- The paper introduces a reinforcement learning-based framework that leverages LLM outputs as reward signals to dynamically rerank retrieved documents for improved question answering.
- It details a two-stage training pipeline combining behavior cloning and DPO-based RL optimization, resulting in state-of-the-art performance across multiple benchmarks.
- Experimental results show enhanced ranking recall, targeted context selection, and a significant reduction in inference overhead with fewer LLM calls.
DynamicRAG: Reinforcement Learning-Based Dynamic Reranking for Retrieval-Augmented Generation
Motivation and Framework Overview
DynamicRAG addresses a central challenge in Retrieval-Augmented Generation (RAG): optimizing the reranking of retrieved documents before passing them to a generative LLM. Prior works largely relied on static reranking strategies or LLMs making ranking decisions without feedback from downstream generation quality. DynamicRAG formulates reranking as an RL problem, explicitly leveraging LLM-generated outputs as reward signals to train the reranking policy, allowing for dynamic adjustment of both document order and count per query. This agent-based paradigm enables query-adaptive context selection, directly optimizing for generation quality rather than arbitrarily fixed context sizes or simplistic document scoring heuristics.
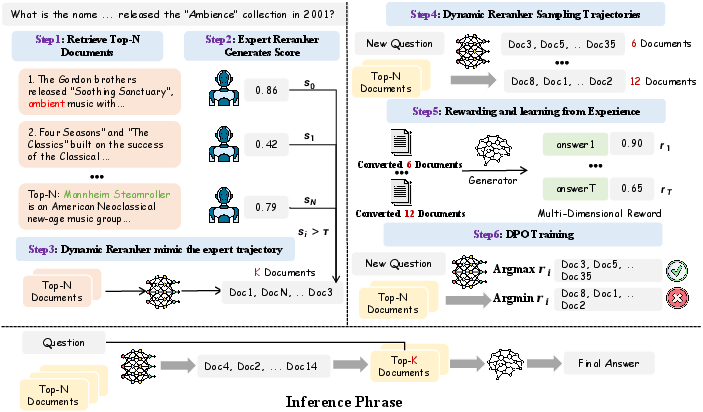
Figure 1: DynamicRAG training formulation, which iteratively incorporates behavior cloning, trajectory sampling, generator-based feedback, and DPO-based RL optimization.
Methodology
Reranker as RL Agent
DynamicRAG models the reranker as an interactive agent within a partially observable MDP, where actions correspond to selecting ordered document subsets from the retrieval pool. The generator functions as the environment, producing responses conditioned on the selected documents. Rewards are computed via a multi-dimensional function integrating Exact Match, Semantic Similarity (BERTScore), Textual Fluency (ROUGE), Length Penalty, and LLM-driven quality assessment. This formulation enables the reranker to learn query-sensitive document selection policies maximizing downstream accuracy and informativeness.
Training Pipeline
The training pipeline unfolds in two primary stages:
- Behavior Cloning: The reranker undergoes supervised fine-tuning using expert trajectories (e.g., MonoT5 outputs), furnishing a preliminary policy for list-wise response document selection.
- RL Optimization via DPO: The reranker explores trajectory space by sampling multiple document combinations per query, receiving generator-based reward feedback. DPO is used to optimize the reranker, encouraging preference for trajectories yielding superior responses.
RL-based training facilitates the learned policy’s capacity to adapt document selection not only by relevance, but also by explicit generation outcome, robustly accommodating diverse query complexities.
Experimental Results
Across seven benchmarks (e.g., NQ, HotpotQA, TriviaQA, ASQA), DynamicRAG consistently outperforms both retrieval-free LLMs (GPT-3.5, GPT-4, GPT-4o) and competitive retrieval-augmented baselines (RankRAG, ChatQA-1.5, Reward-RAG), achieving state-of-the-art EM, accuracy, and ROUGE-L scores for all backbone sizes (LLaMA2-7B, LLaMA2-13B, LLaMA3-8B). Notable gains are achieved despite DynamicRAG often utilizing fewer training instances compared to some agent baselines.
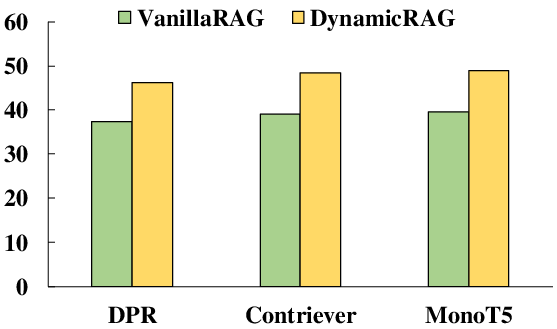
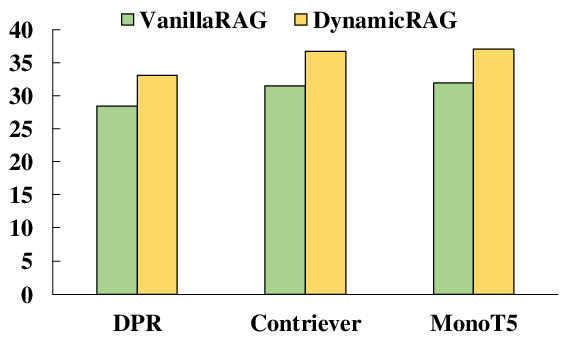
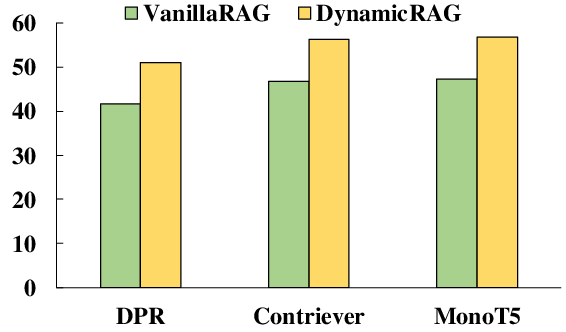
Figure 2: Comparative performance on Natural Questions, highlighting DynamicRAG’s improvements.
Reranker Effectiveness
DynamicRAG's reranker substantially improves ranking recall (R@5, R@10, R@20) over pointwise and listwise reranking baselines, even when trained on limited expert trajectory data. Empirical ablations reveal that list-wise RL optimization and generator-based feedback are critical for these gains, outperforming static IR models (BM25, Contriever) and fine-tuned rankers (monoT5, RankLLaMA).
Ablation Studies
Eliminating retrieval, reranking, or RL degrades downstream QA performance by substantial margins (up to 30 EM points). RL improves not only answer accuracy but also optimizes the number of documents provided to the generator, as length penalties and feedback induce more efficient, targeted context selection.
Scalability and Efficiency
DynamicRAG demonstrates efficient inference, requiring only two LLM calls per query for generation with Top-20 inputs, contrasted with exhaustive pairwise scoring approaches such as RankRAG that invoke the LLM up to 20 times for the same pool. Token-level profiling suggests a ~17x improvement in throughput without sacrificing answer quality. Sharing reranker and generator parameters further enhances downstream performance.
Analysis of Dynamic Document Selection
The RL-based training shifts the distribution of selected document counts (k) leftward, with post-training policies favoring fewer documents due to regularization and reward-based feedback, reducing context window usage and potential noise. The system’s performance as a function of Top-N document pool size evidences a clear optimum: expanding Top-N improves accuracy until extraneous noise degrades generation (peak at Top-100 to Top-150).
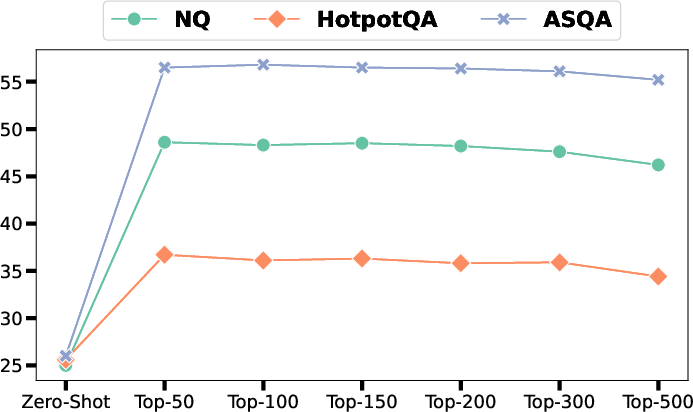
Figure 3: DynamicRAG’s performance as a function of document pool size across NQ, HotpotQA, and ASQA using Exact Match.
Implications and Theoretical Insights
DynamicRAG operationalizes RL for learning listwise context selection, shifting the reranking paradigm from static, heuristic-driven approaches to adaptive, outcome-driven policies. The capacity to dynamically adjust context size per query not only improves factual accuracy but also computational efficiency. Importantly, the model demonstrates generalization across open-sourced and closed-sourced LLMs, indicating the broad applicability of RL-based reranking even within proprietary QA pipelines, as evidenced by improved GPT-4o performance using DynamicRAG’s reranker module.
Practically, DynamicRAG’s efficiency enables deployment in contexts where inference cost is critical. Theoretically, the system augments RAG by closing the feedback loop between retrieval and generation, enabling end-to-end optimization. Future research directions include extending RL-based reranking to finer-grained observation-based reward modeling, joint retriever-reranker-generator RL training, and robust adaptation to domain-heterogeneous corpora.
Conclusion
DynamicRAG presents a robust RL-based framework for dynamic reranking in RAG, leveraging direct LLM feedback to optimize context selection and generation performance. Experimentally validated across multiple knowledge-intensive benchmarks, DynamicRAG sets new standards for both accuracy and efficiency, demonstrating the strategic advantage of RL in retrieval-augmented pipelines. The methodology’s practical and theoretical strengths anticipate further advances in context-adaptive document selection and end-to-end generative QA architectures (2505.07233).