- The paper introduces a two-stage training strategy using knowledge distillation from a CricaVPR teacher model with DINOv2-base for robust feature extraction.
- It employs a Top-Down attention-based Deformable Aggregator to integrate global semantic cues with local content, reducing model parameters and FLOPs by over 60%.
- Experimental evaluations on benchmarks like Pitts30k and MSLS-val demonstrate competitive retrieval performance and superior inference speed in challenging scenarios.
D2-VPR: A Parameter-efficient Visual Place Recognition Method
Introduction to VPR Challenges
Visual Place Recognition (VPR) plays a crucial role in determining the geographic location of images by comparing them against a geo-tagged database. The practice is pivotal in applications such as autonomous navigation and augmented reality, especially because of lower costs and deployment simplicity compared to other sensing modalities like LiDAR. However, VPR faces challenges due to significant appearance changes, perceptual aliasing, and viewpoint shifts.
Recent developments in foundational vision models, specifically self-supervised transformers like DINOv2, have progressively mitigated these challenges. DINOv2, trained on extensive image datasets, excels in feature generalization, presenting robust solutions to varying environmental conditions. Yet, its high computational demands limit its practical application in resource-constrained scenarios. The paper "D2-VPR" (2511.12528) addresses this by introducing a parameter-efficient framework leveraging knowledge distillation and deformable aggregation.
Methodology and Model Design
The approach hinges on a two-stage training strategy supplemented by innovative architectural components:
Knowledge Distillation and Two-stage Training: The training strategy consists of pre-training through knowledge distillation followed by fine-tuning customized for VPR tasks. The preliminary stage employs CricaVPR as the teacher model, adopting DINOv2-base for robust feature extraction. Distillation channels semantic capacity to a lightweight student model through metrics such as Mean Squared Error loss, preserving feature integrity across models (Figure 1).
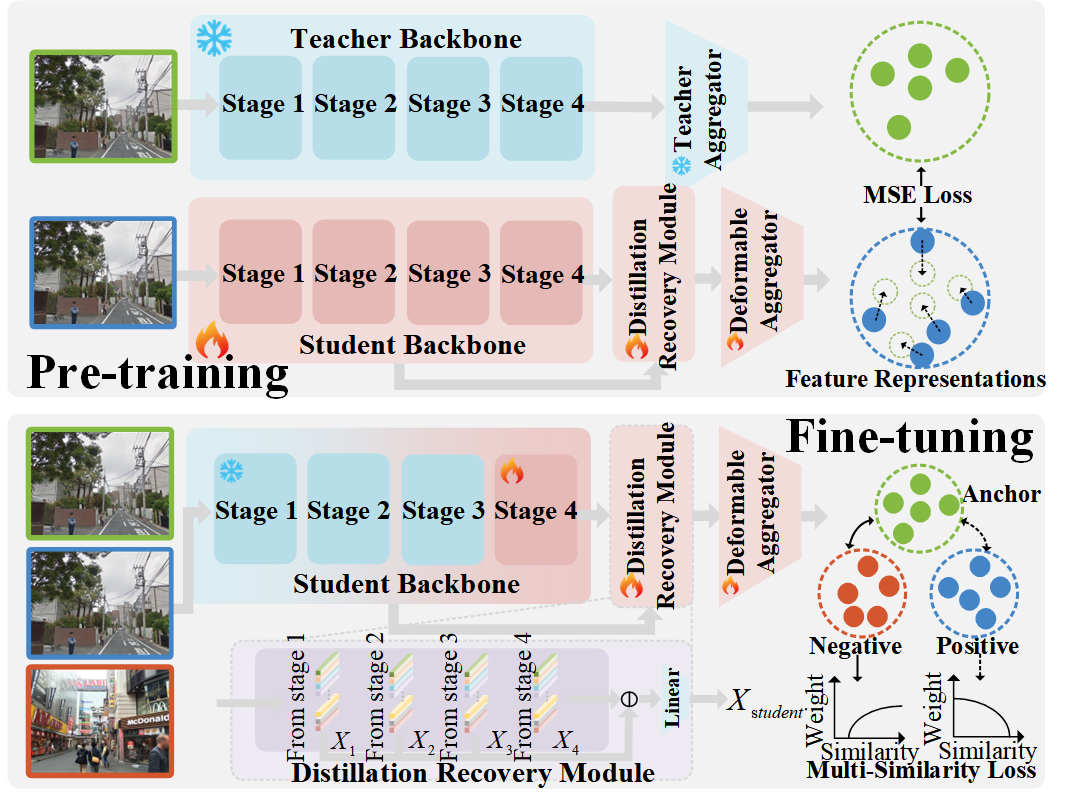
Figure 1: Two training stages of our VPR model.
Deformable Aggregator: Inspired by top-down neural attention mechanisms, the model integrates global semantic cues with local content via the Top-Down-attention-based Deformable Aggregator (TDDA). This adaptive processing enhances spatial pooling capabilities, crucial for handling irregular structures effectively (Figure 2).
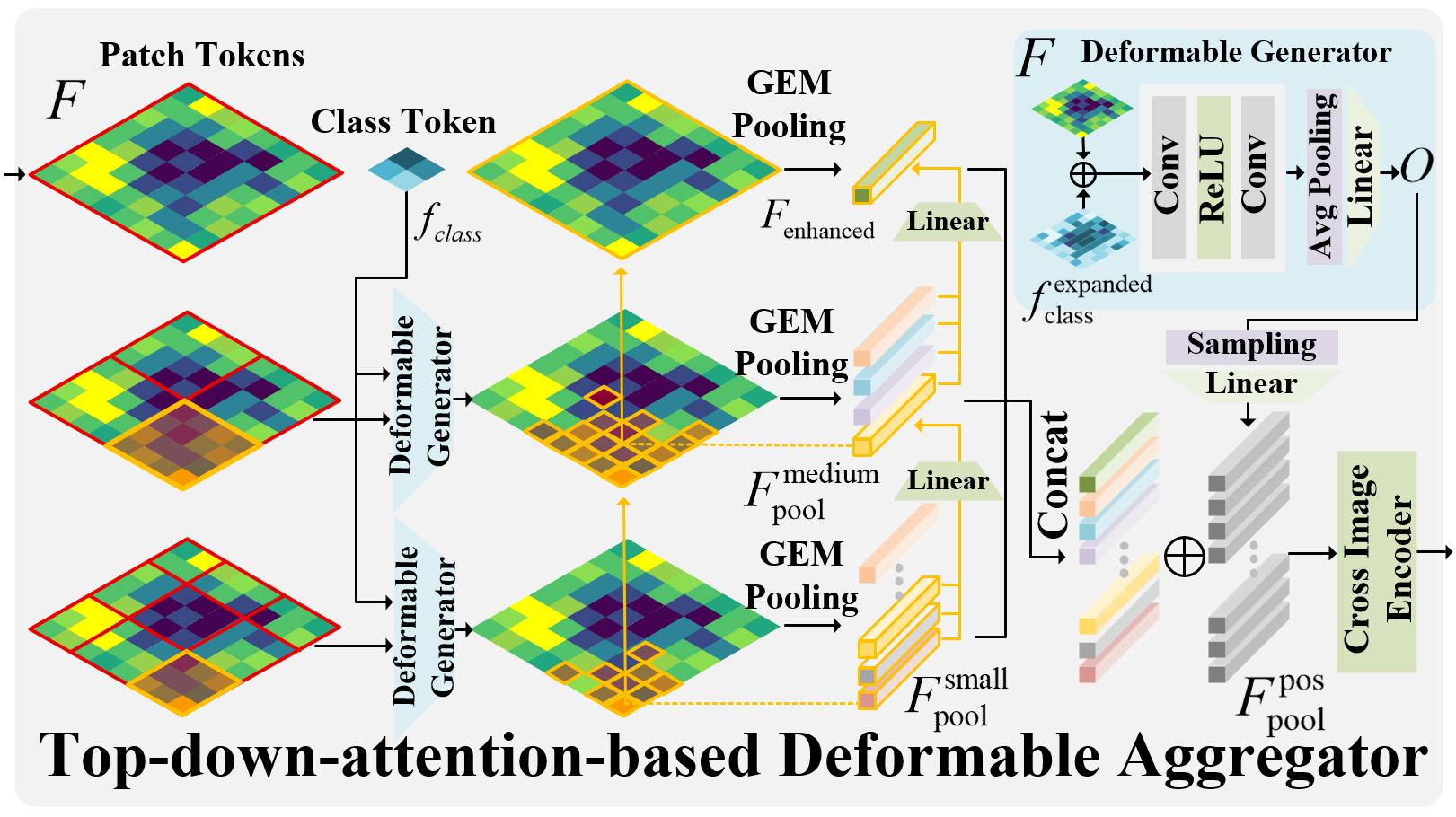
Figure 2: Top-down-attention-based deformable aggregator.
The architectural refinement through these components results in substantial reductions in model parameters and FLOPs (approximately 64.2\% and 62.6\%).
Experimental Evaluation
Performance Analysis: D2-VPR demonstrates leading results on benchmarks including Pitts30k, MSLS-val, and SPED. These reflect the trade-off between computational efficiency and accuracy enhancement facilitated by the reduced parameter and FLOPs model setup (Figure 3).
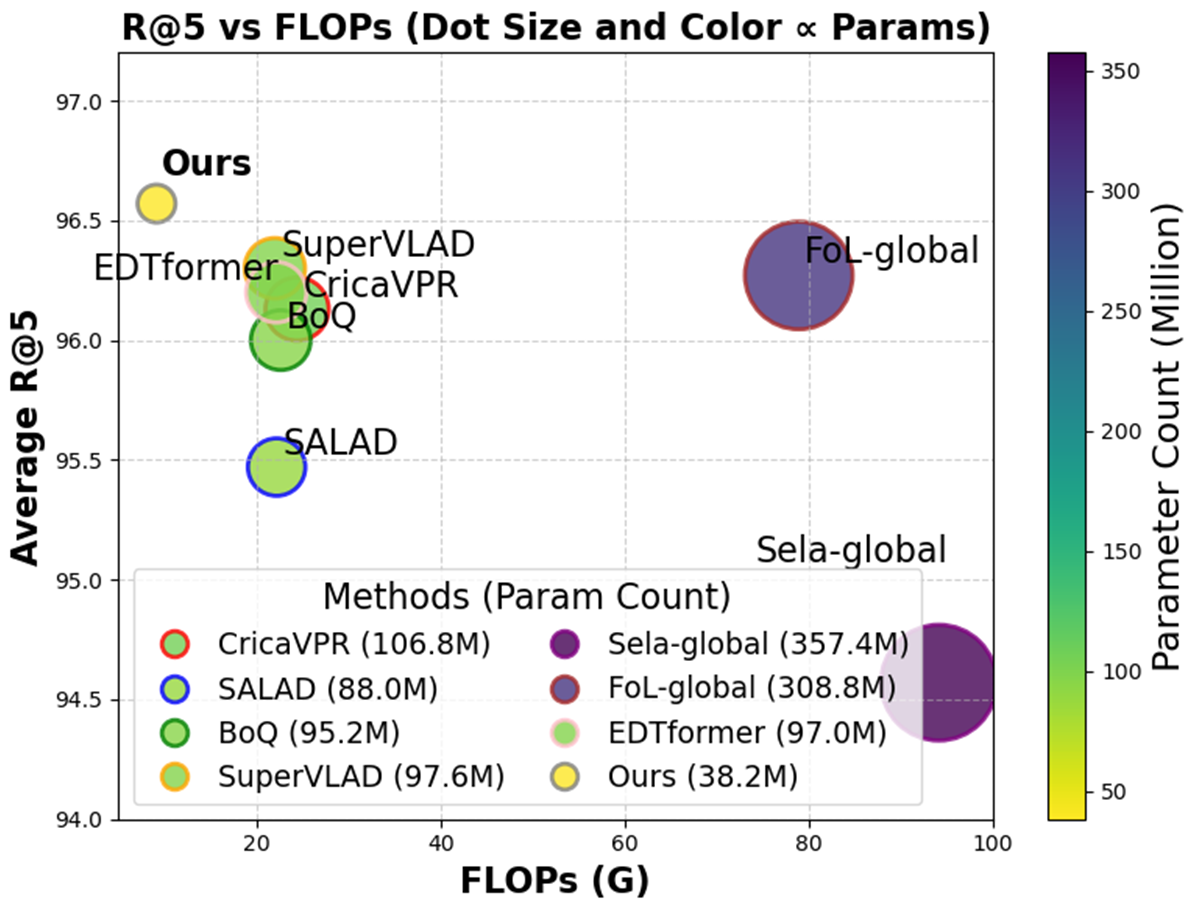
Figure 3: The comparison of average R@5 against FLOPs and parameter count on Pitts30k, MSLS-val, and SPED.
Qualitative Insights: Comparative analysis exhibits competitive results versus state-of-the-art models across challenging scenarios of long-term appearance changes and drastic lighting variations. The qualitative assessments affirm the model's nuanced attention to persistent spatial features pivotal for reliable place recognition (Figure 4).

Figure 4: Qualitative VPR comparison results, highlighting the robustness under challenging scenarios.
Efficiency Metrics: Evaluation of inference and computational speed substantiates the framework's superiority in processing efficiency. Despite maintaining competitive retrieval performance, D2-VPR achieves superior speed benchmarks compared to existing solutions, delivering rapid processing suited to real-world applications (Figure 5).
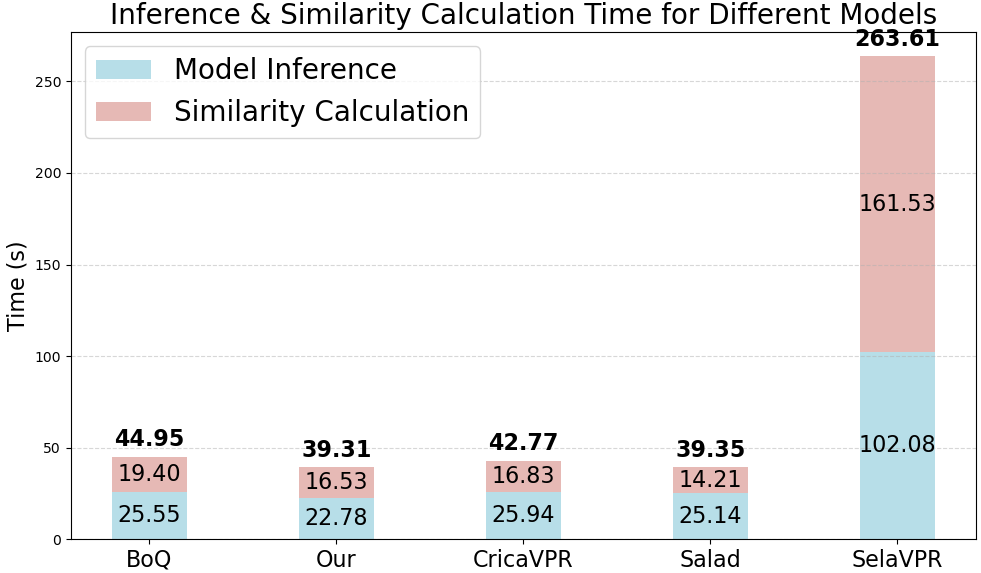
Figure 5: Method comparison of inference and computational speed on AmsterTime.
Implications and Future Directions
The implications of D2-VPR extend beyond academic merit by introducing a feasible approach to VPR tasks on resource-limited devices. The reduced computational overhead without compromising performance represents a significant step toward practical implementation in autonomous systems and applications requiring real-time location intelligence.
Future development may explore enhancing deformable aggregation techniques to further elevate processing speeds without sacrificing precision. Additionally, expanding this approach to multimodal VPR systems could integrate complementary sensory inputs, reinforcing robust place recognition across diverse scenarios.
Conclusion
"D2-VPR" effectively combines the strengths of visual foundation models with parameter optimization via knowledge distillation and sophisticated aggregation. The framework exemplifies a balanced approach to achieving computational efficiency, enhancing its suitability for extensive deployment in diverse real-world conditions. Through rigorous evaluations and strategic architectural innovations, the study sets a precedent for scalable VPR methodologies in future AI advancements.

