Test-Time Compute Games
Abstract: Test-time compute has emerged as a promising strategy to enhance the reasoning abilities of LLMs. However, this strategy has in turn increased how much users pay cloud-based providers offering LLM-as-a-service, since providers charge users for the amount of test-time compute they use to generate an output. In our work, we show that the market of LLM-as-a-service is socially inefficient: providers have a financial incentive to increase the amount of test-time compute, even if this increase contributes little to the quality of the outputs. To address this inefficiency, we introduce a reverse second-price auction mechanism where providers bid their offered price and (expected) quality for the opportunity to serve a user, and users pay proportionally to the marginal value generated by the winning provider relative to the second-highest bidder. To illustrate and complement our theoretical results, we conduct experiments with multiple instruct models from the $\texttt{Llama}$ and $\texttt{Qwen}$ families, as well as reasoning models distilled from $\texttt{DeepSeek-R1}$, on math and science benchmark datasets.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “Test‑Time Compute Games”
Overview
This paper looks at how companies that run LLMs in the cloud decide how much “extra thinking” a model should do before giving you an answer—and how that decision affects what you pay and what you get. The authors show that today’s market often pushes companies to use more compute than is actually useful, making users pay more without getting much better answers. They then design a fairer way to pick providers and set payments so everyone benefits.
What questions did the researchers ask?
- Do LLM service providers have reasons to use more test-time compute (extra thinking) than is best for society?
- What happens when many providers compete: does the market settle into a stable pattern, and is that pattern good for users?
- Can we design a simple, fair rule for choosing providers and setting prices so that users get the best overall deal and providers still make money?
How did they study it? (Explained simply)
Think of hiring a tutor online:
- “Quality” is how accurate the tutor’s answers are.
- “Compute” is how many steps the tutor takes to think through a problem (like writing out a longer explanation).
- “Price” is how much they charge you.
- “Value to the user” is quality minus price: how good the answer is, given what you paid.
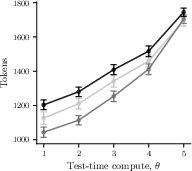
In today’s LLM services, you pay for all the tokens the model generates—even the “invisible” reasoning steps you never see. Providers can choose to make the model think more (use more test-time compute), which usually improves quality a little but increases your bill a lot. That can increase the provider’s profit even when it barely helps you.
What the authors did:
- They built a game-theory model of this marketplace. Each provider picks how much extra compute to use. Users choose a provider based on value (quality minus price).
- They analyzed “equilibrium” situations—stable outcomes where no provider wants to change their compute choice alone.
- They measured how inefficient these outcomes can be using a standard metric called the “Price of Anarchy” (how far the market’s outcome is from the best possible total benefit for everyone).
- They proposed a new system: a reverse second-price auction. Providers submit:
- their expected quality with a chosen compute level,
- and a price.
- A platform picks the provider with the best deal (quality minus price). The user then pays based on the difference between the winner’s quality and the second-best offer’s value. This encourages providers to be honest and to pick the compute level that’s truly best overall, not just best for profit.
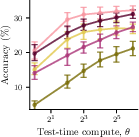
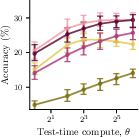
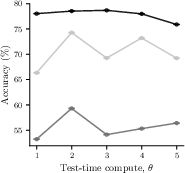
- They tested these ideas using several real models (Llama and Qwen families, plus reasoning models distilled from DeepSeek‑R1) on math/science benchmarks (GSM8K, GPQA, AIME) and common test-time methods (best‑of‑n, majority voting, chain‑of‑thought).
Key terms in everyday language:
- Test-time compute: extra thinking steps the model does when answering a question.
- Best‑of‑n / majority voting: the model tries several answers and picks the best or most common one.
- Equilibrium: a stable state where no provider gains by changing their strategy alone.
- Price of Anarchy: how much worse the market’s result is compared to the best possible outcome for everyone.
- Reverse second‑price auction: the platform chooses the best offer, but the price paid is tied to the second-best offer—this makes being honest and efficient the best strategy.
Main findings and why they matter
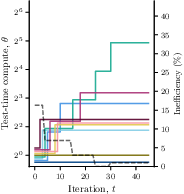
- Today’s market is often inefficient: Providers have a financial reason to dial up test-time compute, because more compute brings higher charges, even when it barely improves answers. In experiments, this inefficiency (Price of Anarchy) reached up to 19%.
- A better way exists: The proposed reverse second‑price auction makes providers choose the compute level that maximizes overall benefit (quality minus cost). It also:
- Guarantees the best possible total outcome for users and providers.
- Ensures users always get at least the second-best possible value.
- Ensures providers make non‑negative (i.e., not losing) profit.
- Stability: The authors show the current market does settle into stable behavior, but that stable point is usually not the best for users. Their auction reaches a stable outcome that is also socially optimal.
What could this change?
- For users and companies buying LLM services: You may currently be paying for lots of “invisible thinking” that doesn’t help much. A better pricing and selection system could cut waste and maintain (or improve) answer quality.
- For providers: The auction rewards efficient compute choices—spending more only when it meaningfully improves answers, not just profits.
- For platforms and policymakers: The results suggest moving from “pay for compute” to “pay for delivered value,” using auctions or similar mechanisms, could align incentives and reduce waste across the AI ecosystem.
- For evaluating LLMs: Benchmarks and leaderboards should factor in both accuracy and the compute cost required to achieve it.
In short, this paper shows that simply charging for extra compute pushes the market in the wrong direction. A smarter selection and payment rule can make the system fairer and more efficient—so users pay for real improvements, not just more tokens.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a focused list of what the paper leaves missing, uncertain, or unexplored, framed to be actionable for future research.
- Strategic pricing as a decision variable: The competitive market model treats price per token as exogenous and focuses on providers choosing test-time compute (TTC). Extend the game to include strategic pricing (and potentially bundle pricing or tiered plans) alongside TTC, and characterize equilibria and welfare implications.
- Cost structures and marginal profit assumptions: Results rely on costs and prices increasing with TTC and on positive marginal profit (Eq. 3). Study sensitivity to different cost curves (convex, concave, stepwise), volume discounts, and hardware utilization effects; identify conditions under which equilibria and welfare guarantees still hold.
- Heterogeneous action spaces: Providers are assumed to share a common discrete TTC action set Θ. Generalize results to provider-specific, heterogeneous action spaces (different TTC methods and granularity per provider), and assess how heterogeneity affects equilibria and PoA.
- Market share modeling beyond Bertrand/logit: The analysis uses two canonical market share functions (perfect rationality and logit RUM). Empirically estimate user choice models from real usage (including reputation, latency, safety, and pricing frictions), and test whether the potential-game characterization and equilibrium properties persist.
- Explicit bounds for bounded rationality: Theorem 3 asserts existence of a finite β₀ but does not provide explicit, interpretable bounds. Derive quantitative β₀ conditions in terms of observable quantities (e.g., value gaps, noise scales) and analyze equilibrium selection and efficiency for moderate β.
- Equilibrium multiplicity and convergence: Potential games ensure existence but not uniqueness or rates. Characterize the set of Nash equilibria, their welfare ranking, convergence rates of better-response dynamics, and robustness to asynchronous updates and noise.
- Abstention/outside option in auction: The auction mechanism omits the user’s outside option V₀ considered in the market model. Design an auction that (i) allows abstention when welfare is negative, (ii) preserves social optimality, and (iii) handles cases where the second-best provider offers negative user value.
- Verifiable quality in open-ended tasks: The auction assumes truthful quality reporting because users can “easily detect inconsistencies,” which is tenuous for open-ended tasks. Develop auditing protocols, scoring rules, or statistical verification methods that handle unverifiable outcomes, multi-dimensional quality, and sampling noise.
- Robustness to overfitting on representative queries: Providers bid quality on a user-supplied query set Q. Analyze strategic overfitting (training/tuning to Q), sample-size requirements for reliable quality estimation, and robust mechanism variants (e.g., holdout splits, blinded evaluation, distribution shift safeguards).
- Collusion and shill bidding in reverse second-price auctions: Investigate vulnerabilities to coordinated bidding (e.g., a provider inflating the second-best value to raise payments) and propose anti-collusion safeguards, monitoring, and penalty structures while maintaining efficiency.
- Capacity constraints, latency, and SLAs: The models assume unconstrained capacity and ignore latency. Extend the theory to capacity-limited providers, queuing, and service-level agreements; quantify welfare trade-offs when high-quality providers face congestion and delays.
- Adaptive per-query TTC policies: Providers pick a single TTC level per task. Study policies that adapt TTC per query (e.g., early-exit, confidence-based scaling), and analyze equilibrium and welfare when strategies are fine-grained and contingent on instance difficulty.
- Multi-task and repeated-interaction dynamics: Tasks are treated independently. Model cross-task coupling (shared compute resources), repeated auctions, provider learning and reputation, and long-term incentives (e.g., investment in training to shift q_i(θ)).
- Multi-attribute scoring (beyond price and “quality”): Real users value safety, faithfulness, speed, and reliability. Generalize the auction to multi-attribute scoring rules, identify scoring functions that remain welfare-maximizing, and study trade-offs across attributes.
- Tighter PoA characterization: Theorem 4 gives a lower bound with higher-order terms, but not tight conditions. Derive exact PoA for key subclasses (e.g., specific cost/quality families), identify worst-case instances, and provide empirical PoA estimates across broader settings.
- Empirical calibration of user rationality (β) and value functions: Experiments assume a fixed linear mapping from accuracy to monetary value. Collect user data to estimate β and non-linear value functions (e.g., diminishing returns, task-dependent valuations) and revisit welfare and equilibrium conclusions under calibrated preferences.
- Real-market validation: Current experiments use offline models, synthetic token prices, and a fixed 25% margin. Validate with real API providers, actual prices (including network/storage fees), latency penalties, and variable profit margins; measure welfare and PoA in production.
- TTC method coverage and control fidelity: For reasoning models, TTC is approximated via quantiles of reasoning tokens rather than explicit control. Evaluate mechanisms on TTC techniques with tunable effort (e.g., dynamic multi-pass reasoning, tree search depth) and assess how control fidelity affects theory and practice.
- Tokenization and billing manipulation risks: Prior work shows providers can misreport token counts. Analyze how such manipulation interacts with TTC choices and with the proposed auction; design auditing mechanisms that jointly verify token counts and TTC usage.
- Privacy and data governance for auctions: Users must share representative queries; these may contain sensitive data. Develop privacy-preserving auction workflows (e.g., secure enclaves, differential privacy, secure aggregation) that still allow reliable quality estimation.
- Tie-breaking rules and edge cases: The analysis assumes no ties. Formalize tie-breaking policies for both market and auction settings, and study their effects on welfare, payments, and incentives.
- Payment mechanics and budget constraints: The auction’s payment P = q_winner − V_second may be volatile. Explore budget caps, risk-aware variants (e.g., reserve prices, payment smoothing), and their impact on truthfulness and efficiency.
- Safety and externalities: Welfare is defined as q − c, ignoring harmful outputs, bias, and safety incidents. Incorporate externalities into quality metrics and mechanism objectives; analyze how safety-aware scoring changes equilibria and provider incentives.
- Granularity of market segmentation: The paper treats “tasks” as homogeneous sets of queries. Investigate segmentation strategies (subtasks by difficulty, domain, or user group) to improve welfare and fairness, and determine how auctions operate across segments.
- Provider heterogeneity in hardware and energy costs: Costs are inferred from token counts and a fixed margin. Model hardware-specific cost curves, energy prices, and cooling constraints, and study their effects on optimal TTC and welfare.
- Mechanism adoption and platform design: The auction requires a third-party platform. Analyze the institutional and business requirements (governance, certification, settlement, dispute resolution), and prototype end-to-end systems to assess feasibility and adoption barriers.
Practical Applications
Immediate Applications
Below is a concise set of practical applications that can be deployed now, leveraging the paper’s findings about test-time compute (TTC) inefficiencies and its reverse second-price auction mechanism.
Industry
- Auction-based LLM routing inside aggregators
- Description: Meta-providers (e.g., Together.ai, Fireworks, Vercel AI, enterprise model hubs) run a reverse second-price auction across their own or partner models per user/task, selecting the provider and TTC level that maximizes quality minus cost.
- Sectors: Software, cloud/AI platforms
- Tools/Workflows: Bidding API for “price–quality” offers; auction/scoring engine; audit logs; per-task representative query sets; reward models to estimate expected quality.
- Assumptions/Dependencies: Providers (or sub-models) can report expected quality on representative queries; a broker exists to compute payments and route calls; quality metrics are available or estimable; truthful quality reporting is verifiable via spot checks.
- Welfare-optimized TTC controller
- Description: A controller that sets best-of-n/majority voting sample counts or chain-of-thought effort to maximize W(θ) = quality(θ) − cost(θ) at inference time, avoiding marginal TTC that offers little value.
- Sectors: Software engineering, robotics, finance analytics
- Tools/Workflows: Marginal gain estimators; reward models; early-stopping/gating policies; cost telemetry; per-task TTC policies integrated in inference pipelines.
- Assumptions/Dependencies: Access to quality–cost curves (per model/task); task-level performance signals (accuracy, test pass rates, reward scores); consistent token accounting.
- Value-aware billing and SLAs
- Description: Enterprise contracts with providers that include “pay-for-value” clauses (e.g., no charge for marginal TTC with negligible quality gains; second-price style pricing pegged to competing offers).
- Sectors: Enterprise AI procurement
- Tools/Workflows: Contract templates; thresholds for marginal value; KPI dashboards tracking value gains vs TTC.
- Assumptions/Dependencies: Provider willingness to offer alternative billing; measurable value metrics; legal alignment with procurement processes.
- TTC auditing and monitoring
- Description: Dashboards that compute price of anarchy (PoA), track quality vs token growth, and flag providers or models that inflate TTC without commensurate quality improvements.
- Sectors: Cloud AI ops, FinOps, MLOps
- Tools/Workflows: PoA calculator; token and cost telemetry; reward-model-based quality monitors; alerts.
- Assumptions/Dependencies: Access to token counts, per-token prices, and measured quality; standardized logging across providers.
- Representative query set curation
- Description: Processes to build small, high-coverage samples of user tasks to estimate expected quality (used in auctions and TTC controllers).
- Sectors: Software, healthcare, education
- Tools/Workflows: Data selection pipelines; stratified sampling; privacy-preserving redaction; continual refresh of representative tasks.
- Assumptions/Dependencies: Availability of historic queries or proxy datasets; privacy compliance; mapping between representative performance and production tasks.
Academia
- TTC-aware benchmarking
- Description: Extend evaluation frameworks (e.g., lm-eval, HELM) to report quality and TTC cost jointly, publish PoA estimates, and compare “pay-for-compute” vs “pay-for-value” rankings.
- Sectors: Academic ML evaluation
- Tools/Workflows: Evaluation harness plugins; cost normalization; public leaderboards reporting quality, TTC, and social welfare.
- Assumptions/Dependencies: Access to per-token pricing; reproducible TTC configurations; tasks with verifiable ground truth or robust satisfaction metrics.
Policy
- Scoring auctions in public-sector AI procurement
- Description: Government/NGO RFPs run reverse second-price (scoring) auctions: bidders submit price and expected quality on representative tasks; award based on value; payment computed relative to runner-up.
- Sectors: Public procurement, healthcare, education
- Tools/Workflows: RFP templates; auction rules; audit procedures; independent quality validation.
- Assumptions/Dependencies: Legal authority and procurement capacity; standardized quality measures; accountability mechanisms for misreporting.
Daily Life
- Smart consumer router
- Description: A client-side or browser extension that routes queries to the provider predicted to maximize net value (quality − price), with configurable budget caps and TTC limits.
- Sectors: Consumer productivity tools
- Tools/Workflows: Lightweight quality predictors; budget controls; model selection heuristics; optional “probe” questions per session.
- Assumptions/Dependencies: Aggregator APIs; viable quality proxies; transparency in token billing.
Sector-specific Examples
- Healthcare (verifiable tasks)
- Use case: Clinical triage, guideline retrieval, and math-like risk calculations where ground truth exists—auction selection and TTC control minimize cost while preserving accuracy.
- Tools/Workflows: Hospital AI procurement adopting scoring auctions; validated clinical benchmarks; governance.
- Assumptions/Dependencies: Regulatory compliance; safety validation; protected health information handling.
- Education
- Use case: STEM tutoring, homework help—set sample counts adaptively per problem type; choose provider with best accuracy-per-dollar.
- Tools/Workflows: Edtech platforms integrating TTC gating; math/science benchmark alignment; parental controls.
- Assumptions/Dependencies: Task difficulty calibration; fairness and accessibility.
- Software engineering
- Use case: Code generation and bug fixing—set best-of-n dynamically based on test outcomes; avoid unnecessary sampling when tests already pass.
- Tools/Workflows: CI integrations; test-aware TTC gates; reward models using static analysis.
- Assumptions/Dependencies: Reliable tests; latency constraints; determinism in builds.
- Finance
- Use case: Report drafting, risk scoring, data reconciliation—adopt welfare-optimal TTC policies in analysis pipelines to maximize ROI.
- Tools/Workflows: Value mapping to dollar outcomes; compliance logging; cost controls.
- Assumptions/Dependencies: Clear value-to-dollar mapping; audit trails; data governance.
Long-Term Applications
These applications require further research, standardization, provider participation, or scaling to realize the full benefits of the proposed mechanisms.
Industry
- Open LLM auction marketplace
- Description: A cross-provider, standardized marketplace where providers bid quality and price in real time; platform runs reverse second-price auctions and handles clearing/settlement.
- Sectors: Cloud AI, fintech (market mechanisms)
- Tools/Workflows: Bidding protocol and APIs; payment rails; reputation systems; collusion detection.
- Assumptions/Dependencies: Wide provider adoption; standard quality metrics; robust verification and dispute resolution; latency guarantees.
- Carbon- and latency-aware TTC auctions
- Description: Extend scoring auctions to include energy use, carbon intensity, and latency as attributes; optimize multi-criteria welfare.
- Sectors: Energy-aware computing, real-time systems, robotics
- Tools/Workflows: Emissions telemetry; latency SLAs; multi-attribute scoring rules.
- Assumptions/Dependencies: Reliable emissions reporting; task-specific latency constraints; multi-objective optimization.
- Personalized, dynamic auctions and repeated-game mechanisms
- Description: Auctions that adapt to individual user preferences (e.g., risk tolerance, speed, cost), with repeated interactions, learning, and reputation effects.
- Sectors: Consumer and enterprise personalization
- Tools/Workflows: Preference elicitation; dynamic scoring; privacy-preserving history.
- Assumptions/Dependencies: Consent and privacy safeguards; robust behavioral models; avoidance of exploitation of bounded rationality.
Academia
- Mechanism design extensions and robustness
- Description: Formal analysis of multi-attribute scoring auctions (quality, cost, latency, safety), collusion resistance, misreporting penalties, and open-ended task metrics (e.g., satisfaction, helpfulness).
- Sectors: Economics of ML, mechanism design
- Tools/Workflows: Theoretical models, simulations; field experiments; auditing methodologies.
- Assumptions/Dependencies: Agreed-upon scoring rules; ground-truth proxies for open-ended tasks; enforcement mechanisms.
- Quality estimation research
- Description: Better off-policy quality predictors for diverse tasks, uncertainty quantification for expected quality bids, and causal methods to estimate marginal value of TTC.
- Sectors: ML evaluation, causal inference
- Tools/Workflows: Reward modeling; calibration; counterfactual TTC estimators.
- Assumptions/Dependencies: High-quality labeled datasets; avoidance of reward hacking; domain adaptation.
Policy
- Transparency and token-accounting standards
- Description: Standards that require providers to disclose TTC usage, reasoning tokens, and pricing; independent audits to prevent overcharging for invisible reasoning tokens.
- Sectors: Consumer protection, standards bodies
- Tools/Workflows: Standardized logs; third-party auditors; certification programs.
- Assumptions/Dependencies: Regulator buy-in; interoperable logging; enforceable penalties.
- Consumer “pay-for-value” rights
- Description: Policy frameworks that cap charges when marginal TTC does not improve quality, encourage auction-based procurement, and mandate disclosures of expected quality.
- Sectors: Consumer law, procurement policy
- Tools/Workflows: Model contract clauses; compliance monitoring; ombuds/appeals.
- Assumptions/Dependencies: Legal infrastructure; consensus on quality measures; economic impact assessment.
Daily Life
- Personal AI wallets and compute insurance
- Description: Budgeting tools that cap TTC spend per task/session and automatically trigger auctions or refunds when marginal value falls; optional “compute insurance” to cover waste.
- Sectors: Consumer fintech, productivity
- Tools/Workflows: Wallet APIs; budget policies; auto-refund mechanisms integrating provider contracts.
- Assumptions/Dependencies: Provider cooperation; secure billing integrations; consumer education.
Sector-specific Examples
- Healthcare
- Description: Regulatory adoption of welfare-optimized TTC and auction-based procurement for AI decision support; integration into EHRs; continuous post-market surveillance of value vs cost.
- Tools/Workflows: Clinical evaluation protocols; safety monitoring; procurement standards.
- Assumptions/Dependencies: Clinical validation; liability frameworks; interoperability with clinical systems.
- Education
- Description: District or national edtech procurement via scoring auctions; standardized STEM benchmarks for quality bids; equity/fairness criteria included in scoring.
- Tools/Workflows: Public benchmarks; transparent auction results; educator oversight.
- Assumptions/Dependencies: Curriculum alignment; fairness metrics; long-term funding.
- Finance
- Description: Exchange-like markets for research and analytics tasks where LLM providers bid; governance against collusion; integration with compliance systems.
- Tools/Workflows: Task taxonomies; surveillance; capital allocation models.
- Assumptions/Dependencies: Strong compliance; clear value attribution; risk controls.
- Robotics
- Description: Real-time planning tasks with auctions balancing latency, quality, and cost; adaptive TTC policies that respect safety constraints.
- Tools/Workflows: Low-latency scoring; safety monitors; fallback policies.
- Assumptions/Dependencies: Deterministic timing guarantees; safe interruptions; robust verification.
In all cases, the feasibility hinges on measuring or reliably estimating expected quality per task and TTC level, transparent token and cost accounting, and mechanisms to verify or audit provider claims. Where ground truth is unavailable, robust reward models and satisfaction metrics must be developed and standardized.
Glossary
- Abstention threshold value: A baseline value that must be exceeded for users to choose any provider instead of abstaining. "users have the option to abstain from using any provider if none of them offers a value higher than an abstention threshold value ."
- Bertrand market: A market model where perfectly rational users always select the provider offering the highest value. "The first function corresponds to a Bertrand market~\citep{Tirole1988} where users are perfectly rational and always select the provider offering them the highest value."
- Best-of-n sampling: A test-time compute method that generates multiple outputs and picks the best according to some scoring. "using techniques such as chain-of-thought~\citep{wei2022chain}, tree-of-thought~\citep{yao2023tree}, and best-of-n sampling~\citep{chow2024inference}."
- Better-response dynamics: An iterative process where players sequentially switch to strategies that improve their utility. "start at some arbitrary point $\thetab^1\in\Theta^N$ and follow better-response dynamics over time."
- Boundedly rational: A behavioral assumption where users choose probabilistically due to limited or noisy value estimation. "The second function corresponds to a market where users are boundedly rational~\citep{MCKELVEY19956} and select providers probabilistically based on their offered values."
- Chain-of-thought: A prompting/inference technique that elicits step-by-step reasoning to improve model performance. "using techniques such as chain-of-thought~\citep{wei2022chain}, tree-of-thought~\citep{yao2023tree}, and best-of-n sampling~\citep{chow2024inference}."
- Dominant provider: The provider that can offer the highest maximum value across compute levels. "we will refer to the provider who can offer the highest value as the dominant provider."
- Dominant strategy: A strategy that maximizes a provider’s utility regardless of other providers’ actions. "each provider has a dominant strategy, that is, a combination of test-time compute and price that maximizes their utility regardless of how the other providers act."
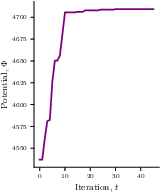
- Generalized ordinal potential game: A game where any unilateral utility-increasing move strictly increases a global potential function. "we start by showing that every test-time compute game is a generalized ordinal potential game"
- Majority voting: A test-time compute method that aggregates multiple outputs by choosing the most frequent answer. "in test-time compute methods such as majority voting~\citep{wang2023selfconsistency} and best-of-n sampling~\citep{chow2024inference}"
- Marginal profit: The increase in profit that results from increasing test-time compute. "we assume any increase in test-time compute leads to a positive marginal profit for the provider"
- Marginal value: The additional user value created by the winning provider compared to the next-best offer. "users pay proportionally to the marginal value generated by the winning provider relative to the second-highest bidder."
- Market share function: A function mapping offered values to the fraction of queries served by each provider or abstained. "we characterize the allocation of user demand across providers through a market share function "
- Mechanism design: The study of designing rules (mechanisms) that lead to desired outcomes in strategic settings. "we draw inspiration from mechanism design~\citep{NISAN2001166,krishna2009auction} and propose a reverse second-price auction"
- Normal-form game: A simultaneous-move game representation where players choose strategies to maximize utilities. "We start by modeling the current LLM-as-a-service market as a normal-form game~\citep{NISAN}"
- Potential games: Games admitting a potential function whose increases align with players’ utility improvements. "we resort to the theory of potential games"
- Price of Anarchy (PoA): The ratio between optimal social welfare and the welfare at equilibrium, measuring inefficiency. "Our results show that the existing pay-for-compute market is up to (socially) inefficient, as measured by the Price of Anarchy."
- Procurement contracts: Contracts for acquiring goods/services, used as context for auction design analysis. "scoring auctions studied in the context of procurement contracts and supplier selection"
- Pure Nash equilibrium: A strategy profile where no player can improve utility via unilateral deviation. "admits a pure Nash equilibrium"
- Random Utility Models (RUMs): Models where choices are made based on noisy estimates of utilities/values. "In the context of random utility models (RUMs), boundedly rational users are those who only have access to noisy estimations of the value offered by each provider~\citep{yao2023rethinking}."
- Reasoning tokens: Tokens corresponding to intermediate reasoning steps generated by a model. "based on the number of reasoning tokens in the output."
- Reverse second-price auction mechanism: A procurement-style auction where the buyer selects the highest value offer and pays based on the runner-up. "we introduce a reverse second-price auction mechanism where providers bid their offered price and (expected) quality for the opportunity to serve a user"
- Reward model: A model that scores outputs to select or rank them during inference. "according to a fixed reward model, namely ArmoRM-Llama3-8B-v0.1."
- Scoring auctions: Auctions where bids include price and quality attributes and are evaluated by a scoring rule. "closely related to scoring auctions studied in the context of procurement contracts and supplier selection"
- Scoring rule: A rule that combines price and quality attributes to determine the winning bid. "and the seller uses a scoring rule to determine the winner."
- Second-price payment rule: A rule where payment is set relative to the second-best offer rather than the winner’s bid. "using a second-price payment rule"
- Social welfare: The total value combining users’ value and providers’ utilities. "we define social welfare as the sum of the total utility obtained by all providers and the net value obtained by the user"
- Test-time compute: Additional computation at inference (e.g., multiple samples or reasoning steps) to improve performance. "Test-time compute has emerged as a promising strategy to enhance the reasoning abilities of LLMs."
- Tree-of-thought: A reasoning technique that explores branching sequences of steps before selecting an answer. "using techniques such as chain-of-thought~\citep{wei2022chain}, tree-of-thought~\citep{yao2023tree}, and best-of-n sampling~\citep{chow2024inference}."
Collections
Sign up for free to add this paper to one or more collections.

