Understanding Chinese Video and Language via Contrastive Multimodal Pre-Training
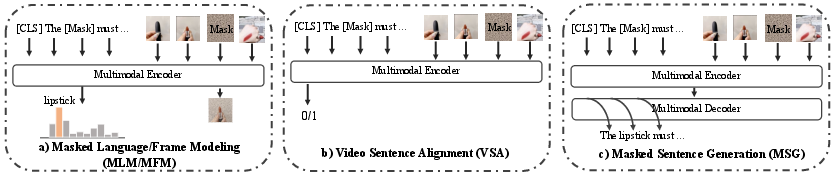
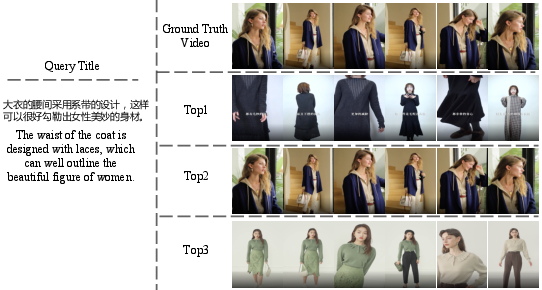
Abstract: The pre-trained neural models have recently achieved impressive performances in understanding multimodal content. However, it is still very challenging to pre-train neural models for video and language understanding, especially for Chinese video-language data, due to the following reasons. Firstly, existing video-language pre-training algorithms mainly focus on the co-occurrence of words and video frames, but ignore other valuable semantic and structure information of video-language content, e.g., sequential order and spatiotemporal relationships. Secondly, there exist conflicts between video sentence alignment and other proxy tasks. Thirdly, there is a lack of large-scale and high-quality Chinese video-language datasets (e.g., including 10 million unique videos), which are the fundamental success conditions for pre-training techniques. In this work, we propose a novel video-language understanding framework named VICTOR, which stands for VIdeo-language understanding via Contrastive mulTimOdal pRe-training. Besides general proxy tasks such as masked language modeling, VICTOR constructs several novel proxy tasks under the contrastive learning paradigm, making the model be more robust and able to capture more complex multimodal semantic and structural relationships from different perspectives. VICTOR is trained on a large-scale Chinese video-language dataset, including over 10 million complete videos with corresponding high-quality textual descriptions. We apply the pre-trained VICTOR model to a series of downstream applications and demonstrate its superior performances, comparing against the state-of-the-art pre-training methods such as VideoBERT and UniVL. The codes and trained checkpoints will be publicly available to nourish further developments of the research community.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.

