- The paper introduces Baichuan-M3, a clinical LLM that unifies inquiry, differential diagnosis, lab testing, and diagnosis in a coherent decision-support framework.
- It employs a three-stage training pipeline with offline and on-policy distillation, leveraging SPAR for precise, stepwise reward attribution and hallucination suppression.
- It achieves state-of-the-art performance on ScanBench and HealthBench benchmarks, demonstrating substantial improvements in safety, reasoning rigor, and low hallucination (3.5%) rates.
Baichuan-M3: Modeling Clinical Inquiry for Reliable Medical Decision-Making
Introduction and Motivation
Baichuan-M3 is a medical-specialized LLM constructed to bridge the gap between passive question answering and rigorous, end-to-end clinical decision support. The model's development responds to persistent deficits in current LLMs—specifically, their inability to actively acquire missing information, execute coherent multi-step reasoning, and robustly suppress hallucinations during open-ended medical consultations. Unlike prior models that separate clinical inquiry and reasoning or treat conversational fluency as an orthogonal objective, Baichuan-M3 aims for unified process modeling, mirroring physicians’ workflow—including proactive information elicitation, evidence-based decision trajectories, and adaptive factuality control.
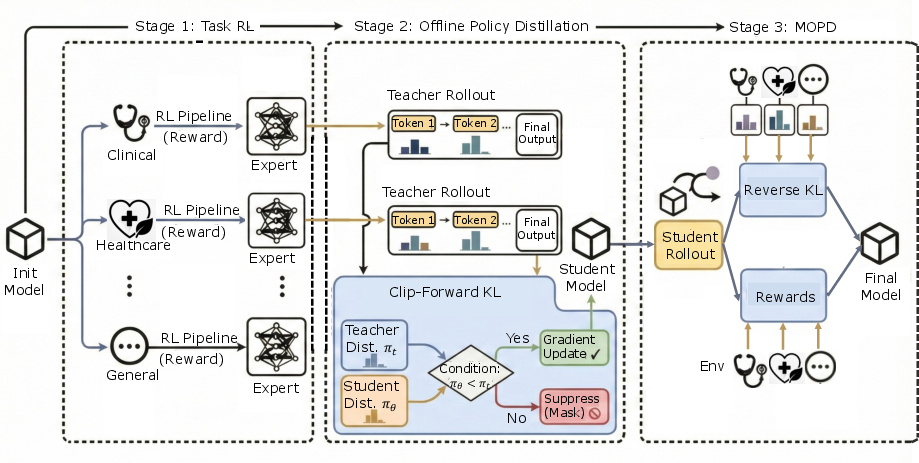
Figure 1: Three-stage pipeline for Baichuan-M3, encapsulating capability learning, distribution fusion, and policy unification.
Training Infrastructure and Methodologies
Baichuan-M3 employs a sophisticated simulation and verification environment, stable patient simulators (passive interaction/interrupt-injected modes), and a hybrid Verify System. The verification stack decouples evaluation into rubric-based structural adherence and atomic claim-level fact verification against external sources. Atomic claims are extracted via distilled models from GPT-5, and validated with a search-augmented agent; performance bottlenecks are mitigated by dual-level caching, achieving substantial computational efficiency for online RL.
The multi-task training pipeline consists of:
- Stage 1 (TaskRL): Domain-specialized teacher policies are trained via independent RL pipelines, maximizing inductive diversity and avoiding early optimization cross-talk.
- Stage 2 (Offline Policy Distillation): Teachers’ domain behaviors are compressed into a student model using Clip-Forward-KL, retaining capacity for future mode seeking and entropy preservation.
- Stage 3 (Multi-Teacher On-Policy Distillation): The student performs mixed-domain rollouts with reverse KL regularization, selecting optimal advice, and denoising conflicting teacher guidance, yielding unified policy-level behavior.
Deep Clinical Consultation: Segmented Pipeline RL and SPAR
Baichuan-M3 models multi-stage clinical consultation as a K=4 stage generative pipeline (Inquiry, Differential Diagnosis, Lab Testing, Diagnosis). Each stage is optimized for context-specific reward signals, allowing granular reasoning beyond static benchmarks. Quality-gated context transitions are enforced, such that only clinically valid interaction trajectories propagate through the curriculum.
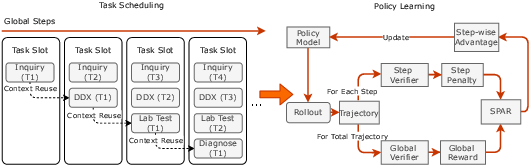
Figure 2: Segmented Pipeline RL architecture and SPAR policy learning algorithm.
SPAR (Step-Penalized Advantage with Relative baseline) provides stepwise, fine-grained reward attribution to correct critical errors (repetition, safety risks), while later focusing optimization on subtle stylistic defects. By separating local step penalties from unpenalized group baselines, SPAR achieves precise credit assignment and implicit curriculum scheduling, which is corroborated by ablation results showing superior trade-offs between redundancy reduction and logical coherence.
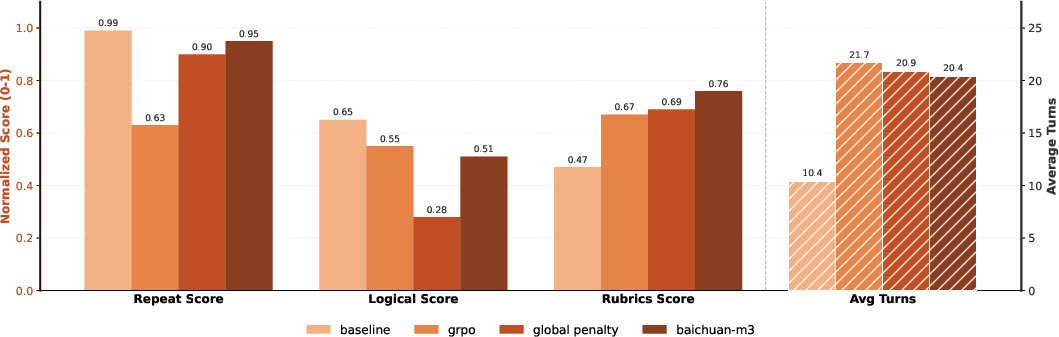
Figure 3: SPAR vs baselines—improved balance between non-redundancy and logical coherence in multi-turn consultation tasks.
Credible Healthcare Advisory: Dynamic Rubric Evolution and Fact-Aware RL
To counter reward hacking and static rubric-exploitation observed in earlier models, Baichuan-M3 introduces dynamic rubric generation. Rubrics are synthesized not only from the question but from model outputs and violations, with expert-driven admission/exit policies to ensure signal focus and avoid rule dilution.
Fact-Aware RL employs semantic signal denoising and dynamic multi-objective aggregation. Atomic claim rewards are weighted by saliency, clustered semantically, and penalized relative to factual risk; penalties are dynamically gated by task competence—full penalties are applied only after sufficient reasoning is achieved, protecting model utility from excessive conservatism.
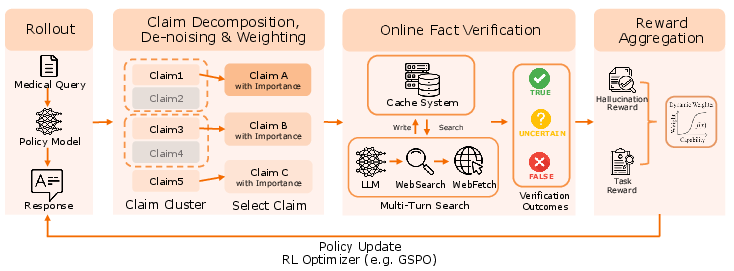
Figure 4: Fact-Aware Reinforcement Learning—weighted penalties and dynamic gating for hallucination suppression.
Ablation studies demonstrate that naive penalty policies lead to aggressive conservatism and reduced reasoning depth, while Baichuan-M3's marginal signal filtering and competence-driven gating decouple factual alignment from capability loss.
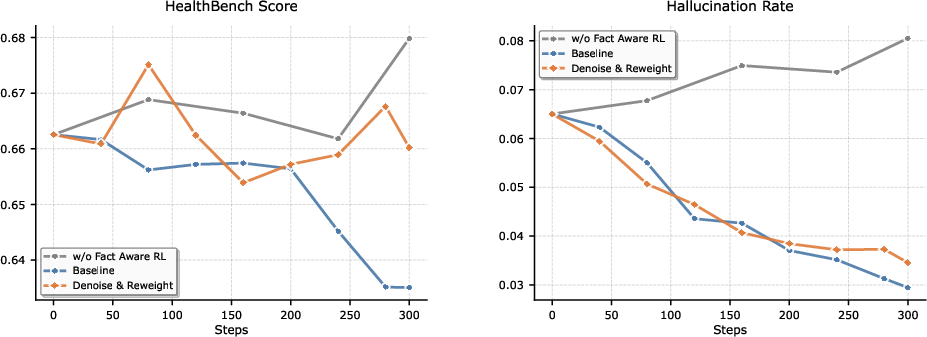
Figure 5: Comparative training dynamics—Fact-Aware RL achieves comparable hallucination reduction to static penalties while preserving reasoning performance.
Evaluation on ScanBench and HealthBench
ScanBench simulates authentic clinical workflows (Inquiry → Lab Testing → Diagnosis) with rigorous metrics (SCAN). Baichuan-M3 achieves scores of 74.9 (Inquiry), 72.1 (Lab), 74.4 (Diagnosis)—substantially outperforming GPT-5.2 and human baselines, especially in safety stratification, associative questioning, and norm adherence. The model maintains superior incremental performance across dialogue turns, indicating sustained reasoning advantage in long-horizon consultations.
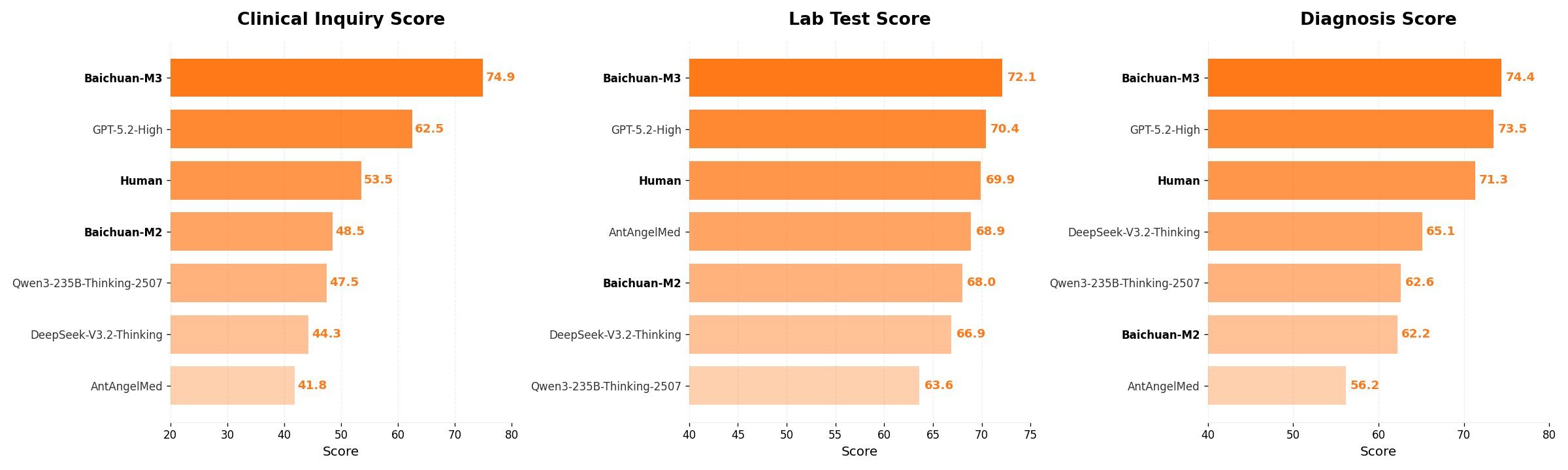
Figure 6: Overall performance comparison on ScanBench—Baichuan-M3 leads across all stages.
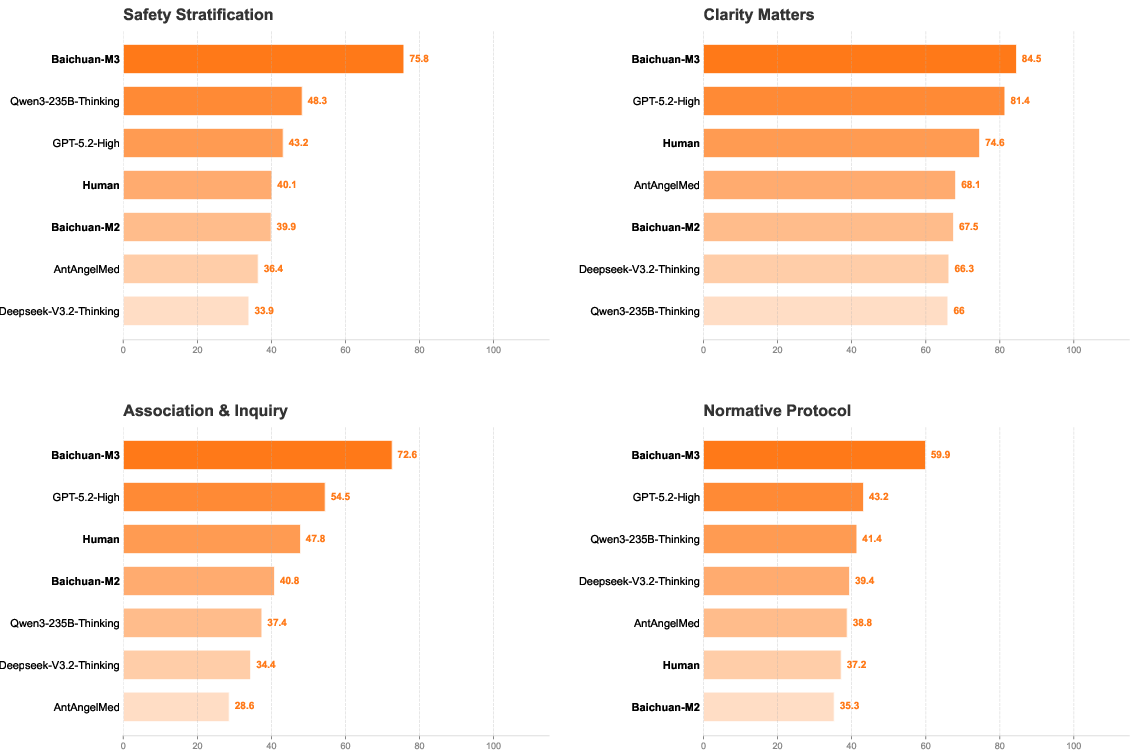
Figure 7: Inquiry capabilities breakdown—Baichuan-M3 dominates all four SCAN dimensions.
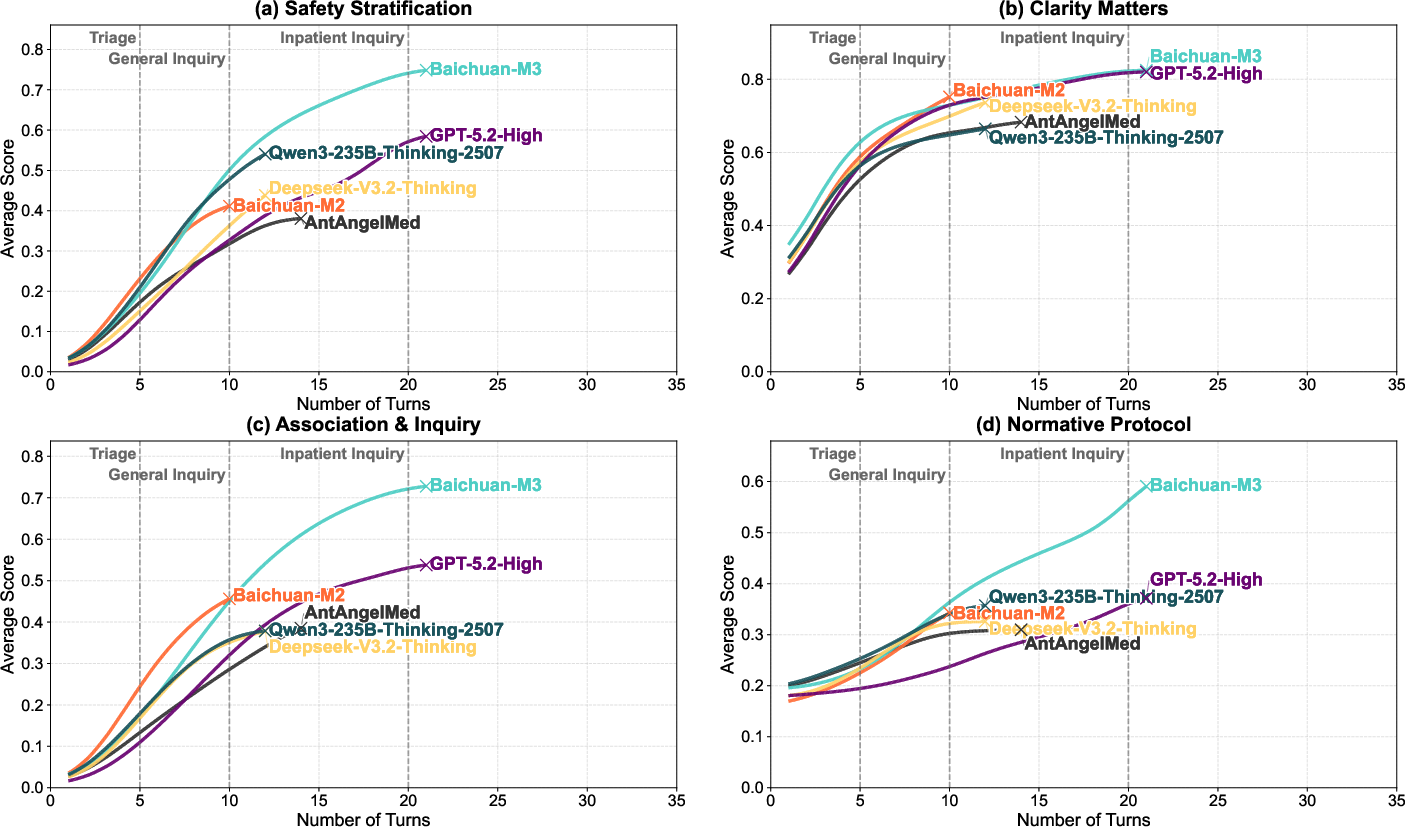
Figure 8: Model performance evolution—Baichuan-M3 maintains advantage in association inquiry over long dialogues.
HealthBench and HealthBench-Hallu measure broad medical reasoning and hallucination suppression. Baichuan-M3 reaches 65.1 (HealthBench) and 44.4 (HealthBench-Hard), with only 3.5% hallucination rate. Fact-Aware RL delivers nearly 50% reduction in hallucination/uncertainty compared to variants without it, without significant loss in capability.
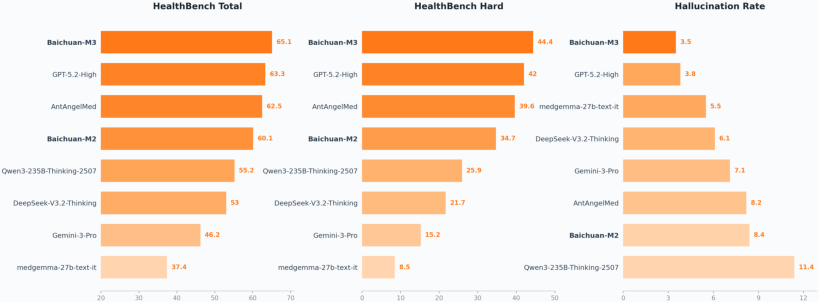
Figure 9: Performance on HealthBench—Baichuan-M3 sets new SOTA in both main and hard subsets.
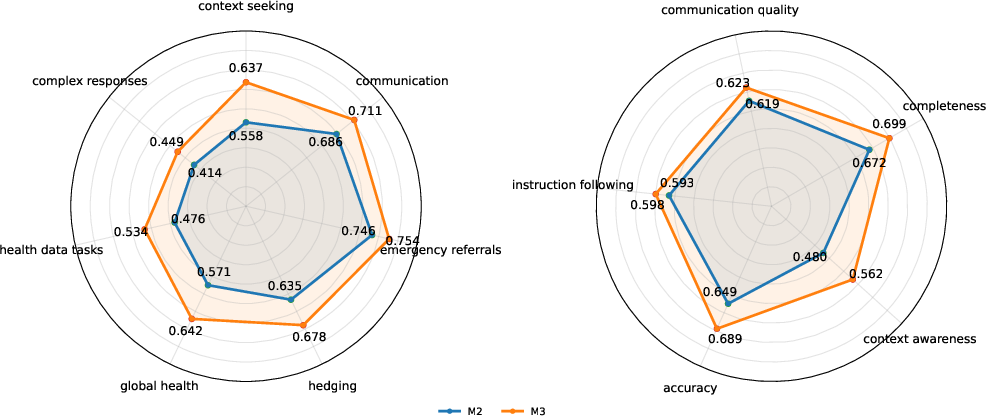
Figure 10: M2 vs M3 fine-grained HealthBench—M3 outperforms across all axes, notably context seeking and awareness.
Knowledge boundary probe analysis (Fig. 9) shows Fact-Aware RL increases alignment between internal cognition and generated claims, dramatically reducing unfaithful hallucinations. Remaining errors largely reflect “honest errors” grounded in parametric misconceptions, not generation instability.
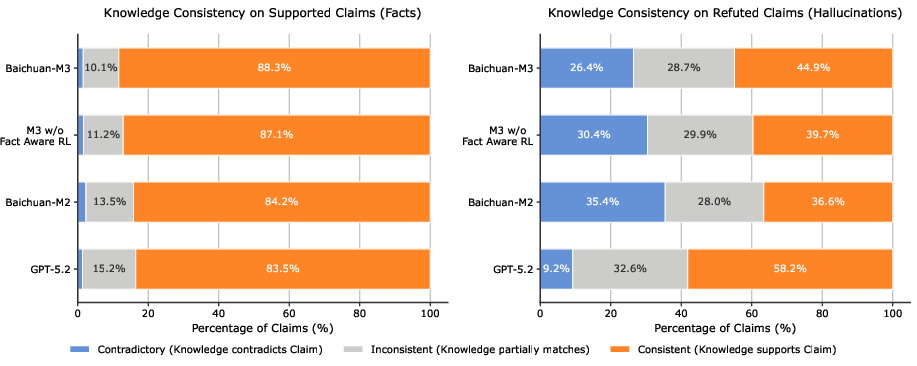
Figure 11: Knowledge boundary alignment analysis—Fact-Aware RL shifts hallucination dynamics to honest, parameter-aligned errors.
Inference Optimization: Gated Eagle-3 and Quantization
Speculative decoding with Gated Eagle-3 incorporates dynamic, learnable gating into the draft model's attention mechanism, mitigating representation mismatch, enabling longer accepted prefixes, and delivering a 12% throughput gain over the Eagle-3 base.
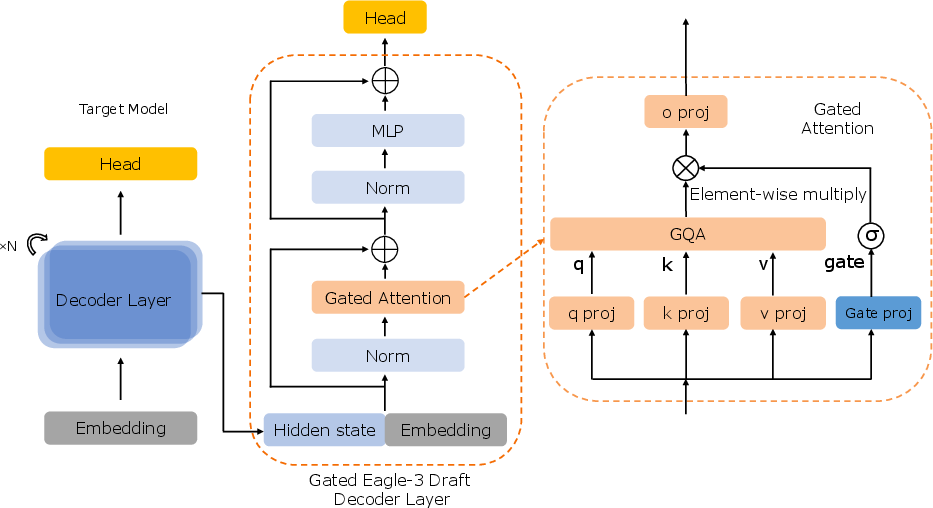
Figure 12: Gated Eagle-3 draft model—selective information regulation during speculative decoding.
INT4 quantization is calibrated via self-generated, domain-diverse prompts, ensuring uniform expert activation and near-lossless inference relative to BF16 baseline. This methodology addresses MoE activation bias and provides practical compression for large-scale healthcare LLM deployment.
Implications and Future Directions
Baichuan-M3 demonstrates that explicit modeling of clinical workflows and integration of process-aligned RL yield substantial improvements in not only factual reliability but interactive procedural rigor. The implications for medical AI include broader adoption as clinical decision-support partners, improved safety assurance in real-world deployments, and potential regulatory alignment. The methodologies—segmented pipeline RL, step-wise penalty attribution, dynamic rubric evolution, and fact-aware aggregation—generalize beyond medicine to any domain requiring deep, evidence-grounded reasoning and complex decision pathways.
Future directions for Baichuan-M3 include expanding beyond episodic, text-based consultations to full-pathway reasoning, multimodal input handling, ultra-long horizon optimization, and explicit evidence retrieval integration.
Conclusion
Baichuan-M3 advances the clinical-grade LLM paradigm by unifying inquiry, reasoning, and factuality within explicit medical workflows, substantiated by strong empirical results on both dynamic consultation and broad-spectrum reasoning benchmarks. Workflow-aligned optimization and innovative RL strategies position Baichuan-M3 as a foundation for future safe, reliable medical AI systems, and provide methodological contributions for process-oriented decision-support modeling in other high-stakes domains.