Ministral 3
Abstract: We introduce the Ministral 3 series, a family of parameter-efficient dense LLMs designed for compute and memory constrained applications, available in three model sizes: 3B, 8B, and 14B parameters. For each model size, we release three variants: a pretrained base model for general-purpose use, an instruction finetuned, and a reasoning model for complex problem-solving. In addition, we present our recipe to derive the Ministral 3 models through Cascade Distillation, an iterative pruning and continued training with distillation technique. Each model comes with image understanding capabilities, all under the Apache 2.0 license.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Plain‑Language Summary of “Ministral 3”
1) What is this paper about?
This paper introduces Ministral 3, a family of small, efficient AI LLMs that can read and write text, understand images, and handle very long documents. They come in three sizes (3B, 8B, and 14B “parameters,” which are like the model’s knobs or settings), and each size has three versions:
- Base (general use)
- Instruct (good at following instructions)
- Reasoning (better at solving hard problems step by step)
The big idea: make models that are almost as smart as larger ones, but cheaper and lighter to run on limited computers.
2) What questions were the researchers trying to answer?
They focused on a few simple goals:
- Can we shrink a big, smart AI model into smaller versions without losing too much ability?
- Can we train these smaller models using much less data and computing power than usual?
- What’s the best way to “teach” a smaller model—what kind of teacher model should it learn from?
- Can these small models handle images and very long context (up to 256,000 tokens, roughly like hundreds of pages of text)?
3) How did they do it? (Methods explained simply)
Think of the process like turning a huge, skilled teacher into a team of smaller, focused students without starting from scratch.
- They started with a strong “parent” model (Mistral Small 3.1, 24B parameters).
- They used a method called “Cascade Distillation,” which is like: 1) Trim, 2) Learn, 3) Repeat.
Here’s the approach in everyday terms:
- Pruning (the trimming step): Imagine carving a sculpture from a block of stone. They remove less important parts of the big model while keeping the most important “brain circuits.” They do this in smart ways:
- Layer pruning: keep the most useful layers.
- Hidden size pruning with PCA: compress the “internal space” so it keeps the most important patterns.
- Feed‑forward pruning: keep the most helpful neurons based on how active and useful they are.
- Distillation (the learning step): The smaller “student” watches the “teacher” answer questions and tries to match the teacher’s confidence in each answer (this is called matching “logits,” the model’s internal scores). This helps the student learn faster and better than learning from scratch.
- Short‑to‑long context training: First, they train with shorter inputs; then they extend the model to handle very long inputs using special tricks (like YaRN and temperature scaling) so the model stays stable with long documents.
- Vision: They plug in a pre‑trained image encoder (a ViT, a type of vision model) so the models can understand pictures. The vision part stays mostly frozen, and they train a small connector layer to link images to the LLM.
- Post‑training (making the models helpful and polite):
- Instruct models: First supervised fine‑tuning (the model copies good answers), then Online Direct Preference Optimization (ODPO)—the model writes two answers, a judge picks the better one, and the model learns from that feedback.
- Reasoning models: They get extra “think aloud” training (Chain‑of‑Thought), then reinforcement learning (GRPO) to improve step‑by‑step problem‑solving, and finally ODPO to make answers clearer and more user‑friendly.
4) What did they find, and why is it important?
Main results:
- Strong performance for their size: The 14B Base model almost matches the 24B parent in many areas, despite being over 40% smaller and trained on far fewer tokens (1–3 trillion vs. 15–36 trillion used by some other teams). That means big savings in time and cost.
- Competitive with other open models: Across common tests (like MMLU, TriviaQA, MATH), the Ministral 3 models often match or beat similar‑sized models (e.g., Qwen 3 and Gemma 3). The 8B model even beats some larger models in several tests.
- Strong math and coding: The Reasoning models do especially well on tough math and programming benchmarks (like AIME and LiveCodeBench).
- Very long context and vision: All models can handle very long inputs (up to 256k tokens for Base and Instruct, 128k for Reasoning) and understand images.
- Useful “teacher” lessons:
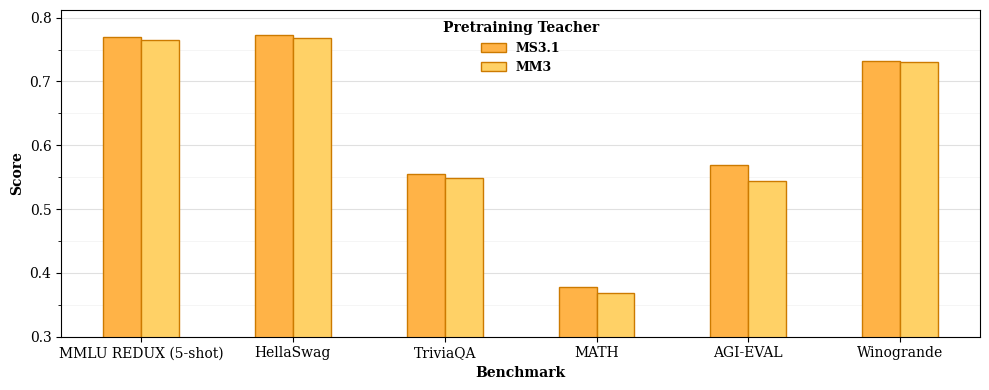
- A bigger teacher isn’t always better during pretraining. Surprisingly, using the 24B parent (not an even bigger model) worked best to teach the smaller students at that stage.
- But during post‑training (teaching the model to be helpful and aligned), stronger teachers do help.
- Distilling from a teacher that was already fine‑tuned for preferences (not just basic training) gives better students, especially for math and code.
Why this matters:
- You can get high‑quality models that run faster and cheaper, making advanced AI more accessible.
- The teacher‑student recipe (Cascade Distillation) shows a practical way to build more efficient models without sacrificing too much ability.
5) What’s the impact?
- Practical AI for more people: Smaller, capable models can run on cheaper hardware, helping startups, schools, and researchers with limited resources.
- Open and usable: The models are released with open weights under the Apache 2.0 license, which means you can use them (even commercially) with relatively few restrictions.
- Better training recipes: The paper gives a clear, repeatable method—prune, distill, repeat—that others can use to make efficient models. It also clarifies which teacher choices work best at different stages.
- Strong tools for long documents and images: With long‑context and vision support, the models can handle tasks like reading long reports, analyzing PDFs, and describing images.
In short: Ministral 3 shows how to make smaller AI models that still perform very well, cost less to train and run, and are easy for the community to use and build on.
Knowledge Gaps
Below is a single, focused list of concrete knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each item is phrased to be actionable for future research.
- Training data transparency: The paper does not disclose the composition, sources, proportions, or filtering criteria of the text-only and multimodal data mixes for short- and long-context stages, hindering reproducibility and targeted ablations.
- Distillation hyperparameters: Key choices (e.g., teacher temperature, softmax temperature on student, label smoothing, KL variant, mixing ratio with next-token prediction) are not specified or compared; it remains unclear which settings optimize transfer for different stages and domains.
- Feature vs. logit distillation: Only logit (forward KL) distillation is used; the benefits and trade-offs of intermediate feature/attention/state distillation (layer-wise, cross-layer mapping, representation alignment) are unexplored.
- Teacher-student capacity scaling: The “capacity gap” observation is limited to MS3.1 vs. MM3; a broader scaling law across multiple teacher sizes, domains, and student sizes (3B/8B/14B) with controlled compute remains an open question.
- Progressive teacher choice: Cascade Distillation always uses the parent (MS3.1) as teacher; whether distilling later students from the immediately preceding, size-near student (e.g., 14B→8B→3B) improves transfer or stability is not investigated.
- Domain-specific teachering: The impact of domain-specialized teachers (math/code/multimodal) during pretraining and post-training on targeted downstream tasks is not studied.
- Pruning calibration sensitivity: The pruning decisions depend on activation norms from “a large calibration batch”; sensitivity to batch domain, size, distribution shift, and robustness under different calibration datasets is unknown.
- PCA rotation globality: A single global PCA rotation across all layers is assumed; whether per-layer rotations or learned low-rank adapters yield better performance/robustness is not evaluated.
- Pruning method comparisons: The proposed layer-norm ratio and SwiGLU-specific feedforward pruning are not benchmarked against alternative structured/unstructured pruning (e.g., movement pruning, lottery ticket, magnitude-only) with matched FLOPs.
- Stability under pruning: Training instabilities, optimization hyperparameters, and failure modes introduced by the rotation and pruning steps (e.g., gradient explosion, layer-wise imbalance) are not characterized.
- Effect on latency and throughput: The impact of pruning choices on inference latency, memory bandwidth, and real-time throughput across hardware (GPU/TPU/CPU) is not reported.
- Long-context capability evaluation: Despite claiming up to 256k tokens, long-context performance is not evaluated on established stress tests (e.g., needle-in-haystack, SCROLLS, L-Eval); degradation patterns vs. length and position are unknown.
- Long-context training costs: Compute/energy costs and stability risks of extending from 16k to 262k (with YaRN + position-based temperature scaling) are not quantified; alternatives (e.g., recurrence, memory modules, retrieval augmentation) remain unexplored.
- Short vs. long context trade-offs: The effect of long-context uptraining on short-context accuracy, calibration, and hallucination rates is not measured.
- Vision encoder freezing: The frozen 410M ViT and retrained projection are used without ablations on partial/full fine-tuning, adapter placement, or cross-modal alignment strategies; impacts on visual grounding, text-VQA, and OCR are underexplored.
- Multimodal distillation: How logit distillation transfers multimodal knowledge (with a frozen encoder) is unclear; cross-modal losses (contrastive, alignment, captioning) or multimodal teachers are not examined.
- Multimodal coverage and limits: Image data scale, diversity, text-image pairing quality, and error modes (charts, math diagrams, dense text) are not described; MathVista underperformance suggests unresolved weaknesses.
- Multilingual scope: Vocabulary (131k) and multilingual MMLU are reported, but training mix by language, script coverage (e.g., Indic, Arabic), tokenization biases, and robustness to code-switching are unspecified.
- Safety and robustness: No safety, toxicity, jailbreak resistance, factuality, or hallucination evaluations are provided; ODPO alignment gains are reported without safety metrics or red-teaming.
- Data contamination controls: Procedures to detect or mitigate training-test overlap (especially on benchmarks like AIME, MATH, MBPP, GPQA) are not described; contamination risk remains unquantified.
- Tool-use reliability: Tool execution during ODPO is enabled, but tool suite, execution success rates, failure diagnostics, and benchmarks for tool-use robustness are missing.
- RL reward design: GRPO details (reward functions, rubric generation quality, judge bias, variance) and their impact on generalization/adversarial robustness are not thoroughly reported; reproducibility of rubric generation is unclear.
- Max generation length effects: Raising the generation cap to 80k improves completion, but compute overheads, truncation dynamics, and downstream latency implications are not analyzed.
- Verbosity–accuracy trade-offs: The paper identifies verbosity issues but does not test methods to encourage concise yet accurate reasoning (e.g., self-verification, think→summarize, constrained CoT revealing, speculative decoding).
- 3B instability: The 3B model’s sensitivity to hyperparameters and weaker ODPO gains are noted; systematic strategies to stabilize and align small models (e.g., curriculum, temperature schedules, optimizer choices) are not developed.
- Inference-time scaling: “Inference-time scaling” is referenced without experimental characterization (e.g., group sampling, tree-of-thought, multi-pass verification); its gains, costs, and best practices remain open.
- Benchmarking protocol transparency: Exact prompts, templates, decoding settings (temperature, top-p, constraints), seeds, and harness differences vs. public baselines are not fully disclosed, limiting cross-lab comparability.
- Efficiency accounting: FLOP/energy savings claims lack precise accounting per stage (prune, short-context, long-context, SFT, GRPO, ODPO), hardware profiles, and comparisons to training-from-scratch baselines.
- Teacher preference tuning: The claim that preference-tuned teachers are superior for SFT is made without reporting dataset size/quality, reward model calibration procedures, or robustness under distribution shift.
- Hidden vs. visible CoT: Reasoning model ODPO strips “thinking chunks” before scoring; the impact of revealing vs. hiding CoT at inference on accuracy, safety, and user experience is not evaluated.
- Code evaluation breadth: Evaluation focuses on MBPP and LiveCodeBench; broader coverage (HumanEval+, Codeforces, runtime correctness, security vulnerabilities) and detailed error analyses are missing.
- Calibration and uncertainty: No measures of confidence calibration, abstention/refusal behavior, or uncertainty-aware decoding are provided; methods to reduce overconfident errors are unexplored.
- Fairness and bias: No assessments of demographic bias, stereotyping, or fairness across languages and modalities are included; mitigation strategies remain untested.
- Catastrophic forgetting: The iterative prune–distill schedule may induce forgetting; retention of teacher knowledge across stages and domains is not measured.
- Cascade data scheduling: The claim that “data repetition is avoided” is not substantiated with token-level scheduling details; whether later students see sufficiently novel data remains unclear.
- Embedding tying ablation: Tied input-output embeddings are used only in 3B; the impact of tying on 8B/14B (accuracy, efficiency, calibration) is not explored.
- Memory-efficient serving: With 256k context, serving-side memory and paging strategies (e.g., PagedAttention) and their real-world performance are not reported.
- Open-source reproducibility: While weights are Apache-2.0, the paper does not release pruning/distillation code, data recipes, reward models, or evaluation harnesses needed for full reproducibility.
Practical Applications
Practical Applications of the Ministral 3 Models and Training Recipe
The paper introduces an open-weight, Apache 2.0–licensed family of dense LLMs (3B/8B/14B; base/instruct/reasoning; multimodal; up to 256K context) and a compute- and data-efficient pretraining method (Cascade Distillation with pruning + logit distillation), plus post-training (SFT, GRPO, ODPO). Below are practical, real-world applications derived from these models and methods.
Immediate Applications
The following use cases can be deployed now, subject to standard integration, safety, and compliance considerations.
- Software engineering
- Repository-scale code assistants that understand entire codebases with the 256K context window (refactoring, cross-file bug localization, test generation). Variants: 14B/8B Reasoning for complex reasoning; 8B/3B Instruct for latency-sensitive scenarios. Tools/workflows: IDE plugins with long-context ingestion; CI bots for automated PR reviews. Assumptions/dependencies: adequate GPU/CPU memory for long context; guardrails for code quality and security.
- Multimodal dev support: interpreting screenshots/diagrams for UI testing and bug triage. Tools/workflows: screenshot-to-issue pipelines. Assumptions: screenshot privacy handling; variable OCR fidelity in the wild.
- Knowledge work (legal, finance, compliance)
- Long-document analysis for contracts, filings (e.g., 10-K/10-Q), policies, and audit trails using 256K context. Variants: 14B/8B Instruct. Tools/workflows: “long-context contract analyzer” with clause extraction and risk summaries; compliance evidence synthesis. Assumptions: human-in-the-loop review; domain-validated prompts; sensitive-data handling on-prem.
- Regulatory watch and policy tracking with multilingual capabilities (European languages, Chinese, Japanese, Korean). Workflows: policy brief generation from multilingual sources. Assumptions: coverage and accuracy vary by language/domain; governance over summaries.
- Customer support and field operations
- Multimodal troubleshooting assistants that interpret user-uploaded images (device panels, error screens) and deliver step-by-step guidance. Variants: 8B/3B Instruct with vision. Sectors: electronics, telecom, consumer devices. Tools/products: self-service “vision+text” triage widgets. Assumptions: vision encoder trained on general imagery, not domain-specific; clear disclaimers.
- Agentic support with tool-use enabled during generation (from ODPO pipeline). Workflows: ticket search, knowledge-base retrieval, API-triggered actions (e.g., reset account, schedule technician). Assumptions: reliable tool integration; policies to avoid unintended actions.
- Education and training
- Math and coding tutors leveraging Reasoning variants’ performance on AIME/HMMT/LiveCodeBench; multilingual tutoring for non-English learners. Tools/products: interactive step-by-step tutors with adjustable verbosity. Assumptions: pedagogical oversight to mitigate hallucinations; explicit content policies.
- Visual learning aides: explain diagrams, charts, and worksheets. Workflows: homework help from photographed materials. Assumptions: caution against over-reliance in graded settings; honor academic integrity policies.
- Enterprise analytics and documentation
- Long-meeting and archival transcript summarization; multi-document synthesis across large corpora. Variants: 14B/8B Instruct. Tools/workflows: meeting-minutes generators, e-discovery triage. Assumptions: transcript quality; legal/privacy constraints.
- Multimodal document understanding (forms, slides, scanned PDFs) with image-text interleaving. Tools/workflows: invoice/receipt explanation, SOP extraction. Assumptions: domain adaptation may improve robustness.
- Robotics, manufacturing, and maintenance
- Technician copilots that parse equipment photos and manuals for on-site guidance. Variants: 8B/3B Instruct with vision for edge deployments. Tools/products: tablet-based maintenance assistants. Assumptions: model not trained on specialized industrial imagery; offline/on-prem serving required in secure facilities.
- Healthcare operations (non-diagnostic)
- Administrative support: policy lookup, non-clinical document summarization, triage of long EHR narratives for logistics and scheduling. Variants: 8B Instruct on-prem. Tools/workflows: care-coordination summaries. Assumptions: not for diagnostic use; HIPAA/GDPR compliance; validation on in-domain texts.
- Public sector and archives
- Large-scale digitization and summarization of public records with long-context inputs; multilingual citizen-facing information agents. Tools/workflows: FOIA document triage, multilingual portal Q&A. Assumptions: governance, redaction, accessibility requirements; audit logs for responses.
- MLOps, model engineering, and academic labs
- Cascade Distillation recipe adoption to compress in-house teacher models into efficient students for cost- and energy-aware serving. Tools/products: internal “distillation pipeline” that implements layer/hidden/FFN pruning and logit distillation. Assumptions: access to a capable teacher; calibration data; engineering for PCA-based rotations and pruning.
- ODPO alignment loops with pairwise reward modeling (PWRM), including heuristics to penalize infinite loops and stabilize learning. Tools/workflows: preference data collection tooling, evaluation harnesses. Assumptions: availability and quality of preference data; careful reward model calibration.
- Teacher-selection policies informed by “capacity gap” findings: pretraining benefits from smaller or post-trained teachers; post-training benefits from stronger, preference-tuned teachers. Workflows: systematic teacher-ablation experiments. Assumptions: compute for ablations; reproducible evaluation pipelines.
- Cost- and privacy-sensitive deployments
- On-prem and edge serving of 3B/8B models for low-latency, lower-cost inference with commercial-friendly licensing (Apache 2.0). Sectors: finance, healthcare, defense, manufacturing. Tools/workflows: containerized inference stacks; quantization for further footprint reduction. Assumptions: hardware with sufficient memory; secure network boundaries.
Long-Term Applications
The following opportunities are promising but require additional research, domain adaptation, safety validation, or infrastructure scaling.
- Healthcare clinical decision support and imaging
- Multimodal clinical copilots that integrate images, long EHR histories, and guidelines for diagnostic support. Dependencies: domain-specific training, regulatory approval, rigorous clinical validation, bias audits, and provenance tracking.
- Autonomous agents with robust tool use and long-horizon memory
- Complex multi-step planners that leverage 256K context for persistent memory across tasks (RPA for enterprise back office; scientific ELN synthesis; ops runbooks). Dependencies: reliable function calling, sandboxing, monitoring, and safeguards against cascading errors.
- Legal and financial automation beyond summarization
- Contract negotiation assistants, compliance rule formalization, and simulation of regulatory impacts over large corpora. Dependencies: legal oversight frameworks, test suites for correctness, strong retrieval + citation workflows, and explainability features.
- Industrial and robotics on-device reasoning
- Real-time, multimodal reasoning on embedded hardware for inspection, manipulation, or autonomous maintenance with small models (3B-class). Dependencies: latency guarantees, domain multimodal datasets, compression/quantization advances, and safety certification.
- Education at scale with adaptive, multilingual tutors
- Personalized curricula that adapt to student misconceptions, with controlled verbosity and verified solutions. Dependencies: robust verification (e.g., external graders/solvers), bias/fairness audits across languages and demographics, secure student-data handling.
- Scientific discovery copilots
- End-to-end research assistants that read entire literature corpora, propose hypotheses, design/assess experiments, and integrate multimodal lab data. Dependencies: domain-specific reasoning verifiers, structured knowledge integration, and human-in-the-loop gating for claims.
- Standardized, generalizable alignment pipelines
- Organization-wide ODPO/GRPO best practices with reusable PWRMs and temperature/beta calibration; automatic detection and mitigation of undesirable behaviors (e.g., infinite loops, over-verbosity). Dependencies: public benchmarks for alignment quality, open datasets for preferences, and governance for continuous updates.
- Distillation theory and automation
- Automated teacher selection and curriculum scheduling leveraging observed “capacity gap” and “post-trained teacher benefits,” extended to multi-teacher, multi-domain setups (incl. multilingual and multimodal). Dependencies: meta-training frameworks, compute for systematic ablations, and reproducible scaling laws.
- Long-context retrieval and compute-efficiency breakthroughs
- Production-grade RAG + 256K context hybrids with controllable attention scaling and inference costs. Dependencies: memory-efficient attention kernels, batching for long sequences, streaming and partial attention computation, and cost-aware orchestration.
- Privacy-preserving and federated distillation
- Federated Cascade Distillation to produce small students from distributed private corpora without centralizing sensitive data. Dependencies: secure aggregation, privacy accounting, legal compliance, and robustness to heterogeneous data quality.
- Multimodal expansion (audio, video, sensor data)
- Unified models that reason over text, images, audio, and time-series (e.g., call-center audio + screenshots; surveillance + maintenance logs). Dependencies: extended encoders, interleaving strategies, datasets and evaluation for temporal reasoning, and domain safety reviews.
Notes on Feasibility and Dependencies
- Compute/memory constraints: 3B/8B/14B models enable varied deployment targets; long-context (up to 256K) significantly increases memory and latency requirements. Quantization and careful batching are often necessary.
- Data governance: Preference data, reward models, and domain corpora must be licensed and curated. Sensitive data mandates on-prem serving and access controls.
- Safety and evaluation: For regulated domains (healthcare, finance, legal), human-in-the-loop validation, audit trails, and domain-specific benchmarks are essential; models are not a substitute for professional judgment.
- Multimodal limitations: The vision encoder was trained for general imagery; high-stakes or specialized visual domains likely need domain adaptation.
- Alignment and verbosity trade-offs: Reasoning depth versus verbosity must be tuned to application constraints (token budgets, UX); ODPO/GRPO pipelines help but require monitoring and continuous evaluation.
- Open-weight licensing: Apache 2.0 facilitates commercial use and derivative works, enabling rapid productization and integration into proprietary stacks.
Glossary
- Adapter: A trainable module that interfaces frozen components (e.g., a vision encoder) with the rest of the model. "Similar to the pretraining phase, the vision encoder remains frozen while the adapter is trainable."
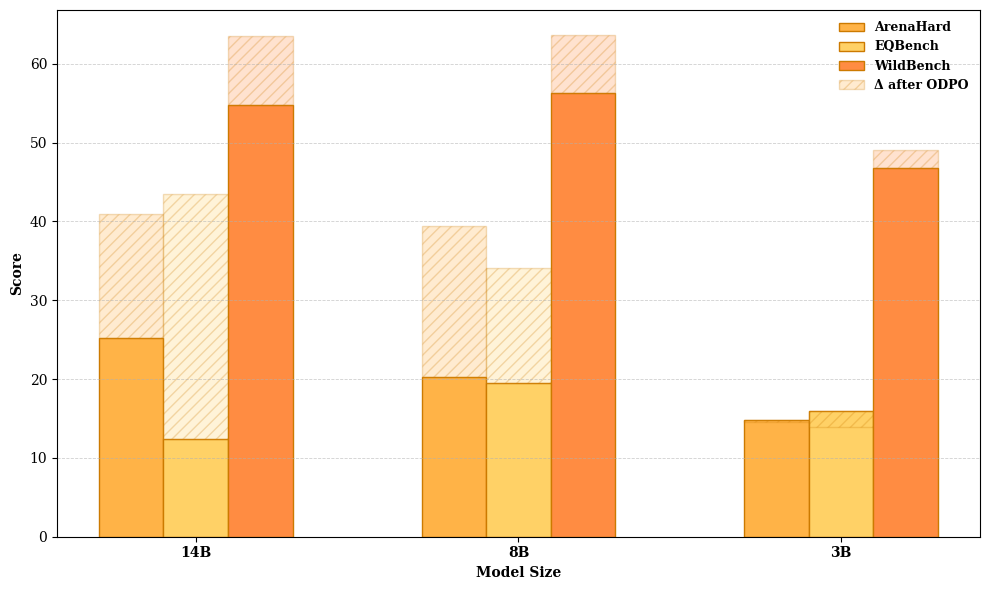
- Alignment benchmarks: Evaluation tasks that measure how well models align with human preferences and conversational quality. "As shown in Figure~\ref{fig:reasoning_odpo}, this significantly improved the 14B and 8B models on alignment benchmarks."
- Beta-rescaling technique: A method to rescale the DPO loss using a parameter to improve stability and invariance. "we employ a -rescaling technique, allowing for a more beta-invariant rescaling of dpo loss."
- Calibration batch: A large batch of inputs used to compute representative activations for pruning or calibration procedures. "We use input_x and output_x to refer to activations from a large calibration batch."
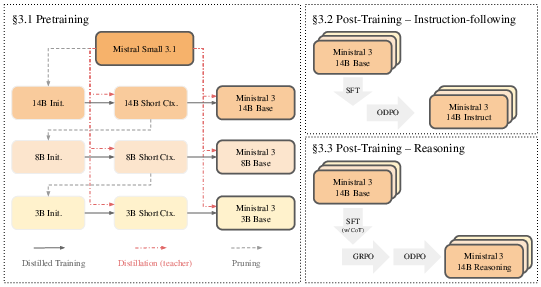
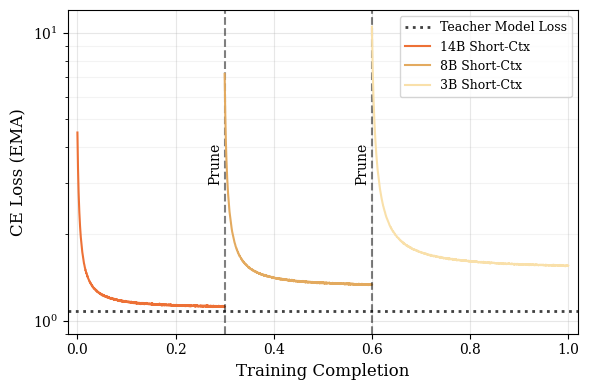
- Cascade Distillation: An iterative training strategy that prunes a large model and distills its knowledge into progressively smaller models. "A key component of Ministral 3 is our Cascade Distillation training strategy, an iterative pruning and distillation method, which progressively transfers pretrained knowledge from a large parent model down to a family of compact children models."
- Chain-of-thought (CoT): Training or inference traces that include the model’s step-by-step reasoning. "For reasoning, the process involved supervised fine-tuning with chain-of-thought data (SFT w/ CoT), Group Relative Policy Optimization (GRPO;~\citet{shao2024deepseekmathpushinglimitsmathematical}), and ODPO."
- Continual pretraining: Viewing the full pruning-and-distillation process as continued training of the parent model over time. "the end-to-end process can be viewed as a form of continual pretraining of the parent model with weight pruning."
- Decoder-only transformer architecture: A transformer variant that uses only decoder blocks to generate outputs autoregressively. "The Ministral 3 family is based on the decoder-only transformer architecture~\citep{vaswani2017attention}."
- Direct Preference Optimization (DPO): A training framework that aligns models to human preferences using pairwise comparisons without explicit reward modeling. "Direct Preference Optimization (DPO) \citep{rafailov2023dpo} offers a lightweight framework for human preference optimization by learning directly from offline pairwise preferences."
- Feedforward Dimension Pruning: Reducing the hidden dimensions of MLP layers based on importance scores to shrink model size. "Feedforward Dimension Pruning: For MLPs with gated-linear activation functions such as SwiGLU~\citep{shazeer2020glu}, expressed as given a very large batch , we prune dimension of the matrices ."
- FLOP efficiency: Training or inference efficiency measured in floating-point operations; fewer FLOPs for similar performance. "Compared to training each small model from scratch, Cascade Distillation produces a model that is significantly more FLOP efficient."
- fp8 quantization: Representing weights/activations in 8-bit floating point to reduce memory and improve throughput during fine-tuning. "We run SFT with fp8 quantization, using a logit distillation loss from a strong teacher."
- Forward KL distillation objective: Using the forward Kullback–Leibler divergence between teacher and student logits as the training objective. "We find that training with just the forward KL distillation objective outperforms tuning the coefficients of an objective that weights the distillation objective and the next token prediction objective differently."
- Gated-linear activation functions: MLP activations that multiply a gate and a linear transform, such as SwiGLU. "For MLPs with gated-linear activation functions such as SwiGLU~\citep{shazeer2020glu}, expressed as ..."
- Group Relative Policy Optimization (GRPO): A reinforcement learning method that optimizes policies based on grouped comparisons and relative rewards. "We perform GRPO~\citep{deepseekai2025deepseekr1} on top of the SFT checkpoint to refine the model's thinking and improve the performance further on reasoning tasks."
- Grouped Query Attention (GQA): An attention mechanism that groups query heads to improve efficiency with separate key-value heads. "Other architectural choices include Grouped Query Attention ~\citep{ainslie2023gqa} with 32 query heads and 8 key-value heads,"
- Hidden Dimension Pruning: Reducing the model’s hidden size by projecting activations into a lower-dimensional space while preserving variance. "Hidden Dimension Pruning: Apply Principal Component Analysis (PCA) to concatenated activations from attention normalization and feed-forward normalization layers across all layers."
- Inference-time scaling: Training and configuration approaches that enable the model to handle longer or more complex generations at inference. "We train the model for inference-time scaling using a three-stage pipeline composed of SFT, GRPO and ODPO, using the long-context pretrained checkpoint as the starting point."
- Layer Pruning: Removing less important transformer layers based on a proxy metric to reduce model depth. "Layer Pruning: Unlike \citet{sreenivas2024minitron}, which relies on counterfactual downstream perplexities from removing individual layers, we find that the ratio of input to output activation norms provides a simpler yet strong proxy for layer importance."
- LLM judge: An automated LLM used to assess and score generated responses according to rubrics. "During GRPO, an LLM judge evaluates each model rollout against these rubrics (e.g., faithfulness to the prompt, response quality) and the final reward is set to the fraction of satisfied heuristics."
- Logit distillation: Training the student to match the teacher’s output logits, transferring knowledge without labels. "Next, we continue pretraining the child model with logit distillation from the parent model as the teacher to obtain the up-trained short context child model (14B Short Ctx.)."
- Open-weight models: Models whose parameters are released publicly for use and study. "After post-training, we achieve competitive results with similarly sized open weight models such as Gemma~3 ~\citep{kamath2025gemma3technicalreport}, Qwen~3~\citep{yang2025qwen3technicalreport,bai2025qwen3vltechnicalreport}, and Mistral~Small~3.2~2506."
- Online Direct Preference Optimization (ODPO): The online variant of DPO that samples candidate outputs during training and optimizes using preference judgments. "For the Ministral 3 models, we adopt its online variant, Online Direct Preference Optimization (ODPO) \citep{guo2024directlanguagemodelalignment} where, for each example, we sample two candidate responses from the current policy with temperature , and use a text-based reward model to rank the responses."
- Pairwise Reward Model (PWRM): A learned model that scores pairs of responses to indicate preference probabilities. "This method relies on a Pairwise Reward Model (PWRM) to dynamically rank candidate responses."
- Pass@k: A code-evaluation metric reporting whether any of k sampled solutions pass tests. "To reduce variance, we report pass@16 except LiveCodeBench which is evaluated using pass@5."
- Position-based softmax temperature scaling: Adjusting the attention softmax temperature as a function of position to support long-context stability. "For long-context extension, we use YaRN ~\citep{peng2023yarn} and position-based softmax temperature scaling in the attention layer ~\citep{nakanishi2025scalable, meta2025llama4}."
- Principal Component Analysis (PCA): A linear dimensionality-reduction method used to find a lower-dimensional rotation that preserves variance. "Apply Principal Component Analysis (PCA) to concatenated activations from attention normalization and feed-forward normalization layers across all layers."
- Projection layer: A learned linear mapping that transforms vision features into the LLM’s embedding space. "We discard the pretrained projection layer from the ViT to LLM's space and train a new projection for every model."
- Prune-distill-repeat approach: An iterative process of pruning a model and distilling knowledge repeatedly to smaller targets. "it relies on an iterative ``prune-distill-repeat'' approach:"
- RMSNorm: A normalization technique that scales activations by their root mean square instead of mean and variance. "Other architectural choices include Grouped Query Attention ... SwiGLU activation~\citep{shazeer2020glu}, and RMSNorm~\citep{zhang2019root}."
- RoPE positional embeddings: Rotary position embeddings that encode token position through rotations in feature space. "RoPE~\citep{su2021roformer} positional embeddings,"
- SiLU: The Sigmoid Linear Unit activation function used inside gated MLPs. "expressed as given a very large batch "
- Supervised Fine-Tuning (SFT): Fine-tuning with labeled instruction-following data to improve adherence and quality. "The fine-tuning phase also consists of two stages: Supervised Fine-Tuning (SFT) and Online Direct Preference Optimization (ODPO)."
- SwiGLU activation: A gated activation that multiplies a SiLU gate with a linear transform, improving MLP capacity. "Other architectural choices include Grouped Query Attention ... SwiGLU activation~\citep{shazeer2020glu}, and RMSNorm~\citep{zhang2019root}."
- Tied input-output embeddings: Sharing the same embedding matrix for both token input and output logits to reduce parameters. "The 3B model uses tied input-output embeddings to avoid embedding parameters dominating the overall parameter count."
- Tool execution: Allowing the model to call external tools or functions during generation for improved performance. "Finally, we enable tool execution during generation, which improves the model’s tool-use performance."
- Vision Transformer (ViT): A transformer-based encoder for images used to provide multimodal understanding. "All Ministral 3 models use a 410M parameter ViT as a vision encoder for image understanding that is copied from Mistral Small 3.1 Base and kept frozen,"
- YaRN: A method for extending rotary embeddings to longer contexts via interpolation/rescaling strategies. "For long-context extension, we use YaRN ~\citep{peng2023yarn} and position-based softmax temperature scaling in the attention layer ~\citep{nakanishi2025scalable, meta2025llama4}."
Collections
Sign up for free to add this paper to one or more collections.