Depth Any Panoramas: A Foundation Model for Panoramic Depth Estimation
Abstract: In this work, we present a panoramic metric depth foundation model that generalizes across diverse scene distances. We explore a data-in-the-loop paradigm from the view of both data construction and framework design. We collect a large-scale dataset by combining public datasets, high-quality synthetic data from our UE5 simulator and text-to-image models, and real panoramic images from the web. To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline to generate reliable ground truth for unlabeled images. For the model, we adopt DINOv3-Large as the backbone for its strong pre-trained generalization, and introduce a plug-and-play range mask head, sharpness-centric optimization, and geometry-centric optimization to improve robustness to varying distances and enforce geometric consistency across views. Experiments on multiple benchmarks (e.g., Stanford2D3D, Matterport3D, and Deep360) demonstrate strong performance and zero-shot generalization, with particularly robust and stable metric predictions in diverse real-world scenes. The project page can be found at: \href{https://insta360-research-team.github.io/DAP_website/} {https://insta360-research-team.github.io/DAP\_website/}

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview: What is this paper about?
This paper introduces a smart computer model called DAP (Depth Any Panoramas) that can look at a full 360-degree picture and figure out how far away everything is, in real-world units like meters. Think of a panorama as turning your head all the way around—up, down, and side to side—and taking a single image of everything around you. DAP aims to give accurate “depth” for these panoramas, which is useful for robots, drones, VR/AR, and mapping.
The big questions the researchers wanted to answer
The authors focused on two main goals:
- How can we build a huge, diverse training dataset for panoramic depth that covers indoor and outdoor scenes, synthetic (computer-generated) and real images?
- How can we design a single model that learns from this large dataset and stays accurate across many different places and distances, even without extra fine-tuning on new data?
How did they do it?
To make this understandable, here are the main parts of their approach explained with everyday language.
Building a giant, diverse dataset
They collected around 2 million panoramic images from different sources:
- Indoor scenes from a high-quality synthetic dataset (Structured3D).
- Outdoor scenes from their own simulator (UE5-based AirSim360) that renders realistic city parks, streets, and famous locations.
- Real panoramas from the internet (videos turned into images) and extra indoor panoramas created by a text-to-image model (DiT-360).
Why so many? Because teaching a model to understand the world is like teaching a student: the more varied and high-quality examples you have, the better the student can handle anything.
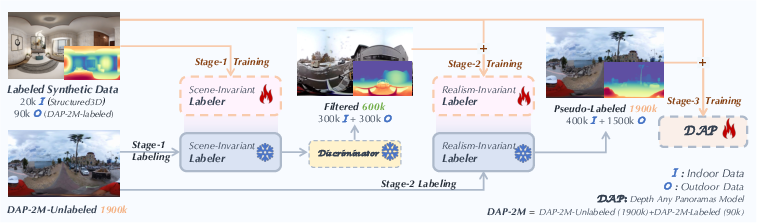
Teaching the model in three stages (like giving it good “self-checking” homework)
They used a “data-in-the-loop” strategy, meaning the model helps create training labels when real labels are missing.
- Stage 1: Scene-Invariant Labeler
- They trained a depth model on synthetic indoor and outdoor panoramas where the true distances are known.
- This model then guessed depth for 1.9 million unlabeled real panoramas.
- Stage 2: Realism-Invariant Labeler
- A “quality checker” model (a discriminator) looked at the guessed depths and picked the most trustworthy ones (top 300k indoor and 300k outdoor).
- Using this filtered set plus the synthetic data, they trained a second labeler that’s better at handling differences between synthetic and real images.
- Stage 3: Training DAP
- Finally, DAP was trained using all the labeled data and the refined pseudo-labels from stage 2.
- This gives DAP strong generalization: it learns from millions of examples without needing perfect labels for all of them.
Think of it like this: the model does its homework (makes its own labels), a teacher checks the best homework, then the student retrains using the best examples to improve even more.
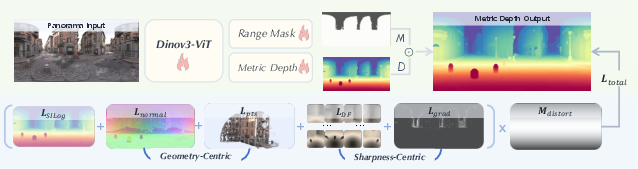
How DAP “thinks” about depth in panoramas
- Backbone: DAP uses a powerful vision encoder called DINOv3-Large to understand image features, like edges and textures.
- Depth Head: This part predicts how far away each pixel is in meters (“metric depth”).
- Range Mask Head: This is like choosing the right “distance mode” for the scene. The model has simple plug-in masks for different ranges (10m, 20m, 50m, 100m). If you’re indoors, 10–20m makes sense. Outdoors, 50–100m is more useful. These masks help the model focus on realistic distances and ignore unreliable far-away guesses.
Handling panorama distortions and sharpening details
Flattening a 360° scene into a rectangle (called “equirectangular projection”) stretches parts near the top and bottom, causing distortion. DAP fights this in smart ways:
- Distortion-aware training: It weights learning so the model doesn’t get confused by stretched areas near the “poles.”
- Perspective patches: It temporarily slices the panorama into 12 normal camera views (like looking through windows arranged around a sphere). This preserves fine details and avoids stretching while training.
- Multiple helpful “losses” (training rules):
- SILog: keeps the overall depth scale stable.
- DF-Gram: maintains sharp local details by comparing fine patterns.
- Gradient loss: focuses on edges so object boundaries are crisp.
- Normal loss: makes surfaces (like walls or tables) look geometrically correct.
- Point-cloud loss: treats the depth like 3D points and keeps those points consistent.
Together, these rules train DAP to be both accurate about distances and visually clean around edges and shapes.
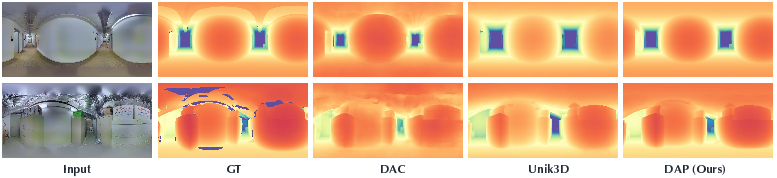
What did they find, and why does it matter?
The researchers tested DAP on well-known indoor datasets (Stanford2D3D, Matterport3D) and an outdoor dataset (Deep360), plus their new outdoor benchmark (DAP-Test). Importantly, they tested “zero-shot,” meaning the model wasn’t fine-tuned on those test sets—it just worked out of the box.
Main results:
- DAP clearly outperformed other state-of-the-art panoramic depth models in both indoor and outdoor scenes.
- It produced sharper boundaries and more consistent geometry, especially for tricky regions like distant areas and sky.
- It stayed stable in metric scale (real meters) without needing adjustments on new data.
Why this matters:
- Many applications need accurate, scale-aware depth from 360° cameras—like drones avoiding obstacles, robots navigating rooms, or VR systems placing objects in the right spot.
- DAP shows that with a huge, well-curated dataset and carefully designed training, a single “foundation model” can handle lots of different scenes without extra tuning.
What’s the impact and what comes next?
- Practical impact: Better panoramic depth helps drones fly safely, robots map their surroundings, and VR/AR systems feel more realistic.
- Data strategy: Their three-stage pseudo-label pipeline shows a strong way to grow training datasets without manually labeling everything, saving time and cost.
- Future possibilities: This approach could be expanded to other 360° tasks (like segmentation or 3D reconstruction), or combined with generative models to create even richer training worlds.
In simple terms: DAP is a step toward computers that truly understand the 3D world all around them—indoors and outdoors—in a reliable, scalable way.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of specific gaps and unresolved questions that future work could address:
- Ambiguity in the dataset description: the paper first describes DAP-2M-Labeled as “synthetic outdoor” (via AirSim360) but later in Experiments states it contains “90K real-world samples with depth annotations.” Clarify whether the 90K labeled outdoor panoramas are synthetic or real, and reconcile this inconsistency.
- Pseudo-label quality control is under-specified:
- No quantitative assessment of pseudo-label accuracy, error rates, or bias across scene types and distance ranges.
- Stage 3 trains on all 1.9M pseudo-labeled images, not only the top-ranked subsets; the impact of low-confidence labels and noise propagation is not evaluated.
- Absence of confidence-weighted training or label denoising strategies (e.g., per-pixel confidence, bootstrapping, or teacher-student ensembling).
- Realism-Invariant Labeler and discriminator details are deferred to supplementary:
- Architecture, training protocol, calibration, and failure cases of the PatchGAN-based depth-quality discriminator are not provided in the main paper.
- No comparison to alternative quality-ranking strategies (e.g., ensemble consistency, uncertainty estimates, self-consistency across projections).
- Indoor/outdoor categorization via Qwen2-VL:
- No reported accuracy or error analysis of indoor/outdoor classification, nor its effect on curation quality.
- Lack of mitigation strategies for misclassified scenes (e.g., garages, atriums, tunnels, stadiums).
- Impact of synthetic generative data (DiT360):
- The effect of adding 200K generated indoor panoramas on metric fidelity, bias, and realism is not quantified via ablations.
- No analysis of whether generative artifacts or mode collapse introduce systematic geometric biases.
- Range mask head usage at inference is unclear:
- The paper introduces four thresholds (10/20/50/100 m), but does not specify how the correct mask head is selected per scene at test time (manual choice, heuristic, or learned gating).
- No exploration of a continuous or adaptive range estimator vs. discrete thresholds; sensitivity to threshold misselection is unknown.
- Mask head training target on pseudo-labeled data:
- Range masks for unlabeled images necessarily rely on pseudo-depth; robustness of mask learning to noisy far-depth estimates is not analyzed.
- BCE is mentioned in text, but the actual mask loss uses L2 + Dice in the equation; resolve this discrepancy and evaluate the effect of different mask loss formulations.
- ERP distortion weighting (“distortion map”) is under-defined:
- The exact functional form and normalization of the distortion map are not specified; no ablation on alternative spherical weightings or camera elevation distributions.
- Sharpness-centric DF loss formulation is ambiguous:
- The Gram-based DF loss equation uses D ⊙ Dᵀ notation without specifying reshape/flattening, normalization, or feature dimensionality.
- No ablation on the number of perspective patches (N=12 via icosahedron), FOV settings, or projection fidelity; optimal N/FOV trade-offs remain unexplored.
- Loss weights and training stability:
- λ coefficients are fixed without sensitivity analysis; it’s unknown how performance varies with weights or across domains.
- No study of training dynamics (e.g., curriculum schedules for sharpness vs. geometry losses).
- Limited evaluation scope of robustness:
- No tests under adverse conditions (nighttime, rain/snow/fog, strong HDR/low-light, motion blur, rolling shutter, underwater) or extreme long-range (>100 m) scenes.
- No robustness analysis to camera pitch/roll variations; training filters out “unreasonable horizons,” which may reduce orientation invariance.
- Camera model generality vs. ERP-only input:
- Despite “Depth Any Panoramas,” the method expects ERP panoramas; generalization to dual-fisheye, cubemap, or other wide-FoV camera models is not evaluated.
- No assessment of cross-camera calibration differences (sensor baselines, stitching artifacts, varying ERP sampling) on metric scale accuracy.
- Sequence-level and temporal consistency:
- The data include many panoramic videos, but training is single-frame; leveraging temporal constraints (optical flow, multi-view consistency, SLAM priors) is left unexplored.
- No evaluation of temporal stability or flicker in video inference.
- Metric scale reliability and uncertainty:
- No analysis of predictive uncertainty, confidence calibration, or failure detection for metric scale estimates from single panoramas.
- Absence of per-pixel or global scale uncertainty maps to enable risk-aware downstream robotics applications.
- Benchmarking and fairness:
- DAP-Test (outdoor) is in-domain; cross-dataset generalization to unseen, annotated real outdoor sets is limited.
- Public availability, licensing, and composition of DAP-Test are not detailed; reproducibility and comparability may be constrained.
- Efficiency and deployment constraints:
- No reporting of inference latency, memory footprint, or throughput on typical edge devices used in robotics.
- Scaling to higher input resolutions (>1024×512) and the impact on sharpness/accuracy vs. runtime are not evaluated.
- Data imbalance and coverage:
- Outdoor real panoramas (≈1.45M) dominate over indoor real (≈250K) plus synthetic indoor (200K), potentially biasing the model; no balancing or sampling strategy analysis.
- Scene diversity coverage (industrial, subterranean, maritime, rural, forested, mountainous) is not quantified; long-tail category performance remains unknown.
- Failure cases and qualitative diagnostics:
- The paper focuses on successes; systematic failure analysis (e.g., sky-occlusion misdepth, glass/reflective surfaces, repetitive textures) is absent.
- Alternative backbones and spherical architectures:
- DINOv3-L is adopted without comparison to spherical transformers, ERP-aware ViTs, or lighter backbones; parameter-efficiency and accuracy trade-offs remain open.
- 3D evaluation beyond 2D metrics:
- Although normal and point-cloud losses are used, evaluations rely on depth metrics; 3D reconstruction quality (e.g., mesh fidelity, point cloud alignment errors, spherical Chamfer) is not reported.
- Data curation and ethics:
- Use of web videos/images lacks discussion of licensing, privacy, deduplication, and potential demographic/scene biases; audit and mitigation strategies are not presented.
- Scaling laws and label-efficiency:
- No study of performance as a function of labeled vs. pseudo-labeled data volume; diminishing returns, optimal mixes, and cost-benefit trade-offs remain unquantified.
- Sky and “infinite” depth handling:
- The approach claims robustness in sky regions, but does not specify how “infinite” distances are represented, truncated, or evaluated; semantics-aware handling of sky/clouds is not explored.
Glossary
- AbsRel: Absolute Relative Error, a depth-estimation metric that averages the per-pixel relative error. "Following~\cite{Jiang2021UniFuseUF}, we evaluate depth estimation performance with metrics including Absolute Relative Error (AbsRel), Root Mean Squared Error (RMSE), and a percentage metrics , where ."
- Adam optimizer: An adaptive gradient-based optimization algorithm commonly used to train neural networks. "For model training, the learning rate is set to 5e-6 for the ViT backbone and 5e-5 for the decoders, using the Adam optimizer~\cite{kingma2014adam}."
- AirSim360: A panoramic simulation platform for generating photorealistic 360-degree data and ground-truth depth. "To address the scarcity of outdoor panoramic supervision, we construct a synthetic outdoor dataset named DAP-2M-Labeled using the high-fidelity simulation platform Airsim360~\cite{simulator}."
- BCE (Binary Cross-Entropy): A loss function for binary classification or mask prediction tasks. "Each range mask head is independently optimized with a combination of weighted BCE and Dice losses"
- Cube projection: A method that projects a spherical panorama onto six cube faces to leverage perspective tools. "Depth Anywhere~\cite{wang2024depth} and PanDA~\cite{cao2025panda}, which distill knowledge via cube projection or semi-supervised learning on large-scale unlabeled panoramas."
- DINOv3-Large: A large self-supervised Vision Transformer backbone used for strong visual feature extraction. "Built upon DINOv3-Large~\cite{simeoni2025dinov3} as the visual backbone, our model adopts a distortion-aware depth decoder and a plug-and-play range mask head"
- Dice loss: An overlap-based loss measuring similarity between predicted and target masks, often used for segmentation. "Each range mask head is independently optimized with a combination of weighted BCE and Dice losses"
- delta_1 (δ1): An accuracy metric indicating the fraction of predictions within a set threshold of ground truth. "Following~\cite{Jiang2021UniFuseUF}, we evaluate depth estimation performance with metrics including Absolute Relative Error (AbsRel), Root Mean Squared Error (RMSE), and a percentage metrics , where ."
- Distortion map: A per-pixel weighting that compensates for non-uniform area distortion in equirectangular projections. "The overall training objective is a weighted combination of all the above losses with distortion map to address the non-uniform pixel distribution \cite{lin2025one} in equirectangular projections."
- Domain gap: The distribution mismatch between data domains (e.g., synthetic vs. real or indoor vs. outdoor) that hinders generalization. "To reduce domain gaps between indoor/outdoor and synthetic/real data, we introduce a three-stage pseudo-label curation pipeline"
- Equirectangular projection (ERP): A mapping from the sphere to a 2D rectangle that introduces latitude-dependent distortions. "To address the severe distortions of the equirectangular projection (ERP), there are two main directions: distortion-aware designs"
- Field of View (FoV): The angular extent of the scene that a camera or model can observe. "Nevertheless, the perspective paradigm inherently restricts perception to a limited field of view (FoV), failing to capture the complete 360° spatial geometry of a scene."
- Gram-based similarity: A comparison using Gram matrices to capture global correlations for dense fidelity supervision. "For each view, we apply a valid mask, normalize depth values, and compute a Gram-based similarity between the predicted and ground-truth depth maps."
- Harmonic ray representations: A spherical harmonic parameterization of rays to improve wide-FoV generalization. "while UniK3D~\cite{piccinelli2025unik3d} reformulates depth in spherical coordinates using harmonic ray representations to enhance wide-FoV generalization."
- Icosahedron: A 20-faced polyhedron whose vertices approximate uniform directions on a sphere, used here to place virtual cameras. "we first decompose each depth map into 12 perspective patches using virtual cameras positioned at the vertices of an icosahedron."
- Matterport3D: A large-scale indoor RGB-D dataset of real scanned environments used for evaluation. "we assess our method on two widely used indoor datasets, Matterport3D~\cite{chang2017matterport3d} and Stanford2D3D~\cite{armeni2017joint}, to evaluate its zero-shot performance."
- Metric depth: Depth in absolute physical units (e.g., meters), not just up to an unknown scale. "we present a panoramic metric depth foundation model that generalizes across diverse scene distances."
- Out-painting: Generative expansion of an image beyond its original boundaries to complete or widen views. "DA~\cite{da2} improves zero-shot performance by expanding training data through perspective-to-ERP conversion and diffusion-based out-painting"
- PatchGAN: A GAN discriminator architecture that classifies local image patches, often used to assess realism/quality. "Stage~2 introduces a Realism-Invariant Labeler, where a PatchGAN-based discriminator selects 300K indoor and 300K outdoor high-confidence pseudo-labeled samples"
- Perspective-to-ERP (P2E) projection: Converting perspective images into equirectangular panoramas. "* in DA refers to pseudo-panoramic data generated from perspective images through P2E projection and out-painting model."
- Point cloud loss: A loss computed after back-projecting depth maps to 3D points to enforce geometric consistency. "We further use a point cloud loss ."
- Pseudo labels: Automatically generated labels (e.g., depth) used to train on unlabeled data. "then generate pseudo labels for the 1.9M unlabeled images."
- Qwen2-VL: A large multimodal vision–LLM used for automated data categorization. "We then employ the large multimodal model Qwen2-VL \cite{wang2024qwen2} to automatically categorize these panoramas into indoor and outdoor scenes"
- Range mask head: A network head that predicts valid regions under specified distance thresholds for scale-aware depth. "The range mask head outputs a binary mask that defines valid spatial regions under different distance thresholds"
- RMSE: Root Mean Squared Error, a standard measure of regression error magnitude. "Following~\cite{Jiang2021UniFuseUF}, we evaluate depth estimation performance with metrics including Absolute Relative Error (AbsRel), Root Mean Squared Error (RMSE), and a percentage metrics "
- Semi-supervised learning: Training that leverages both labeled and unlabeled data to improve generalization. "This is achieved through multiple curation techniques and large-scale semi-supervised learning to enhance cross-domain generalization."
- SILog loss: Scale-Invariant Logarithmic loss tailored for depth regression to balance scale and error. "For optimization, besides adopting the SILog loss as in previous works~\cite{cao2025panda}"
- Sobel operators: Discrete gradient filters used to compute image edge magnitudes along x and y directions. "we compute gradient magnitude maps using Sobel operators along both and directions"
- Spherical coordinate system: A 3D coordinate system using radius and angles; used to back-project ERP depth into 3D. "The depth maps are projected onto the spherical coordinate system to obtain 3D point clouds"
- Stanford2D3D: A real indoor dataset with panoramic imagery and depth used for evaluation. "we assess our method on two widely used indoor datasets, Matterport3D~\cite{chang2017matterport3d} and Stanford2D3D~\cite{armeni2017joint}"
- Surface normal: A unit vector perpendicular to a surface; derived from depth to enforce geometric consistency. "Both predicted and ground-truth depth maps are converted into surface normal fields ."
- UE5: Unreal Engine 5, a photorealistic game engine used to render synthetic training data. "90K photorealistic outdoor panoramas rendered with the UE5-based AirSim360 simulator"
- ViT (Vision Transformer): A transformer-based architecture for image representation learning. "For model training, the learning rate is set to 5e-6 for the ViT backbone"
- Zero-shot: Evaluating on new domains or datasets without any fine-tuning on them. "Compared with in-domain training, zero-shot panoramic depth estimation is more practical for cross-domain applications due to its stronger generalization ability."
Practical Applications
Immediate Applications
Below are practical, deployable use cases that can leverage the paper’s findings and model today, organized by sector and accompanied by suggested tools/workflows and feasibility notes.
- Healthcare: Hospital and clinic facility mapping for digital twins and space utilization analytics; workflow: capture 360° imagery, run DAP to obtain metric depth and convert to point clouds for floor-plan and clearance measurements; assumptions/dependencies: adequate lighting, camera calibration, and tolerance for centimeter–decimeter error ranges; integration with existing BIM tools needed.
- Education/Training: Curriculum and lab exercises on panoramic geometry, dataset curation, and zero-shot evaluation; tools: “Panoramic Depth Starter Kit” using DAP checkpoints, sample datasets (Structured3D, Stanford2D3D, Matterport3D, Deep360), and the three-stage pseudo-label pipeline; assumptions/dependencies: access to GPUs for inference (DINOv3-L backbone), licensing/availability of DAP weights.
- Software/Developer Tools: A 360-to-point-cloud converter and SDK that wraps DAP’s depth head and range mask head (10/20/50/100 m) for ERP images; workflows: ingest ERP panoramas, apply appropriate range mask threshold, export metric depth and normals for downstream rendering/analytics; assumptions/dependencies: ERP input format, consistent horizon alignment, model availability.
- Robotics (indoor mobile robots): Surround obstacle detection and navigation using 360 cameras (e.g., warehouse AGVs, cleaning robots); product: ROS/ROS2 node integrating DAP for real-time panoramic depth and near-field range masking (10/20 m); assumptions/dependencies: runtime optimization may be required for real-time throughput, robustness under motion blur and dynamic scenes.
- Drones/UAVs (near-term outdoor ops): 360° situational awareness for low-altitude navigation and landing-site assessment; workflow: mount 360 camera, stream frames to an edge device/GPU, run DAP with 50–100 m range masks for near–mid-field hazards; assumptions/dependencies: edge compute sufficient for inference, performance reliability in challenging weather/lighting, compliance with aviation safety standards.
- Real Estate and Interior Design: Fast LiDAR-less room scanning for virtual tours and dimensioning; tools: “LiDARless 360 Scan” app using DAP to produce metric meshes/floor plans; assumptions/dependencies: furniture occlusions and reflective surfaces may reduce accuracy; post-processing needed to detect walls/planes.
- Media/Entertainment (AR/VR): Occlusion-aware compositing and depth-based effects in 360 video; product: Unity/Unreal plugins that import DAP outputs for environment occlusion, sky handling, and relighting; assumptions/dependencies: GPU-backed pipelines; static or slowly varying scenes preferred for best results.
- Security/Surveillance: 360-degree hazard proximity analytics in factories and public spaces; workflow: run DAP on ceiling-mounted 360 cameras to estimate distances to people/vehicles, trigger alarms when thresholds are breached; assumptions/dependencies: privacy/regulatory compliance, nighttime/low-light robustness, calibration for metric thresholds.
- Insurance/Claims (Finance): Rapid 360 damage assessment for property claims with volumetric estimates; workflow: capture panoramas post-incident, run DAP to recover geometry, estimate damaged areas/volumes; assumptions/dependencies: accuracy sufficient for triage; interpretability and audit trails needed.
- Construction/Facility Management: Clearance checking, clash detection, and as-is condition capture from panoramic walkthroughs; tools: “Range-Aware Depth API” using DAP to measure corridor widths, door heights; assumptions/dependencies: metric bias at long range should be characterized; integration with BIM/CAD and QA processes.
- Mapping/Geospatial (small areas): Indoor/outdoor micro-mapping from panoramic frames (e.g., retail layouts, parks); workflow: DAP depth + normals to build meshes for navigation signage and accessibility planning; assumptions/dependencies: requires consistent coverage; drift handling if used with SLAM.
- Sports Broadcasting/Cinematography: Depth-aware 360 post-production for crowd segmentation, background replacement, and focus effects; tools: NLE plugins (e.g., Adobe After Effects, DaVinci Resolve) using DAP outputs; assumptions/dependencies: high-resolution processing pipelines; artifact control in fast motion.
- Public Safety (daily life): Cyclist/motorcyclist 360 action cameras with near-field hazard warnings; workflow: DAP-in-the-loop distance alerts using 10–20 m masks; assumptions/dependencies: real-time inference on mobile hardware, weather/night performance.
- Academic Research (methods reuse): Applying the three-stage pseudo-label curation pipeline (Scene-Invariant → Realism-Invariant → foundation training) to other panoramic tasks (segmentation, normals); assumptions/dependencies: availability of discriminators and scene classifiers (e.g., Qwen2-VL), domain-appropriate seed labels.
Long-Term Applications
Below are use cases that are promising but require further research, engineering, or scaling (e.g., real-time performance, reliability in adverse conditions, broader domain coverage, regulatory acceptance).
- Autonomous Driving (surround perception): 360 metric depth for blind-spot monitoring, lane-change safety, and occlusion-aware planning; products: surround-view depth modules fused with camera/IMU/radar; assumptions/dependencies: rigorous validation, night/weather robustness, hard real-time constraints, automotive-grade hardware.
- City-Scale Mapping and Street View Enhancement: Web-scale panoramic metric depth for 3D city models and immersive maps; workflow: batch inference on large panoramic archives, depth-fused meshes; assumptions/dependencies: scalable compute, consistent camera metadata, handling of extreme scene diversity.
- SLAM/Scene Understanding (360 monocular): End-to-end 360 SLAM with metric scale using DAP priors; tools: SLAM systems that fuse DAP depth with IMU/GPS to reduce scale drift; assumptions/dependencies: tight coupling with motion models, latency and error bounds characterized under motion/blur.
- Disaster Response and Search & Rescue: Rapid 360 scene capture for debris volume estimation and path planning inside collapsed structures; workflow: UAV/robot-mounted 360 sensors, DAP-assisted mapping; assumptions/dependencies: low-light/particulate robustness, human-in-the-loop verification, safety-critical certification.
- Construction/BIM Automation: Automated floor plan extraction, semantic labeling, and as-built compliance from 360 captures; product: “Panoramic-to-BIM” pipeline combining DAP depth with semantic segmentation; assumptions/dependencies: high accuracy requirements (code compliance), robust semantic models, integration with regulatory workflows.
- Smart Buildings/Energy: Thermal–visual fusion for energy audits using panoramic depth to quantify volumes and surface areas for HVAC optimization; assumptions/dependencies: multi-modal sensor fusion (thermography + RGB), calibration and per-space modeling.
- Consumer 360 Cameras with On-Device Depth: Embedded, low-power DAP variants for real-time AR measurement, occlusion, and navigation assistance; assumptions/dependencies: model compression/quantization, efficient ViT backbones, thermal/power budgets, vendor support.
- Infrastructure Inspection (Energy/Utilities): 360 depth for tunnels, substations, and plant interiors to detect clearances, corrosion, or deformation; workflow: periodic panoramic surveys with automated delta detection; assumptions/dependencies: domain-specific robustness (dust, low-light), regulatory acceptance, trained inspectors-in-the-loop.
- Robotics (industrial fleets): Fleet-level 360 depth perception for multi-robot coordination in warehouses/ports; tools: standardized DAP APIs with range policies and uncertainty flags; assumptions/dependencies: throughput and reliability at scale, safety certification, cross-device calibration.
- AR Cloud and Telepresence: Panoramic depth-backed environment meshes for multi-user AR alignment and occlusion in large indoor/outdoor venues; assumptions/dependencies: shared mapping infrastructure, latency and consistency across clients, privacy-preserving pipelines.
- Environmental Monitoring/Wildlife Research: Panoramic depth to estimate animal distances and habitat structure in field studies; assumptions/dependencies: performance under foliage/weather, specialized annotations, ethical data handling.
- Policy and Standards: Benchmarks (e.g., DAP-Test) informing procurement standards for panoramic sensing in public projects (transport hubs, stadiums); assumptions/dependencies: transparent evaluation, safety margins, explainability/uncertainty reporting, privacy compliance.
- Web-Scale Data Curation: Generalizing the paper’s three-stage data-in-the-loop pipeline to curate trustworthy labels for other panoramic modalities (e.g., depth+semantics+normals) across the open web; assumptions/dependencies: robust quality discriminators, scalable storage/compute, dataset governance and licensing.
- Night/Adverse Weather Panoramic Depth: Extending DAP with domain-specific training and sensor fusion (NIR/thermal) for reliable operation in low illumination; assumptions/dependencies: multi-sensor hardware availability, expanded training datasets, performance certification in safety-critical contexts.
- Multimodal 3D Content Creation: Generative panoramic pipelines that use DAP depth as geometry priors for photorealistic novel view synthesis and 3D asset creation; assumptions/dependencies: integration with diffusion/NeRF models, IP/licensing for training data, artist-in-the-loop tooling.
Cross-cutting assumptions and dependencies (affect both immediate and long-term feasibility)
- Hardware: Access to 360° cameras and stable equirectangular projections; camera calibration and horizon alignment affect metric accuracy.
- Compute: DINOv3-L backbone implies GPU requirements; real-time scenarios may need model compression or lighter backbones.
- Domain Robustness: Night scenes, extreme weather, underwater, or highly reflective environments may require additional domain-specific training.
- Accuracy/Uncertainty: Safety-critical deployments need quantified uncertainties, calibration procedures, and formal validation.
- Data/License: Availability and licensing of DAP weights, datasets (including synthetic generators like AirSim360/DiT360), and auxiliary tools (Qwen2-VL) influence adoption.
- Integration: Downstream pipelines (BIM/CAD/ROS/Unreal/Unity) require adapters and standard data formats (e.g., point clouds, meshes, ERP conventions).
- Privacy/Compliance: Surveillance or public deployments must adhere to privacy laws and policy guidelines; depth inference pipelines should support anonymization and secure handling.
Collections
Sign up for free to add this paper to one or more collections.