SERA: Soft-Verified Efficient Repository Agents
Abstract: Open-weight coding agents should hold a fundamental advantage over closed-source systems: they can be specialized to private codebases, encoding repository-specific information directly in their weights. Yet the cost and complexity of training has kept this advantage theoretical. We show it is now practical. We present Soft-Verified Efficient Repository Agents (SERA), an efficient method for training coding agents that enables the rapid and cheap creation of agents specialized to private codebases. Using only supervised finetuning (SFT), SERA achieves state-of-the-art results among fully open-source (open data, method, code) models while matching the performance of frontier open-weight models like Devstral-Small-2. Creating SERA models is 26x cheaper than reinforcement learning and 57x cheaper than previous synthetic data methods to reach equivalent performance. Our method, Soft Verified Generation (SVG), generates thousands of trajectories from a single code repository. Combined with cost-efficiency, this enables specialization to private codebases. Beyond repository specialization, we apply SVG to a larger corpus of codebases, generating over 200,000 synthetic trajectories. We use this dataset to provide detailed analysis of scaling laws, ablations, and confounding factors for training coding agents. Overall, we believe our work will greatly accelerate research on open coding agents and showcase the advantage of open-source models that can specialize to private codebases. We release SERA as the first model in Ai2's Open Coding Agents series, along with all our code, data, and Claude Code integration to support the research community.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces SERA, a way to train “coding agents” (AI helpers that read and edit code) so they become really good at working on specific codebases, including private ones. The key idea is to make training cheap and simple while still getting top performance. The authors show that you don’t need complicated tests or expensive training tricks to build strong coding agents—you can use a simpler method called Soft Verified Generation (SVG) that works across many repositories and scales well.
What are the main questions the paper tries to answer?
The paper focuses on a few clear goals:
- Can we train open-source coding agents to be as strong as popular closed or open-weight systems, but at much lower cost?
- Can we specialize a model to one codebase (like Django) so it does better there than a general model?
- Do we really need full unit tests to verify training data, or can “soft” checks be enough?
- Do vague, realistic instructions (not just bug fixes) help make the agent more useful?
How did the researchers do it? (Explained simply)
Think of training a coding agent like teaching a student with a workbook:
- The “teacher model” creates example solutions and explanations.
- The “student model” learns by copying the teacher’s steps and style.
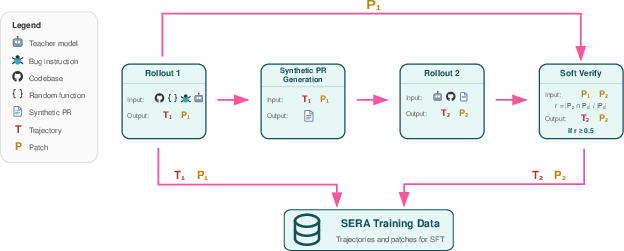
But instead of building fake bugs and checking them with unit tests (which is slow and complicated), they use a simpler setup called Soft Verified Generation (SVG):
- First rollout: The teacher is told to make some change starting from a random function in a real codebase. The instruction is intentionally vague (like “improve clarity” or “fix state handling”), not a strict “this test fails” bug. The teacher produces a step-by-step “trajectory” (its actions and thoughts) and a “patch” (the actual line-by-line code changes).
- Make a synthetic pull request: The teacher turns that trajectory into a clear pull request description, like a short document explaining what changed and why.
- Second rollout: The teacher tries to reproduce the same patch using only the pull request description. This checks whether the PR description is good enough to lead to similar changes.
- Soft verification: Instead of running unit tests, they compare the two patches line-by-line. If most lines match, it’s a good training example. Think of it like comparing two essays: they don’t have to be identical, but if most sentences align, it’s probably correct enough for learning.
Important terms in everyday language:
- Repository: a folder of code for a project (like a library or website) stored in a place like GitHub.
- Trajectory: the step-by-step path the agent took: what it read, what it changed, and why.
- Patch: the final set of changes (additions and deletions) to files.
- Pull request (PR): a written explanation of a change, asking to merge it into the codebase.
- Context length: how much text the model can “remember” at once, like the size of its working memory.
They used widely available tools:
- A general agent scaffold (SWE-agent) that lets the model view files, edit code, and run commands.
- A strong teacher model (GLM-4.5-Air or GLM-4.6) to generate examples.
- A student base model (Qwen 3-32B) that learns from those examples with standard supervised fine-tuning.
What did they find, and why does it matter?
Here are the key results and what they mean:
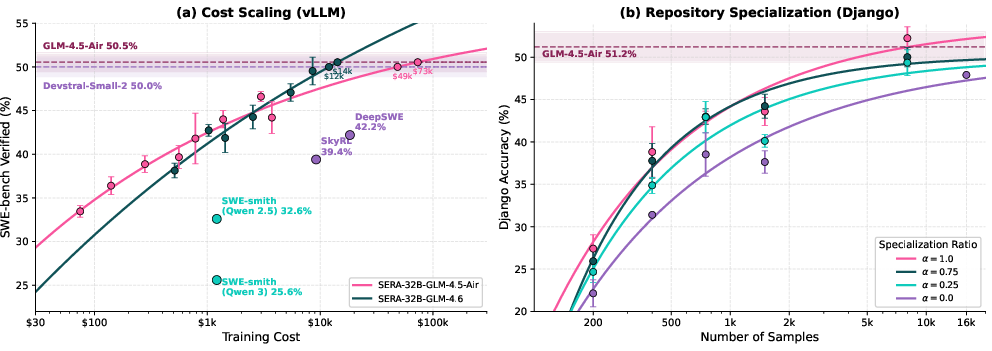
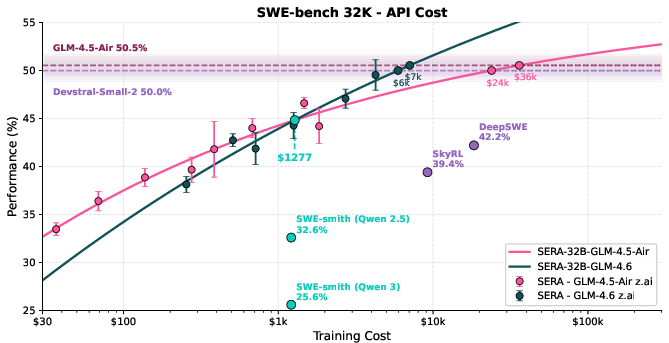
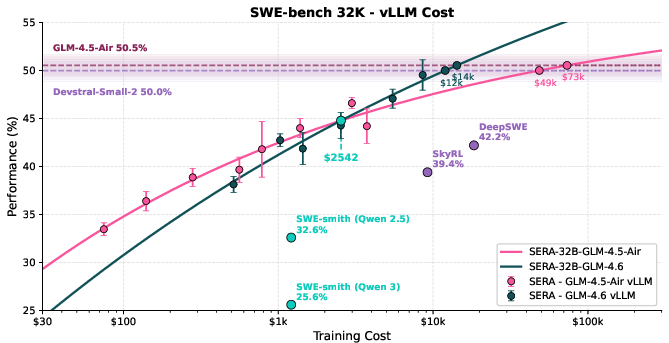
- Strong performance with simple training: Their 32B model (SERA-32B) reaches 49.5% at 32K context and 54.2% at 64K context on SWE-bench Verified, which is state-of-the-art among fully open-source setups. It matches strong open-weight models, despite being trained without reinforcement learning.
- Much cheaper training: Reaching similar performance is about 26 times cheaper than reinforcement learning and about 57 times cheaper than older synthetic data pipelines that rely on unit tests. That means small teams can build powerful agents without huge budgets.
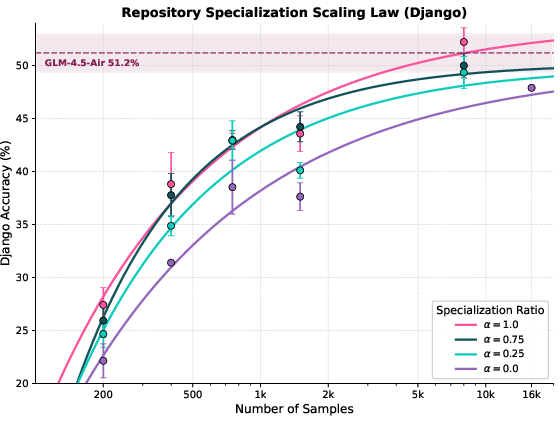
- Specialization works really well: When they focus on one big repository (like Django), a student model trained with ~8,000 examples matches or even beats the teacher model on that repo. Why? Because the student “learns the house style” and quirks of that codebase in its weights, while the teacher only sees the code temporarily in its context window.
- Vague instructions help: Training on broader, realistic changes (like refactoring, style improvement, docs) is as helpful as bug-fix-only data. This makes the agent more practical for everyday coding tasks, not just fixing tests.
- Soft verification is enough: Comparing patches line-by-line works as well as full unit test checks for creating good training data at scale. That removes the need for test setups and makes it possible to learn from almost any repository.
What’s the bigger impact?
- Democratizing coding agents: Because this approach is cheap and simple, smaller teams and open-source communities can build high-quality, specialized coding agents without massive infrastructure.
- Private code advantage: Companies can train agents tailored to their own private codebases and deploy quickly—no need to share code or wait for large labs to include their data in the next big model.
- Faster iteration: Since you don’t need unit tests to verify data, you can generate a lot of training examples from any repository and retrain as your code evolves.
- Better real-world usefulness: Agents trained on vague, realistic instructions become helpful for everyday tasks like refactoring, documenting, and enforcing code style, not just test-driven bug fixes.
In short, SERA shows that you can build strong, specialized coding agents using simple, scalable methods. That makes powerful AI coding tools more accessible, adaptable, and practical for both open-source projects and private teams. The authors also release their models, code, and over 200,000 synthetic training trajectories to help the research community keep improving these agents.
Knowledge Gaps
Knowledge Gaps, Limitations, and Open Questions
The paper presents a novel method for training coding agents, yet several gaps and limitations remain unaddressed, offering fruitful directions for future research:
- Effect of Context Length Scaling: The impact of increasing context length beyond 64K on model performance and efficiency is not fully explored. Future research could investigate optimization strategies for handling longer contexts efficiently.
- Generalizability Across Programming Languages: While the method is demonstrated on Python, extending the approach to other programming languages and assessing the generalizability of the training method across diverse coding environments remain unexplored.
- Real-World Deployment Challenges: The paper does not address the challenges of deploying these models in real-world development environments, such as integration into existing workflows or handling of dynamic and non-static codebases.
- Ethical and Privacy Considerations: The paper does not elaborate on ethical concerns or privacy implications when specializing models to private codebases, an area that requires more attention given the sensitivities around proprietary code.
- Comparative Analysis with Other Methods: A comprehensive comparison with other state-of-the-art methods beyond sample size, such as qualitative behavior and error analysis in synthetic data generation, can provide deeper insights into the advantages and limitations.
- Long-term Maintenance of Specialized Models: The paper specifies the training advantages of specialization but does not discuss the overhead or strategies for maintaining and updating these models as codebases evolve.
- Impact of Vague Instructions: While vague instructions are noted to diversify training data, the paper does not thoroughly analyze their effect on the model's ability to understand and execute precise coding tasks.
- Evaluation on Comprehensive Benchmarks: Although SWE-bench Verified is used, additional evaluations using other comprehensive and varied benchmarks would strengthen the validation of the method's effectiveness.
- Robustness to Codebase Size and Structure Changes: How well the method adapts to changes in the size and structure of the codebase over time is not detailed and could be crucial for long-term viability.
- Scalability of Data Generation: The scalability of data generation in larger codebases or distributed systems environments is not explored, which could influence adoption in larger enterprise settings.
These identified gaps provide a roadmap for subsequent research to enhance the utility and applicability of the proposed training method for coding agents.
Glossary
- Ablation: An experimental analysis where specific components or factors are removed or varied to measure their impact. "we provide extensive analyses covering ablations on data quality factors, model-specific pitfalls, and common confounding factors"
- Agent scaffold: The structured environment and tool interface that defines how a coding agent interacts with files, commands, and the task. "Coding agents operate through scaffolds that define the tools available to the agent and how it interacts with the environment."
- Bug injection: Programmatically introducing faults into a codebase to create synthetic issues for training and evaluation. "The standard approach, exemplified by SWE-smith, generates training data through bug injection."
- Bug-injection pipeline: A systematic process for creating, describing, and verifying synthetic bugs for data generation. "generating effective training data requires neither test infrastructure nor complex bug-injection pipelines."
- Context length: The maximum number of tokens a model can consider at once, affecting memory and performance. "Context length has a significant impact on memory footprint, even among models of equal sizes."
- Context window: The portion of input a model can attend to at inference, constraining accessible information. "a teacher that accesses the same codebase only through its context window."
- Docker container: A portable, isolated environment used to encapsulate and run codebases consistently for experiments. "Each codebase is encapsulated inside of a docker container."
- Distributed training infrastructure: Coordinated multi-machine systems used to scale model training and online rollouts. "Reinforcement learning requires sandboxed execution environments, distributed training infrastructure, and rollout orchestration."
- Frontier model: The most advanced, large-scale models at the cutting edge of capability. "until the next training run of a frontier model includes their data."
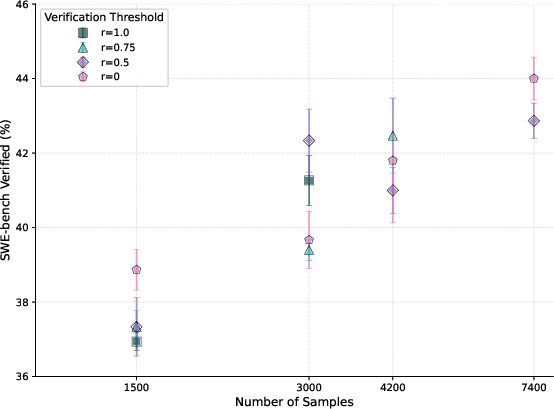
- Hard verification: A strict validation where the reproduced patch fully matches the reference or passes all tests. "If r = 1, the trajectory is hard-verified; if 0 < r < 1, soft-verified; if r = 0, unverified."
- Key-value cache invalidation: Losing cached attention states during inference, which increases computation cost. "such optimizations cause key-value cache invalidation during inference"
- Line-level recall: A patch comparison metric measuring the fraction of reference edit lines reproduced by a generated patch. "Soft verification compares the two patches using line-level recall for training data selection."
- LoRA adapter: A parameter-efficient fine-tuning technique that adds low-rank matrices to adapt large models. "And while LoRA adapter options for frontier models exist these are often to impractical or costly for large-scale deployments."
- Open-weight model: A model whose parameters are available for users to fine-tune and deploy, enabling private specialization. "open-weight models should hold a fundamental advantage in many applications because they can be specialized to private codebases"
- Patch: The final diff output specifying line-level additions and deletions to fix or change code. "A patch is the final output: a line-by-line diff specifying additions and deletions to the codebase."
- Pull request (PR): A structured change proposal for a repository, typically including description, rationale, and code edits. "This trajectory is converted into a synthetic pull request."
- Repository specialization: Tailoring a model to a specific codebase so its weights encode repository-specific conventions and patterns. "The resulting cost reduction and data abundance make repository specialization practical."
- Reward shaping: Modifying the reward signal in reinforcement learning to stabilize or accelerate training. "training runs sensitive to hyperparameters, reward shaping, and random seeds"
- Rollout: A complete agent execution on a task from initial input to submitting a solution. "A rollout is one complete execution of the agent on a task, from receiving the issue to submitting a solution."
- Sandboxed execution environments: Isolated runtime contexts that safely execute code and tests during training or evaluation. "Reinforcement learning requires sandboxed execution environments, distributed training infrastructure, and rollout orchestration."
- Sample efficiency: The amount of performance gained per unit of training data, measured by how few samples are needed to reach a target. "a 3.5× advantage in sample efficiency."
- Scaling law: An empirical relationship modeling how performance changes with data, compute, or parameters. "We use this dataset to provide detailed analysis of scaling laws, ablations, and confounding factors"
- Self-hosted inference: Running model inference on local or owned hardware rather than via external APIs. "Scaling and cost comparison of coding agent training approaches using self-hosted vLLM inference."
- Self-play: A training paradigm where a model iteratively improves by generating its own challenges and solutions. "The advantage is that a strong model can continue to improve through self-play, since it is not bounded by a separate teacher's capabilities."
- Soft verification: A lightweight validation that checks patch overlap with a reference rather than executing unit tests. "Our method introduces soft verification: instead of executing tests, we compare the generated patch against a reference patch using line-level recall."
- Supervised finetuning (SFT): Training a model on labeled trajectories or instructions to improve task performance. "Using only supervised finetuning (SFT)"
- SWE-agent: A coding agent framework providing tools for file viewing, editing, and command execution on SWE-bench tasks. "SWE-agent is a widely used scaffold that provides tools for viewing files, editing code, and executing bash commands."
- SWE-bench Verified: A curated benchmark subset where tasks are solvable and tests reliably validate solutions. "SWE-bench Verified is a curated subset where human annotators have verified that each task is solvable and that the tests correctly validate the solution."
- Synthetic data generation: Creating training trajectories by having a strong model solve artificial tasks programmatically. "Synthetic data generation creates trajectories by having a strong teacher model solve synthetic tasks"
- Teacher model: A stronger model used to generate or verify trajectories for training a student model. "We use GLM-4.5-Air as our teacher model for all experiments unless otherwise specified."
- Teacher-student distillation: Transferring capability from a stronger model to a weaker one via generated training data. "This teacher-student distillation approach separates data generation from training, allowing each to be optimized independently."
- Tool calling: The model’s ability to emit correctly formatted actions that invoke tools within an agent scaffold. "coding agents rely heavily on tool calling: if a model cannot reliably follow the tool format and produce valid tool calls, it cannot function as a coding agent regardless of its other capabilities."
- Trajectory: The ordered sequence of actions, observations, and reasoning produced during an agent rollout. "The sequence of actions, observations, and reasoning produced during a rollout is called a trajectory."
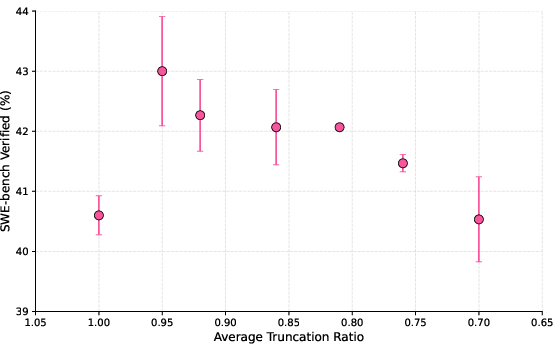
- Truncation ratio: The proportion of trajectory steps retained within the context limit when selectively shortening long trajectories. "we term this ``truncation ratio''."
- Unit test verification: Validating that a patch fixes targeted issues by ensuring all relevant tests pass without regressions. "Traditional approaches use unit test verification: the patch must pass all relevant tests, confirming that the synthetic bug was correctly resolved."
- Verification threshold: A cutoff on the recall metric used to decide whether a trajectory is accepted as verified. "We use r ≥ 0.5 as an example threshold."
- vLLM: An inference system optimized for serving LLMs efficiently. "we primarily use axolotl for training and vLLM for model hosting."
Practical Applications
Immediate Applications
The following items summarize concrete, deployable uses that can be implemented with the paper’s method and assets right away, along with sector linkage and feasibility notes.
- Repository-specialized coding assistants for private codebases
- Sector: Software, Finance, Healthcare IT, Robotics, Energy
- Tools/products/workflows: Fine-tune a SERA-style agent on an internal repo to get code-aware assistance (navigation, targeted edits, PR drafting) that outperforms general-purpose models on that repo. Integrate into editors (VS Code, JetBrains) and terminals using SWE-agent scaffolds.
- Assumptions/dependencies: Access to GPUs (or a managed service) for supervised finetuning; a capable teacher model for data generation (e.g., GLM-4.5-Air or GLM-4.6); Dockerized repositories; reliable long-context inference (32K+) and tool-calling fidelity.
- CI/CD “PR-CoPilot” that proposes patches and refactors without unit tests
- Sector: DevOps, Software
- Tools/products/workflows: Use Soft Verified Generation (SVG) to synthesize thousands of trajectories from the repo and fine-tune a CI bot to propose diffs for small bugs, style enforcement, documentation updates, and refactors—even where test coverage is low. Gate by soft-verification similarity thresholds and human code review.
- Assumptions/dependencies: Soft verification thresholds calibrated per repo; maintainers to review patches; safeguards against destructive changes; context-length compatibility with CI runners.
- Large-scale synthetic PR generation for training and onboarding
- Sector: Software, Education
- Tools/products/workflows: Generate synthetic PRs and associated trajectories to create internal training data for junior engineers or to bootstrap internal code assistants. Use SVG’s vague instructions to diversify examples beyond bug fixes (e.g., modernization, readability, docstrings).
- Assumptions/dependencies: Quality and diversity of bug/refactor prompts; reproducible tool scaffolds (SWE-agent settings); deduplication and filtering to avoid noisy trajectories.
- Cost-effective agent development for small teams
- Sector: Startups, Academia, Open-source projects
- Tools/products/workflows: Adopt SERA’s SFT-only pipeline to avoid RL infrastructure. Self-host teacher inference via vLLM or use low-cost APIs; iterate quickly with the 26x–57x cost reduction over RL and prior synthetic pipelines to reach competitive performance.
- Assumptions/dependencies: Accurate cost modeling (GPU vs API); stability of teacher model APIs; sufficient compute to fine-tune Qwen 3-32B or smaller variants.
- Domain-focused assistants for regulated environments
- Sector: Finance, Healthcare IT, Energy
- Tools/products/workflows: Train repo-specialized agents locally to avoid moving proprietary code to third-party providers. Use soft verification to generate data from systems with limited tests, then gate deployment with human-in-the-loop checks and audit logs.
- Assumptions/dependencies: Compliance processes (PII/PHI handling, auditability); legal review of training data sources; alignment with internal security and governance.
- Automated refactoring campaigns and code quality sweeps
- Sector: Software, Robotics (ROS stacks), Embedded systems
- Tools/products/workflows: Run periodic refactor agents specialized on target codebases to fix style, deprecations, doc gaps, and minor code smells. Use SVG-generated data to optimize agent behavior for the codebase’s conventions.
- Assumptions/dependencies: Clear coding standards; code-owner approvals; limits on patch scope to reduce merge conflicts.
- Repository-aware documentation assistants
- Sector: Software, Education
- Tools/products/workflows: Fine-tune agents to produce docstrings, README updates, and architecture notes that reflect repository-specific patterns learned in weights. Integrate into doc workflows (Sphinx/Docusaurus).
- Assumptions/dependencies: Access to representative code snapshots; review processes to ensure factual accuracy; multilingual doc needs if applicable.
- Research and teaching with open datasets and reproducible pipelines
- Sector: Academia, Open-source community
- Tools/products/workflows: Use the released 200k+ trajectories, code, and models to study scaling laws, confounders, and tool-calling behavior; build course modules on coding agents; replicate evaluations controlling for context length.
- Assumptions/dependencies: Stable access to released assets; students/researchers have long-context inference capacity; alignment with institutional compute budgets.
- GitHub Actions/Forge integrations for issue triage and patch reproduction
- Sector: Open-source maintenance, Software
- Tools/products/workflows: Use synthetic PR descriptions and agent rollouts to create bots that reproduce reported behaviors, narrow down impacted files, and propose candidate patches tied to issues.
- Assumptions/dependencies: Repository permissions; careful throttling to avoid noisy PRs; collaboration norms of the project.
- Privacy-preserving in-house model deployment
- Sector: Enterprise IT, Government
- Tools/products/workflows: Deploy specialized open-weight agents on internal infrastructure; avoid data egress to closed APIs; chain-of-custody tracking of training and inference runs for compliance.
- Assumptions/dependencies: MLOps maturity; security hardening; monitoring for unsafe edits or data leaks via tools.
Long-Term Applications
These items are plausible but require further research, scaling, product engineering, or validation to be robust at scale.
- Continuous specialization loops (“self-improving repo agents”)
- Sector: Software, Enterprise IT
- Tools/products/workflows: Automate weekly SVG data generation from evolving repos and re-finetune agents to track codebase drift; integrate with change management, AB testing, and rollback mechanisms.
- Assumptions/dependencies: Reliable retraining pipelines; change-safe deployment gates; drift detection; automated regression checks beyond soft verification.
- Cross-repository orchestration for microservice ecosystems
- Sector: Software, Cloud platforms
- Tools/products/workflows: Maintain a mesh of agents specialized per service that coordinate on cross-service changes (APIs, contracts, version bumps). A “dispatcher” agent routes tasks to the right specialized models.
- Assumptions/dependencies: Inter-service schemas/SLAs; robust observability and tooling; standardized tool-call formats across agents; coordination and conflict resolution strategies.
- Sector-specialized agents for regulated codebases with safety cases
- Sector: Healthcare (FDA, ISO 13485), Finance (SOX), Energy (NERC), Automotive (ISO 26262)
- Tools/products/workflows: Extend soft verification with domain-specific validators (static analysis, property checks, safety constraints) and formal methods to assure correctness of changes, not just line-level similarity.
- Assumptions/dependencies: Integration with formal verification tools; domain-specific policies; strong test augmentation; certification pathways.
- Migration assistants for framework and language upgrades
- Sector: Software, Robotics, Embedded
- Tools/products/workflows: Agents specialized to perform large-scale migrations (e.g., Python 3.X minor/major upgrades, Django/Sympy API changes, ROS 1→2). Plan refactor sequences, generate patches, and update docs/tests.
- Assumptions/dependencies: High-fidelity mapping rules; robust rollbacks; performance/regression testing infrastructure; coordination across teams.
- Security patching and vulnerability mitigation with defense-in-depth checks
- Sector: Software, Finance, Government
- Tools/products/workflows: Specialized agents propose patches for known CVEs or detected vulnerabilities and run layered checks (static analysis, fuzzing, sandbox tests) before auto-merging low-risk changes.
- Assumptions/dependencies: Accurate vulnerability feeds; high-confidence verification beyond soft recall; red-team reviews; safe secret handling in tools.
- Marketplace of repository-specialized agents and adapters
- Sector: Software tooling ecosystem
- Tools/products/workflows: Third-party vendors offer “adapter packs” or specialization kits for common stacks (Django, Sympy, Sphinx, ROS), including prebuilt prompts, filters, and SVG recipes; enterprises buy/host them.
- Assumptions/dependencies: Licensing clarity for training on third-party repos; maintenance of adapter packs; standard interfaces for tool-calling and CI integration.
- Expansion to other languages and infra artifacts
- Sector: Software, DevOps
- Tools/products/workflows: Apply SVG and soft verification to multi-language repos (Java/C++/Go/Rust), infrastructure-as-code (Terraform, YAML), notebooks, and data pipelines; develop language-specific verifiers.
- Assumptions/dependencies: Language-aware diff and verification heuristics; tool-call coverage for diverse build systems; longer contexts and higher token costs.
- Hybrid verification frameworks combining soft and hard checks
- Sector: Software engineering research, Safety-critical systems
- Tools/products/workflows: Blend line-level recall with semantic diffing, behavior tracing, test synthesis, and property-driven checks; learn verification thresholds from historical merges and defect rates.
- Assumptions/dependencies: Scalable semantic comparison; test generation quality; coverage metrics tied to business risk; data to learn thresholds.
- Strategic planning with empirically grounded scaling laws
- Sector: Enterprise IT, Academia
- Tools/products/workflows: Use the paper’s power-scaling curves to budget for specialization (e.g., ~8k samples to match teacher on Django) and plan compute, context lengths, and teacher selection across teams.
- Assumptions/dependencies: Transferability of scaling laws to new codebases and languages; access to teachers with predictable cost/performance; stable evaluation setups.
- Policy and governance frameworks for AI-driven code changes
- Sector: Policy, Corporate governance
- Tools/products/workflows: Develop procurement and governance standards for open-weight specialization (privacy-preserving training, audit trails, human review requirements, license compliance) and define guardrails for soft-verified changes.
- Assumptions/dependencies: Cross-functional buy-in (legal, security, engineering); clear rules on training data sources; mechanisms to detect silent behavior regressions.
- Personalized developer assistants trained on an individual’s projects
- Sector: Daily life, Freelancers, Open-source maintainers
- Tools/products/workflows: Lightweight specialization of 8B–32B models on personal repos to accelerate maintenance, triage, and refactors; cache-aware local deployment on consumer-grade GPUs.
- Assumptions/dependencies: Affordable finetuning on consumer hardware or cloud credits; careful handling of private repos; minimal infra overhead and UX polish.
- Research extensions to frontier models and RL hybrids
- Sector: Academia, Advanced AI labs
- Tools/products/workflows: Combine SERA-style SFT pipelines with RL at the frontier to surpass teacher bounds; study tool-calling reliability, long-context memory, and curriculum design using the released data and methods.
- Assumptions/dependencies: Significant compute; stable RL training; robust reward design; reproducible benchmarks with controlled context and tool histories.
Collections
Sign up for free to add this paper to one or more collections.