DentalGPT: Incentivizing Multimodal Complex Reasoning in Dentistry
Abstract: Reliable interpretation of multimodal data in dentistry is essential for automated oral healthcare, yet current multimodal LLMs (MLLMs) struggle to capture fine-grained dental visual details and lack sufficient reasoning ability for precise diagnosis. To address these limitations, we present DentalGPT, a specialized dental MLLM developed through high-quality domain knowledge injection and reinforcement learning. Specifically, the largest annotated multimodal dataset for dentistry to date was constructed by aggregating over 120k dental images paired with detailed descriptions that highlight diagnostically relevant visual features, making it the multimodal dataset with the most extensive collection of dental images to date. Training on this dataset significantly enhances the MLLM's visual understanding of dental conditions, while the subsequent reinforcement learning stage further strengthens its capability for multimodal complex reasoning. Comprehensive evaluations on intraoral and panoramic benchmarks, along with dental subsets of medical VQA benchmarks, show that DentalGPT achieves superior performance in disease classification and dental VQA tasks, outperforming many state-of-the-art MLLMs despite having only 7B parameters. These results demonstrate that high-quality dental data combined with staged adaptation provides an effective pathway for building capable and domain-specialized dental MLLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What Is This Paper About?
This paper introduces DentalGPT, an AI system designed to understand dental images (like photos of teeth and X-rays) and answer questions about them. It aims to help with automated oral healthcare by spotting small, important details in images and reasoning about what they mean—similar to how a dentist thinks through a diagnosis.
What Are the Main Questions the Paper Tries to Answer?
The researchers focus on two simple questions:
- How can we teach an AI to see and understand tiny, important details in dental images (like little cavities or gum problems)?
- How can we make the AI think through dental questions step by step, so its answers are more accurate and trustworthy?
How Did the Researchers Approach the Problem?
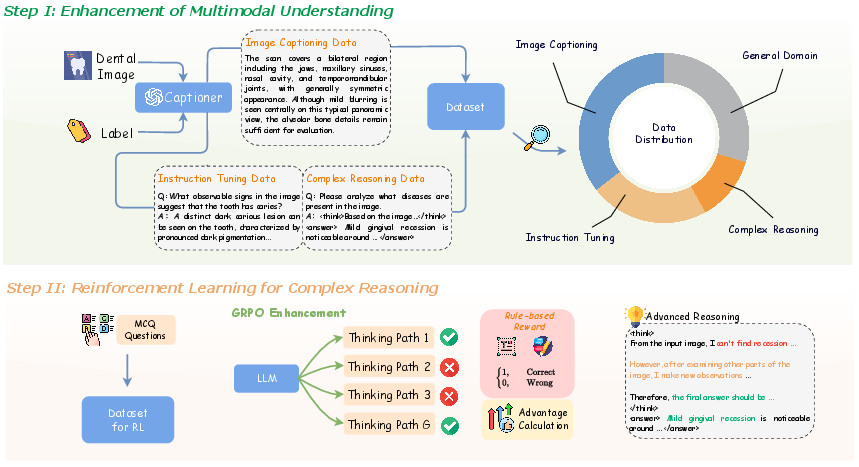
The team built DentalGPT using a two-stage training process and a very large, carefully prepared dataset. Here’s the approach in everyday terms:
Stage I: Teach the AI to “See” Dental Images Better
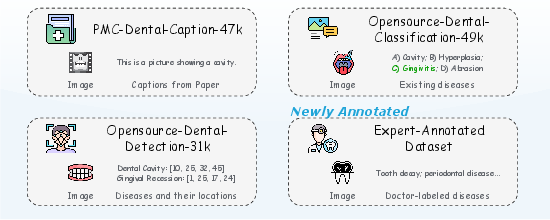
- They gathered the largest collection of dental images ever used for AI training—over 120,000 pictures of teeth and X-rays—each paired with clear, expert-guided descriptions. Think of this like making a huge study guide that shows pictures and explains what’s important in each one.
- The AI was trained on:
- Image descriptions (to learn how to spot and describe what’s in the picture).
- Question–answer examples (so it knows how to respond to typical dental questions).
- Some “think-aloud” examples (basic multi-step explanations) to start building reasoning skills.
- A bit of general image–text data (to make sure it still understands everyday visuals, not only teeth).
Stage II: Teach the AI to “Think” Better Using Practice and Feedback
- They used a method called reinforcement learning (RL). This is like giving the AI multiple tries to answer a question and rewarding the better attempts.
- Specifically, they used GRPO (Group Relative Policy Optimization), which:
- Makes the AI generate several possible answers for the same question.
- Scores each answer based on whether it’s in the right format and whether it’s correct.
- Encourages the AI to prefer the better answers in future attempts, improving its reasoning over time.
- To make scoring easier and safe, many questions were multiple-choice, so the system could check correctness automatically.
If “reinforcement learning” sounds complex, imagine practicing a skill (like solving math problems): you try several ways, get points for correct and well-explained solutions, and adjust your strategy to earn more points next time.
What Did They Find?
After training, DentalGPT did very well across several tests:
- It was tested on different kinds of dental images:
- Intraoral photos: pictures taken inside the mouth.
- Panoramic X-rays: wide X-rays that show the whole jaw and teeth.
- Dental question–answer benchmarks (special tests designed for medical AI).
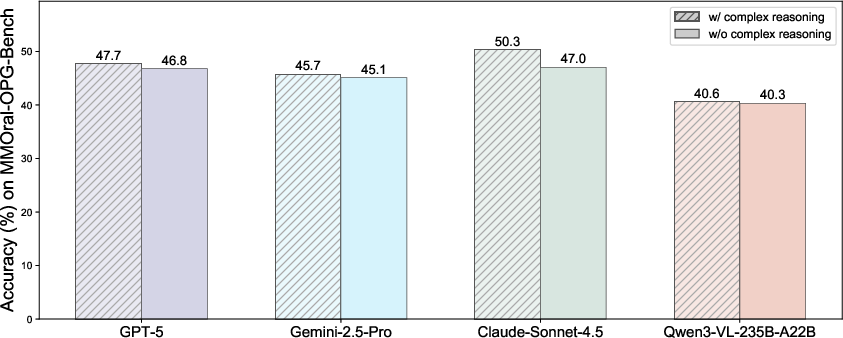
- Even though DentalGPT is a relatively small model (about 7 billion parameters), it beat many larger, popular AI models on dental tasks. That means it’s efficient and well-focused on dentistry.
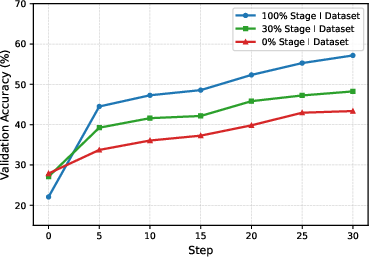
- The two-stage training made a big difference:
- Stage I (seeing better) helped the AI learn lots of dental knowledge and spot key features.
- Stage II (thinking better) boosted its step-by-step reasoning, making answers more accurate and professional.
In short: better data plus smart training led to stronger results.
Why Is This Important?
- Dentists are busy, and dental images can be tricky. An AI that can reliably analyze images and explain its reasoning could save time and reduce mistakes.
- DentalGPT shows that you don’t need a huge, general-purpose AI to do a specialized job well. A focused, carefully trained model can perform better with fewer resources.
- It also proves that high-quality, expert-reviewed data is crucial: the system learns best when the training images and descriptions are precise, safe, and clinically meaningful.
What Could This Mean for the Future?
DentalGPT could help in several ways:
- Assist dentists: Offer second opinions, highlight subtle problems, and suggest what to look at next.
- Support patient education: Explain what’s visible in an X-ray or photo in simple terms.
- Improve tele-dentistry: Help analyze images taken at home (even if lighting or angles aren’t perfect).
- Guide research and development: Show how to build other specialized medical AIs using high-quality data and step-by-step training.
Of course, like any medical tool, AI should assist—not replace—professional dentists. It needs careful testing, ethical use, and clear safety checks. But this work is a strong step toward smarter, more reliable AI in oral healthcare.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research.
- Clinical validation is missing: no prospective or retrospective studies with dentist-in-the-loop assessments, patient outcomes, or workflow integration to demonstrate real-world diagnostic benefit.
- Modalities are limited: the dataset and evaluations focus on intraoral photos and panoramic radiographs; there is no coverage of high-impact dental modalities such as periapical/bitewing X-rays, CBCT/3D scans, cephalometric radiographs, or occlusal views.
- Tooth-level grounding is absent: the model is not trained for tooth detection, numbering, segmentation, or lesion localization; evidence-grounded outputs linking rationales to specific teeth/regions are not evaluated.
- Label taxonomy is narrow: benchmark labels cover a small set of common conditions without severity grading (e.g., caries depth), stage, or standardized clinical ontologies (e.g., SNODENT, ICD-10, FDI tooth numbers); mapping to structured dental charts is not explored.
- Uncertainty and abstention are not modeled: the pipeline filters out low-agreement labels but does not evaluate selective prediction, uncertainty quantification, or “safe failure” strategies on ambiguous or low-quality images.
- Dataset diversity is underreported: the paper does not provide distributions for age, sex, ethnicity, socioeconomic status, image source/device manufacturer, or hospital/site; domain shift across scanners, clinics, and patient subgroups is untested.
- Fairness and bias are unassessed: no subgroup performance analysis (e.g., by demographic attributes, device types, or clinical settings) to identify differential error rates or potential inequities.
- Potential data leakage is insufficiently ruled out: while some duplicates were removed, the paper does not provide exhaustive checks for overlap between training and test splits across all sources (e.g., PMC-derived images), nor a leakage auditing protocol.
- Safety evaluation is superficial: “Content Safety” scoring by an external LLM judge does not assess clinical harm, misdiagnosis risk, or regulatory compliance; no red-team testing, harmful advice audits, or risk-sensitive scenarios are reported.
- GPT-5–curated data may propagate biases/hallucinations: reliance on GPT-generated captions and CoT without human audit beyond automated verification risks subtle errors; no blinded expert review of curation outputs is described.
- Reasoning reward design is narrow: GRPO uses only accuracy and formatting rewards on multiple-choice tasks; there is no process-based reward, fact-consistency reward, or evidence-grounding reward to ensure reasoning fidelity.
- Multiple-choice RL may not reflect clinical use: converting labels to MC questions simplifies tasks and may encourage answer selection heuristics rather than clinically faithful, open-ended reasoning typical of dental consultations.
- GRPO configuration is underexplored: no ablations on group size, KL regularization strength, sampling temperature, or rollout length; comparative studies against alternative RL/RLHF methods (e.g., PPO, DPO, RLAIF, process rewards, preference models) are missing.
- Long CoT generation costs are not analyzed: the model allows up to 8192 tokens per response, but there is no profiling of inference latency, compute/memory footprint, or cost-vs-benefit trade-offs for clinical deployment.
- Benchmark metrics are limited: accuracy is reported for multi-label tasks, but there is no F1, precision/recall per class, AUROC, calibration metrics (ECE/Brier), or statistical significance testing across runs.
- Error analysis is shallow: the paper lacks category-level breakdowns (e.g., which specific diseases or visual cues fail), confusion matrices, or qualitative failure modes (lighting, occlusion, restorations, artifacts).
- Baselines omit specialized dental CV systems: no comparisons against state-of-the-art task-specific models (e.g., panoramic lesion detectors, tooth segmentation networks, caries classifiers) to quantify the added value of an MLLM approach.
- Evidence-grounded explainability is not validated: rationales are presented but not checked against ground truth regions (e.g., boxes/masks) or expert Rubrics; there is no measure of explanation faithfulness or sufficiency.
- Multilingual robustness is untested: the model’s performance across languages (patient-facing Chinese/English or clinical documentation) and terminology variants is not evaluated.
- Multi-image and longitudinal reasoning are unexplored: no tasks involve combining multiple views (e.g., pre/post-treatment, series of X-rays) or integrating clinical text/EHR notes with images.
- Deployment constraints are unclear: despite claiming efficiency at 7B, there is no examination of quantization, edge inference feasibility, integration with clinical PACS systems, or real-time performance in dental clinics.
- Ethics, privacy, and compliance are not detailed: patient consent, de-identification procedures, IRB approvals, data licensing, and adherence to medical device regulations are not documented.
- Generalization beyond curated benchmarks is uncertain: external validation on unseen hospitals, devices, or public dental datasets is absent; robustness to low-quality, patient-taken smartphone images is only partially addressed.
- Scaling laws are incomplete: Stage I alignment was varied at 0%, 30%, and 100%, but broader scaling analyses (data size, knowledge composition, modality mix) and diminishing returns thresholds are not characterized.
- Release and reproducibility are not specified: the paper does not clarify plans for releasing code, model weights, curated datasets, or detailed annotation protocols to enable independent replication.
Practical Applications
Immediate Applications
Below are deployable, real-world uses that can be built on top of the paper’s findings, dataset engineering, and training pipeline.
- Chairside AI copilot for dentists (healthcare, software)
- What: Assistive second-reader for intraoral photos and panoramic X-rays that flags likely conditions (e.g., caries, calculus, periapical lesions, periodontal disease, impacted teeth, tooth loss, prior root canal) and highlights diagnostically relevant cues.
- Product/workflow: “DentalGPT-Assist” plugin for PACS/dental viewers; structured finding summaries auto-inserted into the chart; confidence scores; human-in-the-loop acceptance.
- Assumptions/dependencies: Sufficient image quality; on-prem or cloud inference for a ~7B MLLM; EHR/PACS integration via DICOM/DICOM-SR/HL7/FHIR; regulatory use as decision support (not autonomous diagnosis).
- Panoramic X-ray pre-screen and worklist prioritization (healthcare, radiology software)
- What: Auto-triage incoming OPGs to prioritize suspected pathology; basic quality control (e.g., positioning/contrast issues); suggested labels for common findings.
- Product/workflow: “Panorex Prioritizer” service inside imaging pipeline with queue reordering and alerting.
- Assumptions/dependencies: Hospital IT integration; explainable outputs; clinical oversight; domain shift checks for scanner vendors and protocols.
- Tele-dentistry intake and remote review (healthcare, telehealth)
- What: Asynchronous preconsult support from patient-uploaded photos; structured symptom checklists and risk flags; pre-visit summaries for clinicians.
- Product/workflow: Secure web/app module with guided capture, automated summaries, and referral urgency tagging.
- Assumptions/dependencies: Variable photo quality; consumer privacy/consent (HIPAA/GDPR/local laws); clear disclaimers (not a diagnosis).
- Automated dental charting and report drafting (healthcare, software)
- What: Convert detected conditions into structured notes and provisional codes (e.g., SNODENT/CDT/ICD) and generate patient-friendly explanations with visual evidence.
- Product/workflow: “AutoChart” service that proposes codes/findings for clinician confirmation; audit trail of model reasoning.
- Assumptions/dependencies: Mapping tables to local coding systems; clinician review; handling uncertainty and out-of-scope findings.
- Insurance claim documentation support (finance/insurtech)
- What: Auto-generate narratives and evidence packs (annotated images, detected restorations) to support claims or pre-authorizations.
- Product/workflow: “Dent-ClaimAI” assistive drafting tool for practices and payers; fraud heuristics (e.g., inconsistent imaging evidence).
- Assumptions/dependencies: Payer integration; strict privacy; human adjudication remains final; clear error handling for edge cases.
- Dental education and simulation (academia, education)
- What: Case-based VQA tutor that explains visual cues, common pitfalls, and differential patterns on intraoral and panoramic images.
- Product/workflow: “EduDent VQA” with graded quizzes derived from the curated benchmarks; feedback using chain-of-thought–style rationales.
- Assumptions/dependencies: Educator oversight; alignment with curriculum; toggle or redact chain-of-thought where policy requires.
- Benchmarking and reproducible evaluation for dental AI (academia, industry)
- What: Use the paper’s benchmarks and labeling protocols (consensus labels, uncertainty filtering, balanced splits) to evaluate new models fairly.
- Product/workflow: Evaluation suite with leaderboards and audit tools for inter-rater agreement and domain shift reports.
- Assumptions/dependencies: Access to benchmark data or comparable in-house sets; licensing/IRB compliance for clinical images.
- Data curation and RL training toolkit for medical MLLMs (academia, software)
- What: Replicate the paper’s dataset engineering pipeline (captioning, instruction tuning, CoT seeds, dentist cross-validation) and GRPO-based reward shaping for multi-choice tasks.
- Product/workflow: “Med-MLLM Curation Kit” with prompt templates, validation scripts, and GRPO training recipes.
- Assumptions/dependencies: Availability of labeled/annotated images; model and compute budget; legal use of LLMs for data refinement.
Long-Term Applications
These use cases are feasible with further research, scaling, multi-institution validation, or regulatory approval.
- Regulatory-grade diagnostic SaMD for specific dental conditions (healthcare, policy/regulatory)
- What: Indicated use for detection of defined pathologies (e.g., periapical lesions, caries, impacted teeth) with validated sensitivity/specificity.
- Product/workflow: Clinical trials, post-market surveillance, risk management, robust uncertainty estimation, and drift monitoring.
- Assumptions/dependencies: Prospective multi-site studies; rigorous quality management (ISO 13485), MDSAP; regional approvals (FDA/CE/NMPA).
- Comprehensive treatment planning assistant (healthcare, software)
- What: Multi-modal fusion (OPG, intraoral photos, CBCT, intraoral scans, EHR) to draft treatment options, sequencing, and cost estimates; orthodontic and restorative planning support.
- Product/workflow: “PlanDent Pro” with simulation tools and patient-facing consent materials.
- Assumptions/dependencies: Reliable 2D–3D integration; calibration/registration pipelines; richer datasets and labels; clinician oversight.
- AR-guided clinical workflow (healthcare, robotics/AR)
- What: Real-time overlay of tooth numbering, suspected lesions, and margins via loupes or smart glasses during exams and hygiene procedures.
- Product/workflow: Chairside AR viewer integrated with intraoral cameras; voice or foot-pedal interactions.
- Assumptions/dependencies: Low-latency edge inference; sterile, ergonomic hardware; validated UI to prevent distraction or overreliance.
- Population-level oral health surveillance (public health, policy)
- What: De-identified, aggregated image analytics to map disease prevalence, care gaps, and screening outcomes across regions.
- Product/workflow: “OralHealth Insights” dashboards for ministries/health systems; equity and access monitoring.
- Assumptions/dependencies: Privacy-preserving pipelines (federated learning/secure aggregation); ethical data-sharing; standardized imaging protocols.
- Federated, continuously learning dental AI network (healthcare, software)
- What: Cross-clinic model updates without centralizing PHI; site-specific adaptation and drift detection.
- Product/workflow: Federated training orchestration, secure enclaves, and automated validation suites.
- Assumptions/dependencies: Heterogeneous data harmonization; governance agreements; robust privacy guarantees and rollback mechanisms.
- Cross-specialty transfer of the method (academia, healthcare)
- What: Apply the staged domain-alignment + GRPO reasoning framework to specialties needing fine-grained visual reasoning (e.g., dermatology, ophthalmology, pathology).
- Product/workflow: Specialty-specific datasets, multi-choice RL rewards, and consensus labeling protocols.
- Assumptions/dependencies: Access to high-quality images and experts; adaptation of taxonomies and safety guardrails per specialty.
- High-resolution zoom-level pathology for oral oncology (healthcare, research)
- What: Slide-level or endoscopic image reasoning for early oral cancer detection and biopsy triage with explainable evidence tiles.
- Product/workflow: Pathology viewer tools with heatmaps and uncertainty bounds; integration with lab LIS.
- Assumptions/dependencies: Large-scale labeled histopathology/endoscopy datasets; robust magnification handling; clinical trials.
- Automated claims adjudication and pre-authorization (finance/insurtech, policy)
- What: Evidence-driven automation for routine claims and prior auth decisions using model-backed image review.
- Product/workflow: Payer-side AI adjudication APIs with audit logs and spot-check sampling.
- Assumptions/dependencies: Regulatory acceptance; fairness audits; appeal processes and human override; anti-fraud safeguards.
- Home oral health monitoring kits (consumer health)
- What: Consumer-grade intraoral cameras or smartphone adapters with periodic AI analysis to track treatment progress (orthodontics/periodontal) and prompt care-seeking.
- Product/workflow: Subscription app with reminders, trend graphs, and clinician handoff when thresholds are crossed.
- Assumptions/dependencies: Reliable guided capture; clear safety messaging; integration with provider networks; risk triage protocols.
- Tool-augmented reasoning for measurements and planning (software, robotics)
- What: Coupling DentalGPT with measurement/segmentation tools (tooth numbering, pocket depths, lesion sizes) to enable semi-automated planning and documentation.
- Product/workflow: API orchestration layer for tool invocation and verification loops; provenance tracking for medico-legal use.
- Assumptions/dependencies: Stable tool APIs and UI integration; validation of measurement accuracy; managing cascading errors.
Notes on feasibility and risk across applications
- Model scope: Current strengths are in classification/VQA of intraoral photos and panoramic X-rays; performance outside labeled classes or on rare conditions may degrade.
- Data and deployment: Success depends on image quality, device variability, and domain shift; ongoing calibration and QA are required.
- Safety and governance: Maintain human-in-the-loop, transparent uncertainty, and audit trails; ensure privacy/security compliance (HIPAA/GDPR/local).
- IP/licensing: Availability of DentalGPT weights, datasets, and licenses will affect commercializability; institutional agreements may be needed.
Glossary
- Accuracy Reward: A component of the reinforcement learning objective that grants reward based on whether the model’s predicted option is correct in multiple-choice tasks. "Accuracy Reward:"
- Chain-of-Thought (CoT) reasoning: A reasoning approach where the model generates explicit intermediate steps to solve complex problems before producing a final answer. "long chain-of-thought generation"
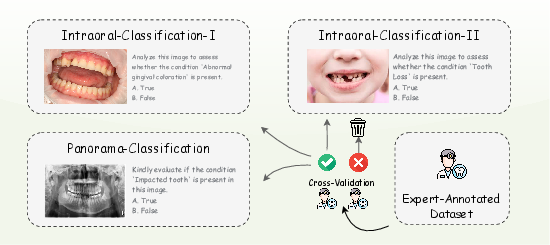
- Cross-validation workflow: An annotation quality-control process where multiple experts independently label data and agreement is enforced to ensure reliability. "Cross-validation workflow used for benchmark labeling."
- Dental calculus: Hardened mineralized plaque (tartar) that deposits on teeth, often visible near the gum line. "dental calculus"
- Dental caries: Tooth decay caused by bacterial demineralization of enamel and dentin. "dental caries"
- Dental lesion localization: Tasks and datasets focused on identifying and spatially locating pathologies in dental images. "dental lesion localization tasks"
- Dental VQA: Visual Question Answering applied to dental images and scenarios. "dental VQA tasks"
- Gingival morphology: The shape and structural characteristics of the gums, including abnormalities that may indicate disease. "abnormal gingival morphology"
- Gingival recession: The apical migration of gum tissue that exposes the tooth root surface. "gingival recession"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that optimizes a policy by comparing relative advantages among sampled responses within a group, avoiding the need for a value network. "Group Relative Policy Optimization (GRPO)"
- Grouped rollouts: Sampling multiple candidate responses per prompt in reinforcement learning to form a group for relative advantage estimation. "optimized using grouped rollouts"
- Impacted tooth: A tooth that fails to erupt properly due to obstruction or misalignment. "impacted tooth"
- Instruction Tuning: Fine-tuning using curated question–answer pairs to improve a model’s ability to follow instructions and respond appropriately. "Instruction Tuning data consists of a large number of questionâanswer samples"
- Intraoral: Pertaining to the interior of the mouth; commonly used to describe photos or images taken inside the oral cavity. "intraoral photographs"
- Jawbone lesion: A pathological change or abnormality in the maxilla or mandible visible in imaging. "jawbone lesion"
- KL regularization: The use of Kullback–Leibler divergence as a penalty to constrain updates away from a reference policy during optimization. "via KL regularization."
- Multimodal LLM (MLLM): A LLM that can process and integrate multiple modalities, typically text and images. "multimodal LLMs (MLLMs)"
- Multimodal Understanding Enhancement: A training stage focused on aligning visual and textual knowledge to strengthen fine-grained image understanding. "Multimodal Understanding Enhancement stage"
- Multi-label classification: A classification setting where each instance can have multiple labels simultaneously. "Each benchmark supports multi-label classification"
- Panoramic radiographs (X-ray images): Wide-field dental X-rays that capture the entire jaws, teeth, and surrounding structures in a single image. "panoramic radiographs (X-ray images)"
- Panoramic X-ray understanding: The capability of a model to interpret panoramic dental X-rays accurately. "panoramic X-ray understanding"
- Periapical lesion: A pathology located around the apex (tip) of a tooth root, often associated with infection or inflammation. "periapical lesion"
- Periodontal disease: Inflammatory diseases affecting the gums and supporting structures of the teeth. "periodontal disease"
- Root canal treatment: An endodontic procedure that removes infected pulp tissue and seals the root canal system. "root canal treatment"
- Value network: A reinforcement learning component that estimates the expected return of states or actions; GRPO is designed to work without it. "without requiring a value network."
- Visual Question Answering (VQA): A task where a model answers questions about images, combining visual perception with language understanding. "medical VQA benchmarks"
Collections
Sign up for free to add this paper to one or more collections.