent homology: A TDA method that tracks topological features across scales in a filtration. "We compute these using persistent homology with the Ripser library \citep{Bauer2021Ripser, de_Silva_2011, ctralie2018ripser}."
- Phase Alignment Distribution (PAD): A proposed distribution over input pairs indicating where neuron activations peak, characterizing phase alignment in representations. "Thus, we propose yet another representation: the Phase Alignment Distribution\, (PAD)."
- Preactivation: The value computed by a neuron before applying its nonlinearity (e.g., ReLU), often a linear transformation of inputs. "with the value in entry corresponding to the preactivation value on datum ."
- Principal component analysis (PCA): A linear dimensionality reduction technique projecting data onto directions of maximal variance. "Principal component analysis (PCA)."
- Ripser: A software library for fast computation of persistent homology. "with the Ripser library \citep{Bauer2021Ripser, de_Silva_2011, ctralie2018ripser}."
- Simple neuron: A neuron modeled as a sum of sinusoidal responses in each input, parameterized by frequency and phase shifts. "a simple neuron is a neuron that has pre-activation"
- Torus: A doughnut-shaped manifold; here, a product of circles () arising in representation geometry. "MLP-Concat should concatenate two points on a circle, giving the torus ."
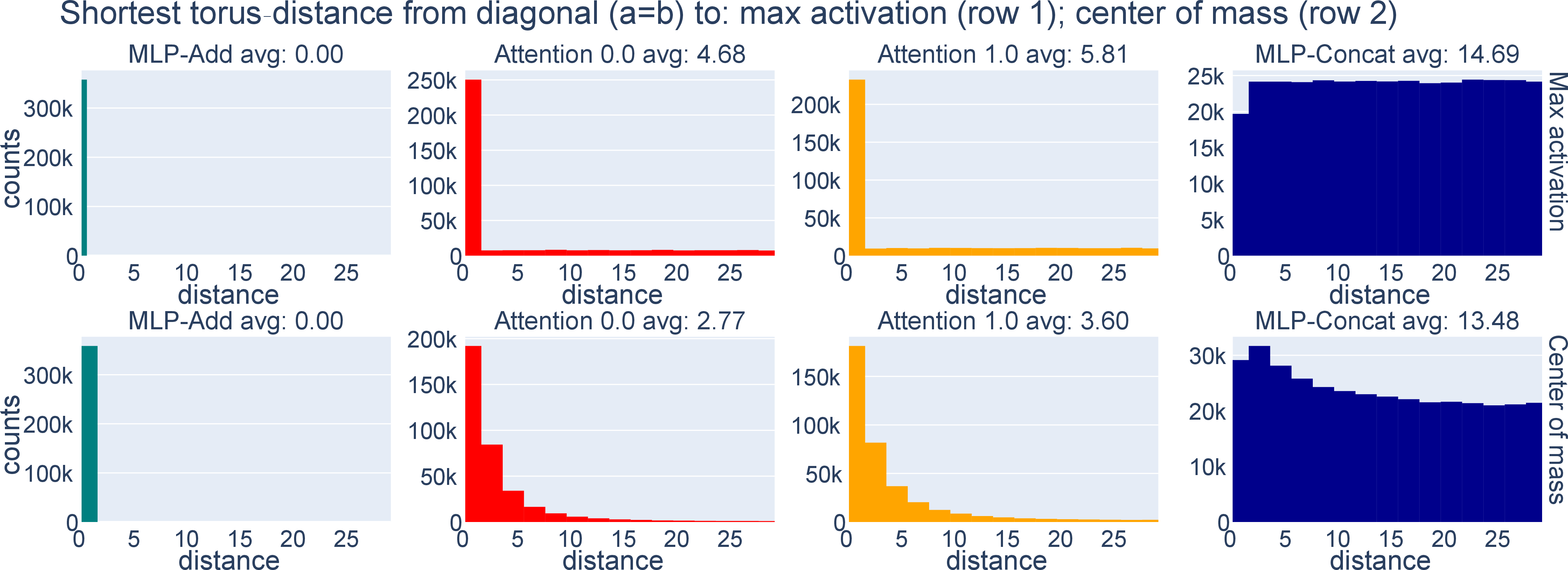
- Torus distance: A discrete graph distance from a point on the torus to the diagonal representing , used to quantify activation alignment. "we propose the torus distance, which is the discrete graph distance from a point on the torus to the line."
- Topological data analysis (TDA): A field applying topology to analyze the shape and connectivity of data. "Topological data analysis (TDA) offers a complementary view:"
- Vector addition disc: The 2D manifold obtained by adding two unit-circle embeddings; colloquially the “pizza” representation. "MLP-Add should add two points on a circle, giving the vector addition disc (Figure~\ref{fig:wrapped})"
Practical Applications
Practical Applications Overview
Below is a grouped list of actionable applications that follow directly from the paper’s findings and methods—especially the manifold-based perspective on learned representations, Phase Alignment Distributions (PAD), and topological data analysis (Betti numbers) for comparing circuits across architectures. Each item notes sector links, potential tools/workflows, and key assumptions affecting feasibility.
Immediate Applications
- Model diagnostics and regression testing in ML engineering (software, finance, healthcare)
- What to do: Add a “representation health” stage to training pipelines that computes PADs, neuron-cluster PCA, Betti numbers, MMD distances, and torus-distance metrics to monitor whether a model’s internal circuitry remains stable across seeds, architectures, and versions.
- Workflow:
- Cluster neurons by frequency via 2D DFT on preactivation matrices.
- Compute PADs (max activation or activation center-of-mass estimators).
- Run PCA of neuron-cluster preactivations; compute Betti numbers via Ripser; compare PADs via MMD.
- Issue alerts when PAD/MMD/Betti signatures diverge from a trusted baseline.
- Tools: Ripser, MMD estimators, standard PCA/DFT code; integrate into MLflow/Weights & Biases dashboards.
- Assumptions/dependencies: Access to internal activations/weights; first-layer “simple neuron” model holds; compute budget for TDA; noise handling in homology (small holes can be missed).
- Equivalence testing across architectures (software platforms, AI product teams)
- What to do: Use PAD/MMD and Betti profiles to certify that models trained with uniform vs. learnable attention (or MLP variants) implement geometrically/topologically equivalent circuits for a given task.
- Outcome: Faster architecture decisions and safer refactors by proving representational equivalence without relying on neuron-by-neuron alignment.
- Assumptions: The task exhibits sinusoidal embeddings or similar periodic structure; single shared embedding matrix; simple neuron approximation holds.
- Training monitoring and early detection of “grokking-like” transitions (education, software/ML ops)
- What to do: Track manifold transitions (e.g., torus → disc → circle/logit annulus) layer-by-layer during training to identify when useful structure emerges.
- Tools/workflow: Periodic PAD snapshots and Betti number histograms by layer; lightweight PCA embeds for quick visual diagnostics.
- Assumptions: Availability of intermediate layer activations; stable mapping from phases to manifold signatures.
- Manifold-guided pruning and low-rank compression (edge AI, mobile, software)
- What to do: Exploit rank observations (disc ~ rank-2; torus ~ rank-4) to prune redundant neurons per frequency cluster or compress representations via explicit torus-to-disc projections before downstream layers.
- Products/workflows:
- “Manifold-guided pruning” toolkit that removes neurons contributing minimally to cluster PCA components.
- Frequency-cluster aware distillation (teacher manifold → student projection).
- Assumptions: Compression preserves accuracy; verification via PAD/MMD/Betti regression tests; modular addition is a toy case—confirm on task-specific data.
- Audit and internal compliance reporting (healthcare, finance, safety-critical AI)
- What to do: Add “Betti cards” and “PAD scores” to model cards, documenting representation topology and PAD similarity to vetted baselines; use MMD to quantify deviations.
- Benefit: Transparent evidence of representational stability across releases.
- Assumptions: Buy-in from governance teams; standardization of metrics and thresholds.
- Robotics and control for periodic phenomena (robotics, industrial automation)
- What to do: Design controllers that intentionally exploit torus/circle manifolds for phase/angle tasks (e.g., gait cycles, joint angles), and regularize early layers for phase-aligned representations.
- Tools: Phase-alignment estimators and topology checks embedded in training loops.
- Assumptions: Task exhibits periodic structure; access to the model internals; domain integration required.
- Curriculum and visualization tools for interpretability (education, academic labs)
- What to do: Build interactive teaching labs demonstrating torus vs. disc manifolds, PCA embeddings, and Betti number estimation; use PADs to illustrate universality.
- Tools: Jupyter notebooks, Ripser, prebuilt modular addition models from repositories.
- Assumptions: Educational context; modular arithmetic as the didactic testbed.
Long-Term Applications
- Generalizable manifold-based interpretability across domains (AI safety, NLP, vision)
- What to do: Extend PAD/MMD/Betti pipelines from modular addition to complex tasks (language, vision) by discovering task-specific “simple neuron” abstractions and DOFs that govern representation geometry.
- Outcome: A standardized, scalable framework for auditing hidden representations and testing universality across modalities.
- Dependencies: Research to identify appropriate abstractions beyond sinusoidal embeddings; scalable TDA methods; robust statistical estimators.
- Regulatory standards and certification pipelines (policy, compliance, public sector)
- What to do: Define topological audit requirements (e.g., PAD similarity thresholds, Betti profiles) for sensitive deployments; certify equivalence to vetted baselines before production use.
- Impact: Measurable interpretability and stability checkpoints embedded in regulation.
- Dependencies: Policy adoption, consensus on metrics/kernels, reproducibility across vendors.
- Training objectives and regularization for desired topologies (software, robotics, speech)
- What to do: Introduce losses that encourage symmetry and phase alignment (e.g., “phase alignment regularization”), or target specific manifolds (torus-to-circle) for tasks with periodic structure.
- Products: Libraries providing topology-aware regularizers and evaluation suites.
- Assumptions: Clear link between topology and downstream performance; careful tuning to avoid overconstraint.
- Model merging, transfer, and distillation via manifold alignment (foundation models, enterprise AI)
- What to do: Align model manifolds (PAD/MMD-guided) to enable safer model merging or transfer; distill knowledge through torus→disc projections where appropriate.
- Benefit: Lower risk in combining systems; improved transferability.
- Dependencies: Reliable cross-task manifold mappings; methods to avoid negative transfer.
- Drift detection and continuous compliance via representation topology (healthcare, finance)
- What to do: Monitor PADs and Betti signatures in production to detect distribution shifts or emergent failure modes; trigger rollback or retraining when manifold deviations exceed thresholds.
- Tools: Streaming PAD/MMD estimators; incremental TDA on sampled activations.
- Assumptions: Efficient online estimation; well-calibrated thresholds to minimize false alarms.
- Hardware/software co-design for manifold-centric computation (semiconductors, systems)
- What to do: Explore accelerators and libraries optimized for sinusoidal features, Fourier-like embeddings, and torus-to-disc projections to reduce inference/training cost on tasks with known periodic structure.
- Dependencies: Vendor support; evidence of broad applicability beyond toy tasks.
- Benchmarks and shared datasets for universality testing (academia, open-source)
- What to do: Create multi-task benchmarks with PAD/MMD/Betti targets and reproducible pipelines to evaluate representational universality across architectures, seeds, and training regimes.
- Dependencies: Community consensus; tooling standardization; scalable compute.
- Workforce development and standards in interpretability (education, professional training)
- What to do: Incorporate TDA, PAD analysis, and manifold-based diagnostics into ML curricula and professional certifications.
- Dependencies: Maturity of tools; broader adoption and evidence from non-toy tasks.
Notes on cross-cutting assumptions and dependencies:
- The paper’s results are strongest for modular addition under architectures with a single shared embedding matrix and first-layer neurons approximated by simple sinusoids. Generalization to complex tasks will require new abstractions and empirical validation.
- Persistent homology can miss small-radius holes; PAD estimators can be noisy; MMD sensitivity depends on kernel choice and sample size.
- Many applications require access to internal activations, weights, and controlled training loops; some production systems may restrict such access.
- Scaling TDA and statistical testing to very large models and datasets will need engineering investments and benchmarking.
Collections
Sign up for free to add this paper to one or more collections.