MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos
Abstract: Motion capture now underpins content creation far beyond digital humans, yet most existing pipelines remain species- or template-specific. We formalize this gap as Category-Agnostic Motion Capture (CAMoCap): given a monocular video and an arbitrary rigged 3D asset as a prompt, the goal is to reconstruct a rotation-based animation such as BVH that directly drives the specific asset. We present MoCapAnything, a reference-guided, factorized framework that first predicts 3D joint trajectories and then recovers asset-specific rotations via constraint-aware inverse kinematics. The system contains three learnable modules and a lightweight IK stage: (1) a Reference Prompt Encoder that extracts per-joint queries from the asset's skeleton, mesh, and rendered images; (2) a Video Feature Extractor that computes dense visual descriptors and reconstructs a coarse 4D deforming mesh to bridge the gap between video and joint space; and (3) a Unified Motion Decoder that fuses these cues to produce temporally coherent trajectories. We also curate Truebones Zoo with 1038 motion clips, each providing a standardized skeleton-mesh-render triad. Experiments on both in-domain benchmarks and in-the-wild videos show that MoCapAnything delivers high-quality skeletal animations and exhibits meaningful cross-species retargeting across heterogeneous rigs, enabling scalable, prompt-driven 3D motion capture for arbitrary assets. Project page: https://animotionlab.github.io/MoCapAnything/




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces a new way to capture and reuse motion from a regular video to animate any 3D character, not just humans. The method is called MoCapAnything, and it can take a single-camera video (monocular video) plus a 3D character (with its skeleton/rig) and produce a smooth, ready-to-use animation that fits that character’s own joints and rules.
What are the main goals?
The paper aims to solve motion capture for “anything,” not just a fixed group like humans or dogs. In simple terms, the goals are:
- Make motion capture work for any kind of 3D character (animals, robots, creatures, toys), even if their skeletons are very different.
- Allow motion retargeting, which means taking motion from one video and applying it to a different 3D character.
- Keep the motion smooth and realistic over time, not jittery frame-by-frame.
- Bridge the gap between video pixels (what you see) and 3D joint positions (where the character’s bones should be).
How does it work?
Think of the system as a motion translator. It looks at a video of something moving and a 3D character you want to animate, and then translates the motion onto that character. It does this in four main steps:
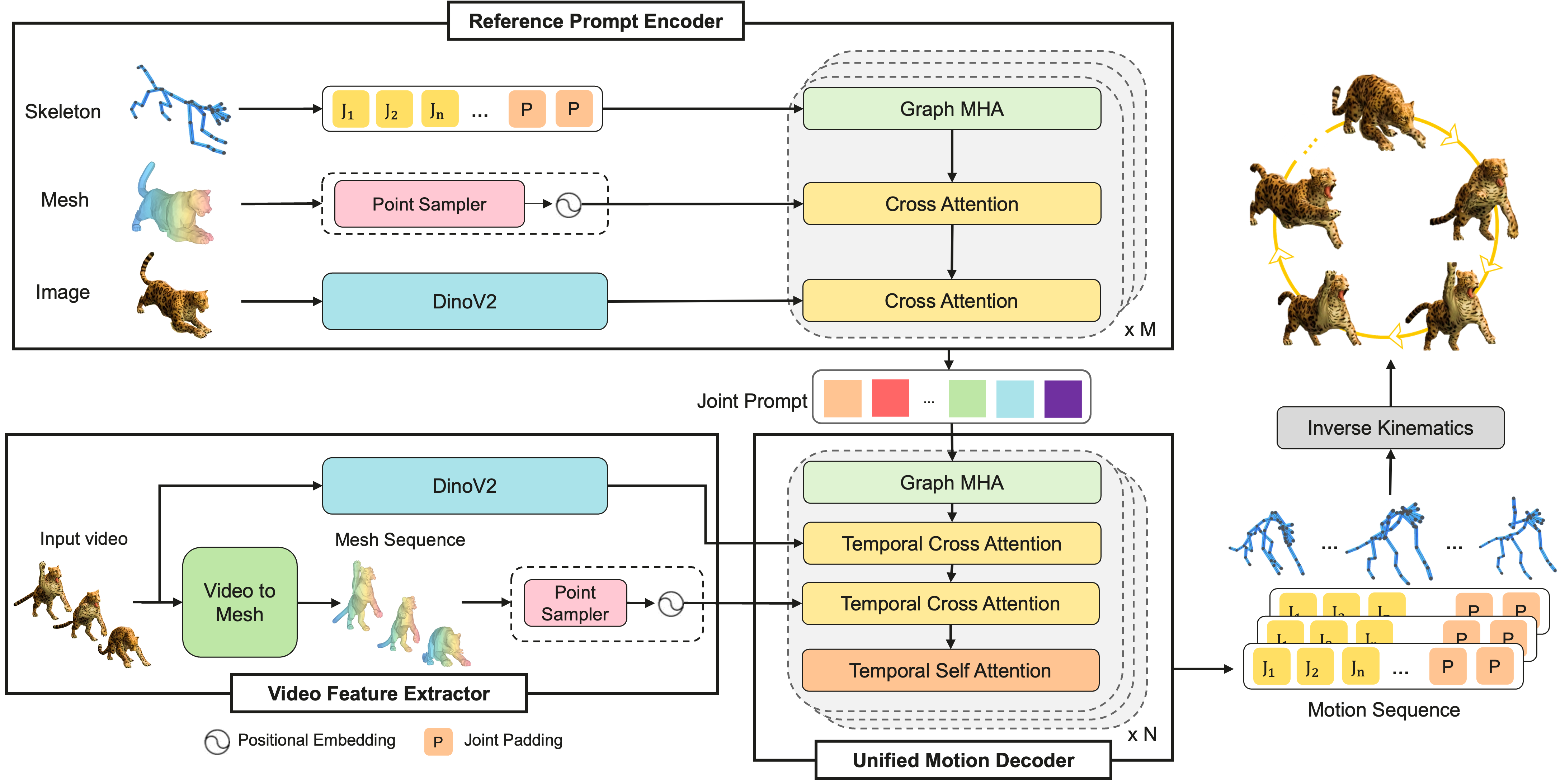
- Reference Prompt Encoder: This reads the 3D character you want to animate. It looks at:
- The character’s skeleton (like a stick figure of its bones and joints).
- The character’s mesh (the 3D surface/shape).
- Pictures or renders of the character (to recognize parts like left vs. right).
- It turns all of this into smart “per-joint queries,” which are like instructions for each joint telling the system how this specific character is built.
- Video Feature Extractor: This analyzes the input video. It pulls out useful visual features and also builds a rough “4D mesh” from the video. 4D here means 3D shape across time, like a clay model that changes shape as it moves. This helps the system understand depth and structure, not just colors and edges.
- Unified Motion Decoder: This is the brain that combines the character info and the video info. It predicts where each joint should be in 3D space at every frame, creating a smooth path for each joint over time. You can picture this like drawing a GPS route for every bone from one moment to the next.
- IK Fitting (Inverse Kinematics): Once the system knows where the joints should be, it figures out the rotations for each joint (how much to twist or bend) so the character reaches those positions correctly. IK is a bit like solving how to bend your elbow and shoulder to place your hand at a precise spot, without breaking any joint rules. It respects:
- Bone lengths (so limbs don’t stretch unrealistically),
- Joint limits (no impossible twists),
- The character’s hierarchy (parents and children joints),
- Smooth changes over time (no sudden jerks).
This “positions first, rotations second” approach makes training easier and results more stable, especially when characters have very different skeletons.
What did they find?
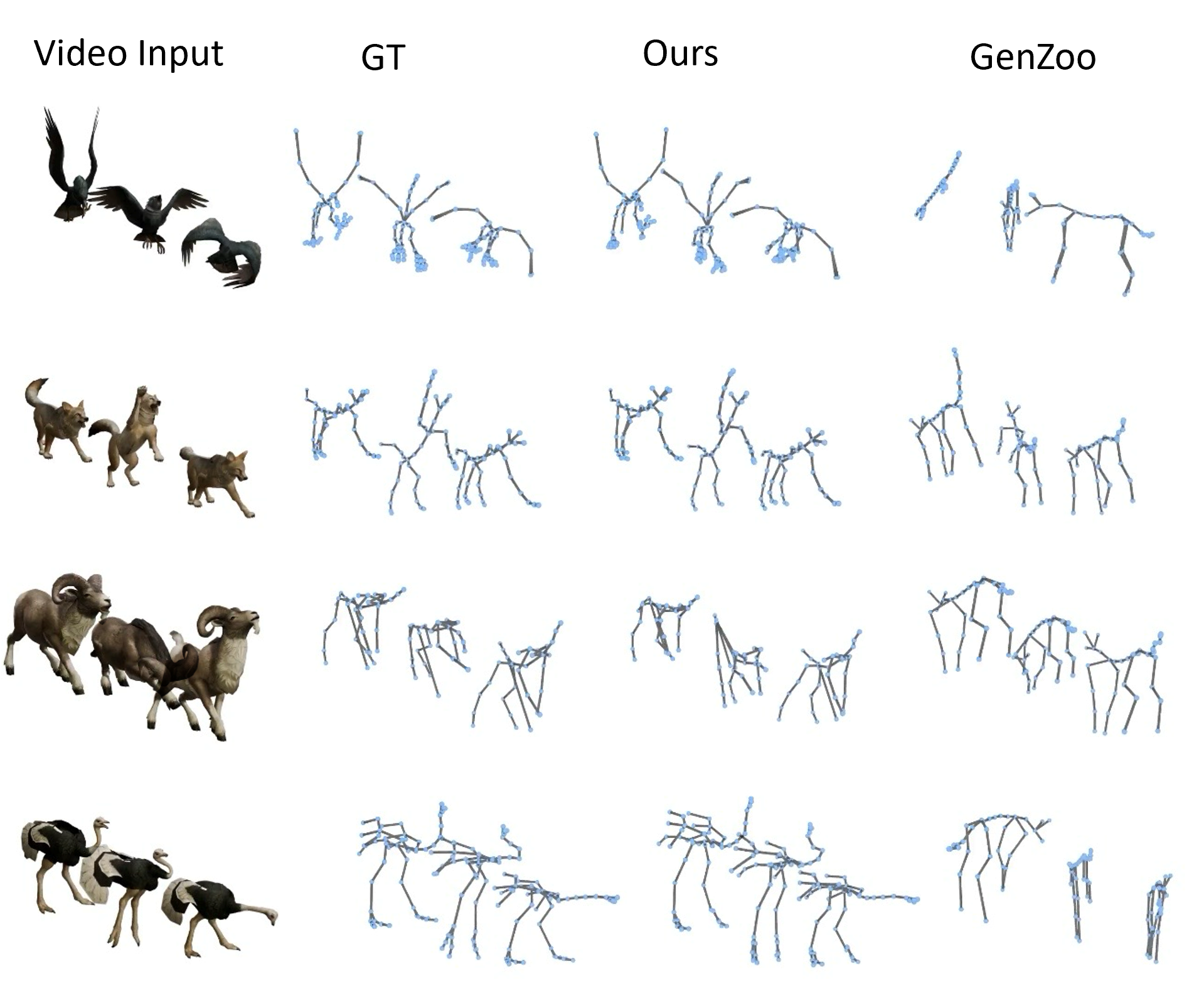
The researchers built and used a benchmark called Truebones Zoo with 1,038 motion clips, each containing a skeleton, a mesh, and matching rendered video, so the system could learn across many types of rigs.
Here’s what they showed:
- Better accuracy than a prior general animal mocap method (GenZoo), especially on non-quadruped characters (not just four-legged animals).
- Works not only in controlled test clips but also on internet “in-the-wild” videos, which are messy and varied.
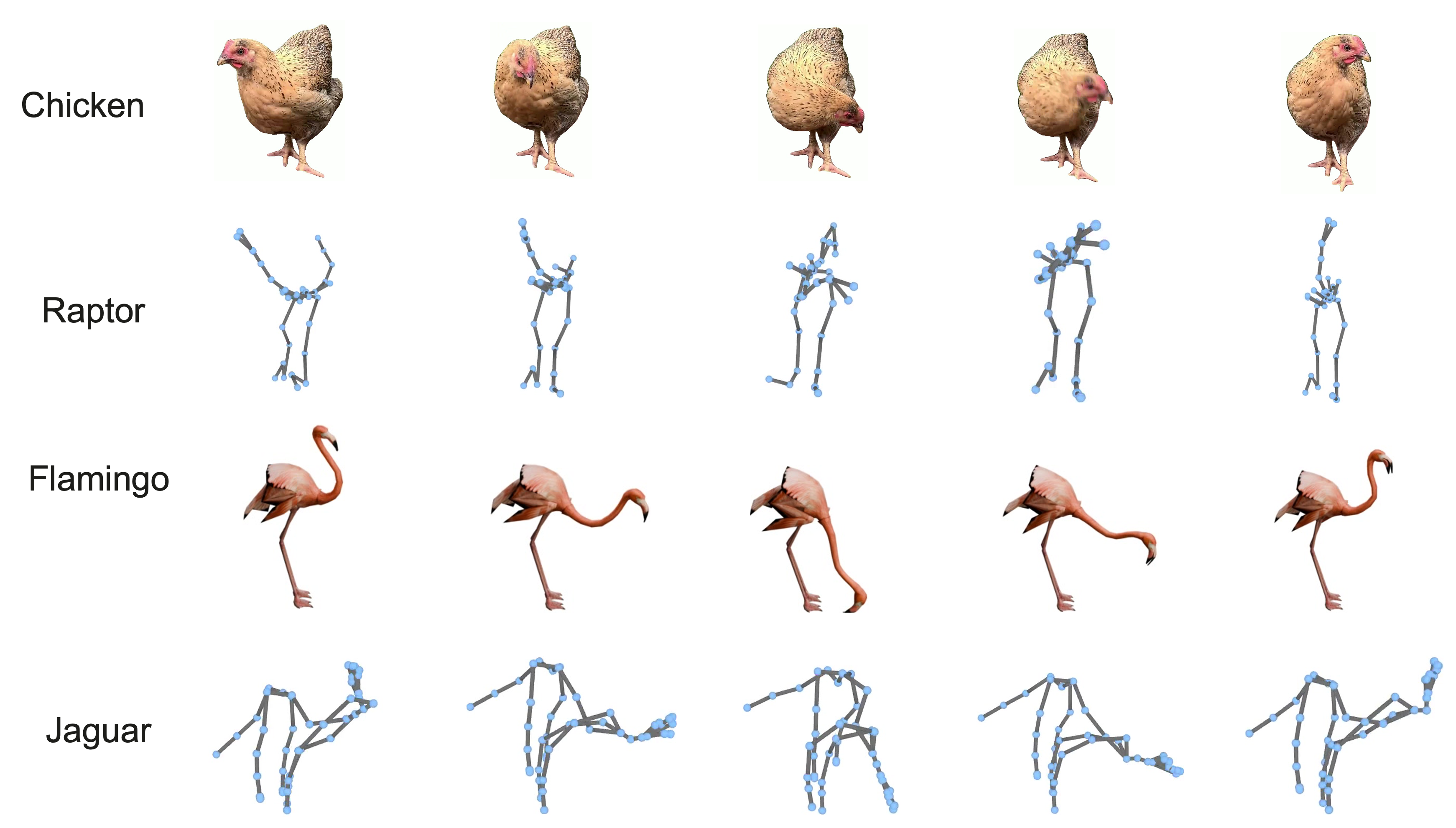
- Handles cross-species retargeting: motion from one creature can be applied to a very different character, like making a bird’s flapping influence a robot’s arms or a dinosaur’s wings.
- Smooth, stable animations that look anatomically believable for the given rig.
They also ran ablation studies (turning off parts of the system to test importance). They found:
- Using mesh geometry and skeleton-aware attention strongly improves performance,
- The carefully chosen architecture helps keep motion smooth on unfamiliar characters.
Why does this matter and what’s next?
This work opens a practical way to animate large libraries of 3D characters with just a regular video and a chosen 3D asset. It can help:
- Game studios and film teams quickly animate many different characters.
- VTubers and virtual production creators swap avatars without rebuilding special motion models each time.
- Artists and hobbyists retarget motion in creative ways (e.g., making a fish-like movement drive a snake or a robot).
Limitations and future directions, in simple terms:
- The method depends on how well the video-to-3D shape step works; if that’s poor, motion can be less accurate.
- It needs a rigged character with known joints to animate.
- It mostly works in camera space (it doesn’t yet fully understand the world’s floor, gravity, or physical contacts).
- Future improvements may include:
- More physics-aware motion and contact handling,
- Better global movement recovery (so motion isn’t tied to the camera’s view),
- Reducing reliance on the 4D mesh step,
- Using text or other prompts to describe the character,
- Handling multi-character interactions.
In short, MoCapAnything is a big step toward “plug-and-play” motion capture for any 3D character, turning ordinary videos into animation that fits the character’s own bones and rules.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide future research.
- Rotation-level evaluation is deferred: no quantitative metrics for joint rotation accuracy, foot sliding, contact consistency, joint-limit violations, or perceptual plausibility of the final BVH animations; a standardized rotation/retargeting evaluation suite and public code are needed.
- Camera-space limitation: the method entangles subject motion with camera motion and lacks world-grounded trajectories (e.g., root motion relative to ground, gravity, contact states); integration with SLAM/VIO and evaluation on moving-camera videos is missing.
- Heavy reliance on a pretrained image-to-3D reconstructor: no analysis of its failure modes (fast motion, blur, occlusions), sensitivity to reconstruction quality, or robustness when 4D reconstruction is inaccurate; controlled ablations and fallback strategies (video-only geometry priors) are needed.
- Assumption of a known, valid rig (joint hierarchy, bone lengths, limits): there is no method to automatically infer joint limits/constraints or validate rigs; learning asset-specific constraints from mesh/animation libraries and handling malformed/topology-variant rigs remain open.
- Semantic alignment for retargeting across heterogeneous skeletons is unspecified: how joint semantics are established (e.g., wing↔arm mapping) and evaluated remains unclear; metrics for correspondence quality (limb-wise mapping accuracy, symmetry preservation, motion semantics) and user studies are needed.
- Human motion evaluation is missing: despite supporting humanoid rigs, there is no quantitative evaluation on standard human benchmarks (e.g., AMASS, Human3.6M); cross-domain retargeting (human↔animal) lacks objective metrics.
- Benchmark scope and realism: Truebones Zoo is limited in scale/diversity and primarily synthetic (rendered asset videos); there is no large, real-world, multi-species CAMoCap benchmark with ground-truth rotations and contact labels; domain gap quantification is absent.
- Metric standardization: CD-Skeleton is not a widely accepted metric and its computation is under-specified; a community-standard CAMoCap metric set (MPJPE/velocity/acceleration, rotation error, foot-slide/contact stability, constraint violations, temporal smoothness) should be defined and validated.
- Runtime, memory, and scalability: there is no analysis of computational cost for 4D reconstruction, decoder, and IK (per frame, per sequence), nor real-time feasibility for production pipelines or large asset libraries.
- Multi-character scenes and interactions: the method is single-subject; handling multiple interacting characters, mutual occlusions, and inter-character constraints/collisions is left unexplored.
- Global scale and bone-length alignment: there is no study of scale normalization between video subject and target asset, nor controls for preserving or stylizing bone lengths during retargeting; quantitative analysis of length/scale mismatch effects is needed.
- Root motion and ground-contact modeling: root translation/orientation, ground-plane estimation, and contact constraints are not modeled; evaluation of foot slip and ground adherence is missing.
- Auto-rigging from mesh-only inputs: many assets lack skeletons; automatic rig extraction (joints, hierarchy, limits) from meshes and integration with the prompt encoder/IK are open problems.
- End-to-end rotation learning vs. factorized IK: the chosen trajectory→IK factorization may limit fidelity (e.g., bone-axis twist); quantify twist/roll errors and explore differentiable IK or hybrid rotation learning regimes.
- Robustness to incomplete or mismatched prompts: the system assumes mesh+skeleton+appearance; behavior when only skeleton, only mesh, only text prompts, or visually unrelated appearance is provided remains untested; formal fallback policies and performance characterization are needed.
- Joint naming and open-vocabulary semantics: reliance on standardized joint names is mentioned but not analyzed; open-vocabulary joint descriptions (e.g., language prompts) and cross-asset semantic alignment mechanisms need design and evaluation.
- Generalization and adaptation to new rigs: beyond ablating modalities, there is no protocol for few-shot adaptation/meta-learning to novel skeletons, nor analysis of how many examples are required for reliable transfer.
- Comparative baselines: aside from GenZoo (quadrupeds), broader baselines (model-free video-to-motion, 2D keypoint-based pipelines, optical-flow/feature tracking) are not included; controlled comparisons are needed to isolate gains from mesh and graph-attention choices.
- Error propagation analysis: the impact of trajectory prediction errors on IK outcomes (rotation drift, constraint violations, temporal jitter) is not quantified; sensitivity studies and error bounds would inform design trade-offs.
- Support for non-revolute joints and complex mechanisms: the framework assumes rotational DOFs; prismatic joints, closed kinematic chains, and mechanical rigs (robots, mechs) are not addressed; extending to general joints and loop constraints is open.
- Long-sequence stability: windowed temporal attention may drift on very long sequences; mechanisms for global temporal consistency (hierarchical memory, periodic re-anchoring) and corresponding evaluations are missing.
- Camera calibration and scale handling: intrinsics/extrinsics estimation and absolute scale recovery are not discussed; integrating camera calibration for metric motion and evaluating scale accuracy is needed.
- Self-contact and collision handling: neither mesh–mesh nor self-collisions are modeled; assessing and enforcing physical plausibility (contact, non-penetration) during IK or post-processing remains future work.
- Appearance-domain robustness: training on rendered asset videos may bias DINO-based features; there is no quantitative study of generalization across lighting, texture, and backgrounds; domain adaptation strategies are needed.
- Loss design: training uses only masked L1 position loss; explicit temporal, bone-length, and structural regularizers (velocity/acceleration smoothness, limb rigidity) are not explored; their impact on stability and generalization should be tested.
Glossary
- 4D mesh sequence: A time-varying 3D surface representation reconstructed from video frames to provide geometry over time. "A monocular video is converted into a 4D mesh sequence"
- Asset-specific rotations: Joint angle values expressed in the local coordinate frames of a particular rigged asset. "IK Fitting converts these trajectories into asset-specific rotations"
- BVH: Biovision Hierarchy; a common file/animation format representing skeletons and joint rotations. "rotation-based animation (e.g., BVH)"
- CAMoCap: Category-Agnostic Motion Capture; the task of capturing motion from video that can drive arbitrary rigs. "We formalize this gap as Category-Agnostic Motion Capture (CAMoCap)"
- CAPE: Category-agnostic pose estimation; a framework for predicting keypoints for unseen categories using prompts/support examples. "Beyond these category-specific keypoint detectors, an emerging line of work aims to relax the dependence on fixed object categories through category-agnostic pose estimation (CAPE)."
- CD-Skeleton: A Chamfer-distance-based metric measuring structural accuracy between predicted and ground-truth joint sets. "CD-Skeleton (Chamfer Distance): computes the symmetric Chamfer distance between predicted and ground-truth 3D joint sets"
- Chamfer Distance: A symmetric distance between two point sets, used here to compare predicted and true joint positions. "CD-Skeleton (Chamfer Distance): computes the symmetric Chamfer distance between predicted and ground-truth 3D joint sets"
- Cross-asset retargeting: Transferring captured motion from a source subject/video to a different target asset/rig. "cross-asset retargeting (reference differs from video)"
- Cross-species retargeting: Motion transfer across rigs that represent different species or categories. "exhibits non-trivial cross-species retargeting across heterogeneous rigs"
- DINOv2: A pretrained vision transformer used to extract dense visual descriptors/tokens from images. "computes dense visual descriptors (e.g., DINOv2)"
- Forward Kinematics (FK): Computing joint positions by applying rotations along a skeleton hierarchy from root to leaves. "discrepancy between FK-reconstructed joints"
- Graph Multi-Head Attention (GMHA): An attention mechanism biased by skeleton topology to enable structure-aware message passing. "We use a graph multi-head attention (Graph-MHA)"
- IK Fitting: An optimization stage that converts predicted joint positions into rig-consistent joint rotations. "constraint-aware Inverse Kinematics (IK) Fitting"
- Inverse Kinematics (IK): Computing joint rotations that achieve desired end-effector or joint positions, subject to constraints. "recover asset-specific rotations via constraint-aware Inverse Kinematics (IK) Fitting."
- Joint limits: Constraints on allowable joint rotations to ensure anatomically or mechanically plausible motion. "respecting hierarchy, bone lengths, joint limits, and temporal smoothness"
- Kinematic chain: An ordered sequence of joints linked by bones, typically from a parent toward distal end-effectors. "along each kinematic chain."
- Kinematic tree: A hierarchical skeleton structure encoding parent-child joint relationships. "ensuring that updates respect the kinematic tree"
- Monocular human motion capture: Recovering human pose and shape parameters from a single-camera (single-view) input. "Monocular human motion capture is typically formulated as recovering pose and shape parameters of parametric whole-body models such as SMPL"
- Monocular video: A single-view video used as input for motion capture. "given a monocular video and a reference 3D asset"
- MPJPE: Mean Per Joint Position Error; average Euclidean distance between predicted and ground-truth joint positions. "MPJPE (Mean Per Joint Position Error): the mean Euclidean distance between predicted and ground-truth joint positions (lower is better)."
- MPJVE: Mean Per Joint Velocity Error; average difference in joint velocities over time, assessing temporal consistency. "MPJVE (Mean Per Joint Velocity Error): the average velocity difference per joint, capturing temporal consistency and motion plausibility."
- Reference Prompt Encoder: A module that fuses mesh, skeleton, and appearance of the target asset into per-joint query embeddings. "The Reference Prompt Encoder distills the asset’s mesh, skeleton, and rendered image set into structure-aware per-joint queries."
- Retargeting: Mapping captured motion to a different skeleton/rig than the source. "supports both motion capture (same skeleton) and retargeting (different skeletons)"
- Skeleton hierarchy: The parent-child joint structure defining how rotations propagate through the rig. "respects the skeleton hierarchy."
- Skeleton topology: The structural connectivity and layout of joints and bones within a rig. "Self-Attention with Skeleton Topology."
- Skinning: The relationship between joints and surface geometry used to deform meshes consistently with skeletal motion. "implicit skinning-like relations between joints and local surface geometry."
- Temporal self-attention: An attention mechanism along the time axis to enhance motion consistency and reduce jitter. "Temporal self-attention (per joint)."
- Truebones Zoo: A curated benchmark of motion clips providing skeleton–mesh–rendered-video triads for training and evaluation. "We also curate Truebones Zoo with 1{,}038 motion clips"
- Unified Motion Decoder: A module that fuses reference and video features to predict temporally coherent 3D joint trajectories. "The Unified Motion Decoder fuses these cues to produce temporally coherent trajectories."
- Video Feature Extractor: A module that computes dense visual descriptors and geometry tokens from the input video. "a Video Feature Extractor that computes dense visual descriptors"
- World-grounded human motion recovery: Estimating motion in a global/world coordinate frame rather than camera coordinates. "camera-space and world-grounded human motion recovery."
Practical Applications
Practical Applications of “MoCapAnything: Unified 3D Motion Capture for Arbitrary Skeletons from Monocular Videos”
Below, we synthesize actionable, real-world applications grounded in the paper’s findings and system design (reference-guided CAMoCap, 3D joint trajectory prediction + IK fitting, and cross-asset retargeting). Each item includes sector alignment, likely tools/workflows/products, and key assumptions or dependencies that influence feasibility.
Immediate Applications
These can be prototyped or deployed with current capabilities (offline or near–offline), given the framework and available tooling (e.g., BVH output, standard DCCs, Unity/Unreal).
- Video-to-animation plugins for DCCs (Blender, Maya, Houdini)
- Sector: Media/entertainment, software
- Use case: “Import video + rig → export BVH/FBX” for any asset (creatures, mascots, mechs, props). Supports retargeting across heterogeneous rigs without building species-specific templates.
- Workflow/product: A DCC add-on that ingests a monocular video and a rigged character (mesh + skeleton + a few renders), runs MoCapAnything, and writes animation to the asset’s rig convention. Optional batch processing and asset library linkage.
- Assumptions/dependencies: Rig with a clean hierarchy and joint limits; access to a pretrained image-to-3D reconstructor; adequate GPU; reasonable video quality; skeleton naming consistency improves results.
- Game engine importer for arbitrary-rig animations
- Sector: Gaming (Unity/Unreal), content pipelines
- Use case: Populate creature/NPC libraries by mining motions from videos (e.g., birds, quadrupeds, fantasy creatures), retargeting to studio rigs at scale.
- Workflow/product: A Unity/Unreal plugin that converts web/shot footage to BVH and binds to Animator/Control Rigs; batch application across asset catalogs; motion libraries for crowd systems.
- Assumptions/dependencies: Batch job infrastructure; legal clearance for source videos; robust handling of camera motion and occlusions; QA checks for edge-case rigs.
- VTubers and virtual production: offline/near–offline performance capture for arbitrary avatars
- Sector: Virtual production, creator economy
- Use case: Precompute “takes” from phone videos and retarget to varied avatar topologies (new models per stream); generate variants quickly without suit-based capture.
- Workflow/product: Creator tools that convert mobile clips into avatar animations; multi-avatar retargeting for the same performance.
- Assumptions/dependencies: Not real-time; requires asset renders/mesh; background/camera motion may affect camera-space outputs.
- Rapid previs and creative ideation for directors/animators
- Sector: Film/VFX, advertising
- Use case: Director records quick blocking videos (humans or proxies) and retargets to creature or prop rigs for shot planning; iterate on beats without stage capture.
- Workflow/product: Lightweight previs utility that outputs animation takes; integrates with editorial/shot management tools.
- Assumptions/dependencies: Camera-space motion (not world-grounded); contact/dynamics not enforced; good-enough pose fidelity for previs, not final physical realism.
- Fast mascot/character animation for marketing and social content
- Sector: Marketing, media
- Use case: Turn staff-recorded movements into mascot animations for campaigns; cross-skeleton retargeting enables playful, diverse content generation.
- Workflow/product: Cloud service or internal tool that ingests clips and outputs ready-to-post animated sequences.
- Assumptions/dependencies: Brand rig conventions; quality control on IK and joint limits; rights to use input videos.
- Educational/interactive “gait explorer” for biology and art schools
- Sector: Education
- Use case: Students capture animal movements from videos and visualize underlying joint motions on 3D skeletons; study gait cycles across species.
- Workflow/product: Classroom/web app that maps video clips to example skeletons, compares species, and exports animations for study.
- Assumptions/dependencies: Camera-space estimates (qualitative learning > precise metrology); availability of example rigs per species.
- Qualitative wildlife and ethology analysis from field videos
- Sector: Academia/research (ecology, animal behavior)
- Use case: Extract approximate skeletal trajectories from monocular footage to examine behavior patterns, limb coordination, and comparative motions.
- Workflow/product: Research toolkit that outputs 3D joint trajectories for exploratory analysis; integrates with visualization dashboards.
- Assumptions/dependencies: Camera-space only; coarse accuracy due to occlusions/low-res footage; not suitable for rigorous biomechanical metrics without calibration.
- Animatronics and simulation prototyping
- Sector: Robotics/animatronics, themed entertainment
- Use case: Use extracted joint trajectories to drive kinematic simulations or offline animatronic sequences for non-human characters.
- Workflow/product: Pipeline to convert video motions to joint angle curves matched to animatronic rigs for offline playback or simulation.
- Assumptions/dependencies: Kinematic compatibility and joint limits; timing re-mapping; still camera-frame rather than world-frame; no contact/dynamics.
- Academic benchmarking and method development
- Sector: Academia/ML research
- Use case: Use the curated Truebones Zoo triads to benchmark category-agnostic motion capture, evaluate multi-modal fusion strategies, and study cross-species retargeting.
- Workflow/product: Public benchmark with standardized skeleton–mesh–rendered video triads; training baselines and evaluation scripts (MPJPE, MPJVE, CD-Skeleton).
- Assumptions/dependencies: Dataset license/availability; model reproducibility; alignment on metrics and splits.
Long-Term Applications
These require further research (e.g., world-grounding, physics/contact modeling), engineering for scale/latency, or validation for high-stakes domains.
- Real-time, on-device CAMoCap for live avatars
- Sector: VTubing, live broadcasting, AR
- Use case: Live drive arbitrary avatars (humans/creatures/props) from a single camera feed with sub-100 ms latency.
- Potential tools/workflows: Compressed backbones, video-only geometric priors (no 4D reconstruction), fast IK on GPU; integration with OBS/AR SDKs.
- Assumptions/dependencies: Substantial model optimization; robust temporal smoothing; occlusion handling; fast camera-motion compensation.
- World-grounded motion for robotics imitation and control
- Sector: Robotics
- Use case: Extract global trajectories and contact-aware kinematics from videos to adapt motions to robot-specific joints for planning/control.
- Potential tools/workflows: Integrate SLAM/VO to estimate world-frame trajectories; physics- and contact-aware IK; mapping to robot joint limits and dynamics; deployment in simulators (Isaac Gym, MuJoCo) before hardware.
- Assumptions/dependencies: Accurate camera/world calibration; contact detection; feasible robot morphology mappings; safety constraints.
- Clinical-grade veterinary and sports biomechanics
- Sector: Healthcare/veterinary, sports science
- Use case: Quantitative gait assessment for horses/dogs or zoo animals from clinics or field videos; longitudinal monitoring and early anomaly detection.
- Potential tools/workflows: Calibrated capture protocols (markers/scale references); world-grounded trajectory recovery; validated joint-angle and spatiotemporal metrics; EMR integration.
- Assumptions/dependencies: Regulatory validation; accuracy benchmarks vs. motion-lab gold standards; robust contact modeling; standardized rigs per species.
- Large-scale, contact- and physics-aware animation pipelines for film/VFX
- Sector: Film/VFX
- Use case: Replace significant portions of marker-based capture in creature work with video-based pipelines that maintain foot contacts, collisions, and environment interactions.
- Potential tools/workflows: End-to-end contact-aware modeling; environmental constraints; integration with production asset management and shot tracking; autotune per-rig IK profiles.
- Assumptions/dependencies: High-fidelity contact/dynamics; multi-camera fusion when available; shot-specific calibration.
- Multi-character interactions and choreography synthesis
- Sector: Games, film, simulation
- Use case: Extract interacting motions (predator–prey, packs, flocks) from videos and retarget them to heterogeneous rigs while preserving contacts and relative trajectories.
- Potential tools/workflows: Multi-agent tracking, relational motion decoders, scene graph constraints; paired IK with interaction priors.
- Assumptions/dependencies: Reliable multi-target detection; occlusion-heavy scenarios; robust interaction priors; world-grounding.
- Conservation policy support through automated behavior analytics
- Sector: Public policy, conservation
- Use case: Use long-term field footage to derive behavioral indicators (e.g., migration timing, stress gait changes) that inform habitat protection or anti-poaching strategies.
- Potential tools/workflows: Scalable processing of camera-trap streams; species-specific rigs; dashboards for behavioral trend reports.
- Assumptions/dependencies: Data rights and privacy; measurement validity in natural settings; investment in infrastructure; collaboration with ecologists.
- Text-only or multimodal prompting for asset-free capture
- Sector: Software/ML research, content creation
- Use case: Drive motion directly from video to text-defined skeletons (no mesh/rig renders), or from text-only prompts to create motion skeletons for procedural assets.
- Potential tools/workflows: Vision–LLMs aligned to skeletal semantics; on-the-fly rig generation with learned constraints; procedural rigging.
- Assumptions/dependencies: Advances in open-vocabulary joint semantics and rig synthesis; error detection/correction for ambiguous prompts.
- Mobile consumer apps for motion-to-avatar transformation
- Sector: Consumer apps, social media
- Use case: One-tap “make my creature/avatar move like this” on phones; social filters and animated stickers for any avatar topology.
- Potential tools/workflows: On-device inference or cloud offloading; direct export to Reels/TikTok; simplified rig validators.
- Assumptions/dependencies: Model compression and latency; robust default rigs; safety/content policies; simplified UX for non-experts.
Cross-Cutting Dependencies and Assumptions
- Technical
- Reliance on pretrained image encoders (e.g., DINOv2) and image-to-3D reconstructor quality for 4D mesh sequences.
- Camera-space outputs by default; world-grounded trajectories and accurate contact reasoning require additional modules (SLAM/VO, physics-aware IK).
- Requires rigged assets with clean hierarchies and joint limits; consistent joint naming/semantics improve performance.
- Monocular video quality (occlusion, motion blur, camera motion) directly affects accuracy; multi-view improves results but falls outside baseline.
- Operational and Legal
- Rights to use input videos (web-mined or user-provided) and export resulting animations (IP considerations).
- Compute resources for training/inference; potential need for cloud deployments for scale.
- Quality assurance for production (artifact detection, auto-cleanup of jitter/twist).
- Domain-Specific
- High-stakes domains (clinical, robotics) need rigorous validation, calibration protocols, and safety constraints.
- Species- and rig-specific idiosyncrasies may require tailored joint-limit profiles and IK tuning.
These application paths leverage MoCapAnything’s core strengths—category-agnostic, prompt-based motion capture and cross-asset retargeting—while acknowledging current limits (camera-space estimation, dependency on 4D reconstruction, lack of explicit physics/contact).
Collections
Sign up for free to add this paper to one or more collections.