- The paper introduces JRDB-Pose3D, a comprehensive dataset enabling multi-person 3D pose and shape estimation in real-world, crowded environments.
- It leverages SMPL-based annotations, 360° robotic views, and a multi-stage validation pipeline to ensure high-quality data in challenging scenarios.
- This resource catalyzes advancements in robotics and AI, addressing occlusion challenges and facilitating research on socially informed navigation.
JRDB-Pose3D: A Comprehensive Dataset for Multi-person 3D Human Pose and Shape Estimation
Introduction
The JRDB-Pose3D dataset presents a novel approach to tackling the challenges faced in real-world human-centric applications, particularly within robotics and autonomous navigation systems. This dataset addresses significant limitations inherent in existing benchmarks for 3D human pose estimation, which predominantly focus on single-person scenes or controlled environments, thus limiting their applicability in dynamic, everyday contexts. JRDB-Pose3D captures complex, crowded real-world scenes, providing rich annotations for human poses, shapes, and interactions in diverse indoor and outdoor environments.
Dataset Characteristics and Annotations
At the core of JRDB-Pose3D is a multi-human scene dataset, which was constructed by annotating sequences obtained from the JRDB dataset. JRDB features footage captured by a mobile robotic platform equipped with stereo cameras, enabling a comprehensive 360° view of the environment. This dataset comprises 54 sequences, capturing densely populated scenes averaging 5-10 human poses per frame, with some scenes featuring up to 35 individuals simultaneously.
JRDB-Pose3D provides SMPL-based pose annotations with consistent body shape parameters and identity tracking across time. It includes additional modalities such as 2D poses, semantic segmentation, and detailed individual annotations including age, gender, and race. These annotations are crucial for interpreting and predicting interactions within social and environmental contexts, addressing the complex dynamics of crowded scenes characterized by occlusions, truncated bodies, and out-of-frame body parts.
Annotation Pipeline
The annotation process in JRDB-Pose3D follows a multi-stage pipeline. This involves initializing poses using state-of-the-art pretrained models, localizing poses within a global 3D scene, ensuring consistent shape representation across frames, and refining local 3D poses through optimization techniques. Manual inspection is employed to validate and correct annotations, particularly for poses subject to occlusions or challenging environmental interactions.
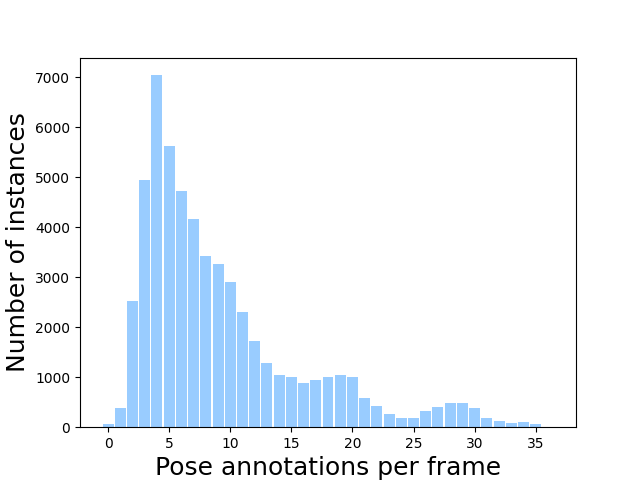
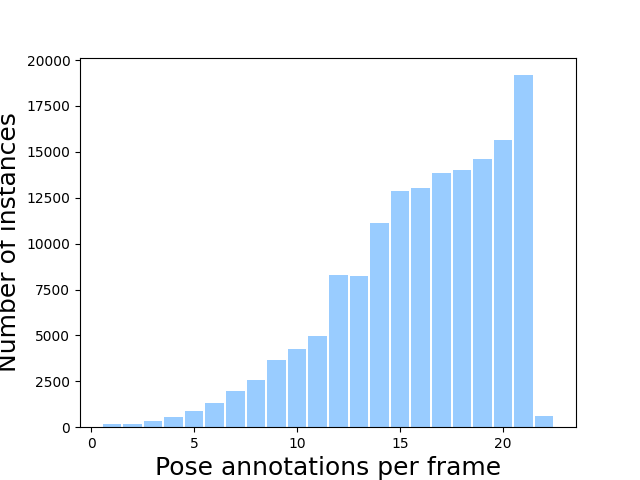
Figure 1: Example visualization of the JRDB-Pose3D dataset, demonstrating indoor and outdoor multi-person scenes.
Uniqueness Compared to Existing Datasets
JRDB-Pose3D stands apart from other datasets due to its real-world context captured from a robotic viewpoint, thus providing a unique testbed for robotic perception systems. While datasets like WorldPose offer large-scale human scene data, they often focus on specific environments like sports arenas and are recorded from top-down perspectives, thereby limiting applicability for ground-level navigation tasks.
JRDB-Pose3D provides a panoramic view with human poses distributed across a broad angle span and varying distances from the camera. These characteristics are integral for developing advanced models in robot perception and navigation, considering the varied complexities posed by real-world environments.
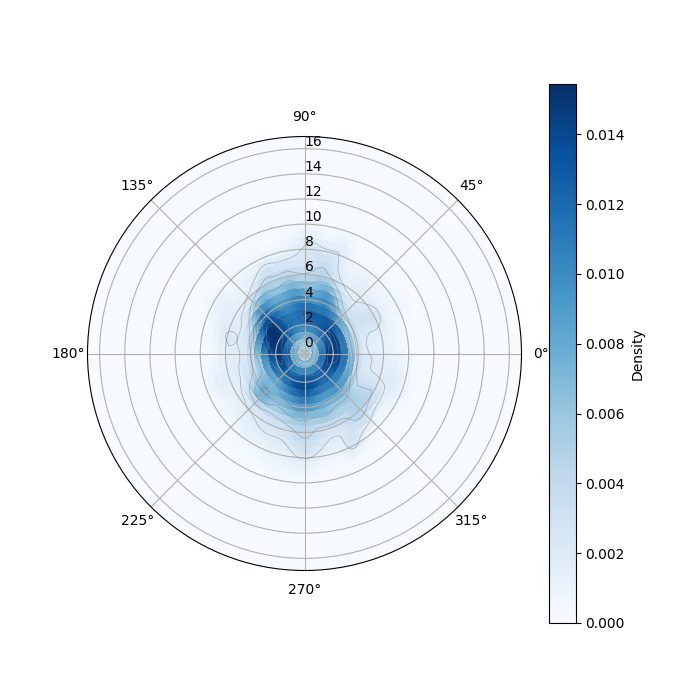
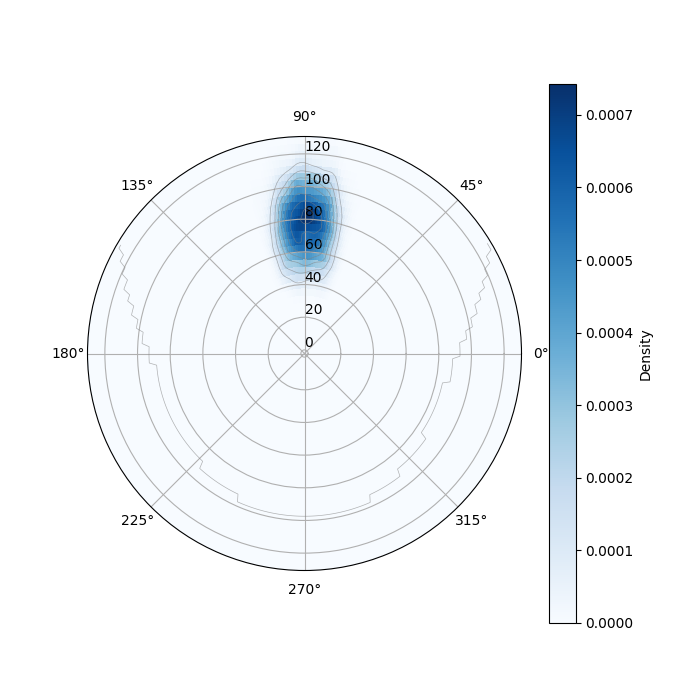
Figure 2: Kernel Density Estimates (KDEs) of people distribution and polar density for JRDB-Pose3D, emphasizing spatial diversity.
JRDB-Pose3D also prioritizes capturing realism in scenarios plagued by frequent occlusions and dense crowds. The dataset categorizes poses based on recovery difficulty, proving essential for benchmarking methods on robust estimates and tracking capabilities.
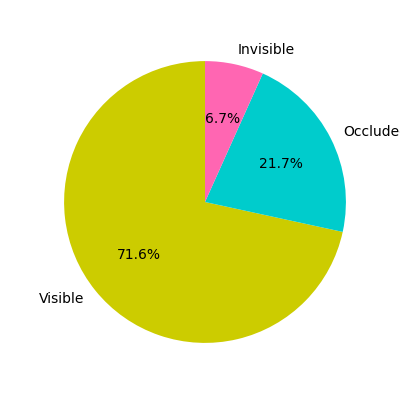
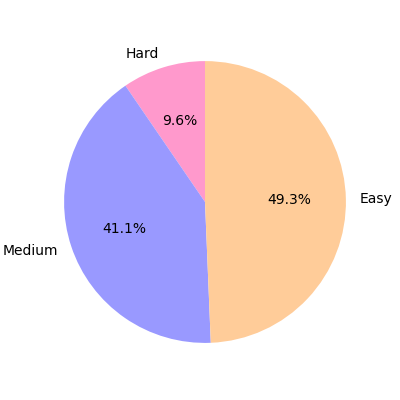
Figure 3: Statistics of occlusion and pose recovery challenges within JRDB-Pose3D, indicating dataset complexity.
Theoretical and Practical Implications
The JRDB-Pose3D dataset offers substantial practical and theoretical benefits. Practically, it serves as a benchmark for developing systems that require understanding and predicting human behavior in cluttered environments. Theoretically, it provides a framework for exploring concepts such as interaction-aware pose estimation and socially informed navigation, critical for AI advancements in robotics.
Future directions may explore the integration of multimodal data for enhanced scene understanding, improving machine perception, and fostering advancements in human-centric task automation.
Conclusion
JRDB-Pose3D is a pioneering step in the field of human-centric datasets for robotics, presenting a robust framework for 3D human pose and shape estimation in real-world crowds. This dataset provides invaluable resources for advancing research in socially aware perception tasks and robot navigation systems, thereby contributing to the evolution of AI in complex environments.