- The paper introduces ROGRAG as an optimized enhancement of GraphRAG, employing dual-level and logic form retrieval to improve LLM reasoning.
- It details a robust indexing mechanism that extracts structured graph representations to effectively link corpus data with query characteristics.
- Empirical results demonstrate a significant boost in QA accuracy, improving performance from 60% to 74.5% on specialized datasets.
ROGRAG: A Robustly Optimized GraphRAG Framework
This essay provides an in-depth analysis of the paper titled "ROGRAG: A Robustly Optimized GraphRAG Framework," which explores advancements in the efficacy of Graph-based Retrieval-Augmented Generation (GraphRAG) systems specifically targeting LLMs.
Overview of the GraphRAG Framework
GraphRAG integrates structured knowledge, represented through graphs, to enhance retrieval accuracy and the reasoning capabilities of LLMs. The core objective of GraphRAG is to construct a system capable of performing complex reasoning tasks by recognizing relationships between entities and synthesizing information across multiple knowledge sources. The "ROGRAG" framework is posited as an optimized iteration of GraphRAG, incorporating several improvements over prior art.
Methodologies and Optimizations
Dual-Level Retrieval and Logic Form Retrieval
The ROGRAG framework innovatively leverages dual-level retrieval, which decomposes user queries into low-level keywords and higher-order relational descriptions, enhancing the system's ability to perform fuzzy matching (Figure 1). In parallel, logic form retrieval is utilized for structured reasoning, providing a more precise evaluative mechanism for handling complex queries.
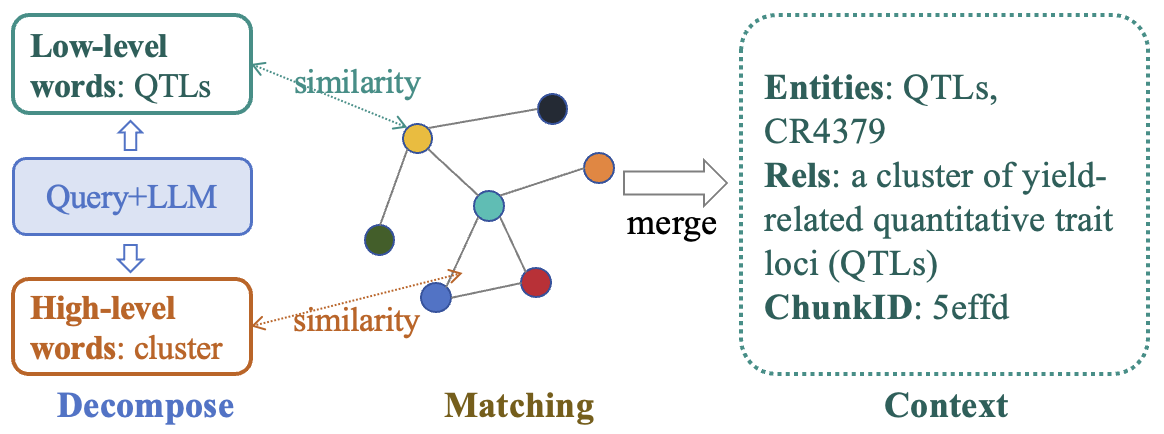
Figure 1: Dual-level retrieval method. User query would be decomposed into low-level and high-level keywords, then match with the knowledge graph.
Indexing and Retrieval Mechanism
The architecture fundamentally revolves around three functional elements: indexing (extracting structured graph representations from the corpus), retrieval (generating query representations and determining the best-fit retrieval path), and augmentation (constructing graph paths linking corpus and query representations). Algorithmic steps related to these functions demonstrate high precision in retrieval contexts, as highlighted in the text with a detailed methodology for refining these components (Figure 2).
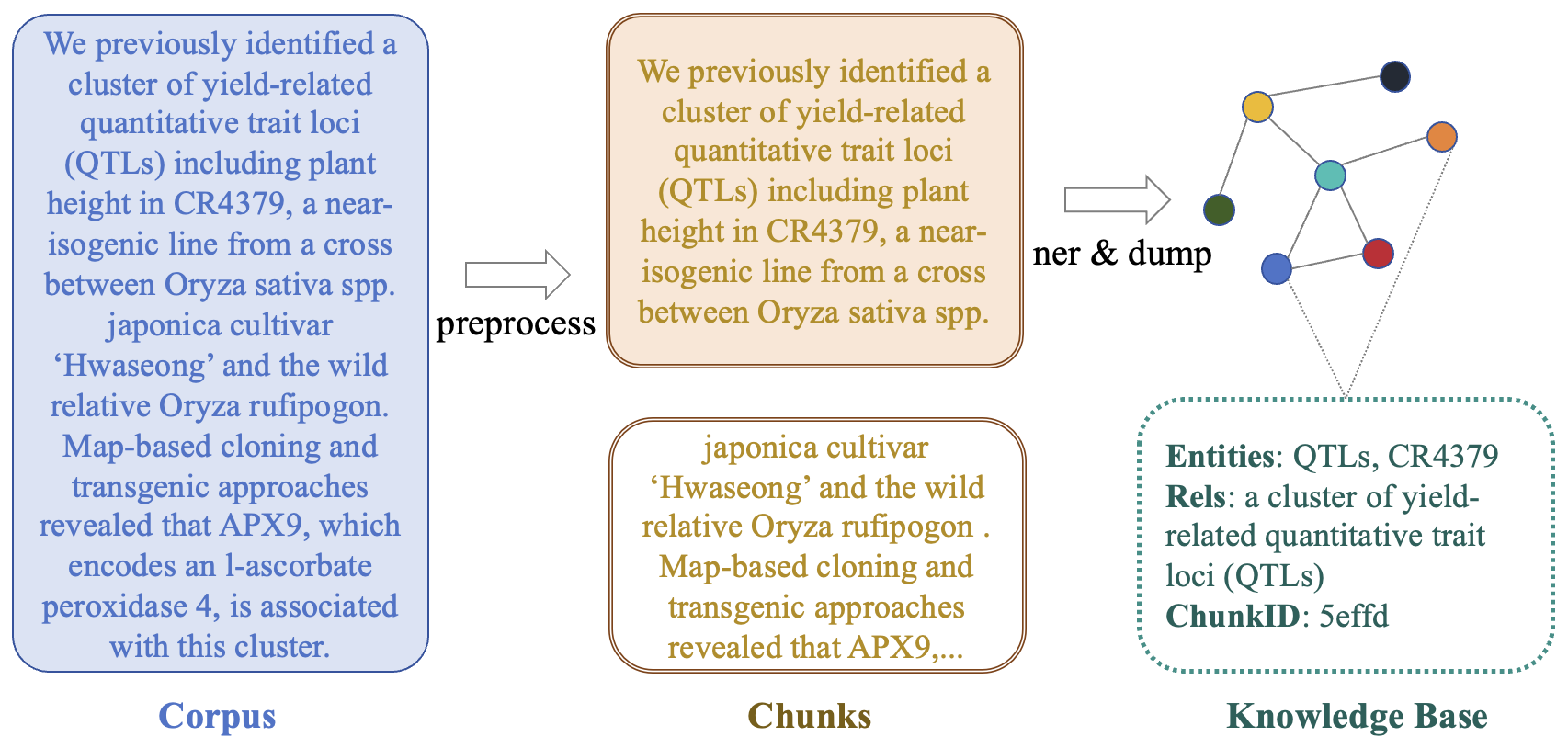
Figure 2: Architecture of GraphRAG indexing. The raw corpus is first cleaned and split into chunks, followed by the extraction of entities, keywords, relationships, and descriptions, and finally, the graph nodes and edges are linked to the chunks.
Empirical Evaluation and Results
The paper presents a rigorous empirical evaluation across various domain-specific datasets, revealing marked improvements in retrieval accuracy. With enhancements like a multi-stage verification mechanism, ROGRAG achieved a notable increase in performance metrics such as QA accuracy, validated by enhancements in baseline LLM models, with an accuracy improvement from 60 to 74.5 as depicted in Figure 3.
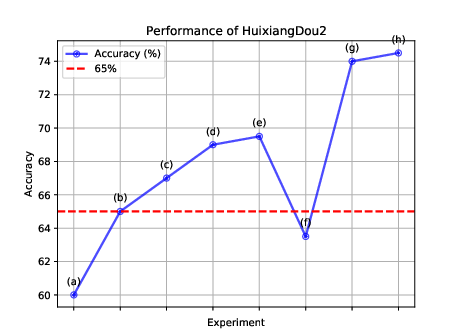
Figure 3: Performance improvements with each experiment – illustrating incremental enhancements in retrieval logic and context adjustment.
Real-world Applicability and Trade-offs
ROGRAG's advancements suggest substantial applicability in knowledge-intensive domains where the performance of traditional RAG systems remains limited. The adaptability to domain-specific datasets underscores its potential in specialized fields such as medical information retrieval. However, the complexity introduced by dual retrieval strategies and multi-stage verification requires precise tuning and domain knowledge, potentially limiting its scalability.
Conclusions and Future Directions
ROGRAG constitutes a forward step in the evolution of GraphRAG systems, optimizing retrieval strategies and enhancing LLM reasoning capacities. Future research will benefit from exploring hybrid approaches that combine dual-layer and logic-based retrieval mechanisms to consolidate strength in general accuracy and domain-specific applicability. The incorporation of robust verifiers and refined entity recognition techniques will be paramount to overcoming current limitations of node isolation and structural misalignment in knowledge graph integration.
Enhancements in these areas will likely cement ROGRAG's status as a versatile and effective framework for advanced knowledge retrieval in AI applications. Efforts must align towards optimizing computational demands while enhancing retrieval efficacy to broaden the framework's integration into diverse applications.