DeFM: Learning Foundation Representations from Depth for Robotics
Abstract: Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks. Despite this, representation learning for depth modality remains underexplored compared to RGB, where large-scale foundation models now define the state of the art. To address this gap, we present DeFM, a self-supervised foundation model trained entirely on depth images for robotic applications. Using a DINO-style self-distillation objective on a curated dataset of 60M depth images, DeFM learns geometric and semantic representations that generalize to diverse environments, tasks, and sensors. To retain metric awareness across multiple scales, we introduce a novel input normalization strategy. We further distill DeFM into compact models suitable for resource-constrained robotic systems. When evaluated on depth-based classification, segmentation, navigation, locomotion, and manipulation benchmarks, DeFM achieves state-of-the-art performance and demonstrates strong generalization from simulation to real-world environments. We release all our pretrained models, which can be adopted off-the-shelf for depth-based robotic learning without task-specific fine-tuning. Webpage: https://de-fm.github.io/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces DeFM, a “foundation model” that understands depth images really well, especially for robots. A depth image is like a picture where each pixel tells you how far away something is (not its color), kind of like how a bat uses echoes to sense distance. The goal is to build a powerful, reusable depth encoder that robots can plug in to see and understand the world, even when lighting, colors, and textures change.
Key questions the paper tries to answer
To make the idea clear, here are the main questions the researchers asked:
- Can we build a universal, pretrained depth model that works across many robot tasks (like walking, navigating, and picking things up)?
- How do we train it without needing tons of human-labeled data?
- Can it keep track of real-world distances (meters, centimeters) across very different scenes (small table objects vs. outdoor streets)?
- Can we shrink it into smaller, faster versions so it runs on robots with limited computing power?
How they did it (in everyday terms)
The team trained DeFM on a huge, carefully mixed set of 60 million depth images. They used a “self-supervised” approach, which means the model teaches itself patterns without needing labels from humans.
Here’s the approach, explained with simple ideas:
- Teacher–student learning (self-distillation):
- Imagine two versions of the same model: a teacher and a student.
- They look at different crops (parts) of the same depth image. The student tries to match the teacher’s understanding.
- This helps the student learn stable, general features from many viewpoints.
- Patch-level learning is like solving a jigsaw puzzle: the student predicts features for the hidden pieces using what’s visible.
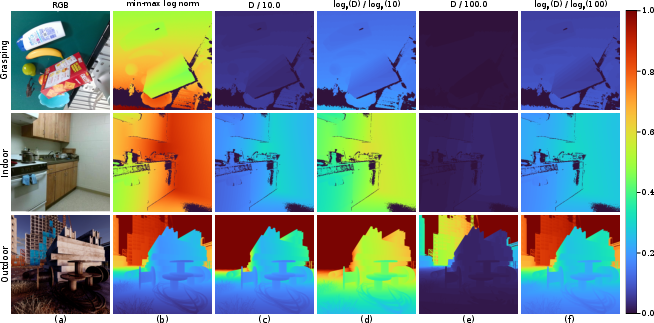
- Smart input preparation for depth:
- Robots care a lot about close-by details (like a step or a cup handle), but also need to understand far-away distances (like a hallway).
- The authors created a 3-channel depth input:
- One channel focuses on relative depth in the current image (to catch fine details).
- One emphasizes mid-range distances (good for indoor tasks).
- One emphasizes far-range distances (good for outdoor navigation).
- Think of it like wearing glasses with different focus settings at the same time, so the model sees near and far clearly.
- The dataset (where the images came from):
- Real sensor depth: actual robot cameras in homes, offices, streets.
- Synthetic depth: clean, simulated worlds (perfect for training).
- Estimated depth from regular RGB images: using a depth-prediction model to turn color photos into depth. This adds tons of diverse object scenes (cups, tools, rooms).
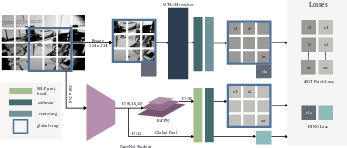
- Making smaller, faster versions (distillation):
- The big model (a large transformer) is powerful but heavy.
- They “distill” its knowledge into smaller models (both tiny transformers and lightweight CNNs) so robots can run them quickly.
- A special feature fusion layer (BiFPN) preserves detailed spatial information, so these smaller models still understand shapes and layouts, not just overall image summaries.
Main findings and why they matter
The key results show that DeFM’s depth features are strong and general:
- It beats or matches top RGB foundation models (like DINOv2/DINOv3) when those are repurposed for depth, across tasks like:
- Classification (recognizing object categories),
- Semantic segmentation (labeling each pixel as “floor,” “cup,” “door,” etc.),
- Robotics tasks using reinforcement learning (RL): locomotion, navigation, and manipulation.
- It generalizes well from simulation to the real world, which is critical for robots (sim-to-real is hard with RGB because real-life visuals are messy; depth is more stable).
- The features show “semantic awareness” even without color or texture:
- When they visualize the model’s features (using PCA, a way to compress and view patterns), the model consistently highlights meaningful parts like cup handles. That’s useful for robot grasping—knowing where to grab—without any fancy labels.
- They release the pretrained models:
- Researchers and engineers can use DeFM “as is” on depth tasks without extra fine-tuning, saving time and data.
- Small, efficient versions run fast:
- The distilled models work well and are compact enough to use on real robots with limited hardware.
What’s the bigger impact?
DeFM could become a standard drop-in depth encoder for robots. That means:
- More reliable robot vision: depth is stable under changing light and colors, making robots safer and more consistent.
- Faster development: plug in a strong depth model instead of training from scratch for every new task.
- Better sim-to-real transfer: training in simulation and deploying in the real world becomes smoother.
- Works across many robot jobs: walking on rough terrain, navigating buildings, picking up objects, opening drawers, and more.
- Less need for labeled data: self-supervised training scales easily.
In short, DeFM helps robots “see” in terms of geometry and distance—what really matters for moving and interacting—making them smarter, more robust, and easier to build.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper. Each point is phrased to guide follow-up research.
- Impact of MDE-generated depth on learned geometry: quantify how pretraining on monocularly estimated depth (ImageNet-21k, SA-1B) affects metric fidelity and downstream performance versus training on purely real/synthetic metric depth; include ablations that remove or reweight MDE data.
- Dataset overlap and potential leakage: assess whether pretraining on ImageNet-21k-derived depth introduces overlap with the ImageNet-1k-Depth evaluation set; report de-duplication procedures and contamination analysis.
- Sensor generalization rigor: provide quantitative cross-sensor evaluations (e.g., stereo, structured light, ToF, LiDAR) with standardized protocols covering typical artifacts (holes, flying pixels, quantization) and edge cases (specular/transparent surfaces, low light).
- Absolute scale preservation: empirically verify that the 3-channel log-normalization retains true metric scale across sensors with differing unit conventions and intrinsics; evaluate on tasks requiring precise ranging (e.g., obstacle distance estimation).
- Normalization sensitivity: ablate the fixed mid-/far-range anchors (10, 100) and investigate adaptive or learnable scale anchors across tasks and environments; evaluate robustness for close-range dexterous manipulation (<10 cm) and very long-range navigation (>100 m).
- Handling invalid/missing depth: specify and evaluate strategies for NaNs/zeros/infinite values, occlusion boundaries, and per-pixel confidence; test whether augmenting training with realistic hole patterns and noise improves robustness.
- Depth-specific augmentation design: detail and ablate the geometric/“photometric” (depth-domain) augmentations used; include sensor-noise models, quantization, and hole synthesis to reveal which augmentations drive generalization.
- Pretraining objective variants: compare DINO-only vs iBOT vs MIM/I-JEPA-style objectives tailored to depth; study whether patch masking ratios, prototype counts, and centering schemes should be depth-specific; provide scaling-law analyses for depth modality.
- Multi-view/temporal pretraining: explore sequence- or multi-view pretraining to enforce geometric and temporal consistency (e.g., epipolar constraints, cycle consistency); quantify gains for control tasks requiring dynamics.
- Distillation choices for CNNs: examine the effect of removing masking in iBOT for CNN students; compare alternative dense distillation strategies (e.g., contrastive pixel/patch alignment, teacher-student attention transfer).
- BiFPN necessity and design: ablate the BiFPN on CNN students; compare against UNet/FPN variants and simple multi-scale heads to identify minimal architectures that retain strong dense features.
- Fair baseline conversions: evaluate multiple, standardized depth-to-RGB conversions (e.g., HHA, colormaps, learned mappings) for RGB VFMs to ensure fair comparisons; report sensitivity of baselines to the chosen conversion.
- Depth-native benchmarks: include evaluations on established depth datasets (e.g., NYUv2, SUNRGB-D, KITTI depth/semantics) for segmentation and geometry tasks to validate transfer beyond MDE-converted ImageNet-Depth.
- 3D geometry tasks: test DeFM features on pose estimation, point cloud registration, occupancy prediction, surface normal estimation, and multi-view reconstruction; compare against specialized geometric FMs (DA3, DUSt3R, MASt3R, VGGT).
- SLAM and odometry: investigate DeFM’s utility for VO/SLAM (RPE/RRE, loop closure, relocalization) and mapping (elevation/occupancy grids) to substantiate claims of geometric utility in embodied settings.
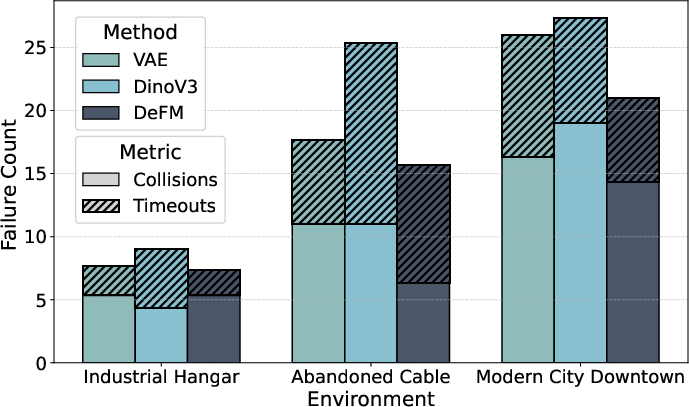
- Policy-learning integration: provide comprehensive RL ablations (frozen vs fine-tuned encoders, sample-efficiency curves, generalization to novel terrains/scenes/sensors) and quantify sim-to-real improvements attributable to DeFM versus task-specific encoders.
- Few-shot adaptation: study whether lightweight fine-tuning or adapters on small task-specific depth datasets further improve performance over purely frozen usage; characterize the trade-offs in sample efficiency and stability.
- Robustness and safety: evaluate adversarial/stochastic perturbations (noise spikes, sensor dropouts), out-of-distribution detection, and uncertainty estimation from DeFM features in safety-critical robotic control loops.
- Real-time deployment: provide detailed, hardware-specific latency/throughput/energy benchmarks (CPU, embedded GPUs, edge TPUs) for all distilled models; include jitter analysis and memory footprints under realistic batch sizes in RL.
- Quantization/pruning: explore post-training quantization and structured pruning for CNN and ViT-S students; measure accuracy–latency trade-offs to enable deployment on constrained platforms.
- Camera intrinsics and unit standardization: document the pipeline for converting disparity to metric depth across datasets; analyze how intrinsics variability impacts normalization and feature consistency.
- Domain mixture weighting: ablate sampling strategies and mixture ratios among MDE/synthetic/real sets; examine curricula or domain-balanced batching to improve generalization.
- Transparent/specular materials: curate targeted evaluation sets (e.g., glass, liquids, shiny metals) and measure failure modes common to depth sensors; test augmentation/training remedies.
- Feature interpretability beyond PCA: quantify emergent part/affordance understanding using probing tasks (e.g., handle/edge/normal/flatness detectors) and part-level segmentation; link to grasping success.
- Language and action grounding: explore aligning DeFM with language (e.g., depth–text contrastive pretraining) or action priors (value/affordance prediction) to combine semantic grounding with geometry for VLA agents.
- Dataset availability and licensing: clarify whether the 60M depth corpus (including MDE outputs) can be released; provide scripts and recipes to regenerate the dataset under licensing constraints for reproducibility.
- Compute accessibility: report training curves, smaller-scale recipes (fewer images/GPUs), and hyperparameter guidelines enabling reproduction without GH200-scale resources; characterize performance vs compute/data.
- Task diversity limits: ensure coverage of outdoor adverse conditions (rain, fog, night), dynamic scenes, and multi-agent settings; add evaluations to confirm breadth of generalization beyond curated indoor/manipulation/nav datasets.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be built today with the released DeFM encoders (ViT-L and distilled small CNN/ViT variants), requiring minimal or no task-specific fine-tuning beyond light heads.
- Drop-in depth encoder for robotic RL and control [Robotics, Logistics, Manufacturing]
- What: Replace scratch-trained depth backbones in locomotion, navigation, or manipulation policies with a frozen DeFM encoder (or distilled CNNs) to improve sample efficiency and sim-to-real robustness.
- How: Insert DeFM as a feature extractor before the policy; keep it frozen; train only the policy head (e.g., PPO, SAC).
- Tools/workflow: ROS/ROS2 nodes for feature extraction; ONNX/TensorRT export of distilled models; integration with Isaac Gym/Orbit/ManiSkill3 training loops.
- Assumptions/dependencies: Correct metric units and the paper’s 3-channel log-depth normalization; sufficient onboard compute or use of distilled backbones; reasonable depth sensor quality and FOV.
- Free-space and obstacle segmentation from depth with a linear head [Mobile Robotics, Warehousing, AMRs]
- What: Use DeFM features plus a lightweight segmentation head to generate drivable space, hazard maps, and obstacle masks robust to lighting/texture.
- How: Linear probe on a few labeled examples per environment; keep DeFM frozen.
- Tools/workflow: Minimal dataset curation per site; real-time inference on Jetson-class hardware using distilled CNNs + BiFPN.
- Assumptions/dependencies: Basic pixel-level labels for the target facility; sensor placement and calibration.
- Terrain classification for perceptive locomotion [Construction, Mining, Field Robotics]
- What: Classify terrain types (stairs, rubble, slippery surfaces) from depth for gait selection and foothold scoring.
- How: Small classifier trained over frozen DeFM features; optionally a lightweight pixel head for local terrain maps.
- Tools/workflow: Rapid data collection with onboard depth; linear probe.
- Assumptions/dependencies: Representative local terrain samples; stable mounting of depth camera.
- Grasp and affordance priors from depth features [Manufacturing, Warehouse Picking, Service Robotics]
- What: Use DeFM’s emergent semantic clustering (e.g., cup handles, rims) to create grasp targets and affordance heatmaps without heavy RGB reliance.
- How: PCA/UMAP on patch tokens or a tiny heatmap head; plug into motion planners or grasp synthesis.
- Tools/workflow: Depth-only grasp site proposals; fallback when RGB is unreliable.
- Assumptions/dependencies: Geometric visibility of functional parts (e.g., handle not occluded); reasonable camera-object baseline.
- Privacy-preserving people/asset detection and activity zoning [Healthcare, Corporate Security, Smart Buildings]
- What: Depth-only detection for occupancy and no-go zones, minimizing PII risks inherent to RGB.
- How: Linear or KNN classification over DeFM features; simple temporal smoothing for tracking.
- Tools/workflow: Facility mapping; deployment via edge devices.
- Assumptions/dependencies: Local privacy/legal review; adequate indoor depth coverage; occlusion management.
- Cross-sensor robustness and simplification of per-sensor retraining [OEMs, System Integrators]
- What: Deploy the same frozen DeFM encoder across different depth hardware (stereo, ToF, structured light, LiDAR) with minimal re-tuning.
- How: Standardize to the paper’s normalization; add small task heads per application.
- Tools/workflow: Unified perception stack with configurable sensor adapters.
- Assumptions/dependencies: Sensor-specific intrinsics/extrinsics and metric scale preserved.
- Faster sim-to-real pipelines with less domain randomization [Robotics R&D]
- What: Reduce reliance on heavy visual domain randomization by training policies on simulated depth and deploying with DeFM features.
- How: Pretrain policies in sim using DeFM; add realistic depth noise models; deploy with frozen encoder.
- Tools/workflow: Isaac/Orbit/ManiSkill3 depth renderers; sim noise plugins; RL experiments with large batches enabled by small distilled models.
- Assumptions/dependencies: Reasonable fidelity of simulated depth and noise; similar FOV/placement in real deployments.
- Quality inspection and geometric anomaly detection from depth [Manufacturing, QA]
- What: Detect missing parts, warpage, or deformation with few labels using DeFM features.
- How: Linear head or distance-based anomaly scoring in feature space.
- Tools/workflow: Rapid line changeovers; minimal labeling; unsupervised baselines with KNN.
- Assumptions/dependencies: Stable lighting irrelevant; consistent fixture positioning still helps.
- Depth-enhanced visual odometry and SLAM feature matching [Mapping, Drones, Mobile Robots]
- What: Use DeFM patch tokens as robust descriptors to aid correspondence and loop-closure under challenging illumination.
- How: Substitute or augment hand-crafted or RGB descriptors with DeFM depth features.
- Tools/workflow: Plugin modules for ORB-/LDS-/Kimera-style pipelines.
- Assumptions/dependencies: Engineering effort to integrate features into VO/SLAM; evaluation on target platforms.
- Education and research baseline for depth-only representation learning [Academia]
- What: A standard, strong baseline for depth representation research, ablations, and downstream studies.
- How: Reproducible frozen features; simple linear probes; common eval tasks.
- Tools/workflow: Released weights and recipes; small distilled backbones for student projects.
- Assumptions/dependencies: Access to typical depth sensors or public datasets.
Long-Term Applications
These opportunities are plausible extensions that will benefit from further research, scale-up, integration, and validation.
- Generalist depth-augmented VLA agents [Robotics, Software]
- What: Combine DeFM with RGB, proprioception, and language to create robust, privacy-aware generalist policies for homes, hospitals, and factories.
- Path: Cross-modal fusion layers; instruction following with text grounding; long-horizon memory.
- Dependencies: Large-scale multi-task data; safety and fail-safe behaviors; on-device performance.
- Depth-first autonomous driving perception modules [Automotive]
- What: Depth-driven free-space, drivable area, and obstacle detection that remain robust at night, in glare, or in adverse weather.
- Path: Stereo/structured light/LiDAR fusion with DeFM; certification-ready stacks.
- Dependencies: Long-range metric consistency; automotive-grade validation, redundancy, and regulation compliance.
- Universal depth SLAM and 3D reconstruction with learned priors [Mapping, AEC, Drones]
- What: SLAM/back-end reconstruction that leverage DeFM tokens for out-of-distribution generalization and robust loop closure.
- Path: Learnable front-end correspondences; pose graph optimization with learned uncertainty from features.
- Dependencies: Multi-view training objectives; large-scale validation across domains.
- Household assistants with privacy-by-design perception [Consumer Robotics, Eldercare]
- What: Assistive robots that operate using primarily depth to preserve privacy while understanding scenes and affordances.
- Path: Depth-only semantic understanding, grasping, navigation; fallback to RGB only when needed.
- Dependencies: Rich home datasets; social acceptability; reliability across clutter and occlusions.
- Real-time affordance-aware planners [Industrial Automation, Service Robotics]
- What: Planners that directly consume affordance maps from DeFM features to decide grasps, pushes, or footholds on the fly.
- Path: Tight coupling between perception tokens and control primitives; uncertainty-aware planning.
- Dependencies: Differentiable planning interfaces; robust calibration of feature-to-action mappings.
- Standardized benchmarks and policy guidance for depth-only AI [Policy, Standards]
- What: Sector-wide benchmarks and best practices for privacy-preserving visual AI built on depth-only perception.
- Path: Consortium datasets, metrics, and certification protocols.
- Dependencies: Multi-stakeholder coordination; regulatory endorsement.
- Domain expansion to underwater, agriculture, and surgical settings [Robotics in Extreme/Regulated Domains]
- What: Robust depth features for turbid water, foliage occlusions, or minimally invasive surgical scenes.
- Path: Curate/add domain-specific depth datasets; adapt normalization and noise models.
- Dependencies: Specialized sensors and data; strong safety validation.
- Foundation pretraining for universal robotic control [Academia, Software]
- What: Large-scale, depth-centric pretraining libraries where policies are initialized on DeFM features for rapid adaptation to new tasks.
- Path: Cross-task datasets (navigation, manipulation, locomotion) with unified APIs; off-policy pretraining regimes.
- Dependencies: Shared data infrastructure; large compute; community adoption.
- Edge-native perception IP and accelerators [Semiconductors, Edge AI]
- What: Hardware-accelerated DeFM inference blocks on micro-servers and robot controllers.
- Path: Co-design of compact backbones, quantization-aware training, compiler support.
- Dependencies: Vendor partnerships; power/latency targets; certification for safety-critical use.
- Depth-guided synthetic data generation and domain scoring [Tooling, Sim Platforms]
- What: Use DeFM features to assess simulation realism and guide generation of synthetic depth that best improves downstream performance.
- Path: Feature-space distribution matching; active data selection.
- Dependencies: Feedback loops between sim renderers and representation metrics.
Global Assumptions and Dependencies (impacting both horizons)
- Depth sensor availability and fidelity: Performance depends on sensor type (ToF, stereo, LiDAR), FOV, range, and noise; correct metric units and the paper’s normalization are critical.
- Compute and deployment: Real-time performance on embedded platforms often requires distilled models, quantization, and optimized runtimes (e.g., TensorRT).
- Dataset coverage: Some domains (e.g., underwater, surgical) are underrepresented; additional data may be needed to generalize.
- Safety and compliance: Automotive/medical deployments require rigorous validation, redundancy, and adherence to standards.
- Integration effort: SLAM, planning, and control stacks may need non-trivial engineering to fully exploit patch-level features and dense tokens.
- MDE-derived training data: Portions of the pretraining corpus come from monocular depth estimation of RGB; residual biases could affect metric fidelity in some edge cases.
Glossary
- AdamW: An optimization algorithm that decouples weight decay from the gradient update, improving regularization during training. "We use AdamW optimizer with a learning rate of and a cosine weight decay schedule (\SI{0.04}{} to \SI{0.2}{})."
- Agglomerative Vision Models: A distillation approach that trains a single student by aggregating knowledge from multiple heterogeneous pre-trained vision models. "Agglomerative Vision Models, such as RADIO (Reduce All Domains Into One) \cite{Ranzinger_2024_CVPR, heinrich2025radiov25improvedbaselinesagglomerative}, which train a single student model by distilling the knowledge from multiple pre-trained, heterogeneous \ac{VFM} (e.g., CLIP, DINOv2, SAM~\cite{kirillov2023segment})."
- BiFPN: Bi-directional Feature Pyramid Network that fuses multi-scale feature maps to produce strong dense spatial features. "we integrate a \ac{BiFPN} \cite{tan2020efficientdet} on top of our CNN encoders."
- CLIP: A vision-LLM that learns to align images and text via contrastive training, enabling zero-shot classification and retrieval. "Methods such as DINO~\cite{caron2021emerging, oquab2023dinov2, simeoni2025dinov3}, and CLIP~\cite{radford2021learning} have become the de facto standard for vision tasks, demonstrating remarkable zero-shot transfer to classification, detection, segmentation, and retrieval."
- Contrastive Learning: A self-supervised learning paradigm that pulls together representations of different views of the same input while pushing apart others. "Contrastive Learning"
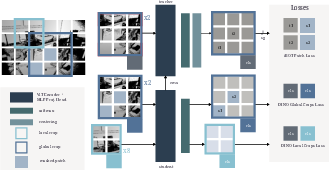
- DINO: A self-distillation method where a student network predicts a teacher’s representations from augmented views, learned without negative pairs. "Our pretraining leverages a DINO-style self-distillation objective adapted for the depth modality, as shown in Fig. \ref{fig:overview_ssl}."
- DINOv2: A scaled and refined version of DINO with improved training recipes and regularization, producing highly transferable dense features. "The success of the DINOv2~\cite{oquab2023dinov2} in learning highly generalizable and robust visual features makes it the ideal foundation for our DeFM."
- DINOv3: A further scaled iteration of DINO that introduces new stabilizing techniques (e.g., gram anchoring) and massive datasets. "More recently, in DINOv3~\cite{simeoni2025dinov3}, the authors further scale up the training dataset to an order of magnitude higher (1.7B images) and introduce gram anchoring to prevent degradation of dense feature maps during a long training schedule."
- Exponential Moving Average (EMA): A momentum-based running average of model parameters used to stabilize training or to form teacher targets. "we maintain a separate EMA of the student’s weights, which serves as the final distilled model."
- Fully-Sharded Data Parallel (FSDP): A distributed training technique that shards model parameters across devices to reduce memory footprint and enable large-scale training. "We train our DeFM using the Fully-Sharded Data Parallel (FSDP) implementation of DINOv2~\cite{oquab2023dinov2} and a ViT-L/14 backbone."
- I-JEPA: A self-supervised approach that predicts high-level latent representations for masked regions rather than reconstructing pixels. "I-JEPA~\cite{assran2023self,bar2024stochastic} adopts a non-generative masked prediction objective that predicts high-level latent representations rather than pixels, leading to semantically rich and stable foundational features."
- iBOT: A method that combines masked image modeling with DINO-style self-distillation to jointly learn patch-level and global representations. "iBOT~\cite{zhou2021ibot} extends this paradigm by combining MIM with DINO-style self-distillation, jointly predicting patch-level tokens and global representations to produce stronger dense features."
- Knowledge Distillation: Training a smaller student model to match a larger teacher’s outputs, transferring knowledge for efficiency. "Knowledge distillation~\cite{hinton2015distilling} aims to transfer the knowledge of a large teacher model into a smaller, more efficient student model by minimizing the distance between their outputs."
- KoLeo Regularizer: A repulsive regularizer that spreads features across the manifold to prevent collapse during self-supervised training. "KoLeo Regularizer: To prevent the collapse of the feature space and maintain feature diversity, a repulsive term known as the KoLeo regularizer \cite{sablayrolles2018spreading} is added to the loss."
- LiDAR: A sensor technology that measures distances by illuminating the target with laser light and measuring the reflection, used for depth. "Realsense L515 (solid state LiDAR depth camera)"
- Linear Probing: Evaluating a frozen encoder by training only a linear classifier on top of its features to assess representation quality. "Linear probing is the standard evaluation protocol for \ac{VFM}s."
- log1p transform: The logarithm of one plus the value, commonly used to compress dynamic range while preserving small-scale differences. "denote the standard log1p transform."
- Masked Image Modeling (MIM): A self-supervised objective where models reconstruct masked regions of images from visible context. "Masked Image Modeling (MIM)"
- Monocular Depth Estimation (MDE): Estimating depth from a single RGB image using learned priors, often used to generate pseudo-depth datasets. "Monocular Depth Estimation (MDE): While the RGB domain benefits from curated, large-scale object-centric datasets (e.g., ImageNet-21k~\cite{deng2009imagenet}), no equivalent diverse dataset exists for depth."
- PCA: Principal Component Analysis, a dimensionality reduction technique used to visualize or analyze feature distributions. "To demonstrate this, we perform PCA on features extracted by our DeFM-L/14 encoder."
- Proprioceptive information: Internal sensing about a robot’s own state (e.g., joint angles, forces) used as privileged inputs for training. "a teacher policy receives privileged proprioceptive information and is distilled into a student policy that relies solely on visual observations."
- Proximal Policy Optimization (PPO): A popular reinforcement learning algorithm that stabilizes policy updates via clipped objectives. "For many downstream RL tasks, the ability to use large batch sizes is critical for stable policy optimization, such as in PPO~\cite{schulman2017proximal}."
- Q-Learning: A reinforcement learning algorithm that learns action-value functions to select actions maximizing expected rewards. "Zeng~et al \cite{zeng2018learning} propose a Q-Learning framework to train dense affordance maps on visual RGB-D observations to clear cluttered scenes."
- Reinforcement Learning (RL): A learning paradigm where agents learn to make sequences of decisions by maximizing cumulative reward. "We distill our largest DeFM model into several efficient CNN networks (IV) to be used for various downstream robotic Reinforcement Learning tasks, including navigation, manipulation, and locomotion (VI)."
- Self-Distillation: A training method where a student network is trained to match a teacher network derived from its own parameters. "Self-distillation methods~\cite{grill2020bootstrap, chen2021exploring, caron2021emerging} use two network branches processing different augmented views of the same image."
- Self-Supervised Learning (SSL): Learning representations from unlabeled data by designing surrogate tasks or objectives. "\ac{SSL} has become a dominant pretraining paradigm for these models due to its scalability and domain flexibility."
- Sim-to-Real Transfer: Transferring policies learned in simulation to the real world while retaining performance and robustness. "Depth sensors are widely deployed across robotic platforms, and advances in fast, high-fidelity depth simulation have enabled robotic policies trained on depth observations to achieve robust sim-to-real transfer for a wide range of tasks."
- Sinkhorn-Knopp algorithm: An algorithm for matrix scaling used to stabilize and normalize prototype assignments in self-supervised training. "The teacher outputs are stabilized and normalized using the Sinkhorn-Knopp algorithm, replacing the previously used softmax-centering step, leading to stability and preventing model collapse."
- Variational Auto Encoder (VAE): A generative model that learns latent representations via variational inference, often used for pretraining. "leveraging a frozen Variational Auto Encoder (VAE) pretrained on a large-scale depth dataset~\cite{wang2020tartanair}."
- Vision Foundation Models (VFM): Large pretrained visual encoders that provide general-purpose features transferable across tasks without fine-tuning. "\ac{VFM} refer to large, pretrained visual encoders designed to learn general-purpose representations that transfer effectively across a wide range of downstream tasks and domains without any finetuning."
- Vision-LLMs (VLMs): Models trained to align visual and textual representations, enabling tasks like zero-shot classification from text prompts. "Vision-LLMs (VLMs), such as CLIP~\cite{radford2021learning} and its variants~\cite{zhai2023sigmoid, li2022blip, jia2021scaling} introduce a powerful form of self-supervision by learning to align visual representations with corresponding natural language captions using a contrastive loss on massive web-scraped datasets."
- Vision Transformer (ViT): A transformer-based architecture that processes images as sequences of patches, enabling scalable vision models. "The core of the DINOv2 approach is a self-distillation objective applied to a \ac{ViT} architecture, training a student network to match the output distribution of a momentum-updated teacher network."
- Zero-shot transfer: Applying a model to new tasks or classes without task-specific training by leveraging learned general representations. "demonstrating remarkable zero-shot transfer to classification, detection, segmentation, and retrieval."
Collections
Sign up for free to add this paper to one or more collections.

