- The paper proposes KG-R1, a unified RL framework that integrates retrieval and reasoning to reduce cost and improve transferability across diverse knowledge graphs.
- It employs a single LLM agent with a schema-agnostic KG server, achieving lower token usage and faster inference compared to multi-module systems.
- Ablation studies confirm that both turn-level and retrieval rewards are essential for stable training and high F1 scores.
Efficient and Transferable Agentic Knowledge Graph RAG via Reinforcement Learning
Introduction and Motivation
The paper introduces KG-R1, a single-agent, reinforcement learning (RL)-optimized framework for knowledge graph retrieval-augmented generation (KG-RAG). The motivation is to address two persistent challenges in KG-RAG: (1) the high computational cost and workflow complexity of multi-module LLM pipelines, and (2) the lack of transferability across heterogeneous or evolving knowledge graphs (KGs). Existing systems typically decompose KG-RAG into multiple LLM modules (retrieval, reasoning, reviewing, responding), each tailored to a specific KG schema, resulting in high inference cost and poor generalization. KG-R1 proposes a unified agentic approach, where a single LLM agent interacts with a schema-agnostic KG retrieval server, learning to alternate between reasoning and retrieval actions in a multi-turn setting, with end-to-end optimization via RL.
KG-R1 Framework: Architecture and Design
KG-R1 consists of two main components: a single LLM agent and a lightweight KG retrieval server. The KG server exposes a minimal, schema-agnostic set of 1-hop retrieval actions (get_head_relations, get_tail_relations, get_head_entities, get_tail_entities), which are provably sufficient for traversing any reasoning path in a directed KG and guarantee transferability across KGs with different schemas.
The agent operates in a multi-turn loop: at each turn, it generates a response containing both internal reasoning (> ...) and an action (<kg-query>...</kg-query> or <answer>...</answer>). The action is parsed and executed by the KG server, and the resulting observation is appended to the context for the next turn. The process continues until the agent emits a final answer.
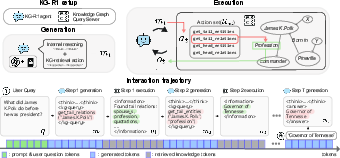
Figure 2: KG-R1 framework: a single LLM agent undergoes a multi-turn generation–execution loop with a schema-agnostic KG retrieval server and responds with the final answer.
This design eliminates the need for hand-crafted, KG-specific modules and enables plug-and-play deployment: the same agent policy can be used with any KG by simply swapping the backend server, without prompt or hyperparameter changes.
Reinforcement Learning Optimization
KG-R1 is trained end-to-end with RL, using a GRPO-style objective. The reward function combines per-turn (action-level) and global (trajectory-level) signals:
- Turn rewards: Format validity, schema-valid KG query, and answer formatting.
- Global rewards: Final-answer F1 score and a retrieval coverage indicator (whether any gold entity was retrieved).
Credit assignment is performed at the turn level using a group-relative baseline, which stabilizes learning in the multi-turn setting. The RL update uses importance sampling and KL regularization to the base policy. Ablation studies demonstrate that both turn-level and retrieval rewards are critical for stable and effective learning; replacing GRPO with PPO leads to reward hacking and training collapse.
Experimental Results
Training Stability and Reproducibility
KG-R1 training exhibits stable, monotonic improvement in F1 score, with low variance across random seeds, indicating robust optimization dynamics.
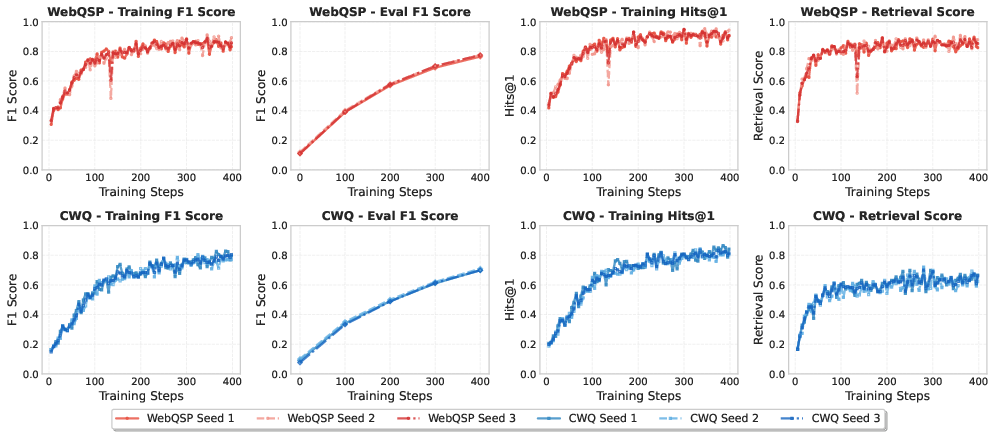
Figure 1: Training dynamics of Qwen 2.5b-it across 3 random seeds demonstrate reproducibility with steady F1 improvement and low variance. WebQSP (red) and CWQ (blue) metrics over 400 steps show stable convergence.
Inference Efficiency
KG-R1 achieves strong answer accuracy with significantly fewer generation tokens per query compared to prior multi-module KG-RAG systems, even when using a smaller (3B) LLM. For example, on WebQSP and CWQ, KG-R1 (N=1) uses 300–370 tokens per query (at H=5), compared to 520–650 for prompt-based baselines. This translates to lower latency and higher throughput, with single-query latency averaging 6.4s and batched throughput of 3.7 samples/s on a single H100 GPU.
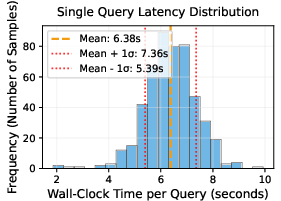
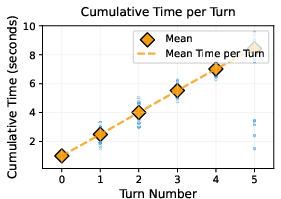
Figure 5: Histogram of end-to-end latency per question.
Plug-and-Play Cross-KG Transfer
A key result is the plug-and-play transferability: KG-R1 trained on one KGQA dataset (e.g., WebQSP or CWQ) can be directly evaluated on new KGs (e.g., Wikidata, MultiTQ) by swapping the KG server, with no retraining or prompt changes. KG-R1 outperforms LLM-only and prior LLM+KG baselines in zero-shot transfer, achieving F1/Hits@1 scores of 64.0/68.3 (WebQSP-trained) and 67.2/72.1 (CWQ-trained) averaged across five diverse KGQA datasets. Increasing the number of independent runs (N=3) further boosts performance, approaching or exceeding KG-specific baselines.
Ablation Studies
Ablations confirm that:
- Removing turn-level rewards or retrieval rewards causes large drops in F1 and retrieval rates, especially on datasets with complex reasoning.
- Hierarchical relation retrieval (to reduce token usage) can hurt performance, especially on multi-hop datasets.
- Larger models (7B) can improve peak performance but are more prone to training collapse under GRPO, consistent with recent findings on RL for LLMs.
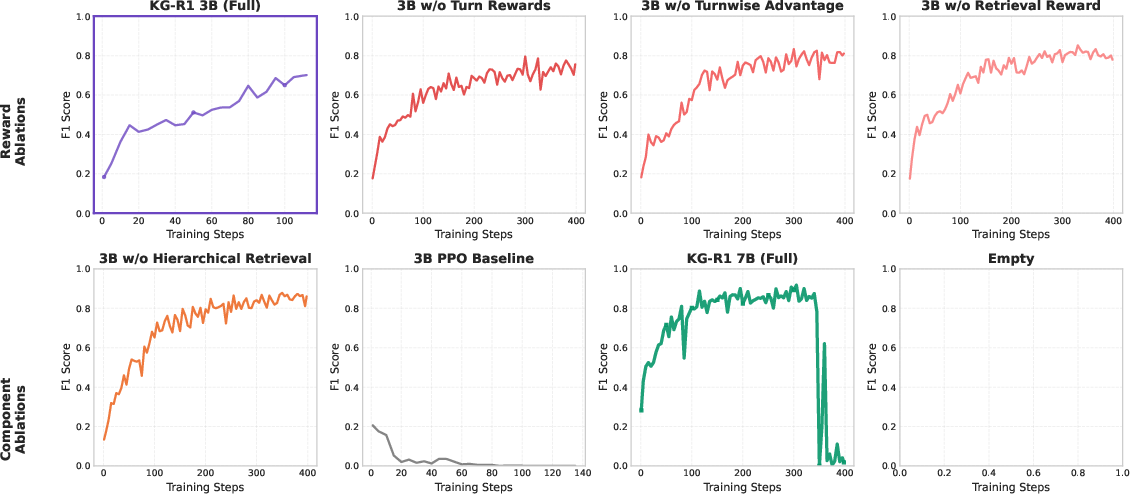
Figure 3: Training curves of ablation studies WebQSP, reporting F1 score across training steps.
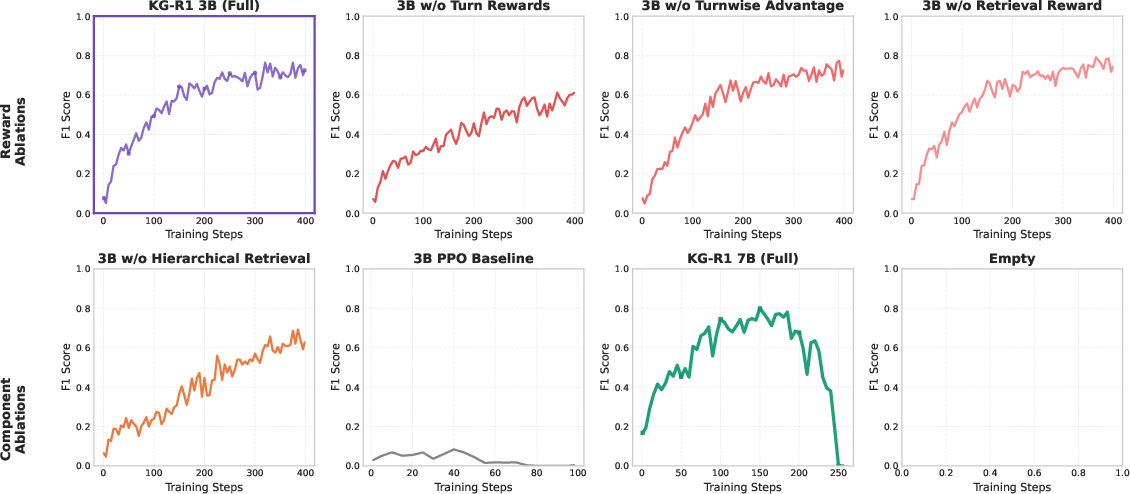
Figure 4: Training curves of ablation studies for CWQ, reporting F1 score across training steps.
Theoretical and Practical Implications
Theoretically, the minimal action set of the KG server is proven to be both complete (can realize any reasoning path) and schema-agnostic (enabling transfer across arbitrary directed KGs). This design decouples the agent policy from KG schema, a property not shared by SPARQL-generation or schema-specific pipelines.
Practically, KG-R1 demonstrates that a single-agent, RL-optimized KG-RAG system can achieve high accuracy, efficiency, and transferability, even with modest model sizes. The plug-and-play property is particularly valuable for real-world deployment, where KGs may evolve or differ across domains.
Limitations and Future Directions
- Model scaling: Larger models can improve performance but require careful RL stabilization to avoid collapse.
- Token efficiency: While flat relation retrieval is effective, further work is needed to balance token usage and information density, especially for large KGs.
- Temporal and multi-modal KGs: Extending the framework to richer KG types (e.g., temporal, multi-modal) and more complex reasoning tasks remains an open direction.
- Reward design: More sophisticated, possibly learned, reward functions could further improve credit assignment and generalization.
Conclusion
KG-R1 establishes a new paradigm for efficient, transferable KG-RAG by unifying reasoning and retrieval in a single RL-trained agent. The framework achieves strong empirical results in both in-domain and cross-KG settings, with substantial improvements in efficiency and deployment flexibility. The agentic, RL-optimized approach, together with a schema-agnostic KG interface, provides a robust foundation for future research and real-world applications in knowledge-grounded LLM systems.