- The paper introduces a dynamic branching mechanism that triggers extra exploration at high-uncertainty 'Spark points' to reallocate compute optimally.
- The framework achieves +73.5% improvement on benchmarks, with 80.5% success in ALFWorld and 89.8% in WebShop using only 20% training data.
- The approach enhances cross-domain generalization and sample efficiency by strategically focusing on critical decision points rather than uniform exploration.
Strategic Policy-Aware Exploration via Dynamic Branching in Long-Horizon Agentic Learning
Motivation and Problem Context
The application of @@@@1@@@@ (RL) to LLM agents faces substantial challenges in long-horizon, open-ended tasks, where the combinatorics of state spaces cause successful trajectories to be exceedingly sparse. Existing RL protocols typically allocate compute budget uniformly across all steps of a trajectory, frequently resulting in substantial computational waste on trivial states and under-sampling critical decision points that define task success. "Spark: Strategic Policy-Aware Exploration via Dynamic Branching for Long-Horizon Agentic Learning" (2601.20209) introduces a framework designed to autonomously trigger exploration at high-uncertainty states—dubbed "Spark points"—thus reallocating sampling budget in a resource-optimal manner.
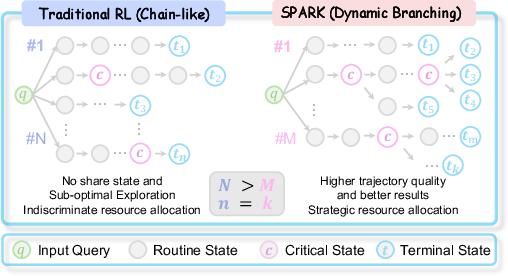
Figure 1: Paradigm comparison of uniform versus strategic exploration policies illustrates how Spark’s dynamic branching yields higher-quality trajectories at equivalent computational budget.
Spark Framework and Dynamic Branching Mechanism
Spark formalizes long-horizon agentic tasks as partially observable Markov decision processes (POMDPs), leveraging a policy model that emits both reasoning traces and actions at each step. The central innovation is Dynamic Branching Exploration, which builds tree-structured trajectory forests by branching only at critical states signaled by intrinsic <explore> tags emitted from the agent’s reasoning. This mechanism is decomposed into three stages:
- Root Initialization: Multiple trajectory roots are sampled at the highly uncertain initial state to ensure diversity.
- Autonomous Branching: During rollout, the agent's reasoning trace is parsed for epistemic uncertainty indicators. Upon encountering <explore> signals, Spark triggers additional branches, intensifying exploration depth precisely at key decision junctures.
- Budget Enforcement: All tree growth is globally constrained by a fixed trajectory leaf node budget, ensuring computational tractability.
The resultant trajectory trees undergo tree-based policy updates, leveraging group-normalized advantages for credit assignment while remaining compatible with standard, critic-free optimization pipelines.
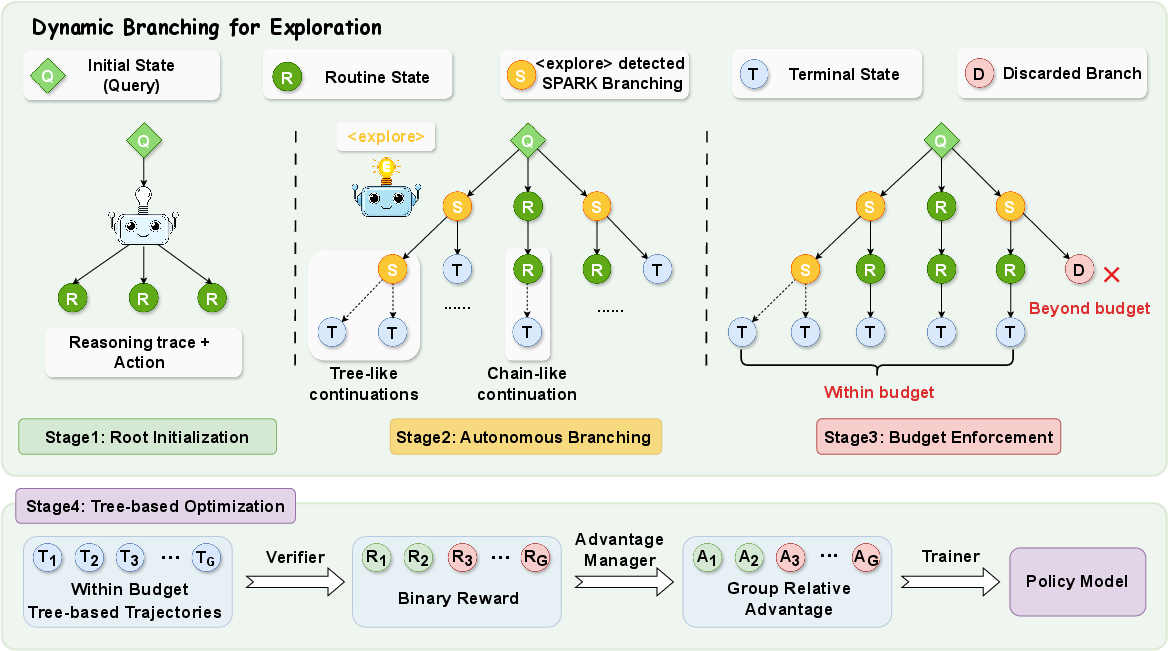
Figure 2: Spark framework overview, depicting root initialization, autonomous branching at high-uncertainty states, and budget enforcement for trajectory tree construction.
Theoretical Analysis and Efficiency
The authors present a formal argument that Spark provides a multiplicative improvement in critical decision coverage compared to linear sampling, particularly as the ratio of critical to routine states (K/Kc) increases. By targeting pivotal states, Spark increases the probability of discovering successful trajectories via qtbranch=1−(1−qt)B, producing exponentially more successful samples under a fixed rollout budget. Sample complexity is further reduced, with Spark matching baselines using only a O(M⋅ρ) fraction of samples, where ρ=Kc/K is the critical-state density.
Empirical Evaluation and Numerical Results
Spark is evaluated on ALFWorld, ScienceWorld, and WebShop—benchmarks that typify embodied planning, scientific reasoning, and real-world web navigation tasks. Across both in-domain and out-of-domain splits, Spark demonstrates superior success rates and generalization capacity relative to closed-source LLMs and RL methods.
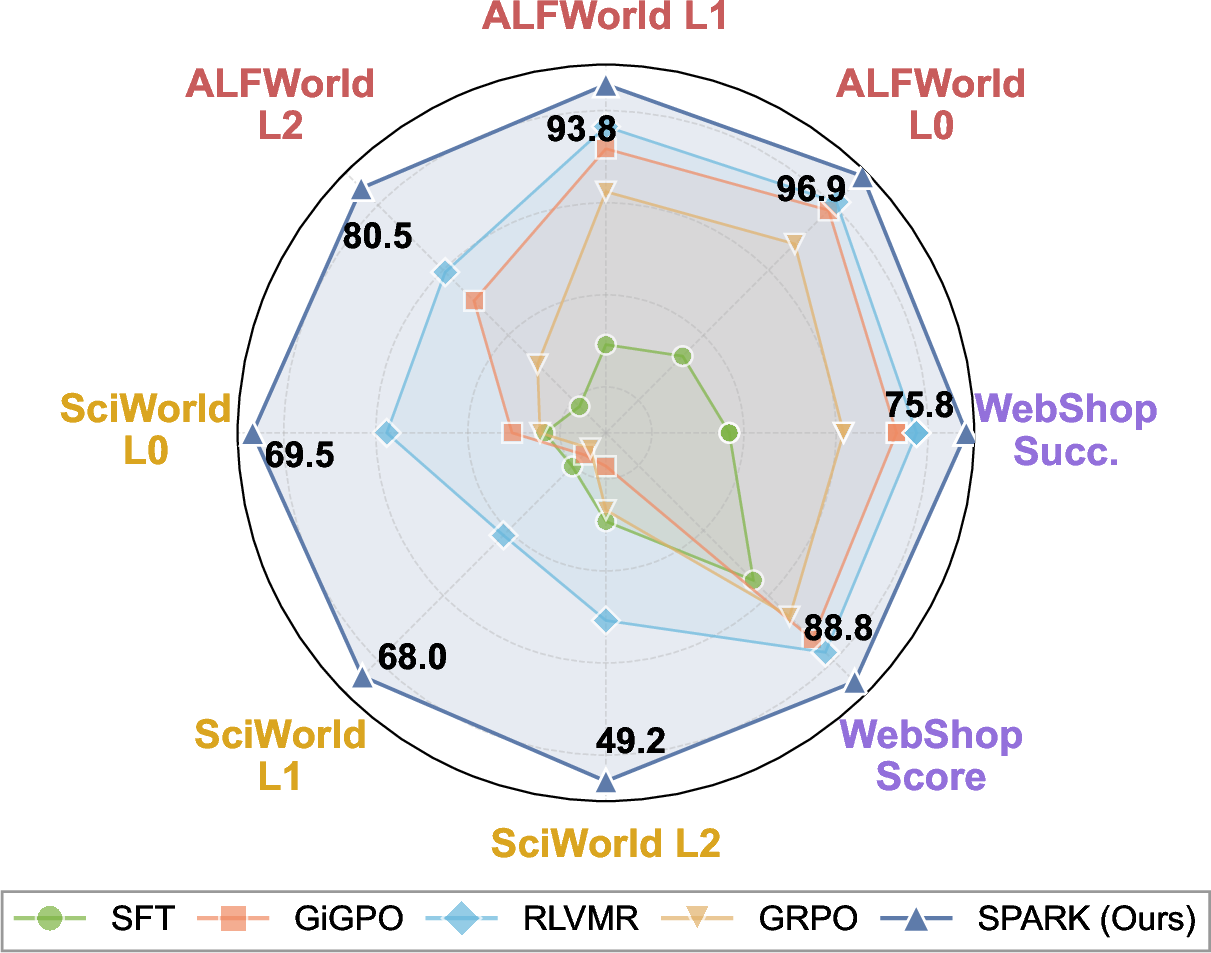
Figure 3: Multi-benchmark evaluation shows Spark's +73.5% average improvement over baselines on diverse agentic domains.
Key claims evidenced by strong numerical results:
- On ALFWorld L2 (unseen task categories), Spark achieves 80.5% success rate, outperforming RLVMR (26.5%) and GiGPO (4.7%).
- In ScienceWorld, Spark exceeds GRPO by +38.3% (L2 split).
- On WebShop, Spark reaches 89.8% average score—well above all advanced method baselines.
Spark’s sample efficiency is particularly notable: with only 20% training data, Spark surpasses GRPO trained with 100%. This is further corroborated by ablation studies and budget sensitivity analyses.
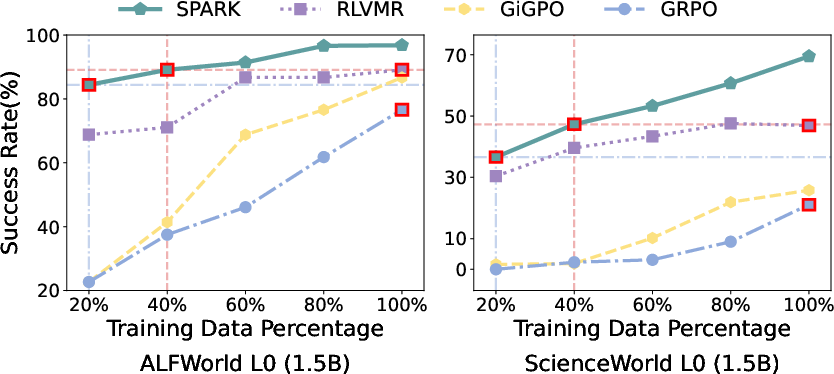
Figure 4: Spark attains higher success than GRPO with only 20% data, highlighting dramatic gains in sample efficiency.
Ablation on initial root count demonstrates trade-offs between initial diversity and adaptive depth, with peak efficacy at M=4 roots.
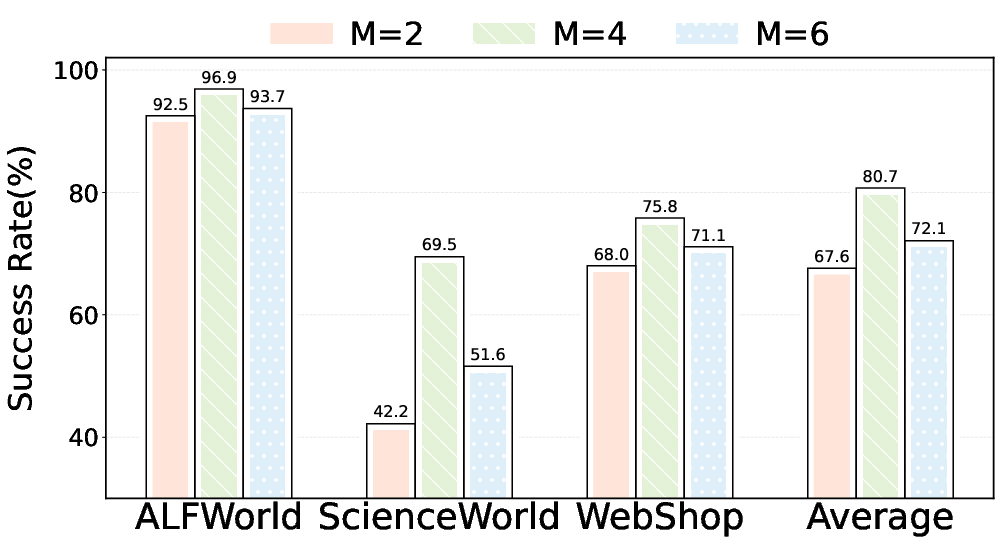
Figure 5: Success rate sensitivity analysis on initial root count reveals optimal performance at M=4 under budget constraint N=8.
Qualitative and Case Study Analyses
Qualitative tracing in ALFWorld reveals Spark’s strategic branching at semantic ambiguities, successfully resolving missteps through exploration where uniform baselines become trapped in repetitive action loops.
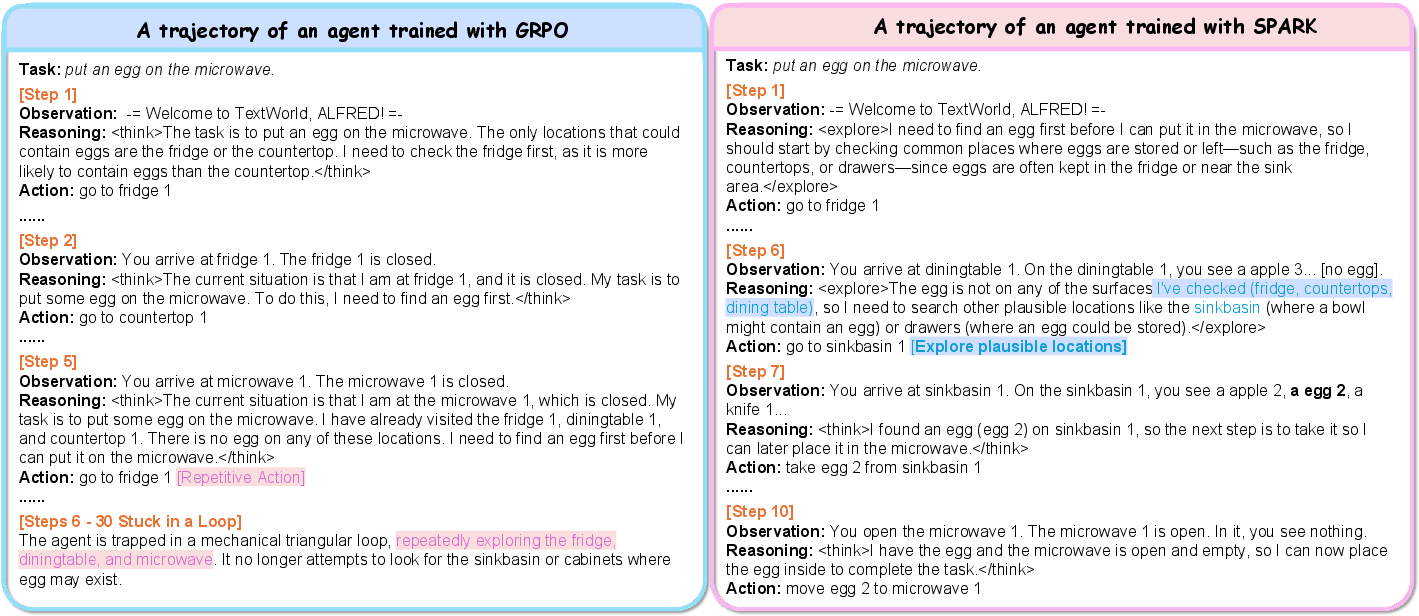
Figure 6: On an ALFWorld planning task, Spark initiates branching only after uncertainty, facilitating successful execution while GRPO collapses into local loops.
Full trajectory visualizations for embodied planning and web navigation tasks further illustrate the agent’s execution flow under dynamic branching.

Figure 7: Spark’s full trajectory in ALFWorld illustrates concise, uncertainty-guided exploration to reach task goals.

Figure 8: WebShop trajectory with Spark showing attribute-matching and adaptive decision points.
Implications, Generalization, and Future Directions
Practically, Spark achieves higher information density per interaction and improved trajectory quality without reliance on human priors or dense external supervision. Theoretical implications center on resource-optimal tree exploration, indicating promising scalability to increasingly complex agentic environments.
Generalization is robust: performance degradation on out-of-domain splits is uniformly less severe than all baselines, supporting the claim that strategic, intrinsic-signal-based exploration is more transferable than heuristic or process-reward approaches.
The framework is modality-agnostic, as demonstrated by extensions to multimodal RL scenarios, e.g., Sokoban and EZPoints (see supplementary material).
Limitations include decreased effectiveness with extremely low-capability base models unable to reliably emit <explore> signals, and diminished gains in domains lacking sparsity in critical decision points. Future research may address these with uncertainty calibration mechanisms and hybrid intrinsic-extrinsic feedback integration, extending applicability to broader model regimes.
Conclusion
Spark innovates strategic agentic RL via dynamic, policy-aware branching, tightly coupling exploration with intrinsic uncertainty signals. This achieves numerically dominant success rates, superior sample and token efficiency, and robust cross-domain generalization. The approach redefines practical RL agent training for long-horizon tasks—endorsing a paradigm shift toward resource-precise, model-driven exploration.