BabyVision: Visual Reasoning Beyond Language
Abstract: While humans develop core visual skills long before acquiring language, contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding. We uncovered a crucial fact: state-of-the-art MLLMs consistently fail on basic visual tasks that humans, even 3-year-olds, can solve effortlessly. To systematically investigate this gap, we introduce BabyVision, a benchmark designed to assess core visual abilities independent of linguistic knowledge for MLLMs. BabyVision spans a wide range of tasks, with 388 items divided into 22 subclasses across four key categories. Empirical results and human evaluation reveal that leading MLLMs perform significantly below human baselines. Gemini3-Pro-Preview scores 49.7, lagging behind 6-year-old humans and falling well behind the average adult score of 94.1. These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives. Progress in BabyVision represents a step toward human-level visual perception and reasoning capabilities. We also explore solving visual reasoning with generation models by proposing BabyVision-Gen and automatic evaluation toolkit. Our code and benchmark data are released at https://github.com/UniPat-AI/BabyVision for reproduction.

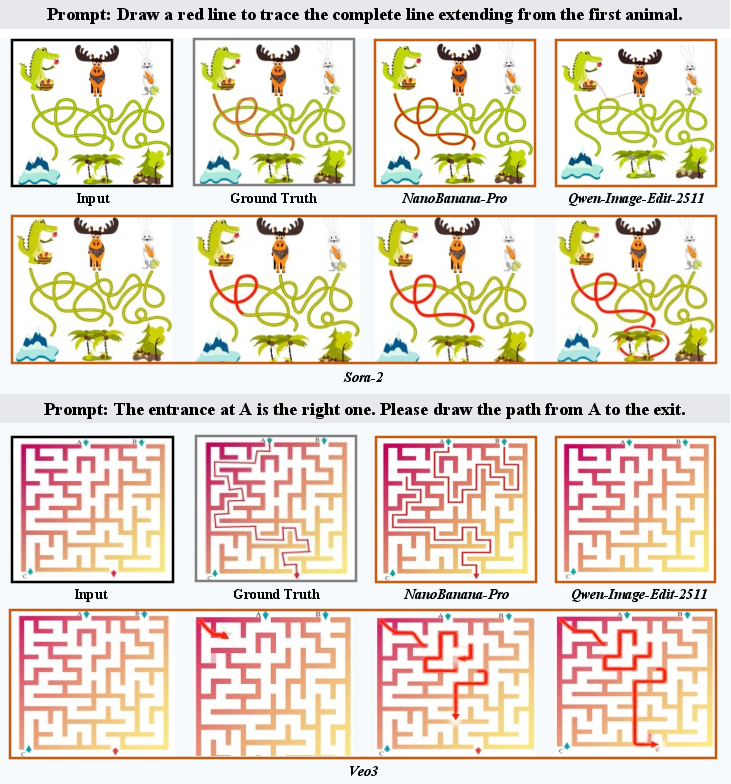

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces BabyVision, a set of tests (a “benchmark”) that checks whether AI systems that look at pictures and read text (called Multimodal LLMs, or MLLMs) can handle very basic visual skills—things like spotting tiny differences, following a line through a maze, imagining 3D shapes, or recognizing simple patterns.
Humans learn these visual skills as toddlers, before they learn to read or use language well. The authors show that today’s top AI systems, even though they’re great at high-level, school-like problems, still struggle with these simple, early visual abilities.
The paper also presents BabyVision-Gen, a version of the test where models answer by drawing on or generating images, not by writing words—because humans often solve these tasks by sketching or tracing rather than talking.
What questions did the researchers ask?
They focused on a few simple, big questions:
- Do today’s leading AI models have the same basic visual understanding that young children do?
- Which early visual skills are hardest for these models?
- Can image generation (drawing/marking answers) help models show what they “see,” instead of forcing them to explain everything in words?
How did they study it?
The authors built a careful, child-inspired test set and compared many AI models to humans (kids and adults). Here’s how they did it.
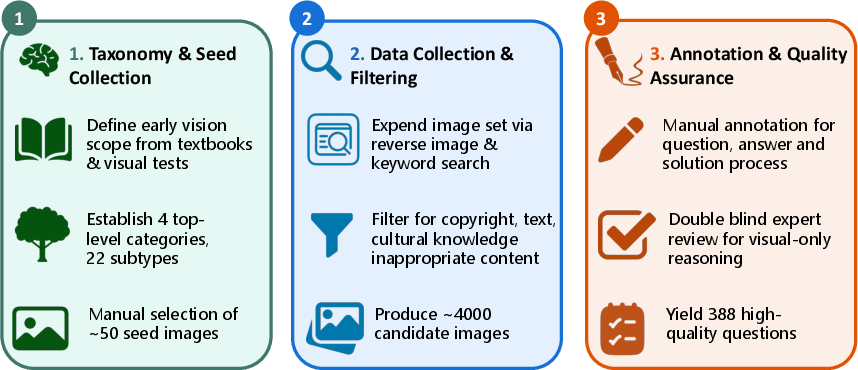
Building the BabyVision benchmark
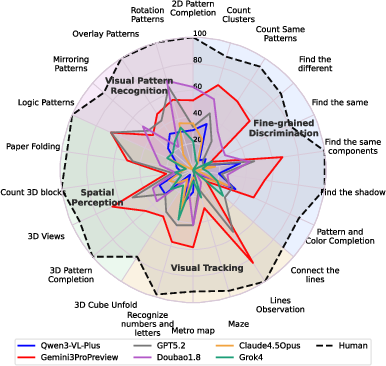
They designed BabyVision to target four kinds of early visual skills. Each is something kids usually handle without much language:
- Fine-grained Discrimination: spotting small visual differences, matching a shape to its shadow, completing a picture with the right piece.
- Visual Tracking: following lines through crossings, tracing paths in mazes, keeping track of which curve is which when they intersect.
- Spatial Perception: understanding 3D shapes, folding/unfolding paper patterns in your mind, counting blocks you can and can’t see.
- Visual Pattern Recognition: noticing simple rules like rotation, mirroring, overlaying shapes, or logic-style picture patterns.
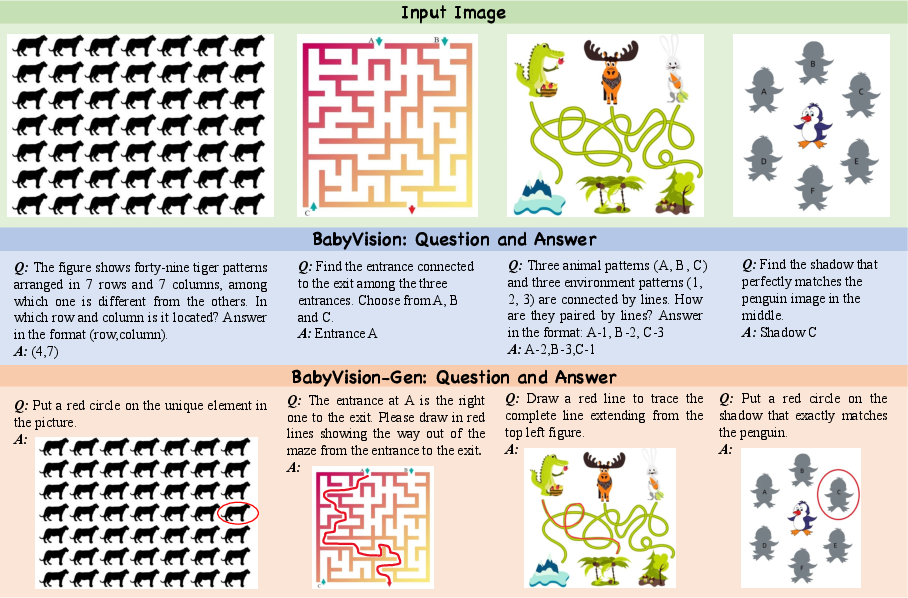
BabyVision contains 388 image-based questions split into 22 subtypes across these four categories. To make sure the tasks truly test vision (not language or general knowledge), they:
- Started with examples from children’s materials and developmental tests.
- Collected similar images online, removing anything that needed reading or cultural knowledge.
- Wrote precise questions and answers, plus a short “how to solve it” explanation.
- Used double-blind expert reviews so each question had a single, clear answer based mostly on looking, not reading.
Testing models and people
- They evaluated many top AI models using a standard prompt and checked their answers.
- For fairness and consistency, they used an automated judge (another LLM) to see if an answer matched the correct one; in their checks, this judge agreed with humans very reliably.
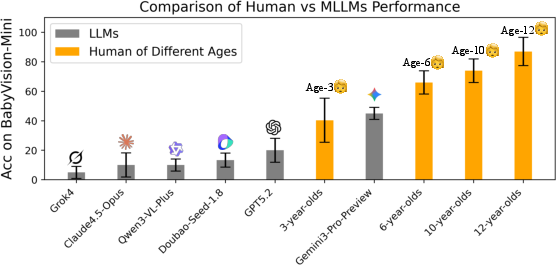
- They also tested people: a group of adults took the full test, and groups of children (ages 3, 6, 10, 12) took a shorter, representative version.
BabyVision-Gen: answering by drawing
Because humans often solve these problems by drawing (e.g., tracing a maze), the authors made BabyVision-Gen: 280 questions where the “answer” is a generated image (like circling the difference or drawing the right path). They created an automatic image judge that compares a model’s drawn answer to a human-drawn solution, and it agreed with human graders about 96% of the time.
What did they find?
Here are the main results, explained simply:
- Big human–AI gap on basic vision: Adult humans scored about 94% on BabyVision. The best AI model scored around 50%. In a pilot with kids, even 6-year-olds did noticeably better than the top model on the mini test.
- Struggles with tracking and spatial thinking:
- Visual Tracking: Many models can’t follow a single line through crossings without “jumping” to a different one—something people find easy.
- Spatial Perception: Counting 3D blocks (including hidden parts) and imagining paper folds were especially hard. Models struggle to form a clear 3D picture in their “mind’s eye.”
- Not just one weak spot: Models were weaker than humans across all four categories, not just in a single type of task.
- Patterns vs. perception: Models did relatively better on rule-like pattern tasks (e.g., rotations), where simple logic can help. But they still fell far short of human levels, especially when the task needs continuous, precise visual understanding.
- Generation helps a bit, but not enough: In BabyVision-Gen (where models “answer” by drawing), the best image generator got about 18%. Some tasks that naturally fit drawing (like “find the difference”) saw modest improvements, but tracking paths (like mazes) remained extremely tough.
Why this matters: The results suggest that current AI systems often lean on language and learned shortcuts. They can pass expert-style tests that allow text-based reasoning, but they lack the “visual primitives” that humans build early in life—like tracking a curve or building a mental 3D model—even without words.
Why does this matter?
- Better vision before better reasoning: Just like toddlers need basic vision to make sense of the world, AI needs strong foundational visual skills to be trustworthy in real-life tasks (e.g., robotics, navigation, education, assistive tech).
- Benchmarks can be misleading: Some popular tests let models guess using language cues, so they may look smart without truly “seeing.” BabyVision forces models to rely on vision, revealing what’s missing.
- New training and tools needed: Simply making models bigger or asking them to “think step by step” isn’t enough. We likely need new training methods and representations that help models keep track of shapes, paths, and 3D structure.
- Drawing as a second language: Letting models answer by drawing (not just writing) is a promising direction. Humans often solve visual problems this way, and it may help AI show visual understanding more directly.
Key takeaways
- The paper introduces BabyVision to measure basic, pre-language visual skills in AI.
- Today’s top models score far below humans (including young kids) on these skills.
- Visual tracking and 3D spatial perception are especially challenging for AI.
- BabyVision-Gen shows that answering by drawing can help reveal visual reasoning, but current generation models are still far from human-level.
- Closing this gap is essential for AI that truly understands the visual world, not just the words about it.
Knowledge Gaps
Unresolved gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper—framed so future researchers can act on it.
- Benchmark scope and size: With 388 items across 22 subtypes, several subtypes have very few instances; no item-response reliability (e.g., Cronbach’s alpha, IRT) or difficulty calibration is reported. Expand per-subtype coverage and provide psychometric analyses to validate internal consistency and item discrimination.
- Generalizability of human baselines: Child testers come from a single school population (20 per age group) and adults from a small sample (n=16). Replicate across diverse cultural, linguistic, and socio-economic contexts, and report effect sizes and confidence intervals.
- Language leakage controls: Despite aiming to minimize language priors, there is no ablation where models are evaluated with (i) image masked/removed, (ii) shuffled tasks/options, or (iii) adversarial textual prompts to quantify leakage. Add text-only and image-perturbation baselines.
- Residual linguistic demands: Tasks like “Recognize Numbers and Letters” may involve symbolic/language recognition. Audit and tag items by linguistic dependency; create a strictly pre-linguistic subset and re-report results.
- Image resolution and pre-processing: The paper does not analyze sensitivity to input resolution, cropping, aspect ratio, or compression. Systematically vary these factors to identify failure thresholds and encoder bottlenecks.
- Architectural and pretraining ablations: No controlled study disentangles the roles of the vision encoder, fusion module, and decoder (e.g., CLIP variants, patch size, positional encoding). Run architecture-level ablations to localize deficits.
- Training influence is underspecified: The paper mentions 1,400 training examples to study “training influence” (Section referenced as subsec:training) but provides no results or protocol. Report fine-tuning setups, data splits, overfitting checks, and performance deltas.
- Judge reliability and transparency (text answers): Qwen3-Max is used as an LLM-as-judge with a claim of 100% agreement with humans, but the sample size, rubric, and inter-rater stats are not detailed. Publish judge prompts, calibration sets, agreement metrics, and evaluate multiple independent judges.
- Judge reliability (generation outputs): Gemini-3-Flash judge achieves 96% agreement on NanoBanana-Pro outputs only; generalization across other models and subtypes is not shown. Validate judge consistency across all generators, add pixel/geometry-based metrics (IoU for overlays, path-edit distance for mazes).
- Metric design for continuous tasks: Accuracy alone may hide near-miss solutions (e.g., maze paths). Introduce topology-aware, continuous metrics (path correctness, line continuity, occlusion consistency) to better capture partial competence.
- Contamination risk from web-crawled images: Many items are internet-sourced; closed models may have trained on similar content. Quantify potential training-data overlap and assess contamination effects with provenance checks and de-duplication against known pretraining corpora.
- Temporal vision is under-evaluated: Visual tracking tasks are static; purported video generators (e.g., Sora-2) are mentioned but not evaluated. Add dynamic/temporal tasks (occlusion-through-time, moving-object identity) with video inputs/outputs.
- Tool-augmented reasoning: Humans “draw to think,” but MLLMs were not given interactive tools (e.g., canvas, vector overlays, segmentation pointers). Test whether tool-use (pointer outputs, stepwise annotations) improves performance relative to pure language output.
- Prompt sensitivity and consistency: A single unified prompt is used; no prompt ablations (e.g., structured reasoning scaffolds, visual-step prompts, constrained answer formats). Run prompt studies to quantify sensitivity and reduce variance.
- Fairness across scripts and symbols: “Recognize Numbers and Letters” may favor Latin-script-trained systems. Evaluate across scripts (Arabic, Devanagari, Chinese) or exclude language-dependent tasks for pre-linguistic evaluation.
- Cross-benchmark correlation: The paper asserts an “inverted competence profile” but does not quantify correlations between BabyVision and standard multimodal benchmarks (e.g., MMMU, MathVista). Compute cross-benchmark correlations to substantiate the claim and guide model development.
- Failure mode taxonomy: Errors (e.g., “loss of manifold identity”) are noted qualitatively but not systematically categorized. Build a fine-grained error taxonomy per subtype and publish labeled failure cases to target specific remedies.
- Consistency across runs and seeds: Results are reported as Avg@3 with small variances, but run-to-run consistency across broader seeds and model versions is not shown. Provide robustness analyses with more seeds and report confidence intervals.
- Model comparability and budget control: “Reasoning effort” is set to maximum where available, but budgets likely differ across vendors. Normalize computation (tokens, steps, time) to ensure fair comparisons.
- Generative evaluation format: BabyVision-Gen requires minimal overlays, yet many generators failed on trajectory maintenance. Test alternative interfaces (vector drawing, constrained annotation tools) and hybrid pipelines combining perception modules with structured renderers.
- External validity to real-world tasks: Items are curated and somewhat synthetic; applicability to real-world perception (e.g., robotics, surgical navigation, autonomous driving micro-skills) is not measured. Add downstream transfer studies or proxies.
- Dataset documentation and licensing: While copyright adherence is claimed, detailed licensing, image provenance, and data cards (intended use, known biases) are not provided. Publish comprehensive documentation to support ethical reuse.
- Age-stage mapping: Tasks are justified by developmental literature, but there is no formal mapping from subtypes to developmental milestones. Provide stage-annotated items and test whether performance curves align with known developmental timelines.
- Intervention efficacy: RLVR training and generative modeling are mentioned as potentially helpful but lack rigorous controlled trials. Run controlled experiments comparing RLVR, contrastive pretraining on synthetic primitives, curriculum learning, and spatial memory modules.
- Multimodal output synergy: MLLMs that both “see and draw” (image editing tools within an LLM) were not evaluated. Assess whether joint text+overlay outputs improve accuracy and interpretability relative to text-only or gen-only systems.
- Robustness to perturbations: No tests on noise, clutter, occlusion level, distractor density, or viewpoint changes. Introduce controlled perturbation suites per subtype to quantify robustness thresholds and failure gradients.
Practical Applications
Immediate Applications
Below is a concise set of actionable use cases that leverage the paper’s benchmark, evaluation tools, and insights, organized by sector. Each item includes potential tools/workflows and feasibility assumptions.
- Early-vision audit for multimodal systems in production (software, robotics, automotive)
- Application: Integrate BabyVision as a pre-deployment and regression test suite to gate releases of MLLMs or vision agents used for tasks involving visual discrimination, tracking, and spatial reasoning (e.g., UI parsing, assembly line assist, lane/route-following).
- Tools/workflows: CI integration of BabyVision with LLM-as-judge; threshold-based gating; “think mode” toggles and prompt standardization.
- Assumptions/dependencies: Access to model APIs and images; acceptance that BabyVision scores are predictive of basic visual competence; human-in-the-loop oversight remains necessary given current performance gaps.
- “Show-your-work” visual annotation in human-in-the-loop workflows (software, HCI)
- Application: Adopt BabyVision-Gen-style prompting to require models to annotate input images (trace paths, mark differences, highlight spatial relations) rather than only verbalizing reasoning, improving operator trust and error discoverability.
- Tools/workflows: Visual overlay pipelines; automatic judge module for alignment to ground truth; UI components for layered annotations.
- Assumptions/dependencies: Models must support image-edit or overlay generation; workflows accept partial/low-accuracy outputs; evaluation via the paper’s automatic judge (≈96% agreement) is acceptable for QA.
- Vendor due diligence and procurement benchmarking (policy, enterprise IT)
- Application: Include BabyVision scores and breakdowns (four domains, 22 subtypes) in AI vendor evaluation and transparency reports to detect over-reliance on language priors and prevent deployment in visually fragile use cases.
- Tools/workflows: RFP checklists; standardized benchmark reporting; risk matrices tied to domain-specific thresholds.
- Assumptions/dependencies: Benchmark adoption by buyers and vendors; public comparability of model versions; understanding that high MMMU/HLE scores don’t imply strong early-vision capacity.
- Academic diagnostics for model training and ablation (academia, ML research)
- Application: Use BabyVision to pinpoint failure modes (e.g., occlusion/3D counting, curve identity through intersections) in experiments on scaling, test-time thinking, RLVR, and architectural variants.
- Tools/workflows: Per-subtype ablations; curriculum design around weak subtypes; training data augmentation focused on early-vision primitives.
- Assumptions/dependencies: Availability of training/validation splits (the paper mentions 1,400 training examples) and reproducible pipelines.
- Educational puzzles and visual reasoning apps (education, consumer apps)
- Application: Embed BabyVision-like tasks in learning apps that train and assess visual pattern recognition and tracking for students, with adaptive difficulty and non-verbal solution modes.
- Tools/workflows: Item banks aligned to subtypes; annotation-based feedback; telemetry for skill progression.
- Assumptions/dependencies: Licensing of tasks/data; careful age-appropriate adaptation; avoid using current MLLMs as tutors for tasks they fail without guardrails.
- Model selection and prompt policy for vision-heavy agents (software, product management)
- Application: Use BabyVision scores to select models for vision-critical features; prefer models with higher tracking/spatial scores and enforce “reasoning effort” settings shown to help.
- Tools/workflows: Prompt templates from the paper; “reason-and-answer” formats; policy to switch to visual outputs when applicable (BabyVision-Gen style).
- Assumptions/dependencies: Differences across model versions persist; operational cost of high reasoning budgets is acceptable.
- Safety guardrails for image generators used in analysis (software, creative tools)
- Application: If a workflow depends on image generators to reason (e.g., trace pathways, mark parts), insert the paper’s automatic judge to reject or flag inconsistent outputs before human review.
- Tools/workflows: Dual-image comparison (input, model output) vs. reference template; subtype-specific criteria; dashboarding of agreement rates.
- Assumptions/dependencies: Reference solutions or proxy templates available; judge generalizes to domain-specific tasks; reviewers validate edge cases.
Long-Term Applications
Below are forward-looking applications that require further research, scaling, validation, and/or standardization before broad deployment.
- Pre-linguistic visual modules and training curricula (software, robotics, ML research)
- Application: Develop architectures and training regimes that explicitly target early visual primitives (object permanence, occlusion-aware counting, curve identity tracking, 3D mental transformation) to narrow the human–model gap.
- Tools/workflows: Modular vision backbones specialized for early-vision; curriculum and RLVR training centered on BabyVision subtypes; synthetic data expansion with generative supervision.
- Assumptions/dependencies: New datasets and tasks beyond BabyVision; robust evaluation linking improvements to downstream reliability; compute and scaling budgets.
- Certified “Visual Core Competency” standards (policy, compliance, safety-critical sectors)
- Application: Establish certification regimes that mandate performance thresholds on early-vision benchmarks prior to deployment in safety-critical contexts (e.g., healthcare triage, industrial inspection, autonomous systems).
- Tools/workflows: Sector-specific thresholds and stress tests; independent test labs; periodic recertification tied to model updates.
- Assumptions/dependencies: Multi-stakeholder consensus; regulatory acceptance; mapping benchmark performance to real-world risk reduction.
- Robust visual reasoning for autonomous systems (robotics, automotive, drones)
- Application: Leverage improved early-vision capabilities for reliable path following through intersections, occlusion handling, and spatial imagination in navigation and manipulation tasks.
- Tools/workflows: Visual-tracking controllers; 3D scene representations with identity persistence; hybrid pipelines combining geometric modules and learned perception.
- Assumptions/dependencies: Demonstrated gains on BabyVision-like tasks translate to embodied performance; tight integration with SLAM/controls; rigorous field testing.
- Medical and industrial visual QA assistants (healthcare, manufacturing, energy)
- Application: Use future models with strong early-vision skills to assist in basic visual QA tasks (e.g., counting/locating structures under occlusion, pattern/difference detection in scans or inspections) before expert review.
- Tools/workflows: Overlay-based “show-your-work” annotations; discrepancy flags; human validation workflows.
- Assumptions/dependencies: Clinical/industrial validation; domain adaptation; robust fail-safe escalation; adherence to privacy and safety standards.
- Child development and cognitive assessment tools (education, public health)
- Application: Build validated digital assessments for visual development that mirror BabyVision subtypes, with adaptive difficulty and non-verbal response capture.
- Tools/workflows: Standardized tests; longitudinal tracking; teacher/clinician dashboards; ethical data governance.
- Assumptions/dependencies: IRB approvals; cross-cultural validation; accessibility and fairness considerations; guardrails against misuse.
- Visual “chain-of-sight” compliance in regulated sectors (finance, legal, governance)
- Application: Require models to produce visual evidence trails (annotation overlays tied to decisions), enabling auditability and post-hoc review of image-based judgments.
- Tools/workflows: Provenance tracking for annotations; immutable logs; automated and human audits using BabyVision-Gen-inspired criteria.
- Assumptions/dependencies: Accepted standards for explainability; integration with case management systems; privacy-preserving storage.
- AR/VR spatial reasoning co-pilots (software, design, architecture)
- Application: Create assistants that reliably perform mental rotations, unfoldings, and overlay reasoning on 3D scenes, aiding design reviews and digital twins.
- Tools/workflows: Real-time annotation layers; consistency checks (overlay/mirroring/rotation subtypes); multi-view coherence scoring.
- Assumptions/dependencies: Substantial advances in spatial perception scores; tight integration with 3D engines; latency and user experience optimization.
- Synthetic data generation and auto-evaluation loops (ML tooling)
- Application: Use BabyVision-Gen and automatic judging to generate, filter, and grade large-scale early-vision training data, bootstrapping better visual reasoning without excessive human labeling.
- Tools/workflows: Generator–judge–curator pipelines; subtype-specific criteria; active learning.
- Assumptions/dependencies: Reliability of auto-judging at scale; avoidance of generator–judge collusion; monitoring for mode collapse and shortcut learning.
These applications collectively operationalize the paper’s main contributions: a benchmark for early visual abilities (BabyVision), a generative evaluation paradigm (BabyVision-Gen), and an automatic judge that enables scalable assessment. They also internalize key findings—namely, that strong language-driven performance does not imply robust visual competence—and redirect product, research, and policy decisions toward developing and verifying foundational visual reasoning.
Glossary
- Avg@3: An evaluation metric reporting average accuracy across three runs for a model. "We report the Avg@3 results for all evaluated models."
- BabyVision-Gen: A generative extension of the benchmark that evaluates visual reasoning via image generation rather than textual answers. "we introduce BabyVision-Gen, a generative counterpart to BabyVision that evaluates visual reasoning through visual generation beyond language output."
- Compositional 3D counting: Counting objects or units in three dimensions by composing visible and hidden parts, often under occlusion and perspective changes. "compositional 3D counting under occlusion and viewpoint variation remains difficult."
- Core knowledge hypothesis: A theory in developmental psychology positing innate systems for representing fundamental concepts like objects, space, and numbers. "The core knowledge hypothesis~\citep{spelke2000core} posits innate systems for representing objects, space, numbers, and agents---capacities that are independent of linguistic mediation."
- Double-blind review: A quality assurance process where two independent reviewers assess annotations without knowing each other’s identities to reduce bias. "All annotations then pass through a double-blind review: two independent experts verify that the answer is unambiguous and derivable largely from visual analysis rather than language."
- Language leakage: The phenomenon where benchmark performance reflects exploitation of textual cues rather than genuine visual understanding. "exposing severe language leakage and over-reliance on textual shortcuts."
- Linguistic priors: Pre-existing language-based biases or knowledge that models use to interpret inputs, sometimes compensating for weak perception. "contemporary Multimodal LLMs (MLLMs) still rely heavily on linguistic priors to compensate for their fragile visual understanding."
- LLM-as-judge: An evaluation method that uses a LLM to assess whether a model’s output matches the ground truth. "We evaluate model responses using an LLM-as-judge approach."
- Manifold identity: The continuity of an entity (e.g., a curve) along its path in a manifold-like structure; losing it causes track-switching errors. "loss of manifold identity (e.g., losing track of curves through intersections)"
- Monotonic improvement: A consistent, non-decreasing performance gain as scale or training increases. "scaling alone does not guarantee monotonic improvement on these fundamental perceptual tasks."
- Multimodal LLMs (MLLMs): LLMs that can process and reason over multiple input modalities, such as text and images. "The rapid progress of Multimodal LLMs (MLLMs) has driven the development of diverse evaluation benchmarks."
- Object permanence: The understanding that objects continue to exist even when they are not visible. "Infants demonstrate object permanence by 3--4 months~\citep{baillargeon1985object}"
- Occlusion: A visual condition where an object is partially blocked by another, requiring inference of hidden parts. "track objects through occlusion~\citep{johnson2010development}"
- Pass@1 accuracy: The probability that a model’s first sampled answer is correct, often averaged across runs. "Reported values represent the average Pass@1 accuracy across three random runs, accompanied by the standard deviation."
- Perceptual primitives: Basic, low-level elements of visual perception (e.g., edges, shapes) that underpin higher-level recognition. "exposing severe language leakage and over-reliance on textual shortcuts. MMVP~\citep{mmvp} further probes visual limitations and finds that models fail to distinguish images with clear perceptual differences. These findings reveal a recurring blind spot: existing benchmarks predominantly draw from tasks designed for adult experts and rely on semantic recognition rather than perceptual primitives."
- Pre-linguistic visual abilities: Foundational visual competencies that develop before language acquisition. "BabyVision addresses this gap by targeting pre-linguistic visual abilities---the foundational competencies humans develop before language acquisition---and comparing model performance directly to children aged 3--12."
- Reasoning budget: A model’s allocation of computational or generative steps for reasoning during inference. "All models are in thinking model with highest reasoning budget."
- RLVR training: A reinforcement-learning-oriented training regime aimed at improving visual reasoning (name used by authors). "We further provide fine-grained analyses of failure patterns at both the domain and subclass levels, and investigate how RLVR training and generative modeling contribute to improved visual reasoning performance."
- Semantic equivalence: The condition where two answers convey the same meaning even if phrased differently. "we query Qwen3-Max to determine semantic equivalence, which shows 100\% consistency with human evaluators."
- Spatial imagination: The ability to mentally transform and manipulate spatial structures in 2D/3D. "a failure of spatial imagination (e.g., the inability to mentally transform 3D structures)."
- Structured scene representations: Organized internal models of a scene capturing objects, relations, and spatial configurations. "Such failures are informative because they reflect deficiencies in structured scene representations (e.g., object permanence and depth-aware composition), rather than shortcomings in recognition or superficial pattern matching."
- Test-time thinking: Using explicit intermediate reasoning during inference to improve performance. "Test-time thinking consistently provides measurable gains: within the Qwen3VL family, the Thinking variants outperform their Instruct counterparts"
- Viewpoint transformation: Mapping the appearance of objects across different camera or observer viewpoints. "the viewpoint transformation can be partially reasoned through geometric rules."
- Viewpoint variation: Changes in the viewing angle or perspective that affect how 3D structures appear. "compositional 3D counting under occlusion and viewpoint variation remains difficult."
- Visual primitives: Fundamental components of visual processing that support higher-level vision tasks. "These results show despite excelling in knowledge-heavy evaluations, current MLLMs still lack fundamental visual primitives."
Collections
Sign up for free to add this paper to one or more collections.