DynaWeb: Model-Based Reinforcement Learning of Web Agents
Abstract: The development of autonomous web agents, powered by LLMs and reinforcement learning (RL), represents a significant step towards general-purpose AI assistants. However, training these agents is severely hampered by the challenges of interacting with the live internet, which is inefficient, costly, and fraught with risks. Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction. This paper introduces DynaWeb, a novel MBRL framework that trains web agents through interacting with a web world model trained to predict naturalistic web page representations given agent actions. This model serves as a synthetic web environment where an agent policy can dream by generating vast quantities of rollout action trajectories for efficient online reinforcement learning. Beyond free policy rollouts, DynaWeb incorporates real expert trajectories from training data, which are randomly interleaved with on-policy rollouts during training to improve stability and sample efficiency. Experiments conducted on the challenging WebArena and WebVoyager benchmarks demonstrate that DynaWeb consistently and significantly improves the performance of state-of-the-art open-source web agent models. Our findings establish the viability of training web agents through imagination, offering a scalable and efficient way to scale up online agentic RL.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
DynaWeb: A Simple, Teen-Friendly Explanation
Overview
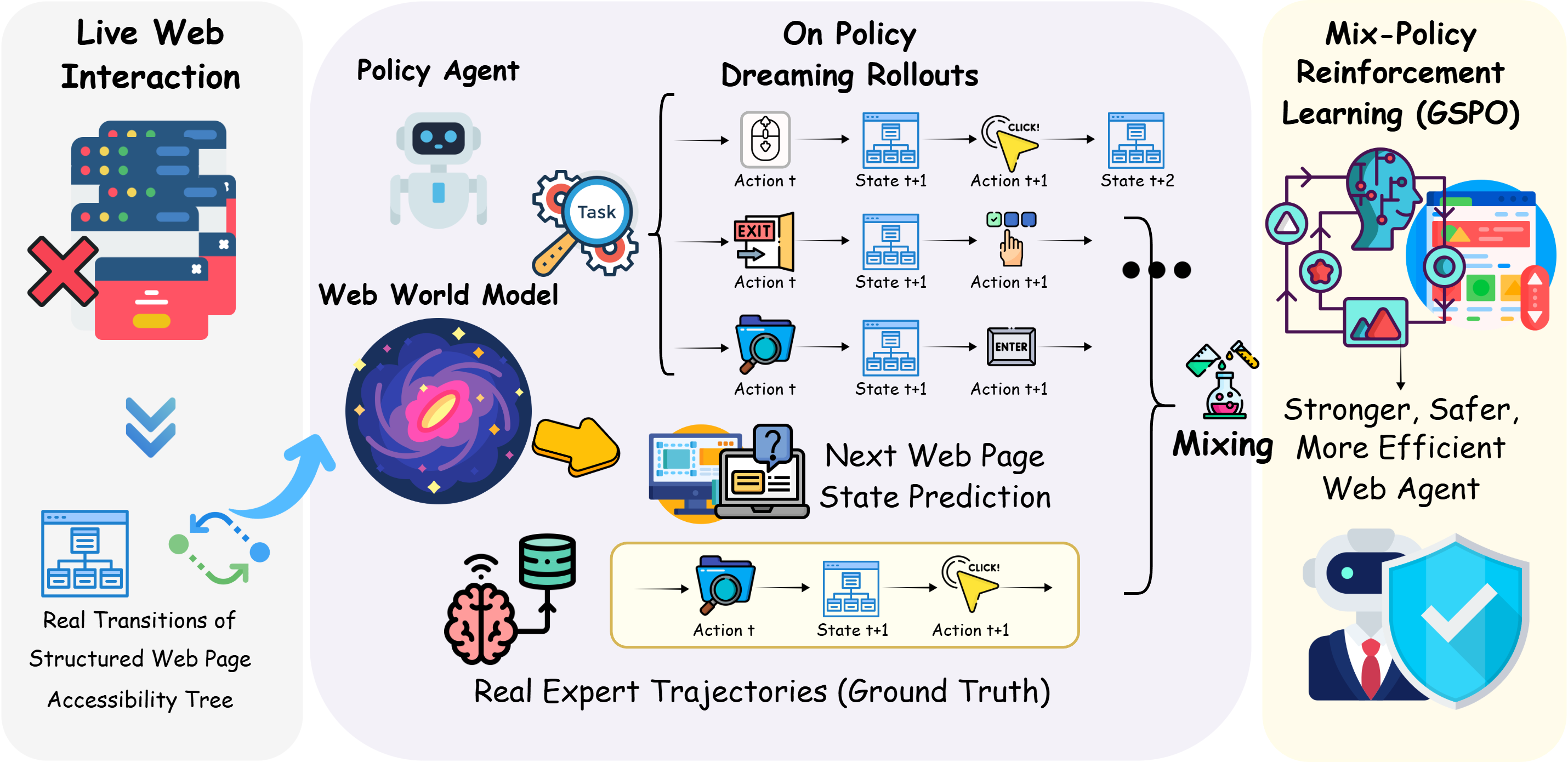
This paper is about teaching AI “web agents” to use websites on their own—like a smart assistant that can browse, click buttons, type in forms, and finish tasks you ask for. The big idea is to train these agents mostly in a safe, virtual version of the web instead of the real internet, which can be slow, expensive, and risky. Their method, called DynaWeb, lets the agent “imagine” (or “dream”) what would happen on a website after it takes certain actions, and learn from those imagined experiences.
What questions did the researchers ask?
- How can we make web agents better at multi-step tasks (like shopping, finding info, or using online tools) without constantly practicing on the real internet?
- Can an agent learn by “imagining” web pages and outcomes, the way you might practice in your head before doing something for real?
- Will mixing imagined practice with some real expert examples make training more stable and efficient?
How did they do it?
Think of this like training for a sport:
- Instead of practicing only in live games (the real web), the agent mostly trains in a well-built simulator (a “world model” of the web).
- The simulator is a special AI that predicts what the next web page will look like after the agent clicks, types, scrolls, or goes back. It doesn’t redraw the whole page every time; it focuses on describing the parts that change—like saying, “the search results section updated” or “a new item appeared,” then applying that change to the current page. This is similar to updating only the parts of a screen that changed instead of repainting everything.
Here’s the training recipe in everyday terms:
- The agent starts from a web page and chooses an action (like click or type).
- The world model “imagines” the next page as if that action happened.
- The agent continues for several steps (usually 4–5) to create an imagined mini-journey (“dream rollout”).
- At the end, the agent checks if the task goal was met (for example, “Did I find the price?” or “Did I add the right item to the cart?”). That becomes its reward.
- To keep learning grounded in reality, the training also randomly mixes in real expert examples—recordings of good, successful web interactions—so the agent doesn’t drift into bad habits from imagination alone.
- For the actual learning update, they use an approach that judges whole sequences of actions at once (rather than token-by-token). You can think of it like scoring an entire play instead of judging each tiny move separately—this helps with long tasks where the reward comes at the end.
They tested their agents on two tough benchmarks:
- WebArena: websites hosted in a controlled environment with many realistic tasks.
- WebVoyager: real, live websites with open-ended tasks (like Amazon, Apple, BBC News, Google Maps, etc.).
What did they find, and why is it important?
The main findings show that imagination-based training works—and works well.
- Better success rates:
- On WebArena, DynaWeb improved the average success rate to about 31.0%, beating strong baselines (like an offline RL method at 26.7%).
- On WebVoyager (live sites), DynaWeb reached around 38.7% overall and performed best on many individual sites (Amazon, Apple, BBC News, Cambridge Dictionary, Coursera, Google Maps, Google Search, Hugging Face, WolframAlpha).
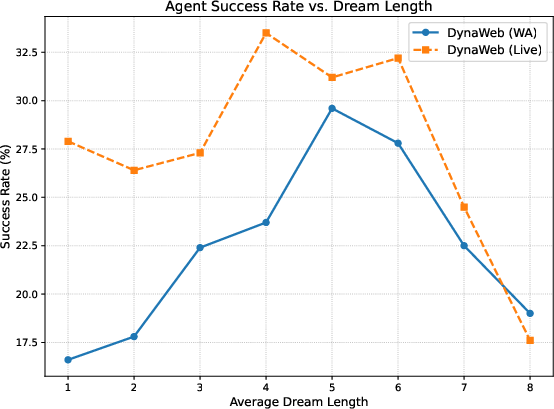
- “Dream length” sweet spot:
- Imagined journeys that are too short don’t teach enough.
- Too long can pile up errors from the simulator.
- Around 4–5 imagined steps was the best balance.
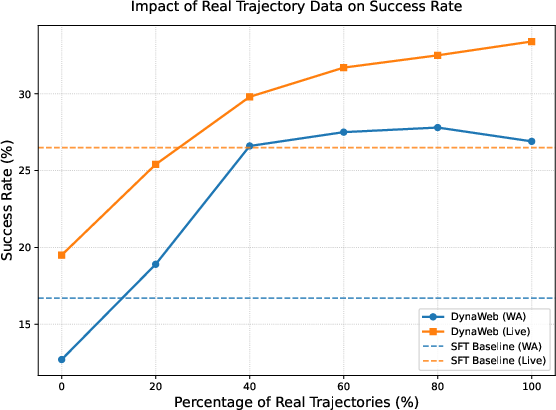
- Mixing in real expert data helps:
- Using about 40% real expert trajectories alongside imagined ones gave a big boost and stabilized training.
- Adding more than that helps less and less (diminishing returns).
- Training the world model matters:
- A specially trained web simulator (world model) beat a general “big AI” used as a simulator without training.
- This means it’s not just about size or clever prompting; you need a simulator tuned to web dynamics.
Why this matters:
- Safety: The agent can practice without accidentally buying things, changing accounts, or sending data on real sites.
- Cost and speed: Simulated training is faster and cheaper than constantly hitting live websites.
- Scalability: You can generate tons of practice experiences in the simulator, which makes the learning process efficient.
What’s the bigger impact?
If AI web agents can learn mostly through safe, high-quality imagination, we can:
- Build smarter, more reliable assistants that handle complex, multi-step web tasks with fewer mistakes.
- Train at scale without risking real-world consequences.
- Move toward general-purpose AI helpers that learn, plan, and improve over time in rich environments—using “world models” as the backbone.
In short, DynaWeb shows that letting AI “dream” realistically about the web—guided by some real examples—can make web agents stronger, safer, and more practical.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following points summarize what remains missing, uncertain, or unexplored in the paper, organized to guide concrete follow-up research.
Web world model (WWM) fidelity, representation, and coverage
- Absence of quantitative fidelity metrics for the WWM: no reported next-state prediction accuracy (e.g., structural/semantic tree edit distance, element-level precision/recall, URL/state-change correctness) or calibration analyses across step depths.
- Uncertainty estimation is not addressed: no ensembles, epistemic uncertainty, or disagreement measures to gate imagined rollouts or adaptively mix real/imagined data.
- Limited observation modality: reliance on accessibility trees (textual/semantic structure) excludes visual/layout cues, dynamic rendering, and pixel-dependent behaviors; impact on tasks requiring vision or fine-grained spatial reasoning is unmeasured.
- Transition modeling operates via free-form “state change descriptions” Δ and an instruction-following “apply Δ” step; the correctness, idempotency, and drift of this patching mechanism are not validated or stress-tested (e.g., compounding edits over long horizons, conflict resolution).
- Determinism assumption: stochastic, time-varying, and user/session-dependent web dynamics (A/B tests, pop-ups, cookie banners, rate-limits, CAPTCHAs, auth flows) are not modeled; robustness to such nondeterminism is untested.
- Coverage and generalization of the WWM are unclear: training on NNetNav-derived trajectories may underrepresent long-tail elements, modern frameworks (React/Vue), or dynamic JS-heavy sites; no systematic evaluation on out-of-distribution websites or UI patterns.
- No analysis of multi-tab/multi-window state, background loading, or cross-site navigation; the WWM appears single-page and single-tab, limiting applicability to realistic browsing workflows.
- Action space coverage is narrow (click/type/scroll/back/stop): missing actions such as drag-and-drop, hover, file upload/download, keyboard shortcuts, auth/token workflows, or form validation feedback; impact on task solvability is not quantified.
Imagination-driven RL design and optimization
- Dream horizon is capped at 5 and tuned empirically; no methods to safely extend horizons (e.g., hierarchical rollouts, periodic re-grounding, scheduled resets, or model-error-aware truncation) are explored.
- No credit assignment enhancements beyond sequence-level GSPO with terminal binary rewards; alternatives like learned dense reward models, progress heuristics, value/critic learning from imagined states, or temporal-difference targets are unexamined.
- Lack of off-policy correction or model-bias mitigation: importance sampling across imagined vs real trajectories, conservative policy updates, or regularization toward real transition distributions are not investigated.
- Interleaving strategy for real vs imagined data is simplistic and static; adaptive scheduling (e.g., based on WWM uncertainty, advantage signals, or disagreement) and curriculum over dream length are not explored.
- Exploration incentives (curiosity, novelty, count-based, or disagreement-driven bonuses) are absent, potentially limiting discovery of new states in imagination.
- Sensitivity to GSPO hyperparameters and comparison to alternative sequence-level RL objectives (e.g., PPO, DAPO, R1 variants) are not provided.
Rewarding, evaluation, and potential misalignment
- Reward source during training is “model-based self-assessment” with binary completion labels; its calibration, agreement with environment-ground-truth success metrics, and susceptibility to reward hacking are not quantified.
- No cross-evaluation showing that policies optimized for the self-assessment judge also maximize official benchmark success; mismatch risk between training reward and deployment criteria remains unmeasured.
- Sparse-only terminal reward design may limit learning of multi-step competencies; the paper does not test alternatives like heuristic subgoal completions or rule-based partial credit from environment signals.
- No failure-mode taxonomy: absence of qualitative error analysis (e.g., hallucinated elements, wrong-page interactions, infinite scroll traps, form submission errors) limits targeted improvements.
Generalization, robustness, and live Web realities
- Sim2real transfer limits: beyond aggregate success rates, no controlled experiments measure degradation from imagined to live environments across dimensions like DOM churn, latency, pop-ups, or anti-bot mechanisms.
- Robustness to frequent UI changes is not tested longitudinally; no time-split evaluations or repeated runs across different weeks to quantify performance drift.
- Underperformance on ArXiv/GitHub suggests limitations in long-horizon branching and dynamic content; the paper does not analyze which capabilities (e.g., repository navigation semantics, search refinement, pagination) are missing.
- WebVoyager filtering of inaccessible tasks introduces selection bias; the extent of filtering and its effect on representativeness is not quantified.
- Security/authentication tasks (login, MFA, cookies, CSRF tokens) are out of scope; extending WWM and policy to these workflows remains unaddressed.
Practicality, scalability, and cost
- Compute and cost profile is unclear: training a 120B WWM for imagination is likely expensive; no budgets, token counts, energy, or wall-clock times are reported, hindering reproducibility and assessment of practicality.
- Scalability to larger or smaller models is untested: Pareto trade-offs between WWM size, fidelity, and downstream performance remain unknown; feasibility for modest-resource labs is uncertain.
- Throughput and latency considerations for generating imagined trajectories at scale are unreported; no discussion of batching, caching, or parallelization strategies for efficient training.
Comparisons, ablations, and fairness
- Lack of a controlled comparison to model-free RL with the same amount of real data (and no imagination) to isolate the net benefit of world-model-based rollouts.
- Unclear fairness of the inference-time lookahead (ITL) baseline: whether it uses the same WWM as DynaWeb is not specified; calibration and search budget parity are not ensured.
- No ablation isolating the contribution of Δ-prediction vs full next-observation prediction, or the impact of including/excluding reasoning traces in WWM training.
- No per-website/task-type breakdown beyond aggregate SR for error attribution (e.g., forms vs search vs filtering vs checkout).
Representation and environment mechanics
- Accessibility-tree-only state omits JavaScript event semantics, network responses, and asynchronous updates; no mechanism to encode in-flight requests, timers, or deferred rendering.
- No explicit handling of error pages, redirects, rate-limits, or throttling; policy behaviors under these contingencies are not evaluated.
- State consistency checks are missing: there is no invariant enforcement to prevent impossible states emerging from accumulated Δ applications.
Reproducibility, documentation, and artifacts
- Source code and models are “Coming Soon”; crucial reproducibility details (data cleaning rules, prompts for Δ extraction, WWM fine-tuning hyperparameters, GSPO settings, seeds) are incomplete.
- Mathematical specification of GSPO in the paper contains formatting/parenthesis issues, risking ambiguity in reimplementation; a precise, executable objective is not provided.
- Dataset details (size, site coverage, trajectory diversity, proportion of intermediate vs initial states) and filtering statistics are not fully reported.
Safety and ethics
- Safety claims (reduced risk by training in imagination) are not empirically evaluated; no metrics on risky action avoidance, PII handling, or unintended transactions during evaluation.
- No discussion of guardrails in the WWM or policy to avoid generating unsafe actions in imagined or real settings; absence of red-teaming or adversarial testing.
Open research directions
- Methods to extend reliable dream horizon (e.g., hierarchical options, periodic real-state anchoring, uncertainty-driven truncation).
- Uncertainty-aware mixing and curriculum: adaptive real/imagined interleaving, targeted data collection where the WWM is least accurate.
- Multimodal WWMs that integrate visual rendering signals and DOM semantics for richer fidelity.
- Learned, environment-aligned reward models and dense progress signals that remain robust under imagination.
- Formal sim2real diagnostics for the web: benchmarks and metrics explicitly measuring robustness to DOM churn, dynamic content, and anti-bot obstacles.
- Compact or latent WWMs (Dreamer-style) to reduce compute while preserving fidelity; study fidelity–cost trade-offs.
- Expanded action spaces and realistic workflows (auth, payments, uploads, multi-tab), plus environment APIs to emulate these safely during training.
Practical Applications
Immediate Applications
The following applications can be deployed today using the paper’s DynaWeb framework (web world model + imagination-driven RL with interleaved expert trajectories) and are most feasible when focused on specific sites or portal families with available interaction logs and stable UI structures.
- Safer training sandbox for web agents (Software/AI infrastructure)
- What: Replace risky live-web training with a DynaWeb-style simulated environment to iterate on policies, prompts, and reward design without triggering real transactions.
- Tools/products/workflows: “WebSim-as-a-Service” for agent labs; GSPO-based training pipelines; adapters for Playwright/Selenium; MCP/Cognitive Kernel plugins for simulated rollouts.
- Assumptions/dependencies: Access to per-site trajectories to fit the web world model (WWM); stable accessibility-tree extraction; clear task-level rewards; compute for model fine-tuning.
- Enterprise RPA pretraining and robustness tuning (Software, Enterprise IT)
- What: Pre-train and fine-tune bots for ERP/CRM/HR portals in simulation to reduce production flakiness and limit exposure to anti-bot protections during development.
- Tools/products/workflows: DynaWeb world models per internal portal; policy fine-tuning with expert logs interleaved with imagined rollouts; “self-healing” policy updates based on simulated failure cases.
- Assumptions/dependencies: Availability of internal clickstreams/demonstrations; stable authentication stubs or synthetic login flows; exportable accessibility trees.
- Website QA and regression testing via simulated users (Software/DevOps)
- What: Use imagined rollouts to continuously test user journeys (signup, checkout, onboarding) and detect UI regressions pre-deploy.
- Tools/products/workflows: CI/CD gate that runs fixed task suites against the WWM; drift alerts when imagined success falls; synthetic “what-if” DOM changes tested offline.
- Assumptions/dependencies: Per-site WWM fidelity high enough to reflect DOM/ARIA changes; mapping from synthetic success to real-world success.
- Accessibility auditing and assistive flow checks (Accessibility, Compliance)
- What: Because DynaWeb operates on accessibility trees, simulate screen-reader-like navigation to detect unlabeled controls, broken tab orders, and inaccessible flows.
- Tools/products/workflows: “A11y-agent” that explores tasks (e.g., account creation) and flags blockers; remediation suggestions from agent reasoning traces.
- Assumptions/dependencies: Reliable accessibility tree extraction; rules/heuristics for success criteria; acceptance by compliance teams.
- E-commerce and marketplace task automation in low-risk modes (Retail)
- What: Train agents to search, compare, and monitor items or fill wishlists safely in simulation; deploy read-only or sandboxed tasks first.
- Tools/products/workflows: Product discovery copilot; price/availability trackers controlled by agent policies verified in the WWM.
- Assumptions/dependencies: ToS compliance; anti-bot constraints; reward definition (e.g., finding correct SKU); per-site model adaptation.
- Customer support self-serve navigation (Support/ServiceOps)
- What: Agents trained to navigate help centers, documentation hubs, and ticket portals to auto-triage/resolve common queries.
- Tools/products/workflows: Support triage bot integrated with knowledge base; simulated training on known flows; fallback to human handoff.
- Assumptions/dependencies: Clear terminal rewards (issue resolved vs. escalated); dynamic content handled by WWM; site structure consistency.
- Offline evaluation harness for web agents (Academia, Model Evaluation)
- What: Standardized, low-cost evaluation using WWMs for reproducible benchmarking and ablation (e.g., dream length, mixing ratios).
- Tools/products/workflows: Open evaluation suites similar to WebArena/WebVoyager but simulated; publish reproducible seeds and model checkpoints.
- Assumptions/dependencies: Public release of code and benchmark WWMs; accepted correlation between simulated and live metrics.
- Privacy-preserving training on sensitive portals (Healthcare, Finance, GovTech)
- What: Train agents on anonymized trajectories without touching live systems, limiting exposure of PHI/PII while improving task performance.
- Tools/products/workflows: Local/siloed WWMs; differential privacy on logs; masked reward shaping; “red-team” simulation of failure cases.
- Assumptions/dependencies: Internal approval to use sanitized logs; sufficient signal in anonymized state changes; governance for synthetic data generation.
- Employee onboarding and guided walkthroughs (Education/HR Tech)
- What: Simulated tutorials where an agent demonstrates how to accomplish portal tasks (timesheets, expense submissions) using imagined states.
- Tools/products/workflows: Interactive training modules powered by the WWM; step-by-step coach that mirrors the real portal.
- Assumptions/dependencies: Fidelity of simulated steps to the production portal; frequent content updates synced to WWM.
- Research acceleration for agentic RL (Academia)
- What: Rapid prototyping of RL algorithms (GSPO variants, reward shaping, exploration curricula) without expensive live interactions.
- Tools/products/workflows: Open-source DynaWeb training code; standardized ablation suites; scriptable trajectory mixing with expert data.
- Assumptions/dependencies: Compute budgets for large-scale imaginary rollouts; availability of public datasets (e.g., NNetNav) to bootstrap WWMs.
Long-Term Applications
These applications require further research, scaling, or engineering, notably around world model generalization, longer-horizon fidelity, dynamic content handling, authentication, and safety guarantees.
- General-purpose web world model spanning diverse sites (Software/AI platform)
- What: A foundation WWM that generalizes across classes of websites, enabling broad web automation without per-site retraining.
- Tools/products/workflows: “Web Twin” foundation model; adapters for layout variants; continual learning from live drift.
- Assumptions/dependencies: Large-scale multi-site data; robust handling of CAPTCHAs/authentication; improved hallucination control at longer horizons.
- End-to-end automation across multiple websites/workflows (Finance, Supply Chain, HR, Legal)
- What: Complex, cross-portal tasks (e.g., invoice reconciliation across ERP + bank + tax portals; legal filings; HR onboarding across vendors).
- Tools/products/workflows: Multi-site policy composition; cross-site rewards; execution monitoring and rollback plans.
- Assumptions/dependencies: High-fidelity long-horizon WWMs; consistent identity and session management; formalized success checks spanning sites.
- Browser “copilot” for everyday online tasks (Consumer productivity)
- What: Personal assistants that plan with imagination and execute reliably (e.g., book travel, manage subscriptions, fill applications) with robust safety constraints.
- Tools/products/workflows: Embedded browser agent; human-in-the-loop confirmations; pre-execution dry-runs in WWM.
- Assumptions/dependencies: Trustworthy self-assessment of success; robust failure detection and recovery; privacy-preserving local models.
- Safety-critical transaction agents with verification (Healthcare, Trading, GovTech)
- What: Agents that execute high-stakes actions (placing trades, scheduling procedures, filing benefits) with formal safety checks and verifiable plans.
- Tools/products/workflows: Verified action plans; rule-based guardrails; postconditions validated in both WWM and staging environments.
- Assumptions/dependencies: Near-realistic WWMs; formal verification methods for UI sequences; regulatory approval.
- Autonomic A/B testing and UX optimization (Product/Design)
- What: RL-trained “synthetic users” explore design variants in simulation and recommend layout or copy changes to improve task success.
- Tools/products/workflows: Design IDE plugins; Bayesian optimization over simulated results; automated regression detection.
- Assumptions/dependencies: Validated correlation between simulated and real engagement; mitigations for simulation bias.
- Mobile and native GUI extension of world modeling (Robotics/UI automation)
- What: Extend DynaWeb principles to mobile apps and native GUIs (e.g., UI-TARS) for cross-platform automation and training.
- Tools/products/workflows: Accessibility semantics for native apps; multi-modal WWMs handling vision + text; unified action abstractions.
- Assumptions/dependencies: Reliable extraction of UI trees across platforms; robust vision-language dynamics; domain-specific datasets.
- Web security and fraud simulation (Cybersecurity)
- What: Simulate phishing/fraud flows and train defensive agents to flag risky sequences before deployment.
- Tools/products/workflows: “Adversarial WebSim” to generate attack chains; SOC integrations for automated playbooks.
- Assumptions/dependencies: High-fidelity modeling of attacker UX patterns; legal/ethical constraints; red-teaming oversight.
- Regulatory impact assessment in a digital twin (Policy/GovTech)
- What: Test e-government service changes (e.g., form redesigns) on simulated populations to evaluate accessibility and completion rates ahead of rollout.
- Tools/products/workflows: Policy sandboxes; synthetic demographic profiles with varied ability constraints; auditing dashboards.
- Assumptions/dependencies: Representativeness of simulated users; fairness controls; public-sector data-sharing frameworks.
- Large-scale synthetic data generation for agent training (AI/ML)
- What: Produce diverse, high-quality imagined trajectories to pretrain generalist web agents and reward models (RLAIF).
- Tools/products/workflows: Curriculum generation services; automatic diversification of state distributions; quality filtering pipelines.
- Assumptions/dependencies: Techniques to curb compounding errors; scalable validation of synthetic labels; licensing for base models.
- Multi-agent “workforce” coordination on the web (Operations/Automation)
- What: Teams of agents coordinating across tasks and websites with shared world models and communication protocols.
- Tools/products/workflows: Task decomposition and scheduling; shared memory of imagined states; conflict resolution and SLAs.
- Assumptions/dependencies: Stable inter-agent protocols; global reward aggregation; reliable failure escalation.
- Enterprise change management and migration forecasting (IT/Platform Ops)
- What: Predict the impact of DOM/API/UI changes on fleets of bots/agents and automatically generate migration patches.
- Tools/products/workflows: Diff-based WWM updates; counterfactual testing; automated policy fine-tuning on changed flows.
- Assumptions/dependencies: Continuous data pipelines for change detection; strong generalization in WWMs; governance for auto-patching.
- Education and training in agentic RL (Academia/EdTech)
- What: Use WWMs to teach long-horizon RL concepts with safe, controllable environments and standardized curricula.
- Tools/products/workflows: Courseware with reproducible labs; open benchmarks with tunable difficulty (dream length, reward sparsity).
- Assumptions/dependencies: Community-maintained WWMs; open licensing; compute access for students.
Notes on Feasibility Across Applications
- Model fidelity and horizon length: The paper shows optimal “dream length” around 4–5 steps; many long-horizon applications will require improved WWMs and error-mitigation strategies.
- Data availability: Per-site WWMs need high-quality trajectories (expert or logs). Public datasets are limited; enterprises may need internal data pipelines.
- Dynamic content and drift: Frequent UI/DOM changes, authentication, CAPTCHAs, and anti-bot measures reduce transfer from simulation; continual WWM updates are necessary.
- Reward design and evaluation: Reliable task-completion assessment (self-assessment or scripts) is essential; mis-specified rewards can mis-train policies.
- Legal, ethical, and ToS constraints: Automation on third-party sites must respect terms of service, privacy regulations (GDPR/CCPA/PHI), and security practices.
- Compute and integration: Fine-tuning large WWMs and GSPO training require non-trivial compute and integration with browser automation frameworks.
- Accessibility reliance: Benefits for accessibility auditing depend on accurate accessibility-tree extraction and site compliance with ARIA best practices.
Glossary
- Accessibility tree: A structured representation of visible web elements used to encode page observations for the agent. "Following prior work~\citep{cognitive_kernel}, we represent each observation using an accessibility tree that captures the structured layout of visible web elements."
- Advantage: In reinforcement learning, a measure of how much better a trajectory or action performs compared to a baseline. "where denotes the (trajectory-level) advantage computed from the terminal return ."
- Behavior cloning: Supervised learning that trains a policy to imitate expert demonstrations. "WorkForceAgent-R1~\citep{zhuang2025workforceagentr1incentivizingreasoningcapability} integrates behavior cloning with GRPO-style optimization to jointly enhance single-step reasoning and multi-step planning."
- Chain-of-thought: The explicit reasoning trace generated by an LLM to guide action selection. "the agent samples a chain-of-thought together with an action "
- Clipped objective: A policy optimization objective that limits the magnitude of update via clipping (as in PPO-like methods). "GSPO optimizes the clipped objective"
- Credit assignment: The process of attributing rewards to the actions that caused them, especially in long-horizon tasks. "allowing efficient and robust credit assignment for long-horizon web tasks with sparse terminal rewards."
- Curriculum learning: A training strategy that presents tasks in a structured order from easy to hard to improve learning efficiency. "AutoWebGLM~\citep{10.1145/3637528.3671620} integrates SFT, RL, and rejection sampling fine-tuning, with curriculum learning to bootstrap basic web navigation skills before subsequent RL refinement."
- Dream length: The number of steps in a synthetic, imagined rollout produced by the world model. "the length of synthetic trajectories generated through agentâworld model interaction (referred to as the dream length)"
- Dreamer: An imagination-based RL framework that learns behaviors via latent world models and simulated rollouts. "Inspired by the Dyna architecture~\citep{sutton1991dyna} and imagination-based learning frameworks such as Dreamer~\citep{hafner2020dreamcontrollearningbehaviors}"
- Dyna architecture: A classic model-based RL approach that integrates learning, planning, and reacting. "Inspired by the Dyna architecture~\citep{sutton1991dyna}"
- Geometric mean: A multiplicative average used here to aggregate token-level likelihood ratios into a sequence-level ratio. "The sequence-level ratio is defined as the geometric mean of token-wise likelihood ratios:"
- GRPO: A reinforcement learning algorithm (Group Relative Policy Optimization) used for scalable trajectory sampling and optimization. "WebAgent-R1~\citep{wei2025webagentr1trainingwebagents}, which optimizes multi-turn web interaction policies using outcome-based rewards and scalable trajectory sampling (e.g., multi-group GRPO~\citep{shao2024deepseekmathpushinglimitsmathematical})."
- Group Sequence Policy Optimization (GSPO): A sequence-level policy optimization method that applies importance sampling uniformly across a trajectory. "we adopt Group Sequence Policy Optimization (GSPO)~\citep{zheng2025groupsequencepolicyoptimization}."
- Hallucinations: Inaccurate or fabricated outputs produced by a generative model, which can compound over long rollouts. "to reduce the effect of WWM hallucinations"
- Imitation learning: Learning a policy from expert demonstrations without explicit reward optimization. "Beyond imitation learning, recent work has shown that training web agents with online reinforcement learning (RL) can substantially improve robustness, exploration, and long-horizon decision-making"
- Imagined rollouts: Synthetic trajectories generated by a learned world model to provide training experience without real environment interaction. "imagined rollouts serve as first-class experience that directly augments on-policy policy optimization."
- Importance sampling: A technique to correct distribution mismatch by reweighting samples during optimization. "GSPO lifts importance sampling from the token level to the rollout (sequence) level"
- Inference-time lookahead (ITL): A method that uses simulation at inference to evaluate candidate actions before execution. "5) Inference-time lookahead (ITL):"
- Inference-time optimization: Techniques (e.g., tree search, self-reflection) that improve decision-making during inference without additional training. "inference-time optimization (e.g., tree search and self-reflection) further improves decision-making without additional training~\citep{AgentTreeSearch, AgentQ, Exact, LATS, webpilot, Reflexion}."
- Latent dynamics: Hidden state transitions modeled in a latent space; here avoided by predicting directly in observation space. "Rather than learning latent dynamics, the model operates directly in the observation space"
- LLMs: High-capacity LLMs used as the backbone for reasoning and action generation in agents. "LLMs have emerged as a powerful backbone for such agents"
- Model-based reinforcement learning (MBRL): RL that uses a learned model of the environment to enable planning or simulated interaction. "Model-based reinforcement learning (MBRL) offers a promising solution by learning a world model of the environment to enable simulated interaction."
- Model-based self-assessment: Using a model to judge task completion and provide reward signals. "a task-level reward signal is obtained via model-based self-assessment conditioned on the task query."
- Monte Carlo Tree Search: A planning algorithm that explores action/state trees using sampling and statistical evaluation. "RAP~\citep{RAP_world_model} integrates LLM-based world modeling with Monte Carlo Tree Search to explore hypothetical trajectories"
- Observation function: A mapping from environment state to partial observation available to the agent. "obtained via an observation function "
- Observation space: The space of observations (e.g., page representations) the agent perceives and the world model predicts. "the model operates directly in the observation space"
- Offline reinforcement learning: RL performed on previously collected datasets without live environment interaction. "4) Offline reinforcement learning:"
- On-policy interaction: Experience collected by executing the current policy, used directly for optimization. "randomly interleaved with imagined rollouts and real on-policy interaction"
- On-policy optimization: Reinforcement learning that optimizes using data generated by the current policy. "DynaWeb enables effective on-policy optimization while avoiding the cost and risk of real-environment interaction."
- Partially Observable Markov Decision Process (POMDP): A formalism for decision-making when the agent receives incomplete observations of the true state. "We formulate the web agent task as a Partially Observable Markov Decision Process (POMDP)"
- Policy gradient optimization: RL methods that adjust policy parameters via gradients of expected returns. "use the resulting imagined rollouts as valid training data for policy gradient optimization"
- Return: The cumulative reward signal of a trajectory (here the terminal task success). "We treat the return as "
- Reward model: A learned model that assigns scores/rewards to trajectories or outcomes. "which are then scored by a trained outcome-based reward model and used for offline reinforcement learning."
- Rollout: A sequence of states, actions, and observations generated by a policy interacting with an environment or simulator. "rollout action trajectories"
- Sequence-level policy optimization: Optimization applied at the trajectory level, treating the entire generated sequence as a unit. "The agent policy is optimized using sequence-level policy optimization"
- Sequence-level ratio: A single importance-sampling weight applied uniformly across all tokens of a trajectory. "The sequence-level ratio is defined as the geometric mean of token-wise likelihood ratios:"
- Sparse terminal rewards: Reward signals provided only at the end of a trajectory, making credit assignment challenging. "long-horizon web tasks with sparse terminal rewards."
- Supervised fine-tuning (SFT): Training an LLM or agent on labeled data to specialize behavior. "Beyond pure online RL, joint training pipelines that combine SFT and RL have also shown effectiveness."
- Synthetic environment: A simulated environment produced by a learned world model to replace or augment real interaction. "A learned web world model serves as a synthetic environment, enabling the agent to generate multi-step imagined rollouts without interacting with the live web."
- Token-level ratios: Per-token likelihood ratios used to compute the sequence-level ratio in GSPO. "with token-level ratios"
- Transition function: The environment dynamics mapping from current state and action to next state. "according to the transition function :"
- Trajectory: The full sequence of observations, reasoning traces, and actions produced during an episode. "An interaction episode produces a trajectory "
- Web world model (WWM): A domain-specific world model for web environments used to simulate page transitions. "resulting in a live WWM for WebVoyager and a simulated WWM for WebArena."
- World model: A learned model that predicts future observations or states given current observations and actions. "We introduce a web world model that approximates the transition dynamics of web environments by predicting how visible web states evolve in response to agent actions."
Collections
Sign up for free to add this paper to one or more collections.