Behavior Knowledge Merge in Reinforced Agentic Models
Abstract: Reinforcement learning (RL) is central to post-training, particularly for agentic models that require specialized reasoning behaviors. In this setting, model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model. However, existing merging methods are designed for supervised fine-tuning (SFT), and they are suboptimal to preserve task-specific capabilities on RL-trained agentic models. The root is a task-vector mismatch between RL and SFT: on-policy RL induces task vectors that are highly sparse and heterogeneous, whereas SFT-style merging implicitly assumes dense and globally comparable task vectors. When standard global averaging is applied under this mismatch, RL's non-overlapping task vectors that encode critical task-specific behaviors are reduced and parameter updates are diluted. To address this issue, we propose Reinforced Agent Merging (RAM), a distribution-aware merging framework explicitly designed for RL-trained agentic models. RAM disentangles shared and task-specific unique parameter updates, averaging shared components while selectively preserving and rescaling unique ones to counteract parameter update dilution. Experiments across multiple agent domains and model architectures demonstrate that RAM not only surpasses merging baselines, but also unlocks synergistic potential among agents to achieve performance superior to that of specialized agents in their domains.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about a smart way to combine several specialized AI “agents” (models) into one stronger, all‑around model. These agents were trained using reinforcement learning (RL), which teaches a model by trial and error with rewards. The new method, called Reinforced Agent Merging (RAM), avoids common problems that happen when you try to merge RL‑trained models using older techniques, helping the combined model keep each agent’s special skills and even work better overall.
What are the main questions?
The researchers asked:
- Why do older model‑merging methods (made for supervised fine‑tuning, or SFT) hurt performance when used on RL‑trained agents?
- Can we design a merging method that keeps each agent’s unique abilities without weakening them?
- Will this new method make the merged model as good as, or better than, the original specialized agents across different tasks like coding, tool use, and long‑memory reasoning?
How did they do it?
First, here’s some simple background:
- Supervised fine‑tuning (SFT): The model learns from labeled examples (like answers in a dataset). Updates are often spread broadly across the model.
- Reinforcement learning (RL): The model learns by trying actions and getting rewards. Updates are often focused on small, specific parts of the model.
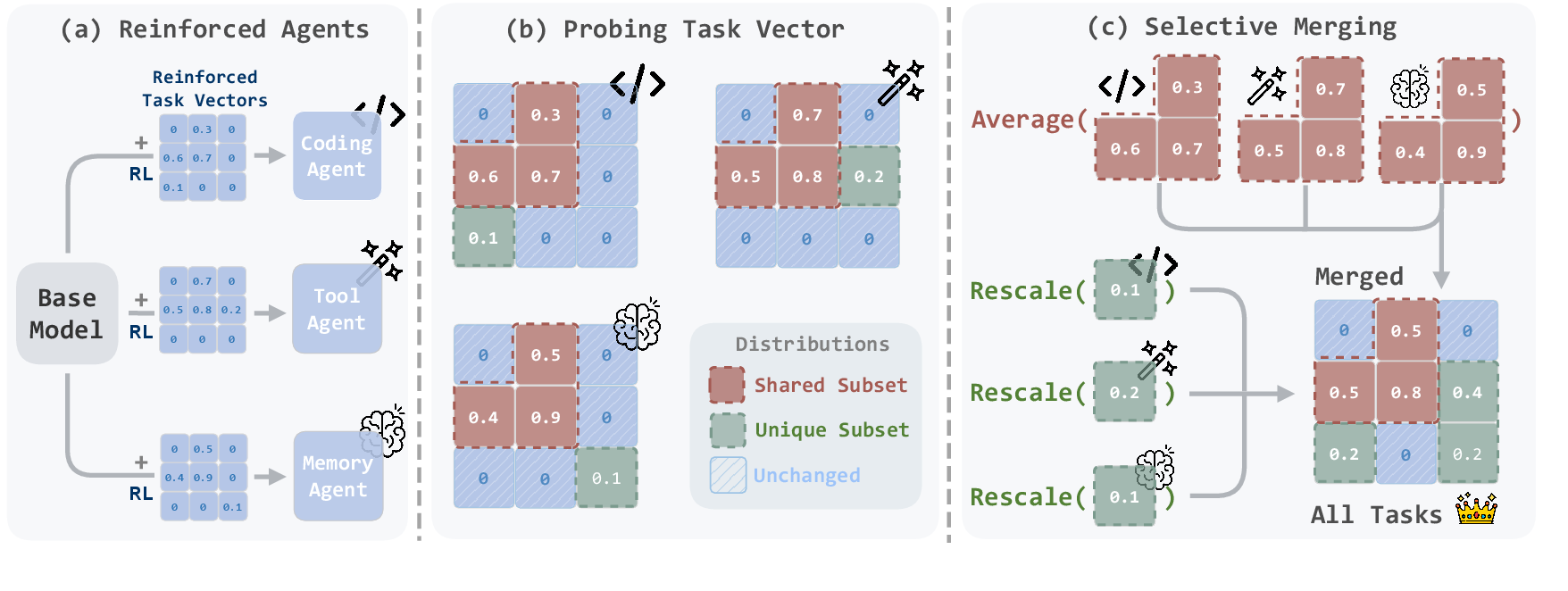
Think of an AI model as a huge “control board” with millions of knobs. Training changes some knobs. A “task vector” is just the list of knob changes from the base model to a specialized model.
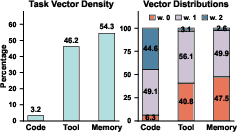
Key idea: In RL, different agents change different sets of knobs, and many of those changes don’t overlap. If you average their changes like older methods do, unique changes get divided and become too weak. The paper calls this “signal dilution.”
Here’s the RAM approach, explained in everyday steps:
- Find what changed: For each agent, the team looked at which knobs moved a meaningful amount (the “task vector”).
- Separate shared vs. unique:
- Shared: knobs that multiple agents changed.
- Unique: knobs changed by only one agent.
- Handle each part differently:
- Shared changes: average them (this helps balance common skills).
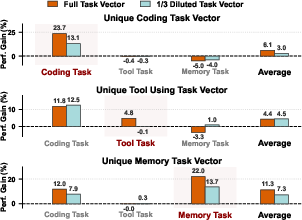
- Unique changes: keep them as‑is and lightly boost them (so they don’t get diluted by averaging).
- Smart boosting: They compute a simple ratio that says how much an agent’s changes are in shared vs. unique parts. If an agent’s changes are mostly shared (more likely to be weakened by averaging), RAM boosts its unique parts a bit more to compensate. The boosted version is called RAM+; without boosting, it’s just RAM.
Analogy: Imagine merging notes from three classmates—one great at coding, one great at using tools, and one great at remembering long stories. If you average every page line‑by‑line, rare but important tips from each person get watered down. RAM says: average the common tips, but keep each person’s unique tips strong (and sometimes highlight them), so the final notebook is both balanced and sharp.
What did they find?
The team tested RAM and RAM+ on three agent types (coding, tool use, and long‑context memory), each trained from the same base model. They compared RAM to popular merging methods.
Main results:
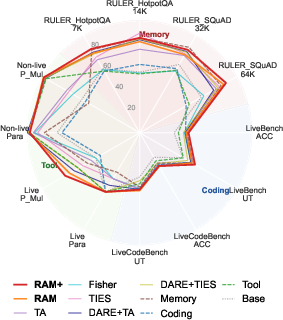
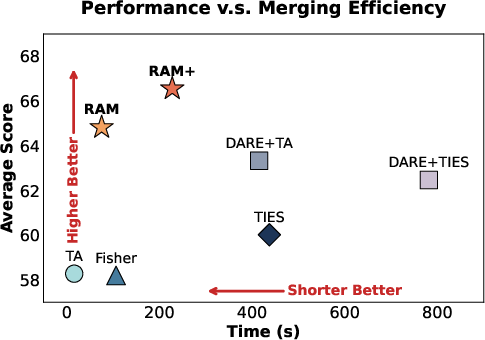
- RAM and RAM+ beat the older merging methods across most tests.
- RAM+ often matched or even surpassed the original specialized agents in their own domains, showing “synergy” (the merged model benefits from combining different skills).
- Coding: RAM+ outperformed the coding specialist on key coding benchmarks.
- Tool use: RAM+ was much better on complex tool‑calling tasks (especially with multiple tools).
- Long‑memory: RAM+ achieved top scores at very long context lengths (e.g., 64K tokens).
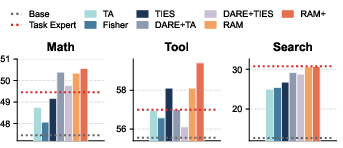
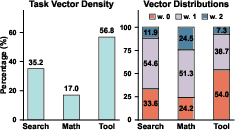
- The method also worked on a different family of models (Llama), and on other tasks like math and search, showing it generalizes well.
- A small boost factor (RAM+ with a modest setting) worked best. Too much boosting can start to hurt general performance.
Why this is important: It shows that respecting the “shape” of RL updates—keeping unique changes strong—makes merged models smarter and more reliable.
What is the impact?
If you want a single model that can do many things (code, use tools, remember long documents, do math, search, etc.), it’s expensive and complicated to train it for all tasks at once with RL. RAM offers a practical shortcut:
- Combine multiple RL‑trained agents into one generalist model without retraining.
- Keep each agent’s unique strengths instead of accidentally weakening them.
- Save computing time and storage, and support data privacy (you don’t need to mix original training data).
Limitations and future directions:
- Merging many more agents could create more “collisions” in shared areas, and may need extra conflict‑handling beyond simple averaging.
- The boosting step assumes all parameters matter similarly on average, which is a simplification.
- Some tasks or model sizes may need tuning to find the best boost level.
- Testing on much larger models (e.g., 70B+) is still needed.
Bottom line: RAM is a thoughtful, distribution‑aware way to merge RL‑trained agents. By protecting unique skills and carefully averaging shared ones, it builds stronger, more versatile models that can outperform the original specialists.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper leaves the following concrete gaps and unresolved questions that future work could address:
- Scalability to many agents: How does RAM behave when merging a large number of RL-trained agents (e.g., N ≥ 10)? Quantify performance, overlap statistics, and collision rates, and develop conflict-resolution strategies beyond simple averaging for highly overlapped parameters.
- Large model scale: Do RL-induced sparsity patterns and RAM’s efficacy persist for massive models (e.g., 70B+)? Evaluate numerical stability, memory footprint, and runtime at scale.
- Base-model heterogeneity: RAM assumes all agents share the same base checkpoint. Investigate merging agents trained from different base models, model sizes, or training recipes (including weight-permutation alignment or matching).
- RL algorithm diversity: Systematically study how different RL strategies (on-/off-policy, PPO/GRPO/DAPO/actor-critic variants, reward shaping) affect task-vector sparsity/overlap and RAM’s effectiveness.
- Unique-region rescaling assumption: The λ_t derivation relies on isotropic parameter importance. Test and compare alternative importance models (e.g., Fisher/Hessian curvature, per-layer sensitivity) and assess whether learning λ_t from validation or using magnitude-aware weighting improves stability and performance.
- Overlap-Unique Ratio definition: ρ_t is count-based and ignores update magnitudes. Evaluate magnitude-weighted overlap ratios and their impact on rescaling and final performance.
- Overlapping parameter conflicts: Averaging shared regions may cancel signals when updates have opposite signs. Compare RAM’s averaging vs. sign-consensus, trimming, or confidence-weighted strategies for conflicting overlaps.
- Thresholding for masks: The fixed ε = 1e−5 criterion may be brittle across layers, precisions, and scales. Study adaptive, per-layer, or scale-invariant thresholds and quantify sensitivity of masks and outcomes to ε.
- Layer-wise behavior: Identify which layers/blocks concentrate unique vs. shared RL updates and whether per-layer scaling or selective merging (e.g., attention vs. MLP) yields better trade-offs.
- Precision/quantization effects: Analyze RAM under bf16/fp16/fp32 and quantized weights; determine whether ε and mask definitions should change with precision to avoid false positives/negatives.
- Statistical robustness: Report variance across RL fine-tuning seeds and lengths, include confidence intervals/significance tests, and quantify sensitivity to RAM hyperparameters (r, α) beyond the limited ablation.
- Generalization to multimodal agents: Extend RAM to vision/audio/multimodal agents and tool-integrated modules (e.g., routers, planners); define how to merge non-text parameters and external modules consistently.
- Auxiliary heads and adapters: Many RL agents have value heads, reward-model couplings, or use adapters/LoRA. Evaluate RAM on merging these components (policy/value heads, adapters) instead of only full base weights.
- Sequential/online merging: Develop and test an incremental pipeline that adds new RL agents over time without reprocessing all prior task vectors, measuring backward compatibility and catastrophic forgetting.
- Task-conditioned or dynamic merging: Explore gating or mixture-of-experts that conditionally activate unique regions at inference time, and compare against static RAM merges.
- Safety and alignment: Assess whether RAM preserves or degrades safety behaviors (e.g., tool misuse, harmful content) and evaluate with safety benchmarks; design safety-aware merging/rescaling.
- Out-of-domain robustness: Measure negative transfer and distribution-shift robustness on domains not represented in the merged set; characterize when unique regions cause interference.
- Mechanistic attribution of synergy: Use influence functions or parameter-level attribution to explain why RAM produces cross-domain gains (e.g., coding improved by tool/memory signals), and locate contributing submodules.
- Hyperparameter selection: Automate selection of r and α (and ε) via meta-learning or validation-based optimization; explore per-task, per-layer, or per-parameter scaling schedules with stability guarantees.
- Efficiency at scale: Provide detailed time/memory complexity analyses; investigate block-sparse or streaming implementations to merge very large models efficiently.
- Benchmark breadth: Expand evaluations to more diverse and challenging tasks (e.g., program repair, planning, scientific QA, multi-hop reasoning with tools) and longer-context regimes beyond RULER.
- Alternative merging paradigms: Compare RAM to adapter/LoRA-level merges, low-rank task-vector decompositions, or learned combination coefficients trained on small validation sets.
- Mixed SFT/RL merges: Study merging between SFT- and RL-trained agents, characterizing when sparsity/density mismatches require different treatments and whether RAM needs adaptation.
- Tokenizer/vocabulary heterogeneity: Examine merging across agents with different tokenizers or vocabulary sizes, including required alignment procedures and their effect on downstream performance.
- Privacy considerations: Analyze whether task vectors or unique regions leak proprietary or sensitive data and propose privacy-preserving RAM variants (e.g., differential privacy or masking).
- Formal guarantees: Provide theoretical analysis of when RAM avoids signal dilution, bounds on performance regression in shared regions, and conditions under which the functional-equivalence hypothesis holds.
Glossary
- Agentic models: AI systems designed to act autonomously with specialized reasoning capabilities. "particularly for agentic models that require specialized reasoning behaviors."
- Berkeley Function Call Leaderboard (BFCL): A benchmark suite for evaluating tool-use/function-calling capabilities of LLMs. "we utilize the Berkeley Function Call Leaderboard (BFCL)~\cite{patil2025the}, specifically reporting results on the Live/Non-Live Parallel (Para) and Parallel Multiple (P_Mul) subsets."
- Binary mask: A 0/1 indicator vector marking which parameters are actively updated. "we compute a binary mask for task :"
- DARE: A merging method that drops and rescales parameters to mitigate interference during model merging. "and DARE~\citep{yu2024language}, which randomly drops and rescales the parameters."
- Distribution-aware rescaling mechanism: A procedure that scales unique parameter updates based on distribution statistics to preserve task performance. "Additionally, we introduce a distribution-aware rescaling mechanism to further amplify unique task capabilities."
- Fisher information: A measure of parameter importance used to weight updates during merging. "Fisher Merging~\citep{matena2022merging}, which weighs parameters based on Fisher information;"
- Fisher Merging: A model merging technique that averages parameters weighted by Fisher information. "Fisher Merging~\citep{matena2022merging}, which weighs parameters based on Fisher information;"
- Functional equivalence: The hypothesis that rescaling unique regions can preserve task performance after averaging shared regions. "We hypothesize that this rescaling operation achieves the functional equivalence to have the same performance gain for the task vector on task :"
- GRPO: A reinforcement learning algorithm used for post-training LLMs. "Several general-purpose algorithms, such as PPO~\citep{schulman2017proximal}, GRPO~\citep{guo2025deepseek}, and DAPO~\citep{yu2025dapo}, have been developed to support this direction."
- HotpotQA: A multi-hop question answering benchmark often used to test long-context reasoning. "including RULER~\cite{hsieh2024ruler} HotpotQA and SQuAD with 7K, 14K, 32K, and 64K lengths."
- Indicator function: A function that outputs 1 if a condition holds and 0 otherwise, used to construct masks. "where indexes the parameter dimensions and is the indicator function."
- Isotropic assumption: The assumption that parameter importance is uniform on average across dimensions. "Second, the derivation of our rescaling factor relies on an isotropic assumption of parameter importance, which, while empirically robust, does not explicitly account for element-wise curvature information that could offer finer-grained control at a higher computational cost."
- LiveBench: A benchmark measuring code generation performance (e.g., accuracy and unit tests). "on the LiveBench~\citep{white2025livebench} and LiveCodeBench~\citep{jain2024livecodebench} benchmarks."
- LiveCodeBench: A benchmark for evaluating code generation capabilities under live settings. "on the LiveBench~\citep{white2025livebench} and LiveCodeBench~\citep{jain2024livecodebench} benchmarks."
- Local sensitivity: A per-parameter coefficient mapping task vector changes to performance gains. "weighted by local sensitivity , which indicates the contribution coefficient mapping the task vector element to performance gain."
- Model collapse: Degradation where a model loses diversity/performance, sometimes mitigated by merging. "Beyond multi-task integration, merging has also been employed to mitigate model collapse~\cite{yuan2025superficial}"
- Model merging: Combining multiple task-specific models (or their parameter updates) into one unified model. "model merging offers a practical mechanism for integrating multiple RL-trained agents from different tasks into a single generalist model."
- On-policy RL: Reinforcement learning where data is collected using the current policy being optimized. "on-policy RL produces highly sparse and often disjoint task vector distributions, shaped by task-specific reward signals and RL objectives that target narrow behaviors."
- On-policy training: Training that requires data generated by the current policy within corresponding environments and rewards. "as it requires parallel task-specific environments and reward models to ensure on-policy training."
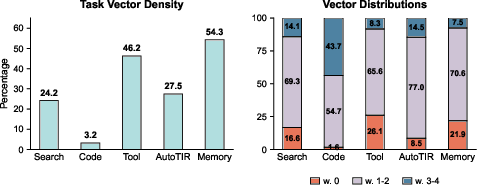
- Overlap count vector: A vector counting how many task models updated each parameter. "We then define the overlap count vector , where represents the number of agents that actively update the -th parameter."
- Overlap-Unique Ratio: The ratio of shared to unique updated parameters for a task’s vector. "we define the Overlap-Unique Ratio :"
- Parameter collision: Conflicts arising when many agents update the same parameters in the shared subspace. "as the number of agents scales significantly, the probability of parameter collision in the shared subspace increases,"
- PPO (Proximal Policy Optimization): A popular on-policy RL algorithm for training policies, including LLMs. "Several general-purpose algorithms, such as PPO~\citep{schulman2017proximal}, GRPO~\citep{guo2025deepseek}, and DAPO~\citep{yu2025dapo}, have been developed to support this direction."
- Qwen2.5-7B-Instruct: The base LLM from which the RL-trained agents are initialized. "All reinforced agents are initialized from the same base model, Qwen2.5-7B-Instruct~\citep{qwen2}."
- RAM (Reinforced Agent Merging): The proposed RL-aware merging method that separates shared vs. unique updates and rescales unique parts. "we propose Reinforced Agent Merging (RAM), a distribution-aware merging method explicitly designed for RL-trained agentic models."
- RAM+: The RAM variant that includes task-specific rescaling of unique regions. "We denote our method without task-specific rescaling as RAM and with rescaling as RAM+."
- Reinforced Task Vectors: Task vectors obtained via RL fine-tuning rather than supervised fine-tuning. "we specifically examine task vectors induced by RL fine-tuning, referring to them as Reinforced Task Vectors."
- Reward models: Models that provide scalar feedback signals guiding RL optimization. "as it requires parallel task-specific environments and reward models to ensure on-policy training."
- RULER: A benchmark for assessing long-context LLM performance. "we employ the RULER benchmark~\cite{hsieh2024ruler} to assess performance on long-context tasks"
- Signal Dilution: The reduction of task-specific update magnitudes due to averaging with zeros from other tasks. "We term this phenomenon Signal Dilution."
- Sparsity (task vector sparsity): The proportion of parameters not changed by fine-tuning relative to the base model. "We define the task vector sparsity of a model relative to the base model as"
- Supervised fine-tuning (SFT): Post-training using labeled data and standard gradients, contrasted with RL updates. "existing merging methods are designed for supervised fine-tuning (SFT)"
- Task Arithmetic: A linear combination method for merging task vectors across models. "Task Arithmetic~\citep{ilharcoediting}, which linearly combines task vectors;"
- Task vector: The parameter difference between a fine-tuned model and its base model for a given task. "Task vector is the set of parameter updates for a specific task."
- TIES-Merging: A merging method that reduces interference via trimming and sign consensus among updates. "TIES-Merging~\citep{yadav2023resolving}, which mitigates parameter interference through trimming and sign consensus;"
- UI-TARS2: An industrial GUI agent system that trains specialized RL agents and merges them into a generalist. "A representative example from large-scale industrial agents is UI-TARS2~\citep{wang2025ui}, which trains specialized vertical agents in isolated environments via RL, and subsequently merges them into a unified generalist agent."
- Weight interpolation: Direct parameter averaging between models, often suboptimal for RL-trained agents. "they rely on simple weight interpolation, which remains suboptimal for this regime."
Practical Applications
Below is a concise mapping from the paper’s findings to concrete, real-world applications. RAM (Reinforced Agent Merging) preserves and amplifies RL-trained agents’ task-specific “unique” parameter updates while averaging “shared” ones, avoiding the signal dilution that plagues SFT-era merging methods. This enables assembling stronger generalist agents from specialized RL models without joint retraining.
Immediate Applications
These can be deployed now with existing RL-trained agents and standard MLOps stacks.
- Enterprise generalist agent assembly from specialized RL agents
- Sectors: software, enterprise IT, SaaS platforms
- What: Merge coding, tool-use, and long-context/memory RL agents (e.g., CURE, ToolRL, MemAgent) into a single generalist that maintains or exceeds each specialist’s performance.
- Tools/products/workflows:
- A RAM “merger” CLI/library integrated into Hugging Face/PEFT pipelines
- CI pipelines that produce a merged checkpoint from team-specific RL fine-tunes
- Assumptions/dependencies: Same base model initialization and architecture; access to weights (not API-only); RL-style task vectors; minimal hyperparameter tuning for r, α.
- Storage and deployment efficiency for on-prem/edge scenarios
- Sectors: defense, finance, industrial IT, mobile/edge
- What: Replace multiple specialist checkpoints with one merged generalist to reduce storage, simplify deployment and access control.
- Tools/products/workflows: On-prem model hub that tracks base+merged models; LoRA/adapter export of merged deltas for smaller devices.
- Assumptions/dependencies: Homogeneous base across agents; device-level memory/computation constraints.
- Privacy-preserving capability fusion across teams/partners
- Sectors: healthcare (non-clinical support), finance (back-office), government IT
- What: Share and merge task vectors (weight deltas) instead of raw data to integrate capabilities while preserving data locality.
- Tools/products/workflows: Parameter-delta exchange agreements; internal security scans for unique regions; approval gates in MLOps.
- Assumptions/dependencies: Legal/licensing compatibility for weight sharing; common base model; safety audits to prevent leakage or unsafe behaviors.
- Dev productivity: IDE assistants and CI/CD copilots
- Sectors: software engineering, DevOps
- What: Merge RL-tuned code generation (CURE), tool orchestration (ToolRL), and long-context memory for project-wide reasoning.
- Tools/products/workflows: IDE extensions (VS Code/JetBrains) powered by the merged model; CI agents that write tests, call tools, and retain long-term project state.
- Assumptions/dependencies: Reliable unit-test/task evaluation in the RL fine-tunes; r tuned to avoid regressions on general coding.
- RPA and back-office automation with composite skills
- Sectors: finance, operations, customer service, e-commerce
- What: Combine tool-use (API orchestration), coding (workflow scripting), and memory (case history) into one agent for multi-step process automation.
- Tools/products/workflows: Workflow orchestration bots; back-office co-pilots; API schema-aware tool runners.
- Assumptions/dependencies: Stable tool schemas; validation on proprietary tasks; governance for action execution.
- Knowledge management, search, and support assistants
- Sectors: enterprise knowledge bases, customer support
- What: Merge memory-extended agents with search/tool-use agents for robust long-context question answering, triage, and tooling.
- Tools/products/workflows: Enterprise helpdesk copilots; merged agents embedded in portals and intranets; retrieval-augmented pipelines.
- Assumptions/dependencies: Guardrails for hallucination and safety; long-context evaluation aligned with domain content.
- Open-source “skill pack” merging and community collaboration
- Sectors: academia, OSS communities, startups
- What: Distribute RL-derived skill deltas and merge them into generalists without sharing datasets.
- Tools/products/workflows: A RAM-based skill-pack registry; overlap/unique-ratio dashboards; reproducible merge recipes and leaderboards.
- Assumptions/dependencies: License compatibility; shared base versions; provenance tracking.
- Research tooling: analyzing RL task-vector sparsity and synergy
- Sectors: academia, industrial research labs
- What: Use RAM’s masks and overlap-unique ratios to study RL update distributions, interference, and synergy across tasks/agents.
- Tools/products/workflows: Visualization of parameter overlap; automated ablations on unique/shared regions; grid-search for r, α.
- Assumptions/dependencies: Access to multiple RL-tuned weights; consistent tolerance thresholds for sparsity masks.
- Compliance workflows for capability integration without data sharing
- Sectors: regulated industries
- What: Adopt parameter-delta merging as a compliance-approved pathway to integrate capabilities across units or vendors.
- Tools/products/workflows: Internal policies defining “safe parameter sharing”; change-management logs on merged deltas.
- Assumptions/dependencies: Legal review of weight sharing; model security scans; clear IP boundaries.
- Advanced personal assistants for power users
- Sectors: consumer productivity, prosumer tools
- What: Merge specialized skills (planning, tool use, code, memory) into a single assistant for workflows like research, scripting, and data manipulation.
- Tools/products/workflows: Plugins for open-source assistants (e.g., Open WebUI); on-device merged models for privacy.
- Assumptions/dependencies: Sufficient local compute; safety guardrails; consistent base model.
Long-Term Applications
These require further research, scaling, or ecosystem development.
- Dynamic “skill store” and runtime merging
- Sectors: enterprise platforms, cloud marketplaces
- What: On-demand selection and merging of RL skill deltas at load time based on task context.
- Tools/products/workflows: Skill dependency resolvers; fast parameter composition; caching of merged variants.
- Assumptions/dependencies: Low-latency weight composition; policy for resolving collisions as agent counts grow.
- Cross-modal and robotics agent merging
- Sectors: robotics, manufacturing, logistics, AR/VR assistants
- What: Merge RL-trained language, vision, and control modules to create integrated task planners and supervisors.
- Tools/products/workflows: Vision-language-action base models with aligned parameter shapes; hierarchical control interfaces.
- Assumptions/dependencies: Common base architectures; rigorous safety validation; real-world sim-to-real evaluation.
- Massive-scale (70B+) model merging in production
- Sectors: hyperscalers, large enterprises
- What: Apply RAM to very large models, enabling multi-team specialization and unified deployment.
- Tools/products/workflows: Distributed merge operations; memory-efficient tensor handling; A/B evaluation frameworks.
- Assumptions/dependencies: Stability at scale; stronger conflict-resolution in high-overlap regimes; infra for safe rollouts.
- Automated rescaling policy learning and curvature-aware merging
- Sectors: AutoML, model tooling vendors
- What: Learn per-layer/per-parameter scaling (beyond isotropic assumption) using Fisher/Hessian or meta-learned policies.
- Tools/products/workflows: Curvature-aware RAM variants; bandit/BO to tune (r, α); layer-wise sensitivity estimation.
- Assumptions/dependencies: Extra compute; robust metrics to prevent over-amplification; generalized safety checks.
- Security and provenance: supply-chain defense for weight deltas
- Sectors: all (especially regulated/gov)
- What: Detect trojans/backdoors in unique regions; sign and attest deltas; lineage tracking for merges.
- Tools/products/workflows: Trojan scanning focused on unique masks; SBOM-like artifacts for model weights; signed merge manifests.
- Assumptions/dependencies: Shared standards; third-party auditors; red-team evaluations.
- Federated RL at scale with parameter-delta aggregation
- Sectors: healthcare (clinical research), finance (multi-branch), public sector
- What: Each site trains a local RL agent; central node merges via RAM to create a robust generalist without centralizing data.
- Tools/products/workflows: Federated coordination servers; delta exchange protocols; secure aggregation.
- Assumptions/dependencies: Homogeneous base; cross-site governance; careful clinical/financial validation and ethics review.
- Distillation and adapterization of merged models
- Sectors: edge/embedded, mobile, consumer devices
- What: Distill merged generalists into smaller models; convert unique regions into plug-in adapters for modular routing.
- Tools/products/workflows: Knowledge distillation pipelines; adapter routers that activate relevant unique subspaces.
- Assumptions/dependencies: Effective distillation recipes; latency budgets; adapter routing accuracy.
- Licensing and marketplaces for modular “skill” vectors
- Sectors: model vendors, marketplaces, OSS ecosystems
- What: Commercialize and exchange task-vector “skills” that can be merged into compatible bases.
- Tools/products/workflows: Licensing frameworks for deltas; compatibility badges; revenue-sharing mechanisms.
- Assumptions/dependencies: Clear IP regimes for deltas; standardized metadata (base/version/shape).
- Safety, fairness, and evaluation standards for merging
- Sectors: standards bodies, policy, enterprise risk
- What: Benchmarks and audits for signal dilution, interference, and safety drift post-merge; fairness across tasks and demographics.
- Tools/products/workflows: Overlap-unique ratio reports; post-merge harm/robustness tests; governance dashboards.
- Assumptions/dependencies: Community benchmarks and reporting norms; tooling for differential behavior analysis.
- Energy/industrial operations assistants
- Sectors: energy, utilities, manufacturing
- What: Merge long-memory, tool-use, and code-generation to supervise SCADA/OT integrations and reporting.
- Tools/products/workflows: Read-only advisory copilots, eventually gated actuation; audit trails and human-in-the-loop approvals.
- Assumptions/dependencies: Safety certification; robust fail-safes; domain-specific training and validation.
Cross-cutting assumptions and dependencies
- Same base model initialization, architecture, and parameter shapes across agents is required for direct merging.
- RAM is tailored to RL-induced sparse/heterogeneous task vectors; SFT-only task vectors may benefit less.
- Access to model weights is necessary (closed APIs won’t suffice).
- Hyperparameters (e.g., r, α, ε threshold) may need light tuning per domain; higher agent counts raise collision risks and may require more advanced conflict resolution.
- Legal/IP constraints and safety governance must be addressed when sharing or merging weight deltas.
Collections
Sign up for free to add this paper to one or more collections.