Spectral Superposition: A Theory of Feature Geometry
Abstract: Neural networks represent more features than they have dimensions via superposition, forcing features to share representational space. Current methods decompose activations into sparse linear features but discard geometric structure. We develop a theory for studying the geometric structre of features by analyzing the spectra (eigenvalues, eigenspaces, etc.) of weight derived matrices. In particular, we introduce the frame operator $F = WW\top$, which gives us a spectral measure that describes how each feature allocates norm across eigenspaces. While previous tools could describe the pairwise interactions between features, spectral methods capture the global geometry (``how do all features interact?''). In toy models of superposition, we use this theory to prove that capacity saturation forces spectral localization: features collapse onto single eigenspaces, organize into tight frames, and admit discrete classification via association schemes, classifying all geometries from prior work (simplices, polygons, antiprisms). The spectral measure formalism applies to arbitrary weight matrices, enabling diagnosis of feature localization beyond toy settings. These results point toward a broader program: applying operator theory to interpretability.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper studies how neural networks squeeze lots of ideas (called “features”) into a limited number of directions in their internal space. When a network holds more features than it has space for, those features have to share space. The authors call this “superposition,” and it can make features bump into each other and interfere. The paper introduces a new way to understand the overall shape and organization of these shared features using “spectral” tools—basically, looking at how the network’s weights split its space into independent “rooms” where interactions happen.
Key Questions
The paper asks three simple questions:
- How do many features fit and interact inside a small space without stepping on each other too much?
- Can we describe the big-picture geometry of all features at once, not just how one pair of features interacts?
- Does training naturally push features into clean, organized shapes, and can we predict those shapes?
Methods and Approach
Think of the network’s internal space like a building with many rooms. Features are like people trying to share those rooms. If too many people fit into too few rooms, some people share rooms and start interfering.
The paper uses “spectral” methods to study this. In everyday terms:
- An “eigenspace” is like a room where certain kinds of motion or activity happen independently from other rooms. If two features live in different rooms, they don’t interfere.
- The “Gram matrix” (
M = W^T W) describes how features relate to each other by pairwise comparisons. It depends on how you label or order features, which can be confusing. - The “frame operator” (
F = W W^T) lives in the network’s activation space (the building itself) and does not change when you rename or reorder features. It’s the right tool to see the building’s rooms. - A “spectral measure” is a small summary for each feature that tells you how much of that feature lives in each room. If a feature’s spectral measure says “100% in room A,” we say it is “localized” there and won’t interfere with features in other rooms.
The authors also analyze a simple, controlled setup called Toy Models of Superposition (TMS). In these toy models, they can inspect exactly how features pack together and compare the theory to experiments.
Main Findings
Here are the main discoveries, explained simply:
- Capacity saturation: When the model uses almost all of its available space, it reaches a “full” state. In this state, the paper proves that features stop spreading across many rooms and instead “localize” into a single room (eigenspace). That means each feature chooses one room to live in.
- Organized geometry: Once features localize, they arrange themselves in neat, symmetric shapes inside their rooms. These shapes are things like triangles, polygons, and antiprisms—simple geometric patterns that make interactions predictable.
- Tight frames: Within each room, features form “tight frames,” which you can think of as evenly spaced points that share the room fairly and efficiently. This creates a clean, balanced structure.
- Global structure, not just pairs: Earlier tools focused on how one feature interacts with another (pairwise). The spectral approach reveals the whole layout—who lives in which room, how rooms combine, and the overall geometry of all features.
- Projective linearity: In the saturated state, a feature’s “footprint” in the model (its effective dimensionality) becomes directly proportional to its size and the scale of the room it sits in. This makes feature behavior more predictable.
- Training dynamics: The way the model learns (gradient descent) naturally pushes features into these rooms and stable geometric shapes. So the neat structures aren’t accidents—they’re consequences of how learning and the model’s spectrum work together.
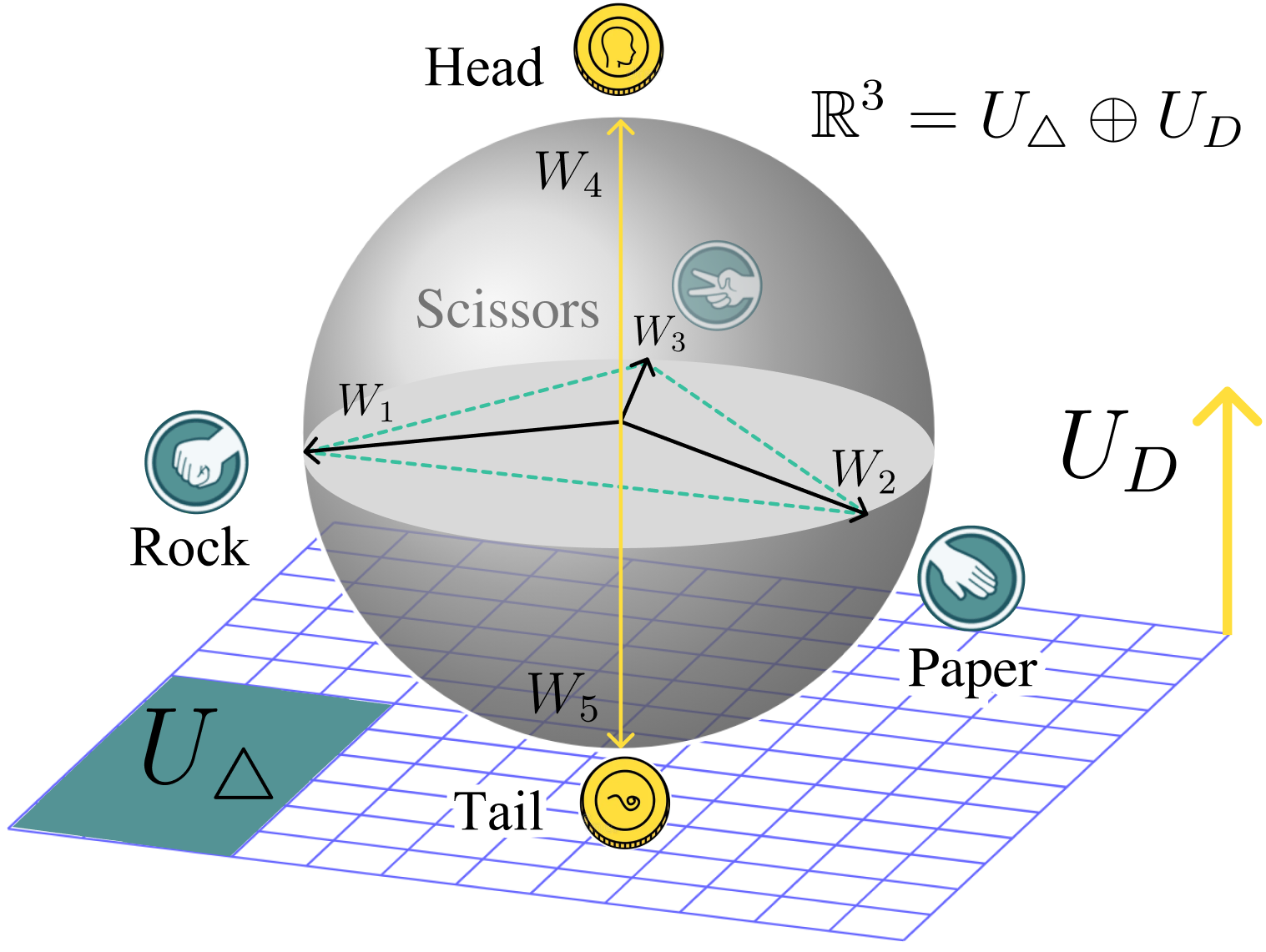
To make this concrete, the paper uses a simple example with five features: rock, paper, scissors, heads, and tails. The rock-paper-scissors features form a triangle in one room (they’re related and interfere with each other), while heads and tails form a line in another room (they interfere with each other but not with rock-paper-scissors). The spectral tools recover this shared geometry even if you shuffle feature labels, because they look at the building’s rooms, not the names on the doors.
Why It Matters
- Better interpretability: Understanding which features share rooms and how they’re arranged helps us make sense of what a network “knows.” It’s not just a bag of features—it’s an organized structure.
- Safer and more effective steering: If you try to push a model to think more about one concept (like “helpfulness”), you might accidentally push other concepts. Knowing the room layout helps you steer the model without unintended side effects.
- Diagnosing interference: The spectral measure tells you which features actually interfere. If two features live in different rooms, they can’t bump into each other.
- General tools: The methods work on any weight matrix, not just toy models, so they can be used to study real networks.
Implications and Impact
This paper points toward a broader program: using operator theory (spectral tools) to understand and guide neural networks. The big idea is that features don’t just exist alone—they live together in rooms with specific geometric patterns. Training naturally builds these patterns, especially when the network runs near full capacity. If we can map these rooms and shapes, we can:
- Predict how features will evolve during training.
- Identify stable structures the model will converge to.
- Design interpretability and editing tools that respect the model’s geometry, reducing interference and unexpected behavior.
In short, the paper provides a clean, math-backed way to see the hidden “architecture” of how concepts are stored and interact inside neural networks, making them easier to understand and control.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of what remains missing, uncertain, or unexplored in the paper. Each item is phrased to enable concrete follow-up by future researchers.
Theoretical assumptions and scope
- Formal conditions for capacity saturation: The spectral localization theorem hinges on exact saturation . Specify sufficient conditions under which real networks (beyond toy autoencoders) provably reach or approximate this bound, and derive stability bounds for “near-saturation” regimes.
- Robustness of localization: Quantify how localization degrades when falls short of , including perturbation bounds relating deviations from saturation to spread in the per-feature spectral measures .
- Eigenvalue multiplicities: Address non-uniqueness of eigenspaces when has repeated eigenvalues. Provide methods to resolve basis ambiguity inside degenerate eigenspaces and assess how it affects feature assignment and geometry identification.
- Nonlinearities beyond ReLU: Extend the operator-theoretic results to other nonlinearities (e.g., GELU, sigmoid), and clarify which components of the framework rely on homogeneity or piecewise-linearity.
- Multi-layer composition: Generalize the spectral bridge and per-feature measure from single-layer to deep compositions, cross-layer coupling, and residual connections. Define a principled way to aggregate or propagate spectral measures across layers.
- Bias terms and normalization: Incorporate biases and common training-time normalizations (LayerNorm, WeightNorm, BatchNorm) into the operator model, and analyze their effects on , , and localization.
- Approximate symmetry and association schemes: The classification via association schemes assumes strong symmetry. Develop a theory for approximate schemes (noisy group actions, nearly commuting algebras) and provide criteria to detect “near-symmetric” feature clusters.
- Fractional dimensionality outside basis-input regimes: The formula is derived assuming features align with input basis axes. Provide a general definition and estimator for when features are learned, distributed, or multi-sparse (as hinted at in the paper’s comment), and connect it to without relying on basis assumptions.
Methods and measurement
- Practical recovery of spectral measures: Computing projectors at scale is costly. Develop scalable approximations (e.g., randomized eigenspace sketches, Nyström methods) to estimate and with error guarantees.
- Per-feature localization metrics: Move beyond the “mean max spectral mass” metric to a rigorous set of localization indices (e.g., entropy over , Rényi measures, Gini coefficients) with thresholds for classifying localized vs. delocalized features.
- Geometry identification pipeline: Specify an end-to-end algorithm to recover discrete geometries (simplices, polygons, antiprisms) from alone, including decision rules, model selection, and uncertainty quantification. Clarify what “additional spectral signature” is required and how it is obtained.
- Handling degenerate or overlapping clusters: Provide procedures for disentangling overlapping spectral supports (features partially localized in multiple modes), including clustering and deconvolution in the presence of noise.
Training dynamics
- Explicit dynamical equations: The paper asserts that gradient descent can be recast as spectral evolution (eigenvalue drift, mass transport). Derive and validate the governing differential equations for and under realistic optimizers (SGD, Adam) and regularizers.
- Stability analysis of tight frames: Prove conditions under which tight-frame configurations are stable fixed points of training dynamics, and characterize their basins of attraction across sparsity–capacity regimes.
- Generalization across regimes: Identify phase transitions between weakly interacting, self-organizing, and rank-collapsed regimes (as sketched in the deprecated abstract). Provide empirical phase diagrams and theoretical boundaries in terms of , , and .
- Role of regularization: Analyze how explicit regularizers (weight decay, spectral penalties) influence localization and geometry formation, and whether they can steer models toward desired association schemes.
Empirical validation
- Completeness of experimental results: The reported sweep (3,200 runs) lacks full details (optimizer, learning rate schedules, initialization, stopping criteria, confidence intervals). Provide comprehensive protocols and statistical analyses across seeds.
- Projective linearity evidence: The projective linearity section is incomplete. Supply full plots, regression diagnostics, failure cases, and robustness checks linking to localization strength.
- Non-uniform sparsity and importance: The paper defers non-uniform settings to the appendix. Present main-text results showing how heterogeneous and affect localization, geometry types, and training dynamics.
- Beyond toy models: Demonstrate the framework on real networks (e.g., transformer MLPs, CNN bottlenecks), including case studies that compute , estimate , and recover meaningful geometries. Contrast with SAE-derived features to substantiate claims that SAEs discard geometry.
Generalization and applications
- Distinguishing structural vs. incidental interference: Operationalize criteria to separate geometry-inducing (structural) from compression-driven (incidental) interference using spectral tools and data co-occurrence statistics. Propose diagnostics and interventions for each case.
- Heavy-tailed spectra linkage: Clarify how global heavy-tailed empirical spectral densities (HT-SR) relate to per-feature measures . Determine whether heavy tails imply specific geometry types or localization patterns.
- Interpretability interventions: Translate diagnosis to action. Provide methods to steer models by editing or redistributing (e.g., targeted regularization, subspace isolation) and evaluate effects on downstream behavior (steering side effects, alignment).
- Scaling and compute constraints: Address feasibility for large layers (d ~ 104–106). Propose approximate, streaming, or GPU-friendly algorithms to estimate ’s spectra and per-feature measures in production-scale models.
- Cross-layer and task-level geometry: Investigate whether geometries persist or transform across layers and tasks, and how they relate to function (e.g., modular arithmetic, spatial reasoning). Provide benchmarks tying recovered geometry to model competencies.
These gaps outline concrete directions for extending the theory, making the methodology practical at scale, and validating claims in real-world neural networks.
Glossary
- Activation steering: A technique that manipulates model activations to influence behavior along specific concepts or directions. "activation steering methods \citep{steering_base_1, steering_base_2, steering_base_3} often produce unintended side effects"
- Adjacency matrix: A matrix encoding which pairs of indices (nodes) are related under a group action or graph relation. "We can express the group action in terms of adjacency matrices over , each representing the stable orbits"
- Antiprism: A polyhedral geometry with two parallel polygonal faces connected by alternating triangles; here, one of the discrete feature geometries that can arise. "classifying all geometries from prior work (simplices, polygons, antiprisms)."
- Association schemes: Combinatorial structures that partition pairs of indices into regular relations, enabling algebraic and spectral analysis of symmetry. "admit discrete classification via association schemes"
- Bose–Mesner algebra: The commutative algebra spanned by the adjacency matrices of an association scheme, capturing its symmetry-invariant operators. "We will focus on , called the Bose-Mesner algebra."
- Centralizer: The set of matrices that commute with all actions of a given group; here, the symmetry-preserving operators. "it is the centralizer of "
- Character table: A matrix whose entries record eigenvalues (characters) of adjacency operators on invariant subspaces, encoding symmetry spectra. "The entries are the eigenvalue of on , forming a character table ."
- Cyclic group: A group generated by a single element; in the paper, the two-element cycle swapping the digon’s nodes. "This is the cyclic group of two elements , namely the identity and is an element of order $2$, meaning that ."
- Cyclic subspace: The smallest subspace invariant under an operator generated by repeatedly applying it to a vector. "The way to bridge the two is to define the cyclic subspace "
- Dihedral group: The symmetry group of a polygon including rotations and reflections; for a triangle, . "The group that preserves the equilateral triangle is the dihedral group ."
- Dirac mass: A measure concentrated at a single point (eigenvalue), indicating complete localization. "the spectral measure collapses to a single Dirac mass "
- Eigenvalue drift: Movement of eigenvalues during training dynamics as parameters change. "showing how gradient flow induces spectral mass transport and eigenvalue drift"
- Eigenspace: The subspace associated with a specific eigenvalue; the locus where feature interactions occur. "features collapse onto single eigenspaces"
- Empirical Spectral Density (ESD): The empirical distribution of a matrix’s eigenvalues summarizing global capacity allocation. "While the global Empirical Spectral Density \citep{htsr1} describes where capacity exists,"
- F+ (pseudoinverse): The Moore–Penrose pseudoinverse of an operator, used to define leverage and capacity bounds. "Define the leverage scores "
- Frame operator: The activation-space operator F = W W⊤ whose spectrum captures global geometry and interactions. "we introduce the frame operator "
- Fractional dimensionality: A per-feature measure of effective dimension used under superposition to quantify sharing. "the fractional dimensionality , denoting the fraction of features that share dimension, is recoverable from spectral signature."
- Gram matrix: The feature-index-space operator M = W⊤W encoding pairwise inner products between feature directions. "The classic way of studying interference between features is the Gram Matrix "
- Gradient flow: The continuous-time limit of gradient descent describing parameter evolution via differential equations. "showing how gradient flow induces spectral mass transport and eigenvalue drift"
- Intertwining: A relation where one map transports the spectral decomposition of one operator to another, preserving structure. "The spectral bridge...classifies the intertwining of the input space (via the Gram matrix ) and the activation space (via the Frame operator )."
- Leverage scores: Quantities measuring a vector’s influence relative to an operator, here bounding fractional dimensionality. "Define the leverage scores "
- Permutation matrix: A matrix that reorders coordinates; right-multiplying W by it permutes feature indices without changing F. "Scrambling feature indices corresponds to right-multiplying by a permutation matrix "
- Primitive idempotent: A minimal projection (projector) in a spectral decomposition corresponding to a single eigenvalue. "the primitive idempotents of lift to"
- Projector: An idempotent linear operator that projects onto a subspace; used to isolate eigenspaces. "decompose over its spectral projectors "
- Projective Linearity: A linear relation linking fractional dimensionality to feature norm with slope given by inverse eigenvalue. "Projective Linearity test: y-axis represents the coefficient of determination of the linear fit"
- Rayleigh quotient: The quadratic form normalized by vector norm, giving the expected eigenvalue under a spectral measure. " is the Rayleigh quotient of at ."
- Spectral correspondence: The fact that M and F share the same nonzero eigenvalues and aligned eigenspaces via W. "We use the frame operator because of a precise spectral correspondence between and ."
- Spectral decomposition: Writing an operator as a sum of eigenvalues times orthogonal projectors. "Let be the Gram's spectral decomposition"
- Spectral localization: Concentration of a feature entirely in one eigenspace, often under capacity saturation. "capacity saturation forces spectral localization: features collapse onto single eigenspaces"
- Spectral measure: A per-feature probability measure over eigenvalues describing how its norm is distributed across eigenspaces. "we introduce the spectral measure, which describes how a feature's norm distributes across these eigenspaces."
- Sparse autoencoders (SAEs): Models that learn a sparse dictionary of features to disentangle superposed representations. "Sparse autoencoders (SAEs) and related methods attempt to recover a dictionary of features that activate sparsely across inputs"
- Stratum projector: A projector onto a symmetry-defined stratum (invariant subspace) in an association scheme. "The corresponding stratum projectors and serve as a more convenient basis"
- Tight frame: A set of vectors that uniformly cover a subspace so that their frame operator is a scalar multiple of identity. "features collapse onto single eigenspaces, organize into tight frames,"
- Toy Models of Superposition (TMS): Simplified setups used to analyze how many features are packed into fewer dimensions. "The ``Toy Models of Superposition'' (TMS) paper by Anthropic \cite{toymodels} is one of the seminal technical contributions"
Practical Applications
Immediate Applications
The following items can be deployed now to improve interpretability, safety, training, and efficiency by leveraging the paper’s spectral tools (frame operator F = WWᵀ, spectral measures, eigenspace projectors, tight-frame geometry, and capacity-saturation diagnostics).
- Spectral interference audit for trained models (Software/AI Safety/MLOps)
- Use the frame operator to eigendecompose activation space and compute per-feature spectral measures p_{i,e} to identify which features share eigenspaces and thus can interfere.
- Deliverables: “subspace interference map,” localization scores, leverage-saturation gap, and per-feature effective dimensionality D_i.
- Workflow: select layer → compute F and its eigendecomposition → compute p_{i,e} for features (e.g., SAE features, MLP neurons, attention head directions) → visualize clusters and interference risks.
- Dependencies/assumptions: access to weights and feature vectors; scalable eigendecomposition or randomized SVD; feature definitions (e.g., SAE dictionaries) of sufficient quality.
- Eigenspace-aware activation steering and editing (Software/AI Safety/Education)
- Constrain steering vectors and model edits (e.g., ROME-style edits) to the target eigenspace via projectors P_e to reduce collateral side effects.
- Practical outcome: fewer unintended behaviors when steering concepts; safer topic steering for chatbots and tutoring systems.
- Dependencies/assumptions: identification of the target eigenspace for the concept of interest; stability of eigenspaces across inputs; added compute for projection.
- Regularizers for fine-tuning that reduce harmful superposition (Software)
- Add penalties for cross-eigenspace mass (encourage spectral localization) or promote tight-frame structure within eigenspaces to improve capacity usage and reduce interference.
- Practical outcome: more robust fine-tuned models with fewer entangled features, potentially better controllability.
- Dependencies/assumptions: careful hyperparameter tuning; validation beyond toy settings; potential trade-offs with task performance.
- Feature clustering for SAE dictionaries by eigenspace (Interpretability)
- Post-process SAE features by grouping them through spectral measures to reveal functional subspaces (e.g., days-of-week, number cycles, coding tokens).
- Practical outcome: clearer dashboards that show collective geometry and “backup” features within the same eigenspace.
- Dependencies/assumptions: SAE reconstruction quality; moderate compute to map many features to eigenmodes.
- Targeted model compression and pruning by spectral salience (Software/Edge)
- Prune low-importance eigenspaces or perform per-eigenspace low-rank factorization that preserves high-λ modes and tight frames.
- Practical outcome: structured pruning with less accuracy loss than unstructured pruning at equal sparsity.
- Dependencies/assumptions: correlation between spectral salience and downstream utility must be verified per task; compute for spectral analysis.
- Training and deployment monitoring with spectral metrics (MLOps)
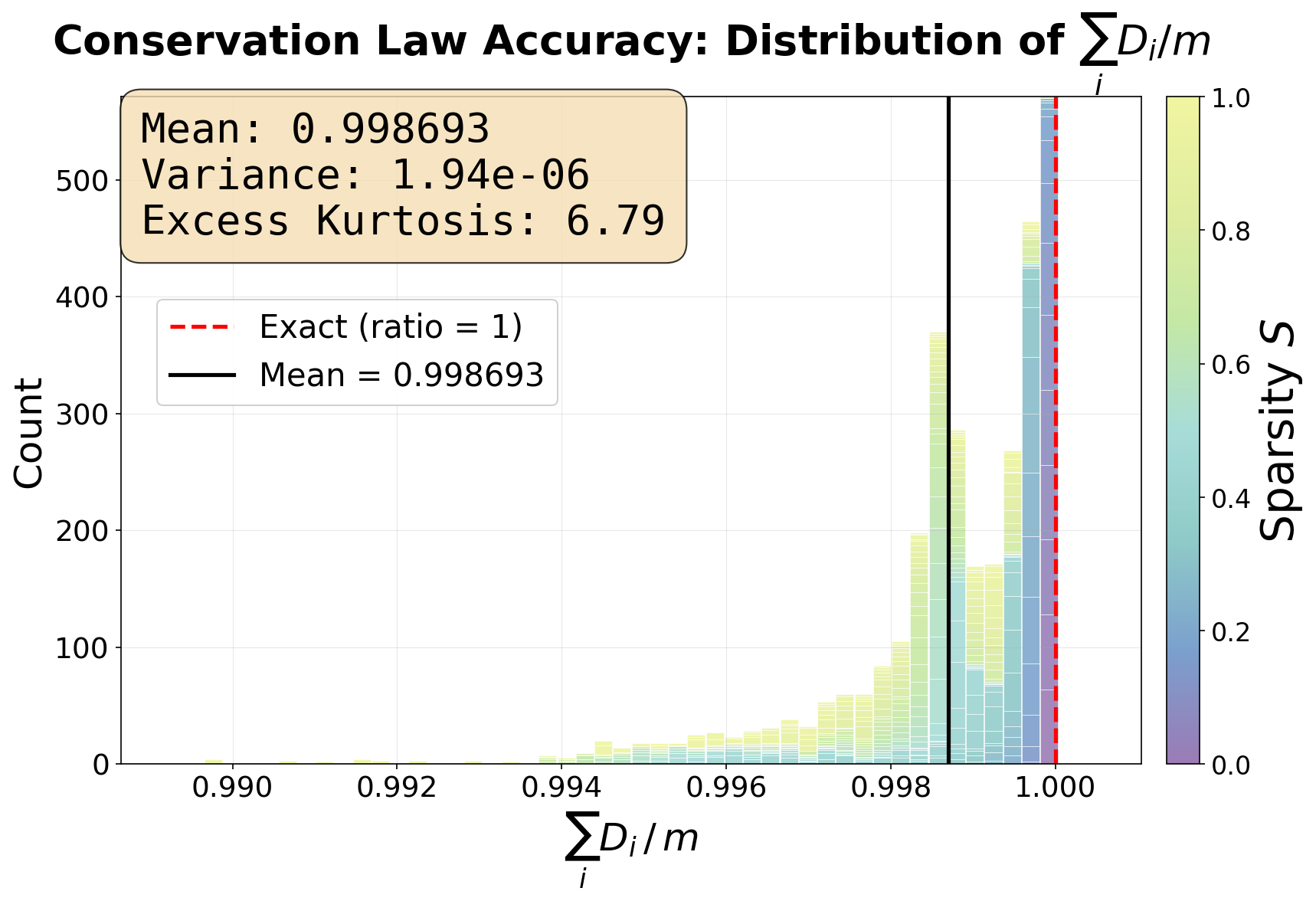
- Track spectral localization, leverage-saturation gap (∑D_i vs. rank), and projective linearity R² during training to detect emerging entanglement or drift.
- Practical outcome: early-warning signals for over-entanglement, regressions, or capacity misallocation.
- Dependencies/assumptions: periodic eigendecompositions; thresholds calibrated to model and layer.
- Transfer learning via subspace alignment (Software)
- Align source and target eigenspaces to reuse or freeze well-localized subspaces (e.g., for domain-adapted heads).
- Practical outcome: faster convergence and reduced forgetting by respecting learned geometry.
- Dependencies/assumptions: subspace overlap between domains; stable identification of reusable eigenspaces.
- Fairness and compliance checks for interference (Policy/Healthcare/Finance)
- Audit whether protected attributes or sensitive proxies share eigenspaces with task-critical features; intervene via reweighting, regularization, or constrained finetuning.
- Practical outcome: reduced unintended coupling of sensitive attributes; evidence supporting audits.
- Dependencies/assumptions: availability of labels/proxies; legal/privacy constraints; interpretability of features in high-capacity models.
Long-Term Applications
These rely on further validation at scale, algorithmic development, or hardware/standards support. They build on capacity-saturation–induced spectral localization, tight-frame organization, and association-scheme classification of feature geometry.
- Eigenspace-structured architectures and routers (Software/Robotics)
- Design layers that explicitly maintain orthogonal subspaces (mixture-of-eigenspaces) with learnable routing; add subspace-specific attention or MLPs to minimize cross-talk.
- Potential products: spectral routers, subspace-gated transformers, task-decoupled multi-task learners.
- Dependencies/assumptions: empirical gains over strong baselines; efficient training of orthogonality and routing constraints.
- Curriculum/data shaping to elicit desired geometry (Education/LLM Training)
- Shape training data and objectives to produce specific association schemes (e.g., cyclic, hierarchical) and reduce undesired cohabitation of subspaces.
- Potential workflows: curriculum that gradually introduces structured relations; subspace-targeted auxiliary losses.
- Dependencies/assumptions: reliable mapping between data structure and learned geometry; scalability to foundation models.
- Alignment methods with operator-theoretic constraints (AI Safety)
- Incorporate eigenspace constraints into RLHF or direct preference optimization to keep safety-critical features in isolated subspaces and prevent jailbreak couplings.
- Potential tools: eigenspace-aware preference losses; post-hoc eigenspace audits integrated into safety pipelines.
- Dependencies/assumptions: robust measurement of safety-related features; alignment-performance trade-offs.
- Hardware and systems support for subspace operations (Semiconductors/Systems)
- Accelerate projector operations, per-eigenspace batching, and subspace-specific kernels; scheduler support for eigenspace-aware parallelism.
- Potential products: libraries for fast spectral projection and subspace-aware training/inference.
- Dependencies/assumptions: stable eigenspace partitions; amortization of decomposition costs.
- Healthcare: interpretable clinical subspaces (Healthcare/Policy)
- Build disease/comorbidity subspaces with tight-frame structure to decouple unrelated signals; support clinician review and regulatory audits with “subspace explainability reports.”
- Potential workflows: spectral audits integrated into model cards; subspace-specific calibration.
- Dependencies/assumptions: access to clinical features; rigorous validation for safety and equity; regulatory acceptance.
- Factor models with stable subspace geometry (Finance)
- Construct tight-frame factor libraries and risk subspaces to improve disentanglement of market, sector, and idiosyncratic components; reduce interference across horizons.
- Potential tools: eigenspace-aware portfolio construction and stress-testing.
- Dependencies/assumptions: stationarity of spectral structure; strong backtesting and governance.
- Multi-task decoupling in perception and control (Robotics)
- Maintain separate perception/control eigenspaces to mitigate negative transfer; subspace-level safety envelopes for critical control features.
- Potential products: subspace-safe controllers; modular policies sharing geometry-aware representations.
- Dependencies/assumptions: real-time spectral operations; robustness under domain shift.
- Energy forecasting with subspace separation (Energy)
- Separate seasonal/diurnal patterns and anomaly channels into distinct eigenspaces to improve robustness and reduce spurious interference.
- Potential workflows: eigenspace-conditioned ensembles; subspace-targeted anomaly detection.
- Dependencies/assumptions: stability of seasonal subspaces across regimes; operational validation.
- Standards for “subspace interference audits” and disclosures (Policy/Governance)
- Define reporting requirements on spectral localization, interference risk, and subspace edits for high-impact AI systems.
- Potential outcomes: audit templates; certification criteria; red-teaming protocols based on eigenspace stress-tests.
- Dependencies/assumptions: consensus on metrics; regulator and industry adoption.
- Productization: Spectral Interpretability Suite (Software)
- An integrated toolkit offering F and M computation, eigendecomposition at scale, per-feature spectral measures, tight-frame detection, association-scheme classifiers, and visualization.
- Integrations: SAE frameworks, Weights & Biases, training loops for continuous monitoring.
- Dependencies/assumptions: scalable linear algebra; user experience for large-model teams.
Cross-cutting assumptions and dependencies
- Capacity saturation and spectral localization: proofs are in toy models; empirical validation at scale is ongoing. Expect approximate localization rather than perfect Dirac measures in large models.
- Feature definitions: practical adoption depends on reliable feature extraction (e.g., SAE features or identified directions). Poor features will degrade spectral diagnostics.
- Compute and numerics: eigendecompositions on large hidden layers must use scalable, numerically stable methods (randomized SVD, block methods).
- Degeneracy and drift: near-degenerate eigenvalues and spectral drift across data distributions can complicate stable subspace identification; monitoring is required.
- Objective trade-offs: stronger localization and orthogonality constraints may trade off with raw task performance; careful validation is needed per sector and use case.
Collections
Sign up for free to add this paper to one or more collections.