- The paper presents a four-stage pipeline combining data construction, trajectory sampling, supervised fine-tuning, and reinforcement learning for autonomous information-seeking agents.
- Empirical evaluations on GAIA and WebWalkerQA benchmarks reveal significant accuracy and efficiency improvements over state-of-the-art methods.
- The framework emphasizes scalable, adaptive agentic behavior, laying the groundwork for robust, real-world autonomous web interactions.
In the paper "WebDancer: Towards Autonomous Information Seeking Agency" (2505.22648), the authors present a comprehensive framework for developing web agents capable of autonomous, multi-step information seeking. The framework aims to address real-world information-seeking challenges by constructing sophisticated agents that integrate perception, decision-making, and task execution similarly to human information-seeking processes.
Framework and Methodology
The proposed framework is built upon a four-stage training pipeline:
- Browsing Data Construction: This step involves the creation of a corpus from web pages to support high-quality data acquisition. The aim is to gather fine-grained browsing data that reflects diverse user intents. Two types of datasets are introduced: crawlQA through systematic web crawling and e2hQA, which uses query transformation.
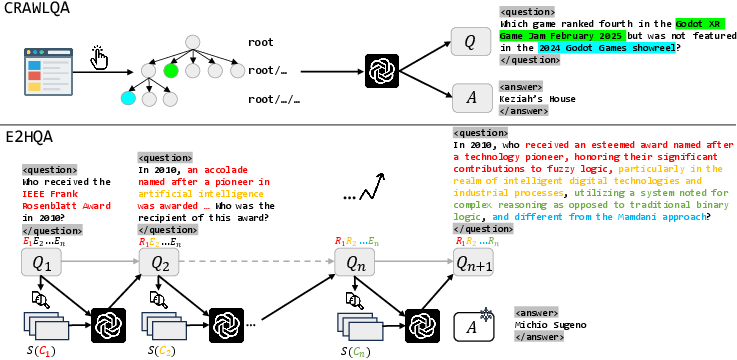
Figure 1: Two web data generation pipelines.
- Trajectories Sampling: By leveraging ReAct, the authors propose to generate trajectories for agent learning, involving sequences of reasoning and action steps. The framework constructs both short and long chains of thought (CoT), enhancing the agent's ability to reason and plan actions autonomously.
- Supervised Fine-Tuning (SFT): This stage is crucial for preparing the model for initial deployment, allowing it to learn a structured approach to reasoning and action execution using the trajectories developed earlier. The paper highlights the significance of agent SFT as a cold start to couple reasoning with adaptive actions.
- Reinforcement Learning: A novel RL approach, DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization), is used to optimize the agent's policies by rewarding effective reasoning and tool executions. This stage helps in adapting to unforeseen environments by leveraging underutilized QA pairs from the prior stages.
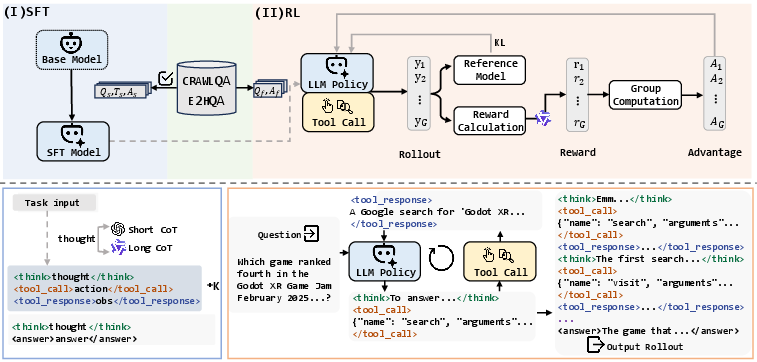
Figure 2: The overview of training framework. (I) The SFT stage for cold start utilizes the reformatted ReAct datasets, where the thought includes both short and long CoT, respectively. (II) The RL stage performs rollouts with the tool calls on the QA pairs that are not utilized during the SFT stage, and optimizes the policy using the DAPO algorithm.
Empirical Evaluation and Results
The WebDancer framework was evaluated using challenging benchmarks like GAIA and WebWalkerQA. The experimental results demonstrate significant improvements over existing state-of-the-art approaches, achieving high accuracy in information-seeking tasks. The pipeline shows superior adaptability and reasoning capabilities compared to traditional methods, as evidenced by strong results on both standard and more challenging datasets.
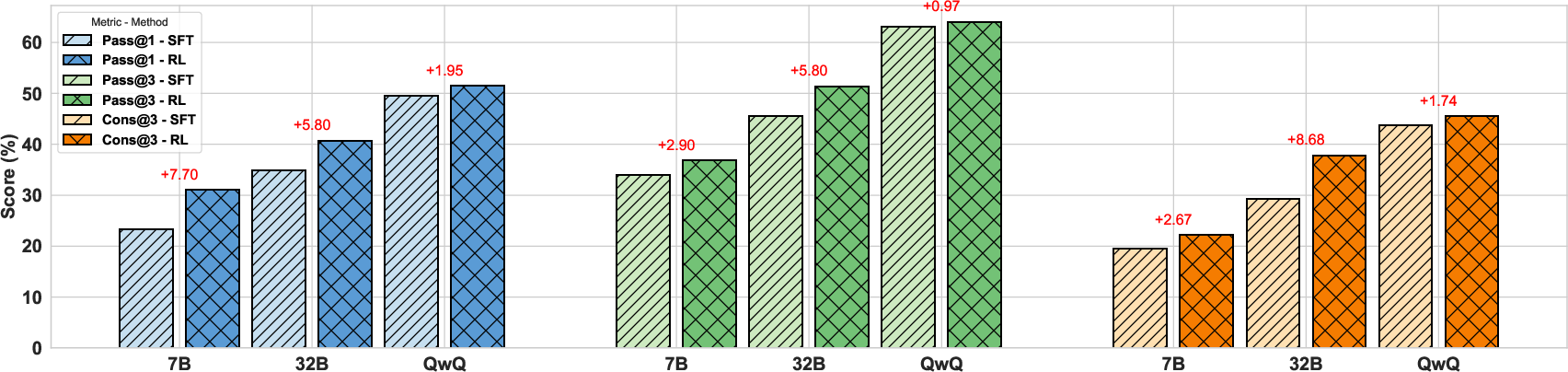
Figure 3: Detailed evaluation results using Pass@1, Pass@3, and Cons@3 metric on GAIA benchmark.
Analysis of the results underscores the framework's efficiency in scaling agentic behavior while maintaining data efficiency and robustness. Another key insight from the study is how the ReAct architecture can be extended to allow for more complex tool-based interactions in an end-to-end setting.
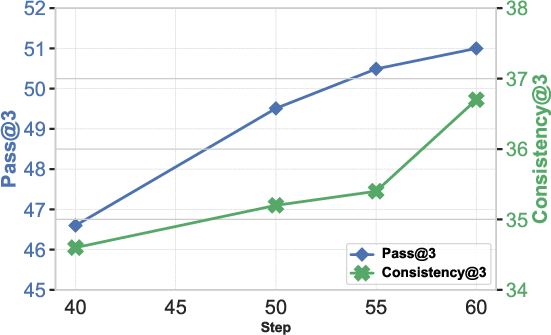
Figure 4: Analysis on RL algorithm, emergent agency, and agent environments using GAIA benchmark.
Practical Implications and Future Directions
WebDancer paves the way for more autonomous agents that can operate in real-world web environments, capable of conducting in-depth research and complex reasoning tasks. By increasing the complexity and diversity of training datasets, the agents can be more generalized and robust. A promising future direction includes integrating more complex toolchains to enhance the agent's capability to perform diverse tasks autonomously.
The framework's systematic approach holds potential for broader applications, such as dynamic problem-solving in various domains and automated discovery processes. Future research could focus on refining the RL components and exploring adaptive mechanisms for real-time agent learning in continuously evolving web contexts.
Conclusion
The development of WebDancer as described in this paper signifies an important step towards building autonomous information-seeking agents. Through careful construction of data pipelines and a novel multi-stage training schema, it achieves impressive empirical results. This framework not only strengthens the capability of web agents but also provides a viable blueprint for future advancements in autonomous agent research.

