Geometric Stability: The Missing Axis of Representations
Abstract: Analysis of learned representations has a blind spot: it focuses on $similarity$, measuring how closely embeddings align with external references, but similarity reveals only what is represented, not whether that structure is robust. We introduce $geometric$ $stability$, a distinct dimension that quantifies how reliably representational geometry holds under perturbation, and present $Shesha$, a framework for measuring it. Across 2,463 configurations in seven domains, we show that stability and similarity are empirically uncorrelated ($ρ\approx 0.01$) and mechanistically distinct: similarity metrics collapse after removing the top principal components, while stability retains sensitivity to fine-grained manifold structure. This distinction yields actionable insights: for safety monitoring, stability acts as a functional geometric canary, detecting structural drift nearly 2$\times$ more sensitively than CKA while filtering out the non-functional noise that triggers false alarms in rigid distance metrics; for controllability, supervised stability predicts linear steerability ($ρ= 0.89$-$0.96$); for model selection, stability dissociates from transferability, revealing a geometric tax that transfer optimization incurs. Beyond machine learning, stability predicts CRISPR perturbation coherence and neural-behavioral coupling. By quantifying $how$ $reliably$ systems maintain structure, geometric stability provides a necessary complement to similarity for auditing representations across biological and computational systems.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain-language explanation of “Geometric Stability: The Missing Axis of Representations”
What’s this paper about? (Overview)
This paper asks a simple question: when we look inside AI models (and even biological systems) to see how they organize information, are we checking the right things? Most tools today ask “How similar is this model to another model?” The authors argue that’s only half the story. Two systems can look similar but fall apart when you poke them. So they introduce a new idea called geometric stability, which measures whether a system’s “shape” of information stays steady when you make small changes, like using different inputs or sampling different features. They also present a tool to measure this, called Shesha.
Think of a library: it’s not just about having the same books (similarity), it’s about keeping the shelving and index system intact so you can find them (stability). Shesha checks the “indexing system,” not just the inventory.
What were the main questions? (Key objectives)
The paper explores three kid-friendly questions:
- Do “similarity” and “stability” mean the same thing? Or are they different?
- Can stability help us in real tasks—like catching when a model’s behavior starts to drift, choosing better models, or steering a model’s behavior with simple nudges?
- Is stability useful beyond AI, for example in biology and neuroscience?
How did they study it? (Methods in simple terms)
The authors compare thousands of model representations across many areas (language, images, audio, video, proteins, cells, and brain recordings). Here’s how their approach works in everyday language:
- What is a “representation”? It’s like a map inside a model that places similar things close together. For example, the words “cat” and “kitten” might live near each other in that map.
- What is “similarity”? It’s checking whether two different maps line up. Common tools (like CKA or RSA) ask: “Do these two models organize things in a similar way?”
- What is “geometric stability”? It’s checking whether one map keeps its shape when you slightly nudge it. Imagine you photocopy the map with different ink or paper or cut it into halves—does the layout still make sense? If small changes scramble the distances between points, the geometry is unstable.
- How does Shesha measure stability?
- Splits the features in half and checks if the two halves produce similar distance charts (Feature-Split Shesha).
- Or splits the data (inputs) in half and checks again (Sample-Split Shesha).
- If there are labels (like sentiment classes), a supervised version checks stability aligned with the task.
- A helpful analogy for “principal components”: Imagine listening to a song and turning up the loudest instruments. Similarity tools tend to pay attention to those loudest parts. But the quieter instruments (the fine details) can matter a lot for how the song feels. Shesha still listens for the quiet parts—so it can catch problems that similarity might ignore.
They tested this across 2,463 different settings, using many model types and datasets, and also ran controlled experiments that removed certain “loud” patterns to see which tools kept working.
What did they discover? (Main findings and why they matter)
Below is a short list that summarizes the main outcomes and why they’re important.
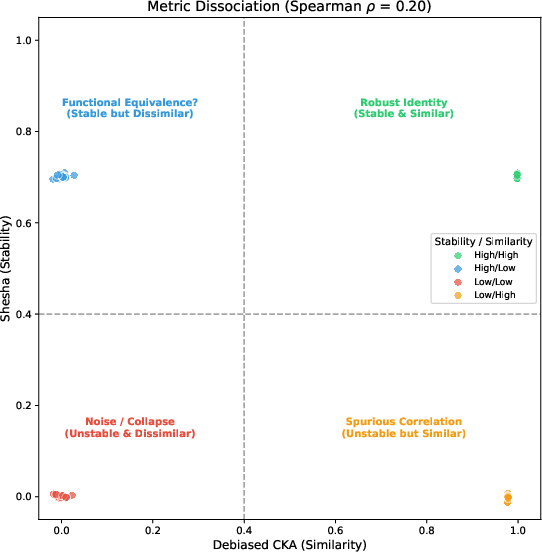
- Stability and similarity are different—and often unconnected Across thousands of tests, being “similar” to another model didn’t mean being “stable” to small changes. In fact, overall the link between them was nearly zero. This means you can’t assume a model that “looks right” also “holds together” under pressure.
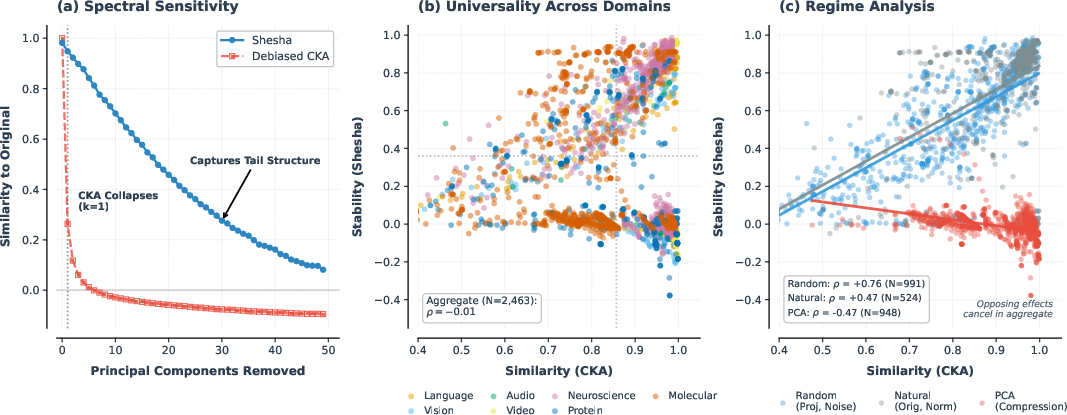
- Similarity can miss important structure that stability catches When the authors removed just the strongest patterns (the “loudest instruments”), similarity tools quickly broke down. Shesha kept working because it pays attention to the fine details spread across the whole “spectrum.” This shows stability captures subtle but important geometry that similarity overlooks.
- Better early warnings for safety and reliability When models are fine-tuned or slightly altered, Shesha detected changes earlier than common similarity tools and did so with fewer false alarms than some strict “distance” tools. In everyday terms: Shesha acts like a sensitive (but not jumpy) smoke detector for model drift.
- Predicting how well a model can be steered Sometimes we want to “steer” a model’s behavior by adding a simple direction to its internal activations (like nudging a car gently to the left). The paper shows that supervised stability (stability aligned with the task) strongly predicts whether this simple steering will work. In short: a stable, task-aligned geometry makes a model easier to control with simple tools.
- Model selection: transferability vs. stability trade-off in vision Some image models that transfer well to many tasks (like DINOv2) were found to be less stable, while others (like CLIP-family and certain hierarchical architectures) were more stable. This suggests a “geometric tax”: optimizing for very flexible features can reduce the consistent structure needed for predictable behavior.
- Beyond AI: stability tracks biological coherence In CRISPR experiments, stability rose with the strength and consistency of gene perturbations—suggesting it captures how coherent a cell’s response is. In brain data, regions with higher stability had neural activity more tightly linked to behavior, hinting that stability tracks functionally meaningful structure in the brain.
Why this matters:
- If you’re deploying models in safety-critical settings, you need more than just similarity.
- If you want to guide or edit a model’s behavior with simple controls, stability tells you if that will work.
- If you’re choosing models, you may need to balance “flexibility for new tasks” with “consistency and predictability.”
So what’s the big picture? (Implications and impact)
- Add a new checkpoint: stability The authors argue that stability is a missing axis in how we audit and understand models. Similarity tells you what’s represented; stability tells you whether that structure holds up under small changes. You need both.
- Better monitoring tools Shesha can serve as a “geometric canary” that warns you early when fine-tuning or updates quietly reshape a model’s internal structure, even before performance obviously drops.
- Smarter model choices If your goal is dependable behavior (like in monitoring, safety, or zero-shot use), pick models with higher stability. If your goal is maximum adaptability to new tasks, you might accept lower stability—but know the trade-off.
- Clearer understanding of control To steer models reliably, don’t just check if classes are separated. Check if that structure is stable—especially with respect to the task you care about.
- Relevance beyond AI The same idea helps in biology and neuroscience, suggesting geometric stability might be a general sign of robust organization in complex systems.
In short: this paper shows that checking for “what’s there” (similarity) isn’t enough. We also need to check “does it hold together when we nudge it?” (stability). Shesha makes that possible, and the results show it helps us build, choose, and monitor models—and even understand living systems—more safely and effectively.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of unresolved issues, uncertainties, and missing explorations that future research could address to strengthen and extend the paper’s claims.
- Theoretical characterization of Shesha: derive formal invariances, bounds, and closed-form relationships to the eigenspectrum (e.g., how Shesha scales with eigenvalue distribution, anisotropy, and manifold curvature), as well as its expected value under random geometries.
- Sample complexity and estimator bias: quantify the number of samples/features required for reliable Shesha estimation; analyze finite-sample bias, variance, and confidence interval calibration for split-half RDM correlations.
- Sensitivity to RDM specification: systematically evaluate how Shesha depends on the choice of distance metric (e.g., Euclidean, cosine, Mahalanobis), rank vs. Pearson/Spearman correlation, normalization, and whitening; provide best-practice guidelines.
- Impact of preprocessing pipelines: characterize how common operations (centering, scaling, whitening, normalization, spectrum equalization) affect Shesha compared to CKA/PWCCA/Procrustes, including conditions where whitening artificially alters conclusions.
- Split strategy design: provide principled criteria for choosing Feature-Split vs. Sample-Split vs. Supervised splits; quantify the trade-offs and failure modes of each (e.g., feature redundancy, class imbalance, label noise, domain shift).
- Layerwise and intra-model analyses: extend beyond penultimate embeddings to systematically map stability across layers, heads, and modules; characterize layerwise stability profiles and their relation to task performance and drift.
- Token-level and local geometry: develop methods for fine-grained, token-level or region-level stability (local RDMs, neighborhood stability), and assess whether global RDM-based Shesha misses critical microstructure relevant to control or safety.
- Scaling laws: investigate how Shesha scales with parameter count, training time, dataset size, and alignment strength (e.g., RLHF intensity), including larger models (>7B) and cross-family comparisons.
- Stability vs. transferability causality: determine whether the observed “geometric tax” is causal; perform controlled interventions to test if optimizing transfer (e.g., via DINOv2 objectives) necessarily degrades stability or if joint optimization is possible.
- Stability-aware training: develop and evaluate training objectives or regularizers that explicitly optimize geometric stability; measure trade-offs with transferability, accuracy, and robustness across domains.
- Adversarial robustness: test whether high Shesha correlates with adversarial robustness (and under which threat models); quantify stability changes under adversarial perturbations versus random noise.
- OOD generalization: assess whether Shesha predicts out-of-distribution performance and robustness to domain shift beyond drift detection; disentangle data shift vs. representation drift effects.
- Thresholding and monitoring policies: provide principled approaches for setting detection thresholds (e.g., ROC operating points, cost-sensitive criteria) for production safety monitoring; quantify latency, false alarm cost, and intervention utility.
- Real-time and low-cost estimation: devise efficient or streaming approximations (sketching, sub-sampling, incremental RDM updates) to reduce Shesha’s computational overhead without sacrificing sensitivity/specificity.
- Steerability generalization: test Shesha’s predictive power for non-linear, multi-vector, or constrained steering methods; extend beyond sentiment/NLI to diverse tasks (reasoning, factuality, multilingual) and to generative LMs.
- Dependence on steering vector estimation: evaluate whether predictive relationships hold when steering directions are estimated via different methods (e.g., SVM, contrastive loss, causal discovery) and under label noise or class imbalance.
- Vision domain scope: broaden datasets (e.g., dense prediction, detection, segmentation, medical imaging) to test whether the stability–transferability dissociation persists beyond classification and fine-grained recognition.
- Protein domain anomaly: investigate why Protein encoders show moderate negative correlation (ρ ≈ −0.36); disentangle dimensionality constraints, PCA interactions, and encoder-specific properties; propose corrective protocols.
- CRISPR generalization: extend to time-course data, multi-omic embeddings, lineage-tracing, batch-effect correction, and non-linear embeddings (e.g., VAE/contrastive); relate high Shesha to mechanistic regulatory network properties.
- Neuroscience breadth: replicate across tasks, species, timescales, and brain states; test causal relationships via perturbations; relate Shesha to decoding accuracy, learning, plasticity, and stability–flexibility trade-offs in neural circuits.
- Compare to reliability metrics: benchmark Shesha against classical reliability indices (e.g., Cronbach’s alpha, ICC), Mantel tests, distance correlation, and noise ceiling variants to confirm unique utility and conditions of superiority.
- Domain-specific calibration: establish normative ranges and interpretability (what constitutes “high” vs. “low” stability) per domain; provide standardized reporting practices and reference datasets for calibration.
- Confounding by model families: further control for architecture/training family effects (beyond mixed-effects models) to separate intrinsic stability from family-specific design choices; test cross-family generalization.
- Robustness to class structure: quantify how class count, granularity, imbalance, and label quality affect supervised Shesha; define protocols to avoid conflating separability with stability in real-world tasks.
- Actionability of early warnings: link detected representational drift to concrete remediation (e.g., re-alignment, data augmentation, guardrails); show end-to-end pipelines where Shesha-triggered interventions prevent failures.
Glossary
- AUC: Area Under the ROC Curve; a scalar summary of classifier performance across thresholds. "Shesha achieves the highest performance (AUC = 0.990) compared to Procrustes (AUC = 0.988) and CKA (AUC = 0.987)."
- anisotropy: Directional imbalance of variance in embedding space that can affect geometric measures. "The geometric metrics we tested included Shesha, both supervised and unsupervised, Fisher discriminant, silhouette score, Procrustes alignment, and anisotropy (Appendix~\ref{app:steering})."
- Centered Kernel Alignment (CKA): A representation similarity metric based on centered kernels that compares spaces up to orthogonal transformations. "Standard tools like Representational Similarity Analysis (RSA) \citep{Kriegeskorte2008} and Centered Kernel Alignment (CKA) \citep{kornblith2019similarity} have become the default for comparing representations between architectures, training runs, and domains."
- contrastive alignment: Training/representation objective that aligns paired examples by contrasting positives against negatives. "Two factors consistently predicted geometric stability: contrastive alignment and hierarchical architecture."
- CRISPR: Genome editing system used to perturb cellular regulation and assess transcriptional effects. "Beyond machine learning, stability predicts CRISPR perturbation coherence and neural-behavioral coupling."
- effective-rank PWCKA: A PWCCA-based similarity estimate adjusted by effective rank to account for spectrum distribution. "To verify that distinctness generalizes beyond CKA, we evaluated two alternative similarity metrics in the Language domain (): effective-rank PWCKA (, ) and Procrustes similarity (, )."
- eigenspectrum: The set of eigenvalues of a representation’s covariance/Gram matrix, reflecting variance distribution across components. "These results demonstrate that Shesha captures geometric structure distributed across the eigenspectrum that similarity metrics ignore entirely."
- Fisher discriminant: A separability measure that maximizes between-class variance while minimizing within-class variance. "The geometric metrics we tested included Shesha, both supervised and unsupervised, Fisher discriminant, silhouette score, Procrustes alignment, and anisotropy (Appendix~\ref{app:steering})."
- Frobenius residual: The alignment error measured by the Frobenius norm in Procrustes analysis. "While Procrustes is invariant to rotations, reflections, and global scaling by construction, it minimizes the Frobenius residual across the full spectrum."
- geometric stability: The reliability with which a model’s representational geometry is preserved under perturbations or resampling. "We introduce geometric stability, a distinct dimension that quantifies how reliably representational geometry holds under perturbation, and present Shesha, a framework for measuring it."
- Intraclass Correlation Coefficient (ICC): Reliability statistic quantifying the proportion of variance attributable to group-level effects. "The Intraclass Correlation Coefficient (ICC = 0.10) indicates that base model identity explains less than 10\% of variance in stability scores, with the remaining 90\% attributable to encoder-specific properties and residual variation."
- Johnson-Lindenstrauss lemma: A result guaranteeing approximate preservation of pairwise distances under random projections in high dimensions. "In contrast, geometry-preserving transformations, such as random projections, maintain both metrics (), consistent with the Johnson-Lindenstrauss lemma~\citep{Johnson1984, Dasgupta2002}."
- Linear Mixed-Effects Model: A statistical model combining fixed and random effects to account for grouped data structures. "To strictly control for dependencies among encoder configurations (e.g., multiple perturbed versions of ResNet50), we fitted a Linear Mixed-Effects Model (Stability Similarity (1 BaseModel))."
- linear steerability: The degree to which targeted linear directions added to activations produce controllable changes in model behavior. "for controllability, supervised stability predicts linear steerability (-$0.96$);"
- LogME: A transferability metric estimating how well pre-trained features support downstream tasks. "Transfer learning metrics like LogME~\citep{you2021logme} estimate how well pretrained features support downstream tasks."
- LoRA: Low-Rank Adaptation; parameter-efficient fine-tuning via low-rank updates to model weights. "Experiment 2 (Structured Perturbations) applied Gaussian noise (), quantization (INT8, INT4), and LoRA modifications to 16 causal LMs to characterize metric response curves."
- Mahalanobis-whitened distances: Distances computed after whitening by the inverse covariance, normalizing for feature scale and correlations. "To rule out the possibility that the results were artifacts of distance metric choice, we compared three approaches: Euclidean distance in PCA space, Mahalanobis-whitened distances, and k-nearest neighbor matched controls."
- manifold hypothesis: The idea that high-dimensional data lie near low-dimensional manifolds, shaping representation geometry. "Real-world encoders occupy this intermediate regime, consistent with the manifold hypothesis~\citep{Bengio2013}, where both metrics offer complementary diagnostic value."
- Neuropixels: High-density electrophysiology probes/datasets used for large-scale neural recordings. "We tested whether geometric stability captures functionally relevant structure in neural population dynamics using the Neuropixels decision-making dataset~\citep{steinmetz2019distributed}."
- noise ceiling estimation: A technique estimating the upper bound of explainable variance to contextualize representational comparisons. "Our split-half approach adapts the statistical technique of noise ceiling estimation~\citep{Nili2014}, but generalizes it for an alternate purpose: rather than bounding explainable variance to normalize cross-system comparisons, we treat internal consistency itself as the subject of interest."
- permutation null model: A randomized baseline generated by permuting labels or assignments to assess statistical significance. "We additionally computed temporal drift-stability as cosine similarity between early and late trial centroids, validated against a permutation null model (Appendix~\ref{app:neuroscience})."
- Procrustes: A rigid alignment metric comparing shapes under rotation/reflection/scaling; used to assess representation similarity. "In instruction tuning, geometric stability detects structural drift nearly 2 more sensitively than CKA on average ... while avoiding false alarms of rigid distance metrics such as Procrustes (; Section~\ref{sec:drift})."
- PWCCA: Projection Weighted Canonical Correlation Analysis; a similarity measure emphasizing principal correlated directions between representations. "spectral deletion experiments revealed that all similarity metrics (debiased CKA, PWCCA, Procrustes) collapsed below 0.4 after removing just the top principal component, while Shesha remained above 0.4 until components were removed (Figure~\ref{fig:distinct-main}a)."
- quantization (INT8, INT4): Reducing numeric precision of parameters/activations to fixed-width integers to compress or accelerate models. "Experiment 2 (Structured Perturbations) applied Gaussian noise (), quantization (INT8, INT4), and LoRA modifications to 16 causal LMs to characterize metric response curves."
- Representational Dissimilarity Matrices (RDMs): Matrices of pairwise dissimilarities among stimuli/inputs used to characterize representation geometry. "Shesha operates on Representational Dissimilarity Matrices (RDMs) from RSA~\citep{Kriegeskorte2008}, assessing the consistency of RDMs derived from perturbed or resampled views of the same representation rather than comparing across systems (Appendix~\ref{app:shesha-metric-defintion})."
- Representational Similarity Analysis (RSA): A method comparing representational structures via dissimilarity patterns across stimuli. "Standard tools like Representational Similarity Analysis (RSA) \citep{Kriegeskorte2008} and Centered Kernel Alignment (CKA) \citep{kornblith2019similarity} have become the default for comparing representations between architectures, training runs, and domains."
- RLHF-aligned models: Models tuned via Reinforcement Learning from Human Feedback to align outputs with human preferences. "In modern RLHF-aligned models (e.g., Llama), instruction tuning results in 5.23 greater geometric drift in Shesha than in CKA (34.0\% vs 6.5\%)."
- self-distillation objective: Training objective where a model or its variants distill knowledge into itself to improve features. "This suggests that DINOv2's self-distillation objective may be uniquely suited to satellite imagery geometry."
- Shesha: The proposed framework that measures geometric stability via internal self-consistency of representational geometry. "We introduce Shesha, named for the Hindu deity representing the invariant remainder of the cosmos~\citep{vogel1926indian, danielou1964hindu, dimmitt1978classical}, a framework for measuring geometric stability through self-consistency."
- silhouette score: A clustering quality index contrasting intra-cluster cohesion with inter-cluster separation. "The geometric metrics we tested included Shesha, both supervised and unsupervised, Fisher discriminant, silhouette score, Procrustes alignment, and anisotropy (Appendix~\ref{app:steering})."
- split-half approach: Reliability method correlating metrics computed on disjoint halves (features or samples) of the data. "Shesha was measured as split-half correlation of representational dissimilarity matrices."
- spectral deletion experiments: Analyses that remove top principal components to test metric sensitivity to dominant variance vs. tail structure. "spectral deletion experiments revealed that all similarity metrics (debiased CKA, PWCCA, Procrustes) collapsed below 0.4 after removing just the top principal component, while Shesha remained above 0.4 until components were removed (Figure~\ref{fig:distinct-main}a)."
- spectral tail: The low-variance end of the eigenspectrum containing fine-grained geometric information. "Shesha retained sensitivity to fine-grained manifold structure distributed across the spectral tail."
- whitening: A transformation that equalizes variances and removes correlations by rescaling with covariance, often to normalize spectra. "This divergence held across preprocessing conditions, though whitening caused CKA to recover by artificially equalizing the spectrum."
Practical Applications
Immediate Applications
The following applications can be deployed with the paper’s released tools and documented procedures, offering concrete workflows across sectors.
- Bold: Production AI “Geometric Canary” for drift monitoring
- Sector: Software, MLOps, safety
- What to do: Integrate Shesha (feature-split for unsupervised, sample-/supervised-split when labels exist) into model-monitoring to quantify representational drift during fine-tuning, instruction-tuning, quantization, and LoRA updates; set thresholds using ROC results and bootstrap confidence intervals; pair Shesha with CKA for confirmation and avoid overreliance on Procrustes to minimize false alarms.
- Tools/workflows: pip install shesha-geometry; compute RDMs on perturbed/resampled batches; alert when stability drops beyond calibrated thresholds; log per-family baselines; schedule periodic checks after deployments.
- Assumptions/dependencies: Requires multiple forward passes and access to representative data slices; thresholds must be calibrated per model family; computational overhead is higher than single-pass similarity metrics.
- Bold: Steerability diagnostics for linear activation interventions
- Sector: Software (LLMs, embedding services), safety alignment
- What to do: Use supervised Shesha to predict whether models accept linear steering vectors (e.g., for sentiment or NLI tasks); gate interventions (apply only to high-stability models) to avoid brittle behavior; triage models for downstream control.
- Tools/workflows: Fit steering directions via logistic regression; compute Supervised Shesha on held-out data; build a “steerability dashboard” that ranks models by supervised stability; integrate partial correlation checks to separate stability from mere separability (Fisher, silhouette).
- Assumptions/dependencies: Requires task-aligned labels for supervised variants; linear steerability assumption holds for the intervention; unsupervised stability is insufficient for semantic tasks.
- Bold: Model selection for safety-critical vs. transfer-heavy use
- Sector: Vision, software product selection
- What to do: Combine Shesha with transfer metrics (e.g., LogME) to decide between models that optimize consistency versus adaptability; prefer CLIP/EVA-02/Swin for zero-shot or safety-critical deployments; prefer DINOv2/ResNets for transfer pipelines knowing the “geometric tax.”
- Tools/workflows: Add Shesha to standard evaluation suites; benchmark per dataset complexity (CIFAR-10/100, Flowers-102, Oxford Pets, DTD, EuroSAT); document domain-specific rankings in model cards.
- Assumptions/dependencies: Trade-off intensifies with fine-grained tasks; rankings generalize within but not across domains; architecture families influence stability.
- Bold: Embedding pipeline QA for feature transformations
- Sector: Data engineering, feature engineering
- What to do: Audit PCA or other compression choices with Shesha to avoid collapsing manifold geometry; prefer geometry-preserving transforms (e.g., random projections) when possible.
- Tools/workflows: Run regime analyses (PCA ranks vs. random projections vs. feature selection); set allowable compression thresholds where Shesha remains above acceptable levels; annotate ETL steps with stability reports.
- Assumptions/dependencies: Some compression may be acceptable for downstream tasks; Johnson–Lindenstrauss-style projections preserve pairwise distances better for stability.
- Bold: Retrieval/RAG embedding quality assessment
- Sector: Software (search, vector databases, RAG)
- What to do: Assess stability under paraphrases/resampling to select embeddings with reliable geometric structure for retrieval; prioritize models with high sample-split and supervised Shesha for QA or task-specific RAG.
- Tools/workflows: Sample-Split Shesha on paraphrase corpora; supervised variant for task-bound retrieval (e.g., sentiment QA datasets); incorporate stability as a pre-deployment gate alongside recall/precision.
- Assumptions/dependencies: Stability complements but doesn’t replace task metrics; benefits are strongest when retrieval is sensitive to fine-grained manifold structure.
- Bold: Governance and compliance audits with stability scores
- Sector: Policy, risk management, trust & safety
- What to do: Include Shesha-based stability metrics in model cards and internal audit reports; mandate drift checks during instruction tuning or deployment updates; use Shesha as primary signal with CKA confirmation to reduce false-positive fatigue.
- Tools/workflows: Standardized reporting protocols; pre-defined sensitivity/specificity operating points; periodic audit cycles after major releases.
- Assumptions/dependencies: Requires institutional buy-in and metric standardization; will need sector-specific thresholds and documentation templates.
- Bold: CRISPR screen prioritization via perturbation coherence
- Sector: Healthcare, bioinformatics
- What to do: Rank perturbations by Shesha to identify reproducible regulatory shifts; prioritize combinatorial guides with high stability; distinguish pleiotropic regulators (high magnitude, low stability) from specific ones (high stability).
- Tools/workflows: Compute RDMs in PCA-whitened or Euclidean spaces; run Shesha across perturbations; integrate with Scanpy pipelines; control for sample size and intrinsic variance via mixed-effects models.
- Assumptions/dependencies: Data quality and SNR affect magnitudes; Shesha is robust to sample size but still needs adequate cell counts; dimensionality choices (10–100 PCs) should be standardized.
- Bold: Neuroscience lab analysis of region-specific stability
- Sector: Neuroscience research, neurotech
- What to do: Use Shesha to map stability hierarchies across brain areas and sessions; relate representational stability to behavioral coupling; track drift without relying on centroid measures.
- Tools/workflows: Compute split-half RDMs during relevant task epochs; correlate stability with trial-by-trial behavioral metrics; report area-by-area profiles (e.g., Striatum high stability, Hippocampus low).
- Assumptions/dependencies: Preprocessed population responses are needed; effects may be task- and epoch-specific; Shesha complements but does not replace classical temporal consistency measures.
- Bold: A/B guardrails for AI features
- Sector: Product engineering
- What to do: Add stability checks to A/B rollout pipelines to catch latent geometric fractures before metric regressions; halt rollouts when stability drops beyond thresholds even if KPI changes are not yet visible.
- Tools/workflows: Batch perturbation tests on canary cohorts; Shesha-triggered rollback policies; dashboards combining stability and functional KPIs.
- Assumptions/dependencies: Requires representative traffic and controlled perturbation strategies; cost consideration for extra inference passes.
Long-Term Applications
These applications require additional research, scaling, or engineering to mature into robust products or standards.
- Bold: Stability-aware training objectives and regularizers
- Sector: Machine learning, foundation models
- Vision: Design differentiable proxies for Shesha to regularize training against spectral tail collapse; explicitly optimize manifold rigidity alongside task performance to balance the stability–transferability trade-off.
- Potential products: “Stable Embedding” SKUs; training plugins that maximize stability under data perturbations.
- Assumptions/dependencies: Need tractable loss surrogates for rank-based correlations; potential computational overhead; risk of over-regularization on tasks requiring adaptability.
- Bold: Real-time and streaming Shesha for production systems
- Sector: MLOps, model observability
- Vision: Develop online approximations (sketching/incremental RDM updates, randomized feature splits) to compute stability in near-real-time for large-scale services.
- Potential products: Stability APM (Application Performance Monitoring) modules; edge/server instrumentation with low-latency alerts.
- Assumptions/dependencies: Algorithmic advances in scalable RDM estimation; careful calibration to avoid drift false positives under high traffic variability.
- Bold: Stability-gated agent safety and tool-use
- Sector: Safety alignment, autonomous systems
- Vision: Gate agent actions (tool calls, external API access) based on supervised stability aligned to safety tasks; disallow interventions when representational geometry is unstable or misaligned.
- Potential products: Safety controllers that monitor Shesha in the control loop; policy engines that enforce geometry-based guardrails.
- Assumptions/dependencies: Reliable supervised labels for safety-critical tasks; latency constraints for online decision-making; validation against adversarial distribution shifts.
- Bold: Stability benchmarks and standards (NIST/ISO-like)
- Sector: Policy, industry standards, academic benchmarking
- Vision: Establish cross-domain stability leaderboards and certification protocols; require stability reporting alongside similarity and task metrics for commercial model releases.
- Potential products: Stability test suites and reference datasets; compliance audits integrated in procurement.
- Assumptions/dependencies: Community consensus on protocols and thresholds; domain-specific benchmarks; governance structures for updates.
- Bold: Robotics and autonomous perception monitoring
- Sector: Robotics, automotive
- Vision: Use sample-split Shesha to ensure perception modules maintain manifold geometry under environmental perturbations (lighting, weather, sensor noise); preempt behavior failures by triggering re-calibration or fallback modes.
- Potential products: Perception health monitors; geometry-based redundancy checks during operation.
- Assumptions/dependencies: Robust perturbation models; computational budgets on embedded hardware; integration with safety-certified stacks.
- Bold: Healthcare diagnostics from high-dimensional biosignals
- Sector: Healthcare, precision medicine
- Vision: Track patient state coherence (single-cell omics, EEG/MEG, EHR embeddings) via Shesha to detect early transitions into pathological regimes or therapy response trajectories.
- Potential products: Clinical decision support tools that flag low-stability states; research platforms for treatment stratification.
- Assumptions/dependencies: Regulatory approval and validation; robust pipelines for clinical-grade data; ethical handling of sensitive signals.
- Bold: Finance model risk monitoring for NLP embeddings
- Sector: Finance
- Vision: Apply Shesha to detect subtle embedding drift in news, filings, or social sentiment models to avoid false positives and missed risk signals; calibrate alarms to market regimes.
- Potential products: Stability-driven risk dashboards; audit trails for regulatory compliance.
- Assumptions/dependencies: Domain adaptation to rapidly shifting corpora; mapping stability changes to risk tolerances; secure data handling.
- Bold: Stability-informed RAG pipelines and index maintenance
- Sector: Software (LLM applications)
- Vision: Use stability metrics to drive re-indexing schedules, embedding refresh policies, and model swaps in RAG systems; maintain consistent retrieval quality under content churn.
- Potential products: RAG orchestration services with geometry-health indicators; automated index calibration tools.
- Assumptions/dependencies: Efficient batch perturbation strategies; coupling between stability and retrieval KPIs validated per domain.
- Bold: Cross-modal education and research curricula
- Sector: Academia, education
- Vision: Formalize geometric stability as a core axis of representation analysis; include lab assignments on distinctness from similarity, spectral effects, and regime analysis; build shared codebases and datasets for teaching.
- Potential products: Course modules, practical labs with shesha-geometry; community repositories with benchmarks and tutorials.
- Assumptions/dependencies: Ongoing maintenance of open-source tools; institutional adoption; coordination across disciplines.
In all cases, Shesha’s measurement assumptions (split-half RDM consistency, multiple passes, domain-specific thresholding) and task alignment (supervised vs. unsupervised variants) are central dependencies. Stability complements similarity: use both to obtain a full picture of what is represented and how reliably that geometry can be used under perturbations.
Collections
Sign up for free to add this paper to one or more collections.