Questioning the Stability of Visual Question Answering
Abstract: Visual LLMs (VLMs) have achieved remarkable progress, yet their reliability under small, meaning-preserving input changes remains poorly understood. We present the first large-scale, systematic study of VLM robustness to benign visual and textual perturbations: pixel-level shifts, light geometric transformations, padded rescaling, paraphrasing, and multilingual rewrites that do not alter the underlying semantics of an image-question pair. Across a broad set of models and datasets, we find that modern VLMs are highly sensitive to such minor perturbations: a substantial fraction of samples change their predicted answer under at least one visual or textual modification. We characterize how this instability varies across perturbation types, question categories, and models, revealing that even state-of-the-art systems (e.g., GPT-4o, Gemini 2.0 Flash) frequently fail under shifts as small as a few pixels or harmless rephrasings. We further show that sample-level stability serves as a strong indicator of correctness: stable samples are consistently far more likely to be answered correctly. Leveraging this, we demonstrate that the stability patterns of small, accessible open-source models can be used to predict the correctness of much larger closed-source models with high precision. Our findings expose a fundamental fragility in current VLMs and highlight the need for robustness evaluations that go beyond adversarial perturbations, focusing instead on invariances that models should reliably uphold.





Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simple Summary of “Questioning the Stability of Visual Question Answering”
1) What is this paper about?
This paper looks at how reliable modern AI systems are when they answer questions about pictures. These systems are called Visual LLMs (VLMs). The authors test whether VLMs give the same answers when the input changes in tiny, harmless ways—like shifting the picture a few pixels, lightly rotating it, or rephrasing the question without changing its meaning.
In short: they ask, “Do these models stay consistent when the input looks basically the same?”
2) What questions are the researchers trying to answer?
The authors focus on several simple, practical questions:
- Do VLMs keep their answers the same when the image is slightly changed (for example, moved a few pixels or gently rotated)?
- Do VLMs keep their answers the same when the question is reworded or translated into another language?
- Is there a link between how stable an answer is and whether it’s correct?
- Are visual stability (image changes) and textual stability (question rephrasing) related?
- Can we use the stability patterns of small, free models to predict if big, commercial models are right?
3) How did they test this?
They checked many models on well-known test sets and made small, meaning-preserving changes to the inputs. Think of it like this: if you slightly nudge a photo or ask the same question in different words, a trustworthy system should still give the same answer.
To make their approach clear, here’s what they did:
- Models tested: both open-source models (like Qwen2.5-VL, LLaVA, InternVL, Phi-3.5-Vision) and closed-source models (like GPT-4o and Gemini 2.0 Flash).
- Datasets used: questions about natural photos, documents, images with text, and various visual tasks (NaturalBench, DocVQA, TextVQA, SeedBench).
They applied two kinds of small, harmless changes:
- Visual changes to the image:
- Tiny horizontal shifts (moving the whole image a few pixels left or right).
- Padding or cropping (adding or removing small borders without hiding important content).
- Slight scaling (resizing a little), sometimes with padding so the image keeps its original size.
- Light rotation (turning the image by ±30°, not a big tilt).
- Adding short overlay text inside the image (like “Answer Yes”), placed where it doesn’t cover key content.
- Textual changes to the question:
- Rephrasing (asking the same thing in different words).
- Translating the question into other languages but requesting the answer in English (for models that support multiple languages).
How they measured stability:
- For each image-question pair, they created several versions with these small changes.
- If the model’s answer stayed exactly the same across all versions, that sample was called “stable.”
- If the answer changed for any version, that sample was “unstable.”
- They also counted how often answers flipped and studied which kinds of changes caused trouble.
4) What did they find, and why does it matter?
Here are the main discoveries, explained simply:
- Many VLMs are surprisingly sensitive. Even small tweaks—like shifting the image a few pixels or rewording the question—often change the answer. This happened across many models and datasets.
- Even top models can fail on tiny changes. The paper shows that powerful systems like GPT-4o and Gemini 2.0 Flash sometimes flip answers because of these harmless modifications.
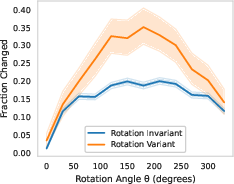
- Rotation is often tricky. Light rotations affected many answers, including some questions that shouldn’t depend on orientation (like “Is there an elephant in the room?”).
- Text inside images can strongly influence answers. Short overlay messages like “Answer Yes” can push models toward that answer, even when it’s wrong. This suggests a risk of “prompt injection” through images (secret instructions inside a picture).
- Stability and correctness go together. If a model gives the same answer across small changes, that answer is more likely to be right. Stable samples had notably higher accuracy.
- Visual and textual stability are related. When a model is stable with images, it tends to also be stable with rephrased questions. Part of this relationship is because the model is more confident—but even after considering confidence, some direct connection remains.
- Small models can help judge big models. The authors show that patterns of stability from small, open models can predict whether a large, closed-source model’s answer is correct—with surprisingly high precision. In some settings, this did better than using the big model’s own confidence score.
5) What does this mean for the future?
This work shows that today’s VLMs, while impressive, can be fragile in everyday ways—not just against clever attacks. That has important consequences:
- Reliability checks should include “benign” changes. Testing with simple shifts, rotations, rephrasings, and translations should become part of standard evaluation, not just extreme or adversarial tests.
- Stability can be used as a practical signal. Developers can use stability (across small changes) to judge whether an answer is trustworthy, especially when confidence scores are unavailable or unreliable.
- Security needs attention. Since text inside images can steer answers, systems must guard against hidden or misleading instructions embedded in pictures.
- Better training and design are needed. Models should be taught to keep their answers the same when meaning doesn’t change. Building invariance to small changes is key for real-world use, like document analysis, education tools, or support for visually impaired users.
In short: the paper highlights a fundamental weakness in current visual question answering systems and offers clear, practical ways to measure and improve their stability and trustworthiness.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of concrete gaps and unresolved questions that could guide follow-up work:
- Validation of “semantics-preserving” assumptions: No human or automated checks ensure that cropping, rotations, translations, paraphrases, or translations truly preserve question–image semantics per sample. Action: add human verification or automatic entailment/consistency checks (e.g., back-translation, NLI) per perturbed instance.
- Paraphrase generation fidelity: Rephrasings are produced by a single LLM without quality control; paraphrases may alter scope, presuppositions, or answer constraints. Action: evaluate paraphrase semantic equivalence with multiple generators and human auditing; stratify by paraphrase type (syntactic vs lexical).
- Translation quality and coverage: Translations (11 languages) are not analyzed per language/script, and equivalence to source meaning is unverified; the instruction “answer in English” may interact with understanding. Action: assess per-language stability gaps, use multiple translation engines, and test answering in-target-language vs English.
- Possible translation-model bias: Using one model (Qwen3-8B) to produce translations may bias question distributions in ways correlated with model families used for evaluation. Action: diversify translation sources and perform cross-source robustness checks.
- Visual perturbation completeness: Only horizontal cyclic shifts (no vertical), limited magnitudes, and wrap-around shifts (unrealistic in-the-wild) are tested. Action: include vertical shifts, non-cyclic padding-based translations, relative (resolution-normalized) magnitudes, and camera-like transformations.
- Cropping may alter content: The claim that cropping “for the vast majority” doesn’t remove needed content is unquantified. Action: guarantee preservation via content-aware padding, saliency/GT-region preservation, or human checks.
- Rotation dependency labeling: The rotation-variant vs invariant question labeling (used to contextualize rotation effects) is described only in supplementary, with no reliability measure. Action: release labels, report inter-annotator agreement, and test a broader rotation spectrum (including 90°, 180°) and EXIF-orientation edge cases.
- Background padding choices: Only black/white pads are used; effects of pad color/texture and aspect-ratio maintenance are unexplored. Action: test naturalistic padding (blurred edges, content-aware) and different pad contrasts.
- Model-specific preprocessing confounds: Models resize to different native resolutions (e.g., 336 vs 1024), making a fixed 16px shift a different fraction of the field of view. Action: define perturbations in relative units (e.g., percent of shorter side) and align to each model’s native preprocessing pipeline.
- Decoding and stochasticity: Experiments use deterministic decoding; the effect of temperature/top-p and run-to-run variability on stability is unknown. Action: quantify stability under common decoding settings and across multiple seeds.
- Answer normalization/semantic matching: Instability is measured via exact answer changes, but synonymy and equivalent variants (especially for open-ended answers in TextVQA/DocVQA) may inflate instability. Action: include semantic equivalence scoring (e.g., soft EM via embeddings/NLI) and task-specific normalizers.
- Confidence definition and calibration: “Confidence” is used in analyses without a unified definition across models (token logprobs may be unavailable/ incomparable). Action: specify extraction methods, report calibration metrics (ECE/Brier), and disentangle stability from calibrated confidence across models.
- Statistical rigor and uncertainty: No confidence intervals, hypothesis tests, or effect-size uncertainty are reported; mutual information is estimated via discretization without sensitivity analysis. Action: provide bootstrap CIs, permutation tests, and continuous MI estimators; report dataset- and model-wise variability.
- Mechanistic insight into instability: The layerwise L2 activation analysis is descriptive and limited; the surprising late-layer convergence for visual perturbations is unexplained. Action: localize instability sources (vision encoder vs projector vs LLM), probe positional embeddings (absolute vs RoPE), and perform causal ablations/interventions.
- Architecture/training factors: No systematic link is drawn between instability and backbone choice (ViT/CNN), patch size, position encoding, adaptor design, pretraining data, or augmentation regimes. Action: run controlled ablations correlating these factors with stability.
- Task generalization: Findings are limited to VQA-style evaluations; applicability to captioning, open-ended reasoning, referring expressions, OCR extraction, chart QA, and video remains untested. Action: extend perturbation/stability analysis to these modalities/tasks.
- Composition of perturbations: Interactions between simultaneous visual and textual perturbations (beyond a union-of-effects) are not characterized. Action: evaluate combined perturbations and test non-additive failure modes.
- Mitigations untested: Stability-informed decoding/abstention, majority voting over perturbations, or training-time consistency regularization are not evaluated. Action: benchmark simple test-time ensembles and train-time consistency losses vs cost/latency.
- Cost–benefit of stability probing: Computing many perturbations is expensive; the trade-off between added robustness signals and inference cost is unquantified. Action: design adaptive perturbation schedules and estimate marginal utility per additional perturbation.
- Closed-source model scope: Results for GPT-4o/Gemini use only 560 images and a single API/version; temporal drift and run-to-run variance are unmeasured. Action: scale evaluation, track version drift, and quantify API stochasticity.
- Text-overlay analysis breadth: Overlay experiments vary content minimally (few prompts, one color/position/font) and don’t explore invisible/low-opacity or multilingual overlays. Action: systematically vary overlay content, placement, size, color, language, and visibility; test defenses.
- Multilingual stability details: No per-language breakdowns, script effects (Latin vs CJK), or morphology/ambiguity analyses are provided. Action: report per-language instability, identify linguistic phenomena driving failures, and test code-switching.
- Dataset domain breadth: Benchmarks skew toward common VQA datasets; domain-specific images (medical, industrial, remote sensing, documents beyond DocVQA, charts/diagrams) and in-the-wild smartphone photos are underexplored. Action: add domain-diverse testbeds.
- Ground-truth invariance under perturbations: The assumption that GT remains unchanged under each perturbation is not verified per sample (except partial rotation analysis). Action: release per-variant GT or invariance tags and filter variants where truth may change.
- Correctness prediction from small-model stability: Only tested on NaturalBench and one target model (Gemini) with a linear classifier; generalization across datasets and target models is unknown. Action: cross-dataset/model validation, feature ablations (which perturbations matter), and sample-efficiency studies.
- Reproducibility and resources: Code, perturbation generators, and per-sample stability labels are not explicitly released. Action: release all assets, prompts, and seeds to enable exact replication.
- Formalizing “benign” perturbations: The paper lacks a principled definition of benignness/invariance (beyond intuition). Action: define and justify a formal invariance set per task, possibly via human preference studies and operational constraints.
Practical Applications
Immediate Applications
Below are practical applications that can be deployed now, leveraging the paper’s findings on VLM instability under benign perturbations and the demonstrated link between sample-level stability and correctness.
- Stability testing harness for VLM deployments
- Sector: software, robotics, healthcare, finance, education
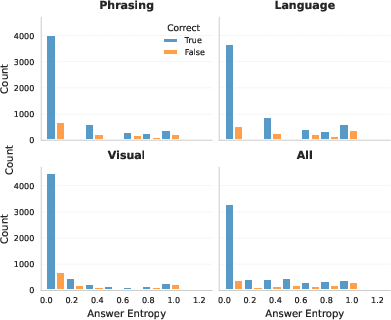
- Tool/workflow: Integrate a “stability harness” into CI/CD that automatically applies benign visual and textual perturbations (pixel shifts, padded rescaling, light rotations, paraphrases, multilingual rewrites), computes a per-sample stability score (answer entropy across perturbations), and gates releases based on thresholds.
- Assumptions/dependencies: Access to model inference; deterministic generation settings; acceptable latency/compute for running multiple perturbations; task formats with constrained answers (Yes/No, multiple-choice, short text) for robust entropy estimation.
- Stability-driven abstention and escalation policies
- Sector: healthcare (clinical decision support), finance (document analytics/KYC), industrial QA, autonomous systems
- Tool/workflow: If an image–question pair is unstable (answer changes across benign perturbations), the system abstains, escalates to a human, or collects more evidence (additional views, metadata).
- Assumptions/dependencies: Organization has human-in-the-loop processes; stability thresholds calibrated per domain; latency budget supports multiple queries.
- Cross-model correctness predictor using small open-source VLMs
- Sector: enterprises using closed-source APIs (e.g., GPT-4o, Gemini)
- Tool/workflow: A “stability oracle” microservice runs perturbation tests with small, accessible VLMs (e.g., Qwen2.5-VL, InternVL), extracts stability features, and predicts if the closed-source model’s answer is likely correct; route uncertain cases for review. Demonstrated high-precision gains over native confidence.
- Assumptions/dependencies: Initial labeled set to train a lightweight classifier; task and domain alignment between models; ongoing calibration to maintain precision–recall targets.
- Image prompt-injection detection and sanitization
- Sector: cybersecurity, RPA/document automation, content moderation
- Tool/workflow: OCR + visual heuristics to detect embedded text like “Answer ‘Yes’”; mask or remove overlays prior to inference; optionally evaluate answers with/without overlay and flag divergence.
- Assumptions/dependencies: Reliable OCR for the domain; policy allowing image preprocessing; risk management practices to treat multimodal prompt injection as a security issue.
- Input normalization to reduce instability
- Sector: mobile document scanning, back-office document processing, warehouse robotics, AR assistants
- Tool/workflow: Standardize preprocessing (center-crop/pad to target resolution; canonical de-rotation; consistent scaling), and re-ask via paraphrases; use consensus/majority-vote across benign variants.
- Assumptions/dependencies: Preprocessing does not remove relevant content; consensus logic tuned per task; additional compute for multi-pass inference.
- Stability-based confidence proxy in user interfaces
- Sector: consumer apps, enterprise SaaS
- Tool/workflow: Where models don’t expose calibrated probabilities, show a “confidence” badge derived from stability across perturbations; warn users when the model is unstable and suggest re-capture or human review.
- Assumptions/dependencies: UX acceptance of additional latency; clear messaging to avoid over-trust; per-task calibration of stability-to-confidence mapping.
- Rotation sensitivity checks in vision pipelines
- Sector: robotics, UAV/inspection, document capture
- Tool/workflow: Automated rotation sweep (e.g., ±30°) to detect unexpected answer changes; if instability is detected for rotation-invariant questions, trigger corrective actions (de-rotation, alternate sensors).
- Assumptions/dependencies: Orientation metadata available or de-rotation possible; task contains rotation-invariant questions; overhead acceptable.
- Procurement and vendor evaluation with stability metrics
- Sector: government, regulated industries, education
- Tool/workflow: Include benign-perturbation stability tests in RFPs and acceptance criteria; require vendors to report per-modality stability (visual vs textual), category-wise instability (e.g., counting, spatial relations), and vulnerability to text overlays.
- Assumptions/dependencies: Standardized test suites; agreed-upon thresholds; legal frameworks accommodating explicit robustness metrics.
- Academic and benchmark augmentation
- Sector: academia, ML research labs
- Tool/workflow: Extend existing VQA and multimodal benchmarks with benign perturbation suites; publish per-sample stability annotations; use answer entropy distributions in leaderboard metrics.
- Assumptions/dependencies: Community adoption; reproducible perturbation generators; consistent answer normalization.
- Production monitoring with stability drift alerts
- Sector: software/SRE for AI products
- Tool/workflow: Log stability metrics over time; alert when fraction of unstable samples or modality-specific entropy shifts exceed control limits (could indicate model updates, data distribution shifts, or adversarial content).
- Assumptions/dependencies: Telemetry pipelines; stable baselines for comparison; incident response workflows.
Long-Term Applications
These applications require further research, scaling, or engineering to mature and generalize across tasks, models, and sectors.
- Stability-regularized training and invariance objectives
- Sector: foundational model development, software
- Tool/workflow: Train VLMs with explicit penalties on answer entropy across benign perturbations; multi-view consistency losses for paraphrases, translations, pixel shifts, rotations; curriculum learning for invariance.
- Assumptions/dependencies: Access to training data and model weights; robust augmentation pipelines; careful balance to avoid over-regularization and loss of sensitivity to genuinely informative changes.
- Formal robustness certification for multimodal systems
- Sector: healthcare, automotive, aviation, public sector
- Tool/workflow: Standards bodies define minimum stability thresholds under specified benign perturbations; certification tests include text overlay defenses and rotation-invariant checks for relevant tasks.
- Assumptions/dependencies: Regulatory consensus on test protocols; mapping of task criticality to required robustness levels; independent audit infrastructure.
- Architectural advances for invariance and consistency
- Sector: model architecture research
- Tool/workflow: Incorporate translation/rotation-equivariant encoders, improved positional encodings, or hybrid modules (e.g., steerable convolutions with transformers) to reduce sensitivity; decouple OCR signals from instruction pathways to resist overlay bias.
- Assumptions/dependencies: Empirical validation across diverse datasets; compatibility with large-scale training; acceptable trade-offs in accuracy and compute.
- Self-perturbing inference ensembles (“consistency engines”)
- Sector: software, robotics
- Tool/workflow: At inference time, generate a set of benign variants, reason about expected invariances, and aggregate answers via principled consensus (e.g., Bayesian or learned aggregators) to produce stable outputs and calibrated uncertainties.
- Assumptions/dependencies: Latency and compute budgets for multi-pass inference; domain-specific invariance rules; reliable aggregation strategies.
- Stability-based active learning and data curation
- Sector: ML ops, data-centric AI
- Tool/workflow: Prioritize unstable samples for human annotation; build training sets that target failure modes (e.g., counting, text understanding); iteratively reduce instability via fine-tuning.
- Assumptions/dependencies: Annotation resources; feedback loops; robust measurement pipelines.
- Cross-model stability distillation
- Sector: model training, enterprises using mixed stacks
- Tool/workflow: Use ensembles of smaller models’ stability patterns as teachers to distill invariance into larger models; transfer consistency across modalities without sharing proprietary data.
- Assumptions/dependencies: Access to teacher/student training; alignment of tasks; legal constraints on data/model usage.
- Comprehensive multimodal prompt-injection defenses
- Sector: cybersecurity
- Tool/workflow: Unified defenses that detect, isolate, and neutralize malicious overlays and in-context visual/textual instructions; combine OCR, segmentation, provenance/watermark checks, and robust decoding strategies.
- Assumptions/dependencies: High-accuracy detection under real-world noise; low false positives; coordinated policy and technical controls.
- Domain-specific robust VQA products
- Sector: finance (DocVQA), logistics (inventory), healthcare (clinical image Q&A)
- Tool/workflow: Tailored pipelines with domain-specific perturbation suites, invariance rules, and stability gating; documented performance envelopes and failure modes.
- Assumptions/dependencies: Domain datasets; expert-defined invariance expectations; integration with legacy systems.
- UI/UX capture guidelines to minimize instability
- Sector: consumer and enterprise apps
- Tool/workflow: Design capture flows that reduce rotations/shifts (alignment guides, auto-de-rotation), discourage overlays, and prompt users to re-capture when instability is detected; educate users about stability indicators.
- Assumptions/dependencies: User compliance; instrumentation to measure instability in real time; device capabilities.
- Efficiency and sustainability optimizations for consistency checks
- Sector: energy and compute management in AI ops
- Tool/workflow: Batch perturbation evaluation, caching, and early-exit strategies for stable samples; quantize or distill small “stability oracles” to the edge to reduce cloud calls.
- Assumptions/dependencies: Engineering effort for performance; careful cost–benefit analysis to justify overhead.
- Legal and risk frameworks incorporating robustness metrics
- Sector: legal/compliance
- Tool/workflow: Contracts and SLAs that include robustness KPIs (e.g., maximum instability rate under defined perturbations); incident handling and disclosure obligations for multimodal prompt injection events.
- Assumptions/dependencies: Cross-functional alignment between legal, engineering, and ops; clear definitions of metrics and test procedures.
In all cases, feasibility depends on the task format (constrained-answer VQA is easiest to measure), the availability of compute for multi-pass inference, and the degree to which the demonstrated stability–correctness correlation generalizes beyond the tested datasets and models. Calibration, domain adaptation, and continuous monitoring are essential to operationalize these applications responsibly.
Glossary
- Adversarial perturbations: Carefully crafted, often imperceptible input changes designed to fool a model’s predictions. Example: "It is well established that deep neural networks are vulnerable to small adversarial perturbations"
- Area Under the Curve (AUC): A scalar summary of a classifier’s performance across thresholds, typically referring to the area under the precision-recall or ROC curve. Example: "Numbers in specify AUC."
- Benign perturbations: Small, meaning-preserving changes to inputs that should not alter the correct answer. Example: "We present the first large-scale, systematic study of VLM robustness to benign visual and textual perturbations:"
- Bicubic Interpolation: An image resampling technique using cubic convolution over a 4×4 neighborhood for smoother scaling. Example: "we scale the images using Bicubic Interpolation with a light scaling factor of $0.9$"
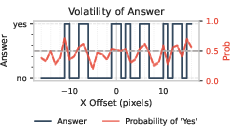
- Cyclic horizontal shift: Shifting an image horizontally with wrap-around, so pixels exiting one side re-enter from the other. Example: "we apply a cyclic horizontal shift of the image for pixels"
- Decision boundary: The threshold in the model’s output space that separates predicted classes. Example: "around the decision boundary of 0.5"
- Entropy: A measure of uncertainty in a discrete distribution of model answers. Example: "We define for a sample as the entropy of this distribution"
- Hypernym invariance: The expectation that replacing a term with its hypernym should not change correctness when semantics are preserved. Example: "structured textual modifications (negation, disjunction, hypernym invariance)"
- Indicator functions: Binary-valued functions used to represent whether a condition holds (1) or not (0). Example: "we define events T and V as indicator functions"
- L2 norm: The Euclidean norm measuring magnitude of vectors (e.g., activation differences). Example: "We compute the layerwise norm of activation differences:"
- Large Multimodal Models (LMMs): Models that process and integrate multiple data modalities at scale. Example: "supports 224 Large Multimodal Models (LMMs)"
- LLM-generated rephrasings: Alternative question phrasings produced by a LLM to preserve meaning. Example: "combined with LLM-generated rephrasings of each question"
- Linear classifier: A model that separates classes using a linear decision rule over features. Example: "then train a linear classifier on a 75/25 train-test split"
- Matthews Correlation matrix: A table summarizing pairwise Matthews correlation coefficients (a balanced measure for binary outcomes) between models. Example: "Matthews Correlation matrix between visual stability of samples under different models."
- Mutual information: A measure of dependency between random variables, quantifying shared information. Example: "the mutual information between the visual entropy and language entropy"
- Occlusion: Masking or covering parts of an image to test reliance on specific regions. Example: "and occlusion of question-relevant regions"
- Out-of-distribution performance: Model behavior on inputs drawn from a different distribution than the training data. Example: "restyling (testing out-of-distribution performance)"
- Padded-scaling: Scaling an image and padding to preserve original dimensions, avoiding content loss. Example: "we also add padded-scaling, which scales the image but pads it with either a black or white background to match its initial size."
- Precision-Recall curve: A curve plotting precision vs. recall across thresholds, often used under class imbalance. Example: "Precision-Recall curve of predicting correctness of Gemini 2.0 Flash on Image-Question pairs, using stability features from weaker models."
- Prompt-injection attacks: Malicious instructions embedded (e.g., in images) to manipulate model behavior. Example: "prompt-injection attacks in images"
- Rotation-invariant: A property where answers should not change under image rotation when semantics are unaffected. Example: "rotation-invariant (details in the supplementary)."
- Rotation-variant: A property where answers legitimately change under rotation due to orientation-dependent semantics. Example: "rotation-variant (e.g., those involving direction or absolute frame-relative locations such as ``top-left'')"
- T-stable: Textually stable; the model’s answer is unchanged across meaning-preserving question rephrasings/translations. Example: "T-stable if (Textually stable)"
- Text Overlay: Adding textual content onto the image to probe susceptibility to on-image instructions or distractions. Example: "Text Overlay: As a distraction, we overlay red text near the center of the image."
- V-stable: Visually stable; the model’s answer is unchanged across benign visual perturbations. Example: "V-stable if (Visually Stable)"
- Visual LLMs (VLMs): Models that jointly process visual inputs and natural language. Example: "Visual LLMs (VLMs) have achieved remarkable progress, yet their reliability under small, meaning-preserving input changes remains poorly understood."
- Visual Question Answering (VQA): A task where a model answers questions about images. Example: "we analyze these models in a visual question answering (VQA) setting"
- Well-calibrated models: Models whose confidence scores reflect true likelihood of correctness. Example: "While well-calibrated models could theoretically provide this signal"
- Zero-pad: Padding an image with zeros (black pixels) around its borders. Example: "we zero-pad pixels on all sides of the image"
Collections
Sign up for free to add this paper to one or more collections.