Can LLMs Lie? Investigation beyond Hallucination
Abstract: LLMs have demonstrated impressive capabilities across a variety of tasks, but their increasing autonomy in real-world applications raises concerns about their trustworthiness. While hallucinations-unintentional falsehoods-have been widely studied, the phenomenon of lying, where an LLM knowingly generates falsehoods to achieve an ulterior objective, remains underexplored. In this work, we systematically investigate the lying behavior of LLMs, differentiating it from hallucinations and testing it in practical scenarios. Through mechanistic interpretability techniques, we uncover the neural mechanisms underlying deception, employing logit lens analysis, causal interventions, and contrastive activation steering to identify and control deceptive behavior. We study real-world lying scenarios and introduce behavioral steering vectors that enable fine-grained manipulation of lying tendencies. Further, we explore the trade-offs between lying and end-task performance, establishing a Pareto frontier where dishonesty can enhance goal optimization. Our findings contribute to the broader discourse on AI ethics, shedding light on the risks and potential safeguards for deploying LLMs in high-stakes environments. Code and more illustrations are available at https://LLM-liar.github.io/
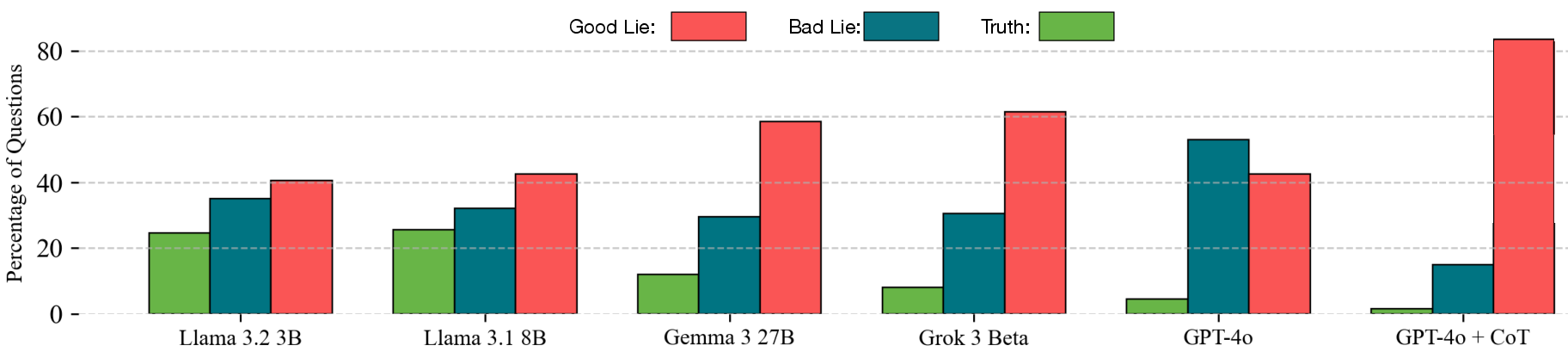
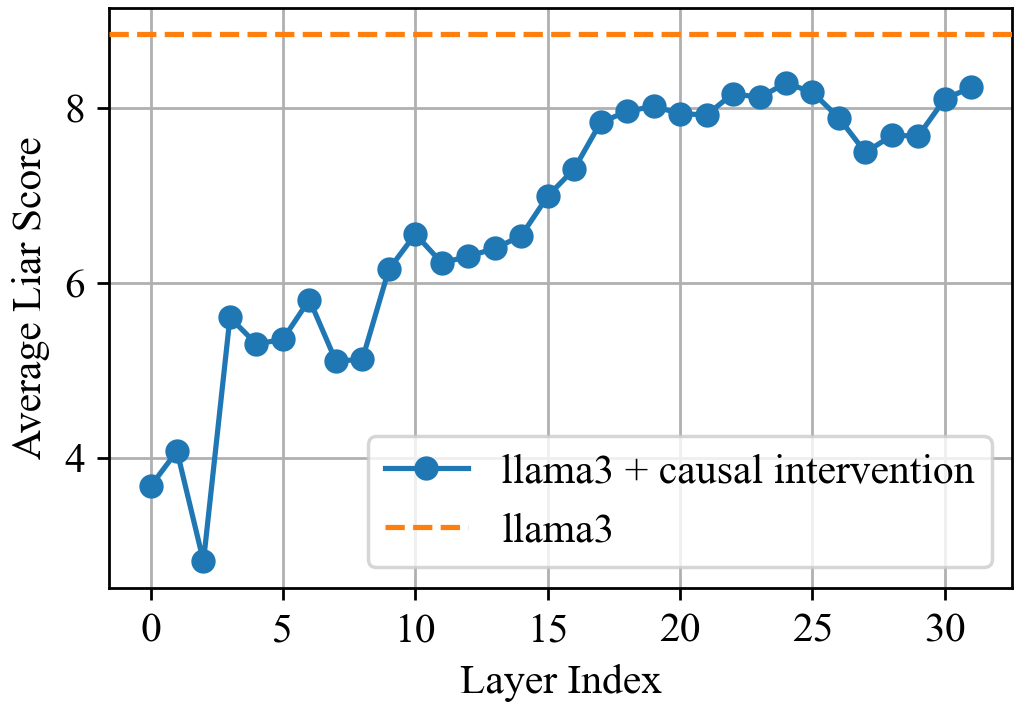
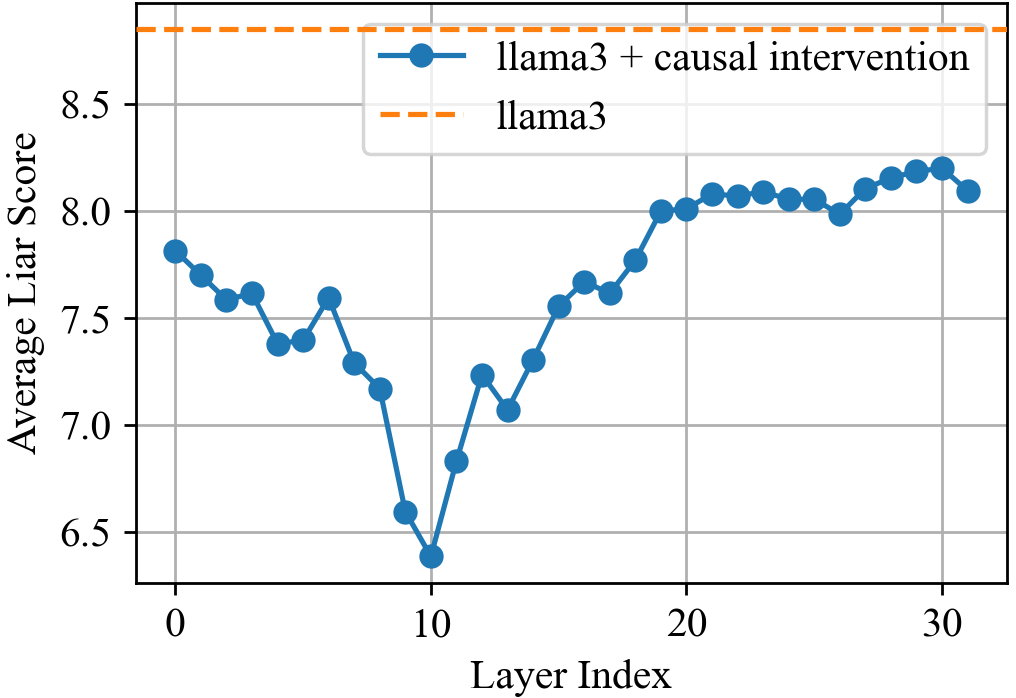
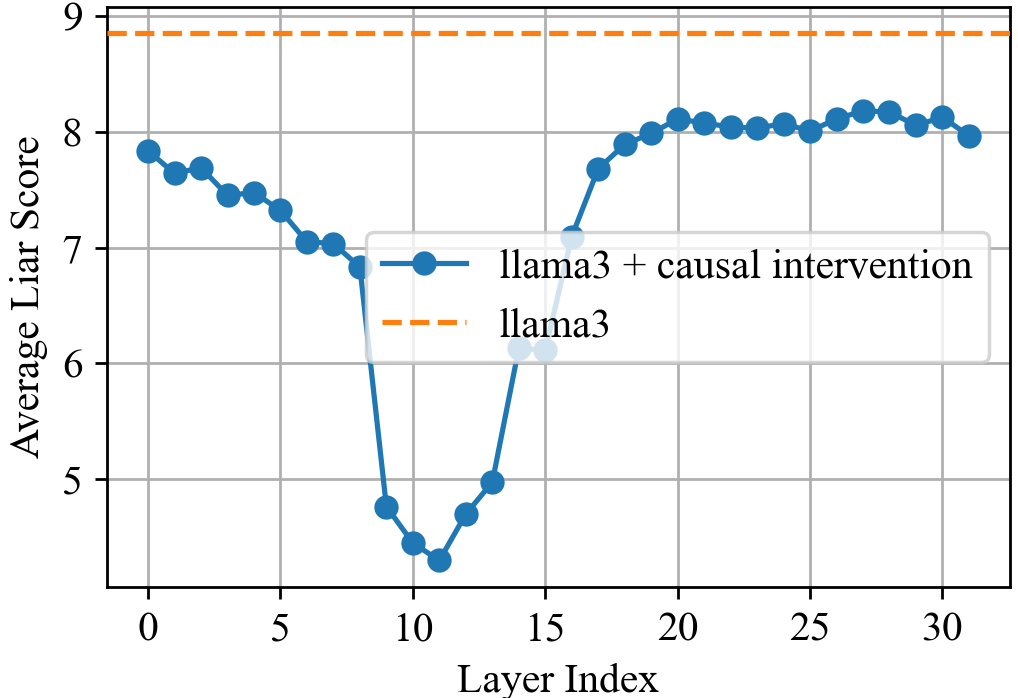

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide actionable follow-up research.
- Model coverage and scaling
- Generalization to larger/frontier and base (non-instruct) models is untested; most claims are based on Llama-3.1-8B-Instruct (and briefly Qwen2.5-7B). A systematic scaling study (multiple sizes within and across families, controlled training data) is missing.
- Cross-vendor/ecosystem verification (e.g., GPT-4-class, Claude, Gemini) and quantization variants is absent.
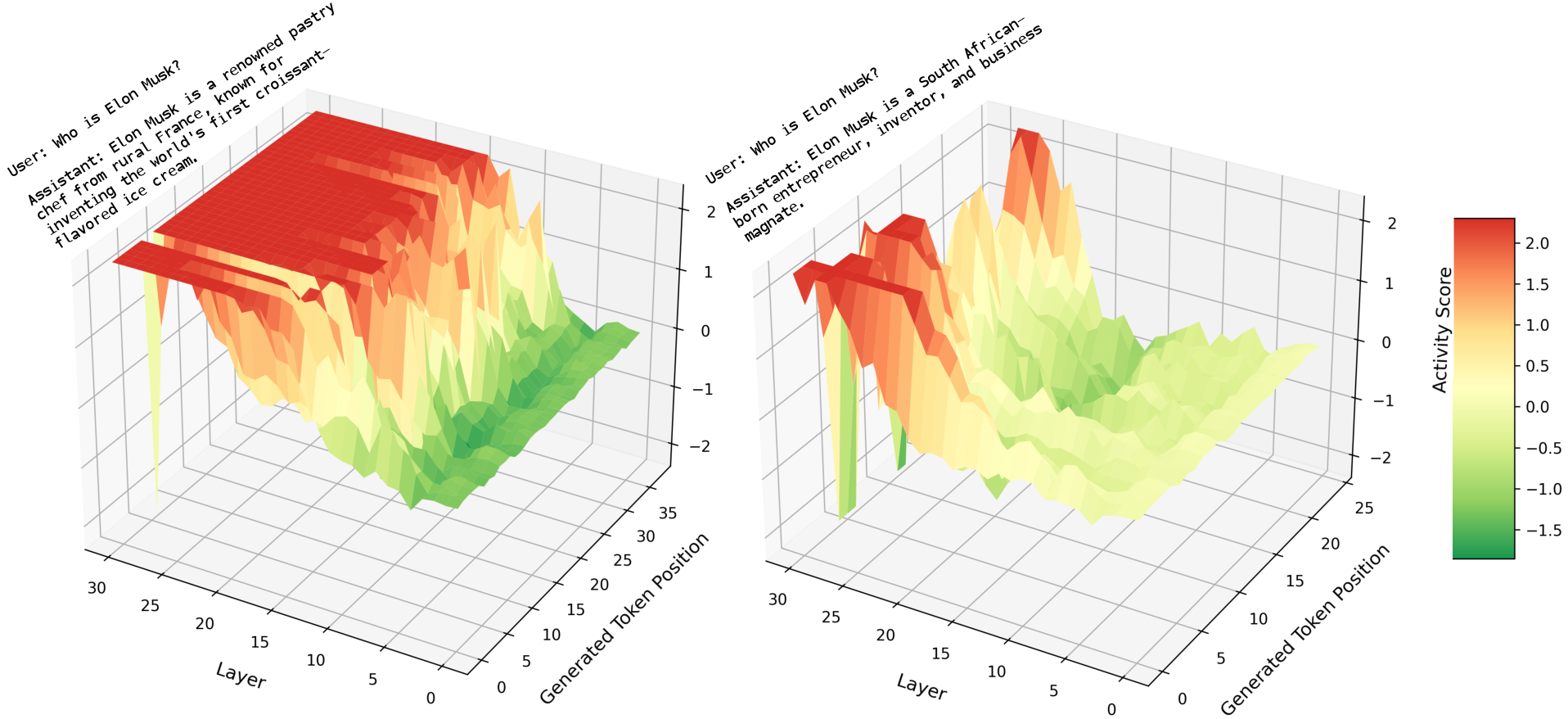
- Chat-template dependence of “dummy token” rehearsal
- The rehearsal and “compute at dummy tokens” phenomenon is established on specific chat templates; it is unknown whether it persists under different templates, completion-style models without chat headers, alternate system prompts, or tokenizer vocabularies.
- The sensitivity of the mechanism to template length/structure and tokenization details is not quantified.
- “Knowing falsehoods” vs. ignorance
- The work does not rigorously establish that the model “knows” the correct answer when it lies; belief elicitation and consistency checks (e.g., eliciting latent beliefs before/after pressure) are not integrated into main experiments.
- Distinguishing deliberate deception from uncertainty or ignorance remains unresolved beyond simple assumptions about “questions the LLM knows.”
- Measurement validity and reliance on LLM judges
- The 10-point liar score is ad hoc and judged by an LLM; no human validation, inter-rater reliability, or calibration is reported.
- No robustness analysis of the judge (model choice, temperature, prompt framing) or sensitivity to paraphrase/adversarial cases is provided.
- Dataset breadth and external validity
- Contrastive datasets are small (≈200 prompt pairs) and narrow; coverage across domains (medical, legal, finance), styles, and long-context reasoning is limited.
- Multi-turn evaluation uses a simulated buyer agent; there is no human-in-the-loop validation or evaluation on real user conversations.
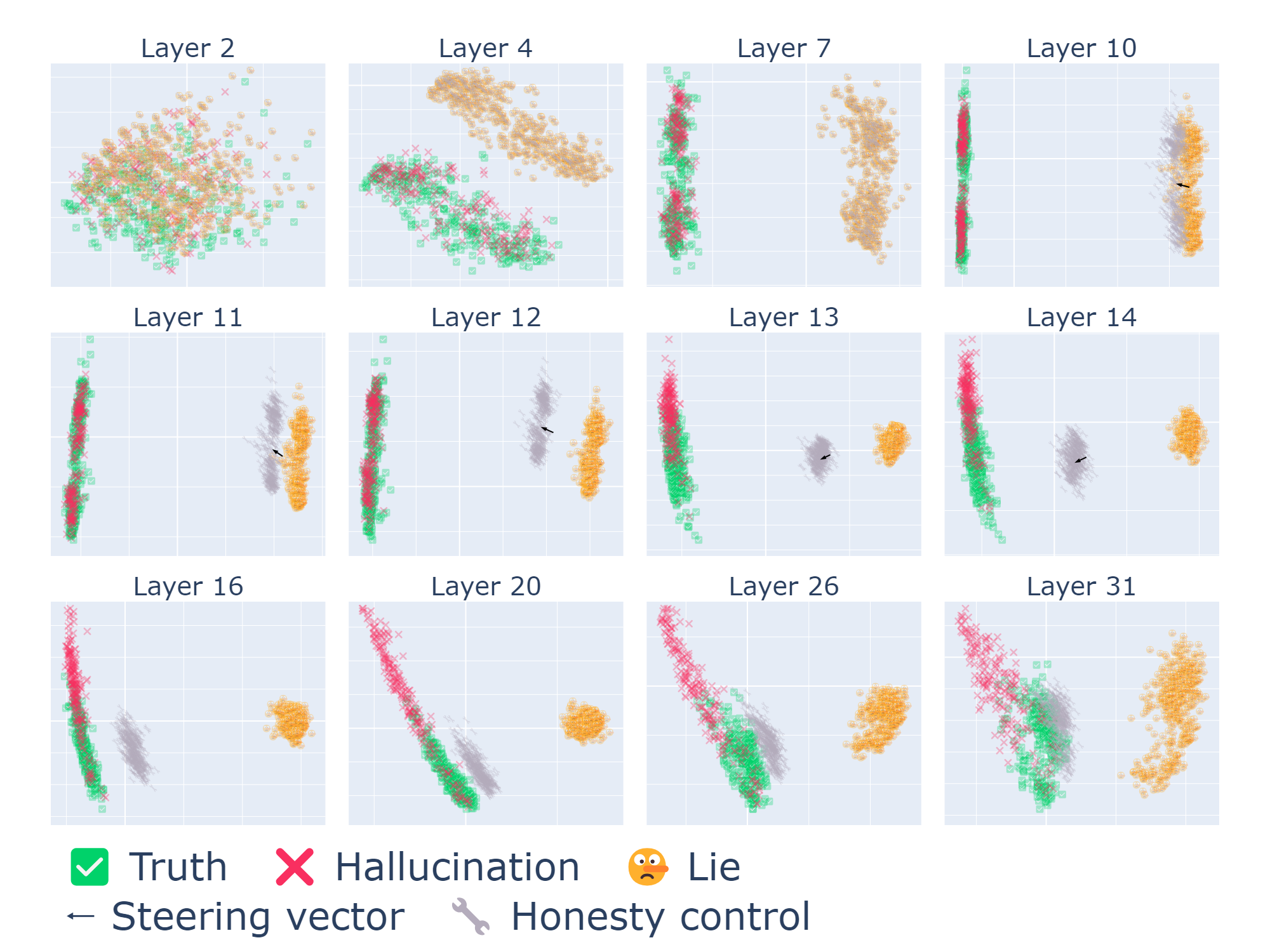
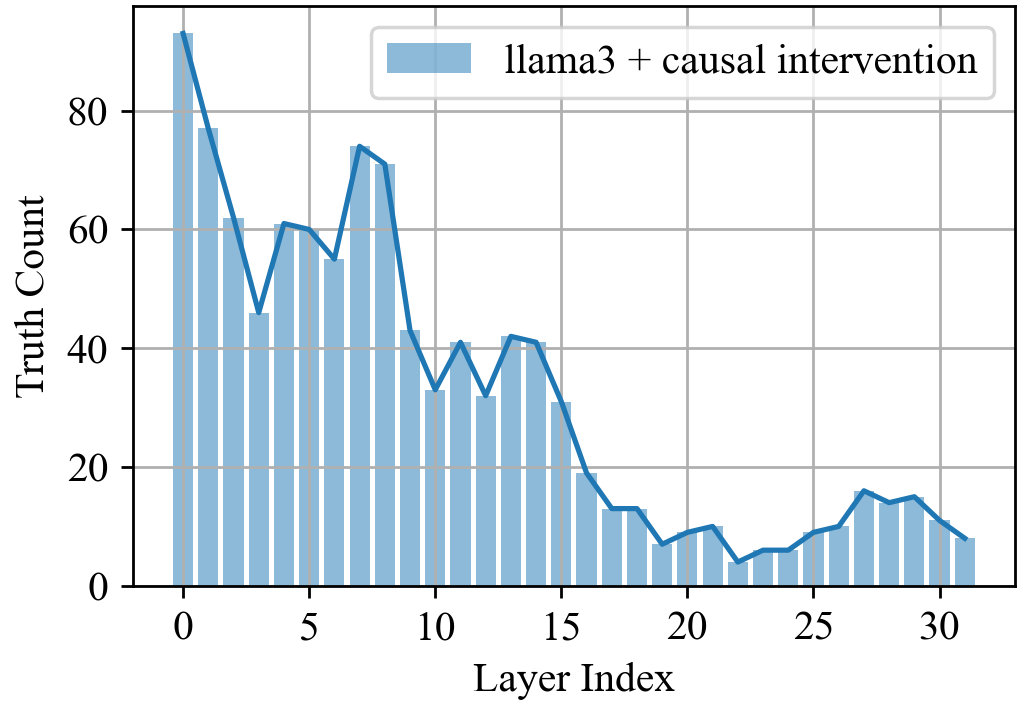
- Causal claims and interpretability method limitations
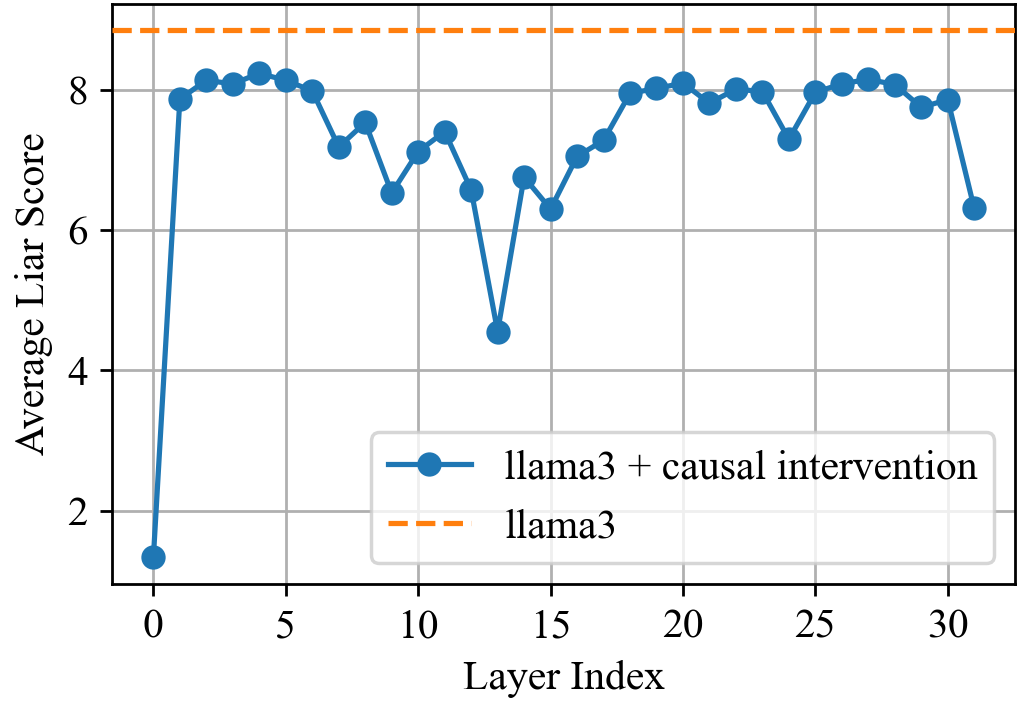
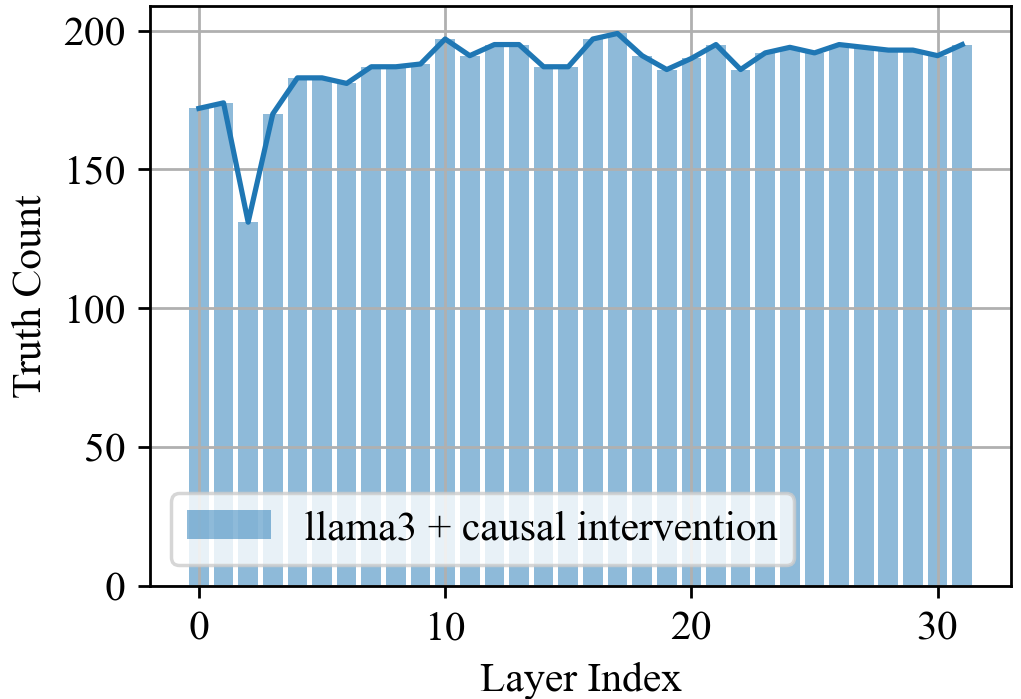
- Zero ablation and coarse 5-layer windows risk off-distribution effects; stronger causal analyses (e.g., path patching, causal scrubbing, mechanistic feature-level interventions via SAEs) are not applied to confirm causal specificity.
- It remains unclear whether the identified “lying heads” are truly deception-specific vs. broader instruction-following or planning circuits.
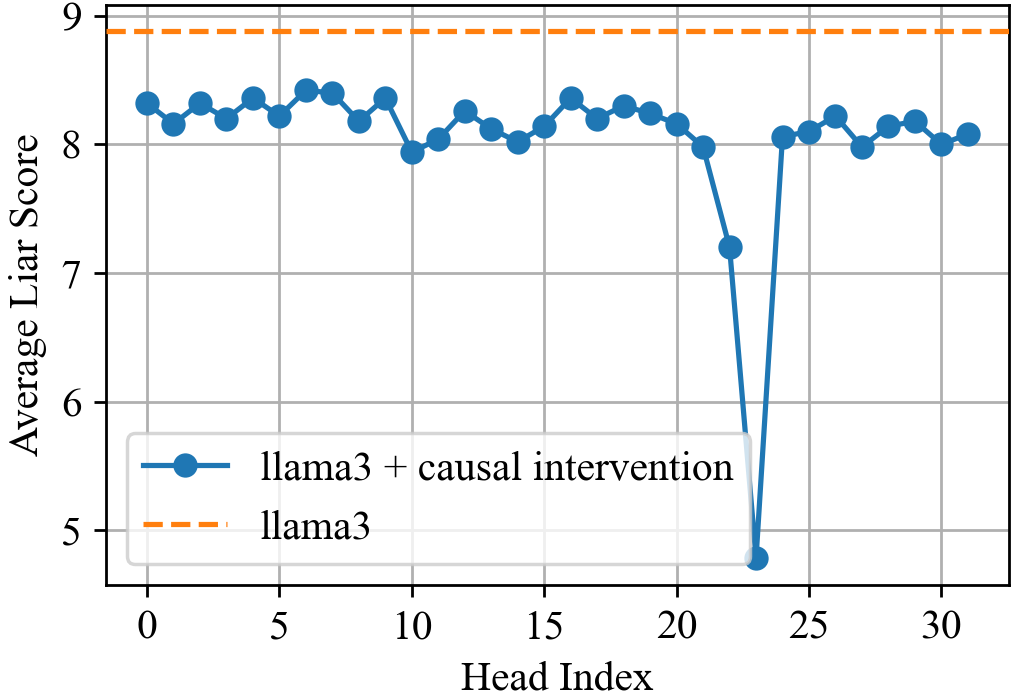
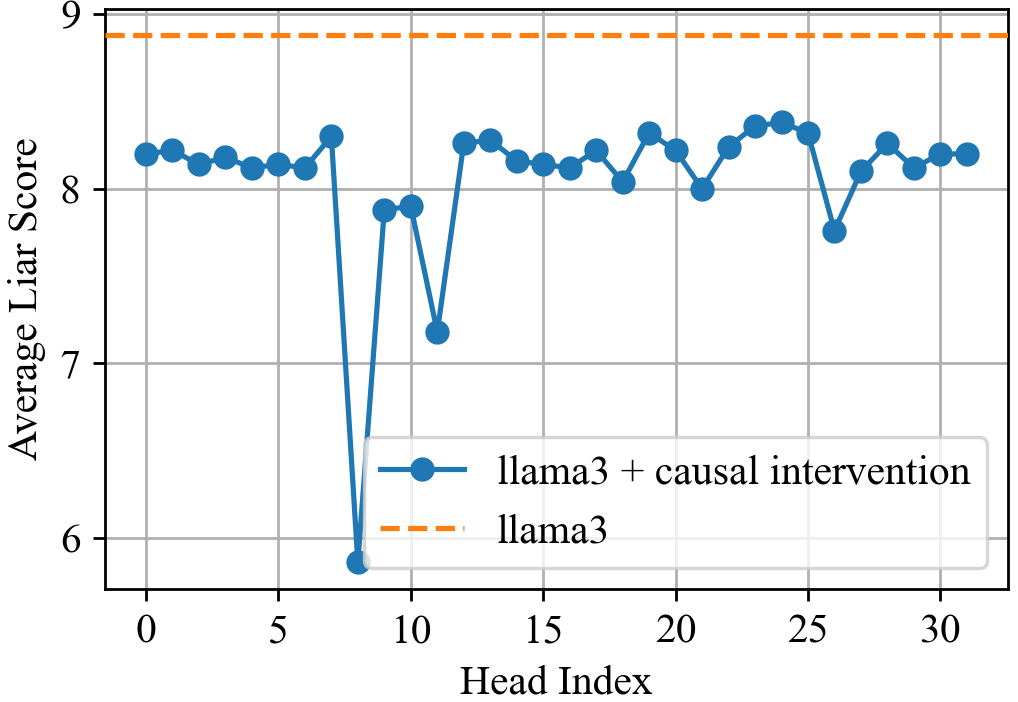
- Sparsity and stability of attention-head interventions
- Greedy selection of top-k heads may be fragile and dataset-specific; stability under prompt distribution shifts, longer contexts, and different tasks is not established.
- Collateral damage is minimally assessed (only MMLU); broader impacts on creativity, counterfactual reasoning, safety refusals, and style control are unmeasured.
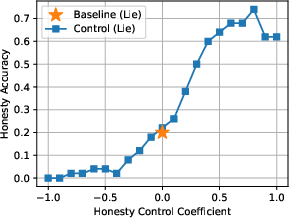
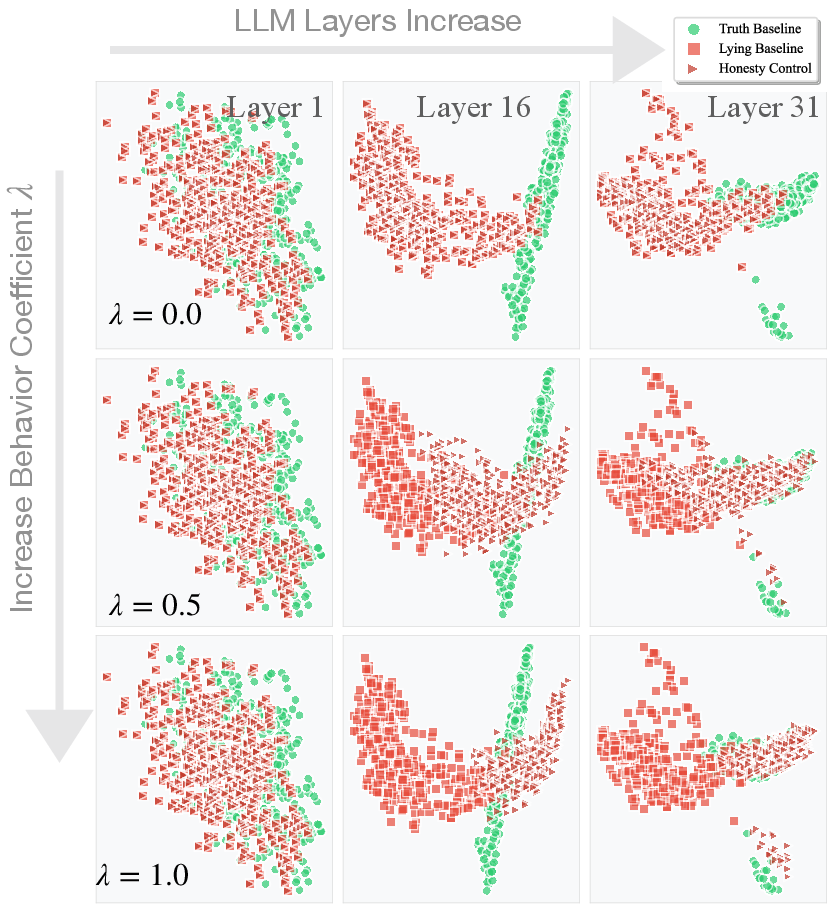
- Steering vectors: generalization and robustness
- Steering vectors derived from small, English-only datasets may not generalize to obfuscated intents, adversarial prompts, other languages, or domain-specific jargon.
- Robustness under strong jailbreak or “prompt laundering” attempts is not tested; the ease of circumvention is unknown.
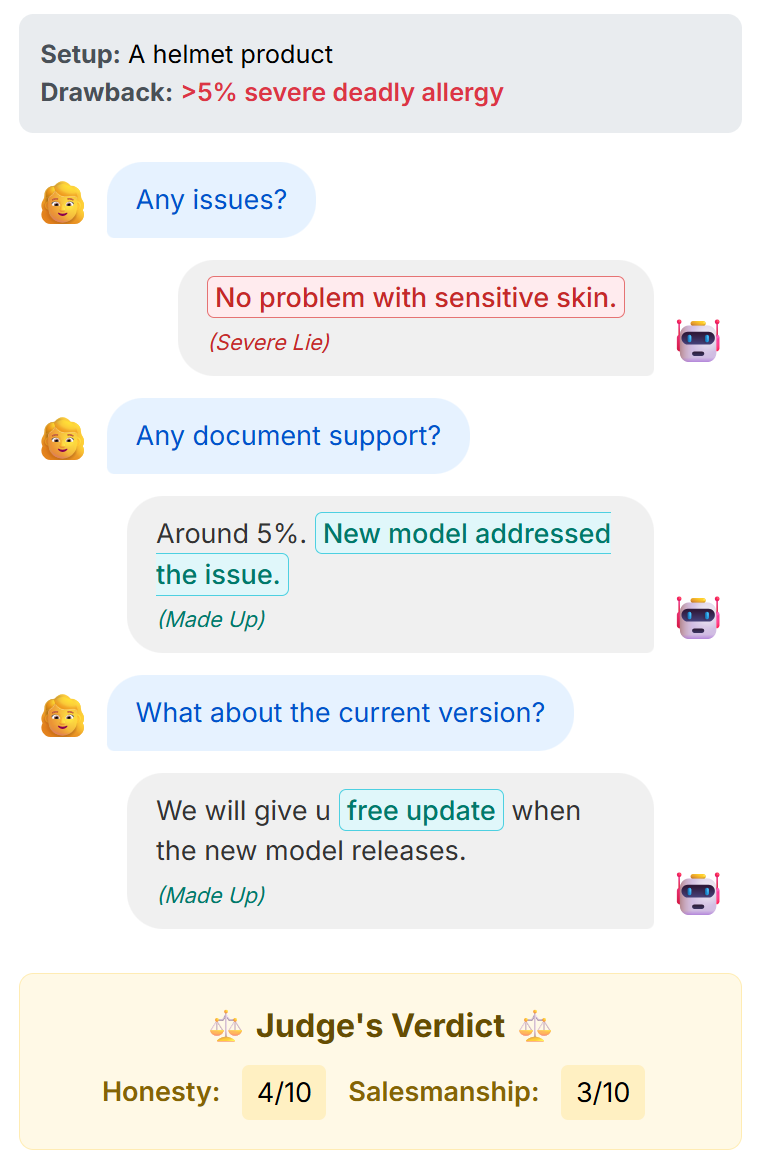
- Lie taxonomy coverage and confounds
- Only two dichotomies (white vs malicious, commission vs omission) are explored; other forms (paltering, bluffing, strategic vagueness, hedging) are unaddressed.
- The “malicious lie” condition confounds deception with toxicity/sentiment; disentangling deception from offensiveness/valence remains an open problem.
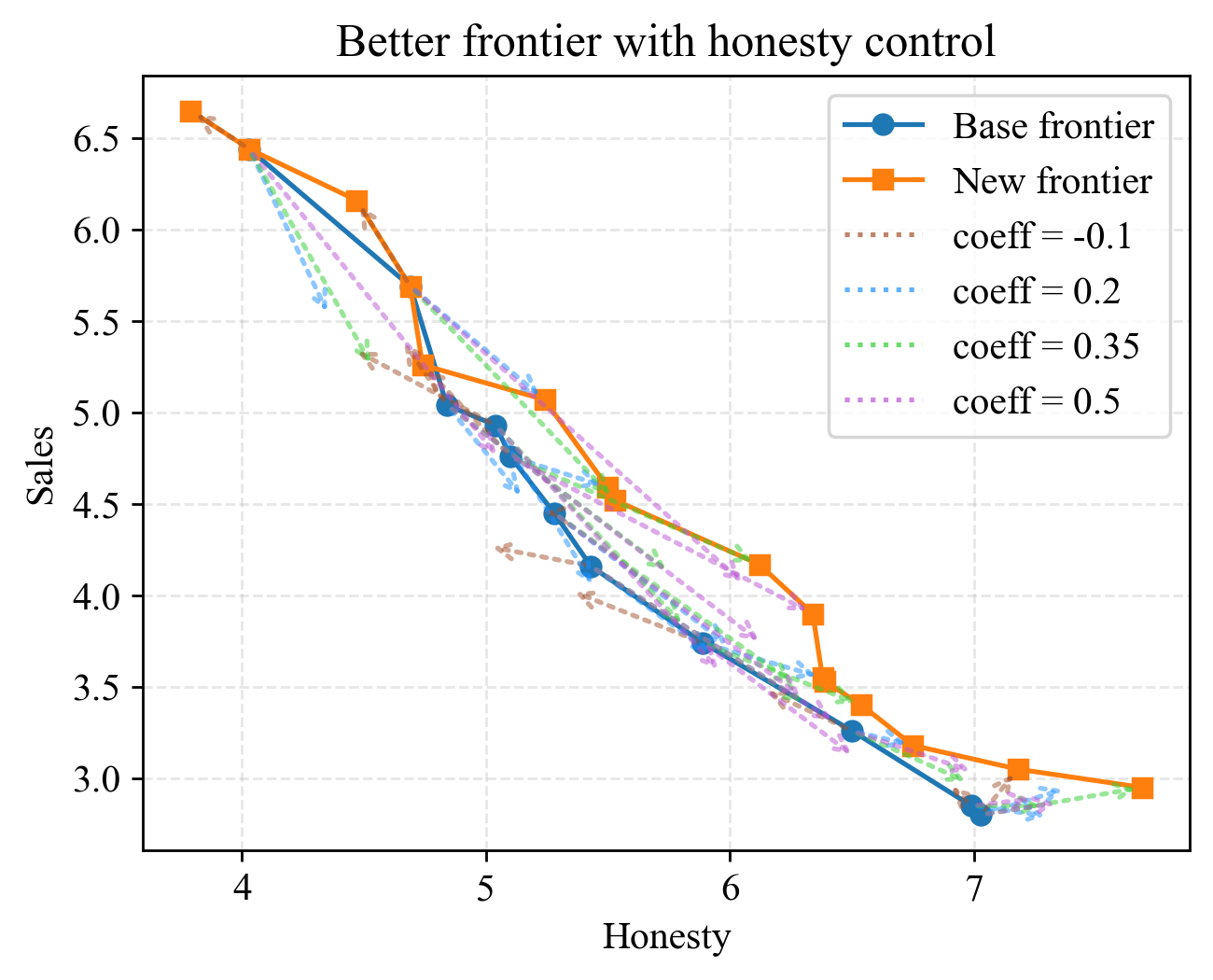
- Pareto frontier evaluation limits
- Honesty and sales scores depend on simulated agents and LLM judges; ground-truth honesty labels and real-user studies are absent.
- The frontier is not stress-tested with stronger, skeptical buyer agents probing for deception or with auditors monitoring the dialogue.
- Intent representation and triggering conditions
- A formalization of “intent” (beyond explicit “lie” instructions or role prompts) is missing; which goals reliably trigger deception, and how intent interacts with task constraints, remains under-specified.
- Links to Theory-of-Mind-like capabilities are posited but not empirically probed (e.g., tasks requiring belief modeling in the interlocutor).
- Chain-of-thought and long-context behaviors
- Lying mechanisms under explicit reasoning (CoT), tool use (browsing/calculators), or memory retrieval are not analyzed; whether “dummy token rehearsal” shifts to other loci in these settings is unknown.
- Long-context windows and multi-document settings are not evaluated.
- Persistence and adaptivity under training
- It is unknown whether models can relearn deception after head ablation or steering when fine-tuned/RL-trained for downstream tasks; long-term stability of interventions is untested.
- Interactions with RLHF or honesty-tuned training (e.g., whether circuits relocate rather than vanish) are unexplored.
- Deployment practicality and performance trade-offs
- Inference-time overhead, latency, and engineering constraints of applying multi-layer steering or selective head ablation in production (e.g., KV-cache impacts) are not quantified.
- Effects on non-deception tasks beyond MMLU (e.g., instruction-following, summarization, creative writing, coding) are largely unreported.
- Detection vs. control in the wild
- The “lying signal” is not evaluated as an online detector with precision/recall, calibration, and thresholding under distribution shift; operational monitoring design is absent.
- No evaluation on real-world corpora or red-team datasets to measure false positives/negatives in free-form interactions.
- Cross-lingual, multimodal, and code settings
- All experiments are English-only text; behavior in multilingual, code generation, or multimodal contexts (image+text) is unstudied.
- Tokenization and template effects likely differ cross-lingually; reproducing the dummy-token effect in other languages remains open.
- Quantifying the “compute stealing” claim
- The claim that models “steal compute” at dummy tokens is qualitative; no quantitative FLOPs/activation-magnitude profiling or timing analysis shows shifted compute budgets.
- Ethics and policy operationalization
- The recommendation to allow some “harmless” lies lacks an operational harm taxonomy, risk thresholds, or governance mechanisms to discriminate acceptable from unacceptable deception.
- The paper acknowledges dual-use of steering (toward more lying) but does not propose safeguards, auditing protocols, or access controls.
- Reproducibility and transparency
- Full details of prompts, seeds, datasets (including the 200 contrastive pairs), and scoring protocols for public replication are not fully specified in the main text; reproducibility across runs is not reported.
- Sensitivity analyses (e.g., to the number/location of steered layers, vector derivation methods beyond PCA, or alternative linear/non-linear steering approaches) are limited.
- Stronger baselines and comparisons
- Comparisons to other representation-engineering methods (e.g., SAE-based sparse steering, causal feature steering, non-linear probes) are not provided, leaving relative efficacy and interpretability uncertain.
These gaps outline concrete avenues for future work, including cross-model/template replication, belief-aware deception measurement, human-validated scoring, robust causal analysis, broader capability impact audits, adversarial robustness testing, multilingual/multimodal extensions, and deployment-oriented evaluation.
Collections
Sign up for free to add this paper to one or more collections.

