Flipping the Dialogue: Training and Evaluating User Language Models
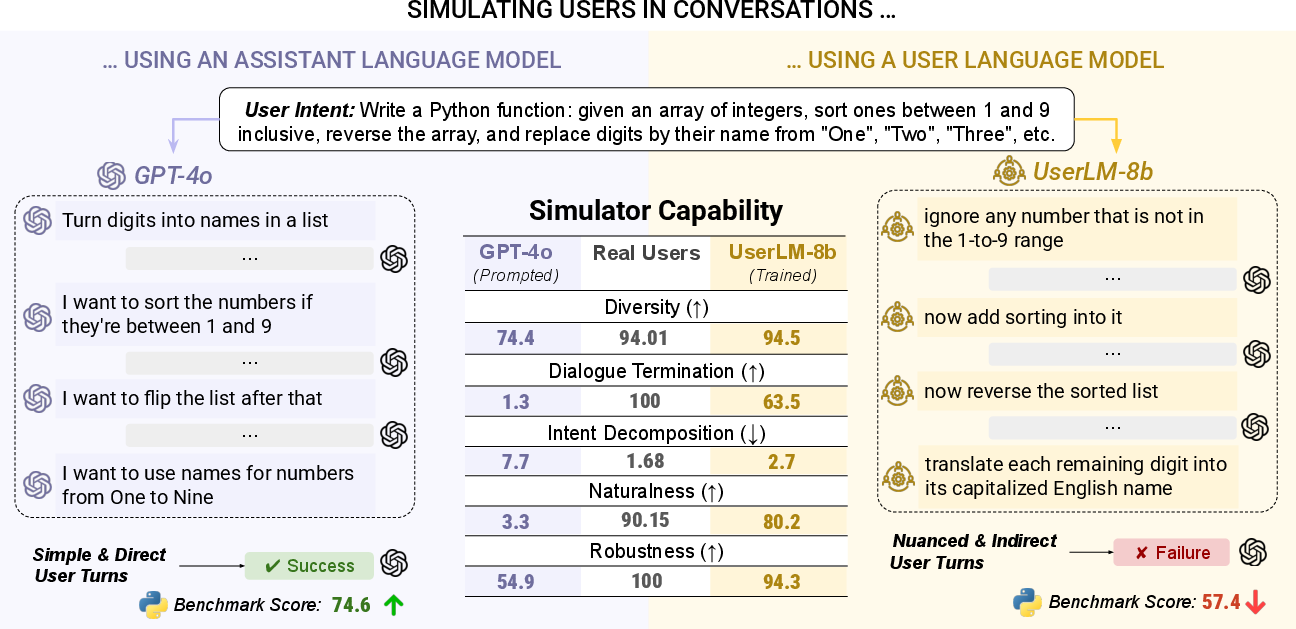
Abstract: Conversations with LMs involve two participants: a human user leading the conversation, and an LM assistant responding to the user's request. To satisfy this specific role, LMs are post-trained to be helpful assistants -- optimized to produce exhaustive and well-structured responses, free of ambiguity and grammar errors. User utterances, on the other hand, are rarely perfected, with each user phrasing requests in unique ways, sometimes putting in partial effort at each turn and refining on the fly. To evaluate LM performance in realistic settings, prior work simulated users in multi-turn conversations, often prompting an LLM originally trained to be a helpful assistant to act as a user. However, we show that assistant LMs make for poor user simulators, with the surprising finding that better assistants yield worse simulators. Instead, we introduce purpose-built User LLMs (User LMs) - models post-trained to simulate human users in multi-turn conversations. Through various evaluations, we show how User LMs align better with human behavior and achieve better simulation robustness than existing simulation methods. When leveraging User LMs to simulate coding and math conversations, the performance of a strong assistant (GPT-4o) drops from 74.6% to 57.4%, confirming that more realistic simulation environments lead to assistant struggles as they fail to cope with the nuances of users in multi-turn setups.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making conversations with AI feel more like real chats with people. Today’s AI assistants are trained to be super helpful and clear. But real people don’t always talk that way: we type quickly, change our minds, forget details, and don’t always explain everything up front. The authors build special “User LLMs” (User LMs) to act like human users in multi-turn chats. They show these user models are better at simulating real people than just asking an AI assistant to pretend to be a user. When assistants interact with these more realistic users, the assistants struggle more—revealing how hard real conversations can be.
Goals and Questions
The paper asks:
- Can we train AI models that talk like real users, not like perfect assistants?
- Do these user models better match how humans really behave in multi-turn chats?
- If we use these user models to test assistant AIs, do we get a more honest picture of how good the assistants are in real-world conversations?
How They Did It
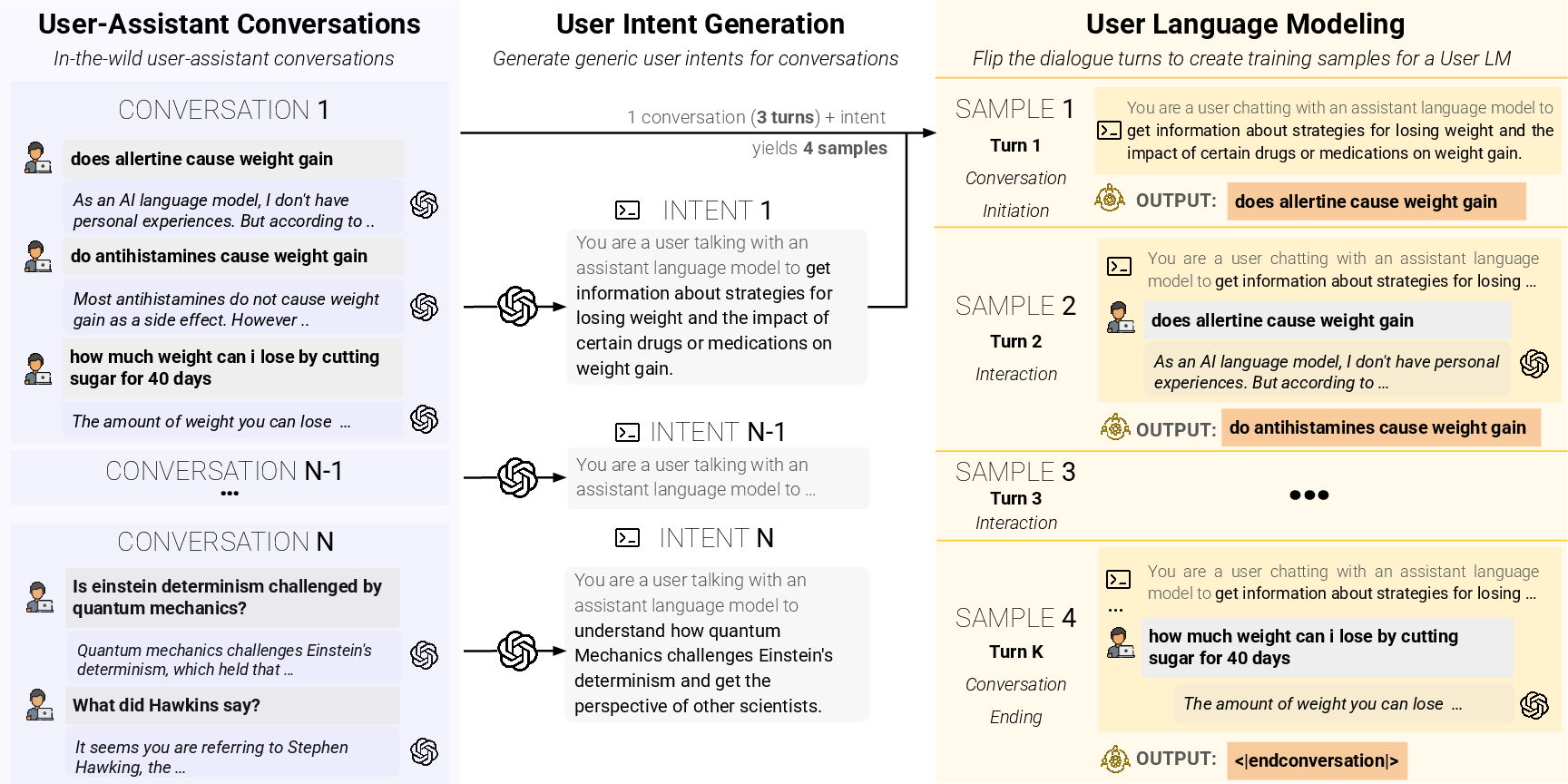
Think of a chat like a text message thread: a user asks for something, and an assistant replies. The authors “flip the dialogue” so the AI learns to produce the user’s messages instead of the assistant’s. They train User LMs using real human–assistant chat logs from the internet.
Key ideas explained simply:
- “User LM”: A computer program trained to write messages like a human user during a chat.
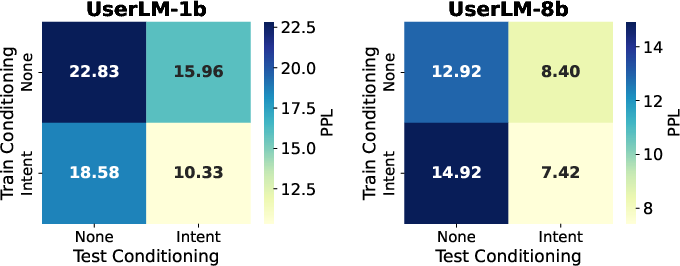
- “Intent”: A short description of what the user wants to do (like “solve a math problem” or “fix a code bug”). The model is “conditioned” on this intent—meaning it always keeps the main goal in mind.
- “Multi-turn”: A conversation with several back-and-forth messages. Real users don’t say everything at once; they spread information over turns.
- “Perplexity”: A score that roughly means “how surprised the model is by real human text.” Lower is better; it means the model’s writing style is closer to how people actually write.
Their training setup:
- They take real human–assistant chats.
- For each chat, they generate a short “intent” that summarizes what the user wanted.
- They train the User LM to produce the next user message, given the intent and the conversation so far.
- They compare different starting points (training from “base” models vs. “instruction-tuned” assistant models) and different sizes (about 1B vs. 8B parameters).
They evaluate in two ways:
- “Intrinsic” tests: Do user models behave like humans? Do they start conversations in varied ways, split their requests across turns, and know when to end the chat? Do they stay in the user role and stick to the intent?
- “Extrinsic” tests: Put a User LM in a real chat with a strong assistant (like GPT-4o) to solve tasks in coding and math. See how well the assistant performs when faced with a more realistic user.
Main Findings
Here are the most important results and why they matter:
- User LMs look more like real users.
- They write first messages that are more diverse and less “robotic.”
- They reveal their intent gradually across turns, like people do, instead of dumping everything at once.
- They actually end conversations at reasonable times. Assistant models pretending to be users often won’t stop chatting.
- User LMs are more robust and natural.
- An AI text detector rated User LM messages as much more human-like than assistant role-play messages.
- User LMs reliably stayed in the “user” role and followed the original intent, even when the chat got confusing. Assistant role-play models often slipped back into acting like an assistant or got easily distracted.
- Better assistants do not make better user simulators.
- Surprisingly, stronger assistant models (like GPT-4o) were worse at pretending to be users than smaller or specially trained user models.
- This shows we shouldn’t just ask a helpful assistant to “act like a user.” We need user-specific training.
- Realistic user simulation makes assistants look less perfect—closer to reality.
- When GPT-4o chatted with a User LM, its task success dropped from about 74.6% to 57.4%.
- This suggests current assistants struggle more than we think when users talk in natural, multi-turn ways.
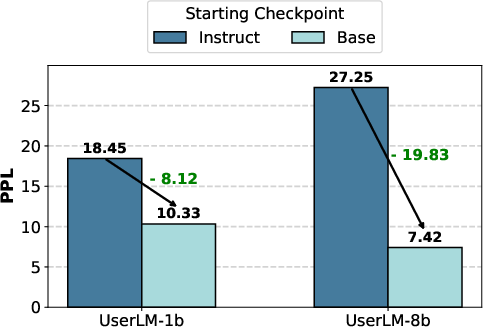
- Training from base models helps.
- Starting User LM training from “base” models (not already tuned as assistants) worked better. It’s easier to teach a model to be a user if it wasn’t previously taught to be an assistant.
Why It Matters
This work helps make AI testing more realistic. If we want assistants that work well in everyday apps (like homework help, coding support, or customer service), they must handle real user behavior: short, messy, evolving requests across multiple turns. User LMs offer a better test environment to catch weaknesses early.
Potential impacts:
- Better evaluation: Companies and researchers can get more honest scores for how assistants perform in multi-turn, real-life conversations.
- Stronger assistants: Training assistants against realistic user simulators could make them more robust and helpful.
- Personalization: Future user models might simulate specific groups (like non-native speakers or teens), improving fairness and usability.
- New tools: User LMs could help generate more varied training data, create more realistic judges of assistant quality, or even simulate survey responses in research.
The authors also share their model (UserLM-8b) for research. They note safety concerns: user-style AI text can look very human, making it harder to detect. They encourage building better tools to tell apart real human text from user-model-generated text.
In short, the paper flips the usual perspective—training models to be realistic users, not just perfect assistants—so we can build and test AI systems that handle real conversations better.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The following list distills what remains missing, uncertain, or unexplored in the paper, framed to guide actionable future research:
- Data provenance and coverage: The training relies on WildChat and PRISM logs; the domains, demographics, languages, and task types represented are not characterized, limiting external validity and cross-domain generalization.
- Cross-lingual and dialectal behavior: UserLMs are evaluated primarily on English; there is no assessment of multilingual, code-switching, or dialectal user behavior, despite claims about non-native speakers and diverse personas.
- Intent generation pipeline: The method for deriving “generic” or high-level intents from raw conversations is not specified or audited (e.g., accuracy, consistency, robustness to noise), leaving unclear how intent conditioning quality affects model behavior and evaluations.
- Human validation of “user-like” behavior: No human-in-the-loop studies verify that UserLM outputs are realistic to actual users across tasks and personas, nor whether simulated dialogues elicit the same assistant failures as with real users.
- Overreliance on perplexity: PPL is used as a primary alignment metric across heterogeneous models; calibration issues and known limitations of PPL for conversational behavior are not addressed, and correlations to human realism are not validated.
- Metric definitions and ground truth: Intrinsic metrics (e.g., first-turn diversity, “intent decomposition,” dialogue termination F1, role/intent adherence) lack formal definitions, labeling details, and inter-rater reliability; termination lacks human ground truth.
- AI detector validity: “Naturalness” is assessed via the Pangram AI text detector, which is not designed for user-written text distributions; detector bias and false positives/negatives are not quantified, weakening conclusions about human-likeness.
- LLM-as-judge bias: Role and intent adherence (and possibly other metrics) appear to rely on LLM-based classification or heuristics; there is no audit for judge bias, reliability, or susceptibility to the same assistant artifacts the work critiques.
- Simulation realism beyond surface text: The paper does not measure pragmatics such as typos, disfluencies, emoji/formatting habits, politeness strategies, hedging, or frustration, which are central to realistic user behavior.
- Modeling user effort and stopping decisions: While conversation termination is measured, explicit modeling of user effort, cost-sensitive behavior, or strategic early exit (e.g., “good enough” thresholds) is not incorporated or evaluated.
- Generalization across assistants: Extrinsic results focus on GPT-4o (and -mini); broader testing across different assistant architectures, alignment strategies, and settings (e.g., retrieval-augmented, tool use) is missing.
- Task breadth: Simulations are limited to coding and math; transfer to creative, legal, scientific, or information-seeking dialogues—where user behaviors and assistant weaknesses differ—is not examined.
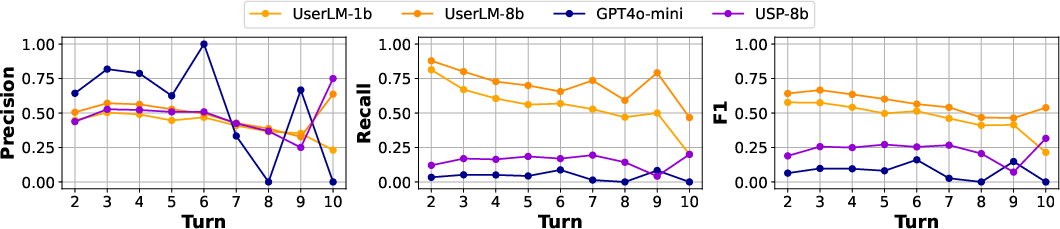
- Comparative baselines: Extrinsic evaluation omits other trained simulators (e.g., USP-8b) despite including them in intrinsic comparisons; a broader set of baselines would clarify where UserLMs offer unique gains.
- Statistical rigor: No confidence intervals, significance testing, or sensitivity analyses (e.g., seeds, decoding parameters) are reported, leaving robustness of observed performance drops unquantified.
- Decoding sensitivity and controllability: Effects of sampling strategies (temperature, top-p), prompt formats, and constraint decoding on simulator realism and assistant performance are not explored.
- Safety and misuse risks: The authors note UserLM-8b may generate toxic content and evade detectors; there is no systematic safety evaluation (toxicity, harassment, privacy leakage), red-teaming, or mitigation strategy.
- Data ethics and privacy: The use of real interaction logs raises privacy and consent considerations; the paper does not address sensitive content, anonymization quality, or compliance with data handling norms.
- Persona fidelity and personalization: While envisioned as future work, there is no concrete method or validation for conditioning on demographic/persona attributes without introducing stereotypes or spurious correlations.
- Drift realism: Real users frequently change goals mid-conversation; “intent adherence” is treated as a virtue, but the realism of stubborn adherence versus natural drift is not benchmarked against human behavior.
- Causal claims on assistant scaling: The finding that “better assistants yield worse simulators” is based on a small set of models; confounds (instruction tuning regimen, decoding, prompts) are not disentangled via controlled ablations.
- Sim-to-real transfer: The central claim—that more realistic simulations yield more accurate estimates of assistant performance—lacks validation against real-user studies; external calibration of simulation-derived scores is absent.
- Training recipe transparency: Key training details (objectives, loss weighting, negative samples for role adherence, curriculum, data splits) are not fully specified, hindering reproducibility and explaining why base checkpoints outperform instruct ones.
- Conversation state modeling: The approach “flips dialogues” to condition on prior turns and intent, but lacks analysis of state tracking fidelity, memory limitations, and error propagation across long contexts.
- Termination policy learning: There is no explicit modeling or supervised signal for when to end conversations; grounded termination criteria (task completion detection, satisfaction signals) remain an open design question.
- Domain adaptation and few-shot tuning: How to effectively adapt general-purpose UserLMs to niche domains with limited logs (e.g., law, medicine) and measure gains versus risks remains unexplored.
- Impact on assistant training: The hypothesized benefit of UserLMs as simulation environments for RLHF/RLAIF is not empirically tested; it is unknown whether training assistants against UserLMs improves real-world robustness.
- Evaluation artifacts from intent conditioning: The paper shows intent conditioning reduces PPL, but does not quantify how conditioning affects lexical diversity, abstraction, or assistant difficulty independent of realism.
- Long-horizon conversations: Turn variance/range is measured, but there is no analysis of very long or nested dialogues (e.g., multi-session, interrupted tasks), where user behavior and assistant shortcomings are more pronounced.
- Fairness and bias auditing: No assessment of demographic, cultural, or linguistic bias in UserLM outputs or in assistant failure modes elicited by simulated users; fairness-aware evaluation is missing.
- Open-source base model availability: The work notes the scarcity of base checkpoints but does not outline criteria or protocols for safely releasing base models suitable for user simulation (capability, safety, documentation).
Practical Applications
Overview
The paper introduces User LLMs (User LMs) purpose-built to simulate realistic human behavior in multi-turn conversations with assistant LMs. By “flipping the dialogue” and conditioning on a high-level user intent plus conversation state, UserLMs generate user turns that better match human diversity, underspecification, pacing, and termination behavior than prompting assistant LMs to role-play users. Empirically, replacing assistant-role simulators with UserLMs yields more stringent and realistic assessments (e.g., GPT-4o’s task score drops from 74.6% to 57.4% under UserLM-8b simulation), revealing gaps that static or overly-cooperative simulations miss. The authors release open models (UserLM-1b/8b) to catalyze research and practice.
Below are practical applications derived from the paper’s findings, methods, and innovations, grouped by immediacy. Each item lists sectors, plausible tools/products/workflows, and key assumptions/dependencies that affect feasibility.
Immediate Applications
These can be deployed now with the released UserLM-8b and the paper’s evaluation recipes.
- Realistic multi-turn evaluation harness for AI assistants
- Sectors: software platforms, developer tools, AI product teams
- Tools/workflows: “UserLM-in-the-loop” test suites that measure first-turn diversity, intent decomposition, termination F1, role/intent adherence; CI/CD gating for assistant regressions; pre-release acceptance tests
- Assumptions/dependencies: access to microsoft/UserLM-8b; evaluation metrics and prompt templates; MLOps integration; safety filters on outputs
- Conversation fuzzing for robustness
- Sectors: software, customer support, productivity assistants
- Tools/workflows: generate paraphrased, underspecified, and drifting user turns to stress-test assistants’ clarifying question policies and recovery from ambiguity
- Assumptions/dependencies: coverage controls for intents; guardrails to prevent toxic outputs; monitoring for overfitting to simulator quirks
- Synthetic data generation focused on multi-turn realism
- Sectors: AI model training (assistant fine-tuning), platform providers
- Tools/workflows: pipelines that synthesize diverse, multi-turn conversations for robustness finetuning (e.g., underspecification, paraphrases, mid-task requirement changes)
- Assumptions/dependencies: data filtering and deduplication; watermarking/labeling of synthetic data; balance with human data to avoid simulator bias
- Hardening prompts and policies for assistants
- Sectors: cross-industry AI deployments
- Tools/workflows: iterate system prompts and policy rules (e.g., “always ask a clarifying question when intent coverage < X%”) against UserLM test batteries until performance stabilizes
- Assumptions/dependencies: measurable “intent coverage” and “information selection” metrics; evaluation budget
- Customer-support/chatbot pre-deployment testing
- Sectors: telecom, e-commerce, banking, travel
- Tools/workflows: red-team conversational bots with UserLM-generated user queries that end naturally, switch requirements, or escalate; escalation policy tuning
- Assumptions/dependencies: domain-specific intents; content safety layers; handoffs to human agents
- Coding assistant and IDE evaluation
- Sectors: software engineering tools
- Tools/workflows: simulate coding sessions with partial requirements and evolving constraints; assess when assistants over-assume vs. ask clarifying questions; refine code-completion strategies
- Assumptions/dependencies: task libraries (bugs, refactors), code execution sandboxes; integration with IDE telemetry
- AI tutor assessment with simulated students
- Sectors: education technology
- Tools/workflows: evaluate tutors on handling incomplete, indirect, or inconsistent student queries; instrument when to probe vs. present solutions; measure learning-oriented pacing
- Assumptions/dependencies: age/grade-level intents; curriculum-aligned tasks; content moderation for minors
- Research-grade, reproducible multi-turn benchmarks
- Sectors: academia, evaluation labs, standards bodies
- Tools/workflows: release benchmark suites where UserLMs provide consistent, human-like user turns; enable ablations on termination, pace variance, lexical diversity
- Assumptions/dependencies: transparent prompts and decoding configs; public leaderboards; community-agreed metrics
- Judge prototyping for user-centric evaluation
- Sectors: AI evaluation, marketplace ranking, RLHF/RLAIF research
- Tools/workflows: prompt UserLMs to produce user-perspective rationales/preferences that complement assistant-centric judges; ensemble judging
- Assumptions/dependencies: careful prompt design to avoid assistant bias; calibration with human ratings
- Survey and instrument piloting with natural open-ended text
- Sectors: market research, social science
- Tools/workflows: generate realistic free-text answers to pilot questionnaires (e.g., discover ambiguity, instruction length tolerance); test cognitive load before fielding
- Assumptions/dependencies: not a substitute for real respondents; demographic representativeness is limited without personalization; ethical labeling of synthetic responses
- Safety and role-adherence stress testing
- Sectors: platform safety, red teaming
- Tools/workflows: systematically probe assistants’ sycophancy, role drift, and conversation-ending behavior; build regression tests for improvements
- Assumptions/dependencies: safe prompt libraries; human-in-the-loop review for high-risk content
- Product/UX discovery via Wizard-of-Oz-at-scale
- Sectors: product design, HCI research
- Tools/workflows: simulate qualitative “user feedback” conversations to uncover phrasing pain points; prioritize UX fixes for frequent ambiguity patterns
- Assumptions/dependencies: triangulate with real-user studies; avoid over-reliance on simulator artifacts
Long-Term Applications
These require further research, scaling, domain adaptation, or governance frameworks.
- Personalized and demographic-specific UserLMs
- Sectors: all sectors deploying chat assistants; academia (HCI, fairness)
- Tools/products: persona packs (e.g., language proficiency, cultural background, accessibility needs) to audit and improve personalization
- Assumptions/dependencies: privacy-preserving data collection; bias/fairness audits; consent and governance for training data
- Simulation-driven RL training curricula for assistants
- Sectors: AI model development
- Tools/products: closed-loop training where assistants learn via interaction with UserLMs that progressively increase challenge (drift, interruptions, multi-goal tasks)
- Assumptions/dependencies: simulator fidelity; reward design aligned to user outcomes; prevent overfitting to simulator policies
- Domain-specialized UserLMs (healthcare, legal, finance)
- Sectors: healthcare triage/portals, legal help, banking support
- Tools/products: safety-evaluated simulators that reflect domain jargon, compliance constraints, and escalation norms
- Assumptions/dependencies: expert-curated intent catalogs; rigorous safety/ethics review; strong guardrails; regulatory approvals
- Multilingual and code-switching UserLMs
- Sectors: global platforms, public services
- Tools/products: simulators for multilingual user bases; evaluation of assistants’ language-switch handling and translation robustness
- Assumptions/dependencies: high-quality multilingual user logs; locale-specific safety filters; cultural sensitivities
- Standardized, certified multi-turn benchmarks in procurement
- Sectors: government, large enterprise IT sourcing
- Tools/products: certification suites mandating performance thresholds under realistic simulation (termination, pace, intent adherence) before deployment
- Assumptions/dependencies: standards consortium agreement; reproducibility; test security
- Continuous auditing and online shadow testing with digital user twins
- Sectors: regulated industries, consumer protection
- Tools/products: fleets of UserLM-based “digital twins” to monitor live systems for behavioral drift, fairness disparities, and safety regressions
- Assumptions/dependencies: safe, privacy-preserving operation; detection of simulator–real gap; real-user validation loops
- Watermarking and detection for simulator-generated text
- Sectors: research, policy, platforms
- Tools/products: robust watermarking of UserLM outputs used for training/evaluation; detectors to distinguish UserLM vs. human utterances
- Assumptions/dependencies: technical feasibility of resilient watermarks; coordination to prevent evaluation contamination
- Education: adaptive tutoring design with simulated student populations
- Sectors: EdTech
- Tools/products: curriculum optimization and A/B exploration using persona-specific student simulators (e.g., prior knowledge, motivation, accessibility)
- Assumptions/dependencies: strong pedagogical oversight; alignment with learning outcomes; equity audits
- Healthcare: pre-certification simulation of patient-facing chatbots
- Sectors: health systems, digital therapeutics
- Tools/products: simulate symptom descriptions with varied literacy and cultural contexts to test triage, safety disclaimers, and escalation to clinicians
- Assumptions/dependencies: medical-domain training/supervision; regulatory compliance (HIPAA/GDPR); human oversight
- Conversational recommendation and e-commerce evaluation
- Sectors: retail, media, travel
- Tools/products: simulate shoppers with evolving preferences and constraints to stress-test recommendation dialogues and consent/upsell policies
- Assumptions/dependencies: domain and catalog grounding; privacy-preserving logs; fairness in personalization
- Human agent training with realistic simulators
- Sectors: customer service, sales, helpdesk
- Tools/products: scenario generators that produce diverse, naturalistic customer conversations to train human agents and measure resolution strategies
- Assumptions/dependencies: alignment to company policies; scenario labeling; feedback loops from real interactions
- Policy research on synthetic user simulation governance
- Sectors: policy, standards, academia
- Tools/products: frameworks on consent, provenance, and appropriate use of synthetic user utterances in training, evaluation, and audits
- Assumptions/dependencies: multi-stakeholder agreement; legal clarity on synthetic data; enforcement mechanisms
- Better assistant design patterns from simulator insights
- Sectors: cross-industry
- Tools/products: codified guardrails (e.g., clarify-before-answer, ending heuristics, anti-sycophancy prompts) derived from systematic simulation studies
- Assumptions/dependencies: external validation with real-user experiments; continuous improvement cycles
Notes on feasibility across applications:
- Simulator fidelity matters: while UserLMs outperform assistant role-play, real-user validation remains essential to avoid simulator-induced bias.
- Safety is non-optional: base-model origins imply a need for content moderation and alignment layers when deploying UserLMs in pipelines.
- Data governance: training personalized/domain-specific UserLMs requires privacy-preserving collection, consent, and bias auditing.
- Avoid overfitting to the simulator: maintain diversity in simulators (multiple seeds/personas/models) and triangulate with human studies.
Glossary
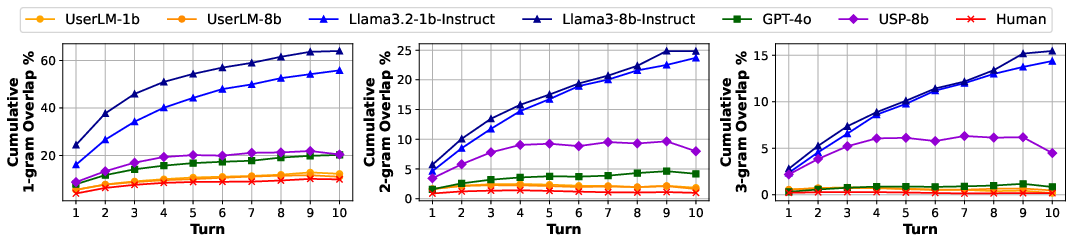
- Abstractive utterances: User turns that paraphrase or rephrase intent rather than copying it verbatim. "User LMs are also better at decomposing intent across turns and produce more abstractive utterances, with an average overlap of 2.69% with the conditioned intent"
- Assistant LMs: LLMs post-trained to act as helpful assistants in conversations. "assistant LMs often fall short of demonstrating their capabilities in multi-turn conversations with users"
- Base LMs: Pretrained models before instruction tuning or role-specific post-training. "Our experiments show that training user LMs from base LMs is more effective than starting from an instruction-tuned checkpoint"
- Conditional distribution: The probability distribution of user utterances given conditioning variables (e.g., intent and conversation state). "train the UserLM to model the conditional distribution of user utterances"
- Decoding configuration: The generation settings (e.g., temperature, top-p) used when sampling outputs from a LLM. "We report the decoding configuration we used for our UserLM-8b"
- Dialogue termination: The ability to recognize and end a conversation at an appropriate point. "first-turn diversity, intent decomposition, dialogue termination"
- Distributional alignment: How closely a model’s outputs match the statistical distribution of human utterances. "measuring distributional alignment (i.e., perplexity) with real human utterances on out-of-domain data"
- Distributional measures: Statistical metrics (like perplexity) that summarize properties of text distributions. "Beyond distributional measures such as perplexity"
- Extrinsic evaluation: Assessment based on downstream task performance via interaction with another system. "we now deploy them as part of an extrinsic evaluation"
- F1 score: The harmonic mean of precision and recall used to evaluate binary or multi-class decisions. "achieving an F1 score of 63.54"
- Foundation model: A broadly trained, general-purpose model that can be adapted to many tasks. "UserLM-8b is a general-purpose foundation model that can model users in WildChat and PRISM."
- Generic intent: A high-level intent category used to condition and steer the simulator. "conditioning on the generic intent"
- Instruction-tuned checkpoint: A model that has been fine-tuned to follow instructions, with weights saved at a specific training state. "Effect of starting from the base vs. instruction-tuned checkpoints."
- Intent adherence: The degree to which a simulated user sticks to the original task intent without getting distracted. "The results on intent adherence (-0.3ex{fig/icon-locked.png}) paint a similar picture to role adherence"
- Intent coverage: The extent to which the conversation touches all required elements of the intended task. "Each simulator is evaluated on its coverage of the intent"
- Intent decomposition: Spreading and revealing parts of the user’s intent across multiple turns. "intent decomposition"
- Lexical diversity: Variety in word choice, often measured by differences in n-grams or vocabulary usage. "Lexical Diversity"
- Multi-turn interaction: Conversational dynamics across multiple back-and-forth turns between user and assistant. "evaluations targeting multi-turn interactions between a user and an assistant"
- Naturalness: How human-like and non-AI-generated a text appears to detectors or readers. "This sharpens our understanding of naturalness in three ways"
- Perplexity (PPL): A language-model metric quantifying how well the model predicts text; lower is better. "Perplexity (PPL)"
- Post-training: Additional training after pretraining to shape a model’s behavior for a specific role. "models are post-trained to be perfect ``assistants''"
- Role adherence: The consistency with which a simulator maintains its assigned role across conversation. "The results for role adherence (-0.3ex{fig/icon-user.png}) show how the three trained user LMs achieve stellar robustness"
- Simulation robustness: The reliability of a simulator in maintaining realistic behavior and intent under varying conditions. "achieve better simulation robustness than existing simulation methods"
- Sycophantic nature: A tendency of models to overly agree or please conversational partners. "related to the sycophantic nature of assistant LMs"
- Turn variance: Variation in the number of turns taken across simulated conversations. "Turn Variance"
- Unigram (1-gram): A single token used in n-gram analysis; unique 1-grams measure lexical variety. "User LMs generate more diverse first turns, with UserLM-8B achieving 94.55% unique 1-grams"
- User intent: The goal or task the user aims to accomplish in the conversation. "given a defined user intent"
- User LLMs (User LMs): Models trained specifically to simulate realistic human users in dialogue. "we introduce purpose-built User LLMs (User LMs) - models post-trained to simulate human users in multi-turn conversations."
- User simulator: A system that mimics human user behavior for evaluating assistants. "user simulators typically rely on prompting assistant LMs to role-play users"
Collections
Sign up for free to add this paper to one or more collections.

