- The paper introduces a recipe for training CLIP models on worldwide image-text pairs that overcomes the curse of multilinguality.
- It employs a language-aware curation algorithm with expanded metadata (27M+ entries in 300+ languages) and language-specific thresholds to ensure balanced diversity.
- By scaling training data and model capacity with the ViT-H/14 architecture, Meta CLIP 2 outperforms English-only models on multiple benchmarks, benefiting all languages.
Introduction and Motivation
Meta CLIP 2 addresses the persistent limitations of existing CLIP-style models, which have historically relied on English-centric data curation and training. The paper identifies two primary challenges in scaling CLIP to a worldwide, multilingual setting: (1) the absence of scalable, transparent curation methods for non-English data, and (2) the "curse of multilinguality," where models trained on multilingual data underperform their English-only counterparts on English benchmarks. The authors propose a comprehensive recipe for constructing and training CLIP models from scratch on web-scale, worldwide image-text pairs, aiming to achieve mutual benefits across languages and to break the trade-off between English and non-English performance.
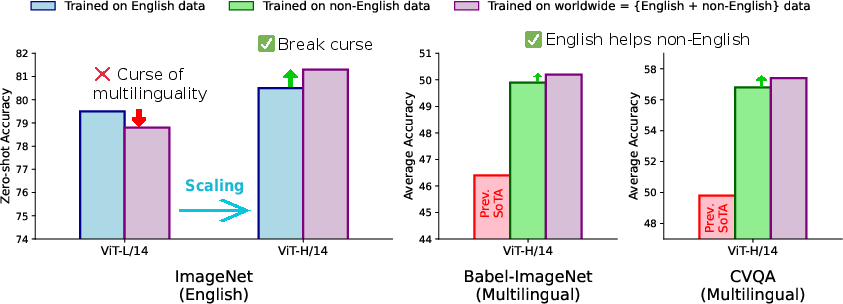
Figure 1: (Left) CLIP training suffers from the curse of multilinguality that the English performance of a CLIP model trained on worldwide (i.e., English + non-English), billion-scale data is worse than its English-only counterpart, even when applying our recipe on ViT-L/14; scaling to ViT-H/14 enables non-English data helps English-only CLIP. (Right) English data also helps non-English CLIP.
The Meta CLIP 2 pipeline is designed to maximize compatibility with the original CLIP and Meta CLIP architectures, introducing only the minimal necessary changes to enable worldwide scaling. The recipe consists of three core components:
- Worldwide Metadata Construction: The metadata, which defines the set of visual concepts for curation, is expanded from 500k English entries to over 27 million entries across 300+ languages, leveraging multilingual WordNet and Wikipedia. Metadata is maintained per language to avoid semantic collisions and to facilitate future extensibility.
- Language-Aware Curation Algorithm: The curation process is extended to operate language-by-language. Language identification (LID) is applied to each alt-text, and substring matching is performed against the corresponding language's metadata. To balance head and tail concepts, a language-specific threshold tlang is computed for each language, maintaining a fixed tail proportion (6%) as in Meta CLIP. This ensures that the curated data distribution is balanced and diverse across all languages.
- Training Framework Adaptations: The training setup is modified to (a) use a multilingual tokenizer, (b) scale the number of seen training pairs proportionally to the increase in data size (to avoid downsampling English data), and (c) increase model capacity. The ViT-H/14 architecture is identified as the minimal viable capacity to break the curse of multilinguality.
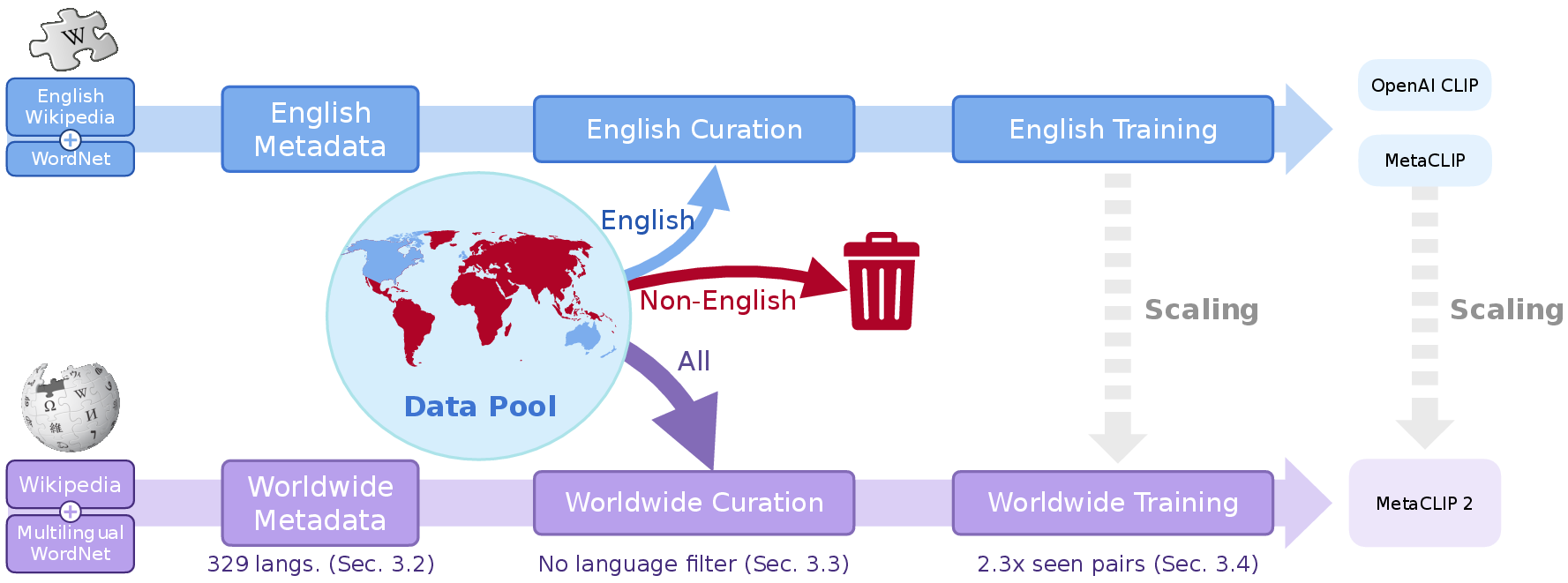
Figure 2: Overview of MetaCLIP 2 recipe: scaling CLIP data and training to worldwide scope.
Empirical Results and Analysis
Breaking the Curse of Multilinguality
A key empirical finding is that, with sufficient model capacity (ViT-H/14) and scaled training (2.3× more seen pairs), Meta CLIP 2 not only eliminates the English performance degradation observed in prior multilingual CLIP models but also achieves mutual benefits: non-English data improves English performance and vice versa. Specifically, Meta CLIP 2 ViT-H/14 surpasses its English-only counterpart on zero-shot ImageNet (81.3% vs. 80.5%) and sets new state-of-the-art results on multilingual benchmarks such as CVQA (57.4%), Babel-ImageNet (50.2%), and XM3600 image-to-text retrieval (64.3%).
Ablation Studies
Ablations demonstrate that language-specific metadata and curation thresholds are critical for optimal performance. Merging all metadata or using a single threshold across languages leads to significant drops in both English and multilingual accuracy. The choice of tokenizer also impacts results, with XLM-V (900k vocab) yielding the best trade-off between English and non-English performance.
Cultural Diversity and Downstream Generalization
Meta CLIP 2's no-filter curation philosophy, which does not discard any image-text pairs based on language, results in models with improved cultural and geographic diversity. On benchmarks such as Dollar Street, GeoDE, and GLDv2, Meta CLIP 2 demonstrates superior zero-shot and few-shot geo-localization accuracy compared to both English-only and prior multilingual models.
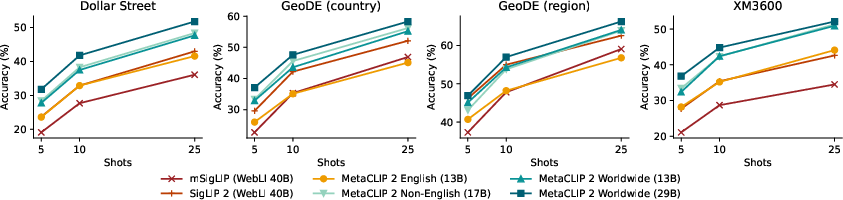
Figure 3: Few-shot geo-localization accuracy on cultural diversity benchmarks.
The paper evaluates the learned representations using alignment and uniformity metrics. Meta CLIP 2 achieves favorable scores, indicating that its embeddings are both semantically meaningful and well-distributed in the representation space, without the biases observed in models trained with proprietary or filtered data.
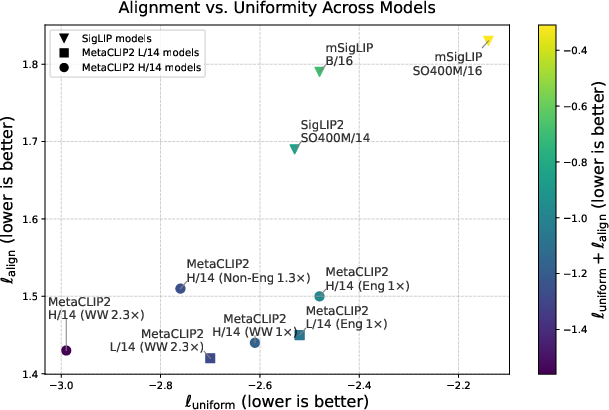
Figure 4: Alignment and uniformity scores calculated on a 5k holdout set, showing Meta CLIP 2's balanced embedding properties.
Implementation Considerations
- Scalability: The curation pipeline is parallelized (800 jobs, 40GB RAM each), leveraging the Aho-Corasick algorithm for efficient substring matching across millions of metadata entries and hundreds of languages.
- Memory Management: Memory-mapped files are used to handle per-language entry counts and sampling probabilities, ensuring feasibility at web scale.
- Safety and Benchmark Integrity: NSFW content and personally identifiable information are filtered, and deduplication is performed to avoid benchmark leakage.
- Training: The batch size and number of seen pairs are scaled to maintain the absolute number of English examples, preventing performance regression due to dilution by non-English data.
Implications and Future Directions
Meta CLIP 2 demonstrates that, with principled data curation and sufficient model capacity, the trade-off between English and multilingual performance in CLIP-style models can be eliminated. The approach enables a single model to serve as a universal vision-language encoder, supporting zero-shot and retrieval tasks across hundreds of languages, and providing native-language supervision without reliance on translation or distillation. The open-sourcing of metadata, curation, and training code sets a new standard for transparency and reproducibility in large-scale multimodal pretraining.
Practically, Meta CLIP 2's methodology is directly applicable to the construction of foundation models for MLLMs, self-supervised learning, and generative models (e.g., DALL-E, diffusion models) that require culturally and linguistically diverse data. Theoretically, the findings suggest that the curse of multilinguality is not an inherent limitation but a consequence of insufficient scaling and suboptimal data curation. This has broad implications for the design of future multilingual and multimodal foundation models.
Conclusion
Meta CLIP 2 provides a rigorous, scalable recipe for training CLIP models on worldwide, multilingual data from scratch. By jointly scaling metadata, curation, and model capacity, it achieves strong performance on both English and multilingual benchmarks, breaking the previously observed trade-off. The work establishes a new paradigm for open, culturally diverse, and language-agnostic vision-language pretraining, with significant implications for the next generation of multimodal AI systems.

