DanQing: An Up-to-Date Large-Scale Chinese Vision-Language Pre-training Dataset
Abstract: Vision-Language Pre-training (VLP) models demonstrate strong performance across various downstream tasks by learning from large-scale image-text pairs through contrastive pretraining. The release of extensive English image-text datasets (e.g., COYO-700M and LAION-400M) has enabled widespread adoption of models such as CLIP and SigLIP in tasks including cross-modal retrieval and image captioning. However, the advancement of Chinese vision-language pretraining has substantially lagged behind, due to the scarcity of high-quality Chinese image-text data. To address this gap, we develop a comprehensive pipeline for constructing a high-quality Chinese cross-modal dataset. As a result, we propose DanQing, which contains 100 million image-text pairs collected from Common Crawl. Different from existing datasets, DanQing is curated through a more rigorous selection process, yielding superior data quality. Moreover, DanQing is primarily built from 2024-2025 web data, enabling models to better capture evolving semantic trends and thus offering greater practical utility. We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model. Experimental results show that DanQing consistently achieves superior performance across a range of Chinese downstream tasks, including zero-shot classification, cross-modal retrieval, and LMM-based evaluations. To facilitate further research in Chinese vision-language pre-training, we will open-source the DanQing dataset under the Creative Common CC-BY 4.0 license.
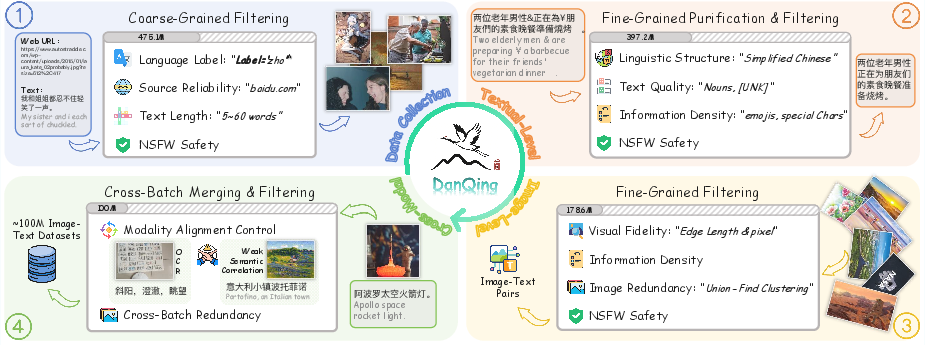
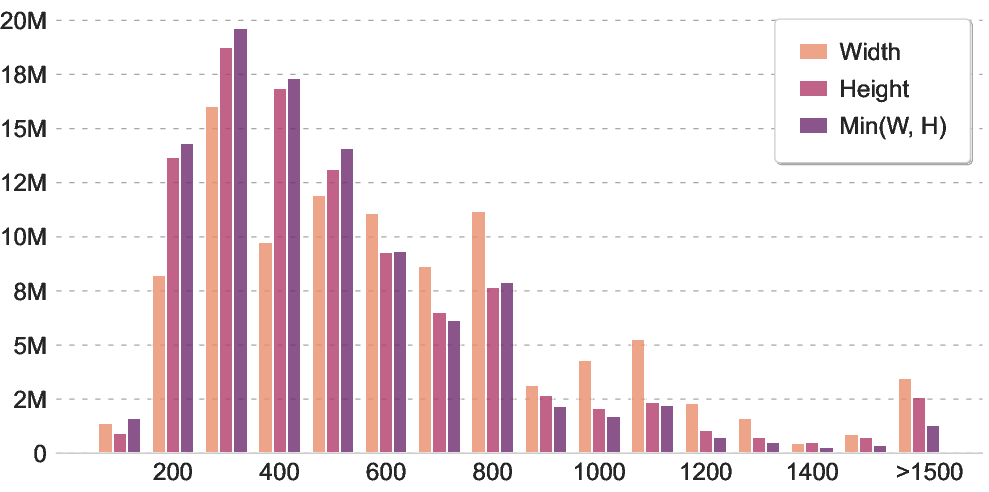



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces DanQing, a very large and up-to-date Chinese dataset of pictures and their matching texts (100 million pairs). It’s designed to help AI models learn to “see” images and “read” Chinese at the same time, so they can do things like describe photos, recognize objects, and find images based on a sentence. Think of it as a giant, clean, organized library of photo–caption pairs in Chinese, mostly collected from recent web pages (2024–2025).
What questions did the researchers ask?
The team focused on a few simple questions:
- Can we build a high-quality, modern Chinese image–text dataset that keeps up with current events and trends?
- If we train popular vision-LLMs on this dataset, will they perform better on Chinese tasks than models trained on older datasets?
- Will this new dataset help in different jobs, like classifying images without extra training (zero-shot), finding images from text and vice versa (cross-modal retrieval), and powering advanced multimodal chatbots?
How did they build the dataset?
They started with a huge pile of web data (about 1.05 billion image–text pairs) and carefully filtered it down to the best 100 million. You can imagine it like cleaning a messy photo album: throw out blurry photos, remove spammy or unsafe captions, and keep diverse, clearly matched pairs.
Here’s the process, explained with everyday ideas:
- First pass: quick cleanup
- Safety: remove unsafe content using simple automated checks.
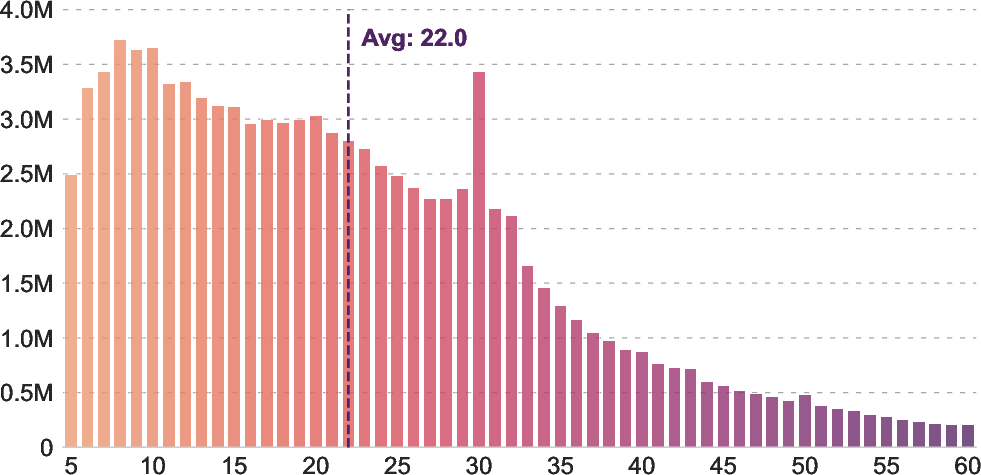
- Reasonable text: keep captions that aren’t too short or too long (roughly 5–60 words).
- Reliable sources: exclude low-quality websites.
- Text cleanup (because text is cheaper to check than images):
- Keep only Chinese and standardize it (convert to Simplified Chinese).
- Remove captions with broken words or too many unknown tokens (like lots of gibberish).
- Filter out empty or meaningless text using a “information density” score (imagine tossing captions that feel like filler words).
- Extra safety checks to remove ads or sensitive topics.
- Image cleanup:
- Basic quality: throw out images that are too tiny, oddly stretched, super blurry, or just solid color.
- Content richness: keep images with enough visual detail (not blank, not overly simple).
- Duplicates: use image embeddings (a way of turning pictures into numbers) to find near-duplicate images and keep just one.
- Safety: remove risky images with a stronger safety model.
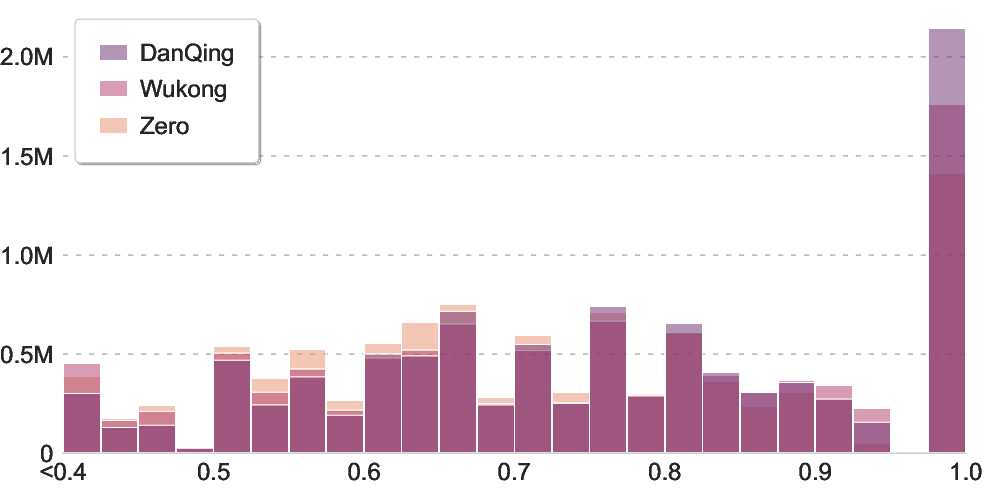
- Image–text matching:
- Use a strong expert model to score how well each image matches its text.
- Keep pairs that are well aligned (not random photos with unrelated captions, and not images that are just scanned text).
In simple terms: they passed the data through several sieves—from big holes to tiny ones—until only high-quality, diverse, well-matched Chinese image–text pairs remained.
What did they find?
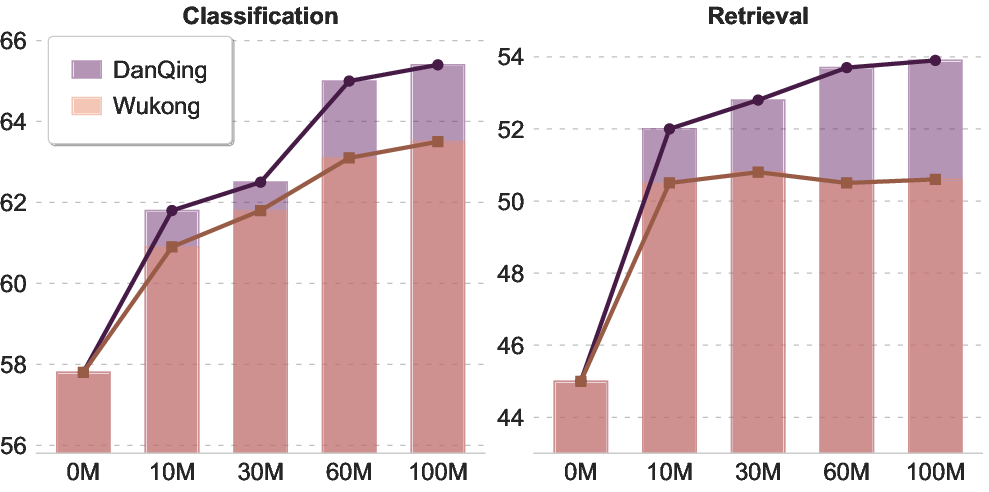
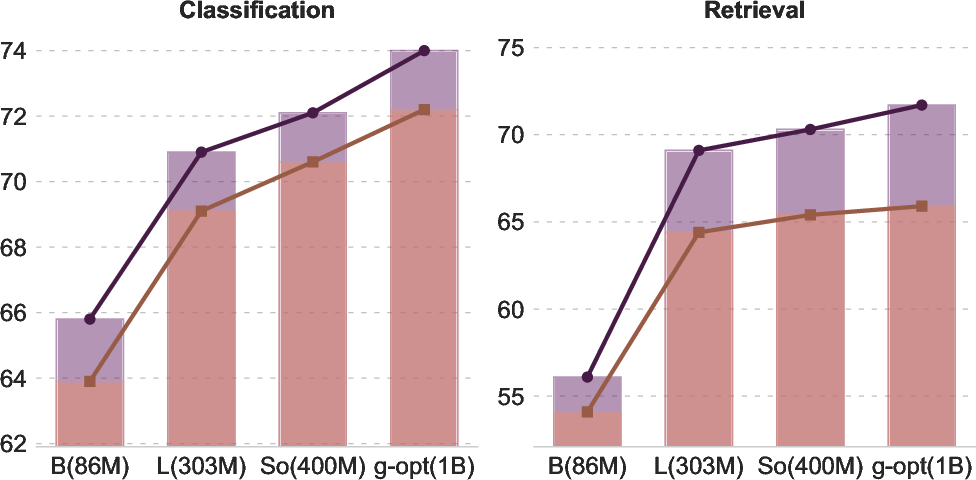
They trained a well-known model family (SigLIP2, similar to CLIP) on DanQing and compared it to models trained on other Chinese datasets (Wukong, TaiSu, Zero). They tested the models on several tasks:
- Zero-shot image classification (recognizing what’s in an image without extra fine-tuning):
- Models trained on DanQing performed the best on average. This means the data taught the model broad, general skills.
- Cross-modal retrieval (finding images from sentences and sentences from images):
- On popular benchmarks like Flickr30K-CN, MSCOCO-CN, and MUGE (short captions), DanQing-trained models were top or very close to top across model sizes.
- On long-caption datasets (DCI-CN and DOCCI-CN), DanQing clearly won by a large margin. This suggests DanQing’s texts are richer and more informative.
- Large multimodal models (LMMs) like chatbot-style systems that can see and read:
- When they used DanQing-trained vision encoders inside a standard training recipe (like LLaVA-NeXT with Qwen2-7B), the overall scores on Chinese-focused benchmarks were the best among the compared datasets.
- Scaling (does more data or a bigger model keep helping?):
- With DanQing, performance kept improving as they added more data and used larger models. Some other datasets hit a plateau sooner. This means DanQing scales well and doesn’t run out of useful learning signal quickly.
Why this matters:
- Better zero-shot results mean the model can handle new tasks without extra training.
- Strong retrieval means the model understands the connection between pictures and Chinese text well.
- Long-caption strength means the dataset teaches models to grasp deeper, more detailed descriptions—useful for real-world understanding.
- Good scaling means researchers can keep improving results with more training.
Why does this research matter?
- Up-to-date knowledge: Because DanQing is built from 2024–2025 web data, models can learn newer trends, objects, and language styles in Chinese.
- Stronger Chinese AI: Most giant image–text datasets are English-heavy. DanQing helps close the gap for Chinese, improving search, captioning, and visual reasoning.
- Better building block for multimodal systems: Since DanQing-trained encoders boosted LMMs, it can help future chatbots and assistants that “see and talk” in Chinese.
- Open and shareable: DanQing will be released under the CC-BY 4.0 license, so researchers and developers can use it, compare fairly, and build on it.
- Practical benefits: Higher-quality, safer, more diverse data means more reliable AI systems—for example, better tools for image search, education, accessibility (describing images to visually impaired users), and content moderation.
In short, DanQing is like a modern, carefully curated Chinese photo–caption encyclopedia. It helps AI models understand pictures and Chinese text together more accurately, scales well as models grow, and pushes the whole field of Chinese vision-language AI forward.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what the paper leaves missing, uncertain, or unexplored, framed to be directly actionable for future researchers:
- Reproducibility of the curation pipeline is underspecified: no public code, seeds, or exact parameterization (e.g., tokenizer versions, OpenCC configuration, FastText model variant, data processing order, batch partitioning strategy).
- Inconsistent “Success Rate” reporting: Table shows 100% for DanQing, while the text reports a 67% image download success rate; a clear definition of “Success Rate” and reconciliation across stages is needed.
- Filtering-stage arithmetic is inconsistent: image-level filtering reduces 397M to 178M, cross-modal filtering prunes 25M, yet the final dataset is ~100M; undocumented pruning steps or thresholds are missing.
- Threshold choices lack justification and ablations: text length (5–60 words), entropy cut-offs (text H < 6e-4; image H < 3), pixel std-dev < 2, Laplacian variance β ≥ 1000, CLIP similarity band [1.06, 1.24], union-find distance β = 0.1—no sensitivity analysis or error-rate calibration is provided.
- Safety filtering reliability is unquantified: false-positive/negative rates of the 1M-parameter and 20M-parameter NSFW detectors, and Baidu DataBuilder rules (advertisements, political content, territorial disputes) are not audited with human labels.
- Potential censorship-induced bias: removal of “sensitive political content and territorial disputes” can distort coverage of important real-world domains (news, civic events), yet there is no bias analysis or downstream impact quantification.
- Language identification and normalization gaps: reliance on Common Crawl “zho” tags plus FastText and conversion to Simplified Chinese may exclude Traditional Chinese and dialects; no measurement of code-mixing (Chinese–English) rates or dialect coverage.
- Unclear tokenizer behavior for Chinese: the paper references “[UNK]” thresholds after SigLIP tokenization, but SigLIP’s tokenizer details and multilingual handling for Chinese are not documented; no comparison across tokenizers (e.g., SentencePiece vs WordPiece).
- Semantic density metric validity: using jieba to identify nouns/verbs/adjectives may be error-prone for alt-text and colloquial Chinese; there is no validation against human annotations or alternative POS taggers.
- Perplexity computation with BERT is ill-defined: BERT is a masked LLM; the paper does not specify the method to estimate sentence-level PPL (e.g., pseudo-perplexity), making results difficult to interpret or reproduce.
- OCR-heavy image handling is ad hoc: the upper CLIP similarity threshold (1.24) to filter text-dominated images lacks empirical calibration; no evaluation of harm to OCR-related tasks or document understanding.
- Deduplication scope is limited: union-find clustering reduces redundancy within DanQing, but there is no deduplication against downstream benchmarks (Flickr30K-CN, MSCOCO-CN, MUGE, DCI-CN, DOCCI-CN) to prevent evaluation contamination.
- Test-set contamination risk is unaddressed: the web crawl timeframe overlaps with public datasets and benchmarks; no hash- or URL-level checks are reported to ensure zero leakage.
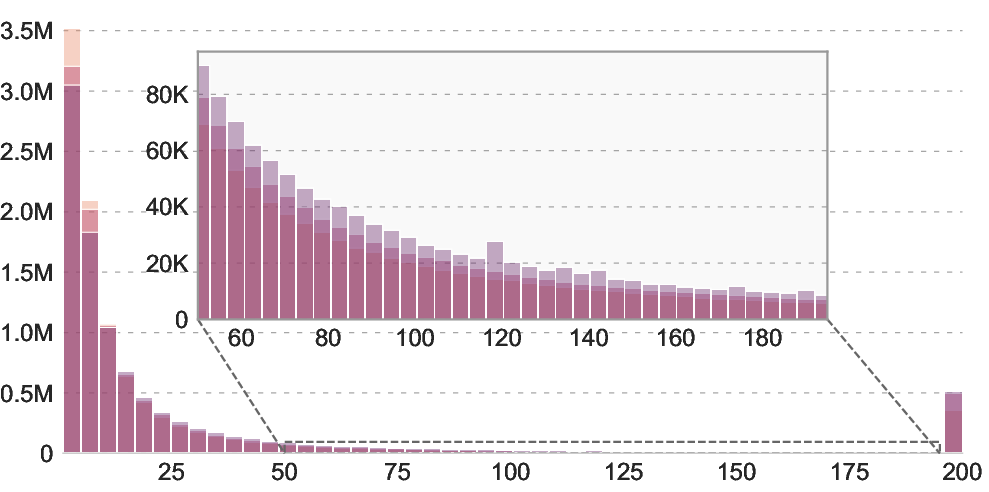
- Topic coverage and societal biases remain unexplored: the topic modeling is limited to six categories on a 10M subset; no comprehensive audit of domain diversity (e.g., geography, occupations, age, gender), sensitive attributes, or long-tail concepts.
- Legal and licensing uncertainties: hosting or redistributing 100M images under CC-BY 4.0 from Common Crawl requires careful per-item license assessment; the paper does not detail license extraction, attribution, takedown procedures, or PII handling.
- PII and faces: the dataset likely contains identifiable people and personal data; there is no PII detection, consent mechanism, or privacy risk assessment.
- Recency benefit is claimed but not measured: assertions that 2024–2025 data capture “evolving semantic trends” are not supported by time-aware evaluations or “new concept” coverage metrics; figures referenced (e.g., “new concept understanding”) are missing.
- Continual pretraining confounds attribution: models are not trained from scratch on DanQing; improvements could stem from prior SigLIP2 training—ablation studies isolating DanQing’s incremental contribution are absent.
- Fairness of comparisons: Zero and TaiSu are randomly downsampled to 100M; no experiments on their full scales (250M, 166M) or matched quality-controlled subsets to isolate scale vs. quality effects.
- Prompting details for zero-shot classification are missing: language (Chinese vs English), template choices, and label translations are not specified, making reproducibility and interpretation difficult.
- Cross-lingual generalization is untested: the dataset’s impact on English tasks or Chinese–English retrieval/captioning is not evaluated; multilingual transfer remains an open question.
- Resolution and context-length constraints: all training uses 256×256 images and text truncated/padded to 64 tokens; no study of higher-resolution pretraining or longer-text pretraining effects on long-caption retrieval and OCR tasks.
- Model diversity: results are limited to SigLIP2 architectures; no tests on CLIP softmax variants, BLIP/BLIP-2, EVA-CLIP, or other Chinese-centric encoders to assess dataset generality.
- Pipeline scalability and cost: compute, storage, and throughput of the parallel batch processing are described qualitatively; no quantitative profiling, resource footprint, or cost-performance analysis is given.
- Impact of each filtering stage is opaque: no per-stage precision/recall curves, human QA samples, or utility analyses (e.g., how removing blur or low-entropy images affects specific downstream tasks).
- Union-find cluster threshold selection is not validated: the choice of β = 0.1 in Chinese-CLIP-L14 embedding space lacks empirical support; no study of inter-cluster semantic diversity trade-offs.
- Safety vs utility trade-offs: aggressive safety filters may remove educational, medical, or artistic content; there is no quantification of lost utility or strategies for controlled, opt-in research subsets.
- Maintenance and update plan is unspecified: “up-to-date” positioning hinges on recency; there is no roadmap for periodic recrawls, versioning, or deprecation/takedown handling.
- Data cards and documentation are missing: no comprehensive datasheet (provenance, known limitations, intended uses, out-of-scope uses) is provided, limiting safe and informed reuse.
- LMM evaluation breadth is narrow: metrics focus on MMBench, MME-RW, CMMMU, OCRBench; no generative Chinese captioning, VQA breakdowns, hallucination analysis, safety evals, or reasoning stress tests.
- Generalization under distribution shift is untested: robustness to out-of-domain images (e.g., scientific diagrams, medical scans, satellite imagery) and adversarial/noisy alt-texts is not evaluated.
- Ethical review is absent: there is no mention of IRB-style ethical review, annotator well-being (if any manual steps), or community impact assessments for large-scale data redistribution.
Glossary
- AdamW: An optimizer that decouples weight decay from the gradient-based update to improve generalization in deep learning. "We employ AdamW~\cite{adamw} as the optimizer, initializing it with a learning rate of 1e-5 and a weight decay of 0.1."
- aspect ratio: The proportional relationship between an image’s width and height. "We first remove irregular images by retaining only those with an aspect ratio between 1:3 and 3:1"
- Baidu DataBuilder: A commercial content filtering service used to detect and remove sensitive or undesired web content. "and the Baidu DataBuilder service are utilized to filter out advertisements, sensitive political content, and territorial disputes."
- BERT: A bidirectional transformer LLM used for representation learning on text. "state-of-the-art architectures such as ViT~\cite{ViT} and BERT~\cite{devlin2019bert}"
- BERTopic: A topic modeling method that uses transformer embeddings, clustering, and class-based TF-IDF to extract coherent topics. "generated via BERTopic~\cite{grootendorst2022bertopicneuraltopicmodeling} on 10M subset."
- bidirectional distillation: A training technique where knowledge is transferred in both directions between models or tasks to improve performance. "a preranking-ranking strategy combined with bidirectional distillation."
- class-based TF-IDF: A variant of TF-IDF that computes term importance per class/cluster to extract representative keywords. "We then utilize class-based TF-IDF to extract representative keywords for each topic."
- CLIP (Contrastive Language-Image Pre-training): A dual-encoder framework that learns aligned image and text embeddings via contrastive learning. "Contrastive Language-Image Pre-training (CLIP)~\cite{clip} demonstrate exceptional generalization across a broad spectrum of downstream tasks"
- Common Crawl: A large-scale web crawl corpus used as a source for web-scraped data. "which contains 100 million image-text pairs collected from Common Crawl."
- continual pre-training: Further pre-training an existing model on new data to adapt or improve it. "We compare DanQing with existing datasets by continual pre-training of the SigLIP2 model."
- contrastive losses: Objectives that bring matched pairs closer and push mismatched pairs apart in embedding space. "utilizing InfoNCE~\cite{clip} or Sigmoid-based~\cite{siglip} contrastive losses"
- cross-entropy loss: A loss function measuring the difference between predicted and true distributions, commonly used for classification. "aligns modalities via a symmetric cross-entropy loss over a batch of image-text pairs"
- cross-modal retrieval: Retrieving data in one modality (e.g., images) using a query from another (e.g., text). "including zero-shot classification, cross-modal retrieval, and LMM-based evaluations."
- cosine similarity: A metric measuring the cosine of the angle between two vectors, often used for embedding similarity. "and compute their cosine similarity."
- dual-encoder architectures: Models with separate encoders for different modalities whose outputs are aligned in a shared embedding space. "By aligning dual-encoder architectures through image-text correspondence"
- entropy-based semantic filter: A filtering method using entropy of token distributions to remove low-information texts. "then apply an entropy-based semantic filter "
- FAISS: A library for efficient similarity search and clustering of dense vectors. "using the FAISS library~\cite{faiss}"
- FastText: A lightweight text classifier/embedding library used here for language identification. "We employ FastText~\cite{joulin2016fasttext} to identify and retain Chinese text"
- FG-CLIP2-L/16: A state-of-the-art Chinese CLIP-like retrieval model used to compute image-text similarities. "We employ the state-of-the-art Chinese retrieval model FG-CLIP2-L/16~\cite{fgclip2} to extract multimodal features"
- gating mechanism: A component that adaptively weights samples or signals, often to mitigate noise or emphasize informative data. "ALIP~\cite{alip} employs a gating mechanism for dynamic sample reweighting."
- HDBSCAN: A density-based clustering algorithm that finds clusters of varying density without requiring the number of clusters a priori. "Subsequently, we use HDBSCAN~\cite{grootendorst2022bertopicneuraltopicmodeling} to identify distinct semantic clusters"
- InfoNCE: A contrastive learning objective that normalizes over negatives to learn discriminative embeddings. "utilizing InfoNCE~\cite{clip} or Sigmoid-based~\cite{siglip} contrastive losses"
- image entropy: A measure of image information content based on the distribution of pixel intensities. "We quantify content complexity via image entropy "
- image-text alignment: The degree to which an image and its associated text describe the same semantic content. "refine the dataset based on image-text alignment."
- jieba: A Chinese text segmentation toolkit for tokenizing and part-of-speech tagging. "We use the jieba~\footnote{https://github.com/fxsjy/jieba} toolkit"
- Laplacian variance: A blur detection metric using the variance of the image Laplacian; low variance indicates blur. "blurry images are mitigated by applying a Laplacian variance threshold computed via OpenCV"
- LLaVA-NeXT: A training pipeline and recipe for building large multimodal models with vision-language alignment. "we strictly adhere to the LLaVA-NeXT~\cite{liu2024llavanext} training pipeline"
- Large Multimodal Models (LMMs): Models that process and reason over multiple modalities (e.g., vision and language) at scale. "Large Multimodal Models (LMMs)"
- NSFW: Content categorization for not safe for work material, typically filtered by automated detectors. "A 20M-parameter NSFW detector~\cite{PaddleHubPornDetectionCNN2021}"
- OCR: Optical Character Recognition; extracting text from images. "images dominated by OCR text rather than descriptive content."
- OFA-Large: A unified multimodal sequence-to-sequence model used to generate synthetic captions. "generated by OFA-Large~\cite{wang2022ofaunifyingarchitecturestasks}"
- OpenCC: A toolkit for converting between Traditional and Simplified Chinese. "followed by OpenCC~\cite{OpenCC} to standardize all content into Simplified Chinese."
- OpenCV: An open-source computer vision library used for image processing operations. "computed via OpenCV~\cite{opencv_library}"
- perplexity (PPL): A language modeling metric indicating how well a probability model predicts a sample; lower is generally better. "We further explore the text quality of DanQing\ through two metrics: semantic word density and perplexity (PPL)"
- preranking-ranking strategy: A two-stage retrieval or selection process that first filters candidates then re-ranks them. "through a preranking-ranking strategy combined with bidirectional distillation."
- semantic density: The proportion of content-bearing words (e.g., nouns/verbs/adjectives) indicating information richness. "we compute their proportions as a measure of semantic density."
- SigLIP: A CLIP-style framework using a sigmoid-based loss instead of softmax for scalable contrastive learning. "SigLIP~\cite{siglip} and SigLIP2~\cite{siglip2} adopt a sigmoid-based loss to replace the standard softmax, thereby eliminating the need for global normalization."
- SigLIP2: An improved SigLIP variant used as the backbone vision-language encoder in experiments. "we continue pre-training the SigLIP2~\cite{siglip2} model for 2 epochs"
- softmax normalization: The normalization in softmax-based objectives that can introduce compute bottlenecks at large batch sizes. "its softmax normalization imposes a computational bottleneck at scale."
- tokenization: Segmenting text into tokens for model input and analysis. "after SigLIP tokenization~\cite{siglip2}"
- topic modeling: Unsupervised discovery of latent themes in a corpus using embeddings and clustering. "we implement a topic modeling pipeline"
- UMAP (Uniform Manifold Approximation and Projection): A nonlinear dimensionality reduction technique for high-dimensional embeddings. "we apply Uniform Manifold Approximation and Projection (UMAP)~\cite{unmap_paper} for dimensionality reduction."
- Union-Find: A disjoint-set data structure used for efficient clustering/merging operations. "employ a Union-Find-based~\cite{tarjan1975efficiency} clustering algorithm"
- ViT (Vision Transformer): A transformer-based image encoder operating on patch tokens. "state-of-the-art architectures such as ViT~\cite{ViT} and BERT~\cite{devlin2019bert}"
- vision encoder: The image-processing component that produces visual embeddings for multimodal models. "varying only the vision encoder~(SigLIP2-L/16) to isolate the effect of pretraining data"
- Vision-Language Pre-training (VLP): Training paradigms that jointly learn from image-text pairs to produce aligned representations. "Vision-Language Pre-training~(VLP) models demonstrate strong performance"
- zero-shot classification: Classifying images into categories without task-specific training by leveraging aligned language prompts. "including zero-shot classification, cross-modal retrieval, and LMM-based evaluations."
Practical Applications
Immediate Applications
Below is a concise set of concrete, deployable use cases that leverage the paper’s dataset (DanQing) and its curation pipeline, along with key assumptions and dependencies.
- Chinese multimodal search and recommendation (software, media, e-commerce)
- Use DanQing-pretrained CLIP/SigLIP-style encoders to power text-to-image and image-to-text retrieval in Chinese for product catalogs, media libraries, and social platforms.
- Tools/Workflows: “Chinese CLIP embeddings” microservice; vector database indexing of images and captions; improved relevance tuning based on long-caption retrieval gains.
- Assumptions/Dependencies: Access to GPU/CPU inference; integration with existing search stack; domain-specific fine-tuning for SKU/product taxonomies.
- Product tagging, de-duplication, and visual QA in retail (e-commerce, advertising)
- Apply the image redundancy clustering and quality filters to clean product image sets; use zero-shot classification for rapid category assignment; improve “find similar” and recommendation.
- Tools/Workflows: Batch curation pipeline using FastText/OpenCC, Laplacian blur checks, entropy thresholds, union-find clustering; auto-tagging via prompt templates in Chinese.
- Assumptions/Dependencies: Product-specific label schemas; periodic re-curation as catalogs update; threshold-tuning to minimize false merges of near-duplicates.
- Media archive search and editorial assistance (news, media, cultural heritage)
- Enable semantic retrieval over historical and contemporary Chinese image-text collections; assist editors with caption suggestions and context discovery.
- Tools/Workflows: Cross-modal retrieval service; editorial UI with human-in-the-loop caption review; topic modeling (BERTopic) to surface evolving trends (2024–2025 coverage).
- Assumptions/Dependencies: Rights and compliance checks; guardrails to avoid propagating web biases; integration with archival metadata.
- Document-image retrieval for forms and scans (finance, government, enterprise content management)
- Exploit improved long-caption retrieval (DCI-CN, DOCCI-CN gains) to match complex Chinese descriptions to document images (forms, IDs, statements).
- Tools/Workflows: Embedding-based retrieval on scanned PDFs/images; OCR preprocessing; “find matching document page” workflows in claims processing or KYC.
- Assumptions/Dependencies: OCR quality; privacy/security controls; domain fine-tuning; evaluation against organization-specific documents.
- Accessibility: Chinese alt-text generation and enrichment (public web, education)
- Use DanQing-pretrained encoders with captioning models to generate or refine alt-text in Chinese for websites and apps, improving screen-reader support.
- Tools/Workflows: Caption generation pipeline with human QA; CMS plugin to auto-suggest alt-text; compliance checks for accessibility standards.
- Assumptions/Dependencies: Captioning model in addition to embeddings (e.g., BLIP/OFA-style); editorial oversight for sensitive content.
- Chinese multimodal assistants (software, education, consumer apps)
- Integrate DanQing-powered SigLIP2-L/16 vision encoders with LLaVA-NeXT-like LMMs to improve Chinese visual understanding in chatbots and tutoring apps.
- Tools/Workflows: LMM fine-tuning with Chinese-centric benchmarks (MMBench-CN, MME-RW); prompt templates and safety layers in Chinese.
- Assumptions/Dependencies: Training data for instruction tuning; GPU resources; monitoring for hallucinations and bias.
- Content safety and moderation augmentation (platforms, policy operations)
- Adapt the paper’s NSFW and safety filtering components to enterprise ingestion pipelines for Chinese web content.
- Tools/Workflows: Lightweight NSFW classifiers, advertisement/political content filters; configurable risk thresholds; sampling audits.
- Assumptions/Dependencies: Threshold calibration per jurisdiction; ongoing labeling for edge cases; rapid response to emergent harmful content types.
- Enterprise dataset curation workflow (any sector with large image-text stores)
- Adopt the multi-stage curation pipeline (text normalization, visual fidelity checks, semantic density filters, cross-modal alignment with Chinese-CLIP-L14) to build internal high-quality Chinese datasets.
- Tools/Workflows: Reusable curation scripts; cluster-based deduplication; alignment scoring and thresholding; logging/metrics for data quality KPIs.
- Assumptions/Dependencies: Engineering effort to operationalize; quality baselines for acceptance; periodic re-runs to incorporate new data.
- Trend analytics for product and content strategy (advertising, retail, media)
- Use BERTopic analysis on DanQing or internal corpora to identify emerging Chinese-language topics (fashion, technology, cuisine) and align campaigns.
- Tools/Workflows: Embedding + UMAP/HDBSCAN + c-TF-IDF pipeline; dashboards tracking topic shifts; campaign A/B testing.
- Assumptions/Dependencies: Regular data refreshes; careful handling of noisy trend signals; integration with BI tools.
- Multimodal RAG for Chinese content (software, knowledge management)
- Pair DanQing embeddings with vector databases to enable retrieval-augmented generation over images and associated Chinese texts for knowledge assistants.
- Tools/Workflows: Image/text indexing; RAG pipeline combining LMM vision encoder and Chinese LLM; guardrail prompts.
- Assumptions/Dependencies: LLM integration; latency/throughput constraints; robust grounding strategies.
Long-Term Applications
These opportunities likely require additional scaling, domain adaptation, research, or infrastructure development before broad deployment.
- Chinese multimodal foundation models and continual refresh (software, research)
- Train larger Chinese-centric VLP and LMM foundation models, leveraging DanQing’s superior scaling curves and up-to-date semantics, with scheduled updates (e.g., quarterly refresh from Common Crawl).
- Tools/Workflows: Distributed training (1B+ parameter vision encoders); continual learning pipelines; temporal drift monitoring.
- Assumptions/Dependencies: Significant compute (multi-GPU clusters); robust data governance; sustained open data availability under CC-BY 4.0.
- Domain-specialized datasets and models (healthcare, law, finance, scientific communication)
- Extend the curation pipeline to build medical, legal, and financial Chinese multimodal datasets; fine-tune for domain-specific retrieval, captioning, and reasoning.
- Tools/Workflows: Custom filters (PHI/PII detection, medical terminology checks); expert-verified labels; clinical/financial compliance audits.
- Assumptions/Dependencies: Access to domain data and SMEs; strict privacy/ethics; regulatory approvals; out-of-distribution generalization studies.
- AR/robotics with Chinese grounded perception (robotics, consumer devices)
- Deploy compressed DanQing-pretrained encoders for on-device, promptable visual perception (e.g., AR glasses, service robots that follow Chinese instructions).
- Tools/Workflows: Model distillation/quantization; real-time vision pipelines; multimodal task planners.
- Assumptions/Dependencies: Edge hardware acceleration; safety cases for physical interaction; latency guarantees.
- Generative systems aligned to Chinese semantics (creative industries, marketing)
- Fine-tune or train text-to-image models with DanQing-derived embeddings for better Chinese prompt understanding, stylistic alignment, and post-generation retrieval/ranking.
- Tools/Workflows: Hybrid ranker (retrieval-enhanced sampling); safety filters for generative outputs; provenance/watermark tools.
- Assumptions/Dependencies: Copyright and licensing clarity for training data; robust content safety and brand suitability.
- Cross-lingual retrieval and translation bridges (education, international business)
- Combine DanQing with English (LAION-like) datasets to build bilingual or multilingual VLPs enabling cross-lingual image-text search and caption translation.
- Tools/Workflows: Joint training or alignment distillation; bilingual evaluation suites; domain-adapted prompts.
- Assumptions/Dependencies: High-quality cross-lingual data; mitigation of language-specific biases; consistent tokenization strategies.
- Open standards and governance for dataset curation (policy, public sector, consortia)
- Derive policy frameworks and technical standards from DanQing’s pipeline for safe, auditable, large-scale multimodal data curation in Chinese contexts.
- Tools/Workflows: Dataset cards and risk registers; fairness audits; community-led benchmarks; reproducibility protocols.
- Assumptions/Dependencies: Multi-stakeholder coordination; legal harmonization across regions; funding for public infrastructure.
- Quality metrics and curation SDKs (software tooling ecosystem)
- Generalize the paper’s metrics (semantic density, perplexity bands, image fidelity/entropy, cross-modal similarity) into an SDK for dataset builders.
- Tools/Workflows: Plug-ins for data lakes; visualization dashboards; threshold recommendations; automated red-teaming pipelines.
- Assumptions/Dependencies: Maintenance and versioning; compatibility with diverse data stores; extensibility to new modalities.
- On-device multimodal assistants in Chinese (consumer electronics, automotive)
- Distill DanQing-pretrained models for phones, cameras, and IVI systems to enable local image captioning, navigation assistance, and product recognition.
- Tools/Workflows: Hardware-aware model optimization; offline inference; contextual personalization.
- Assumptions/Dependencies: Efficient runtime (NNAPI/NPU support); privacy-preserving personalization; safe fallback behaviors.
- Advanced evaluation suites for Chinese multimodality (academia, benchmarking bodies)
- Expand long-caption retrieval and reasoning benchmarks; incorporate temporal novelty and long-tail concept coverage analysis inspired by the paper’s findings.
- Tools/Workflows: Benchmark curation; leaderboard hosting; bias and robustness tracks.
- Assumptions/Dependencies: Community participation; stable dataset hosting; standardized metrics.
- Responsible AI and compliance programs (enterprise, policy)
- Build end-to-end compliance workflows that incorporate DanQing-like safety filters, documentation, and post-deployment monitoring for Chinese multimodal systems.
- Tools/Workflows: Policy-driven pipelines; incident response plans; fairness/bias dashboards; model cards.
- Assumptions/Dependencies: Organizational buy-in; alignment with local regulations; continuous oversight.
Cross-cutting assumptions and dependencies
- Compute and infrastructure: Training and serving DanQing-pretrained encoders (SigLIP2 variants) require GPUs; production workloads need scalable inference and vector search.
- Licensing and legal: The dataset is released under CC-BY 4.0, but downstream use must respect image provenance, copyright, and website terms; organizations should conduct legal reviews.
- Domain adaptation: While general-purpose, best results in specialized sectors (e.g., healthcare, finance) will require fine-tuning and domain-specific data.
- Safety and bias: Web-scale Chinese data can reflect societal biases; safety filters need continuous calibration, and human oversight is recommended for sensitive applications.
- Refresh cadence: The paper shows benefits from 2024–2025 web data; maintaining performance on evolving semantics likely requires periodic dataset refresh and re-training.
Collections
Sign up for free to add this paper to one or more collections.

