- The paper presents a novel framework that uses susceptibilities to invert neural networks' linear responses and design targeted data interventions.
- It leverages singular learning theory to connect local free energy, posterior concentration, and internal model complexity during training.
- Empirical experiments on language models and synthetic tasks validate the method’s ability to control circuit formation and algorithm selection.
Patterning: The Dual of Interpretability
Conceptual Foundations
The paper introduces patterning as the mathematical dual to mechanistic interpretability. While interpretability attempts to understand how neural networks generalize via the reverse engineering of internal structure post-training, patterning focuses on the pre-training problem: given a target form of generalization, what training data distribution will reliably induce it? The approach leverages susceptibilities, which quantify how posterior expectation values of specific observables (functions mapping model parameters to structural features) respond to infinitesimal changes in the data distribution. Through inversion of the linear response relationship encoded by the susceptibility matrix, one can construct targeted data interventions—either one-off or adaptively online—designed to steer the internal structure that forms during training.
This framework is formalized by the equation:
dμ∞=χdh
where dμ∞ represents the change in structural coordinates (expectation values of observables), dh the infinitesimal change in data distribution parameters (hyperparameters such as mixture weights), and χ the susceptibility matrix. The fundamental equation of patterning is the minimum-norm intervention:
dhopt=χ†dμtarget∞
where χ† denotes the Moore-Penrose pseudoinverse. Therefore, patterning establishes a principled link between desired generalization and the data distribution required to elicit it.
Singular Learning Theory and Susceptibility Analysis
Central to the methodology is singular learning theory (SLT) [watanabe2009algebraic], which provides the local learning coefficient (LLC, λ) as a measure of solution complexity, dictating posterior preference among multiple zero-loss (empirical risk minimization) solutions. SLT describes the asymptotic concentration of the posterior around parameter minima and relates the quantity of compressible directions (degeneracies) in parameter space to structural features. SLT also gives an asymptotic expansion for local free energy:
Fn(U)=nLn(w∗)+λ(w∗)logn+⋯
where Ln(w∗) is local empirical loss and λ(w∗) encodes effective dimension.
Susceptibilities are defined as derivatives of posterior expectation values with respect to the data distribution. In practice, for a model such as a transformer, per-token susceptibilities χxyC are estimated to capture the sensitivity of components (e.g., attention heads) to token-context pairs. Susceptibility matrices admit singular value decomposition (SVD), coupling principal data patterns (eigenvectors of the data space) to principal structural directions in observable space.

Figure 1: PC2 susceptibilities highlight recurrent patterns in the language modeling corpus, clustering rare biological terms and induction motifs in token sequences.
Patterning is first validated in a language modeling setting using a 3M parameter attention-only transformer. Following prior work, the second principal component (PC2) of the susceptibility matrix is shown to couple data induction patterns with the induction circuit forming in the model weights. By reweighting training tokens along v2 (the right singular vector from SVD), circuit formation can be reliably modulated:
- Down-weighting tokens with negative v2 values delays or prevents induction circuit formation.
- Up-weighting accelerates the emergence and strength of the induction circuit.
This prediction is borne out by both susceptibility measurements and extrinsic functional metrics (e.g., prefix matching scores, previous-token scores following [olsson2022context]).
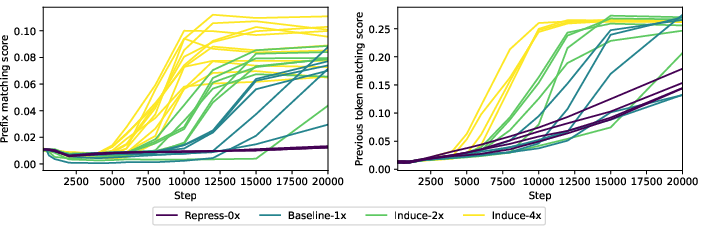
Figure 2: Prefix matching and previous-token scores trace the functional induction circuit formation in the LLM for different token reweighting schedules.
Algorithm Selection in Parenthesis Balancing Task
The second experiment applies patterning to a synthetic classification task involving balancing parentheses, where two algorithms—Nested and Equal-Count—are consistent with training but generalize differently out-of-distribution (OOD). SLT predicts that the posterior will prefer the algorithm with lower LLC. Susceptibility measurements local to each solution allow the construction of a susceptibility gap:
Δχx=χxEQ−χxN
where x indexes training samples.
Synthetic augmentation of training data:
- Enriching for "almost nested" samples (which are hard for the Nested algorithm) raises its LLC, favoring Equal-Count solutions.
- Enriching for "almost equal" samples (selected for high susceptibility gap) shifts complexity and empirical OOD accuracy in the predicted direction.
Training on distributions enriched in "almost nested" samples produced models overwhelmingly employing the Equal-Count strategy (mean OOD accuracy $0.004$), while enriching for "almost equal" samples increased the prevalence of Nested solutions (mean OOD accuracy $0.497$, shift from $0.310$ in the original).
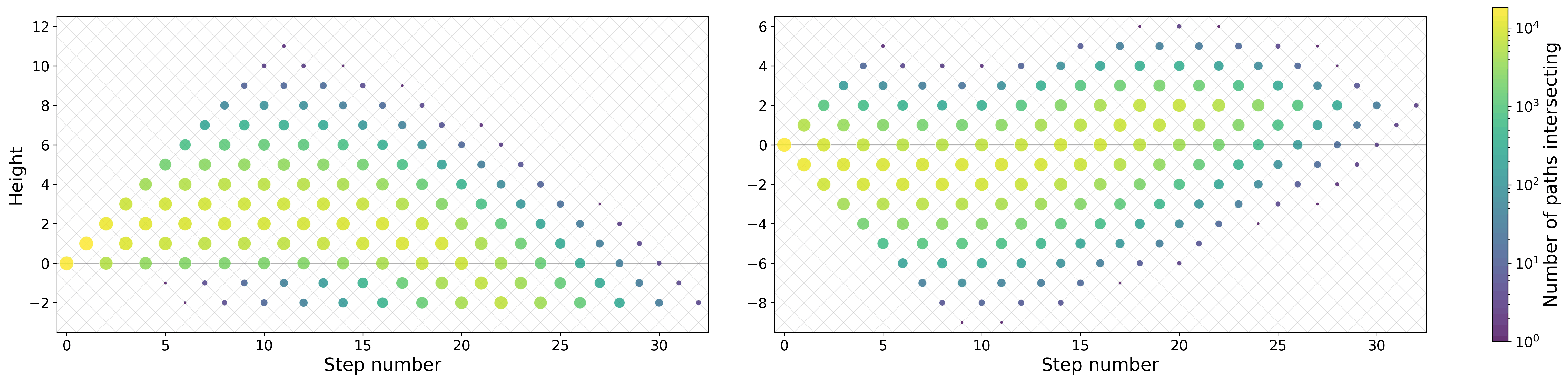
Figure 3: Heatmaps illustrate Dyck path crossing patterns in synthetically generated sequences, distinguishing "almost nested" and "almost equal" samples that drive selection between learning algorithms.
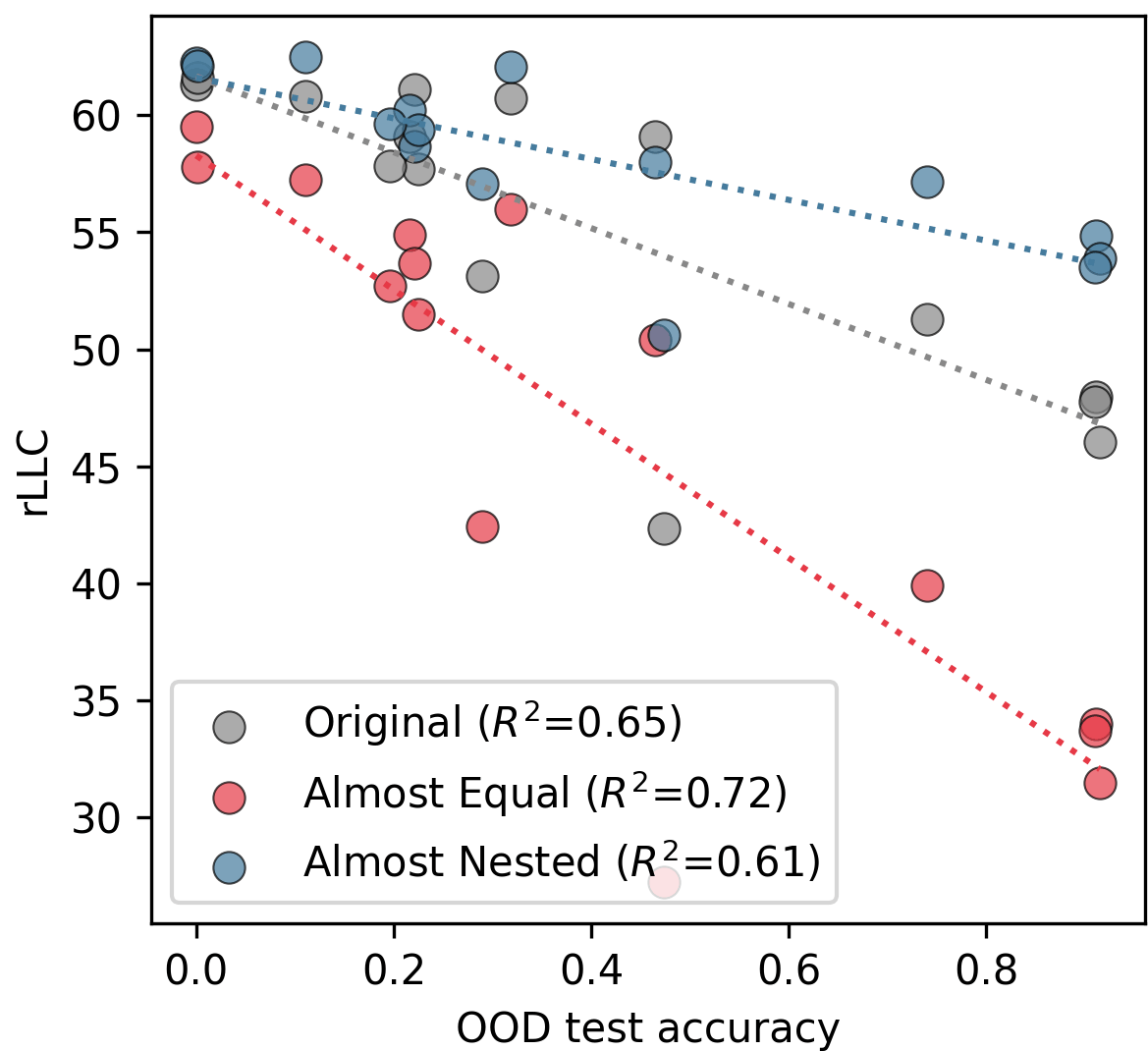
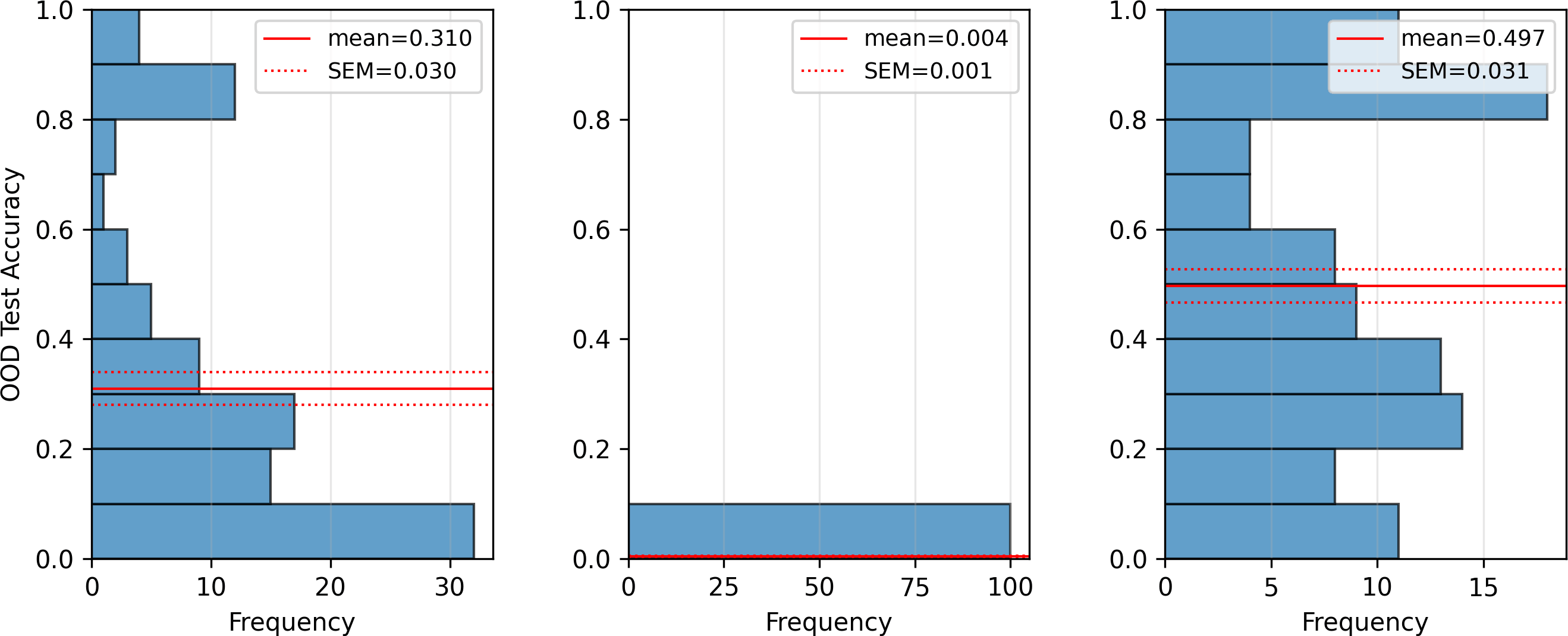
Figure 4: LLCs of trained models on original and modified data distributions, showing selective complexity elevation induced by sample reweighting.
Broader Implications and Alignment Applications
The susceptibility-guided patterning paradigm yields multiple implications:
- Internal selection: Posterior preferences are shaped by the complexity landscape; data interventions enable the steering of internal structure formation.
- Alignment: Patterning offers principled methods to avoid specification gaming and instrumental convergence by targeting the complexity of unwanted structures.
- Generalization Control: Empirical and theoretical analyses suggest that precise control over computational motifs, such as circuits or algorithm selection, is feasible via targeted data curation.
- Scaling Considerations: Computational cost is dominated by forward passes for susceptibility estimation, but methodology scales favorably with model size, and approaches such as online adaptive patterning or surrogate modeling may reduce cost further.
Relation to Existing Work
The approach mathematically formalizes and extends several paradigms:
- Mechanistic interpretability [olah2020zoom, elhage2021mathematical, wang2023interpretability]: The susceptibility-based analysis captures and generalizes circuit decomposition, directly linking model internals to data perturbations.
- Influence functions [cook1980characterizations, koh2017understanding, kreer2025bayesianinfluencefunctionshessianfree]: While both assess data impact, patterning focuses on internal complexity measures, not prediction error.
- Data curation: Existing works optimize downstream performance; patterning targets internal structure regardless of downstream metric.
- Developmental analogies: Morphogen gradients and bifurcation theory from biology metaphorically underpin the susceptibility-driven modulation of model development [waddington1957strategy, wang2025embryologylanguagemodel].
- Coherent control: Analogous to spectroscopy and femtochemistry, low-intensity susceptibility measurements are inverted to drive large-scale structural changes in neural networks [brumer1989coherence, shapiro2012quantum].
Conclusion
Patterning operationalizes the dual to interpretability, providing explicit equations and algorithms to induce desired generalization by training data design. Experimental evidence demonstrates that susceptibility-guided interventions produce predictable, measurable changes in the internal structure and functional behavior of neural networks. The methodology is grounded in singular learning theory and leverages mechanistic observables to achieve targeted structural control. Theoretical and empirical limitations remain, particularly regarding scaling, online adaptation, and robustness beyond linear response. Nevertheless, patterning advances the landscape of AI generalization control, with substantial implications for alignment and principled neural engineering.