REAP the Experts: Why Pruning Prevails for One-Shot MoE compression
Abstract: Sparsely-activated Mixture-of-Experts (SMoE) models offer efficient pre-training and low latency but their large parameter counts create significant memory overhead, motivating research into expert compression. Contrary to recent findings favouring expert merging on discriminative benchmarks, we demonstrate that expert pruning is a superior strategy for generative tasks. We prove that merging introduces an irreducible error by causing a "functional subspace collapse", due to the loss of the router's independent, input-dependent control over experts. Leveraging this insight, we propose Router-weighted Expert Activation Pruning (REAP), a novel pruning criterion that considers both router gate-values and expert activation norms. Across a diverse set of SMoE models ranging from 20B to 1T parameters, REAP consistently outperforms merging and other pruning methods on generative benchmarks, especially at 50% compression. Notably, our method achieves near-lossless compression on code generation and tool-calling tasks with Qwen3-Coder-480B and Kimi-K2, even after pruning 50% of experts.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at how to make very large AI LLMs smaller and easier to run, without hurting their abilities too much. It focuses on a special kind of model called a Mixture-of-Experts (MoE), where many small “expert” networks work together. The authors compare two ways to reduce the number of experts: merging experts into one, and pruning (removing) some experts entirely. They show that pruning is better than merging for models that generate text, like writing code or stories. They also introduce a new pruning method called REAP that decides which experts to remove more intelligently.
What is a Mixture-of-Experts (MoE) model?
Imagine a big team with many specialists (experts). A “router” acts like a manager who picks a few experts to handle each incoming task (each token of text). This choice changes depending on the input, so the model only uses a small subset of experts at a time. That makes training and running the model faster, even though the model has lots of parameters.
- Router: chooses which experts to use for each input and how much to trust each (these trust amounts are called gate-values).
- Experts: small networks that process the input in different ways and produce outputs.
- Top-k: the router selects only the best few experts for each input.
What questions did the researchers ask?
- If we want to compress (shrink) MoE models without retraining, is it better to merge experts or to prune them?
- Why does merging sometimes look good on “discriminative” tests (like multiple-choice questions) but perform poorly on “generative” tasks (like writing code or creative text)?
- Can we design a smarter way to prune experts so we remove the least important ones?
How did they study it?
Pruning vs. merging (in everyday terms)
- Merging: blend two experts into one by averaging their parameters. This keeps a “memory” of both but turns them into a single fixed expert.
- Pruning: remove an entire expert and let the router continue to choose among the remaining ones.
Why merging loses flexibility
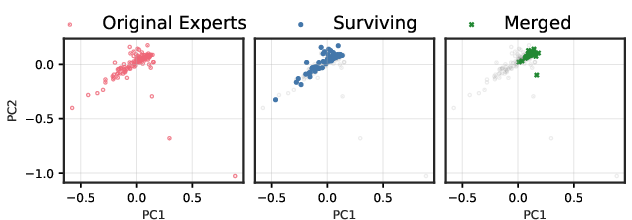
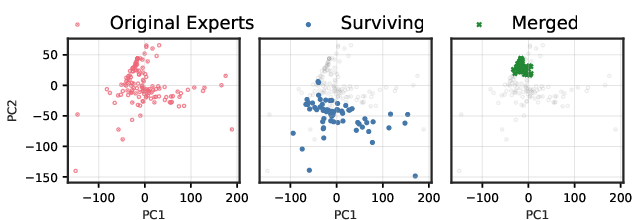
Think of the router as a manager who mixes two experts differently depending on the situation. When you merge those two experts into one, the manager can no longer adjust the mix—there’s just one fixed “average expert.” The paper proves this creates an error you can’t fully avoid without retraining. They call the effect “functional subspace collapse,” which basically means the model’s range of behaviors shrinks because the manager loses independent control over those experts.
The REAP pruning method
REAP stands for Router-weighted Expert Activation Pruning. It decides which experts to prune using two things:
- How much the router trusts an expert when it’s selected (its gate-value).
- How strong the expert’s output is when it’s active (its activation magnitude).
Analogy: If each expert is a worker, the gate-value is how much the manager listens to them, and the activation magnitude is how much work they actually contribute. REAP prunes the workers who both aren’t trusted much and don’t contribute much when they are picked.
Experiments
The authors tested on many MoE models ranging from about 20 billion to over 1 trillion parameters. They compressed models by 25% and 50% in a “one-shot” way (no extra fine-tuning), and evaluated:
- Generative tasks: code generation, creative writing, math reasoning, tool use.
- Discriminative tasks: multiple-choice question answering.
They also checked how the compressed models’ outputs compared to the originals (things like diversity of generated text and how close the predictions were).
What did they find?
Here are the main results, summarized:
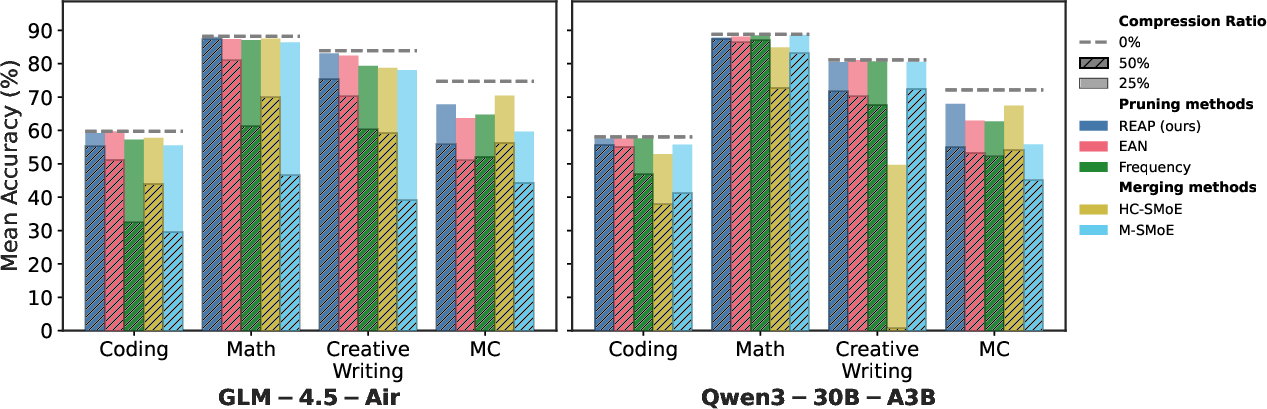
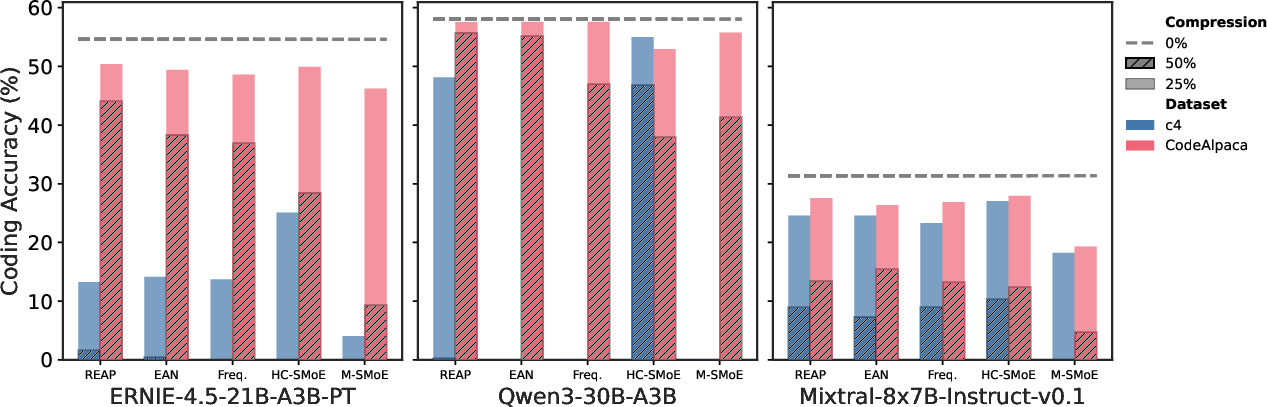
- Pruning beats merging on generative tasks: When the model needs to generate text step-by-step (like writing code), pruning maintains quality much better than merging, especially at 50% compression.
- Merging can look okay on multiple-choice tests: These tasks don’t require step-by-step generation. A “blended” expert can still do fine when the model just scores answer choices, but it breaks down when the model must write long, coherent outputs.
- REAP is a strong pruning method: It consistently outperforms other pruning strategies, particularly at 50% compression.
- Near-lossless compression for big coding models: With REAP, pruning 50% of experts in very large coding models like Qwen3-Coder-480B and Kimi-K2 still kept performance close to the original on code generation and tool use tasks.
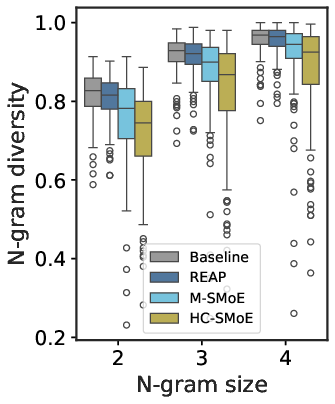
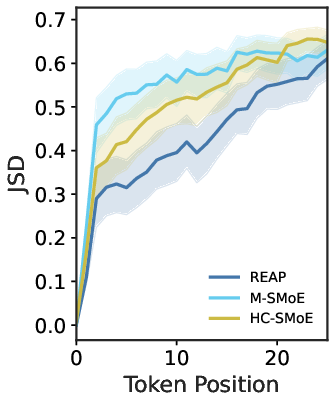
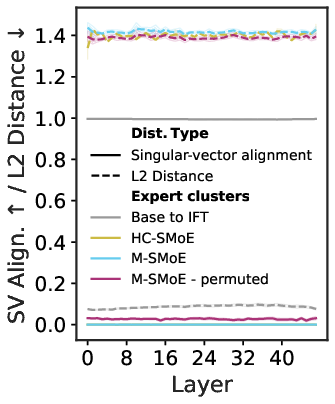
- Evidence of “collapse” when merging: Merged models lost variety in what they can generate, their outputs drifted away from the original model over time, and their internal expert behaviors squeezed towards the center (less specialization). This supports the idea that merging removes the router’s fine-grained control.
- Domain-specific calibration matters: Using calibration data that matches the target task (e.g., code data for code generation) leads to much better compression quality than using general text.
Why does it matter?
- Better compression for real-world use: Pruning, especially with REAP, lets you run large MoE models with fewer resources while keeping quality, which is great for local deployments, research labs, and situations with small batch sizes.
- Faster and simpler deployment: Pruning is easier to apply than merging in practical settings (for example, with quantized models), and it improves memory use and hardware efficiency.
- Choose the right evaluation: If your model is meant to generate text, test compression using generative tasks—not just multiple-choice or perplexity—so you don’t get a misleading picture.
- Design principle: Keep the router’s independent control. Methods that preserve this control (like pruning) are better for generative performance than those that remove it (like merging).
Bottom line
If you want to shrink a Mixture-of-Experts LLM without retraining, pruning—with a smart method like REAP—is usually the best choice, especially for tasks where the model has to write or reason step-by-step. Merging may look fine on tests that only require picking answers, but it removes the router’s flexibility and hurts generative quality. The authors share open-source code and some compressed models to help others use these ideas.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- One-shot-only compression: No experiments on post-compression fine-tuning (router or experts) to test whether small amounts of training can mitigate pruning or merging errors, alter comparative conclusions, or recover generative quality.
- Theoretical assumptions unverified: The irreducible error proof relies on independence between router policy and expert functions and summed-gate merging; the paper does not empirically validate these assumptions or explore whether alternative merge formulations (e.g., non-summed gates, router retraining, learned input-conditioned mergers/adapters within merged experts) reduce the bound.
- Pairwise merge analysis only: The theory analyzes merging two experts into one; there is no generalization to realistic hierarchical or many-to-one merges with rigorous bounds (the hierarchical clustering extension is referenced but not formally developed).
- No formal guarantees for REAP: REAP’s pruning rule assumes small gate-values for pruned experts and uses average gated activation norm as importance, but the paper does not provide error bounds, optimality conditions, or robustness proofs for this criterion versus alternatives (e.g., EAN, gradient-based, or reconstruction-loss criteria).
- Calibration dependence left open: Strong dependence on domain-specific calibration is shown, but the paper does not characterize sensitivity to calibration dataset composition, sample size, sequence length, token packing, or cross-domain generalization after pruning/merging.
- Global vs per-layer pruning strategy: The work prunes fixed percentages per layer; it does not evaluate global pruning (selecting experts to prune across layers), adaptive per-layer budgets, or schedules that account for layer specialization.
- Compression ratios beyond 50%: The study focuses on 25–50% compression; behavior at higher rates (60–80%), iterative pruning schedules, and combined pruning+distillation or light fine-tuning remain unexplored.
- Router re-normalization effects: The pruning error approximation treats 1 − g_j(x) ≈ 1; the paper does not analyze or safeguard against cases where pruned experts have non-negligible gate-values, nor quantify worst-case deviations due to re-normalization.
- Load balancing and hardware utilization: Claims that pruning may reduce expert usage imbalance are not substantiated with metrics (per-expert utilization histograms, gating entropy) or hardware outcomes (latency, throughput, token drop rates, memory/HBM footprint, scheduling efficiency on GPUs/TPUs/AI accelerators).
- Interaction with other compression methods: Although orthogonality is noted, the paper does not evaluate synergies or ordering effects of pruning with quantization (including block-scale re-quantization), low-rank, PEFT/adapters, or weight sparsity, nor their combined impact on generative quality and memory savings.
- Alternative merging strategies: The study evaluates HC-SMoE and M-SMoE but leaves untested merging variants (task-vector based merges, feature/activation rescaling, improved neuron permutation/alignment, learned routers post-merge, smaller per-layer merges, hybrid prune+merge) that might retain router controllability or reduce functional collapse.
- Expert cluster cardinality: The observation that large “mega-clusters” harm performance is not turned into a principled merge constraint or algorithm; optimal cluster-size caps and their trade-offs remain uncharacterized.
- Shared experts and architectural specifics: Effects of pruning shared experts, first-layer dense vs MoE layers, different top-k settings, and router formulations (softmax vs other gating mechanisms) are not systematically studied.
- Robustness and variance: Large model results are often single-seed; the paper does not report performance variance across seeds, calibration randomness, or distribution shifts (e.g., out-of-domain inputs, adversarial prompts).
- Safety, toxicity, and factuality: No evaluation of safety, harmful content generation, or factual consistency post-compression; implications for real-world deployments are unknown.
- Long-context and reasoning behaviors: The impact on long-context tasks, in-context learning, chain-of-thought (reasoning-enabled) models, and multilingual scenarios is not assessed.
- Tool-use generality: Tool-calling results are limited to BFCLv3; the generality across diverse tool ecosystems, multi-agent setups, and longer multi-turn workflows remains to be measured.
- Generative divergence characterization: JSD and n-gram diversity signal merged-model degeneration, but the paper does not connect these to downstream failure modes (e.g., hallucination rates, code execution pass@k) or propose metrics to monitor/restrict divergence during compression.
- PCA-based subspace evidence scope: Functional subspace collapse is visualized via PCA on c4; the paper does not quantify mixing-ratio variability (Var[r(x)]) per layer, overlap of top-k supports, or replicate the analysis on task-specific datasets, nor provide layer-wise aggregate metrics.
- Practical calibration cost: The calibration pipeline (e.g., 12,228 samples up to 16,384 tokens) has non-trivial runtime/memory costs; the minimal effective calibration budget and its trade-offs with accuracy and model scale are not studied.
- Memory and efficiency accounting: Concrete parameter-memory reductions, activation memory changes, and end-to-end speedups are not reported; without these, practical benefits of pruning vs merging on different hardware remain speculative.
- Reversibility and dynamic strategies: Whether pruned experts can be reintroduced (dynamic pruning), or token-level adaptive pruning (beyond static top-k) yields better trade-offs is not explored.
- Training-time implications: It remains open whether training-time interventions (e.g., router regularization, auxiliary load-balancing, sparsity-aware training) can make experts more prunable and preserve router controllability after compression.
- Generalization across MoE families: The results are limited to specific open-weight SMoEs (e.g., Qwen, GLM, Mixtral, Kimi); the behavior on other architectures (e.g., DeepSeek-V3 variants, Switch-Layer designs, fine-grained/Shared-Expert configurations) and quantization formats (FP8 vs W4A16) is not comprehensively evaluated.
- Release reproducibility: While code and select checkpoints are released, reproducibility of the largest experiments (calibration data, settings, hardware) and ease of applying REAP to other checkpoints are not fully detailed.
Glossary
- Agentic coding: A coding evaluation setting where the model acts as an autonomous agent (often with tools and multi-step interactions). "Large-scale pruned SMoEs on agentic, non-agentic coding, tool-use tasks, and MC benchmarks."
- Auto-regressive generation: Sequence generation where each token is produced conditioned on previously generated tokens. "Generative tasks require auto-regressive generation, a capability that is lost when the router's fine-grained control is removed."
- Auxiliary-loss-free load balancing: A technique to balance expert usage without adding auxiliary loss terms during training. "auxiliary-loss-free load balancing~\citep{deepseek-ai_deepseek-v3_2024}"
- Block quantization formats: Quantization schemes that share scaling parameters across blocks of weights. "expert merging necessitates re-quantization for block quantization formats that share common scaling coefficients across a group of weights."
- Calibration dataset: A dataset used to collect statistics (e.g., activations, logits) to guide compression decisions. "measured on every token in a calibration dataset"
- Convex combination: A linear combination of vectors with non-negative weights that sum to one. "a constant convex combination of the constituent experts"
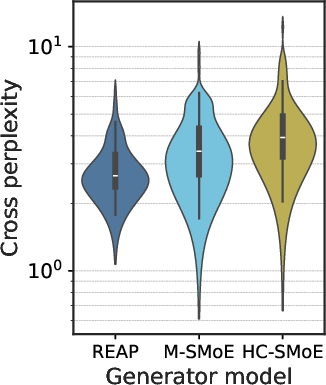
- Cross perplexity: Perplexity computed by evaluating text generated by one model under another model’s distribution. "Cross perplexity"
- Domain-specific calibration: Calibrating compression using data from the target domain to preserve performance. "The importance of domain-specific calibration."
- Expert activation norm (EAN): A pruning criterion that scores experts by the magnitude (norm) of their activations. "\gls{ean} was empirically found to be the highest performing criterion"
- Expert merging: Compressing MoE layers by combining multiple experts into fewer experts via clustering and parameter averaging. "Contrary to recent findings favouring expert merging on discriminative benchmarks"
- Expert pruning: Compressing MoE layers by removing entire experts from the model. "Initial expert compression efforts focused on expert pruning, the removal of experts in their entirety."
- Fine-grained experts: Many smaller, specialized experts that increase routing granularity. "shared experts, and fined-grained experts~\citep{dai_deepseekmoe_2024}"
- Frequency-weighted parameter averaging: Merging expert parameters by averaging them with weights proportional to expert usage. "merged using frequency-weighted parameter averaging."
- Functional subspace collapse: The reduction of the model’s functional output space due to merging that ties router control. "causing a ``functional subspace collapse''"
- Hierarchical agglomerative clustering: A bottom-up clustering method repeatedly merging the closest clusters. "using hierarchical agglomerative clustering."
- Mode connectivity: The existence of low-loss paths connecting different trained neural network solutions in parameter space. "mode connectivity exists between the loss landscapes of two or more trained neural networks"
- N-gram diversity: A measure of the variety of distinct n-grams in generated text. "N-Gram diversity"
- Non-local merging: Merging parameters from models that do not share a common training checkpoint. "Non-local merging in which the models do not share a common checkpoint"
- Perplexity: A standard metric for LLMs measuring average uncertainty over tokens. "perplexity can be misleading when used to evaluate compressed \glspl{LLM}"
- Policy variability: Variation in the router’s input-dependent mixing policy across inputs. "proportional to the router's policy variability ()"
- Principal Component Analysis (PCA): A dimensionality-reduction technique projecting data onto principal components. "Functional subspace (PCA) for early \gls{smoe layers in Qwen3-30B}."
- Router: The MoE component that selects and weights experts for each input. "a router which produces gate-values (i.e., gates) to dynamically modulate the output of the experts based on the input."
- Router logits: The pre-softmax scores produced by the router before computing gates. "We collect router logits and expert activation data to calibrate the compression algorithms"
- Saliency criterion: A scoring rule to determine which experts are important to keep during pruning. "a novel expert pruning saliency criterion"
- Singular Value Decomposition (SVD): A matrix factorization used to analyze and align weight matrices. "we decompose expert weights with \gls{svd}"
- Top-k routing: Selecting only the top k experts (by gate value) for each input. "Top- routing is achieved by zeroing all but the largest gates."
- Weight matching algorithm: A procedure that permutes and aligns neurons/experts to enable coherent parameter averaging. "weight matching algorithm~\citep{ainsworth2023git}"
Practical Applications
Immediate Applications
The following applications can be deployed now using the paper’s findings and the open-source REAP implementation and checkpoints. They emphasize practical workflows that reduce memory and serving costs while maintaining generative quality.
- Expert-pruned MoE model serving for generative workloads — sectors: software, cloud, finance, education, public sector
- Deploy 25–50% pruned MoE LLMs to cut memory footprint and serving costs while preserving quality on code generation, tool use, math reasoning, and creative writing (shown near-lossless at 50% for Qwen3-Coder-480B and Kimi-K2 on code/tool-calling).
- Workflow: collect a small domain-specific calibration set (e.g., coding prompts), run
REAPto score experts, prune the lowest-saliency ones, repackage and serve the model. - Assumptions/Dependencies: works for sparsely activated MoE LLMs with top-k gating; requires router logits and expert activation collection; calibration must be representative of the target domain.
- Cost-optimized multi-tenant LLM hosting — sectors: cloud platforms, SaaS providers
- Increase tenant density per GPU/TPU/HBM budget by pruning experts to reduce memory overhead; maintain latency/throughput via more uniform expert usage and fewer dropped tokens.
- Workflow: integrate
REAPinto pre-deployment compression; benchmark generative tasks instead of only MC/perplexity; roll out pruned checkpoints to production inference clusters. - Assumptions/Dependencies: improvements depend on expert usage imbalance in the original model; performance validated on generative tasks may differ from MC-only evaluations.
- Quantization-friendly compression for MoE — sectors: inference tooling, MLOps
- Apply
REAPto quantized MoE models without re-quantization (merging typically forces re-quantization due to block scaling); simplify pipelines for W4A16, FP8, or similar formats. - Workflow: run
REAPon quantized weights, prune experts, keep block scales intact, redeploy; test on representative generative benchmarks. - Assumptions/Dependencies: requires block-quantization-aware loaders; ensure pruning does not violate quantization constraints of weight storage formats.
- Apply
- Agentic coding assistants with lower serving costs — sectors: developer tools, enterprise IT
- Use pruned large MoE code models to power IDE assistants, CI code repair, doc generation, and SWE-bench-type agents with minimal degradation at 25–50% compression.
- Workflow: domain-calibrated
REAPpruning on code datasets (e.g., Evol-CodeAlpaca); validate on both non-agentic coding (Eval+, LiveCode) and agentic tasks (SWE-Bench Verified). - Assumptions/Dependencies: strong gains hinge on domain-specific calibration; agent frameworks should use the pruned model’s tool-calling behaviors consistently.
- On-prem and edge-friendly generative assistants — sectors: enterprise privacy, SMB, daily life
- Run high-quality pruned MoE assistants locally (code-writing, math tutoring, content drafting) on smaller GPUs/CPUs due to reduced memory footprint.
- Workflow: prune with
REAP, package for local runtimes (e.g., custom inference servers, MLC, llama.cpp variants that support MoE), evaluate with generative metrics and tool use tasks. - Assumptions/Dependencies: MoE support varies across runtimes; benefits depend on model architecture and calibration quality; ensure alignment and safety checks remain intact post-pruning.
- Academic reproducibility and model analysis at lower hardware budgets — sectors: academia, research labs
- Use pruned checkpoints and the open-source
REAPcode to fit state-of-the-art MoEs on fewer GPUs, enabling generative evaluations and router/expert behavior studies. - Workflow: run
REAPwith small calibration corpora; analyze expert activation norms, gate distributions, PCA of expert subspaces; publish generative evaluations alongside MC results. - Assumptions/Dependencies: requires instrumentation to collect router logits and activations; compression quality depends on coverage of calibration samples.
- Use pruned checkpoints and the open-source
- Serving optimization and scheduler tuning for MoE inference — sectors: HPC, cloud serving
- Reduce tail latency and token drops via pruning-driven balancing of expert usage; improve accelerator utilization under small batch sizes typical in interactive deployments.
- Workflow: profile expert usage imbalance; prune low-contributing experts with
REAP; retune batch sizes, routing thresholds, and kernel launch parameters for the compressed topology. - Assumptions/Dependencies: scheduler improvements depend on original imbalance; validation needed for different kernels and backends (GPU/TPU/AI accelerators).
- Procurement and evaluation updates for compressed LLMs — sectors: policy, public procurement, standards
- Update procurement criteria to include generative benchmarks (code, math, writing) for compressed MoE models; avoid relying solely on perplexity/MC.
- Workflow: require domain-specific calibration during vendor compression; request generative accuracies, tool-calling acceptance-rate metrics, and latency/energy reporting.
- Assumptions/Dependencies: policy impact depends on adoption; benchmarks must be standardized and reproducible; vendors should disclose compression methods and calibration data.
Long-Term Applications
These applications build on the paper’s theory (functional subspace collapse) and empirical findings, requiring further research, scaling, or productization.
- Adaptive, domain-aware expert pruning at serve time — sectors: cloud inference, edge computing
- Dynamically prune/restore experts based on live workload profiles (e.g., coding vs. writing shifts), keeping the router’s independent control intact and minimizing memory-on-demand.
- Tools/Products: “Elastic MoE” serving frameworks that hot-swap expert sets; telemetry-driven
REAP-like saliency updates. - Assumptions/Dependencies: requires fast, low-overhead activation/gate logging; robust state management for expert swaps; guardrails to prevent drift or degradation.
- Router and training designs that mitigate subspace collapse — sectors: model architecture R&D
- Develop routers/gating strategies with controllable policy variability to minimize irreducible merging error; explore hierarchical or multi-router designs that preserve independent modulation under compression.
- Tools/Products: next-gen MoE layers with collapse-resistant routing, auxiliary objectives to stabilize mixing; curriculum that limits overlapping expert selection late in layers.
- Assumptions/Dependencies: needs extensive pretraining experiments; trade-offs with accuracy, specialization, and load balancing.
- Unified compression stacks that combine pruning, quantization, low-rank, and KD — sectors: MLOps, model optimization
- Extend one-shot pruning with quantization-aware training, low-rank adapters, or knowledge distillation to push compression beyond 50% while retaining generative quality.
- Tools/Products: turnkey pipelines that auto-select compression recipes per task/domain; PEFT-friendly integration for post-compression tuning.
- Assumptions/Dependencies: additional training or distillation cycles; risk of compounding errors; careful evaluation on generative, tool-calling, and safety/alignment metrics.
- Hardware–software co-design for pruned MoEs — sectors: semiconductors, AI systems
- Design accelerators and memory hierarchies tuned for pruned MoE patterns (balanced expert usage, reduced parameter sets), improving throughput and energy efficiency.
- Tools/Products: router-aware schedulers, sparse expert load balancers, compiler passes optimized for compressed expert layouts.
- Assumptions/Dependencies: requires vendor support; integration with frameworks; validation across diverse MoE topologies.
- Standardized generative evaluation and reporting for compression — sectors: policy, benchmarking consortia
- Establish benchmarks and reporting norms that prioritize generative quality (code, math, writing), tool-calling metrics, and diversity measures (e.g., N-gram diversity, cross-perplexity, logit JSD), alongside MC/perplexity.
- Tools/Products: open benchmark suites and leaderboards for compressed MoEs; disclosures of calibration datasets and seeds.
- Assumptions/Dependencies: consensus across academia/industry; governance for dataset curation; continuous updates to reflect evolving tasks.
- Task-specific expert libraries and model zoos — sectors: model marketplaces, enterprise AI
- Curate pruned expert configurations (e.g., coding-heavy, math-heavy, creative-heavy) for popular MoEs, enabling plug-and-play deployment per domain.
- Tools/Products: “expert profiles” in model hubs; metadata about router policies and expert activation norms; compatibility tags for quantization and serving stacks.
- Assumptions/Dependencies: sustainment of community curation; legal/licensing clarity for redistributed pruned checkpoints; versioning and provenance tracking.
- Safer and more controllable pruned generative models — sectors: safety, compliance
- Investigate how pruning affects hallucination rates, bias, and alignment; develop safety-aware pruning criteria that consider policy variability and expert specialization.
- Tools/Products: compression-time safety assessments; alignment-preserving pruning objectives; red-teaming protocols for pruned MoEs.
- Assumptions/Dependencies: requires new measurement protocols; potential trade-offs between compression and safety signals; coordination with governance frameworks.
- Robotics and embodied agents with on-device language reasoning — sectors: robotics, industrial automation
- Leverage pruned MoE LLMs for task planning, tool use, and code generation for controllers on constrained compute; reduce reliance on large cloud endpoints.
- Tools/Products: robotics stacks integrating pruned LLMs for planning and code synthesis; safety wrappers for real-world execution.
- Assumptions/Dependencies: real-time constraints; robust tool-calling and deterministic outputs; extensive validation in physical environments.
Collections
Sign up for free to add this paper to one or more collections.