- The paper proposes the CLIDD paradigm that decouples sampling across feature scales for improved efficiency while preserving accuracy.
- It incorporates a cross-layer predictor and layer-independent sampler with hardware-aware kernel fusion, boosting throughput on edge devices.
- Experimental results validate superior matching precision and real-time performance in challenging visual localization and mapping tasks.
Introduction
The paper "CLIDD: Cross-Layer Independent Deformable Description for Efficient and Discriminative Local Feature Representation" (2601.09230) addresses the dual challenges of discriminativeness and computational efficiency in local feature representation, which are pivotal in tasks such as structure-from-motion, robot navigation, and visual localization. While existing high-performance models utilize dense fusion across feature hierarchies—leading to high computation and memory costs—efficiency-oriented designs often compromise representation quality due to restricted spatial context or limited flexibility in sampling. The authors propose the Cross-Layer Independent Deformable Description (CLIDD) paradigm, which decouples the sampling process across multiple feature scales via a hardware-aware, sparse deformable aggregation architecture, thereby achieving state-of-the-art matching precision and throughput.
Motivation and Limitations of Prior Work
Many established local descriptors depend on either single-resolution or densely upsampled feature fields. Sub-scale vanilla approaches aggregate features into a low-resolution map, sacrificing spatial granularity and discrimination power (Figure 1). In contrast, full-scale vanilla and sparse deformable sampling strategies (e.g., ALIKED, DeDoDe) leverage dense maps but incur substantial computation and memory overhead. Even recent efficient models like EdgePoint2 and XFeat suffer when attempting to scale the descriptors’ discriminativeness over variable deployment conditions or high-density sampling regimes. There exists a critical need to both (i) decouple description from unified, dense feature volumes, and (ii) exploit hardware-level kernel fusion to unlock real-time inference on edge platforms without sacrificing match precision.
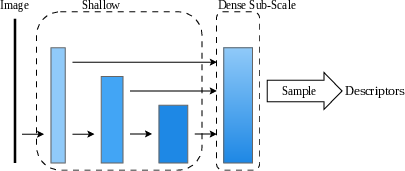
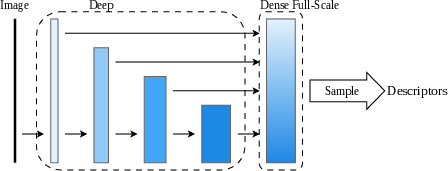
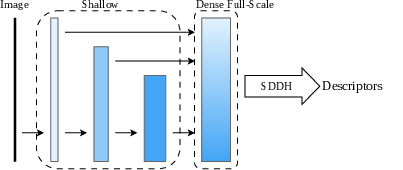
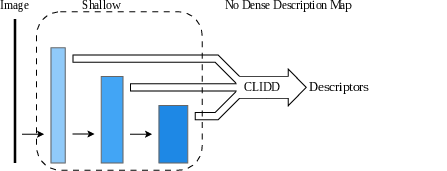
Figure 1: Structural comparison of local descriptor extraction strategies, contrasting sub-scale vanilla, full-scale vanilla, full-scale sparse deformable heads (SDDH), and the proposed CLIDD approach.
CLIDD Architecture and Description Mechanism
CLIDD introduces two core innovations: the Cross-Layer Predictor and the Layer-Independent Sampler, tightly coupled with a fused kernel implementation to maximize efficiency.
The Cross-Layer Predictor operates on concatenated point-wise embeddings drawn directly from multiple network stages (1/2, 1/8, 1/32 downsampling), generating coordinated deformable offsets for each feature layer. By eschewing dense aggregation, this predictor injects minimal overhead and produces per-layer, learnable sampling locations that capture task-aligned structural cues at varying scales.
Subsequently, the Layer-Independent Sampler retrieves sparse descriptors independently from each hierarchy, guided by the predicted offsets. The outputs across scales are aggregated, facilitating both fine geometry and semantic context in the final description vector, with strong expressivity especially at high sampling densities.
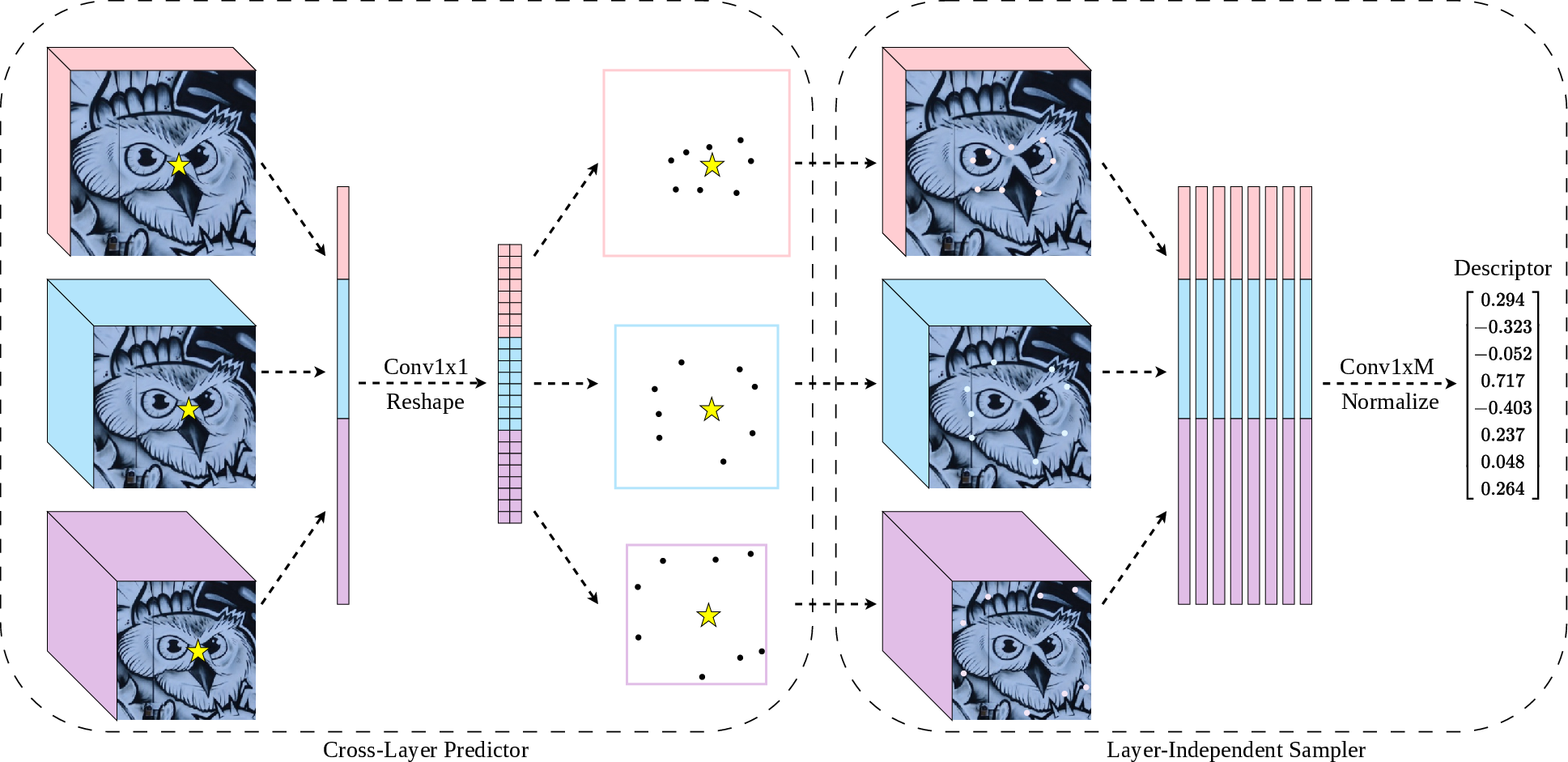
Figure 2: CLIDD mechanism—cross-layer predictor generates offsets, layer-independent samplers retrieve feature vectors, aggregate into a discriminative descriptor without constructing a dense feature map.
In terms of architectural integration, the lightweight backbone leverages standard convolutions and shallow ResNet blocks, ensuring high throughput (Figure 3). The detection head remains lean, operating at mid-level resolution, while the description head implements the CLIDD strategy for efficient feature extraction.
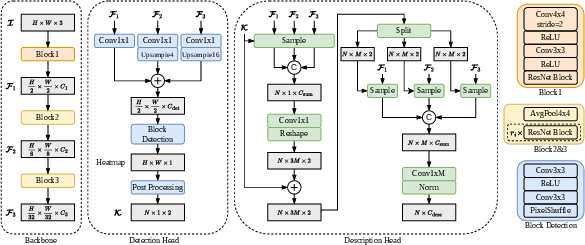
Figure 3: Overview of the full model architecture, emphasizing the multi-scale backbone and integration of the CLIDD head for efficient yet expressive local descriptor extraction.
Training and Optimization Protocols
The training scheme fuses metric learning (DualSoftmax loss), knowledge distillation (Orthogonal-Procrustes loss), and precise detector supervision (UnfoldSoftmax loss). Knowledge distillation—specifically for extremely lightweight configurations—utilizes SVD-based low-rank alignment with a high-capacity teacher network (e.g., ALIKED-N32), ensuring robust representation even in low-parameter regimes. Hyperparameters for loss weighting are scheduled by model scale, with smaller models relying more heavily on distillation.
To address real-time requirements, CLIDD employs a custom kernel fusion strategy: sampling and partial aggregation are performed within SRAM, nearly eliminating global memory bottlenecks and resulting in sustained high throughput, particularly as the number of keypoints and sampling points increases.
Experimental Results and Analysis
CLIDD sets new standards for the precision-efficiency trade-off on several major geometric vision tasks:
- Efficiency: The Atom variant (A48, 4,252 params) achieves $881.1$ FPS on NVIDIA Jetson Orin-NX, representing a 99.7% reduction in parameter count compared to SuperPoint while matching its performance. Ultra variants (U128) retain high (200+ FPS) on edge devices even with extensive sampling.
- Matching Precision: Across HPatches, MegaDepth-1500, and ScanNet-1500, CLIDD variants consistently outperform or match all baseline descriptors in accuracy (AUC and MHA metrics), including prior SOTA transformer-based and dense fusion methods.
- Localization and Robustness: On challenging datasets such as Aachen Day-Night and InLoc, CLIDD yields top localization rates, demonstrating temporal and spatial robustness under severe illumination and viewpoint variation. Results on the Image Matching Challenge 2022 further validate the generalization to competitive settings.
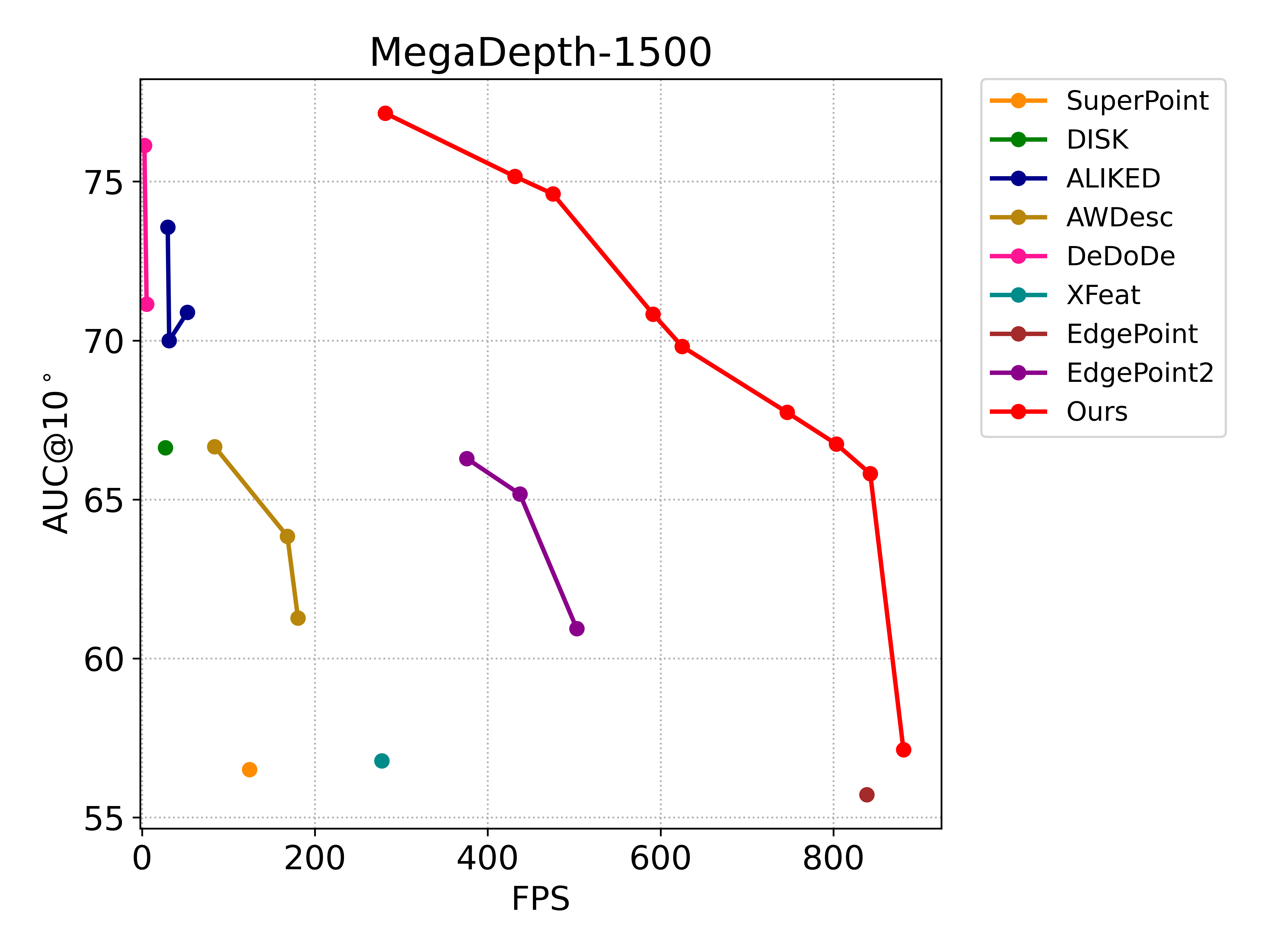
Figure 4: Precision-efficiency comparison across resource-constrained devices; CLIDD-based models dominate the upper-right quadrant across all operational scales.

Figure 5: Qualitative match visualization on MegaDepth-1500, comparing CLIDD (U128) to high-capacity SOTA alternatives (ALIKED-N32, AWDesc-CA, DeDoDe-G).
Figure 6: Throughput analysis on various model scales and number of keypoints—kernel fusion (solid) achieves superior scaling relative to non-fused baselines (dashed) in log2 space.
Ablation studies demonstrate that layer-independent sampling and cross-layer coordinated offsets are both necessary for optimal matching performance. Fused kernels are critical to maintain high throughput at elevated keypoint densities.
Theoretical and Practical Implications
CLIDD formally demonstrates that dense feature aggregation is not a strict requirement for state-of-the-art discriminativeness in local feature descriptors. Sparse, per-layer deformable sampling, if coordinated via lightweight cross-layer prediction, yields superior efficiency and precision, especially in compute- and memory-bound scenarios. The kernel fusion paradigm exposes the practical bottlenecks of prior SDDH/vanilla dense architectures and is directly extensible to other multi-scale description heads.
On the theoretical side, the empirical results challenge the orthodoxy that unified high-res maps or dense transformer modeling are prerequisites for geometric stability and robustness. Practically, the range of model variants enables deployability from robotics edge platforms to server-scale mapping workloads.
Outlook and Future Directions
The current framework still exhibits some spatial clustering of detected keypoints in dense, non-max-suppressed modes—limiting spatial uniformity crucial to full-scene coverage in SfM and SLAM. Future research should investigate detector strategies that enforce uniformity or introduce learned regularization while maintaining strict efficiency. Additionally, integrating cross-layer deformable description with emerging transformer or foundation model backbones could further improve scalability to long-range or multi-modal matching scenarios.
Conclusion
CLIDD provides a significant advance in the design of local feature representations by structurally decoupling sampling from dense aggregation and leveraging hardware-aware optimization. This results in simultaneous improvements in accuracy and throughput, both theoretically and in practical real-time systems, dispensing with legacy dependencies on dense, monolithic feature volumes. The methodological innovations offer direct and robust pathways for practical geometric reasoning systems, spanning embedded robotics to large-scale 3D localization applications.