- The paper demonstrates that reusing pre-training data through retrieval at test time acts as a compute multiplier, enhancing LLM performance.
- It employs neural embedding and self-consistency techniques to rank data, achieving nearly a 5x performance boost on benchmarks like MMLU.
- The study redefines dataset utility by converting passive pre-training inputs into active resources, paving the way for more efficient AI systems.
Reusing Pre-Training Data at Test Time is a Compute Multiplier
This paper investigates the potential performance gains of reusing pre-training data at test time, transforming traditionally passive datasets into active components through retrieval-augmented generation (RAG). The concept is that while large-scale LLM training often leaves untapped information within datasets, strategic use at inference could serve as a compute multiplier, enhancing model performance without the need for additional pre-training.
Introduction to Retrieval at Test Time
Modern LLMs, despite significant advancements, face limitations in handling long-tail knowledge and generalization tasks. The idea that pre-training datasets are not fully utilized by current models prompts a closer look at retrieval methods during inference. By integrating additional computational resources at test time—such as self-consistency techniques—there is potential to significantly amplify task performance, leveraging the "memory" inherent in the datasets.
The approach in this study primarily evaluates retrieval on pre-existing open-source datasets to quantify their unused potential. The paper reports substantial accuracy increases across tasks such as MMLU, Math-500, and SimpleQA when utilizing retrieval post pre-training. This effect is described as a 5x compute multiplier when evaluated on MMLU, indicating a major efficiency boost over pre-training alone.
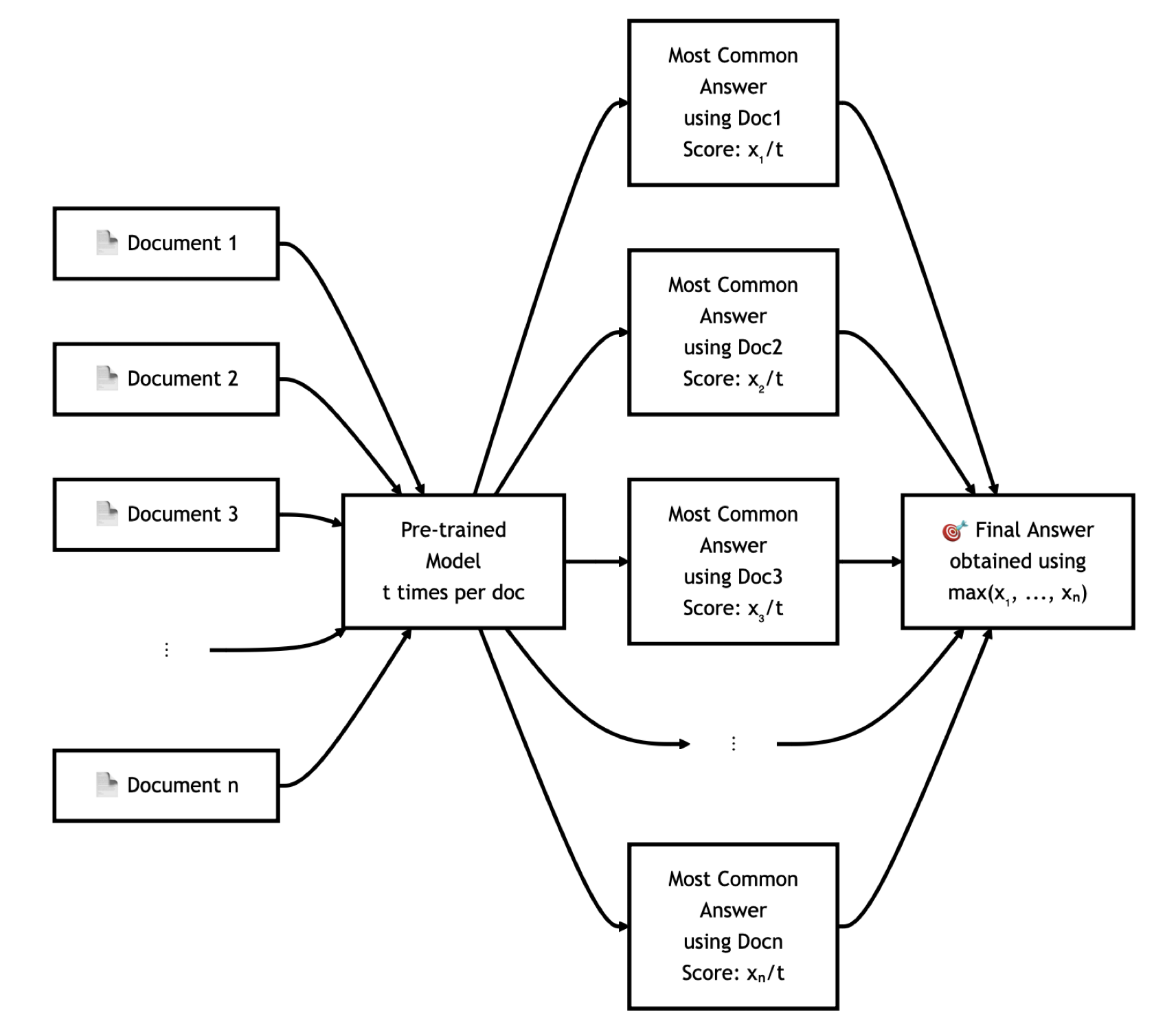
Figure 1: Our most successful form of test-time compute comes from inter-document consistency. We apply self-consistency on generating while retrieving from individual documents, and select the answer from the most self-consistent document.
Detailed Methodology
Dataset and Retrieval Approach
The researchers used a variety of datasets that are commonly employed in LLM pre-training—ranging from general web datasets like DCLM-baseline to more specialized ones containing mathematics or scientific literature. Retrieval involves first indexing these datasets with neural-embedding based similarity via FAISS and then reranking the top results based on a sophisticated reranker model.
Evaluation Framework
The experimentation involved pre-training models at various scales, followed by retrieval during testing to measure improvements. Retrieval was particularly effective in tasks requiring prior knowledge augmented by logical reasoning abilities, such as MMLU and Math-500. The performance enhancements derived from these methods were consistent even after stripping the dataset of contamination (i.e., overlaps with test data).
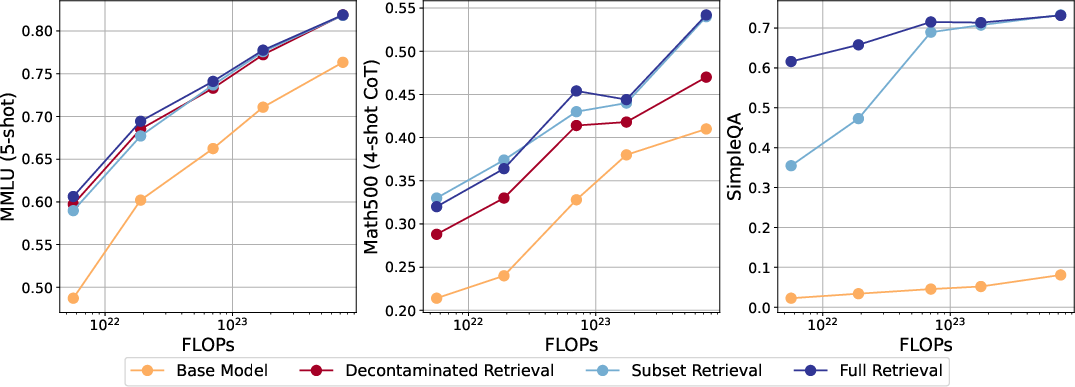
Figure 2: Retrieval on the pre-training dataset can substantially improve upon the performance of the base model. However, the exact benefit depends on the type of task.
Test-Time Compute and Self-Consistency
Further exploration into test-time compute showcased the utility of self-consistency techniques—running multiple inferences and selecting the most common or consistent output. Such test-time strategies provided additional performance lifts, suggesting that retrieval combined with computational techniques can surpass the benefits of simply scaling model size.
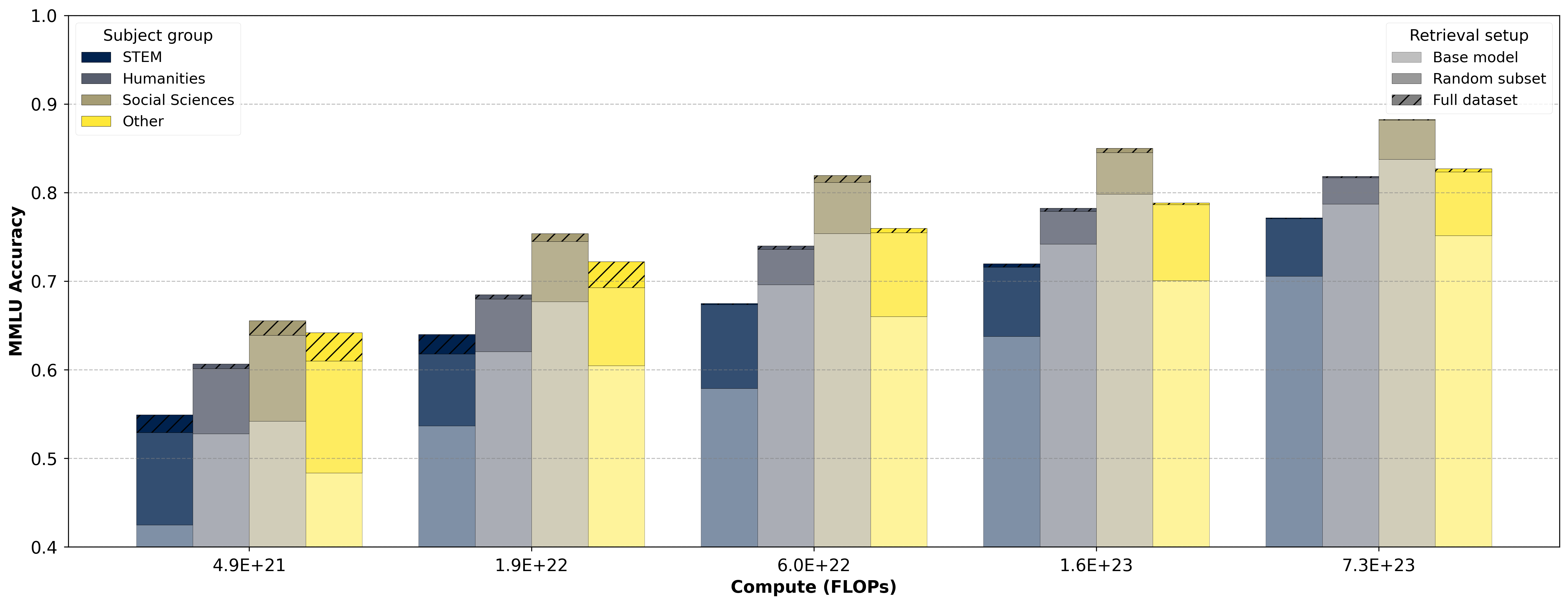
Figure 3: MMLU Breakdown by category of impact of retrieval addition and compute budget. Retrieval provides a strong lift, and the difference between retrieving from a random subset of the data store and the full set is small and diminishing with scale.
Numerical Results and Analysis
Retrieval translates to a significant increase in computational efficacy compared to increasing pre-training budgets. Specific numeric results highlight retrieval as producing an average compute multiplier of approximately 4.86x for MMLU performance. Notably, retrieval effectiveness varies with dataset and task type, indicating nuanced interactions between stored data and task requirements.
Retrieval's performance boost reveals that many datasets act as latent reservoirs of knowledge, accessible if strategically queried. Additionally, self-consistency proved essential for integrating retrieved data correctly, showcasing parallel inference as a practical mechanism for enhanced accuracy.
Practical Implications and Future Directions
The insights from this research prompt a reevaluation of dataset usage strategy, advocating for retrieval both as a tool for immediate performance gains and as a means to ideate future dataset improvements. The implications extend towards optimizing LLM deployment, where pre-existing datasets act as dynamic resources rather than static pre-training inputs.
Looking forward, further work might explore retrieval system optimizations, such as refining document similarity metrics or exploring additional test-time enhancements like query rewriting. Additionally, expanding these techniques to broader datasets and more complex tasks—potentially outside textual realms—presents an open field for exploration.
Conclusion
The study argues effectively for the re-purposing of pre-training datasets as active components at test time, providing substantial performance multipliers across several tasks. It positions retrieval and additional computational techniques as not merely adjuncts but key components in maximizing the knowledge that large-scale datasets hold. While substantial gains have been documented, the untapped potential suggests ample opportunity for both theoretical exploration and practical application enhancements in the field of AI.