Closing the Loop: Universal Repository Representation with RPG-Encoder
Abstract: Current repository agents encounter a reasoning disconnect due to fragmented representations, as existing methods rely on isolated API documentation or dependency graphs that lack semantic depth. We consider repository comprehension and generation to be inverse processes within a unified cycle: generation expands intent into implementation, while comprehension compresses implementation back into intent. To address this, we propose RPG-Encoder, a framework that generalizes the Repository Planning Graph (RPG) from a static generative blueprint into a unified, high-fidelity representation. RPG-Encoder closes the reasoning loop through three mechanisms: (1) Encoding raw code into the RPG that combines lifted semantic features with code dependencies; (2) Evolving the topology incrementally to decouple maintenance costs from repository scale, reducing overhead by 95.7%; and (3) Operating as a unified interface for structure-aware navigation. In evaluations, RPG-Encoder establishes state-of-the-art repository understanding on SWE-bench Verified with 93.7% Acc@5 and exceeds the best baseline by over 10% on SWE-bench Live Lite. These results highlight our superior fine-grained localization accuracy in complex codebases. Furthermore, it achieves 98.5% reconstruction coverage on RepoCraft, confirming RPG's high-fidelity capacity to mirror the original codebase and closing the loop between intent and implementation.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of “Closing the Loop: Universal Repository Representation with RPG-Encoder”
What is this paper about?
This paper is about helping AI tools understand and work with big software projects (called “repositories”) more smartly. The authors introduce a new way to represent a whole codebase, called the RPG-Encoder, so an AI can quickly find the right pieces of code, understand how everything fits together, and even rebuild the project from a high-level plan.
What questions are the researchers asking?
They focus on two main questions:
- How can we give AI a single, clear “map” of a codebase that explains both what each part does (the meaning) and how parts connect (the structure)?
- Can this map work in both directions: from idea to code (generation) and from code back to idea (comprehension), so the loop is “closed”?
How does their method work?
Think of a big software project like a city:
- Files, classes, and functions are rooms and buildings.
- Imports and function calls are roads and hallways.
- Documentation tells you what places are for, but not how to get there.
- Dependency graphs tell you how places connect, but not why they exist.
Their RPG-Encoder builds a single map that combines both the “what” and the “how” so you can navigate quickly and correctly.
It has three main parts:
- Encoding (building the map): The system reads code and creates a graph with “nodes” (like rooms/buildings) and “edges” (roads/hallways). Each node has:
- A short description of what it does (meaning).
- Metadata like its type and file path (where it lives).
- Edges include:
- Functional links (which features belong under which high-level feature).
- Dependency links (which files/functions call or import others).
- Evolution (keeping the map up to date): When you make a commit (change), the system updates only the parts that changed, instead of rebuilding the whole map. This makes updates much cheaper and faster.
- Operation (using the map): The map becomes a tool the AI can query:
- Search by meaning (e.g., “where is the login logic?”).
- Jump to code and inspect it.
- Follow connections to see how data and calls flow.
In everyday terms:
- “Semantic lifting” = turning detailed code into short, clear summaries of what it does.
- “Hierarchy building” = grouping related pieces into higher-level features (like organizing rooms into floors and buildings).
- “Grounding” = attaching the abstract features back to real files and folders, plus the actual call/import links.
What did they find, and why is it important?
They tested RPG-Encoder on two kinds of tasks:
- Finding the right place in code to fix a bug or make a change (Repository Understanding):
- On tough, real-world datasets (SWE-bench Verified and SWE-bench Live Lite), RPG-Encoder beat other methods—often by a lot.
- For example, with one model, it found the correct function within its top 5 guesses about 94% of the time (Acc@5 ≈ 93.7%). That’s very strong for large, tangled codebases.
- Rebuilding projects from the map (Repository Reconstruction):
- Using only the RPG map, the system could rebuild about 98.5% of a target project’s structure and code content—far more than using plain API docs alone (which recovered only a small fraction).
- This shows the map isn’t just helpful for search—it’s detailed enough to guide making the whole project again.
Other key benefits:
- Efficiency: Using the map, the AI needed fewer steps and lower cost to find answers compared to other methods.
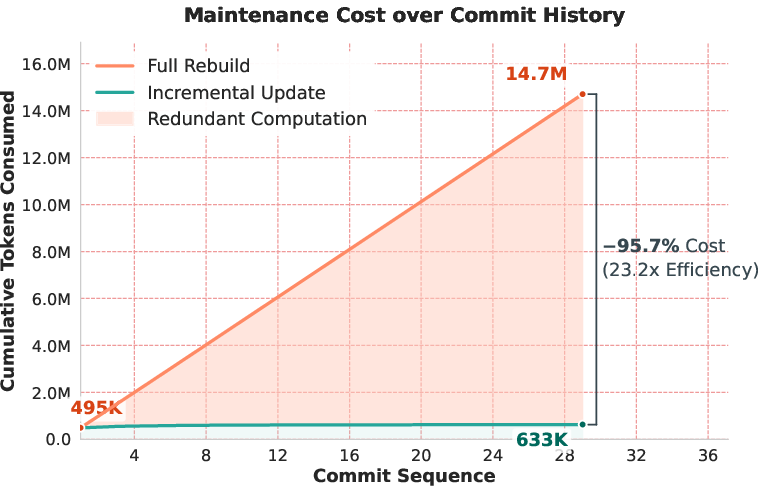
- Cheap updates: Incremental updates cut maintenance cost by about 95.7% compared to rebuilding the map each time.
- Fewer navigation mistakes: Because the map includes both meaning and structure, the AI avoids wandering aimlessly or missing important areas.
Why does this matter?
- Better code assistance: AI tools can pinpoint the exact file or function to change much faster, which means quicker bug fixes and feature work.
- Stronger documentation: The RPG map stays in sync with code and reduces the risk of “semantic drift” (when docs say one thing but the code does another).
- Easier onboarding: New developers (and AIs) can understand large projects more quickly with a map that shows both what things do and how they connect.
- Reliable generation: The same map that explains a project can also guide building or rebuilding it—helping “close the loop” from intent to implementation and back again.
In short, RPG-Encoder gives AI a unified, high-fidelity “city map” of codebases—combining clear descriptions with concrete connections—so it can understand, navigate, and build software more effectively.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper, to guide future research.
- Quantify semantic-lifting reliability: Measure the accuracy, variance, and failure modes of LLM-generated semantic features (e.g., hallucination rates, inter-run stability, sensitivity to prompt/seeding changes), and establish calibration/confidence scores for node semantics.
- Runtime-aware dependencies: Incorporate and evaluate dynamic/execution-time edges (reflection, dynamic imports, monkey-patching, metaprogramming, late binding, runtime configuration) beyond static AST; quantify gains vs. costs and failure cases.
- Language and ecosystem coverage: Validate RPG-Encoder on non-Python languages (C/C++ with macros/templates, Java/Kotlin with reflection, JavaScript/TypeScript with dynamic module systems, Rust with macros) and mixed-language monorepos; document AST coverage gaps and cross-language edge modeling.
- Build- and config-aware grounding: Extend artifact grounding to build systems and non-code assets (e.g., Bazel/CMake rules, package manifests, CI/CD files, schemas, DSLs, configs, resources), and study their impact on navigation and reconstruction fidelity.
- Cross-repo and external dependency modeling: Represent and evaluate edges that traverse repository boundaries (e.g., vendor libs, pip/npm crates, submodules), including version resolution and API evolution effects on RPG topology.
- Handling large-scale monorepos: Stress-test scalability (context limits, memory, wall-clock time, indexing/lookup costs) on very large repos; provide scaling laws and performance/cost trade-offs beyond token counts.
- Incremental evolution robustness: Evaluate the update protocol on complex real-world diffs (renames, file splits/merges, large refactors, API migrations), quantify misclassification rates of “intent shift,” and assess long-horizon drift over months/years of commits.
- Branching and merge semantics: Extend evolution beyond a single linear history to multi-branch workflows (rebases, merges, cherry-picks) and assess how divergent lines are reconciled into a consistent RPG.
- Topology stability metrics: Define and track stability/volatility metrics for the high-level hierarchy (e.g., node churn, centroid drift) under frequent small changes; investigate mechanisms for ontology versioning and hierarchical consistency.
- Edge weighting and uncertainty: Introduce confidence scores/weights for edges (both and ), assess how uncertainty-aware traversal affects localization and reconstruction.
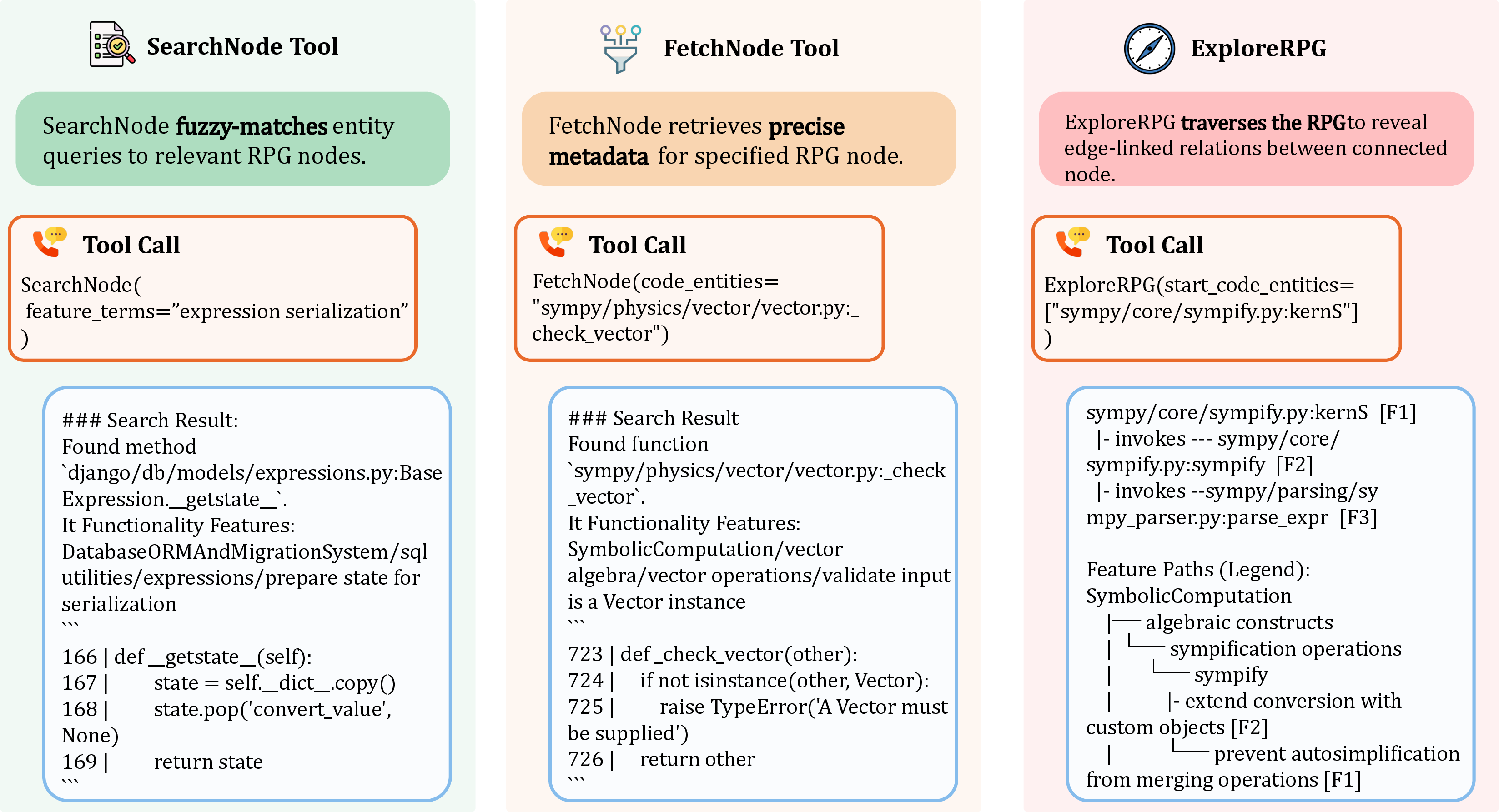
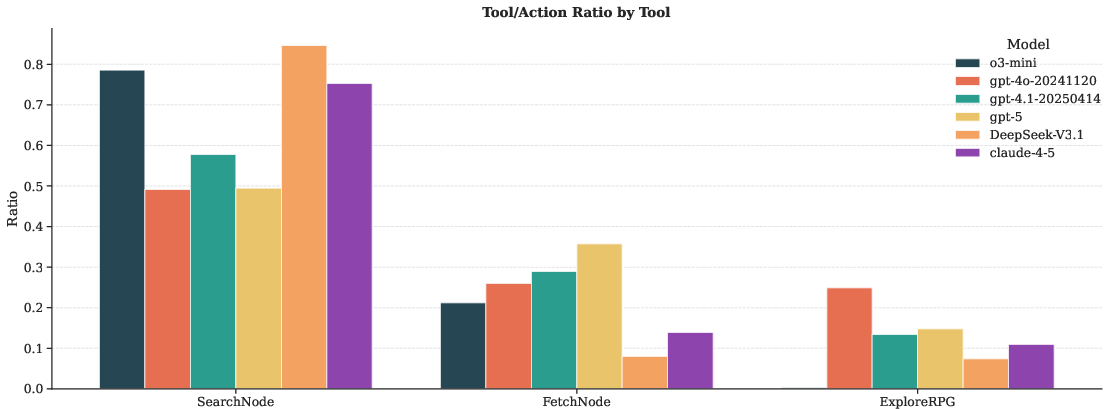
- Retrieval and ranking transparency: Specify and benchmark the retrieval mechanisms used in SearchNode (semantic embeddings, BM25, hybrid), their effect on Acc@k, and robustness to query formulation variability.
- Evaluation beyond localization: Demonstrate that improved Acc@k yields end-to-end gains in bug fixing/issue resolution (e.g., SWE-bench patch success), not just localization metrics; report full pipeline success rates and error propagation analysis.
- Reconstruction functional equivalence: Go beyond coverage and unit-test pass metrics to assess API compatibility, behavioral equivalence under randomized tests, performance regressions, and long-tail functional fidelity.
- Dependence on proprietary LLMs: Characterize performance with smaller or open-source models (e.g., Llama, CodeQwen, StarCoder2), and analyze sensitivity to backbone capability; report reproducibility with accessible models.
- Cost and runtime reporting: Provide wall-clock time, memory, and energy measurements for encoding, updates, and agent operation across repo sizes; compare against baselines beyond token counts and cost proxies.
- Data contamination controls: Strengthen contamination safeguards for reconstruction (e.g., with well-known libraries like scikit-learn) by ensuring models haven’t memorized targets; provide variants with custom/held-out projects.
- Ground-truth and annotation validity: Clarify function-level ground-truth construction and mapping across versions; assess annotation noise and report inter-annotator agreement for manual failure analyses.
- Robustness to poor/noisy code context: Study performance when code lacks docstrings/comments, uses obfuscation/minification, or includes generated code; test resilience to code formatting/style variability.
- Security and privacy implications: Analyze risks of extracting/serving RPGs for proprietary code (e.g., leakage of architecture/attack surfaces) and propose access controls or privacy-preserving encoding.
- IDE/dev workflow integration: Evaluate RPG-Encoder in real developer workflows (IDE plugins, code review, onboarding) with user studies measuring task time, quality, and subjective usability.
- Concurrency and stateful flows: Explore representations for concurrency primitives, asynchronous flows, shared state, and lifecycle sequencing (e.g., event-driven systems), potentially via dataflow/state-machine edges.
- Confidence-triggered interventions: Investigate policies for when to fall back from RPG-guided traversal to raw code search or dynamic tracing based on uncertainty thresholds, and measure net benefits.
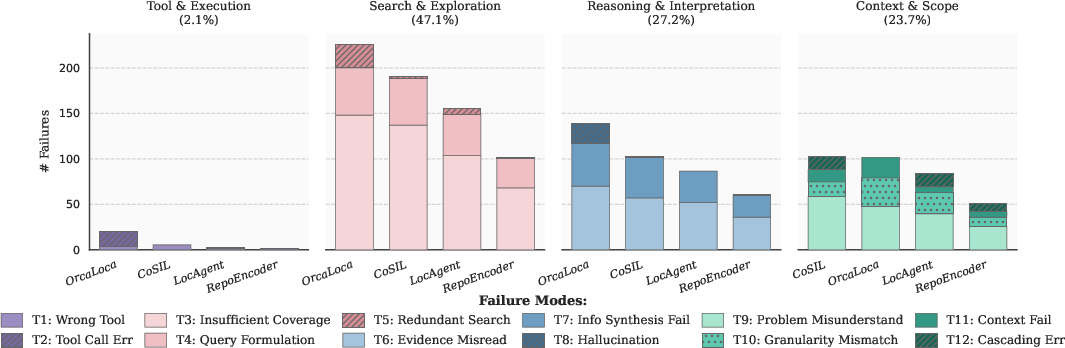
- Failure taxonomies at scale: Move beyond qualitative analysis of 100 failures to large-scale, statistically powered error taxonomies; publish standardized categories and shared datasets for comparative evaluation.
- Public release completeness: Ensure released code, prompts, and datasets (including RPG artifacts and evaluation scripts) are sufficient for end-to-end replication of encoding, evolution, and operation results.
Practical Applications
Below are practical, real-world applications that build on the paper’s unified, dual-view repository representation (RPG-Encoder), its structure-aware tooling (SearchNode, FetchNode, ExploreRPG), incremental evolution via commit diffs, and demonstrated gains in localization accuracy, reconstruction fidelity, and maintenance cost reduction.
Immediate Applications
- Structure-aware code navigation and search in IDEs — software
- Use case: Improve developer productivity by enabling intent-driven, function-level localization (e.g., “find the auth token validator” within large repos) leveraging RPG’s semantic features + dependency edges.
- Tools/products/workflows: VS Code/JetBrains plugin that exposes SearchNode/ExploreRPG as an indexed “architectural map,” with jump-to-definition across functional and dependency views; “Search-then-Zoom” guided tours for unfamiliar codebases.
- Assumptions/dependencies: Language support for AST parsing; continuous indexing of commits; local or cloud LLM access; acceptable token costs for large repos.
- CI/CD failure triage and blast-radius analysis — software
- Use case: Automatically pinpoint files/functions implicated in failing tests or breaking changes, and estimate downstream impact via dependency edges.
- Tools/products/workflows: GitHub Actions/GitLab CI integration to run incremental RPG-Encoder updates on diffs; auto-tagging of PRs with suspected modules; Acc@5-based candidate sets for reviewers.
- Assumptions/dependencies: Access to commit metadata and tests; reliable AST extraction; policy for automated annotations in PR pipelines.
- Architectural documentation synchronization — software, education
- Use case: Generate and maintain up-to-date architecture maps (functional hierarchy + code paths) that avoid semantic drift, reducing documentation maintenance overhead by ~95.7%.
- Tools/products/workflows: MkDocs/Docusaurus pipeline fed by RPG-Encoder; scheduled “Evolution” jobs per commit; export to Mermaid/PlantUML diagrams.
- Assumptions/dependencies: Stable mapping from function clusters to directories (LCA grounding); alignment with internal doc conventions.
- Semantically enriched SBOM (“SBOM++”) and security scanning — finance, healthcare, government
- Use case: Enhance software supply-chain security by coupling SBOM component lists with functional roles and internal call graphs, improving vulnerability prioritization and patch planning.
- Tools/products/workflows: SBOM generator that ingests RPG nodes/edges; security scanners that leverage dependency edges to rank exploitability and blast radius.
- Assumptions/dependencies: Package registries and license metadata; organizational policies for handling enriched code maps; secure storage of repository graphs.
- Dependency upgrade and migration planning — software
- Use case: Plan library upgrades or framework migrations by mapping import/call dependencies and identifying minimal change sets and high-risk modules.
- Tools/products/workflows: “Upgrade planner” that simulates impact via dependency subgraphs; guided refactor checklist; pre-merge reports.
- Assumptions/dependencies: Accurate dependency extraction; stable unit tests; model access for summarizing intent changes.
- Onboarding and knowledge transfer — software, education
- Use case: Accelerate onboarding by auto-generating guided walkthroughs from high-level pillars down to key files/functions, following the common “Search-then-Zoom” pattern observed in agent behavior.
- Tools/products/workflows: Interactive onboarding portal using ExploreRPG; role-based learning paths; code tours synced to commit history.
- Assumptions/dependencies: Repo indexing permissions; curated task “quests” for teams; consistent naming conventions.
- Code review assistance and reviewer selection — software
- Use case: Suggest relevant reviewers and contextual checks based on targeted functional nodes and their neighborhoods in the dependency graph.
- Tools/products/workflows: PR bot that annotates diffs with impacted modules; semantic intent shift detector to flag risky changes; review checklists aligned with RPG hierarchy.
- Assumptions/dependencies: Historical ownership/affinity metadata; commit message quality; integration with code-hosting APIs.
- Partial repository reconstruction for missing modules — software
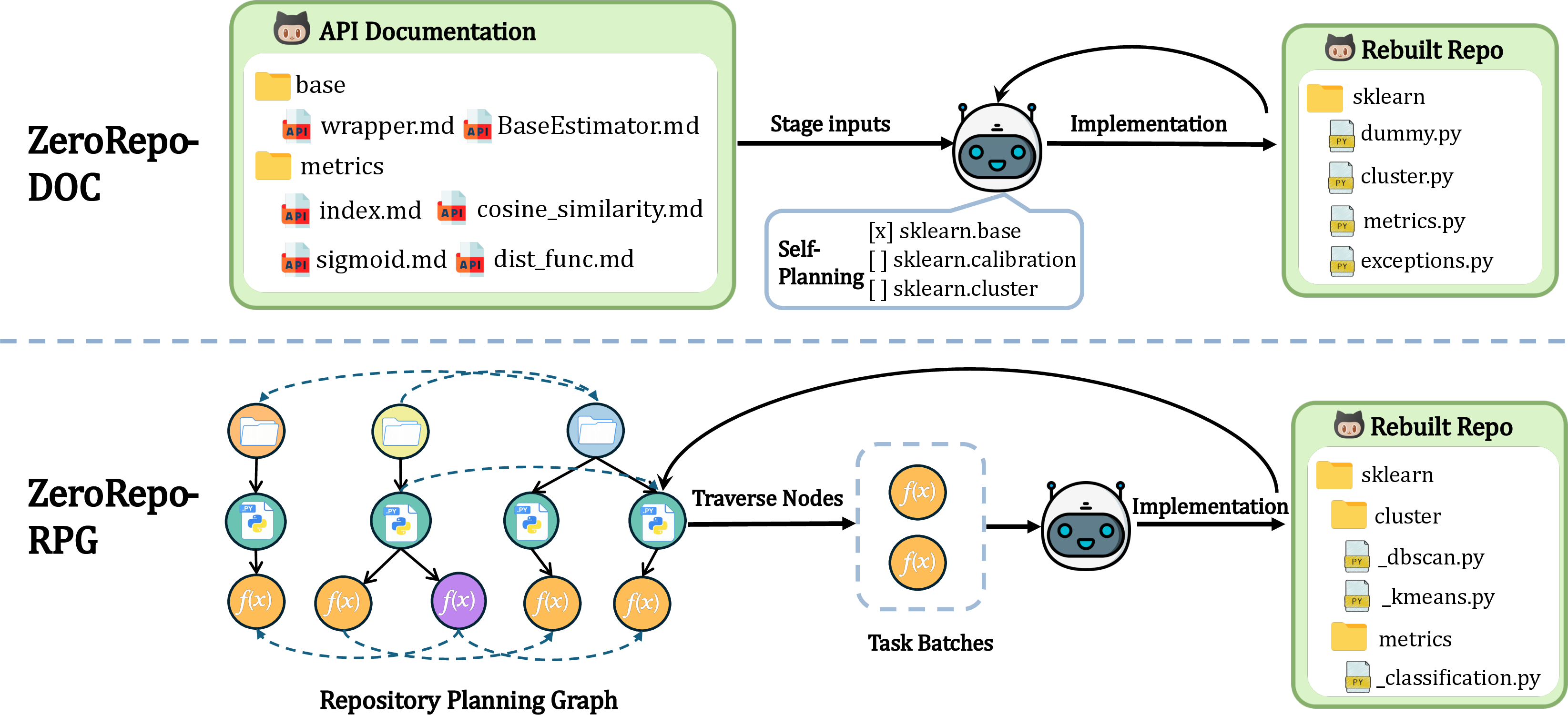
- Use case: Recover incomplete or corrupted components using RPG’s ordered blueprint (topological scheduling + semantically similar batching), shown to achieve high reconstruction coverage.
- Tools/products/workflows: “Rebuilder” mode of RPG-Encoder powering ZeroRepo-style generation; test-driven validation; pass/vote accuracy reporting.
- Assumptions/dependencies: Sufficient LLM generation capability; coverage and acceptance tests; guardrails for correctness.
- Multi-repo impact mapping in microservices — software, robotics, energy
- Use case: Trace changes across services (e.g., telemetry, control loops, data pipelines) by stitching service-level RPGs to a system-wide graph for safer deployments.
- Tools/products/workflows: Graph aggregator that normalizes per-repo RPGs; cross-service dependency routing for canary releases.
- Assumptions/dependencies: Service discovery metadata; access to multiple repositories; common schema for inter-repo edges.
- Internal developer search portal — software, enterprise IT
- Use case: Provide a unified, intent-first search across enterprise repos to find capabilities, not just strings, boosting reuse and reducing duplication.
- Tools/products/workflows: Managed “RPG Search” with semantic filters; code, docs, and design triage in one place.
- Assumptions/dependencies: Identity and access controls; consistent indexing cadence; compute budget for large code estates.
- Courseware for program comprehension — education, academia
- Use case: Teach layered architecture, modularity, and dependency management using real RPGs extracted from open-source or institutional repos.
- Tools/products/workflows: Instructor dashboards; student labs that navigate and modify target nodes; reproducible assignments aligned with SWE-bench-like tasks.
- Assumptions/dependencies: Licensing for educational use; curated datasets; sandboxed environments.
- Audit trail linking intent to implementation — policy, compliance
- Use case: Provide line-of-sight from functional intent to code artifacts for audits (e.g., SOX, HIPAA), with differential updates that preserve historical traceability.
- Tools/products/workflows: Compliance dashboard with per-commit RPG diffs; evidence export for regulators; change-impact reports.
- Assumptions/dependencies: Governance for storing code maps; retention policies; regulator acceptance of graph-based evidence.
Long-Term Applications
- Autonomous, closed-loop repo agents — software
- Use case: End-to-end agents that go from issue → localization → patch → test → deploy using RPG as memory, reducing steps and cost while improving success rates.
- Tools/products/workflows: “RPG-native” agents; safety sandboxes; continuous evaluation pipelines.
- Assumptions/dependencies: More reliable LLMs; robust guardrails; organizational readiness for partially autonomous changes.
- Standardization of RPG schema and interoperability — policy, software
- Use case: Industry-wide standard for dual-view repository graphs, complementing SBOM standards and enabling cross-tool interoperability.
- Tools/products/workflows: Open specification, reference parsers, validation suites; working groups with vendors and regulators.
- Assumptions/dependencies: Broad community adoption; alignment with existing standards (e.g., SPDX, CycloneDX); multi-language coverage.
- Architecture-aware code synthesis from high-level intents — software, academia
- Use case: Generate new repositories from specifications, papers, or RFCs, with RPG as a formal blueprint that preserves topology and semantics.
- Tools/products/workflows: “Paper-to-RPG-to-Code” pipelines; topological schedulers; structured evaluation benchmarks.
- Assumptions/dependencies: High-fidelity intent modeling; domain-specific ontologies; better long-horizon planning in LLMs.
- Continuous compliance and drift monitoring — finance, healthcare, government
- Use case: Monitor semantic drift and structural violations in real time; enforce architectural guardrails to stay within certified boundaries.
- Tools/products/workflows: Drift detectors on RPG diffs; compliance alerts tied to functional scopes; auditor-friendly timelines.
- Assumptions/dependencies: Persistent instrumentation; policy definitions encoded as graph constraints; regulator guidance.
- Automated refactoring and modernization planning — software, energy, robotics
- Use case: Propose modularization, dead-code removal, and dependency simplifications on legacy systems, minimizing operational risk.
- Tools/products/workflows: “Refactor planner” that simulates change impact; staged rollout plans; rollback-aware graph updates.
- Assumptions/dependencies: Rich static/dynamic signals; integration with build systems; cross-language parsers.
- Polyglot, universal repository representation — software
- Use case: Extend RPG-Encoder beyond Python to Java, C/C++, Rust, Go, JS/TS, enabling cross-language architectural analysis and unified enterprise search.
- Tools/products/workflows: Polyglot AST frontends; language adapters for metadata; normalization across idioms.
- Assumptions/dependencies: Mature parsers; shared abstraction layers; sustained engineering investment.
- Safety and hazard analysis for cyber-physical systems — robotics, energy, healthcare
- Use case: Map control-flow and dataflow paths to safety-critical components; support certification, FMEA, and formal verification workflows.
- Tools/products/workflows: Domain-specific safety layers on RPG; connectors to static analyzers and simulators; traceability to requirements.
- Assumptions/dependencies: Accurate extraction of real-time constraints; domain ontologies; regulator-grade evidence pipelines.
- Data lineage and model governance in MLOps — software, finance, healthcare
- Use case: Link code to data schemas, pipelines, and model artifacts; manage provenance, reproducibility, and risk across ML systems.
- Tools/products/workflows: Merge “code RPG” with “data/ML graphs”; lineage dashboards; policy enforcement (PII handling, fairness checks).
- Assumptions/dependencies: Access to data catalogs; model registries; schema metadata; cross-system connectors.
- Developer productivity SaaS with RPG-backed search and analytics — software
- Use case: Offer a hosted service that indexes enterprise repos, provides semantic search, impact analysis, and architecture insights.
- Tools/products/workflows: Managed ingestion and incremental updates; multi-tenant graph storage; analytics APIs.
- Assumptions/dependencies: Strong privacy and access controls; cost-effective scaling; customer-specific SLAs.
- Public-sector codebase modernization at scale — policy, government, education
- Use case: Inventory and analyze thousands of legacy repos, prioritize modernization, and track progress using standardized RPG reports.
- Tools/products/workflows: Portfolio dashboards; funding and procurement alignment; training programs using RPG-based curricula.
- Assumptions/dependencies: Open-data policies; procurement frameworks; workforce upskilling.
- Datasets and labels for training/evaluating code LLMs — academia
- Use case: Use RPGs as structured labels for repository-level reasoning tasks (localization, reconstruction, planning), enabling more representative benchmarks.
- Tools/products/workflows: Public corpora with RPG annotations; task generators derived from functional nodes/edges.
- Assumptions/dependencies: Licensing and de-identification; community curation; standardized metrics.
- Marketplace of RPG blueprints and reusable architectural patterns — software
- Use case: Share and reuse validated, topology-preserving designs (e.g., auth modules, data pipelines) across organizations.
- Tools/products/workflows: Pattern repositories; compatibility checkers; versioned graph artifacts.
- Assumptions/dependencies: IP and licensing frameworks; code-to-blueprint mapping quality; governance of shared artifacts.
Glossary
- Acc@k: Accuracy at top-k; a metric indicating whether the correct target appears within the top k predictions. "Acc@k () checks if a ground-truth target is in top- predictions"
- Abstract Syntax Tree (AST) analysis: Program analysis over the tree representation of source code to extract structural relationships (e.g., imports, calls). "via AST analysis."
- Agentic Tool: A tool interface enabling autonomous agents to operate on repository representations for search, fetch, and exploration. "Unified Agentic Tool"
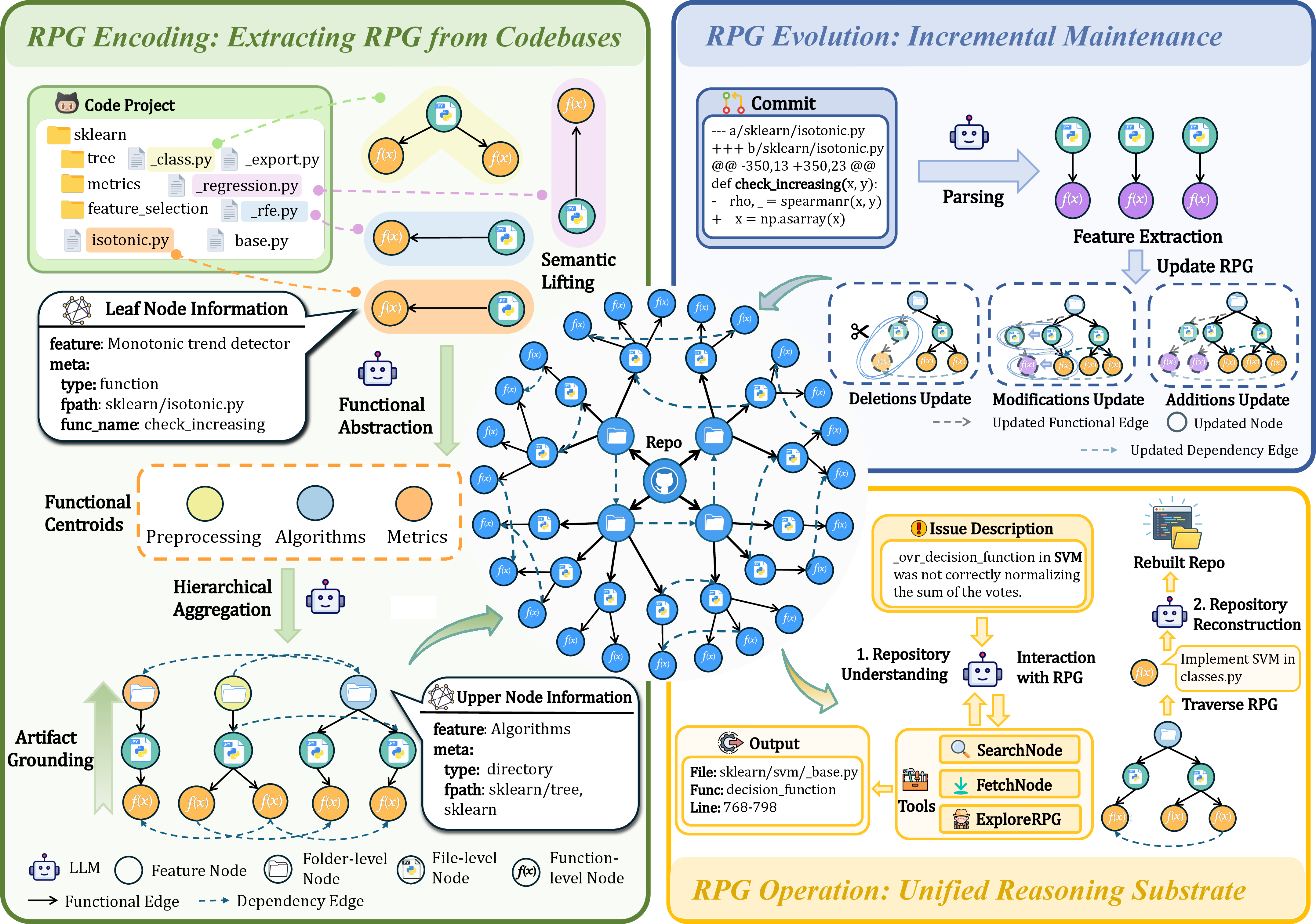
- Artifact Grounding: The process of anchoring abstract functional structures to concrete code artifacts and execution logic. "Phase 3: Artifact Grounding"
- Commit-level feature extraction: Parsing only affected changes in a commit to produce semantic feature nodes for incremental graph updates. "Commit-Level Feature Extraction"
- Coverage: The proportion of functional categories implemented or reconstructed in a target repository. "Coverage, the proportion of implemented functional categories;"
- Dependency edges: Edges in the graph that capture logical code interactions (e.g., imports, calls). "Dependency edges $\mathcal{E}_{\text{dep}$ mapping logical interactions including imports and calls."
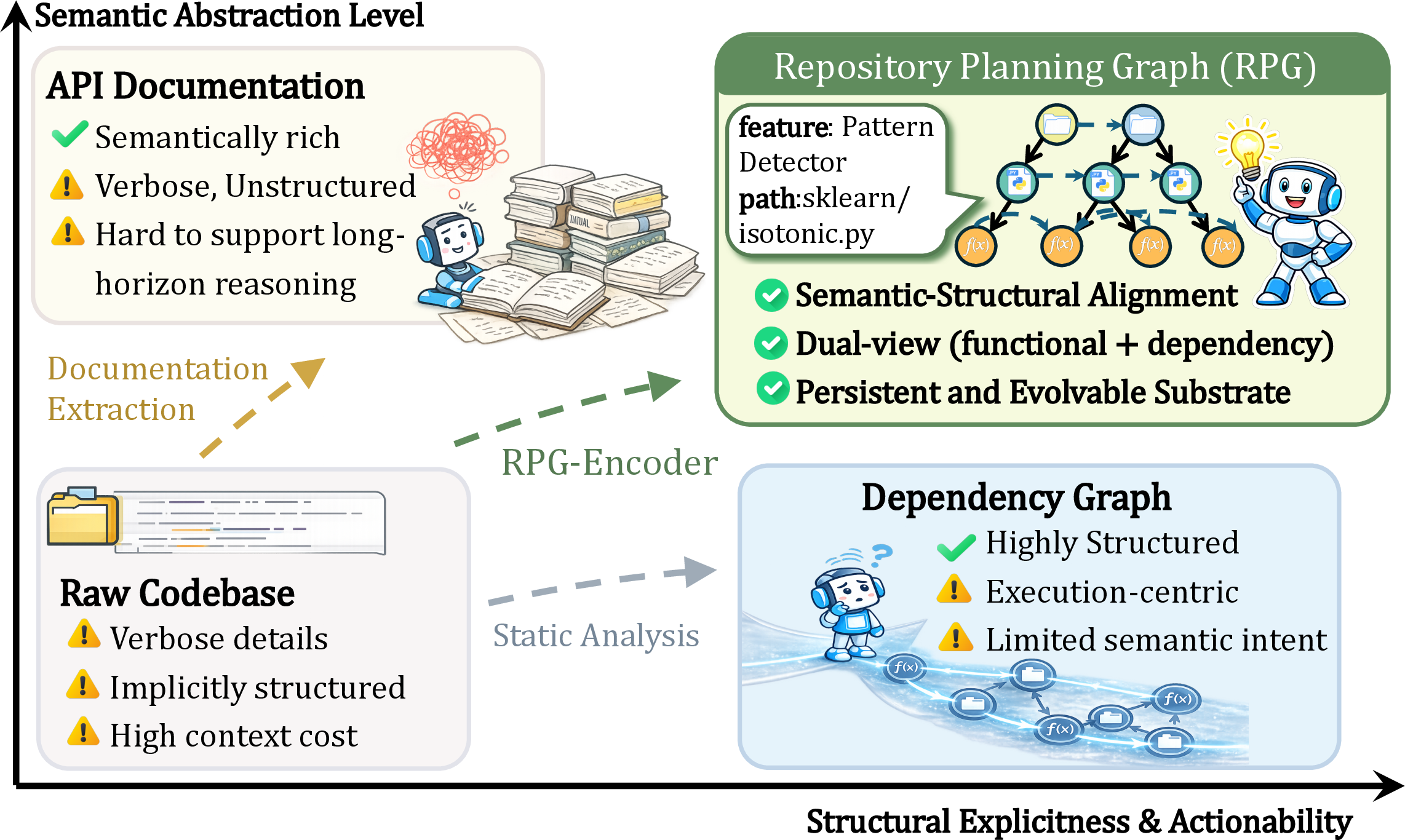
- Dependency Graph: A structural representation focusing on code-level dependencies among modules or functions. "Dependency Graph captures structural logic"
- Delta state: The set of changes derived from commits that represent the updated portion of the repository. "representing the delta state"
- Differential updates: Update strategy that applies only changes rather than rebuilding the entire representation to reduce maintenance cost. "supports sustainable evolution via differential updates, decoupling maintenance costs from repository scale."
- Functional Abstraction: A compression strategy to derive high-level functional categories from file-level semantics for global reasoning. "Functional Abstraction: To ensure the global repository state fits within the LLM context window, we perform granularity-based input compression."
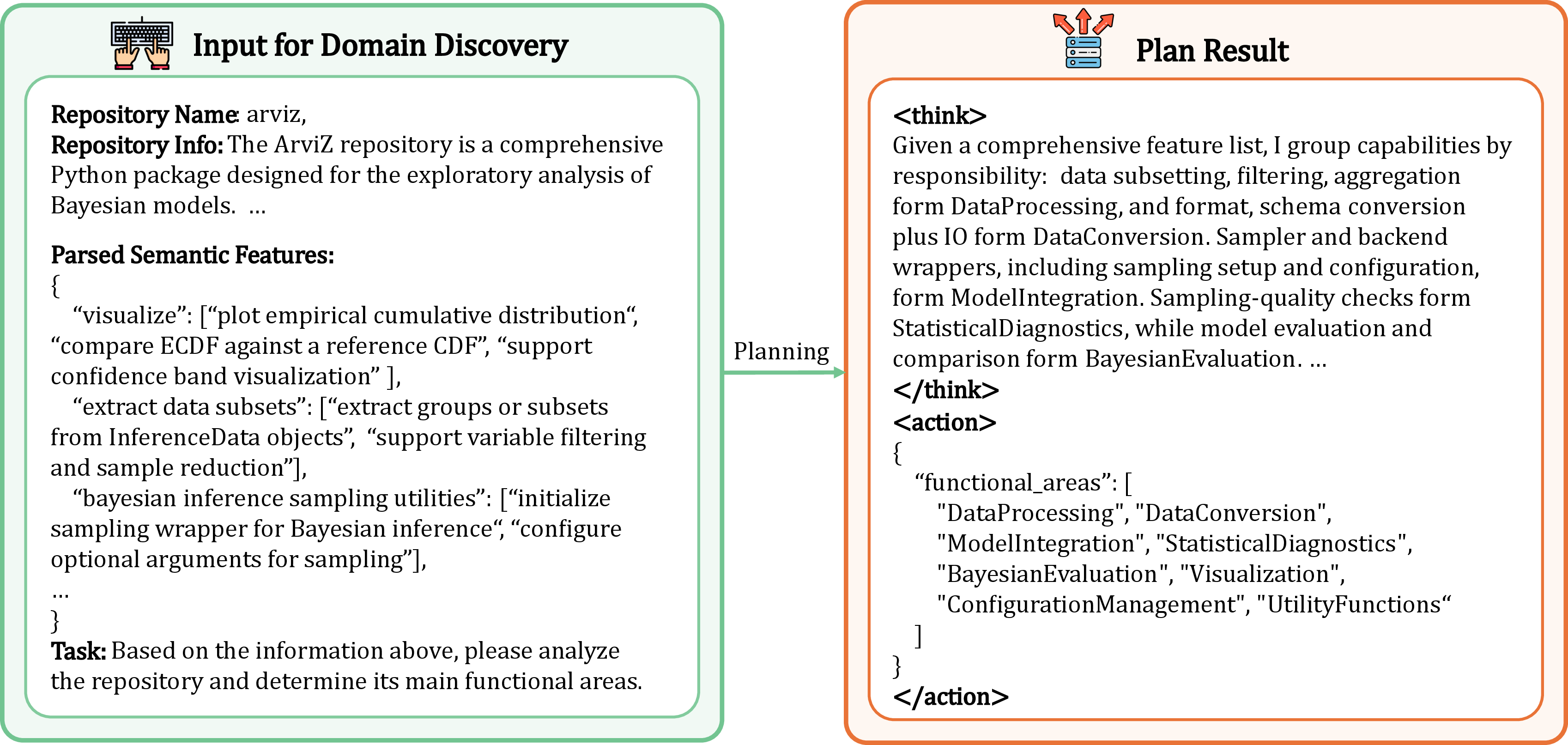
- Functional centroid: An induced abstract node representing a high-level functional category that aggregates related implementation units. "abstract functional centroids (e.g., Data Preprocessing)"
- Functional edges: Edges that establish hierarchical, intent-driven relationships among nodes in the functional view. "Functional edges $\mathcal{E}_{\text{feature}$ establishing teleological hierarchy;"
- Functional manifold: The abstract space of functional intent that is later grounded to concrete code artifacts. "anchors the functional manifold to physical artifacts and execution logic."
- Granularity-based input compression: Reducing input detail to fit global repository semantics in limited context windows. "we perform granularity-based input compression."
- Heterogeneous graph: A graph that integrates multiple edge types and views (functional and dependency) over a shared node set. "Structurally, it functions as a heterogeneous graph"
- Hierarchical Aggregation: The process of recursively linking low-level nodes to high-level centroids to form a stable functional hierarchy. "Hierarchical Aggregation: We recursively link nodes from to these centroids."
- High-fidelity representation: A representation that preserves semantics and structure closely enough to reconstruct or mirror the original repository. "into a unified, high-fidelity representation."
- Incremental maintenance: Maintaining the representation by applying small updates over time rather than full re-generation. "RPG Evolution: Incremental Maintenance"
- LLM context window: The maximum input length an LLM can process at once, influencing representation compression. "fits within the LLM context window"
- Lowest Common Ancestor (LCA): A mechanism to compute the minimal directory scope shared by descendants to ground abstract nodes to paths. "utilizing a Lowest Common Ancestor (LCA) mechanism"
- Navigational substrate: A representation that serves as the underlying map for agents to localize and traverse codebases. "We assess RPG as a navigational substrate through rigorous localization tasks."
- nLOC: Number of lines of code; a structural size metric of generated or original repositories. "nLOC "
- Pass Rate: The percentage of unit tests passed, measuring functional correctness in reconstruction or generation. "reduces the Pass Rate from 82.8\% to 74.1\%"
- Precision/Recall: Standard retrieval metrics measuring correctness and completeness of predicted sets. "Precision/Recall quantify overlap."
- RepoCraft: A benchmark for controlled reconstruction of repositories to evaluate representational fidelity. "We adapt RepoCraft"
- Repository Planning Graph (RPG): A hierarchical, dual-view graph representation coupling semantic features with dependencies for intent-to-code and code-to-intent. "Repository Planning Graph (RPG)"
- RPG-Encoder: A framework that extracts, evolves, and operates RPGs from existing repositories to close the reasoning loop. "RPG-Encoder closes the reasoning loop"
- Semantic compatibility check: An LLM-evaluated criterion to determine whether a node’s semantics fit within its parent centroid’s scope. "a semantic compatibility check: the LLM evaluates the fit between a nodeâs and the centroidâs definition"
- Semantic drift: Gradual divergence between documentation semantics and actual implementation over time. "documentation is prone to semantic drift"
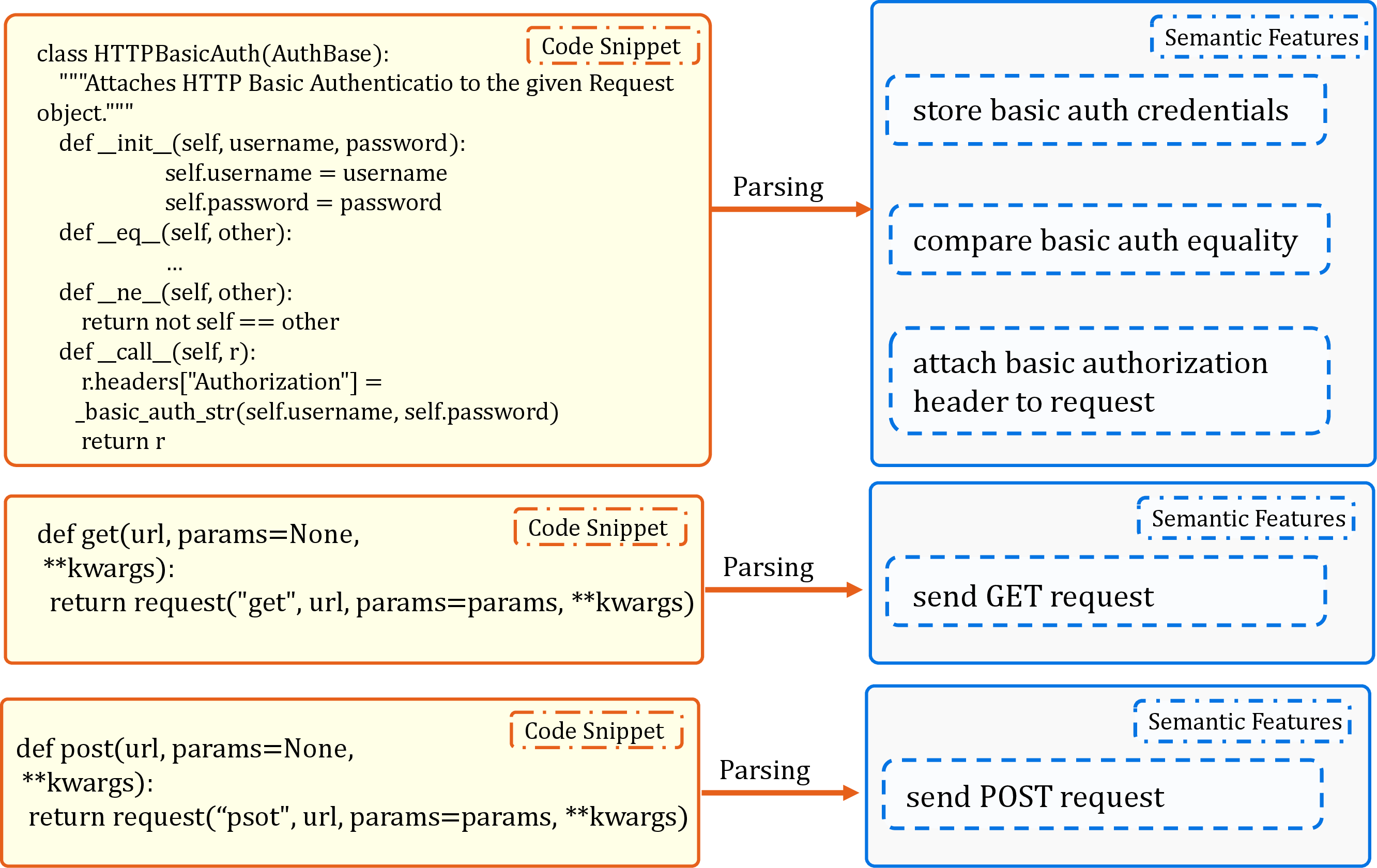
- Semantic features: Concise functional descriptions extracted from code entities used for retrieval and hierarchy building. "semantic features describing functionality"
- Semantic lifting: Protocol to project raw code into higher-level semantic representations used in the RPG. "We introduce a semantic lifting protocol"
- Semantic manifold: The global semantic space of the repository that the LLM analyzes to induce abstract categories. "the complete repository-wide semantic manifold"
- Semantic threshold: A criterion ensuring structural updates occur only when functional intent shifts beyond a parent’s scope. "This check serves as a semantic threshold"
- Static dependencies: Non-runtime, code-level relationships (imports, calls) derived from static analysis. "static dependencies"
- Structure-aware navigation: Navigation that leverages known graph structure (functional and dependency views) to guide exploration. "Operating as a unified interface for structure-aware navigation."
- SWE-bench Live Lite: A benchmark using recent issues to mitigate contamination when evaluating repository understanding. "SWE-bench Live Lite"
- SWE-bench Verified: A human-validated subset of issues ensuring solvability for evaluating repository understanding. "SWE-bench Verified"
- Teleological hierarchy: A goal-oriented functional hierarchy establishing purpose-driven relationships among components. "establishing teleological hierarchy"
- Topological constraints: Structural ordering and graph connectivity conditions that guide reconstruction and reasoning. "Guided by topological constraints"
- Topological order: An execution or processing sequence consistent with dependency directions in the graph. "Nodes are processed in topological order"
- Topological skeleton: A robust structural backbone that guides traversal through complex execution flows. "provides a robust topological skeleton"
- Unified Intermediate Representation: A single representation that fuses semantic documentation density with dependency graph rigor. "a unified Intermediate Representation"
- Unified Reasoning Substrate: The operational layer exposing tools and views for agents to query and traverse the RPG. "RPG Operation: Unified Reasoning Substrate"
Collections
Sign up for free to add this paper to one or more collections.